me dijo: “todo ese tema del software suena como a un montón de nerds aburridos buscando llamar la atención” y le respondí “tal vez sea un montón de nerds aburridos” pero seguro que no están buscando llamar la atención. Y realmente me quede pensando en que tampoco son un montón de nerds aburridos, solucionar problemas con software es algo realmente cool, y me siento muy bien cuando hablo con otros developers sobre como estructurar proyectos y volverlos disponibles para millones de usuarios, esto es algo realmente cool. Tan cool que nos sentimos trabajando con una ciencia reservada solo para un grupo elite de personas que incluso han llegado a crear pequeños grupos o hermandades según las herramientas que dominan, como este grupo de django bogotá que cumple dos años y de nuevo pienso “Claro que somos muy cool” pero debemos hacer algo para dejarnos de ver como unos bichos raros, al fin y al cabo somos personas comunes y corrientes que disfrutamos lo que hacemos. ! Entonces en el vuelo de regreso a Bogotá, de repente pensé “Hay que hablar de algo común que llame la atención” y aquí estamos hoy reunidos.
soluciones de alto nivel que sirven a millones de usuarios en todo el mundo. Allí he tenido la oportunidad de colaborar en proyectos como Django, easy-thumbnails, social-auth, django-pipeline, django-crispy-forms, entre otras librerías y actualmente mantengo activamente el desarrollo de django-extensions, django-axes y otros proyectos open source. ! En AxiaCore hemos trabajado en proyectos como el portal institucional del Copnia, el Festival Iberoamericano de Teatro, apps.co, ondademar y crepes & waffles aquí en Colombia y otros proyectos interesantes en Estados Unidos y Europa. ! Somos la única compañía del país certificada en ISO-9001 en desarrollo ágil, y nuestros proyectos han sido ganadores del premio lápiz de acero al mejor portal web durante los últimos tres años consecutivos. ! Soy Camilo Nova y esto es “Cómo hacer un sitio porno con Django”
! “El término porno se refiere a todos aquellos materiales, imágenes o reproducciones realizadas con el fin de provocar la excitación sensorial del receptor.” El porno se manifiesta a través de una multitud de disciplinas, como cine, escultura, fotografía, historieta, literatura o pintura, y ha logrado un gran auge en medios masivos como las revistas, televisión, y últimamente Internet. ! Django es un framework basado en el lenguaje de programación Python que permite construir proyectos en corto tiempo, muy estables y seguros, actualmente están a punto de lanzar la versión 1.7 que incluye muchas mejoras técnicas que no pienso mencionar para no entrar en detalles aburridos para la mayoría. ! Se dice que el trafico porno representa un 30% de todo el trafico de la Internet, aunque recientemente con el crecimiento de smartphones se ha generado grandes contenidos de fotografías (facebook) y big data (google) que la proporción hoy en día se estima reducida a un 4%. Solamente basta recordar la cantidad ‘absurda’ de ‘selfies’ y videos del ‘Ice Bucket Challenge’ que se generan hoy en día. ! Luego es un tema interesante, por supuesto, existen miles de categorías de porno ahi afuera esperando por usuarios de la web, una web que
o videos glamurosos de comida con altos contenidos de grasas y calorías, o platos experimentales con ingredientes inusuales. ! ¿Han visto personas tomando fotografías de lo que se van a comer para publicarlas en alguna red social? eso es Food Porn. Hoy en día existen miles de sitios, los más populares Reddit, Instagram, Facebook, Flickr y muchos otros que contienen millones de contribuciones diarias al Food Porn. ! Debido al gran auge de este término se ha comenzado a volver popular otros usos tales como architecture-porn, carn-porn, space-porn, camera-porn, coffee-porn y muchos otros, tantos que Reddit ha creado una categoría especial llamada “SFW Porn Network“ que consiste de subreddits dedicados a imágenes no eróticas de alta calidad y visualmente llamativas del contenido en cuestión. ! Así como es posible tomarse un selfie, es posible foodstagramear comida, una practica muy común en los asiáticos. Incluso hoy en día hay restaurantes en Nueva York que prohiben tomarle fotos a los platos que sirven.
- Definimos una serie de urls donde sabemos que hay contenido que nos interesa. - Ejecutamos una tarea automatizada cada cierto tiempo que vaya a esas urls y descargue las imágenes por nosotros. - Con esa información vamos construyendo una base de datos de contenido que podemos administrar, agregando detalles a las imágenes, incluso deshabitando aquellas que no nos interesan. - Luego vamos a construir una página sencilla para mostrar las imágenes de nuestro interés, pero lo haremos de forma que no deba consultar la base de datos en cada petición. - Realizaremos las configuraciones necesarias para que el sitio cargue lo más rápido posible. - Obtendremos ganancias de nuestro proyecto debido al alto trafico de visitantes que vamos a tener. ! Entonces comencemos por imaginarnos como sería la arquitectura de nuestro prototipo.
de alto tráfico en producción, tres capas principales y dentro de cada capa servicios y componentes específicos para cada necesidad del portal, ciertamente complejo de entender. Pero a eso nos dedicamos nosotros, a volver más simple y sencillo lo complicado, de forma que no necesitemos años para construir una plataforma, sino que podamos salir a producción en cuestión de meses. ! Luego para construir este sitio que pensamos tener vamos a plantear hipotéticamente las cosas que debemos tener en cuenta para lograr un sitio agregador de contenidos que sea rápido y estable, por supuesto que esto puede aplicar para otros casos distintos al de esta charla. ! Vamos a ir desde la capa visual, luego a la capa lógica y por ultimo a la de datos, comencemos por utilizar el mejor servidor web del mercado, Internet Information Server.
dioses del Internet para que podamos cargar fotos de gatos a toda velocidad, sin embargo, para el ojo no entrenado puede parecer una herramienta común y corriente, es por eso que voy a compartir con ustedes algunos secretos sobre como debe lucir nginx para un sitio de alto tráfico.
