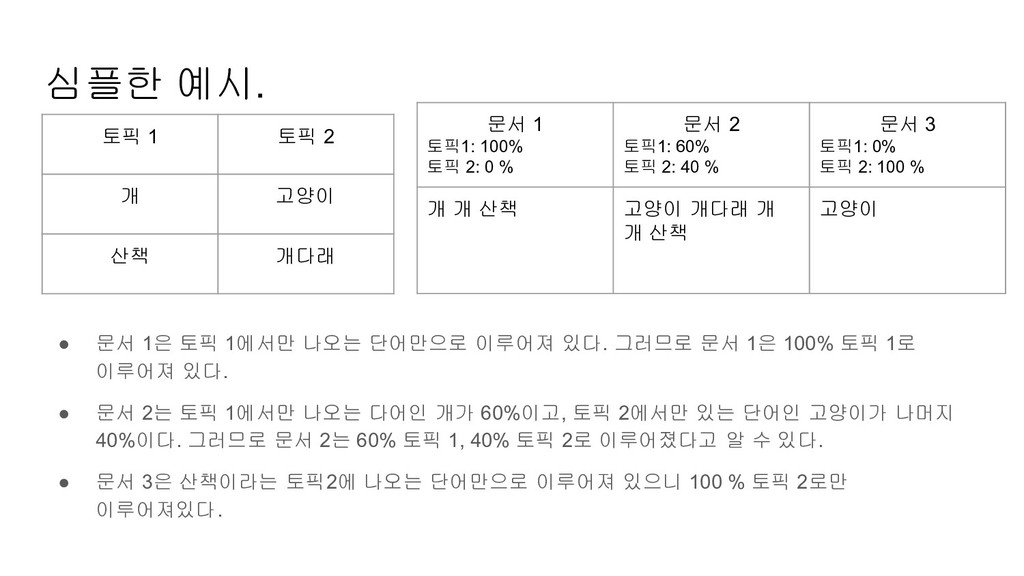
있다. 그러므로 문서 1은 100% 토픽 1로 이루어져 있다. • 문서 2는 토픽 1에서만 나오는 다어인 개가 60%이고, 토픽 2에서만 있는 단어인 고양이가 나머지 40%이다. 그러므로 문서 2는 60% 토픽 1, 40% 토픽 2로 이루어졌다고 알 수 있다. • 문서 3은 산책이라는 토픽2에 나오는 단어만으로 이루어져 있으니 100 % 토픽 2로만 이루어져있다. 토픽 1 토픽 2 개 고양이 산책 개다래 문서 1 토픽1: 100% 토픽 2: 0 % 문서 2 토픽1: 60% 토픽 2: 40 % 문서 3 토픽1: 0% 토픽 2: 100 % 개 개 산책 고양이 개다래 개 개 산책 고양이
가장 기본적인 용도 • 검색 ◦ 단순히 입력 키워드의 개수만을 가지고 검색결과를 정하는 알고리즘은(예 tfidf) 입력 키워드가 포함되지 않은 문서는 검색결과에서 제외하게 된다. ◦ 토픽 모델링은 입력된 키워드에 없는 단어만을 가진 문서라도 입력된 키워드와 연관이 높다면 검색결과의 상위에 포함 시킬 수도 있다. • 주어진 문서들에 대한 인사이트 ◦ 주어진 문서의 집합에서 어떻한 주제들이 나타나는지 관찰하여 새로운 인사이트를 얻을 수 있다. ◦ 비중이 높은 주제에 맞춘 컨텐츠의 작성 등. • 추천 시스템 ◦ 텍스트를 가지고 있는 아이템들의 경우 토픽 모델링으로 토픽을 추출하고 각 아이템의 토픽 구성 벡터를 생성후, 유저가 열람한 아이템들의 토픽 구성률을 구한후 이에 기반하여 유저가 열람하는 아이템들과 비슷한 구성의 토픽을 가진 아이템을 추천할 수 있다.
