Slides from CloudNative 2018 London.
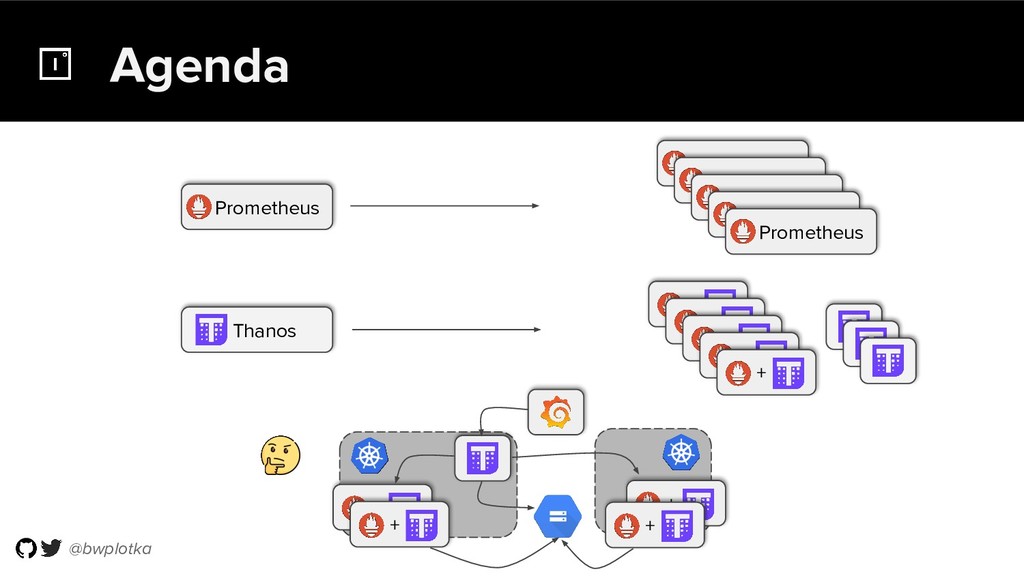
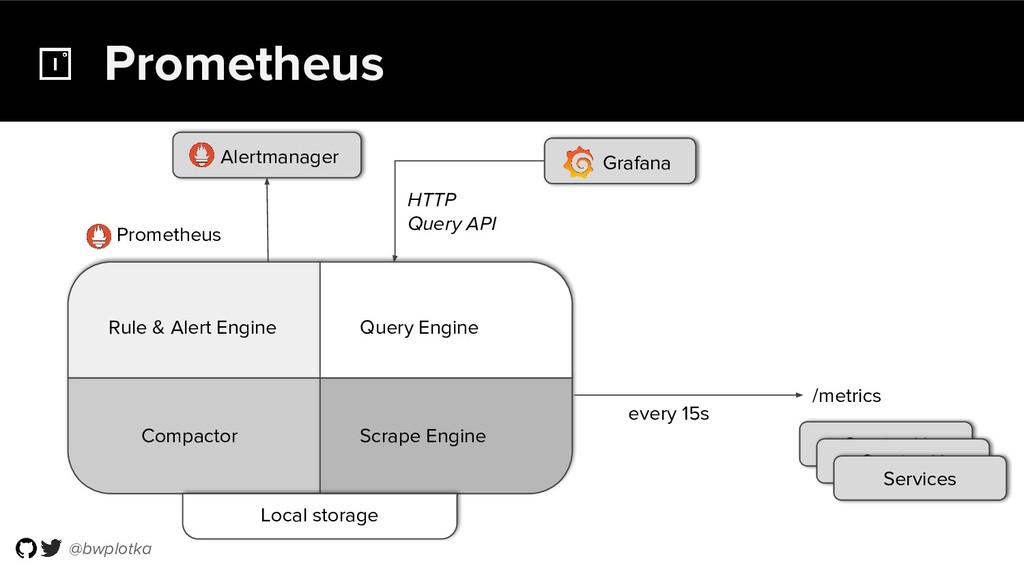
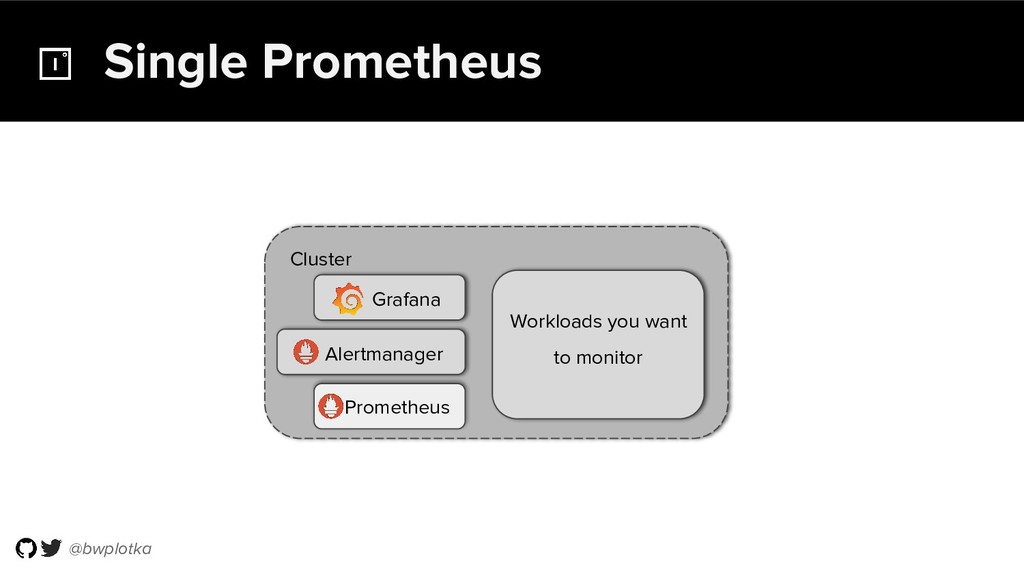
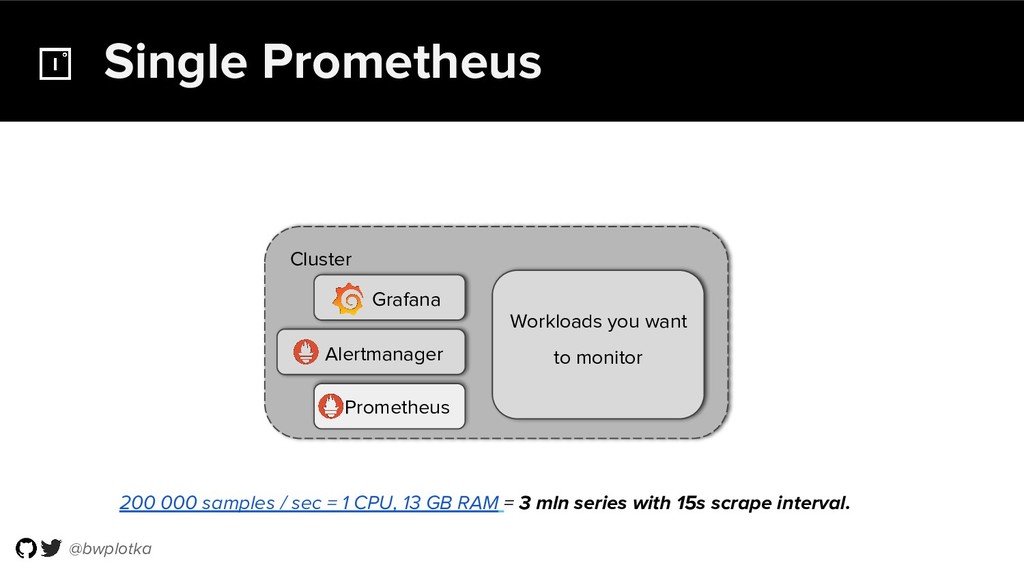
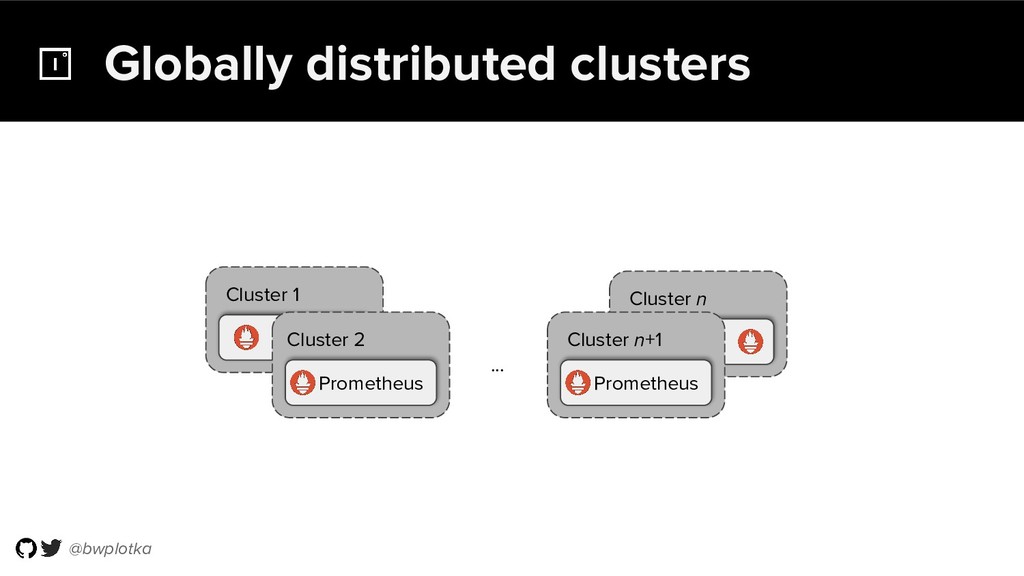
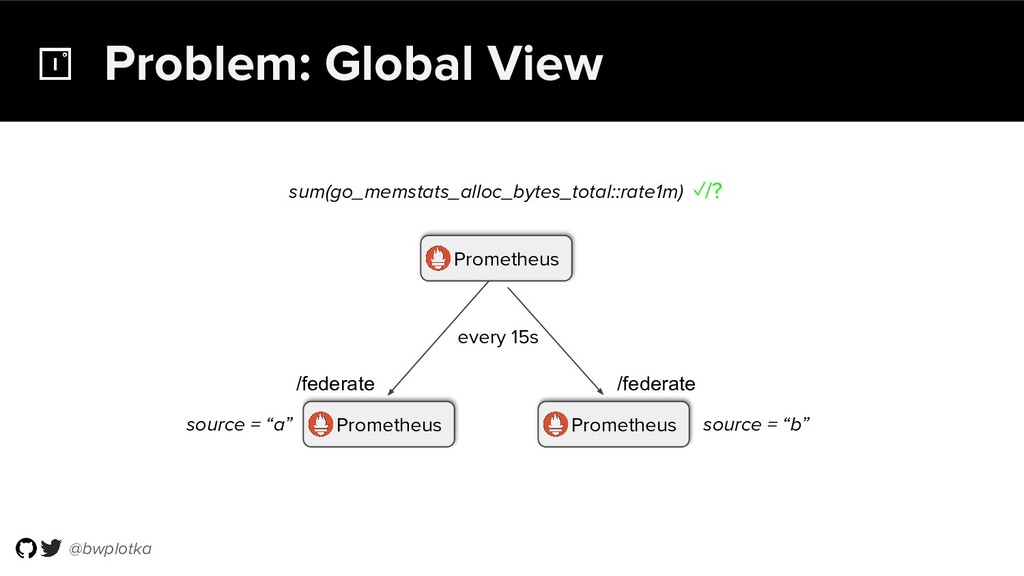
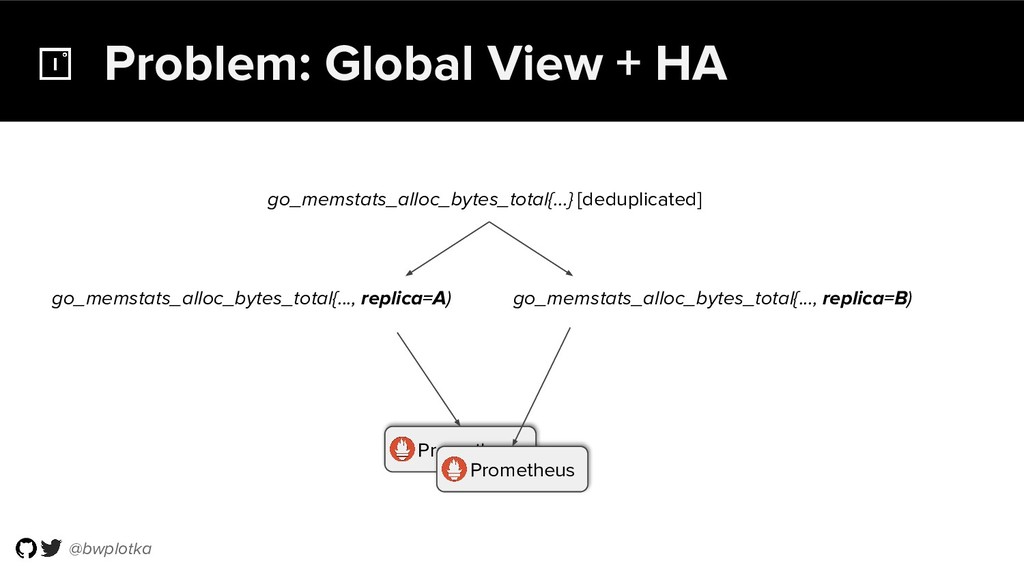
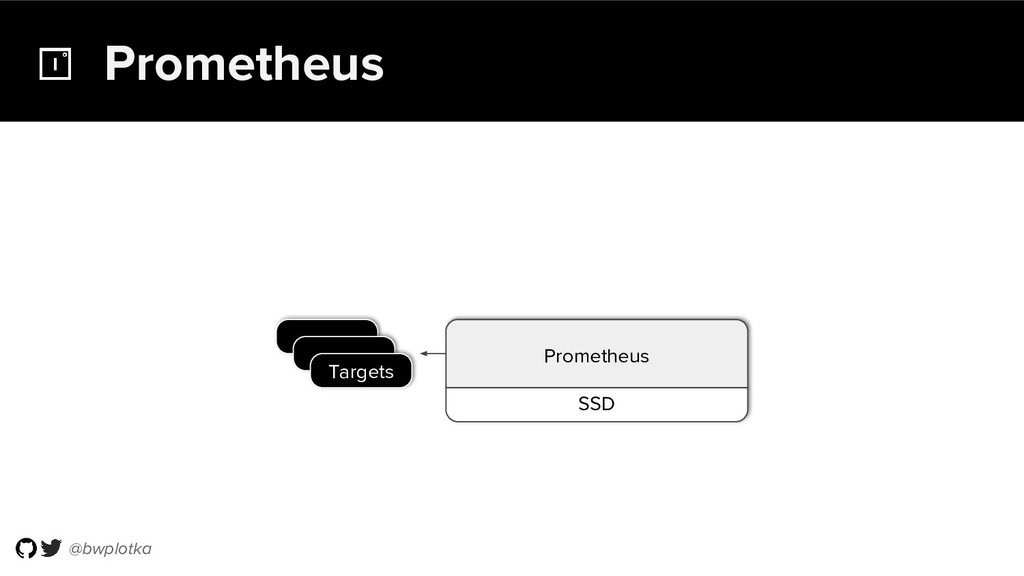
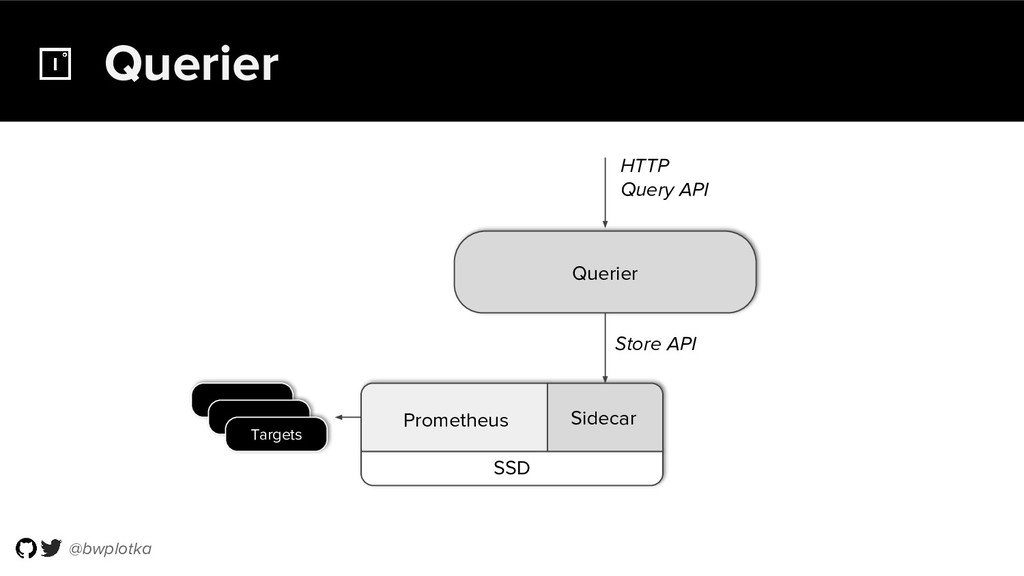
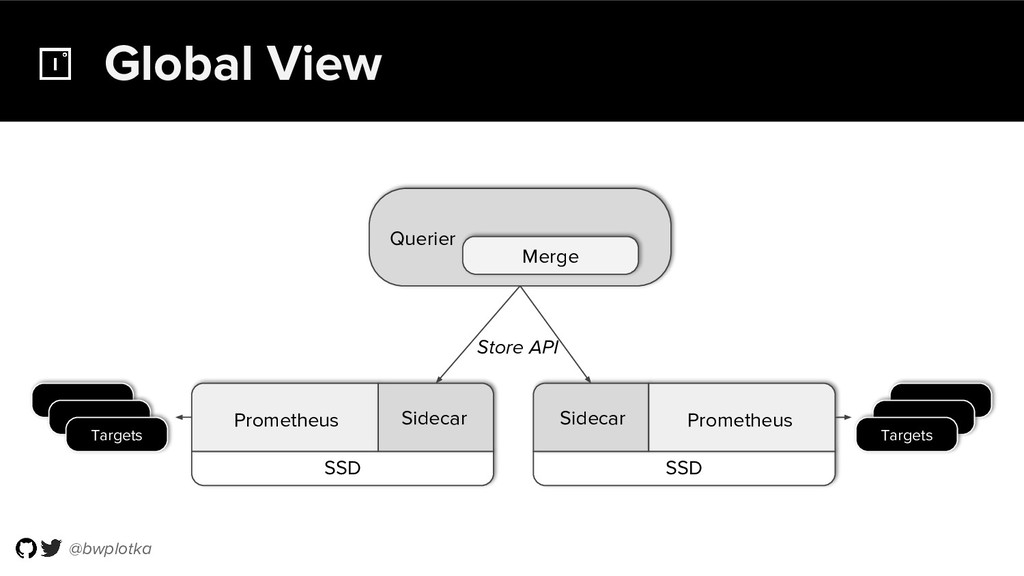
