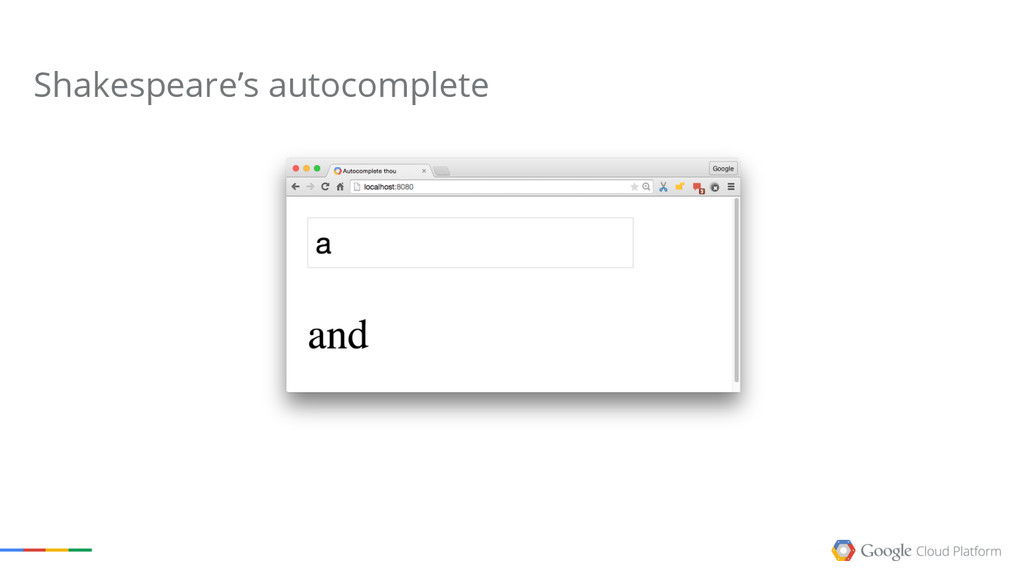
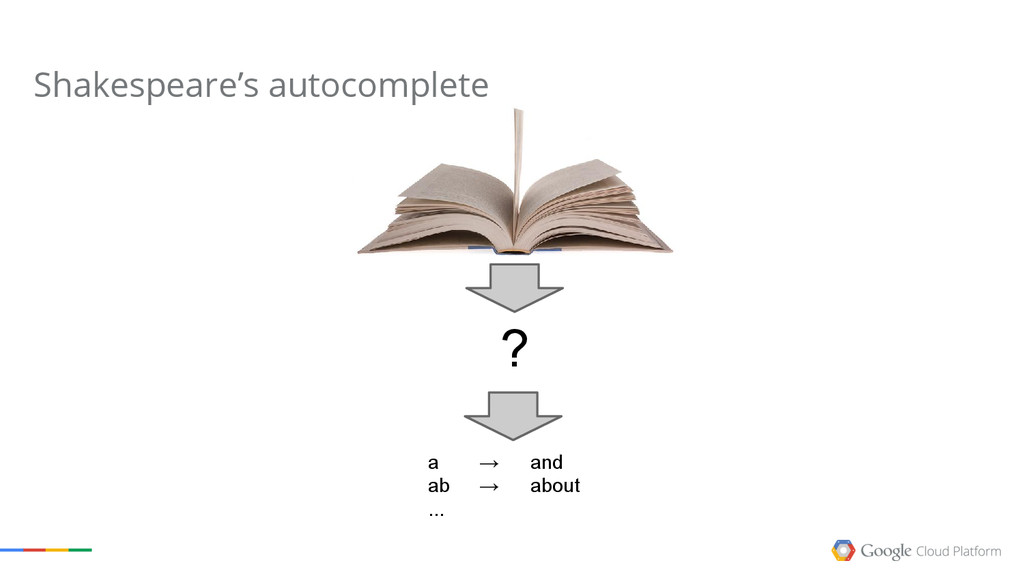
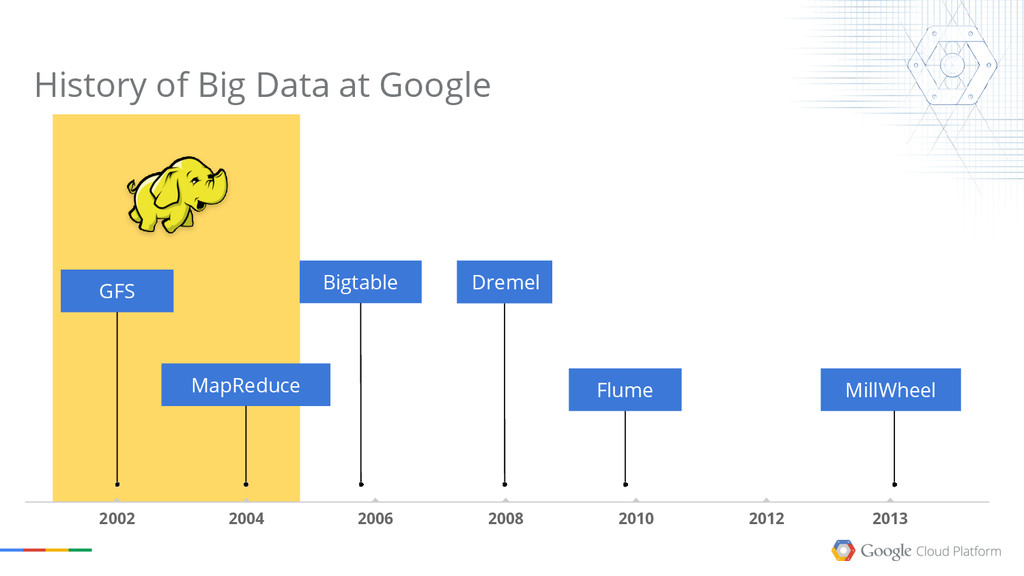
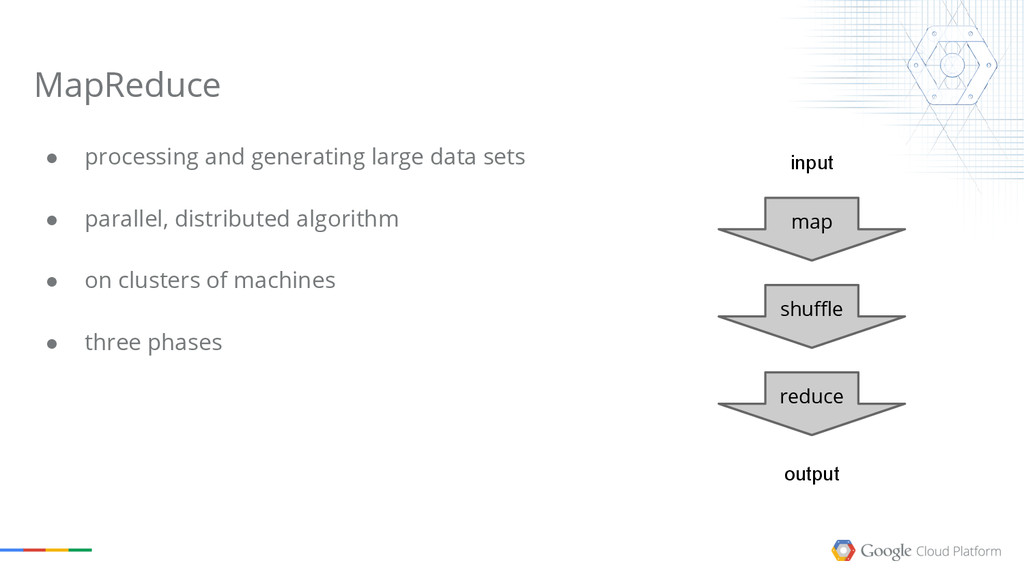
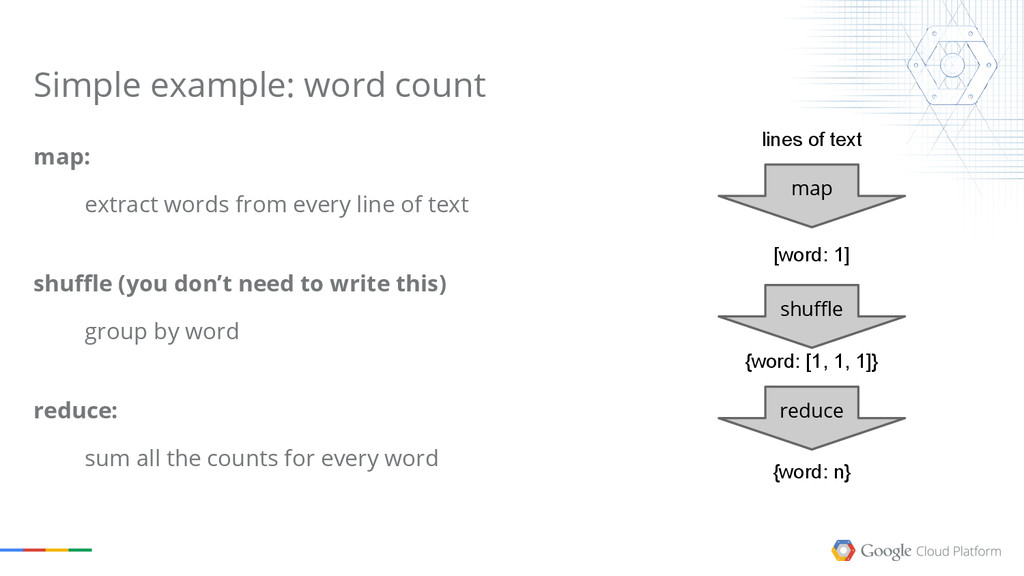