토픽이 정해졌을 경우) 각 토픽은 단어의 분포도이다. 다음과 같은 2개의 토픽이 주어졌다. 단어 고양이 개 토픽 1 80% 20% 토픽 2 10% 90% 여기서 토픽 1을 40% 토픽 2를 60%로 해서 단어가 10개 들어간 문서를 만들고자 한다. 토픽 1 토픽 2 40% 60%
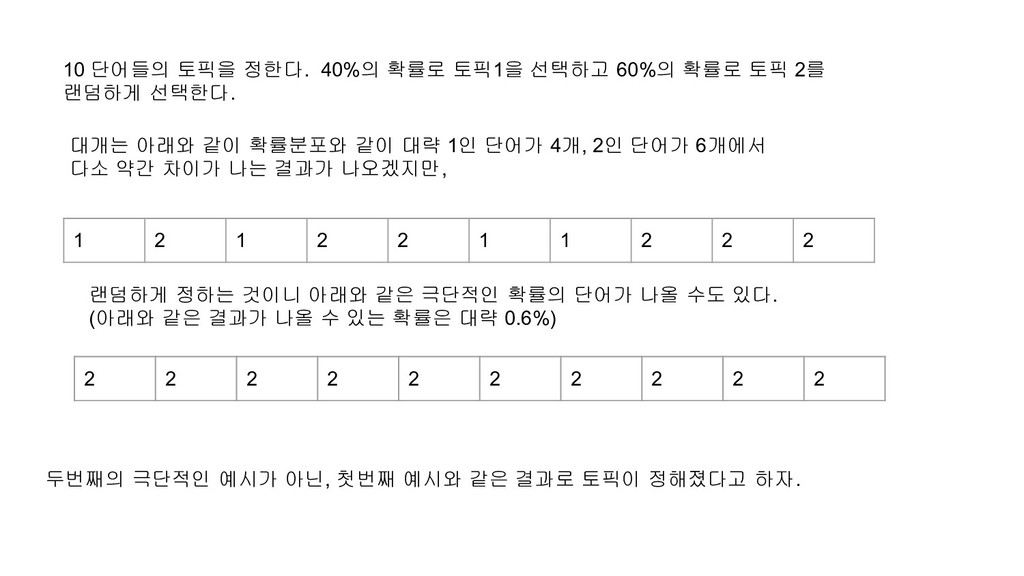
토픽 2를 랜덤하게 선택한다. 1 2 1 2 2 1 1 2 2 2 대개는 아래와 같이 확률분포와 같이 대략 1인 단어가 4개, 2인 단어가 6개에서 다소 약간 차이가 나는 결과가 나오겠지만, 2 2 2 2 2 2 2 2 2 2 랜덤하게 정하는 것이니 아래와 같은 극단적인 확률의 단어가 나올 수도 있다. (아래와 같은 결과가 나올 수 있는 확률은 대략 0.6%) 두번째의 극단적인 예시가 아닌, 첫번째 예시와 같은 결과로 토픽이 정해졌다고 하자.