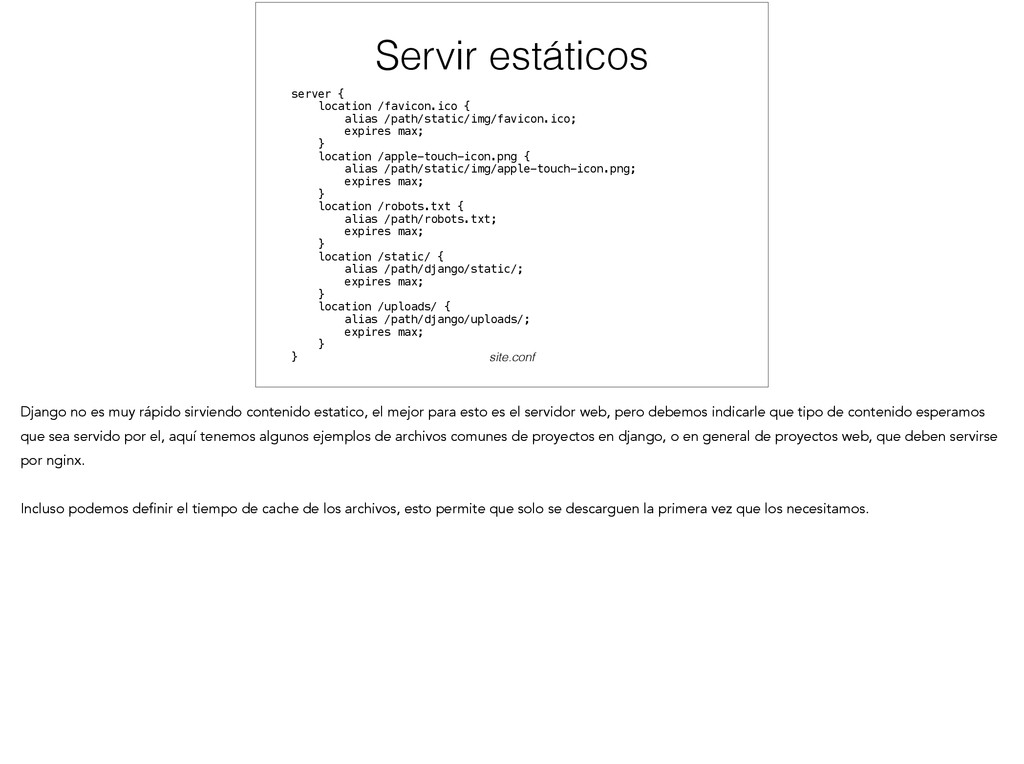
location /apple-touch-icon.png { alias /path/static/img/apple-touch-icon.png; expires max; } location /robots.txt { alias /path/robots.txt; expires max; } location /static/ { alias /path/django/static/; expires max; } location /uploads/ { alias /path/django/uploads/; expires max; } } Servir estáticos site.conf Django no es muy rápido sirviendo contenido estatico, el mejor para esto es el servidor web, pero debemos indicarle que tipo de contenido esperamos que sea servido por el, aquí tenemos algunos ejemplos de archivos comunes de proyectos en django, o en general de proyectos web, que deben servirse por nginx. ! Incluso podemos definir el tiempo de cache de los archivos, esto permite que solo se descarguen la primera vez que los necesitamos.
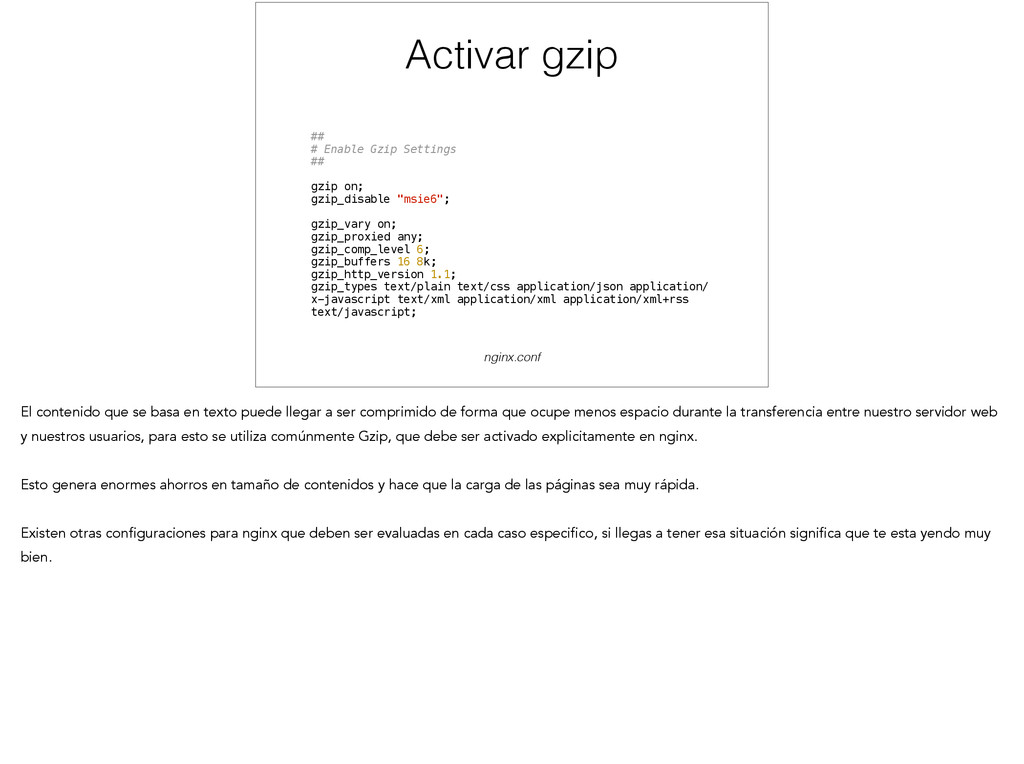
on; gzip_disable "msie6"; ! gzip_vary on; gzip_proxied any; gzip_comp_level 6; gzip_buffers 16 8k; gzip_http_version 1.1; gzip_types text/plain text/css application/json application/ x-javascript text/xml application/xml application/xml+rss text/javascript; nginx.conf El contenido que se basa en texto puede llegar a ser comprimido de forma que ocupe menos espacio durante la transferencia entre nuestro servidor web y nuestros usuarios, para esto se utiliza comúnmente Gzip, que debe ser activado explicitamente en nginx. ! Esto genera enormes ahorros en tamaño de contenidos y hace que la carga de las páginas sea muy rápida. ! Existen otras configuraciones para nginx que deben ser evaluadas en cada caso especifico, si llegas a tener esa situación significa que te esta yendo muy bien.
/ { limit_req zone=one burst=10 nodelay; include uwsgi_params; uwsgi_pass unix:///tmp/uwsgi_app.sock; } } Limitar peticiones site.conf Tenemos que limitar las peticiones a nuestro servidor, no queremos que se bajen todo nuestro porno con un script. Esto genera un limite de peticiones por IP suficiente para estar tranquilos y no permitir que un solo usuario se consuma la mayoría de recursos de nuestro servidor que pueden necesitar otros usuarios. ! En la primera línea básicamente estamos creando una zona llamada ‘one’ con un espacio de 10 megas para almacenamiento y definimos el limite de una petición por segundo. Luego al definir donde queremos utilizar la zona damos un rango de aceptación de 10 para disparar el bloqueo, y luego con la opción ’nodelay’ hacemos que el error aparezca al usuario de inmediato, por defecto lo que hace es demorar los requests que superan el margen que hemos dado. ! Otra optimización que pueden lograr es utilizar sockets y no puertos TCP para comunicar el servidor web con el servidor de aplicaciones.
mayor tiempo de carga tiene la pagina y mayor riesgo hay de que al recibir muchas visitas se ponga muy lenta o se caiga. ! La cantidad de peticiones al servidor depende generalmente de la cantidad de imágenes, librerías javascript, y archivos css, entre mas librerías se tenga para un proyecto, más peticiones tendrán que realizarse y mas tiempo tomará la página en cargar. ! Los navegadores actuales hacen un gran trabajo en optimizar esta carga de recursos, sin embargo cada petición HTTP tiene un impacto, sea para cargar una imagen de 2k o una de 2 megas. ! Una muy buena herramienta que se puede utilizar, hay varias, es django-pipeline, con la cual puedes agrupar y comprimir varios archivos de javascript o css en uno solo.
