structures for semantic queries with nodes, edges, and properties to represent and store data” -> 그래프 데이터베이스는 크게 노드와 엣지(관계)로 이루어져 있습니다. 또한 노드와 엣지는 각각의 라벨 및 프로퍼티를 갖을 수 있습니다. Name: ‘Asher’ Age: ‘2x’ Company:’Buzzvil Lives:{‘Ilsan’} CO-Worker :KNOWS Name: ‘Zendya’ Age: ‘2x’ Company:’Buzzvil Hobbies:{‘tennis’} Name: ‘Jandy’ Age: ‘4x’ Company:’Kakao’ Hobbies:{‘coding’} since:2020 team:CCO since:2020 university:d ongguk Person Person Person Node(Vertex) Label Edge Property 참조 https://www.youtube.com/watch?v=c21D8zHmk-E
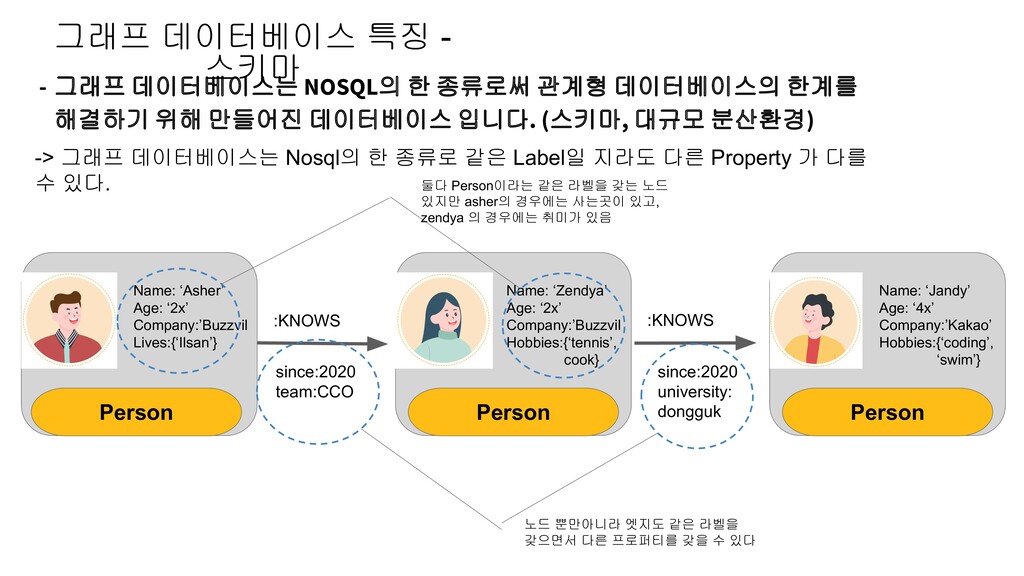
Age: ‘2x’ Company:’Buzzvil Hobbies:{‘tennis’, cook} Name: ‘Jandy’ Age: ‘4x’ Company:’Kakao’ Hobbies:{‘coding’, ‘swim’} since:2020 team:CCO since:2020 university: dongguk Person Person Person - 그래프 데이터베이스는 NOSQL의 한 종류로써 관계형 데이터베이스의 한계를 해결하기 위해 만들어진 데이터베이스 입니다. (스키마, 대규모 분산환경) -> 그래프 데이터베이스는 Nosql의 한 종류로 같은 Label일 지라도 다른 Property 가 다를 수 있다. 