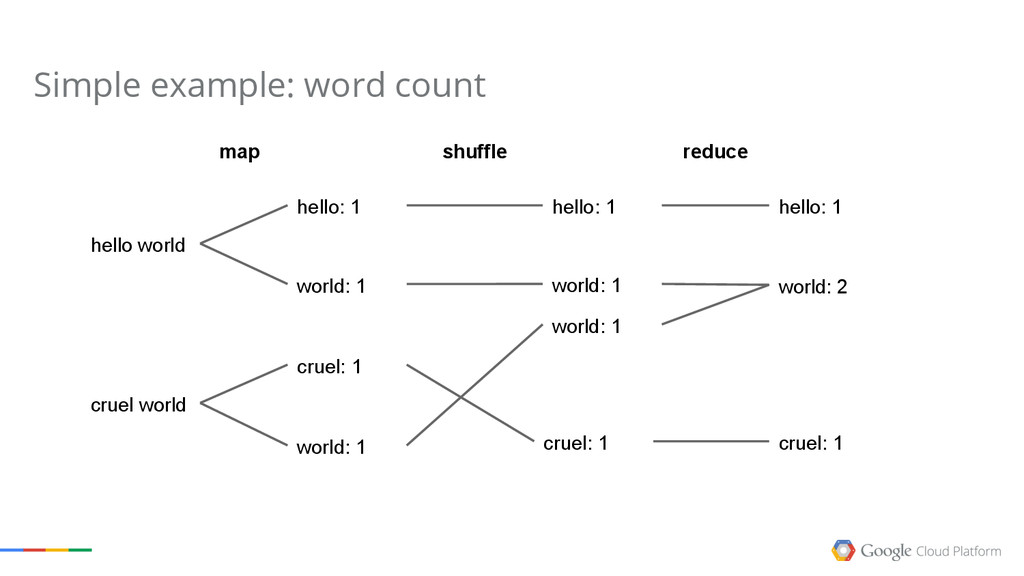
The talk explains what Google Cloud Dataflow, one of the latest released products of the Google Cloud Platform. Dataflow is the result of many years of research on data processing models done internally at Google,and it has the power to revolutionize how you process your own data now.
We will cover the basics of MapReduce, then point out some of the limitations of the model, and show how Dataflow solves most of them.