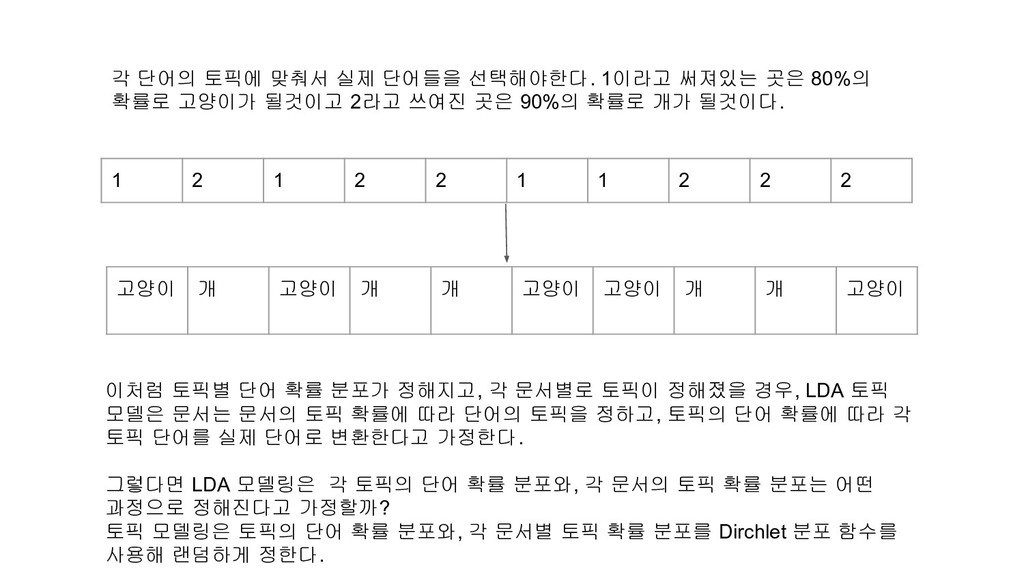
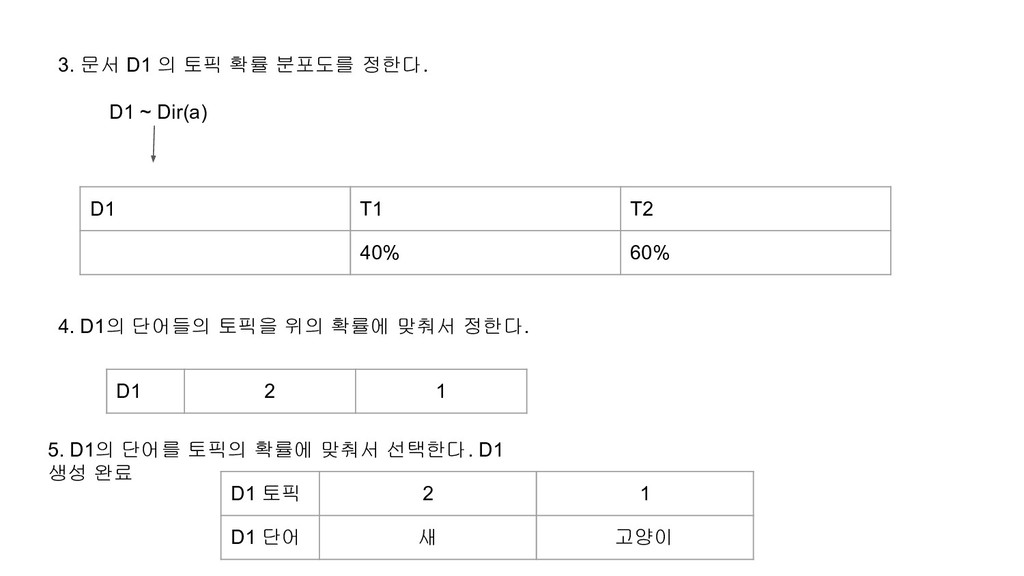
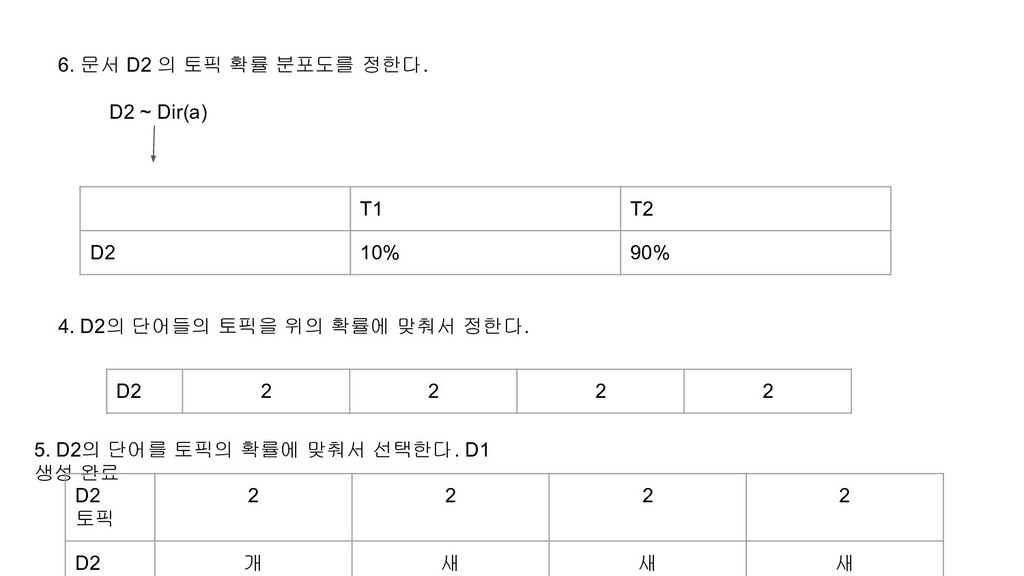
80%의 확률로 고양이가 될것이고 2라고 쓰여진 곳은 90%의 확률로 개가 될것이다. 1 2 1 2 2 1 1 2 2 2 고양이 개 고양이 개 개 고양이 고양이 개 개 고양이 이처럼 토픽별 단어 확률 분포가 정해지고, 각 문서별로 토픽이 정해졌을 경우, LDA 토픽 모델은 문서는 문서의 토픽 확률에 따라 단어의 토픽을 정하고, 토픽의 단어 확률에 따라 각 토픽 단어를 실제 단어로 변환한다고 가정한다. 