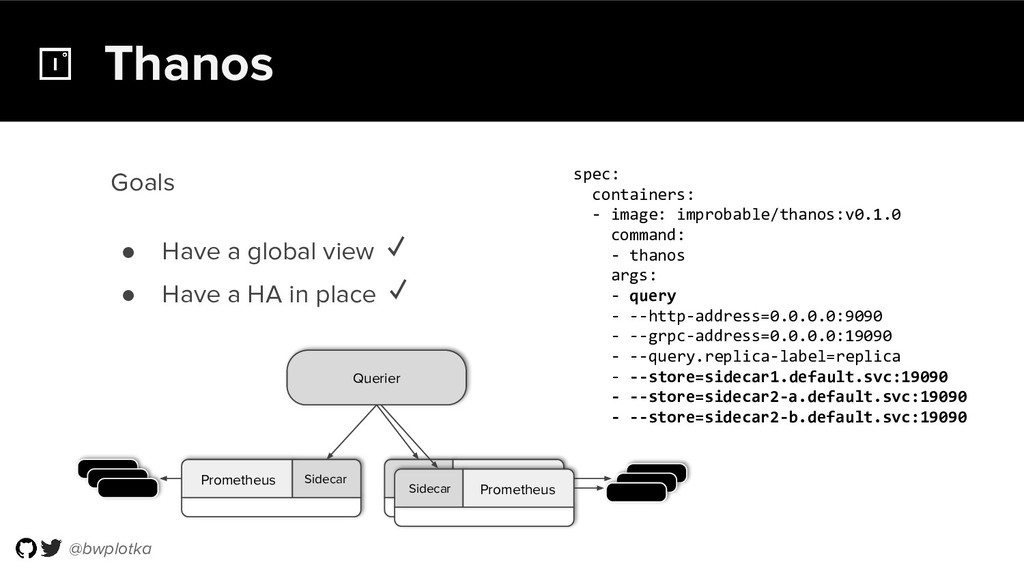
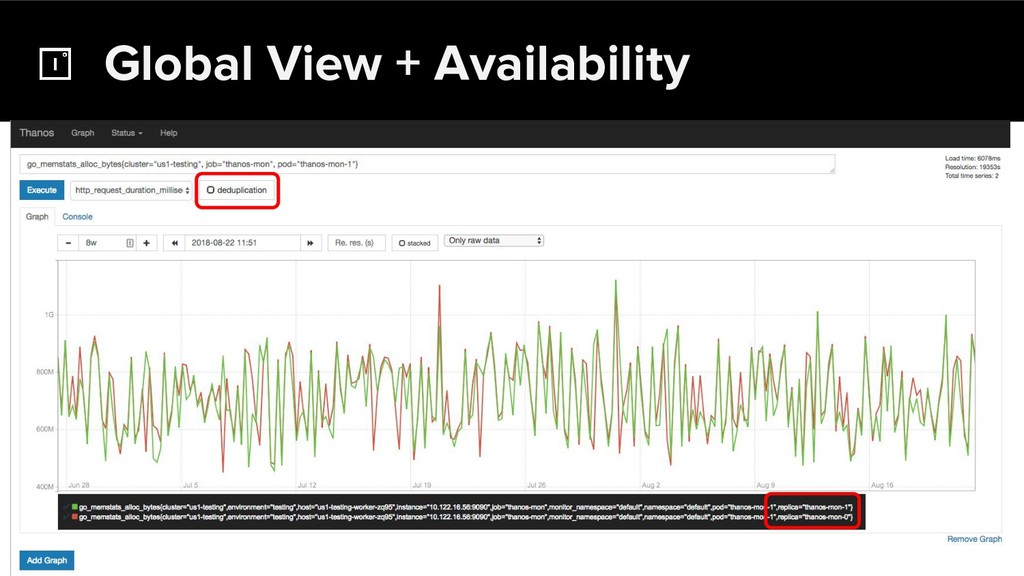
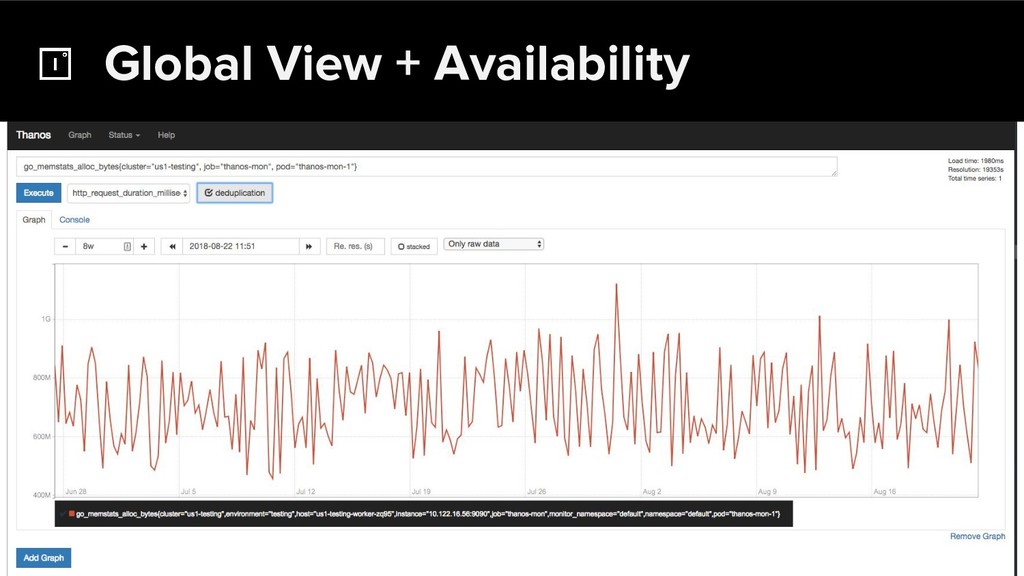
The CNCF's Prometheus Monitoring system has been thriving for several years. Along with its powerful data model, operational simplicity and reliability have been a key factor in its success. However, some questions were still largely unaddressed to this day. How can you store historical data at the order of petabytes in a reliable and cost-efficient way? Can you do so without sacrificing responsive query times? And what about a global view of all your metrics and transparent handling of HA setups? Thanos takes Prometheus' strong foundations and extends it into a clustered, yet coordination free, globally scalable metric system. It retains Prometheus’s simple operational model and even simplifies deployments further. Under the hood, Thanos uses highly cost-efficient object storage that’s available in virtually all environments today. By building directly on top of the storage format introduced with Prometheus 2.0, Thanos achieves near real-time responsiveness even for cold queries against historical data. All while having virtually no cost overhead beyond that of the underlying object storage. During this talk, Bartek will explore the theoretical concepts behind Thanos and demonstrate how it seamlessly integrates into existing Prometheus setups.