The goal of the session is to give you an understanding of the possibilities the Google Cloud Platform offers in terms of Big Data processing. Google has been doing this for more than a decade, and we want everyone to share the experience.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
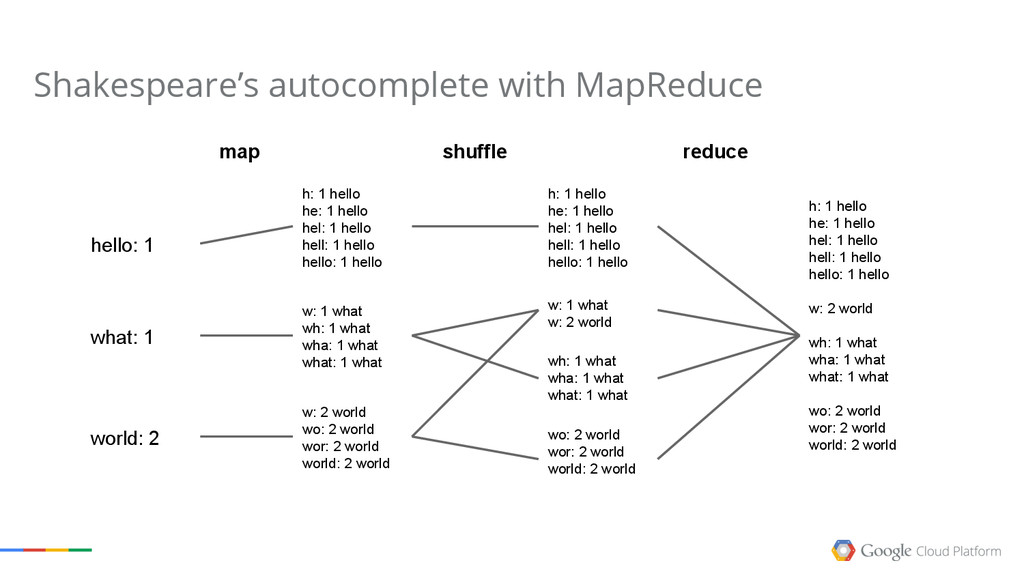{kind=link}
{kind=link}