그렇다면 LDA 모델링은 각 토픽의 단어 확률 분포와, 각 문서의 토픽 확률 분포는 어떤 과정으로 정해진다고 가정할까? 토픽 모델링은 토픽의 단어 확률 분포와, 각 문서별 토픽 확률 분포를 Dirchlet 분포 함수를 사용해 랜덤하게 정한다.
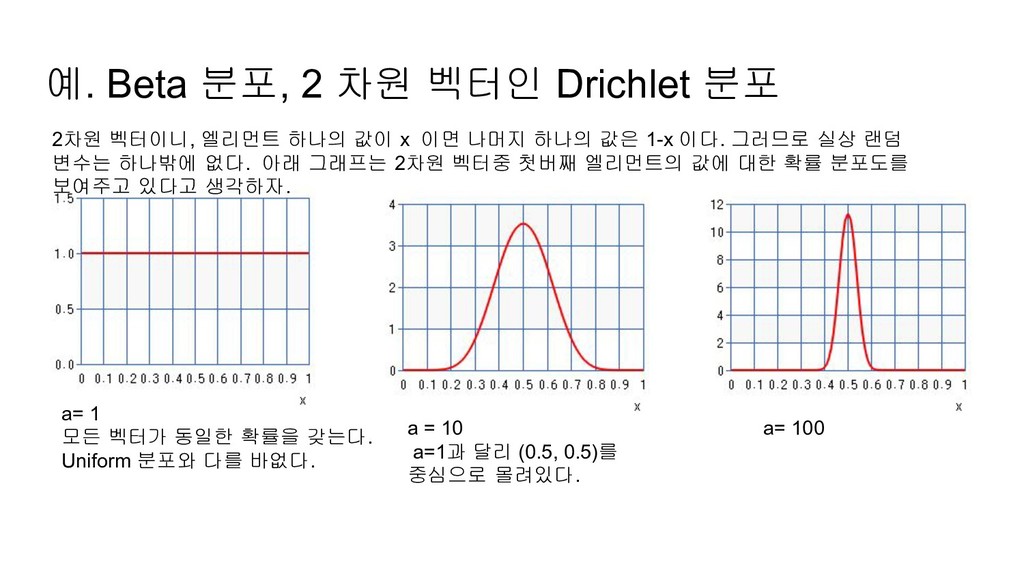
벡터를 랜덤하게 생산하는데 사용되는 확률 분포이다. 생성되는 랜덤 변수인 벡터의 엘리먼트의 합은 1이고 각 엘리먼트는 0 이상의 값ㅇ르 갖는다. 예. n= 2인 경우 (0.5, 0.5), (0.32, 0.68) 등이 Drichlet 분포로 생성될 수 있는 랜덤변수의 값이다. (2, -1), (23, 24), (0.1, 1.1) 등은 생성될 수 없는 값이다.