둘다 Person이라는 같은 라벨을 갖는 노드 있지만 asher의 경우에는 사는곳이 있고, zendya 의 경우에는 취미가 있음 노드 뿐만아니라 엣지도 같은 라벨을 갖으면서 다른 프로퍼티를 갖을 수 있다 그래프 데이터베이스 특징 - 스키마
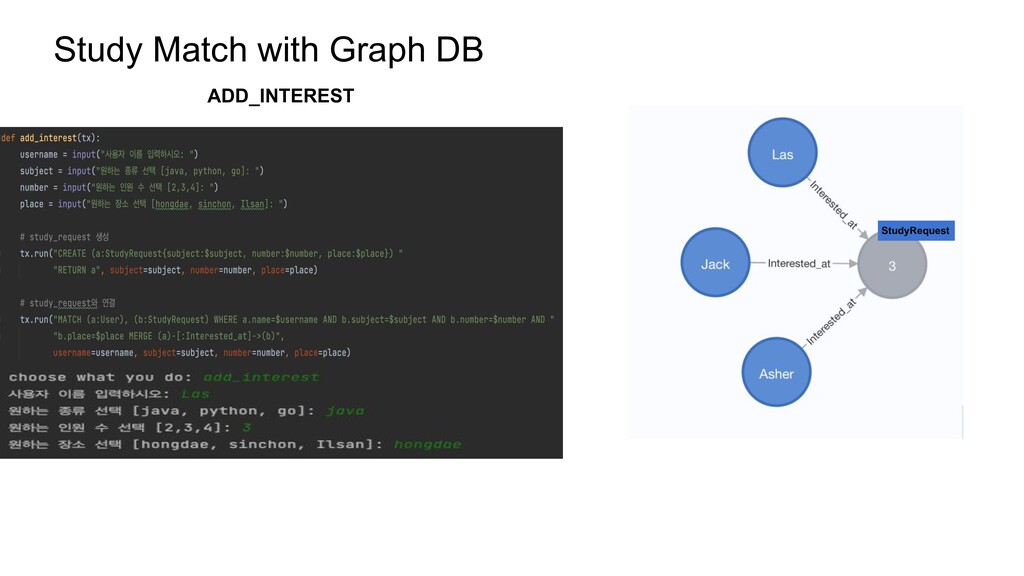
Asher 2 Jandy person_id Relate_to 1 2 2 3 Relationship Person Q : Asher가 알고있는 사람의 수? // Asher와 KNOWS 로 연결된 노드의 수 MATCH (n:Person{name:'Asher'})-[:KNOWS]->(m) RETURN COUNT(m) // Asher와 KNOWS 로 연결된 노드의 수 SELECT COUNT(*) FROM Relationship R JOIN Person P on R.relate_to = P.ID where P.Name = ‘Asher’ ; Foreign Key
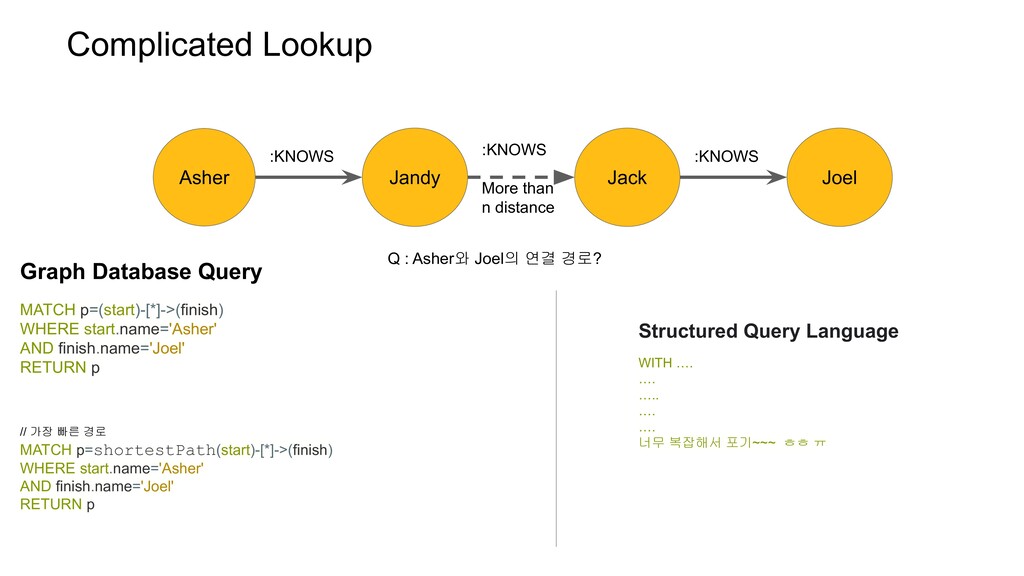
n distance :KNOWS Q : Asher와 Joel의 연결 경로? Graph Database Query MATCH p=(start)-[*]->(finish) WHERE start.name='Asher' AND finish.name='Joel' RETURN p Structured Query Language WITH …. …. ….. …. …. 