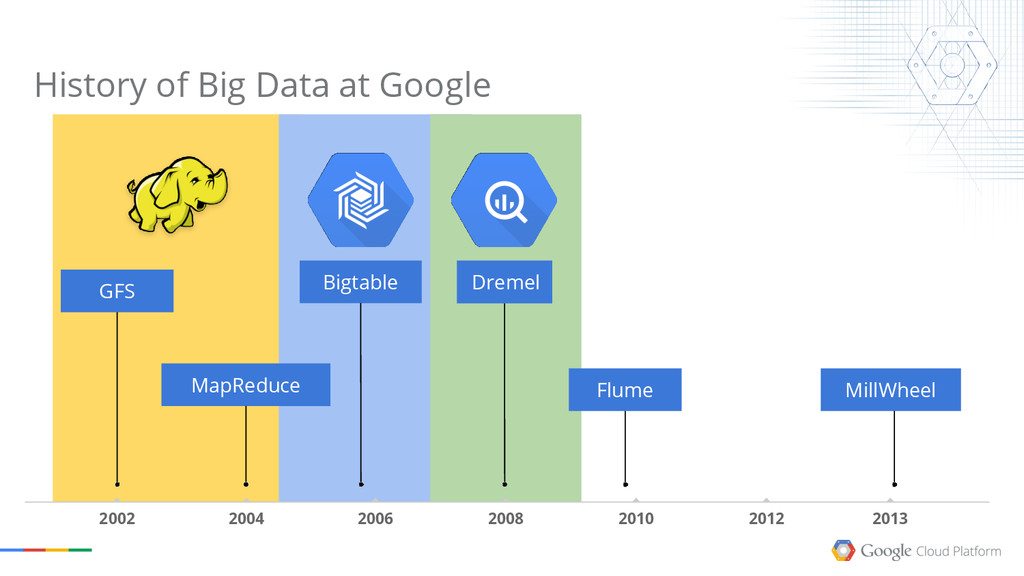{kind=link}
{kind=link}
{kind=link}
![SELECT SPLIT( REGEXP_REPLACE(line, '[^a-z^A-Z]*([a-zA-Z]+)[^a-z^A-Z]*', '\\1|'), '|') word FROM [shakespeare.lines] Word](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_18.jpg){kind=link}
![SELECT word FROM ( SELECT