모든 벡터가 동일한 확률을 갖는다. Uniform 분포와 다를 바없다. a = 10 a=1과 달리 (0.5, 0.5)를 중심으로 몰려있다. a= 100 2차원 벡터이니, 엘리먼트 하나의 값이 x 이면 나머지 하나의 값은 1-x 이다. 그러므로 실상 랜덤 변수는 하나밖에 없다. 아래 그래프는 2차원 벡터중 첫버째 엘리먼트의 값에 대한 확률 분포도를 보여주고 있다고 생각하자.
n을 정한다. 2. 토픽 생성시에 사용할 Dirchlet 함수의 하이퍼 파라미터 b를 정한다. 3. 문서 생성시에 사용할 Dirchlet 함수의 하이퍼 파라미터 a를 정한다. 4. Dir(b)를 사용해 n개의 토픽 벡터를 생성한다. 토픽의 엘리먼트 개수는 사용할 유니크 단어의 개수인다. 5. Dir(a)를 사용해 생성할 문서의 토픽 확률을 정한다. 6. 문서의 토픽 확률에 따라 문서에 나오는 단어의 토픽을 정한다. 7. 문서에 있는 단어들의 토픽에 따라 실제 단어를 정한다.
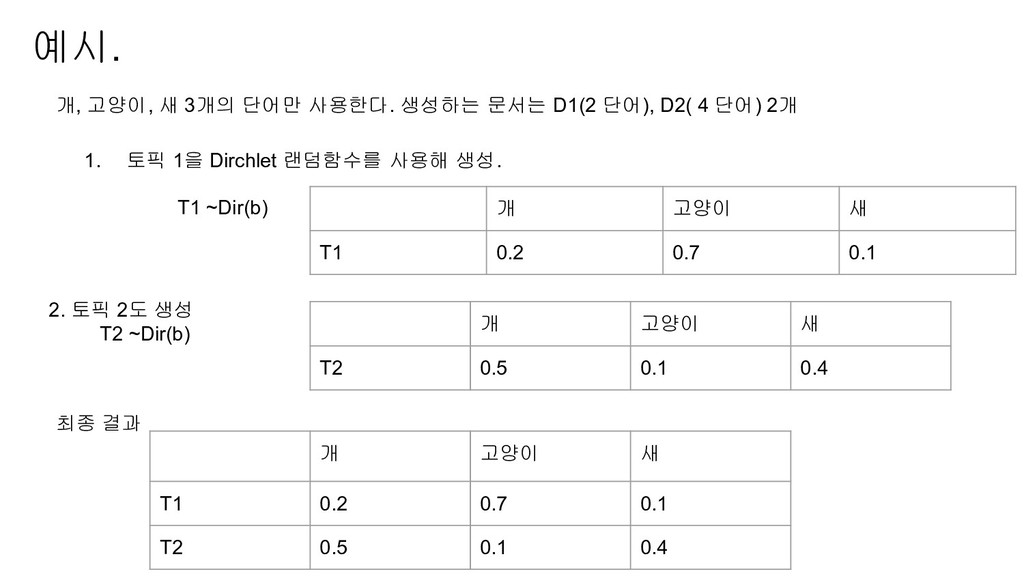