que usaremos para nuestro sitio porno, principalmente usamos jquery y varias librerías o plugins adicionales para diversas funcionalidades que tenemos en nuestra página, esta lista generalmente crece a medida que se agregan nuevas funciones al sitio, y no solo librerías externas, también puedes llegar a necesitar el código javascript que has creado especialmente para esta página. ! Algunos pueden estar pensando que un CDN es la mejor opción, pues es valido siempre y cuando puedas pagar cloudfront sin arruinarte, además de necesitar unos pasos adicionales para usar esta opción. ! En un proyecto estándar pueden utilizarse alrededor de 15 librerías diferentes y tanto javascript como sea necesario, esto implica alrededor de 20 peticiones http para traer cada librería en cada carga de cada página, multipliquen eso por miles de usuarios ingresando simultáneamente, se ve mal cierto? que tal si pudiéramos convertirlo en…
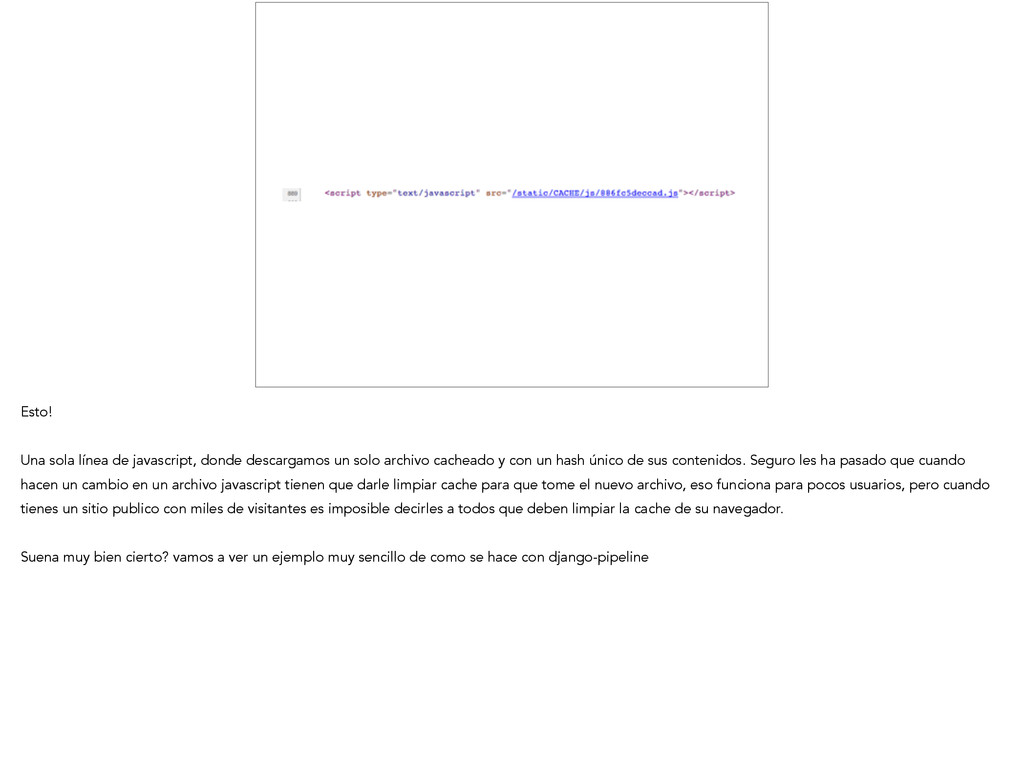
solo archivo cacheado y con un hash único de sus contenidos. Seguro les ha pasado que cuando hacen un cambio en un archivo javascript tienen que darle limpiar cache para que tome el nuevo archivo, eso funciona para pocos usuarios, pero cuando tienes un sitio publico con miles de visitantes es imposible decirles a todos que deben limpiar la cache de su navegador. ! Suena muy bien cierto? vamos a ver un ejemplo muy sencillo de como se hace con django-pipeline
( 'bower_components/dropzone/downloads/css/dropzone.css', 'bower_components/bootstrap-datepicker/css/datepicker.css', 'bower_components/eonasdan-bootstrap-datetimepicker/build/css/ bootstrap-datetimepicker.min.css', 'bower_components/bootstrap-switch/dist/css/bootstrap3/ bootstrap-switch.min.css', 'css/styles.css', ), 'output_filename': 'css/styles.min.css', } } settings.py Vamos a nuestro archivo settings.py y agregamos un storage diferente para nuestros archivos estáticos, aquí estamos indicando a django que debe utilizar el storage de django-pipeline que utiliza cache, esto quiere decir que genera un hash único para los archivos y se lo agrega al archivo generado, para que cuando cambie algún contenido se genere otro hash y no tengan los usuarios que limpiar la cache para utilizar el nuevo código. ! Luego vamos a definir en un diccionario los archivos css que vamos a utilizar, les damos la ruta y le decimos como queremos que se llame el archivo de salida, incluso podemos configurar el tipo de compresor que queremos utilizar para el archivo de salida, con esto reducimos varios archivos css de diferentes librerías en un único archivo. ! Este ejemplo tiene un solo archivo, pero no es regla general, la regla es utilizar la menor cantidad posible, pero esto dependerá únicamente de cada proyecto y de cada caso, pero con esto pueden tener una idea de como es la cosa.
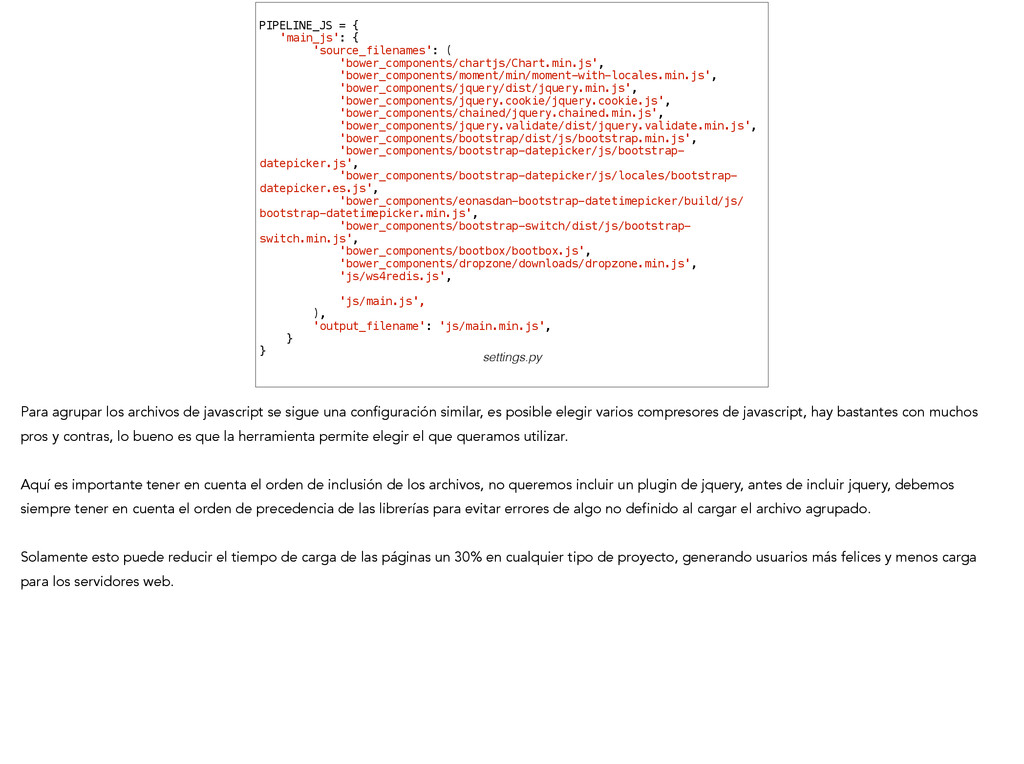
'bower_components/jquery.cookie/jquery.cookie.js', 'bower_components/chained/jquery.chained.min.js', 'bower_components/jquery.validate/dist/jquery.validate.min.js', 'bower_components/bootstrap/dist/js/bootstrap.min.js', 'bower_components/bootstrap-datepicker/js/bootstrap- datepicker.js', 'bower_components/bootstrap-datepicker/js/locales/bootstrap- datepicker.es.js', 'bower_components/eonasdan-bootstrap-datetimepicker/build/js/ bootstrap-datetimepicker.min.js', 'bower_components/bootstrap-switch/dist/js/bootstrap- switch.min.js', 'bower_components/bootbox/bootbox.js', 'bower_components/dropzone/downloads/dropzone.min.js', 'js/ws4redis.js', ! 'js/main.js', ), 'output_filename': 'js/main.min.js', } } settings.py Para agrupar los archivos de javascript se sigue una configuración similar, es posible elegir varios compresores de javascript, hay bastantes con muchos pros y contras, lo bueno es que la herramienta permite elegir el que queramos utilizar. ! Aquí es importante tener en cuenta el orden de inclusión de los archivos, no queremos incluir un plugin de jquery, antes de incluir jquery, debemos siempre tener en cuenta el orden de precedencia de las librerías para evitar errores de algo no definido al cargar el archivo agrupado. ! Solamente esto puede reducir el tiempo de carga de las páginas un 30% en cualquier tipo de proyecto, generando usuarios más felices y menos carga para los servidores web.
