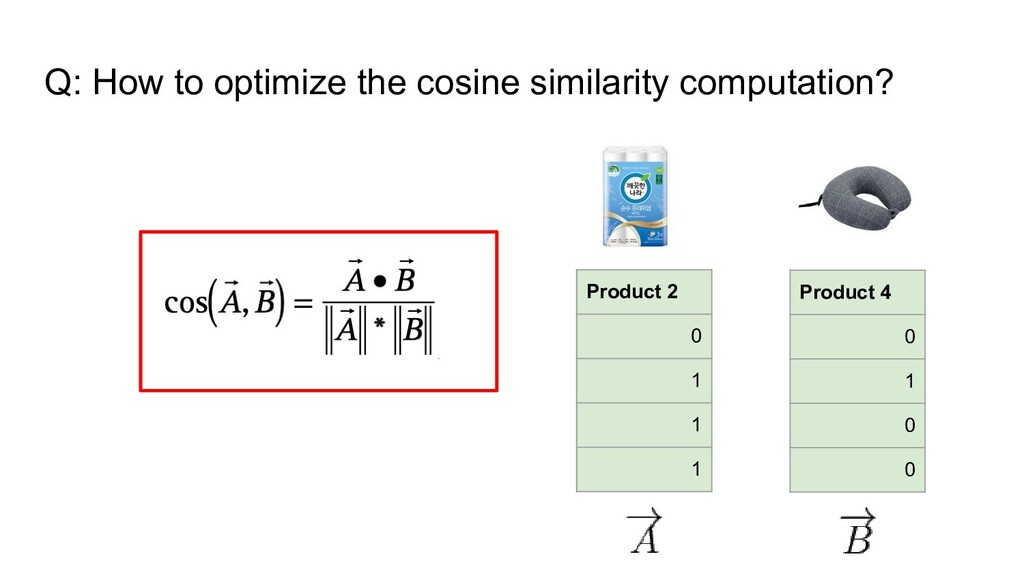
scipy.sparse import csr_matrix from sklearn.metrics.pairwise import cosine_similarity a = csr_matrix(...) b = csr_matrix(...) sim = cosine_similarity(a, b) # 6x faster
version now takes 1200 hours (50일) 300일 전역하기 전까지는 끝낼 수 있다 from scipy.sparse import csr_matrix from