SPLIT( REGEXP_REPLACE(line, '[^a-z^A-Z]*([a-zA-Z]+)[^a-z^A-Z]*', '\\1|'), '|')](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
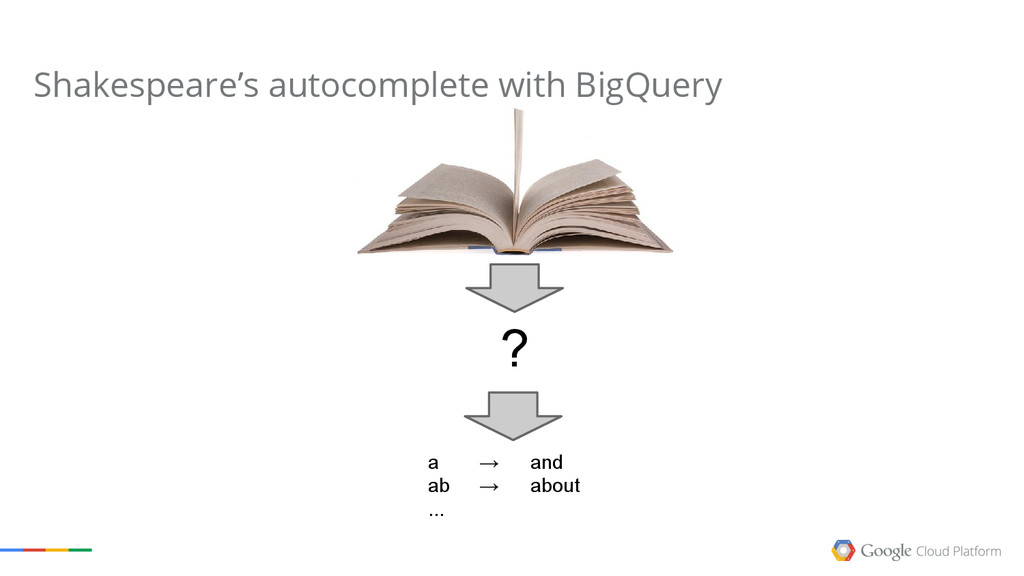{kind=link}
{kind=link}
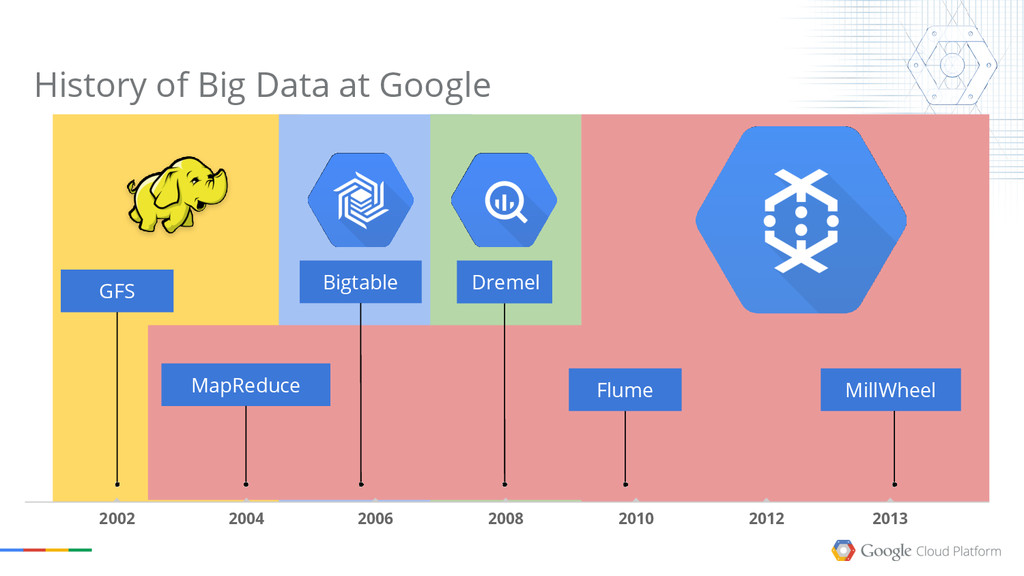{kind=link}
{kind=link}
{kind=link}
![MapReduce primitives map input output <key, value> <key, value[]> shuffle](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_28.jpg){kind=link}