vamos a servir desde nuestro sitio, serán millones de imágenes, ocupando terabytes de espacio en disco y tendrán un crecimiento importante diariamente para atender la demanda del publico que quiera más. En este caso vamos a simplificar las cosas usando solamente imágenes pero bien podemos servir también audio, video o streaming que puede comenzar a poner las cosas pesadas. ! Alojar todo este contenido en nuestro servidor ya no es viable, tenemos que buscar un proveedor de almacenamiento que nos garantice que la información no se pierde, se sirve rápido a los usuarios y esta disponible desde cualquier parte del mundo, la mejor opción de lejos es ir con un proveedor de los grandes del mercado, en este caso vamos con Amazon. ! Amazon ofrece un servicio de almacenamiento en la nube muy económico y eficiente para grandes volúmenes de datos llamado S3, este servicio te cobra por el almacenamiento que utilizas de manera flexible permitiendo hacer muy eficientemente la gestión de los contenidos en tu sitio. Proyectos como Instagram o Dropbox utilizan S3 para almacenar las toneladas de archivos que procesan, así que nosotros lo haremos igual. ! Al ser un servicio externo necesitamos encontrar una manera de podernos comunicar con el, amazon S3 provee un API para almacenar y obtener los archivos de forma segura y rápida, para evitar hacer esto manualmente vamos a ahorrarnos mucho trabajo utilizando una librería llamada boto que nos permite acceder a los servicios de amazon desde código python en nuestro proyecto django.
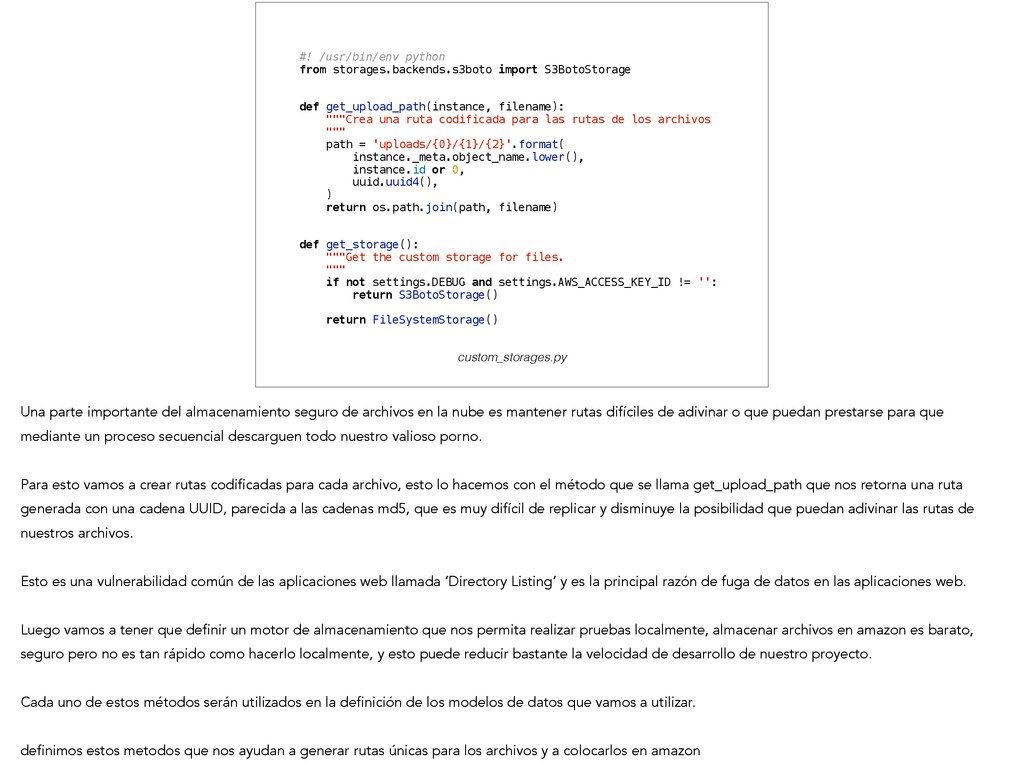
get_upload_path(instance, filename): """Crea una ruta codificada para las rutas de los archivos """ path = 'uploads/{0}/{1}/{2}'.format( instance._meta.object_name.lower(), instance.id or 0, uuid.uuid4(), ) return os.path.join(path, filename) ! ! def get_storage(): """Get the custom storage for files. """ if not settings.DEBUG and settings.AWS_ACCESS_KEY_ID != '': return S3BotoStorage() ! return FileSystemStorage() custom_storages.py Una parte importante del almacenamiento seguro de archivos en la nube es mantener rutas difíciles de adivinar o que puedan prestarse para que mediante un proceso secuencial descarguen todo nuestro valioso porno. ! Para esto vamos a crear rutas codificadas para cada archivo, esto lo hacemos con el método que se llama get_upload_path que nos retorna una ruta generada con una cadena UUID, parecida a las cadenas md5, que es muy difícil de replicar y disminuye la posibilidad que puedan adivinar las rutas de nuestros archivos. ! Esto es una vulnerabilidad común de las aplicaciones web llamada ‘Directory Listing’ y es la principal razón de fuga de datos en las aplicaciones web. ! Luego vamos a tener que definir un motor de almacenamiento que nos permita realizar pruebas localmente, almacenar archivos en amazon es barato, seguro pero no es tan rápido como hacerlo localmente, y esto puede reducir bastante la velocidad de desarrollo de nuestro proyecto. ! Cada uno de estos métodos serán utilizados en la definición de los modelos de datos que vamos a utilizar. ! definimos estos metodos que nos ayudan a generar rutas únicas para los archivos y a colocarlos en amazon
app.custom_storages import get_upload_path ! ! class Entry(models.Model): name = models.CharField( max_length=100, ) ! image = models.FileField( upload_to=get_upload_path, storage=get_storage(), max_length=255, ) ! is_active = models.BooleanField( default=True, ) ! created_at = models.DateTimeField( auto_now_add=True, ) models.py Vamos a pensar en un modelo muy sencillo para almacenar cada imagen de comida que queramos, para esto vamos a definir en el FileField o Image Field, la ruta a donde lo queremos subir, que es la generada aleatoriamente por nuestro metodo y el motor de almacenamiento que vamos a usar para este archivo, django hace fácil el uso de varios motores de almacenamiento para los archivos que necesitemos, bastante util porque nos ahorra mucho trabajo. ! Con esta sencilla configuración ya tenemos un modelo de datos que permite almacenar los archivos en amazon S3 para que sean disponibles para todos nuestros usuarios. ! Otra ventaja que no debemos olvidar es que servir los contenidos desde diferentes servidores permite que los navegadores puedan cargarlos de forma paralela, reduciendo los tiempos de carga de los usuarios, incluso podemos ir más allá en optimización utilizando lazy load en las imágenes, trayendolas únicamente cuando el usuario esta a punto de hacer scroll sobre ellas.