{kind=link}
![Bartek Płotka Software Engineer [email protected] @bwplotka](https://files.speakerdeck.com/presentations/3311f0f1d5b04480bc97b4f0f2efb0ed/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@bwplotka Problem: Global View Prometheus Prometheus sum(rate(go_memstats_alloc_bytes_total[1m])) ? source =](https://files.speakerdeck.com/presentations/3311f0f1d5b04480bc97b4f0f2efb0ed/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
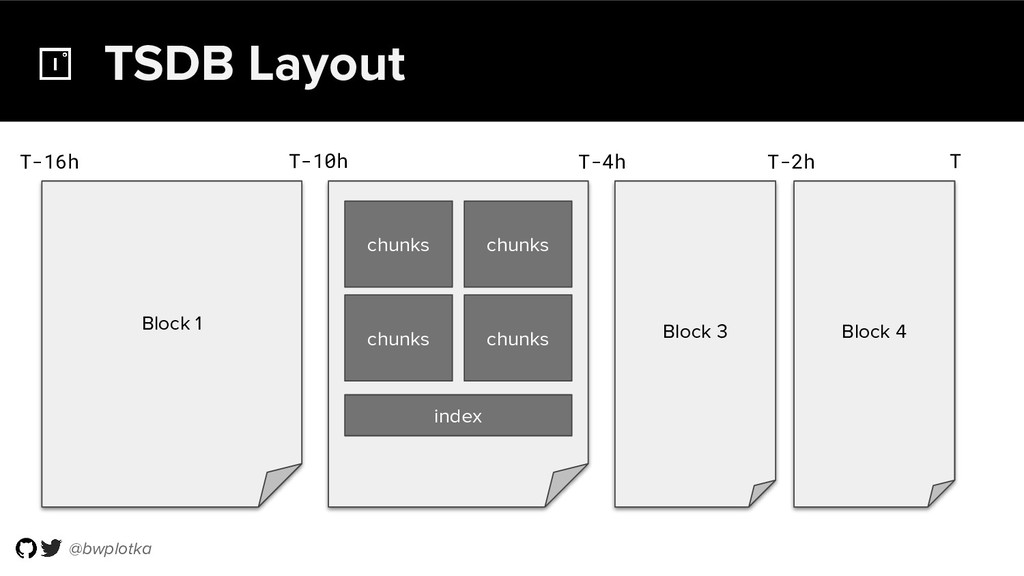{kind=link}
{kind=link}
{kind=link}
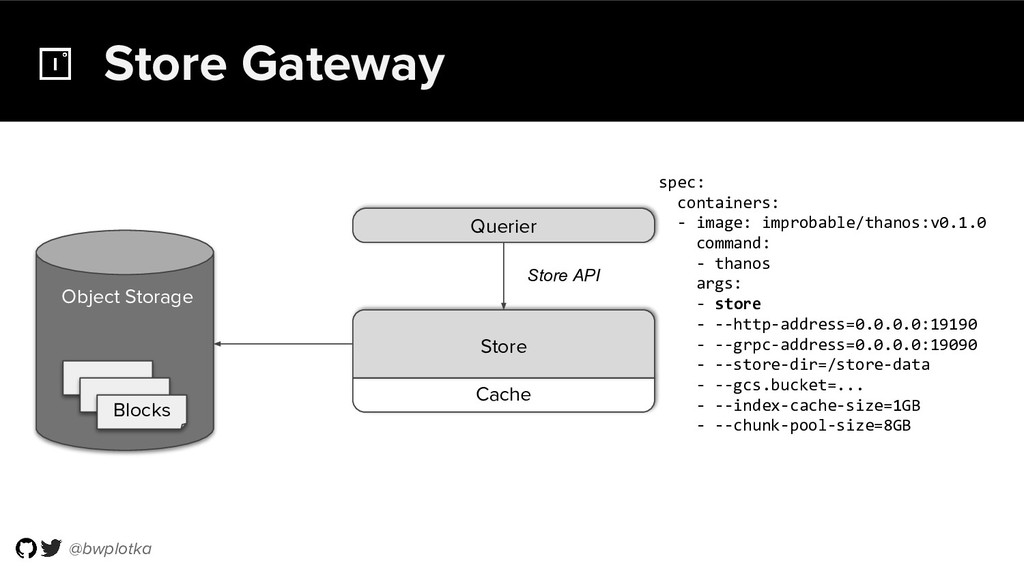{kind=link}
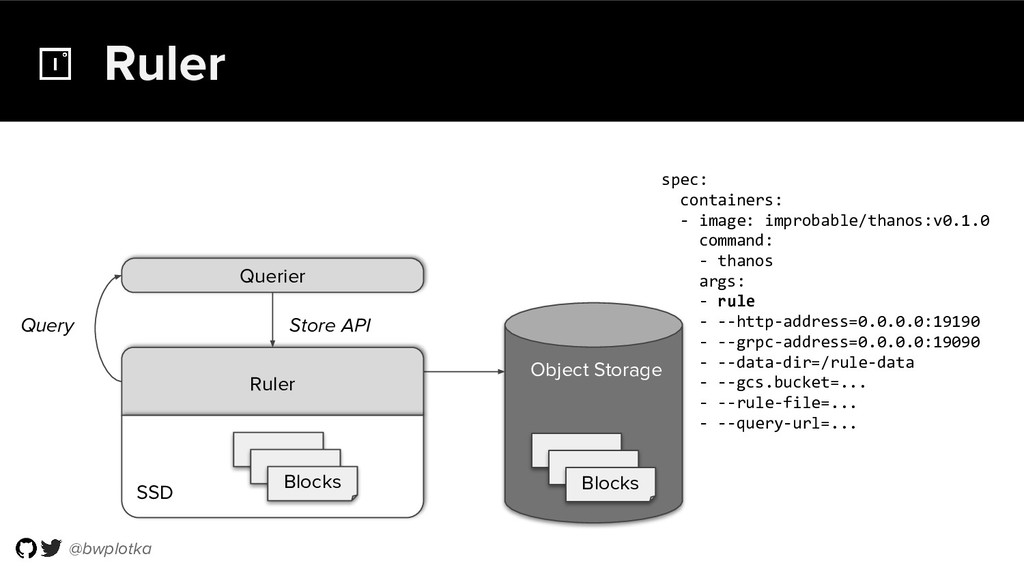{kind=link}