너무 복잡해서 포기~~~ ㅎㅎ ㅠ // 가장 빠른 경로 MATCH p=shortestPath(start)-[*]->(finish) WHERE start.name='Asher' AND finish.name='Joel' RETURN p
ID Name 1 Asher 2 Jandy Person_id Relate_to 1 2 2 3 Relationship Person Q : 언제부터 알고지냈는지 데이터를 추가한다면? // Asher의 KNOWS 에 since 파라미터 추가 MATCH (n:Person{name:'Asher'})-[r:KNOWS]->(m:Person{ name:'Jandy'}) SET r += {since:2020} return r // Relationship table 에 since column 추가 ALTER TABLE ‘Relationship’ ADD COLUMN ‘since’ INT(10) DEFAULT NULL { "identity": 45, "start": 51, "end": 52, "type": "KNOWS", "properties": { "since": 2020 } } NEW !! Since 2020 NULL Foreign Key since:2020
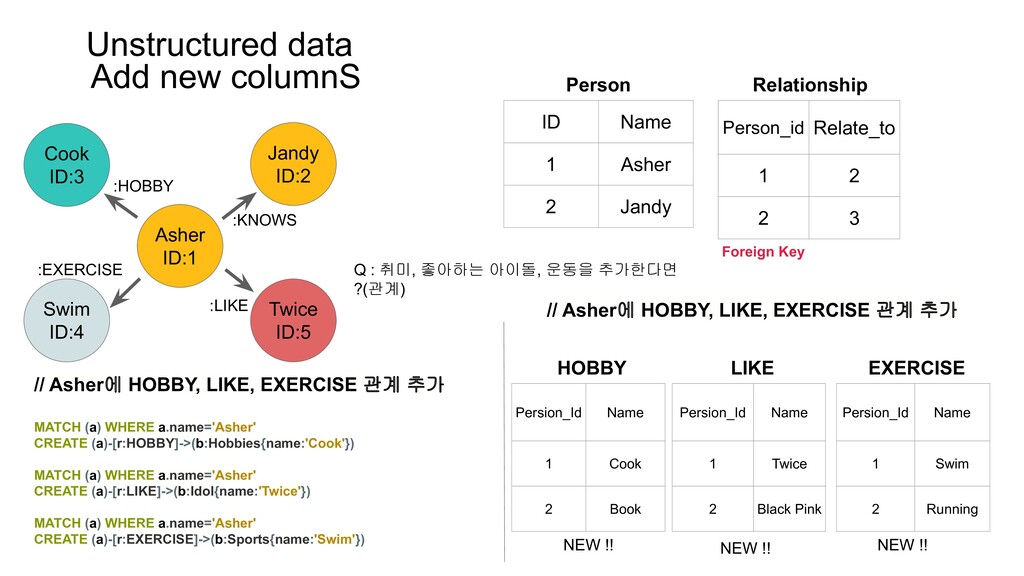
