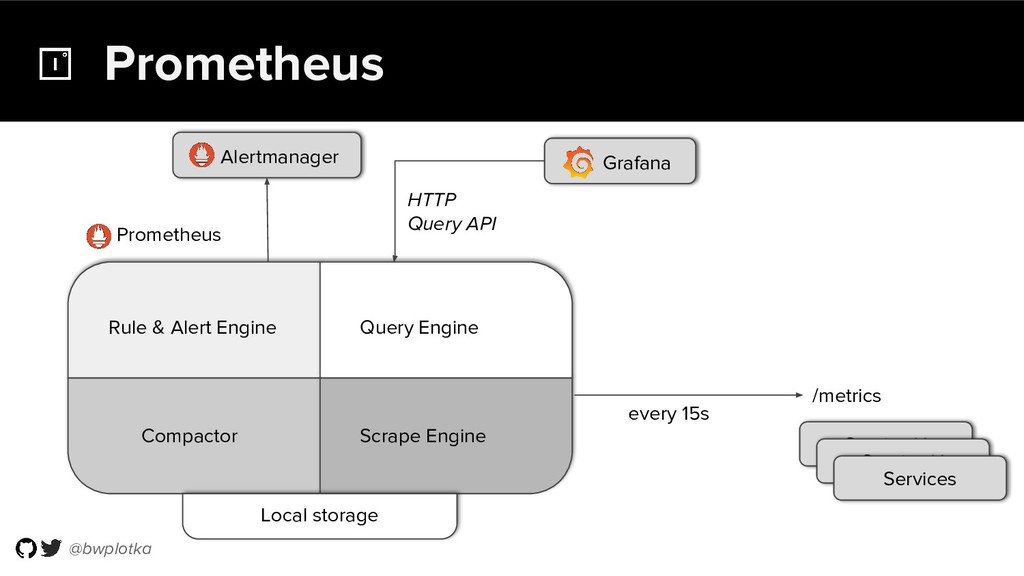
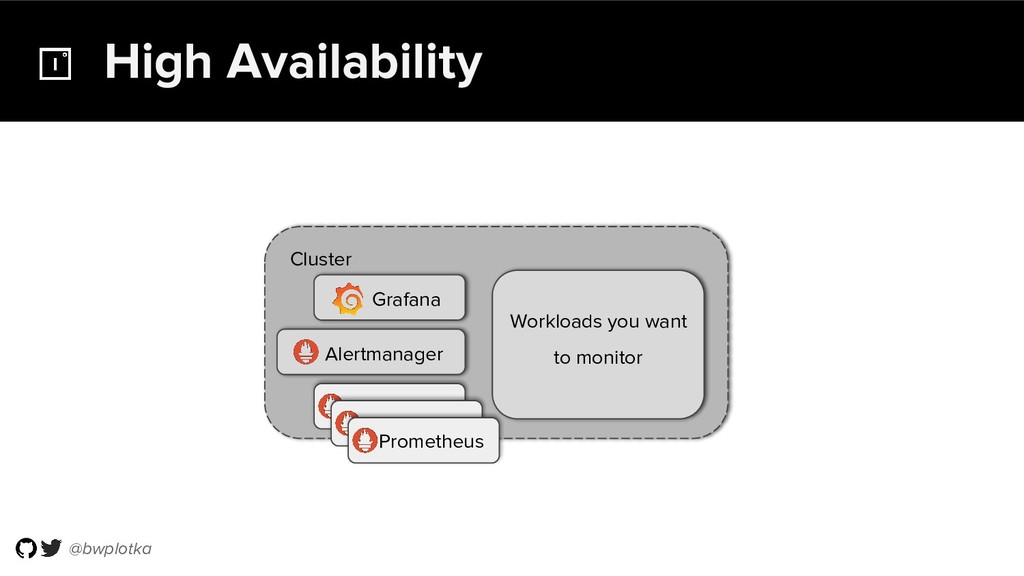
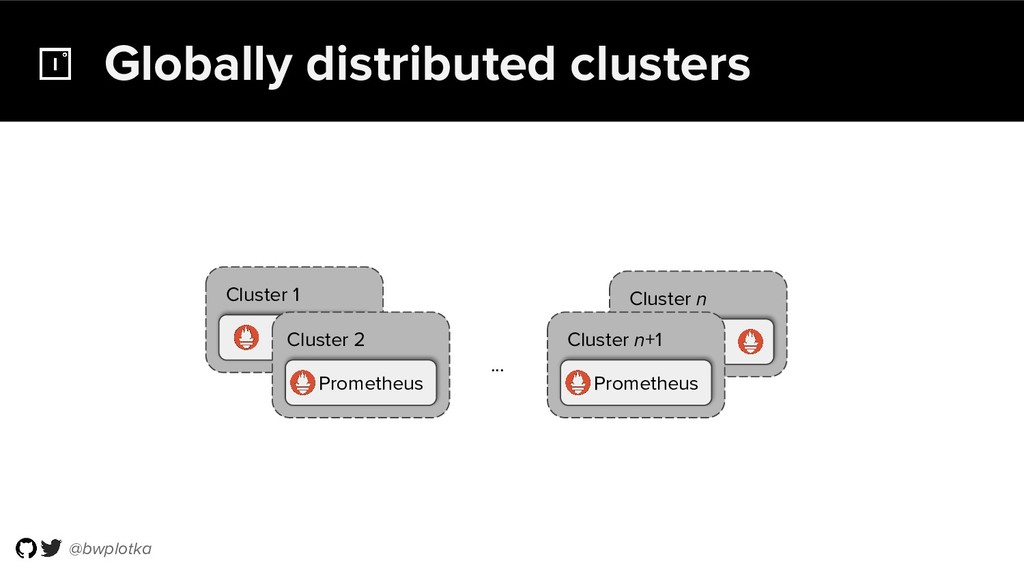
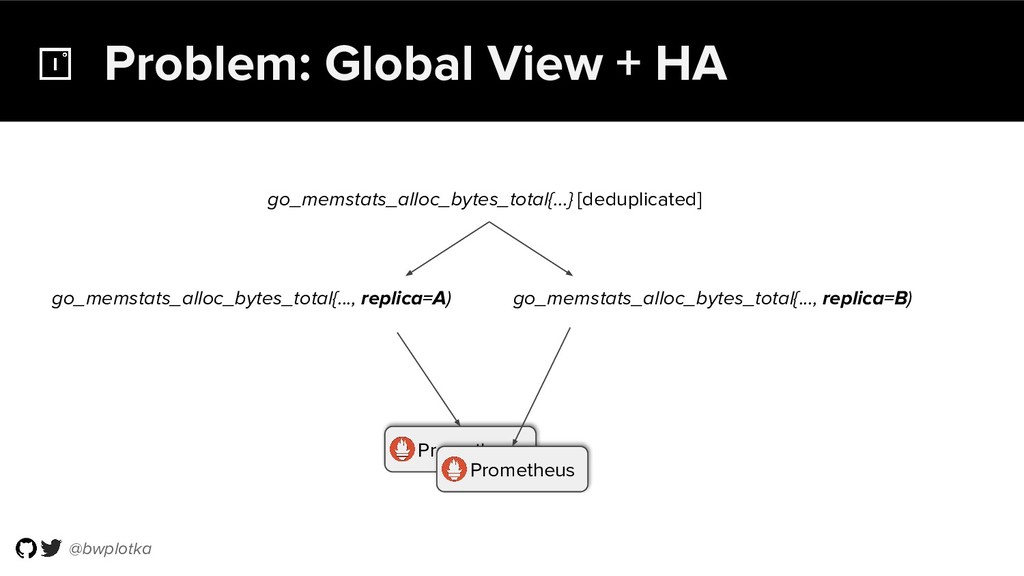
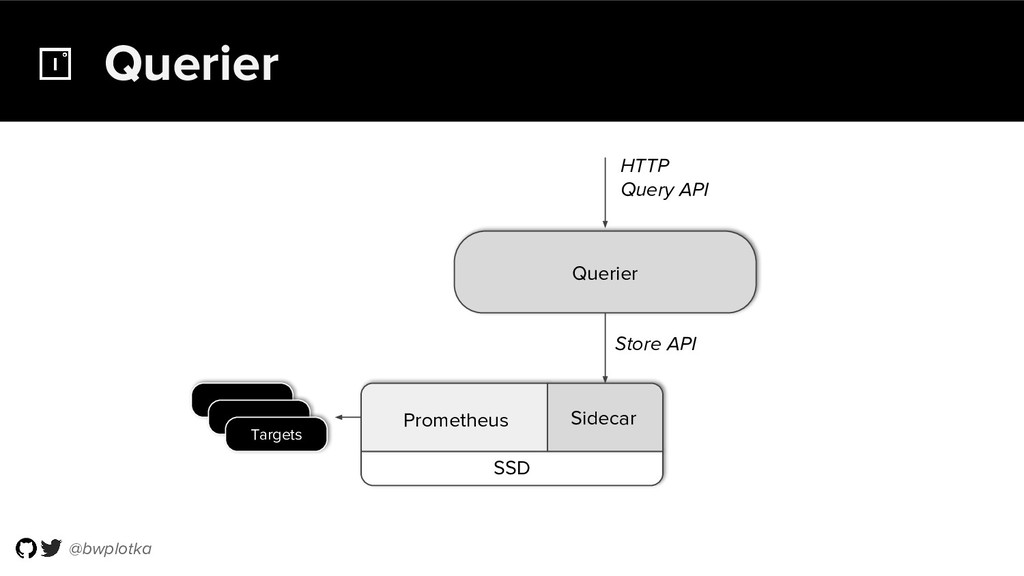
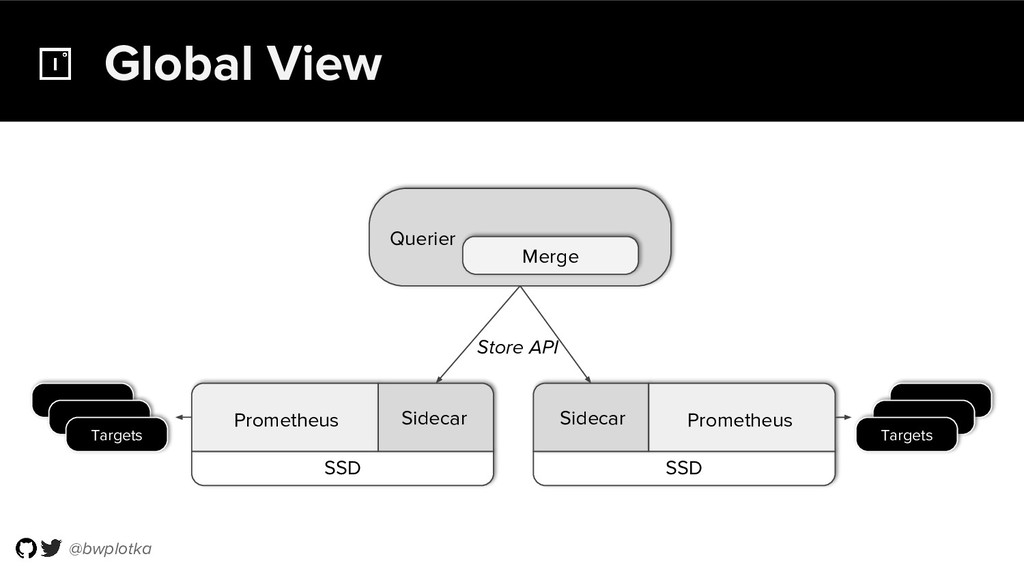
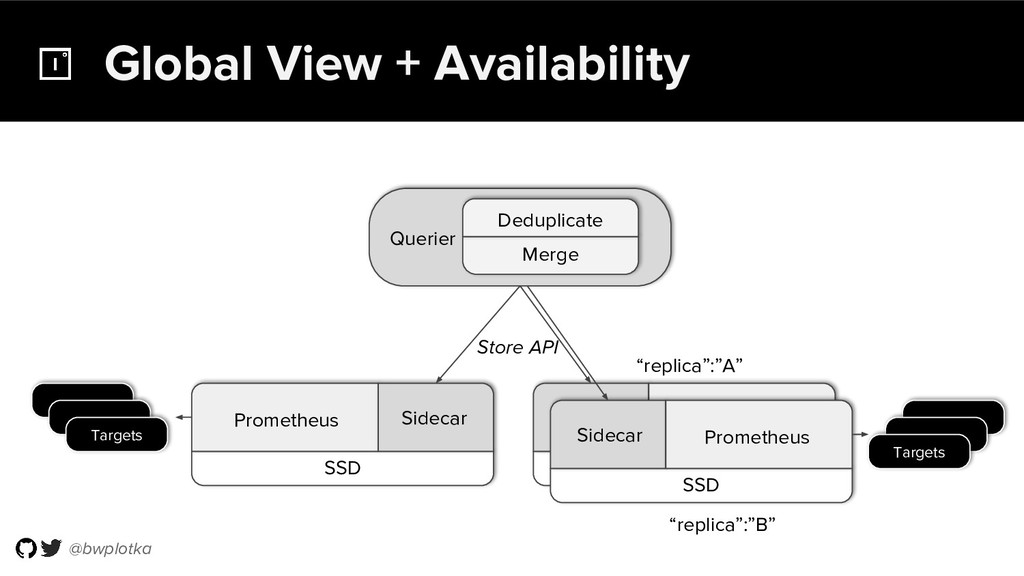