sklearn.metrics.pairwise import cosine_similarity a = csr_matrix(...) b = csr_matrix(...) sim = cosine_similarity(a, b) # 6x faster
time • Optimize algorithms from the single-core level, then multi-core • Deploying & managing ML is hell but most of it can be automated • Building your own tools can increase your life quality by 10X ◦ Python + boto3 makes it very easy. PeterFlow is <200 lines.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
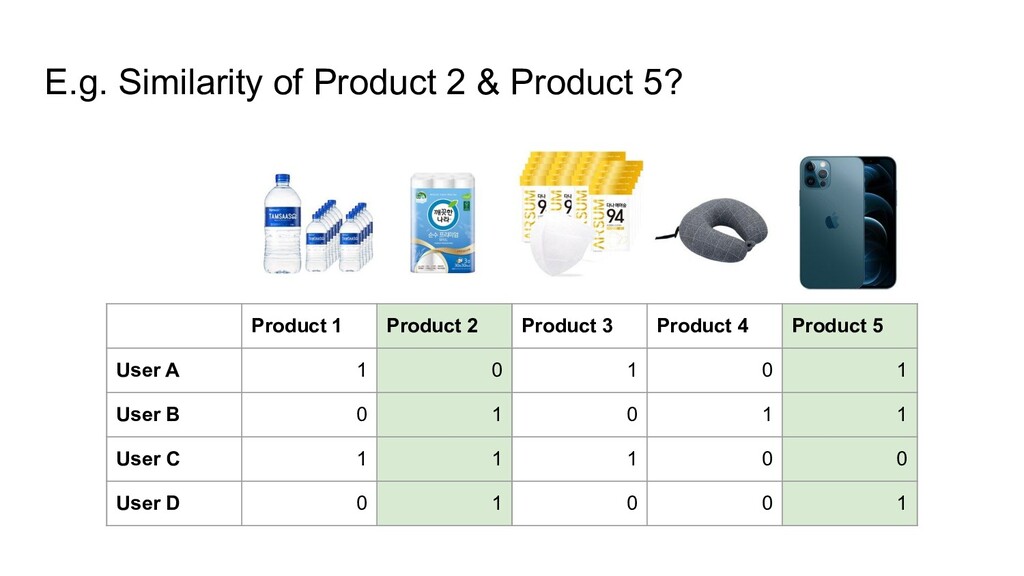{kind=link}
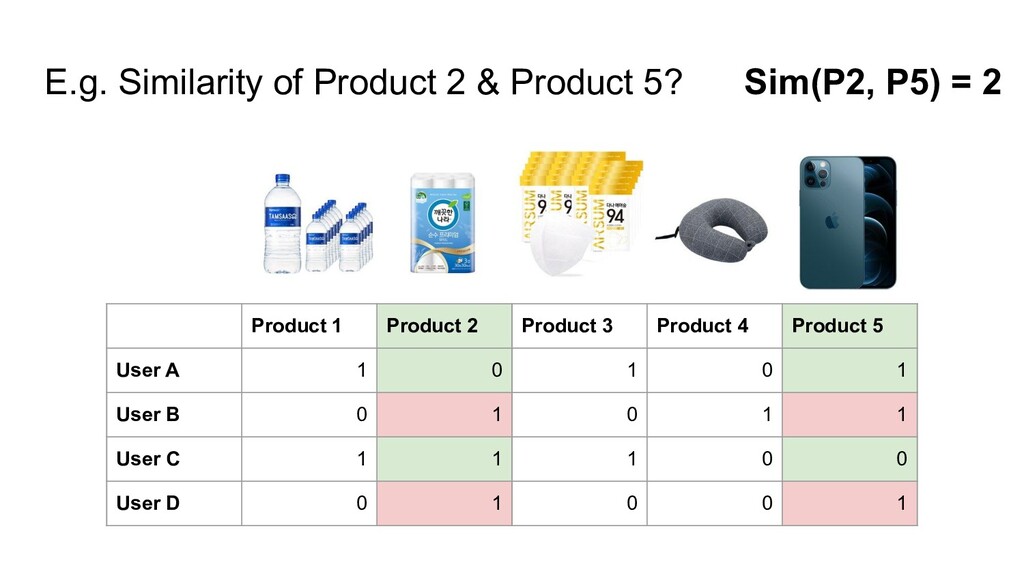{kind=link}
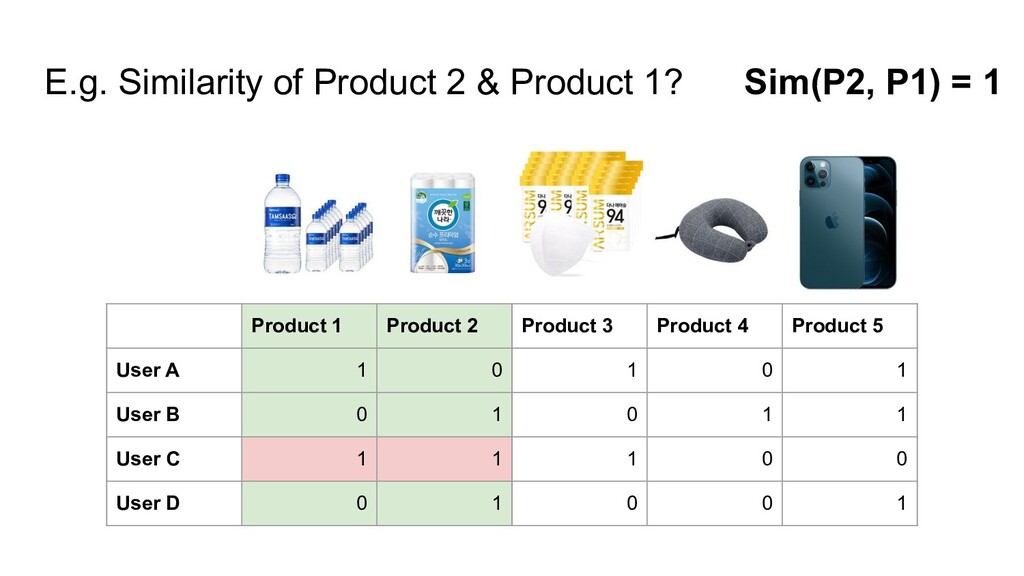{kind=link}
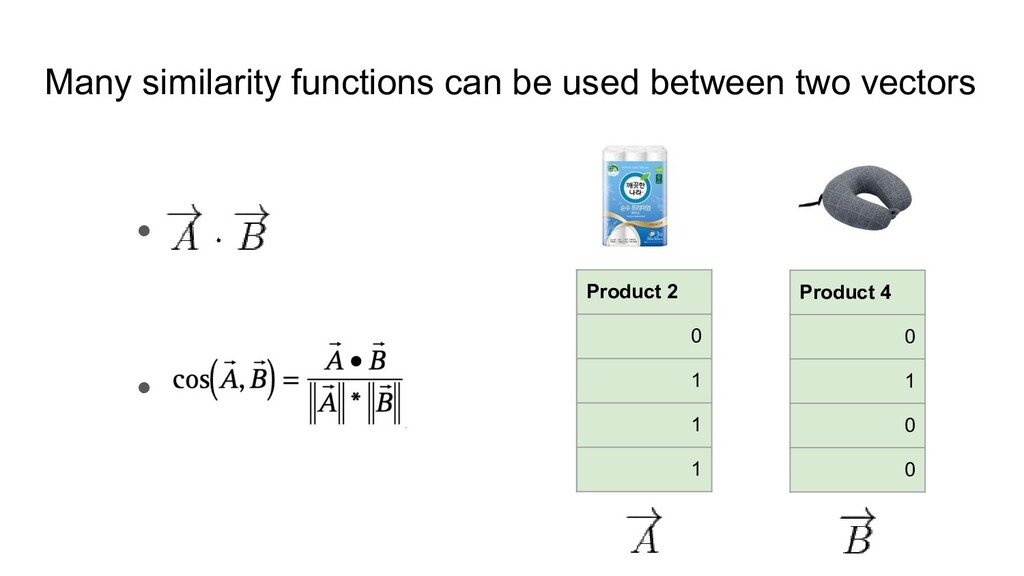{kind=link}