Asher 2 Jandy Person_id Relate_to 1 2 2 3 Relationship Person Q : 취미, 좋아하는 아이돌, 운동을 추가한다면 ?(관계) // Asher에 HOBBY, LIKE, EXERCISE 관계 추가 MATCH (a) WHERE a.name='Asher' CREATE (a)-[r:HOBBY]->(b:Hobbies{name:'Cook'}) MATCH (a) WHERE a.name='Asher' CREATE (a)-[r:LIKE]->(b:Idol{name:'Twice'}) MATCH (a) WHERE a.name='Asher' CREATE (a)-[r:EXERCISE]->(b:Sports{name:'Swim'}) // Asher에 HOBBY, LIKE, EXERCISE 관계 추가 NEW !! Asher ID:1 Cook ID:3 Swim ID:4 Twice ID:5 :KNOWS :LIKE :EXERCISE :HOBBY Persion_Id Name 1 Cook 2 Book HOBBY Persion_Id Name 1 Twice 2 Black Pink LIKE Persion_Id Name 1 Swim 2 Running EXERCISE NEW !! NEW !! Foreign Key
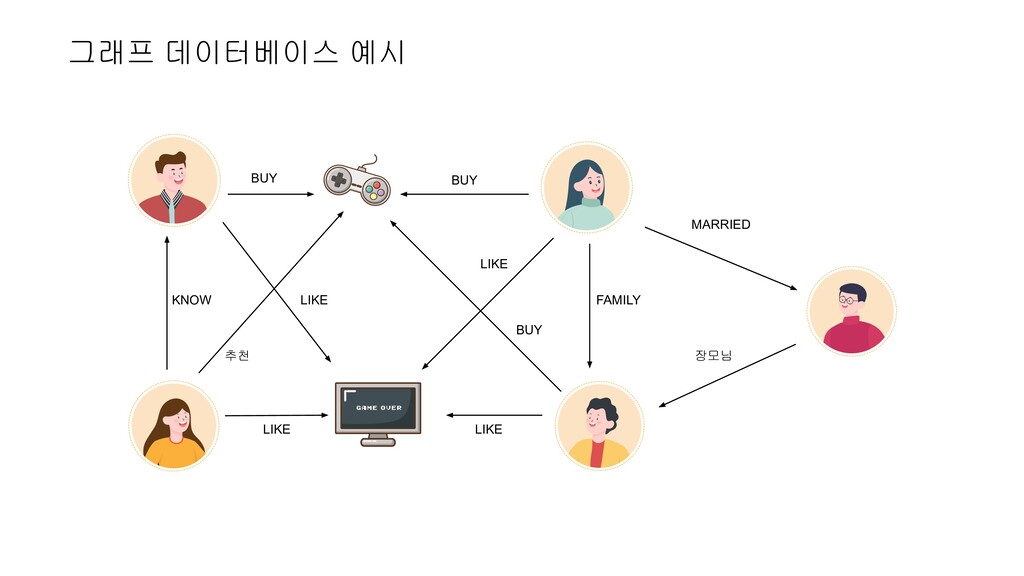
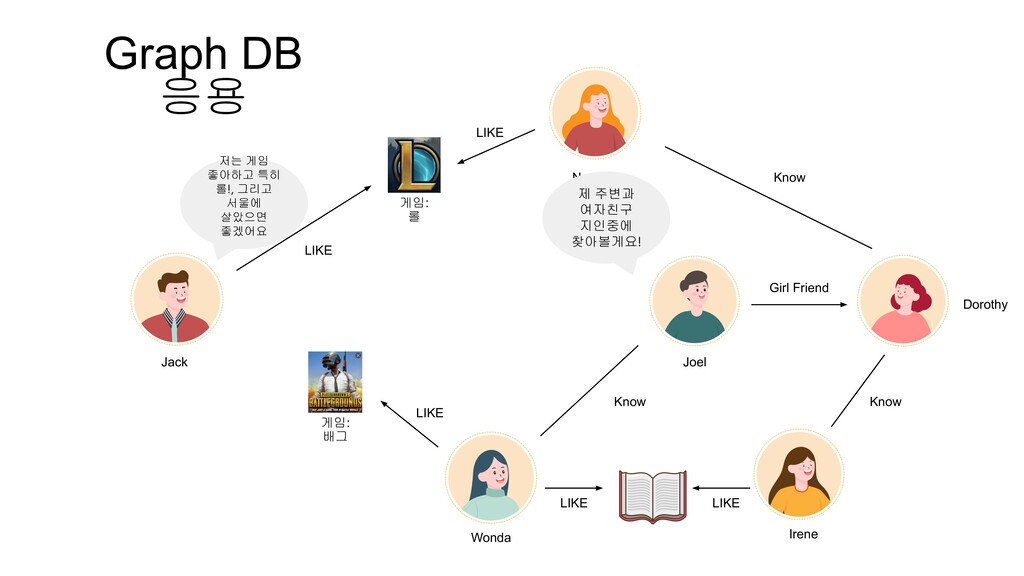
Irene Girl Friend Know Know Know LIKE LIKE 게임: 배그 LIKE LIKE LIKE Joel 요즘 외로운데 소개팅좀 시켜줘요~~! 물론이죠 Jack, 이상형이 어떻게 되나요? 저는 게임 좋아하고 특히 롤!, 그리고 서울에 살았으면 좋겠어요 제 주변과 여자친구 지인중에 찾아볼게요!