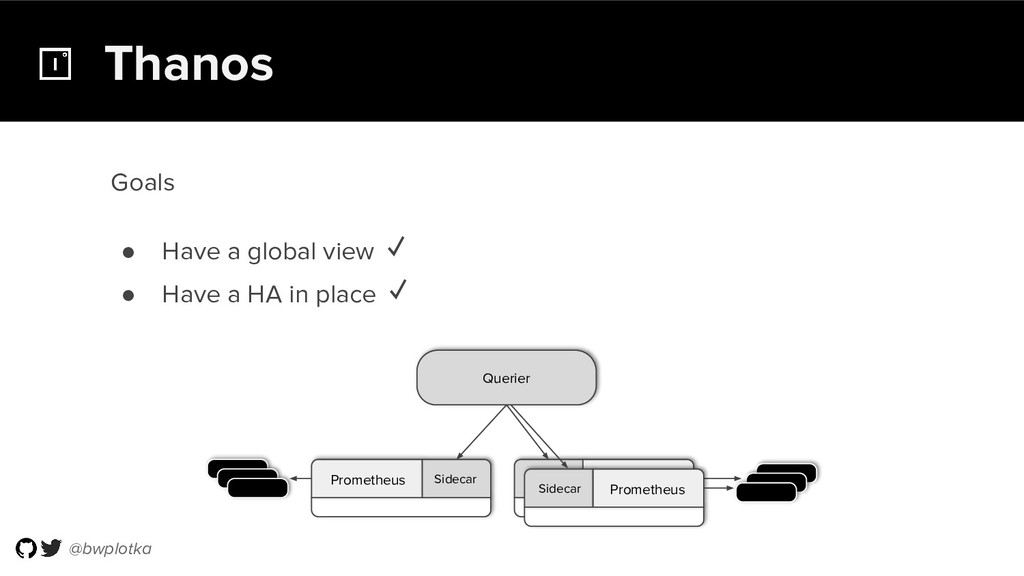
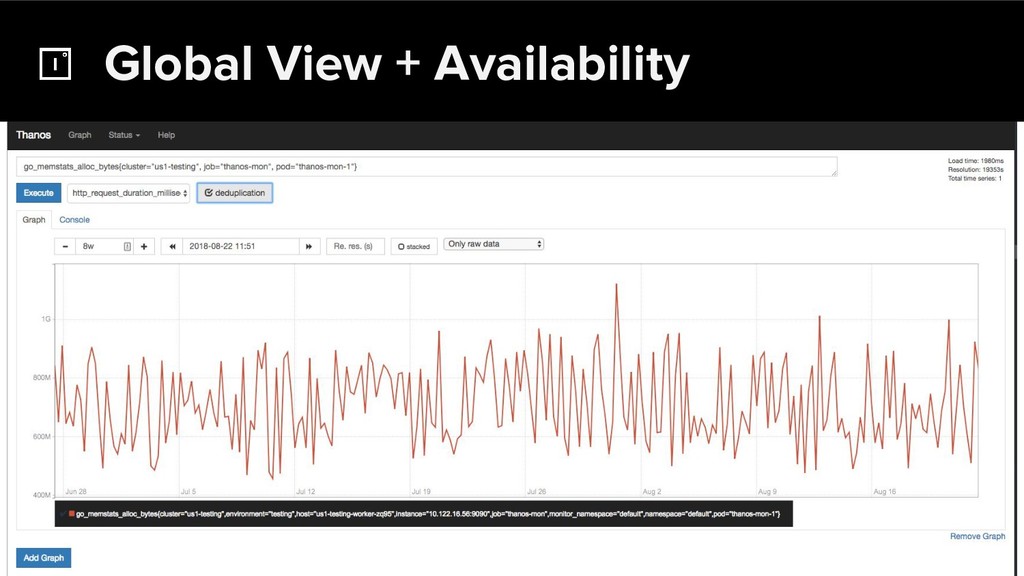
Prometheus has been thriving for several years. However, some questions were still largely unaddressed to this day. How can we store historical data at the order of petabytes in a reliable and