{kind=link}
{kind=link}
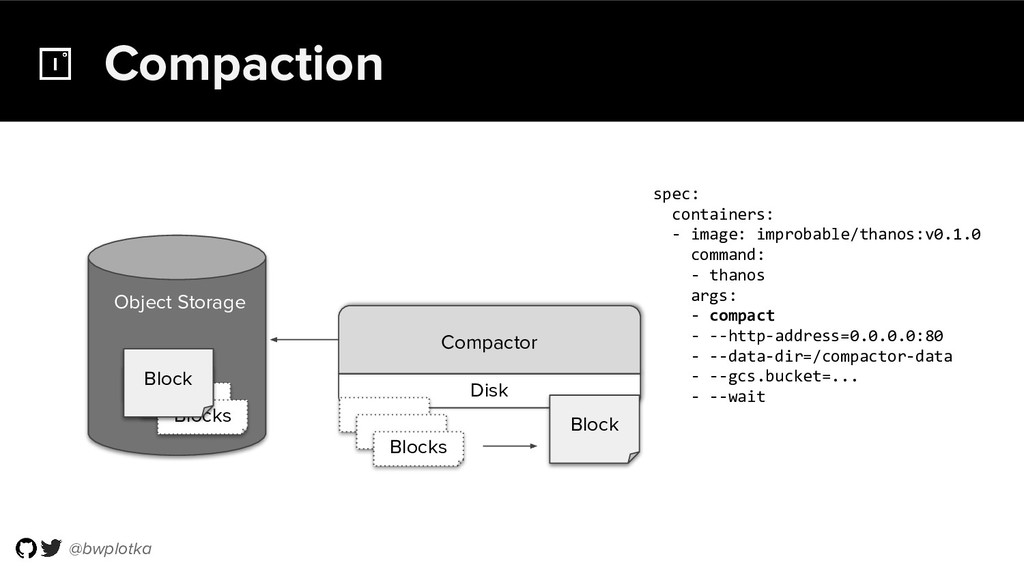{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
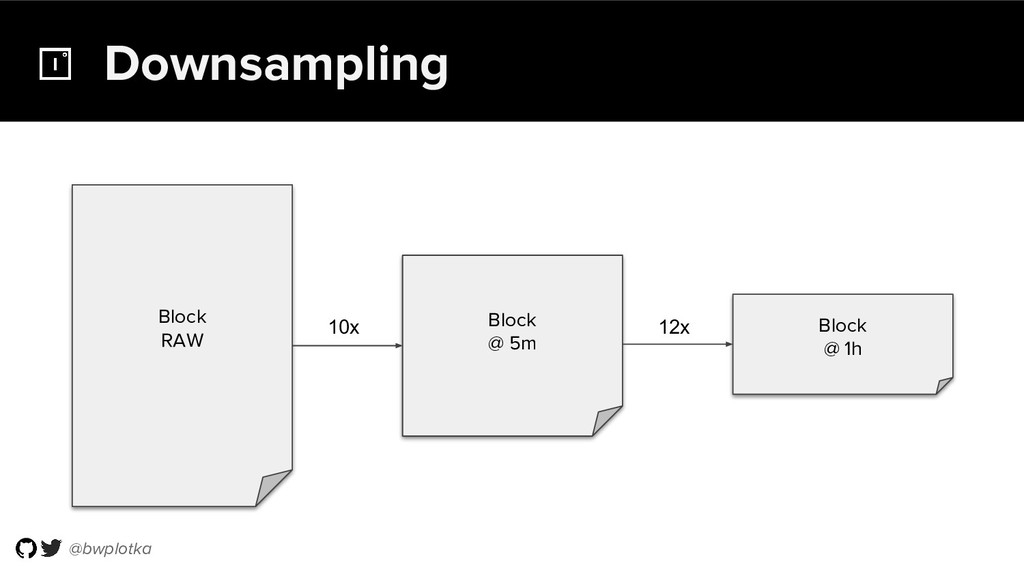{kind=link}
{kind=link}
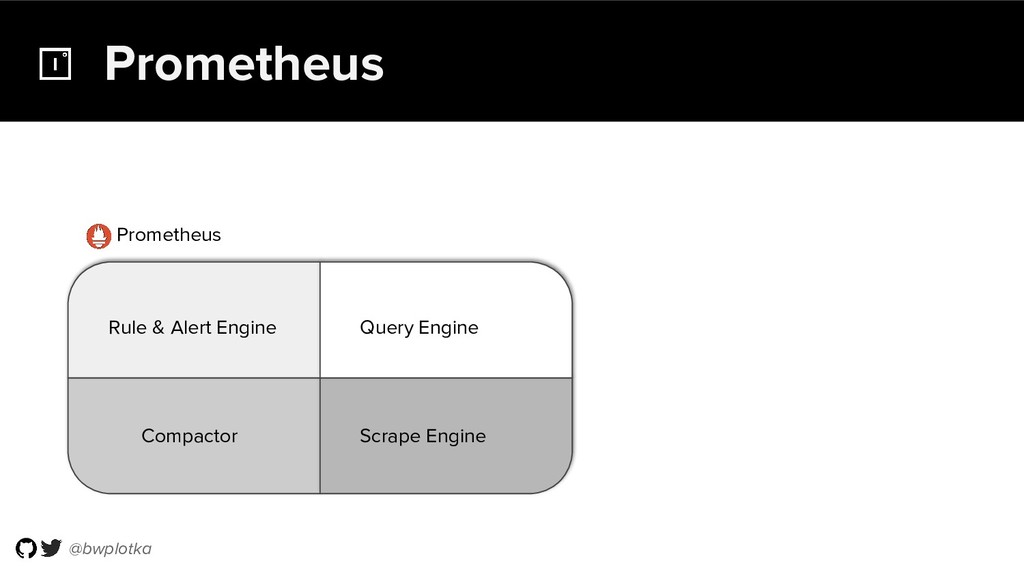{kind=link}
{kind=link}
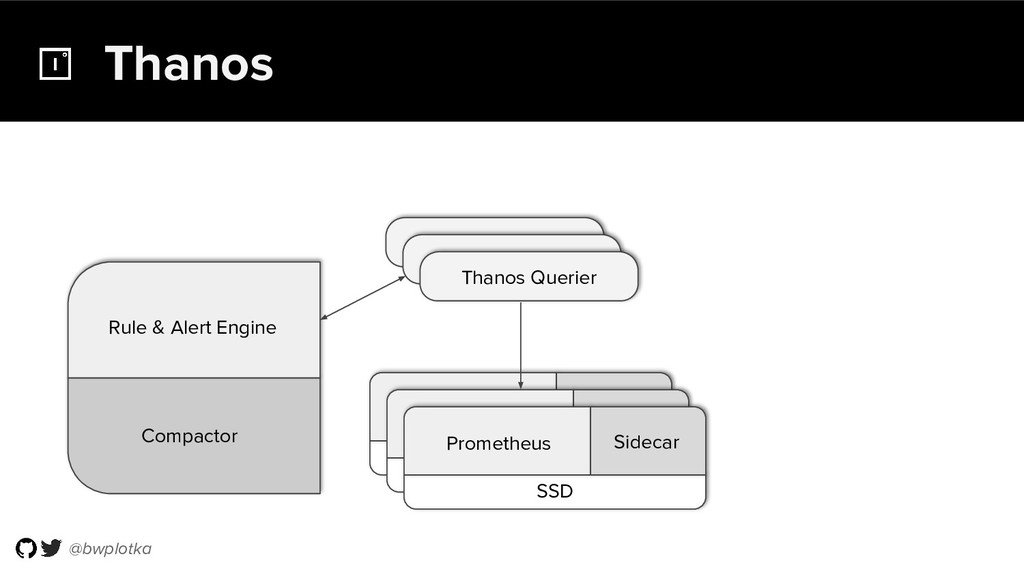{kind=link}