= friends_hobby return COUNT(joel_friends) MATCH (jack:Person{name:'Jack'})-[:LIKE]->(jack_hobby:Hobby) MATCH (joel:Person{name:'Joel'})-[:Girl_Friend]->(joel_girl_friend)-[:KNOW*1]->(joel_girl_friend_friends)-[:LIKE]->(friends_hobby) WHERE jack.live = joel_girl_friend_friends.live AND jack_hobby = friends_hobby return COUNT(joel_girl_friend_friends), joel_girl_friend_friends.name
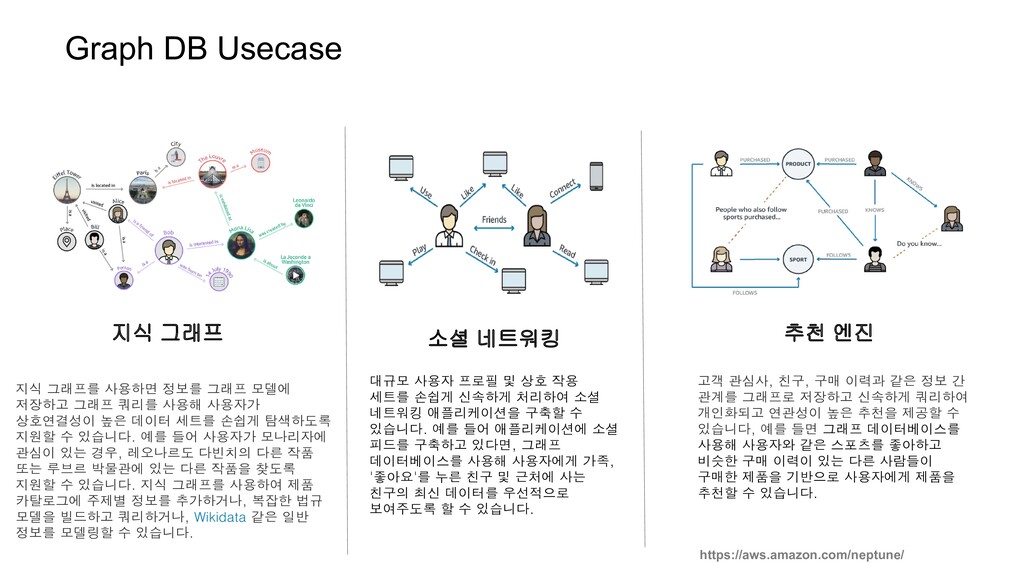
고객 관심사, 친구, 구매 이력과 같은 정보 간 관계를 그래프로 저장하고 신속하게 쿼리하여 개인화되고 연관성이 높은 추천을 제공할 수 있습니다, 예를 들면 그래프 데이터베이스를 사용해 사용자와 같은 스포츠를 좋아하고 비슷한 구매 이력이 있는 다른 사람들이 구매한 제품을 기반으로 사용자에게 제품을 추천할 수 있습니다. 대규모 사용자 프로필 및 상호 작용 세트를 손쉽게 신속하게 처리하여 소셜 네트워킹 애플리케이션을 구축할 수 있습니다. 예를 들어 애플리케이션에 소셜 피드를 구축하고 있다면, 그래프 데이터베이스를 사용해 사용자에게 가족, '좋아요'를 누른 친구 및 근처에 사는 친구의 최신 데이터를 우선적으로 보여주도록 할 수 있습니다. 지식 그래프를 사용하면 정보를 그래프 모델에 저장하고 그래프 쿼리를 사용해 사용자가 상호연결성이 높은 데이터 세트를 손쉽게 탐색하도록 지원할 수 있습니다. 예를 들어 사용자가 모나리자에 관심이 있는 경우, 레오나르도 다빈치의 다른 작품 또는 루브르 박물관에 있는 다른 작품을 찾도록 지원할 수 있습니다. 지식 그래프를 사용하여 제품 카탈로그에 주제별 정보를 추가하거나, 복잡한 법규 모델을 빌드하고 쿼리하거나, Wikidata 같은 일반 정보를 모델링할 수 있습니다.