개 고양이 새 T1 0.2 0.7 0.1 2. 토픽 2도 생성 T2 ~Dir(b) 개 고양이 새 T2 0.5 0.1 0.4 개, 고양이, 새 3개의 단어만 사용한다. 생성하는 문서는 D1(2 단어), D2( 4 단어) 2개 개 고양이 새 T1 0.2 0.7 0.1 T2 0.5 0.1 0.4 최종 결과
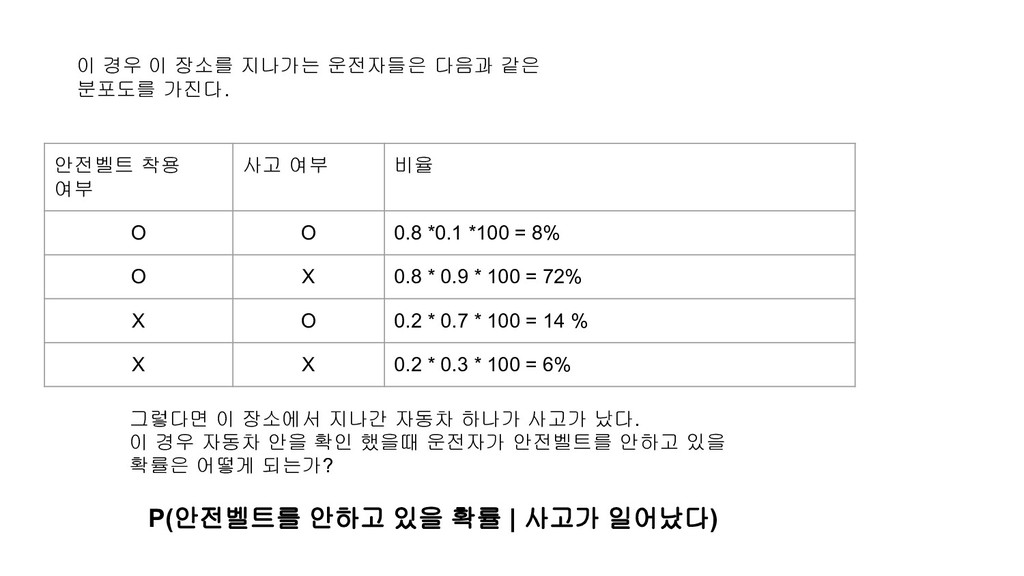
안전벨트 착용 여부 사고 여부 비율 O O 0.8 *0.1 *100 = 8% O X 0.8 * 0.9 * 100 = 72% X O 0.2 * 0.7 * 100 = 14 % X X 0.2 * 0.3 * 100 = 6% 그렇다면 이 장소에서 지나간 자동차 하나가 사고가 났다. 이 경우 자동차 안을 확인 했을때 운전자가 안전벨트를 안하고 있을 확률은 어떻게 되는가? P(안전벨트를 안하고 있을 확률 | 사고가 일어났다)
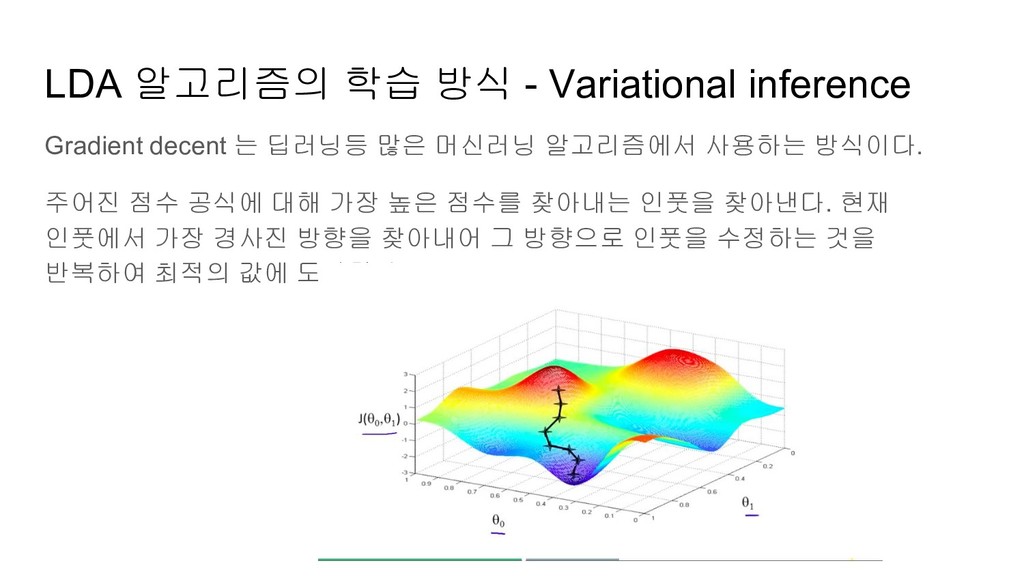