{kind=link}
{kind=link}
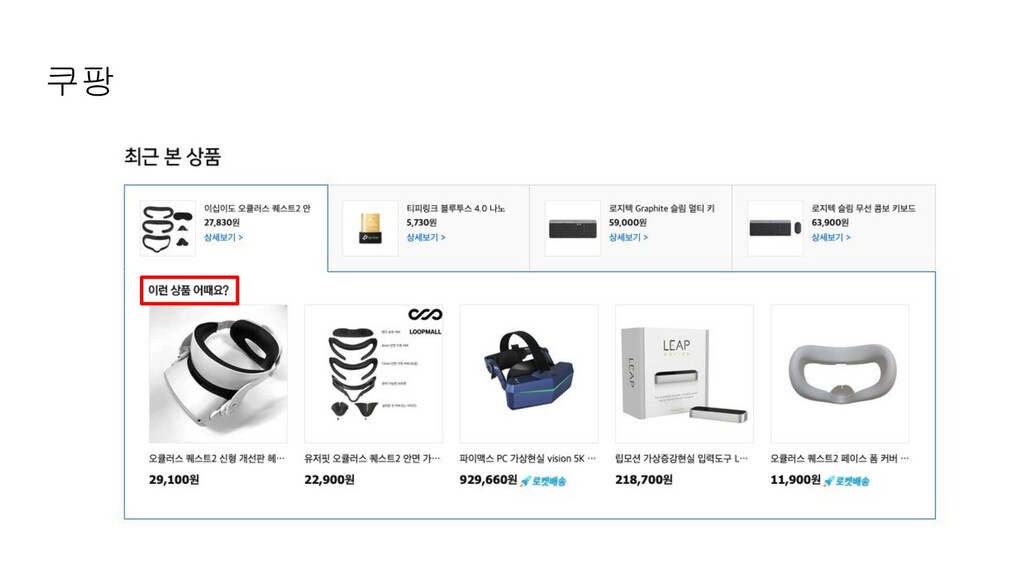{kind=link}
{kind=link}
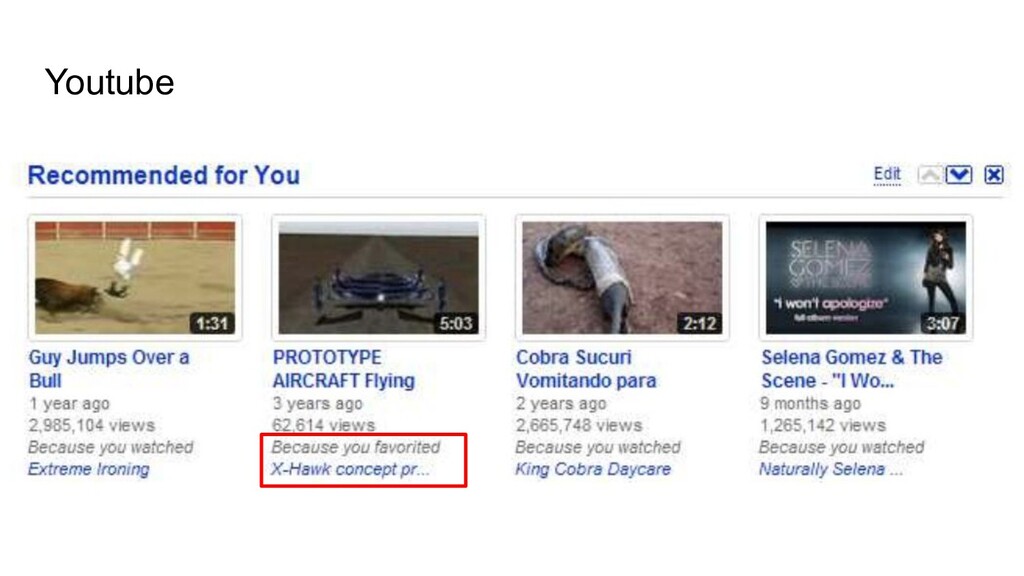{kind=link}
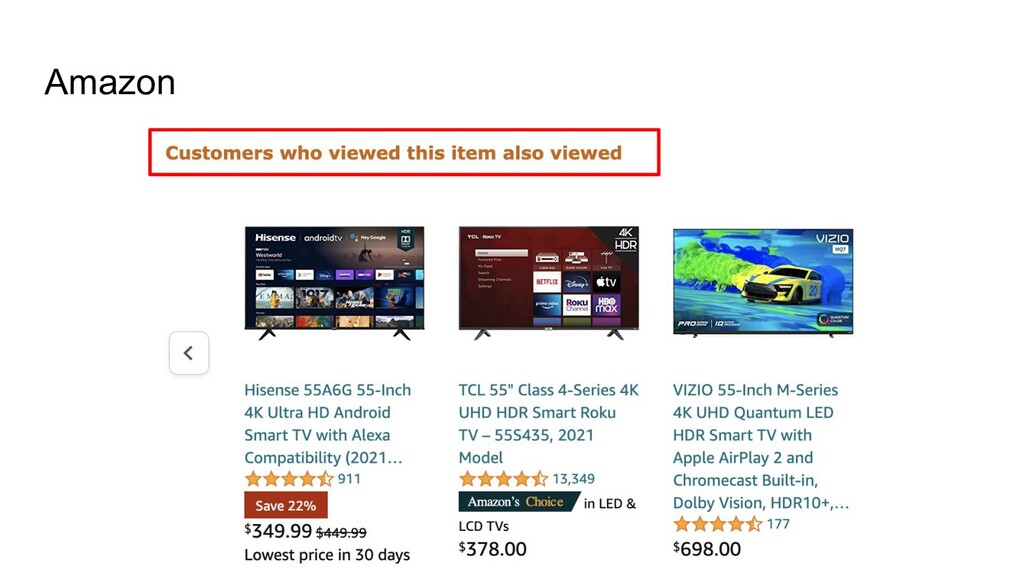{kind=link}
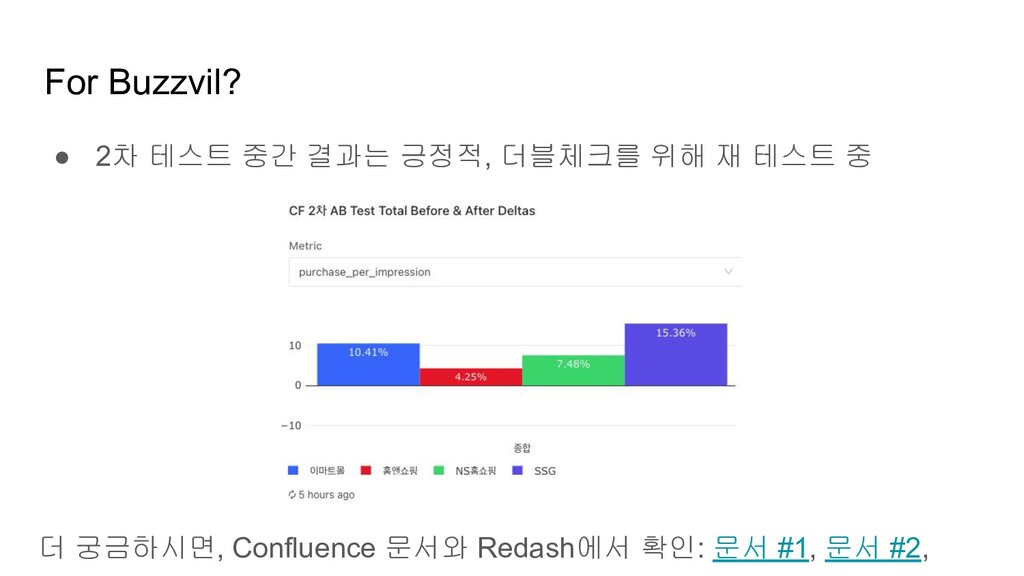{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}