cost-efficient way? Can we do so without sacrificing responsive query times? And what about a global view of all our metrics and transparent handling of HA setups?
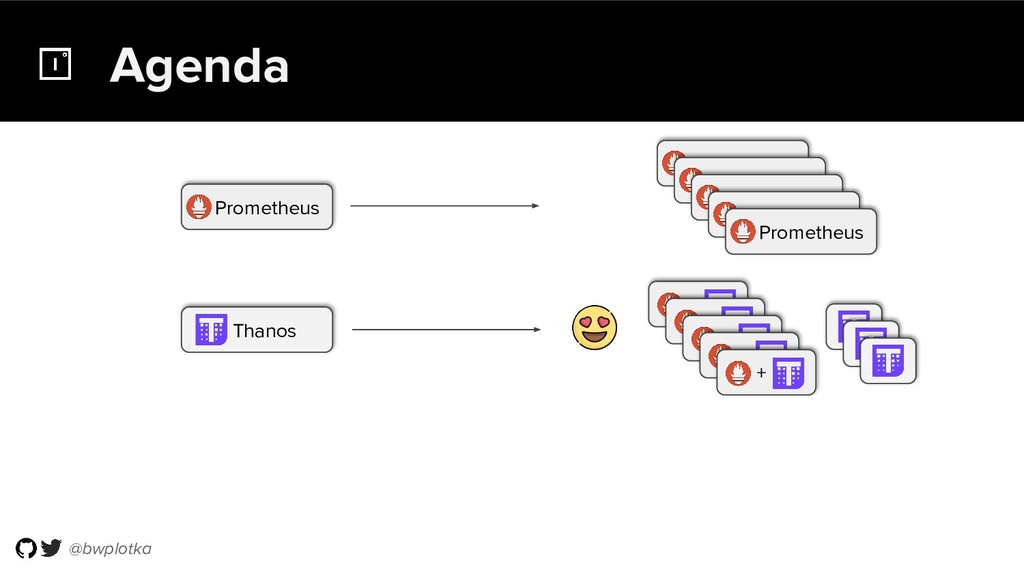
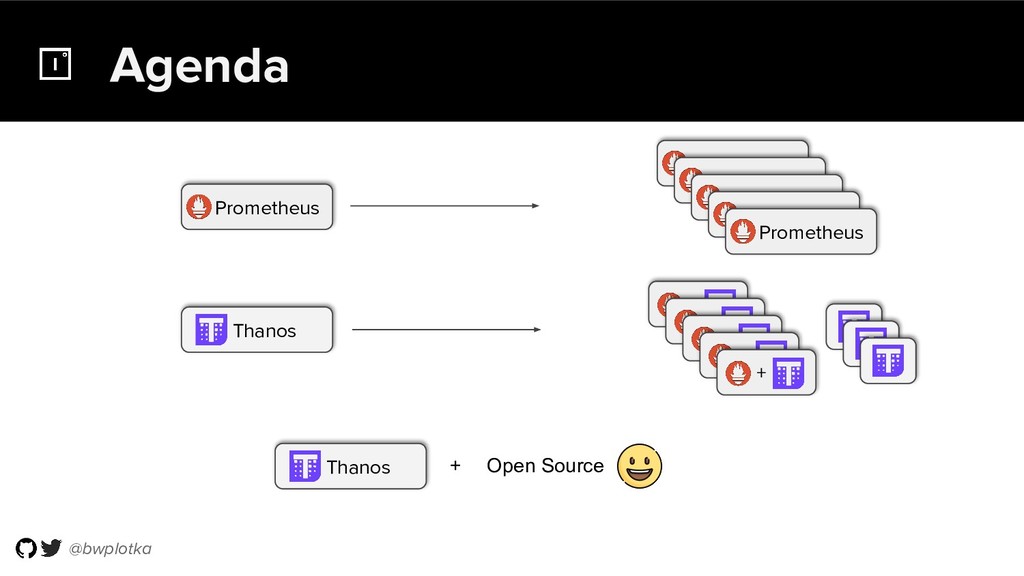
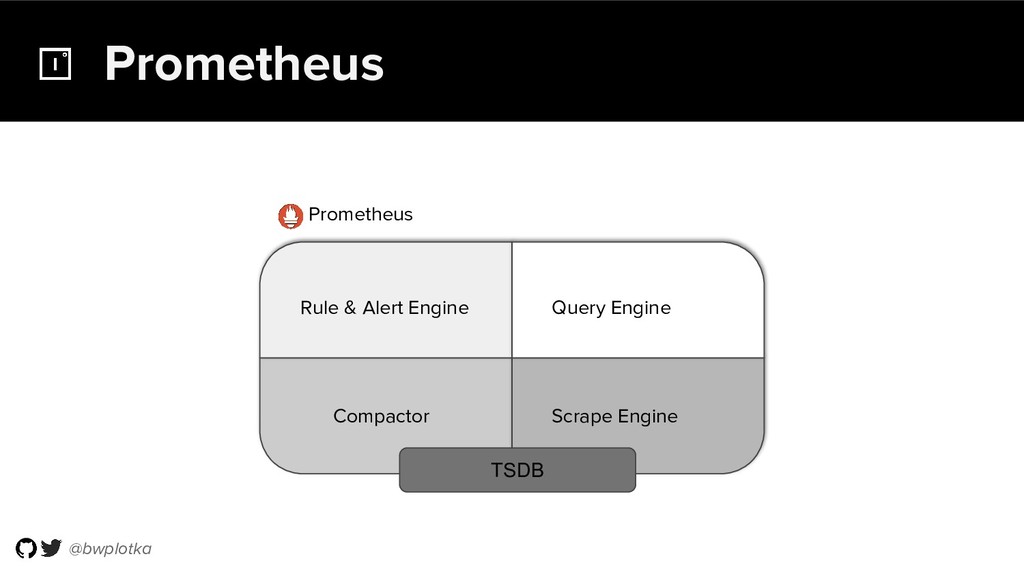