구성률 D에 대해 주어진 문서 W가 나올 확률 공식은 gradient를 구하는 것이 불가능하다. P(W|T, D, a, b) → gradient is intraceable 그렇기에 Variational Inference라는 알고리즘을 사용해 정확한 P(W|T, D, a, b)의 값이 아닌 P(W|T, D, a, b)의 lower bound가 되는 값을 구해 grandeint decent를 적용한다. 자세한 내용은 http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf를 참조
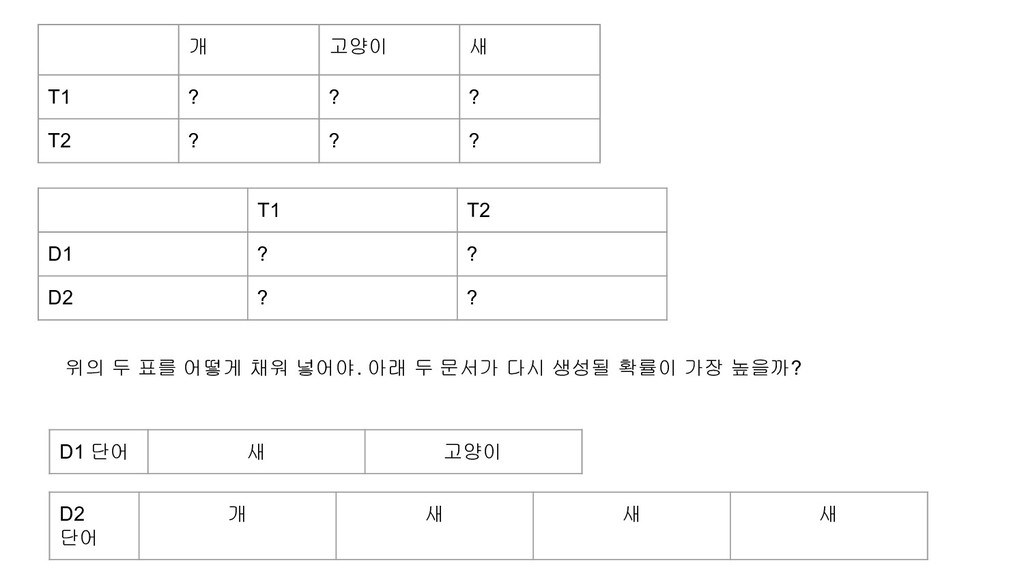
비율과 문서 비율 보다는 각 문서의 단어의 토픽 값을 알아내고자 하는 기법. D1 토픽 ? ? D1 단어 새 고양이 D2 토픽 ? ? ? ? D2 단어 개 새 새 새 위의 값을 채워 넣으면, 토픽의 단어 비율과 각 문서의 토픽 비율은 자연스럽게 최적의 값을 알아낼 수 있다. 각 단어가 각 토픽에 할당된 횟수를 카운팅후 그 비율을 구하면 토픽의 단어 분포도가 나온다. 각 문서에서 각 토픽이 할당된 횟수를 카운팅후 그 비율을 구하면 문서의 토픽 분포도가 나온다.