de botella muy común llamado ‘Base de datos’, aquí es común encontrar puntos donde luego de una cantidad considerable de información una consulta se vuelve muy demorada haciéndonos perder valiosos usuarios. ! A pesar de utilizar la mejor base de datos jamás creada, sql server, no garantiza que tengamos consultas rápidas en nuestro sitio. Algunos alcanzaron a alegrarse al escuchar sql server, pero la realidad es que postgres es MUY superior. ! De todas formas, a pesar de utilizar postgres, tener nuestras tablas correctamente indexadas, y tener un DBA con un doctorado, la base de datos es un cuello de botella que debemos complementar con una buena estrategia de cache. ! Esto solo aplica para portales con “Alta demanda” por favor no lo hagan en portales pequeños, recuerden evitar la optimización temprana de los proyectos. ! Una buena estrategia de cache debe permitirnos servir desde la memoria RAM del servidor la información más relevante para el usuario, ya que es mucho más rápido que servirla desde la base de datos o del disco duro del servidor. Lo podemos pensar como si un mensajero viene a recoger un paquete a la torre colpatria y en vez de tener que ingresar al edificio, tomar el ascensor hasta el piso 50 y preguntarle al doctor por el paquete, lo pudiera recoger
{ "CLIENT_CLASS": "redis_cache.client.DefaultClient", } } } settings.py $ pip install django-redis Primero debemos decirle a django que nuestro backend de cache va a ser redis, django permite utilizar varios backends en una sola aplicación, esto nos permite utilizar por ejemplo redis específicamente para unas cosas y otro backend, como memcached por ejemplo, para otras, aquí para hacer las cosas sencillas vamos a usar redis para todo. ! Luego de instalar el paquete django-redis, debemos indicar la ubicación de nuestro servidor de redis y la base de datos que queremos utilizar, por defecto vienen 8 bases de datos diferentes para evitar problemas de choque de llaves. ! Redis es una base de datos que almacena tipos de datos llave, valor, como un diccionario de django y lo hace muy eficientemente, generalmente sirviendo la información desde memoria lo que lo hace tan rápido. Redis no solamente almacena información, también es capaz de generar cálculos y aplicar otras funciones interesantes sobre los datos, eso vale la pena conocerlo en otra charla. ! Luego que hemos indicado la ubicación de nuestro servidor Redis, el puerto y la base de datos podemos comenzar a almacenar y servir de allí información que sepamos no cambia mucho y que podemos servir al usuario más rápidamente.
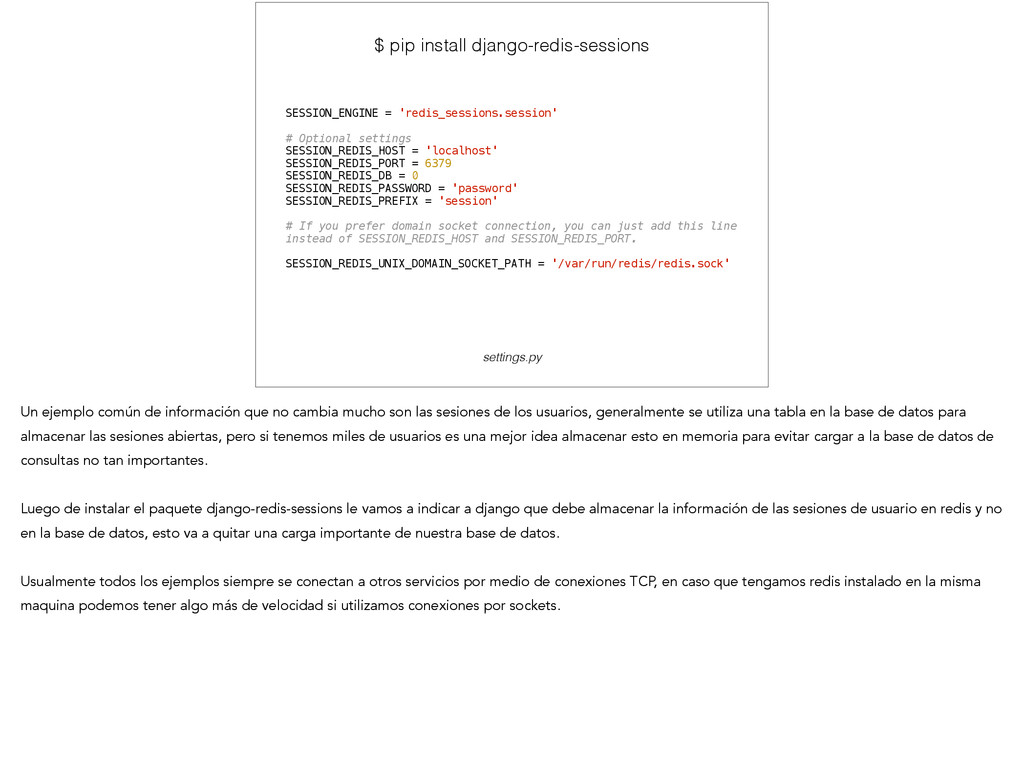
Optional settings SESSION_REDIS_HOST = 'localhost' SESSION_REDIS_PORT = 6379 SESSION_REDIS_DB = 0 SESSION_REDIS_PASSWORD = 'password' SESSION_REDIS_PREFIX = 'session' ! # If you prefer domain socket connection, you can just add this line instead of SESSION_REDIS_HOST and SESSION_REDIS_PORT. ! SESSION_REDIS_UNIX_DOMAIN_SOCKET_PATH = '/var/run/redis/redis.sock' Un ejemplo común de información que no cambia mucho son las sesiones de los usuarios, generalmente se utiliza una tabla en la base de datos para almacenar las sesiones abiertas, pero si tenemos miles de usuarios es una mejor idea almacenar esto en memoria para evitar cargar a la base de datos de consultas no tan importantes. ! Luego de instalar el paquete django-redis-sessions le vamos a indicar a django que debe almacenar la información de las sesiones de usuario en redis y no en la base de datos, esto va a quitar una carga importante de nuestra base de datos. ! Usualmente todos los ejemplos siempre se conectan a otros servicios por medio de conexiones TCP, en caso que tengamos redis instalado en la misma maquina podemos tener algo más de velocidad si utilizamos conexiones por sockets.