![Cloud Dataflow primitives parallelDo input output <key, value> <key, value[]>](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_29.jpg){kind=link}
{kind=link}
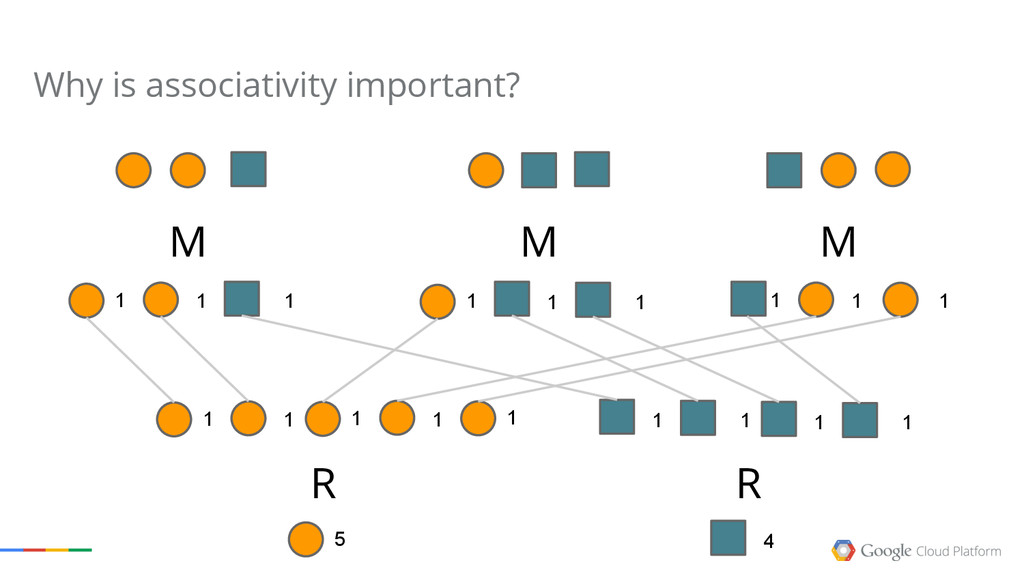{kind=link}
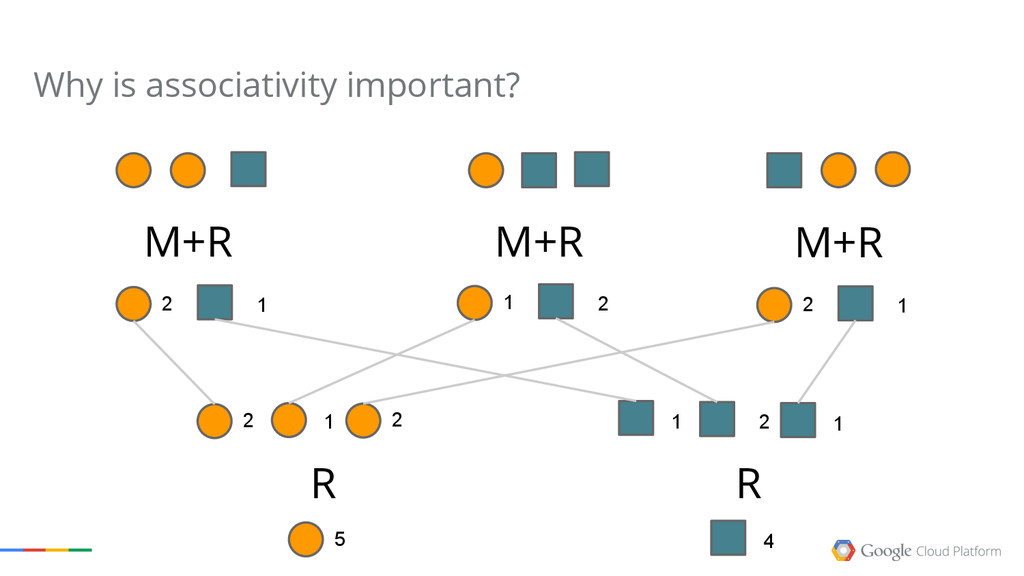{kind=link}
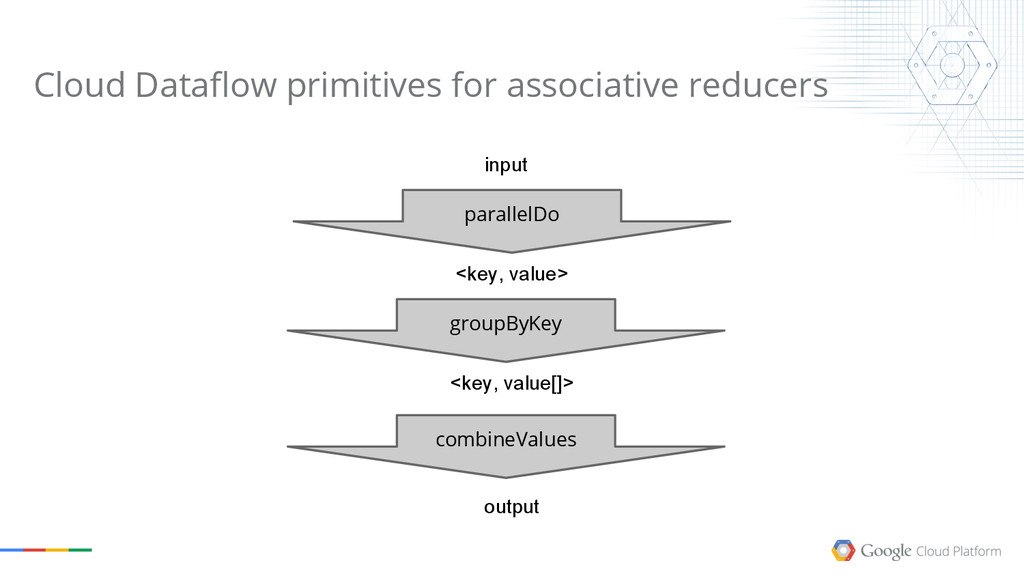{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![flatten