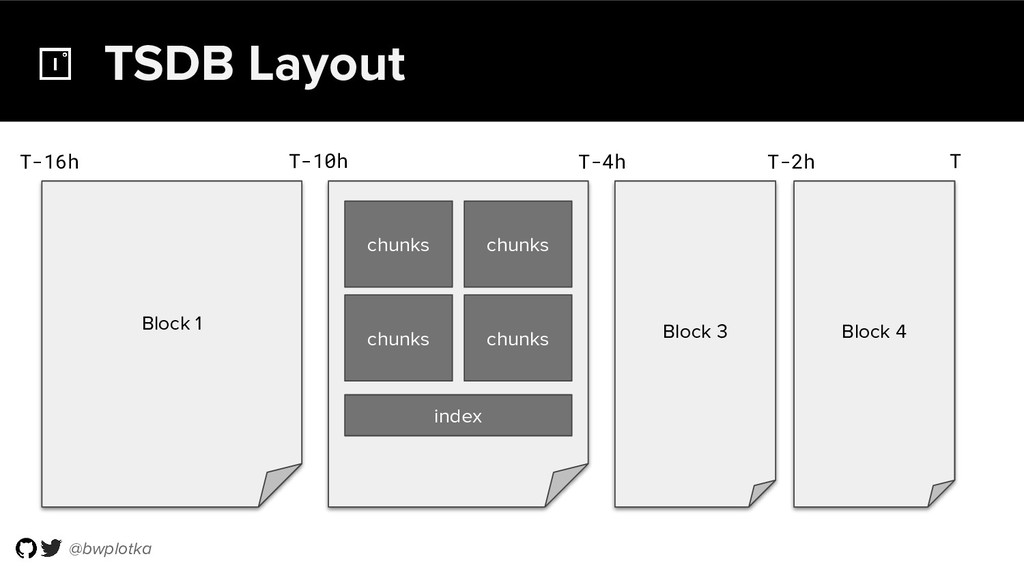
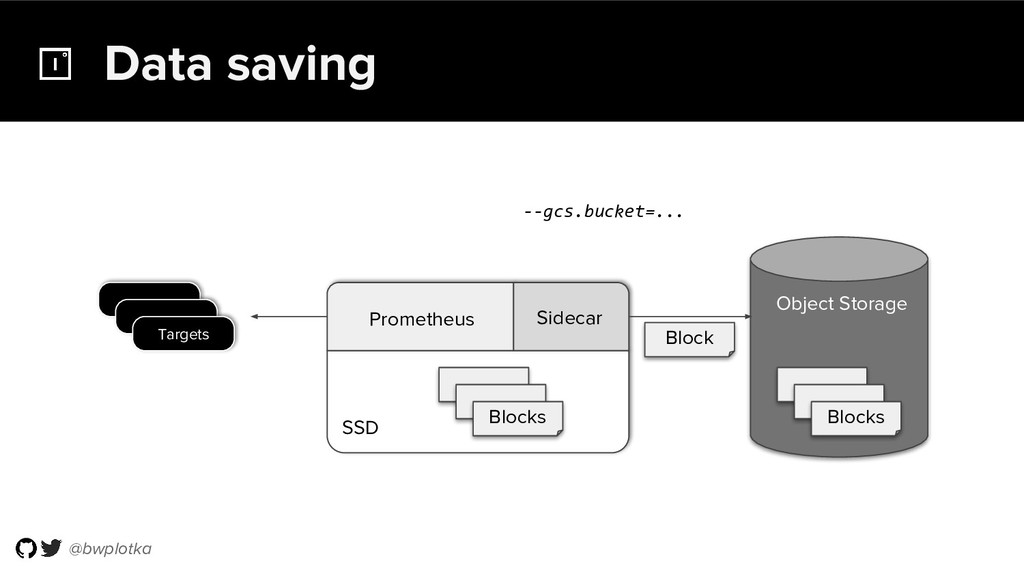
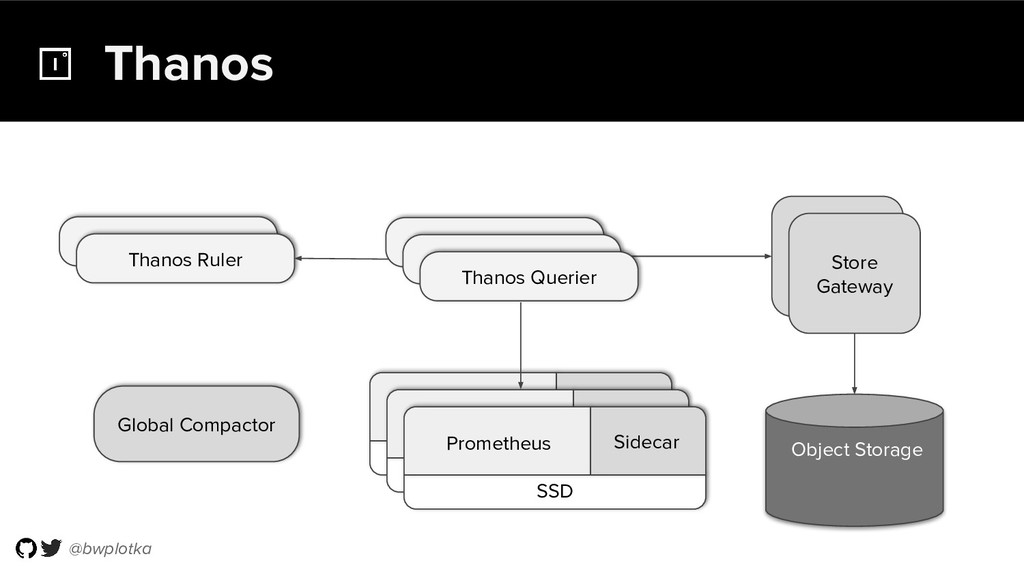
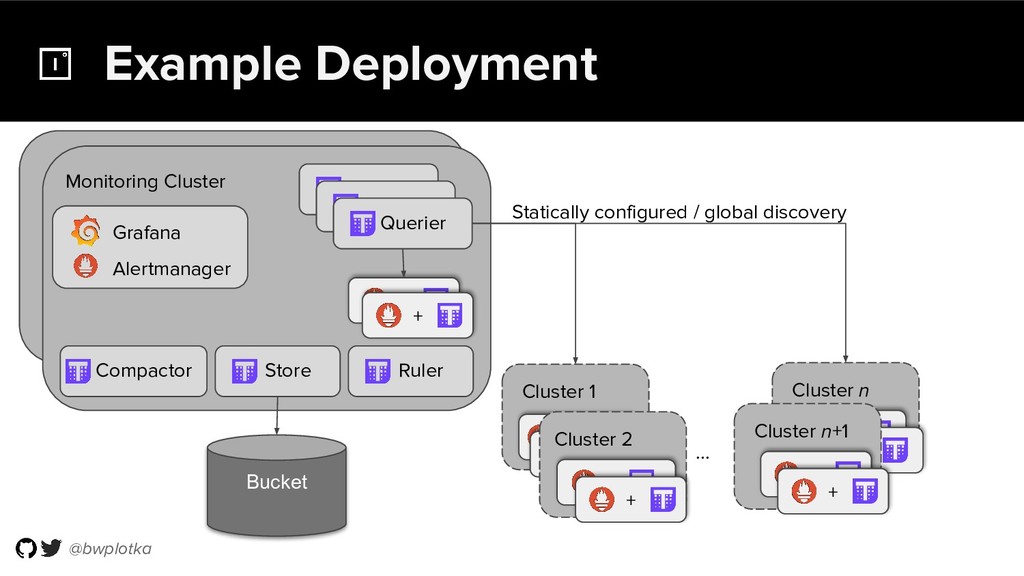
Thanos takes Prometheus' strong foundations and extends it into a clustered, yet coordination free, globally scalable