<a href="#amateur">Amateur {{ amateur_list.count }}</a> <a href="#new">Recently added {{ recent_list.get_a_join_on_20_tables }}</a> ... </nav> {% endcache %} Cache en las plantillas base.html Una vez que hemos definido nuestro backend de cache podemos comenzar a utilizarlo en diferentes partes, por ejemplo en las plantillas, si alguien ha hecho un menu de navegación administrable de tres niveles sabe lo complicado que puede ser cargar el menu en todas las páginas del sitio, esto porque en cada página debe ir a la base de datos a tomar la estructura del menu de navegación, que no cambia tan frecuentemente y mostrarlo al usuario en cada página que visita. ! Al colocar la generación del menu de navegación en la cache lo que hacemos es cargar la primera vez la información desde la base de datos y luego django la coloca en el servidor de cache, en memoria, para servirla desde allí en las páginas posteriores reduciendo la cantidad de consultas a la base de datos y el tiempo de carga de las páginas. ! Simplemente debemos colocar la porción de código de las plantillas que queremos cachear entre los tags de cache que reciben dos parametros, el primero el tiempo en millisegundos que queremos mantener la información en cache, hasta que sea regenerada y luego un nombre para la porción de código que estamos colocando en cache, esto facilita que no tengamos problemas con los nombres de las llaves de lo que estamos almacenando. ! Como pueden ver esto puede reducir una consulta a la base de datos que haga un join en 20 tablas y se demore más de 10 segundos, a colocar el resultado directamente en memoria y entregarlo al usuario de manera inmediata.
render_to_string ! def render_intercom(request): code = cache.get('intercom-{0}'.format(user.id)) if not code: code = render_to_string('intercom.html', { 'user': user, 'app_id': queryset.some_complex_db_query(), }) cache.set('intercom-{0}'.format(user.id), code, 60 * 60 * 24) ! return code ! views.py El cache también lo podemos utilizar directamente para almacenar valores puntuales que quisiéramos mantener en memoria para agilizar algunas cosas. ! En este ejemplo definimos el nombre de una llave única que utilizamos en el cache, esta llave es independiente para cada usuario y luego preguntamos si ya hay un valor almacenado para esa llave, en caso que no lo tengamos en cache, vamos a realizar el proceso para generar el valor y lo colocamos en cache durante 1 día. ! Estas optimizaciones se pueden llevar a cabo en muchas partes del proyecto, donde podamos identificar cuellos de botella para nuestra aplicación, es por eso que una buena estrategia de cache se hace necesaria y mantener vigilando el comportamiento de proyecto en producción es recomendado. ! En general, entre menos tengas que ir a la base de datos, siempre será mejor.
el nombre de esa dona, en realidad es el nombre de una librería que unifica los selectores disponibles en jquery para navegar por el DOM de una página HTML, con python. ! Quienes hayan utilizado jquery para encontrar elementos dentro del HTML de las páginas sabrán lo util que puede ser para encontrar contenido rápidamente, en este caso estamos pensando en encontrar imágenes en las páginas web, porque queremos agregar contenidos de otros lugares para mostrarlos en el nuestro, si queremos hacerlo de manera automática este es el camino que debemos tomar. ! A menos que alguien quiera demostrar sus conocimientos en expresiones regulares..
ganado el premio lápiz de acero a mejor sitio web, ni porque haya sido desarrollado por AxiaCore, sino porque hacen los mejores helados, postres y crepes en Colombia y los otros 7 países donde se encuentran. ! Este portal nos puede brindar mucho material porno para nuestro agregador, tiene una fotografía excelente y el portal es muy visual, ideal para invitar a los usuarios a comerse un de-li-ci-o-so helado de chocolate con arequipe. ! No puedo decir que sea legal o ilegal, pero vamos a suponer que vamos a utilizar este portal para obtener nuestros contenidos.
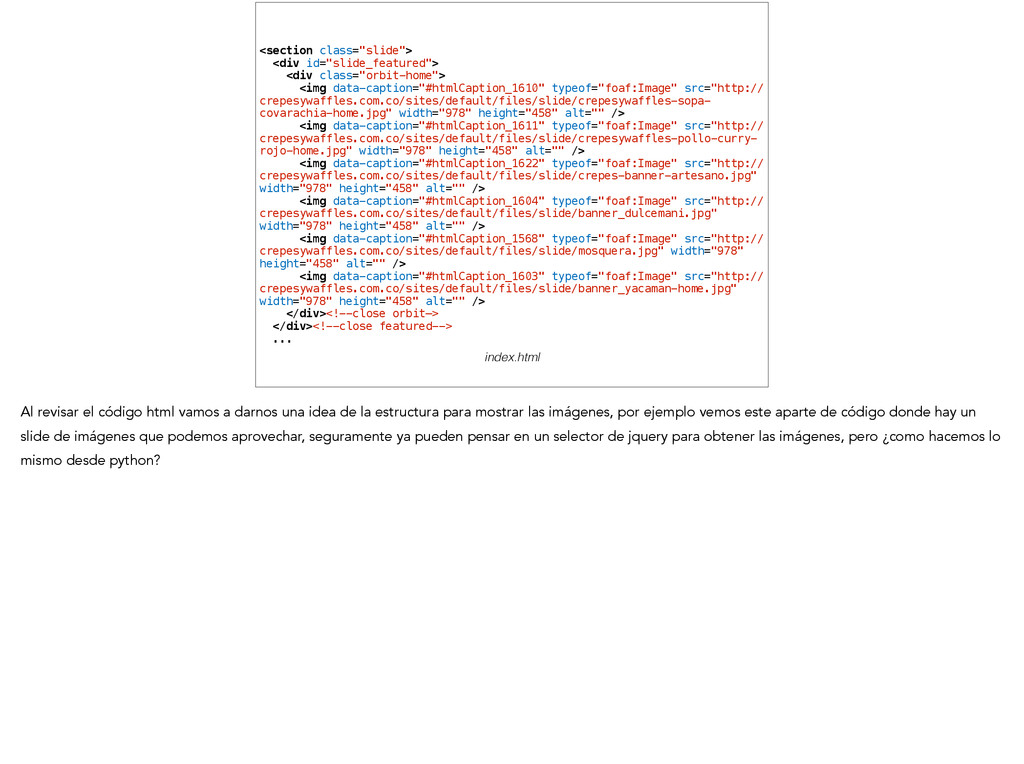
crepesywaffles.com.co/sites/default/files/slide/crepesywaffles-sopa- covarachia-home.jpg" width="978" height="458" alt="" /> <img data-caption="#htmlCaption_1611" typeof="foaf:Image" src="http:// crepesywaffles.com.co/sites/default/files/slide/crepesywaffles-pollo-curry- rojo-home.jpg" width="978" height="458" alt="" /> <img data-caption="#htmlCaption_1622" typeof="foaf:Image" src="http:// crepesywaffles.com.co/sites/default/files/slide/crepes-banner-artesano.jpg" width="978" height="458" alt="" /> <img data-caption="#htmlCaption_1604" typeof="foaf:Image" src="http:// crepesywaffles.com.co/sites/default/files/slide/banner_dulcemani.jpg" width="978" height="458" alt="" /> <img data-caption="#htmlCaption_1568" typeof="foaf:Image" src="http:// crepesywaffles.com.co/sites/default/files/slide/mosquera.jpg" width="978" height="458" alt="" /> <img data-caption="#htmlCaption_1603" typeof="foaf:Image" src="http:// crepesywaffles.com.co/sites/default/files/slide/banner_yacaman-home.jpg" width="978" height="458" alt="" /> </div><!--close orbit—> </div><!--close featured--> ... index.html Al revisar el código html vamos a darnos una idea de la estructura para mostrar las imágenes, por ejemplo vemos este aparte de código donde hay un slide de imágenes que podemos aprovechar, seguramente ya pueden pensar en un selector de jquery para obtener las imágenes, pero ¿como hacemos lo mismo desde python?