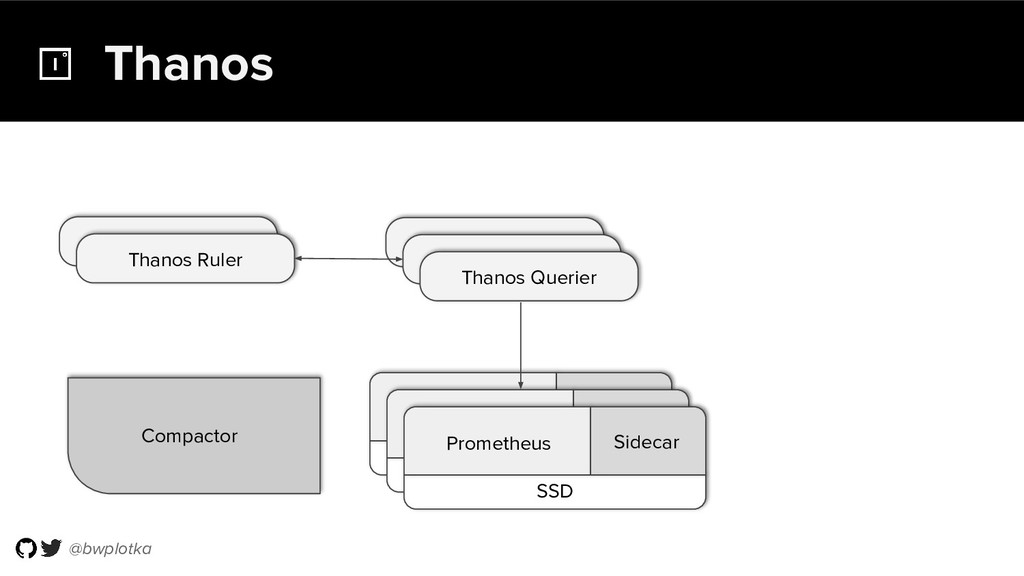{kind=link}
{kind=link}
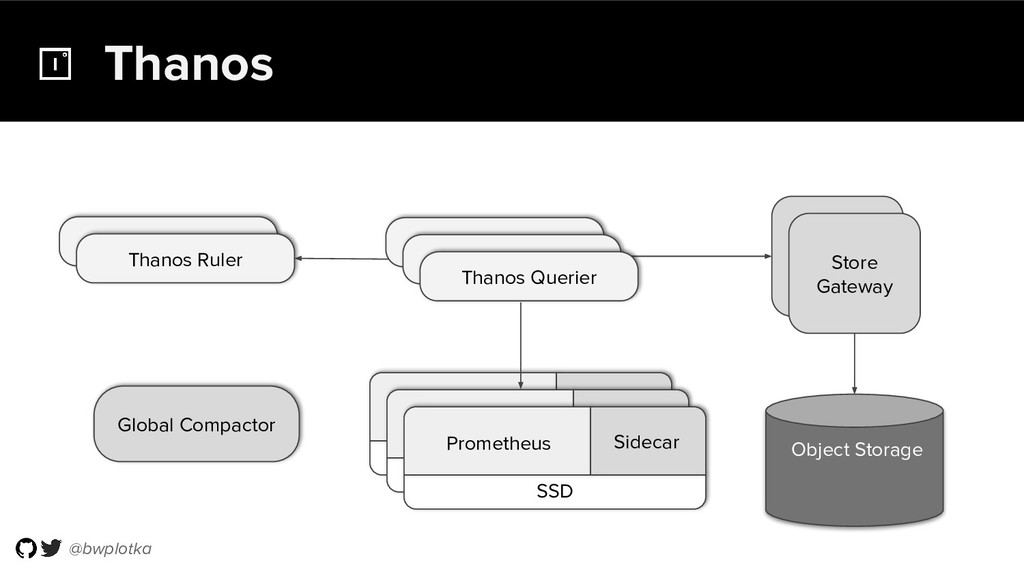{kind=link}
{kind=link}
{kind=link}
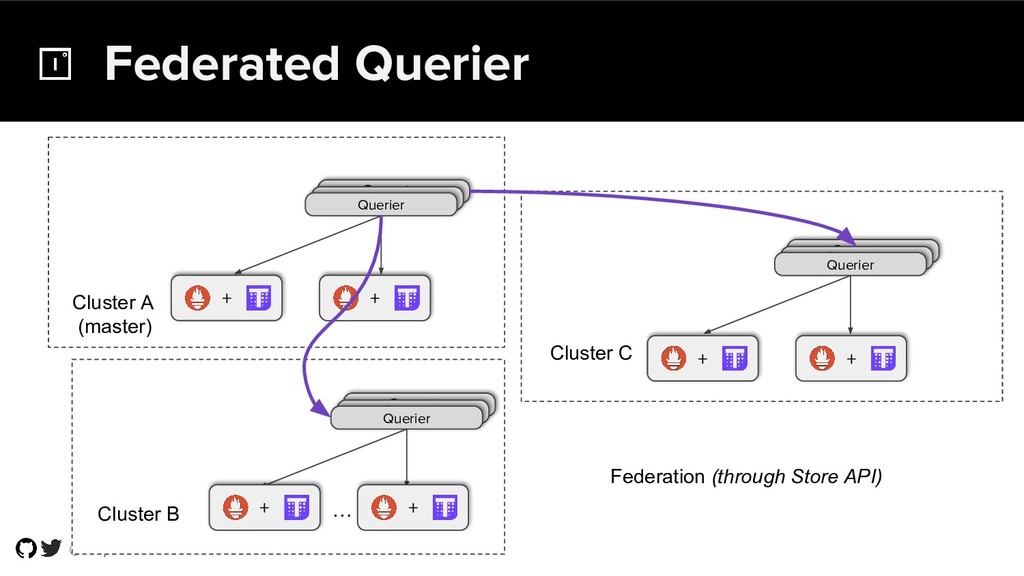{kind=link}
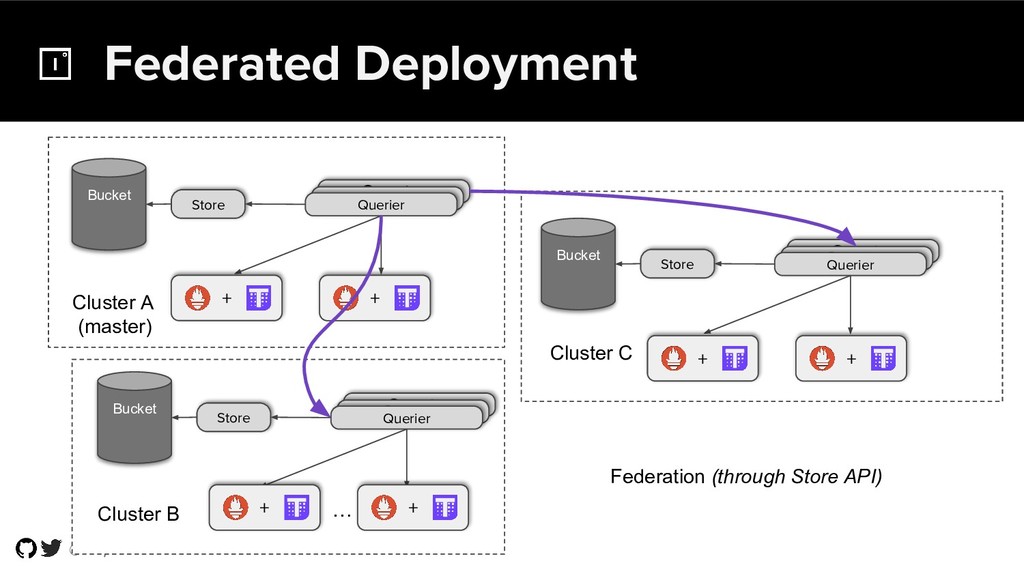{kind=link}
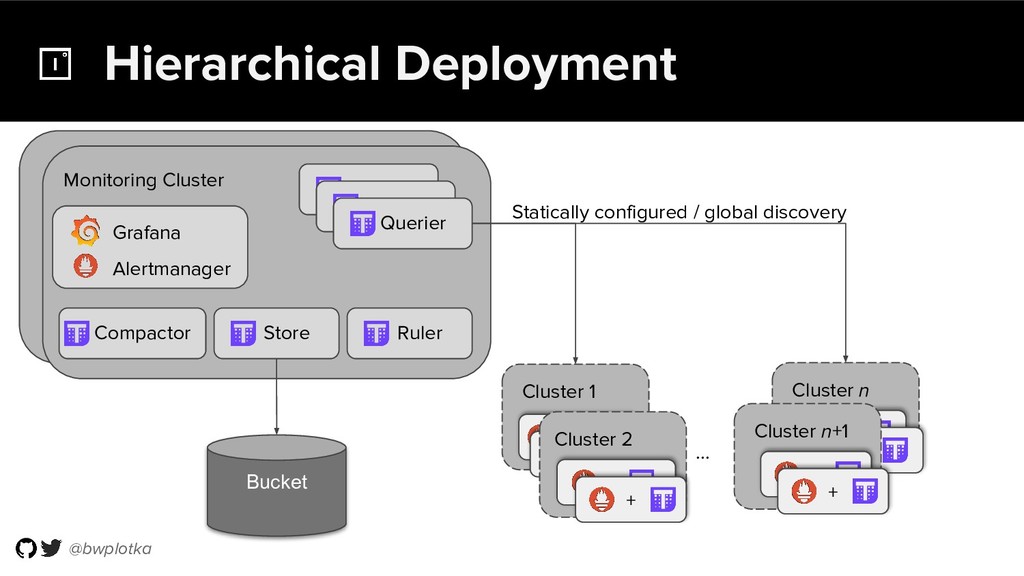{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}