조합에 대한 확률을 구한후 가장 높은 확률을 갖는 토픽 할당을 선택하는 방법은 비현실 적이다. 가능한 모든 조합의 수는 단어 수에 따라 가하급수적으로 늘어난다. 그러나 단 한단어를 제외하고 모든 단어에 토픽을 할당한후, 나머지 한단어에 들어갈 토픽의 확률을 구하는 것은 손쉽다.
1 1 1 ? D2 단어 개 새 새 새 예. 아래와 같이 D2에 있는 단 한 단어 만 제외하고 다른 단어들의 토픽이 무엇인지 알고 있을 경우 D1의 토픽이, x1, x2이고, D2의 토픽이 y1, y2, y3, y4일 확률을 p(D1=(x1, x2), D2=(y1,y2,y3,y4)) 라고 할때 베이즈 추론에 의해 D2의 마지막 단어의 토픽이 x일 확률은 다음과 같다.
단어수) or b= 0.1 가 많이 쓰인다. ɑ= 50/( 토픽 개수) = 25 = 200 / (유니크한 단어수) ~= 67 로 할경우 p(2) = 0.15가 되며 p(1)은 0.17이 된다. 그러므로 마지막 단어인 새가 2일 확률 점수는 0.15 이며 1이될 확률 점수는 0.15 이다. D2의 토픽 미지정 단어인 새의 토픽이 1이 될 확률은 (0.17 / 0.31) * 100 ~= 58% 이고 2가 될 확률은 42%이다.
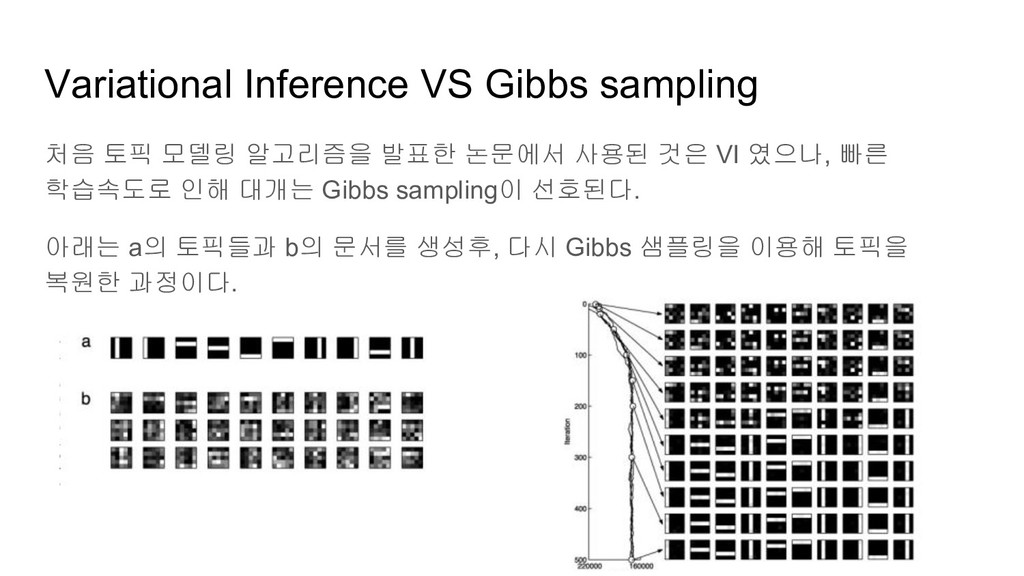
것을 문서내의 모든 단어에 반복하여 모든 단어들의 토픽을 재할당 한다. 그리고 이 사이클을 다시 많은 수 반복하는 것이 깁스 샘플링이다. 이 사이클을 많은 수 반복하면, 각 단어에 할당된 토픽은 가장 적절한 토픽들이 될것이고, 각 문서 내의 할당된 토픽 수의 벡터와, 토픽별 단어 수가 일정하게 수렴하게 되고, 이렇게 해서 구한 토픽의 단어 비율과 문서의 토픽 비율이 가장 적절한 비율에 가까워지게 된다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}