! # We can crawl for urls too url = ['http://crepesywaffles.com.co',] ! with codecs.open('crawled.log', 'a', 'utf-8') as outfile: for url in url_list: print 'Getting page %s ...' % url res = requests.get(url) if not res.ok: break doc = pq(res.content) images = doc('img') if not images: break for image in images: url = image.attrib.get('src') name = image.attrib.get('alt') img_file = download_file(url) obj, created = Entry.objects.get_or_create(name=name, image=File(img_file)) if created: outfile.write(url + '\n') print 'Done.' crawler.py Vamos a imaginar nuestro ‘crawler’ que utiliza urls y consigue las imágenes que allí se muestran. ! “Hipoteticamente” luciría como lo vemos aquí, pyquery es una librería que se instala por pypi y la podemos incluir así en nuestro proyecto, luego vamos a definir una lista de urls que quisiéramos analizar, esa lista puede ser estatica o podemos hacer un crawler para obtener las urls de forma automatica también, por lo pronto lo definimos manualmente a el home de la página de crepes y waffles. ! Luego vamos a abrir un archivo de log para llevar un registro del análisis que vamos a realizar, luego por cada url de nuestro listado de urls vamos a comenzar a obtener información. ! Utilizando la librería requests, también disponible desde pypi vamos a consultar la url con el método get, si la consulta no fue exitosa vamos a salirnos del ciclo, de lo contrario vamos a enviar el resultado de la consulta, básicamente el contenido html a pyquery el cual nos crea un objeto, llamado doc, al cual podemos hacer consultas con selectores como los utilizados en jquery para obtener elementos html que podemos utilizar en python, en este caso estamos utilizando el selector general ‘img’ para que nos traiga todos los elementos html creados con el tag ‘img’ eso lo estamos almacenando en la variable images, si no hay imágenes nos salimos del ciclo, pero si hay vamos a ir por cada una de ellas y vamos a obtener los atributos del origen de la imagen y el nombre, con esa información vamos a llamar a nuestro metodo download_file al cual enviamos la url, y en un momento veremos en detalle, el
r = requests.get(url, stream=True) with open(local_filename, 'wb') as f: for chunk in r.iter_content(chunk_size=1024): if chunk: # filter out keep-alive new chunks f.write(chunk) f.flush() return local_filename crawler.py Aquí podemos ver el código necesario para descargar una imagen desde una url, utiliza también la librería requests, con la precaución de utilizar el parámetro stream para evitar problemas de memoria y la vamos a almacenar en nuestro sistema local de archivos. ! Como pueden ver requests es una excelente librería, supremamente útil para lidiar con páginas web, y por supuesto pyquery nos va a hacer la vida más fácil cuando buscamos analizar un documento HTML. ! Esto puede ser automatizado, pero no quiere decir que sea rápido, a pesar que tengamos librerías rápidas y algoritmos sencillos, hacer peticiones a páginas externas puede tomar un tiempo, luego hay que descargar las imágenes y posiblemente cargarlas a amazon S3, esto puede tomar bastante tiempo, por esa razón vamos a utilizar tareas asíncronas para hacer esto mejor.
torta con trozos de banano con caramelo, con una capa de crema chantilly acompañado de una bola de helado. ! Esta librería nos permite crear y administrar tareas asíncronas para que sean ejecutadas en segundo plano por nuestro proyecto django. Esta disponible por medio de Pypi, y requiere que configuremos un procesador de colas, algunos tal vez hayan escuchado sobre beanstalk, rabbitMQ y otros que son pesados en consumo de recursos y generalmente utilizados en procesos bancarios o de sistemas muy complicados, sin embargo redis es tan bueno que también nos sirve para procesar colas de procesos y aprovechando que lo hemos configurado previamente vamos a utilizarlo con celery. ! De verdad que se ve muy rico, cierto?
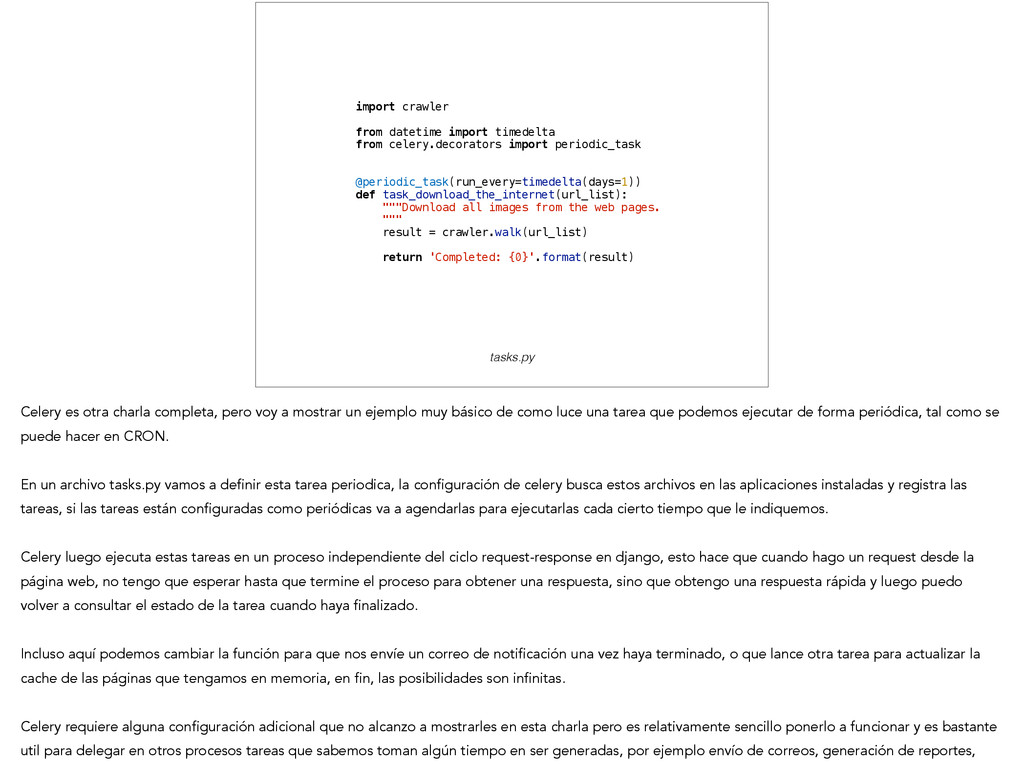
periodic_task ! ! @periodic_task(run_every=timedelta(days=1)) def task_download_the_internet(url_list): """Download all images from the web pages. """ result = crawler.walk(url_list) ! return 'Completed: {0}'.format(result) ! tasks.py Celery es otra charla completa, pero voy a mostrar un ejemplo muy básico de como luce una tarea que podemos ejecutar de forma periódica, tal como se puede hacer en CRON. ! En un archivo tasks.py vamos a definir esta tarea periodica, la configuración de celery busca estos archivos en las aplicaciones instaladas y registra las tareas, si las tareas están configuradas como periódicas va a agendarlas para ejecutarlas cada cierto tiempo que le indiquemos. ! Celery luego ejecuta estas tareas en un proceso independiente del ciclo request-response en django, esto hace que cuando hago un request desde la página web, no tengo que esperar hasta que termine el proceso para obtener una respuesta, sino que obtengo una respuesta rápida y luego puedo volver a consultar el estado de la tarea cuando haya finalizado. ! Incluso aquí podemos cambiar la función para que nos envíe un correo de notificación una vez haya terminado, o que lance otra tarea para actualizar la cache de las páginas que tengamos en memoria, en fin, las posibilidades son infinitas. ! Celery requiere alguna configuración adicional que no alcanzo a mostrarles en esta charla pero es relativamente sencillo ponerlo a funcionar y es bastante util para delegar en otros procesos tareas que sabemos toman algún tiempo en ser generadas, por ejemplo envío de correos, generación de reportes,
para facilitar su conexión con otras plataformas, uno de los casos más comunes hoy día es la creación de aplicaciones nativas cliente en iOS y android, que sean muy sencillas y que consuman un API del contenido que desean mostrar, esto además de reducir los costos para llegar a todas las plataformas hace mucho más extensible y predecible el crecimiento de la plataforma. ! Realizar la arquitectura de un API es un proceso que requiere de trabajo formal y mucha planeación, el cual puede ser decisivo frente a que otras plataformas puedan consumir información de nuestro portal o incluso colaborando enviándonos contenidos. ! En esta época en la que el contenido es el rey, se debe buscar llegar a tantos usuarios sea posible y facilitar que puedan generar contenidos de calidad y que rápidamente se puedan hacer disponibles para toda la red de usuarios en la misma plataforma. ! Por tal razón se hace necesario contar con un API en nuestra plataforma de #foodporn donde podamos facilitar a los usuarios agregar sus propios contenidos, compartirlos en redes sociales, geolocalizarlos, etc. ! Vamos a ver un ejemplo muy sencillo de como luce una declaración de API, para más detalles pueden ver charlas pasadas del meetup de Django Bogotá que han explicado el tema en detalle.