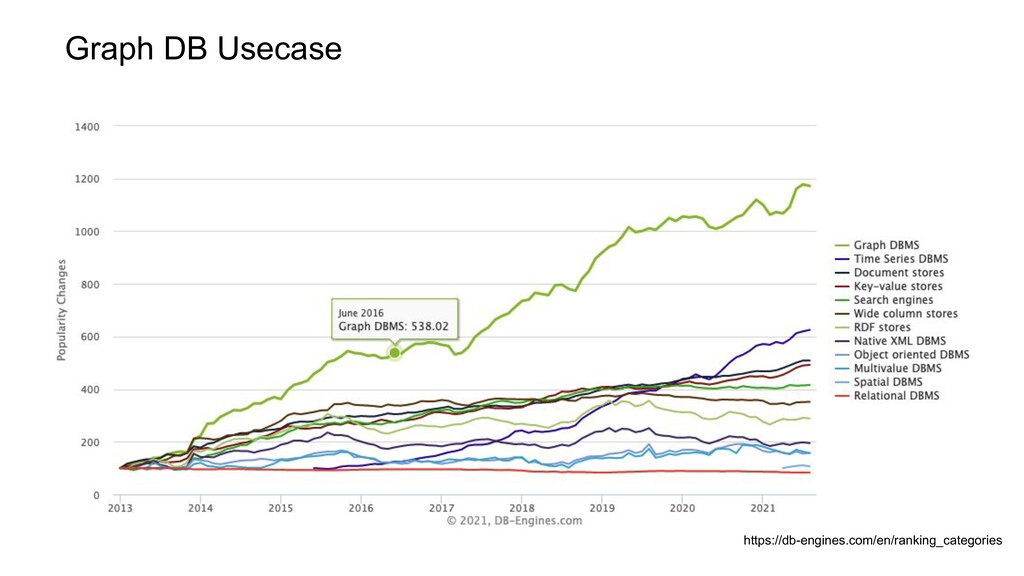
앞에서 보여드린 것처럼 노드간의 거리가 멀리 떨어져있는 복잡한 조회가 아닌경우에는 큰 차이가없습니다. - GraphDB는 로컬 그래프를 처리하는데 있어서는 뛰어나지만, 노드 클러스터를 찾고, 노드 사이의 알려지지 않은 관계 패턴을 발견하고 그래프 구성요소의 중심 및 구역 사이를 정의하는 작업, 그래프 전체를 보는 글로벌 그래프 작업에는 성능적으로 많은 자원과 시간을 소모합니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Graph Query Language (Cypher) Node Edge ex) (p:Person{name:’Asher’,age:27})-[r:WORK_AT{since:2021}]->(c:Company{name:’Buzzvil’}) -> 나이:27,](https://files.speakerdeck.com/presentations/0e3e1e9e4f7c492a8e8eb29acff89d3b/slide_9.jpg){kind=link}
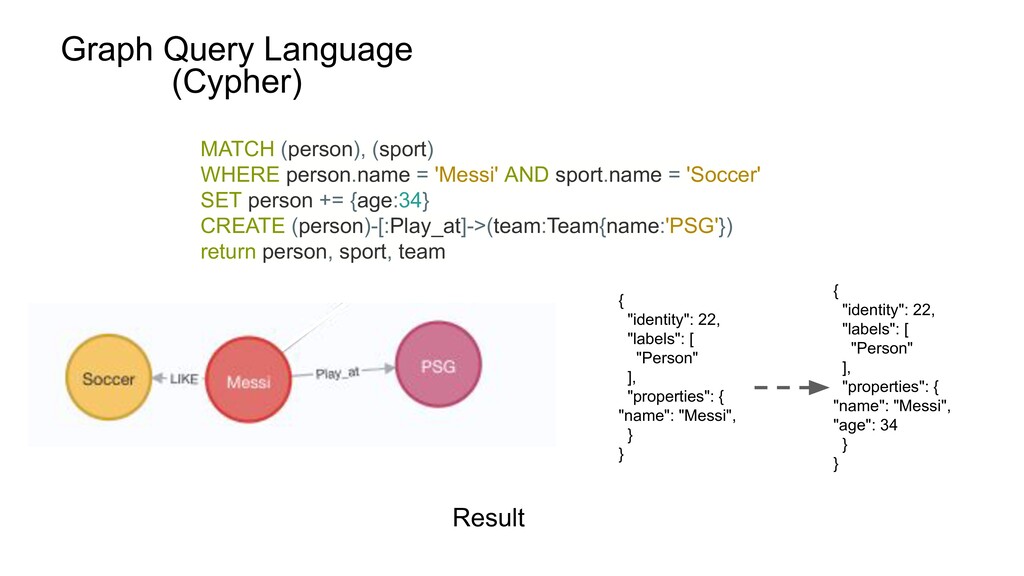
![CREATE (n:Person{name:'Messi'})-[:LIKE]-> (m:Sports{name:'Soccer'}) return n, m Result { "identity": 22,](https://files.speakerdeck.com/presentations/0e3e1e9e4f7c492a8e8eb29acff89d3b/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MATCH (jack:Person{name:'Jack'})-[:LIKE]->(jack_hobby:Hobby) MATCH (joel:Person{name:'Joel'})-[:KNOW*1]->(joel_friends)-[:LIKE]->(friends_hobby) WHERE jack.live = joel_friends.live AND jack_hobby](https://files.speakerdeck.com/presentations/0e3e1e9e4f7c492a8e8eb29acff89d3b/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}