metric system. It retains Prometheus’s simple operational model and even simplifies deployments further. Under the hood, Thanos uses highly cost-efficient object storage that’s available in virtually all environments today. By building directly on top of the storage format introduced with Prometheus 2.0, Thanos achieves near real-time responsiveness even for cold queries against historical data.
{kind=link}
![Bartek Płotka Software Engineer [email protected] @bwplotka](https://files.speakerdeck.com/presentations/58b8a6ac57674e98966ba7eecc8ca004/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@bwplotka Problem: Global View Prometheus Prometheus sum(rate(go_memstats_alloc_bytes_total[1m])) ? source =](https://files.speakerdeck.com/presentations/58b8a6ac57674e98966ba7eecc8ca004/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
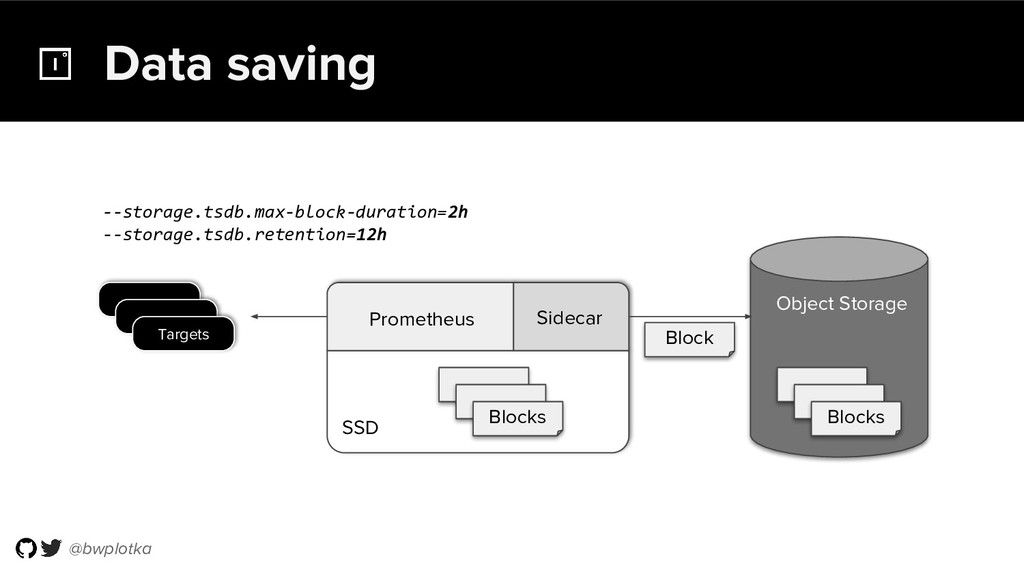{kind=link}
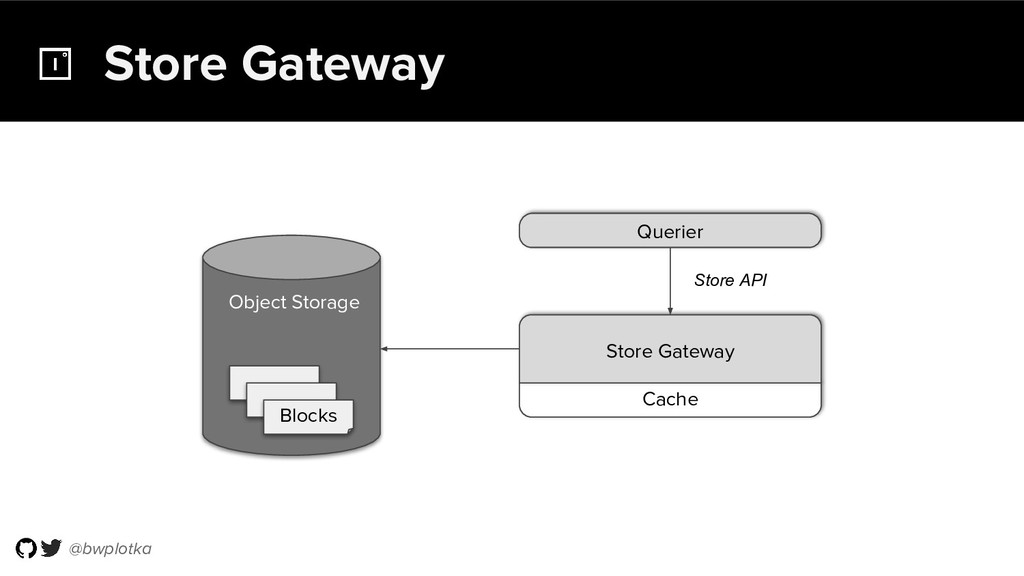{kind=link}
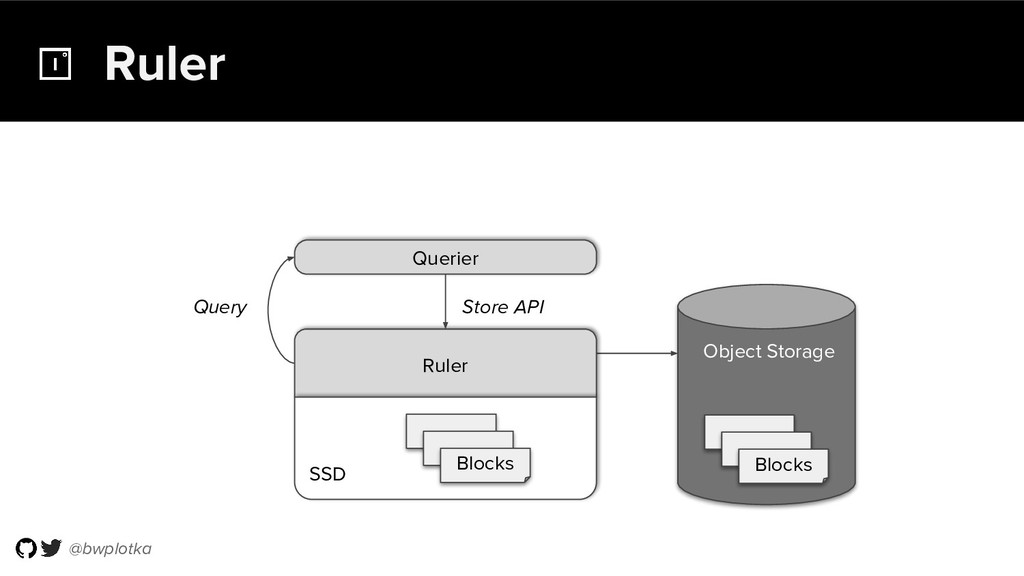{kind=link}
{kind=link}
{kind=link}
{kind=link}
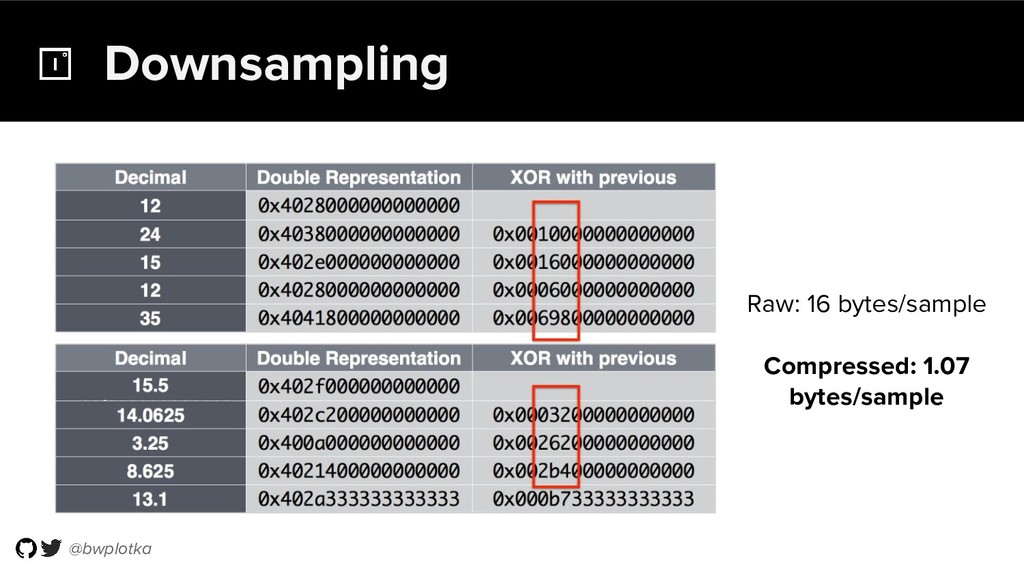{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}