class EntrySerializer(serializers.HyperlinkedModelSerializer): class Meta: model = Entry fields = ('name', 'image') ! serializers.py Vamos a utilizar django-rest-framework, aunque si quieren pueden utilizar otras librerías o incluso hacerlo manualmente. ! Rápidamente podemos iniciarnos con django rest framework creando un serializador que luce así, donde definimos el modelo que vamos a utilizar y los campos que queremos habilitar, podemos ver que no estamos utilizando todos los campos, si quisiéramos pueden ser más campos, pero por lo pronto vamos a hacer sencillo el ejemplo.
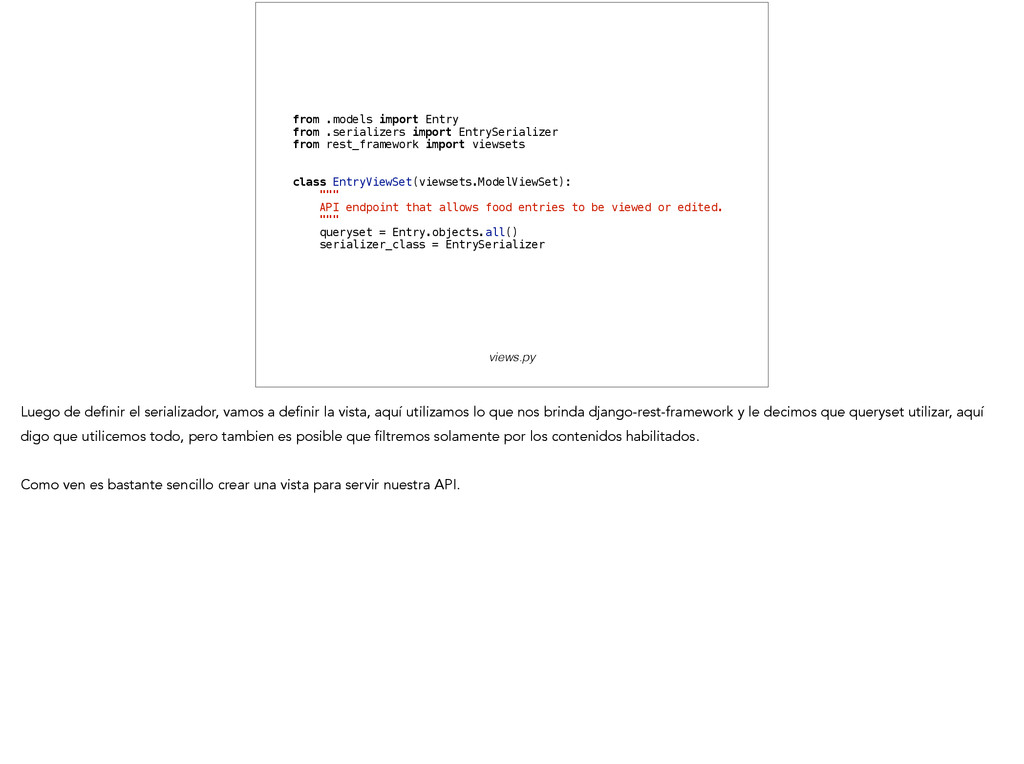
import viewsets ! ! class EntryViewSet(viewsets.ModelViewSet): """ API endpoint that allows food entries to be viewed or edited. """ queryset = Entry.objects.all() serializer_class = EntrySerializer ! views.py Luego de definir el serializador, vamos a definir la vista, aquí utilizamos lo que nos brinda django-rest-framework y le decimos que queryset utilizar, aquí digo que utilicemos todo, pero tambien es posible que filtremos solamente por los contenidos habilitados. ! Como ven es bastante sencillo crear una vista para servir nuestra API.
.views import EntryViewSet ! router = routers.DefaultRouter() router.register(r'entries', EntryViewSet) ! # Wire up our API using automatic URL routing. # Additionally, we include login URLs for the browseable API. urlpatterns = [ url(r'^', include(router.urls)), url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework')) ] ! urls.py Por ultimo debemos hacerla accesible por medio de URLs, aquí registramos nuestra vista y dejamos que django-rest-framework se encargue del resto. ! Lo que se puede ofrecer por medio de APIs puede ser bastante útil siempre y cuando tengamos personas interesadas en utilizarlo, por ejemplo en proyectos que hemos realizado como apps.co y copnia.gov.co tenemos APIs disponibles para que otros proyectos o personas puedan consultar información de manera rápida y confiable, si alguno quiere proponer información para consultar de esas dos plataformas estamos atentos a escuchar, tal vez alguien quiera hacer alguna aplicación móvil que consulte si un profesional se encuentra sancionado legalmente, o alguien quiera hacer un crunchbase con toda la información de emprendimientos en Colombia.
las posibilidades es que dentro del contenido nosotros agreguemos al azar algunas imágenes patrocinadas, por ejemplo de algún restaurante, y los usuarios las puedan ver cada cierto tiempo. Para lograr esto solamente tenemos que habilitar en nuestro proyecto la carga manual de imágenes, con esto se puede lograr generar un impacto que nos puede llevar de comer empanada con colombiana, a comer caviar con champaña. ! Si logran hacer que alguien les pague un peso por cada vez que se imprime un anuncio, y resultan teniendo 300mil visitas al día, están fácilmente generando unos 7 millones de pesos al mes, o posiblemente unos 100 millones de pesos en el año. ! ¿Quien dijo que el porno no paga?
es uno de los resultados de la estimulación visual de estos sitios, y es la razón principal de su popularidad y viralidad. El foodporn es un tema realmente serio en Japón. ! Tanta ansiedad por comer por ejemplo llevo a este personaje a morder hasta lograr entrar en la caja, comer todo lo que pudo, tanto, que luego no logró moverse para salir, lo encontraron así al día siguiente, claramente sin arrepentirse de nada de lo que hizo. ! Se que el titulo de la charla fue algo llamativo, pero no me arrepiento tampoco de nada, espero hayan disfrutado tanto de esta charla que se animen a construir proyectos que inspiren a otros y que puedan llamar la atención por si mismos sin tener que recurrir a titulares amarillistas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def download_file(url): local_filename = url.split('/')[-1] # NOTE the stream=True parameter](https://files.speakerdeck.com/presentations/b852b53016c401321030426a91aead3e/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}