in: Collection<PCollection<T>> out: PCollection<T> example: in: {[“hello”, 1], [“world”,](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
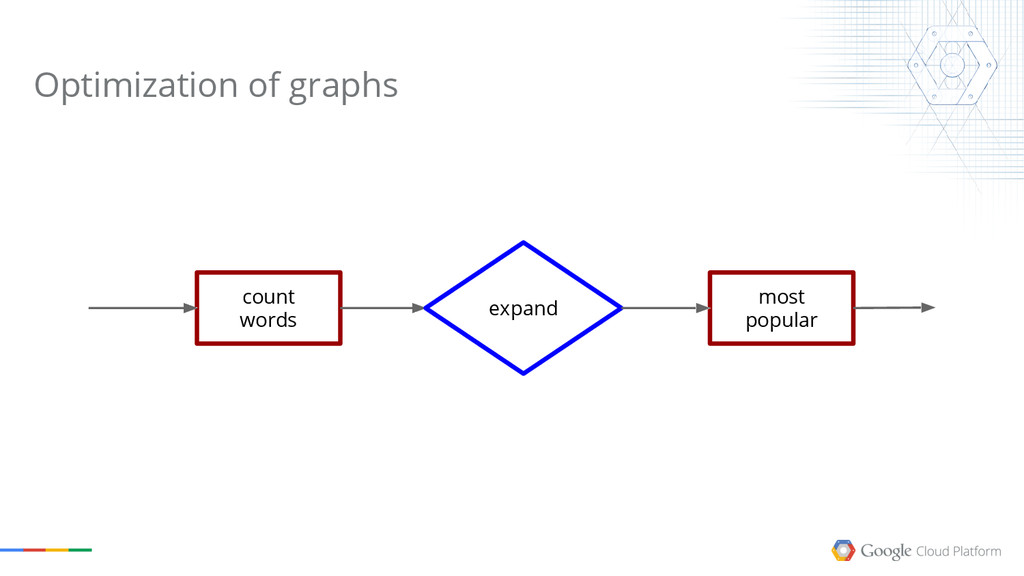{kind=link}
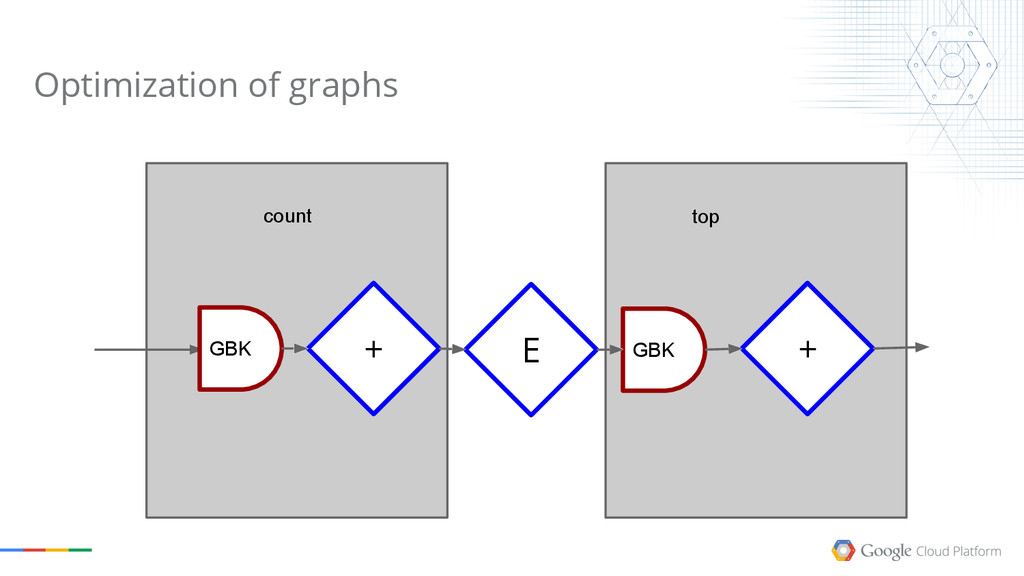{kind=link}
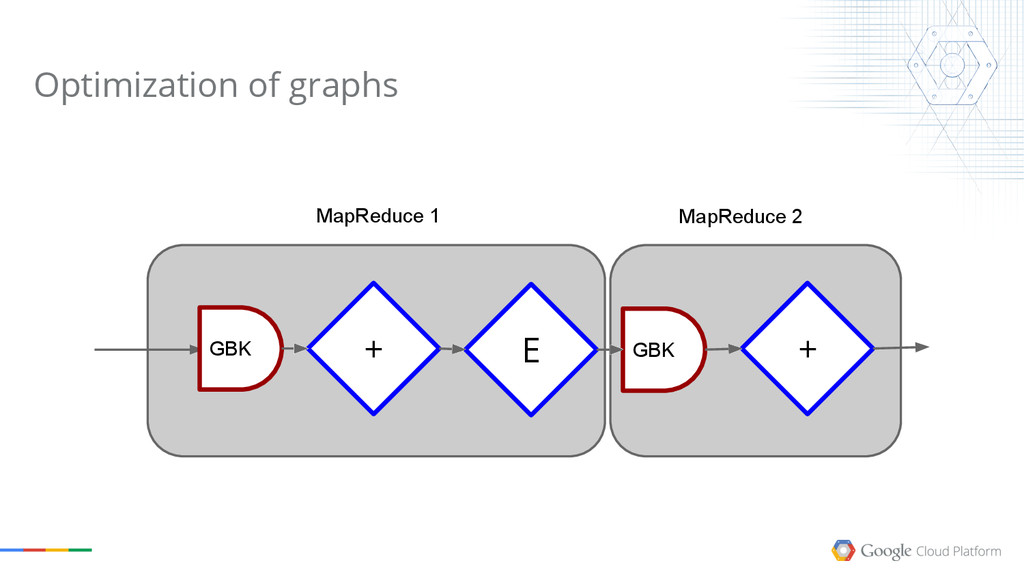{kind=link}
{kind=link}
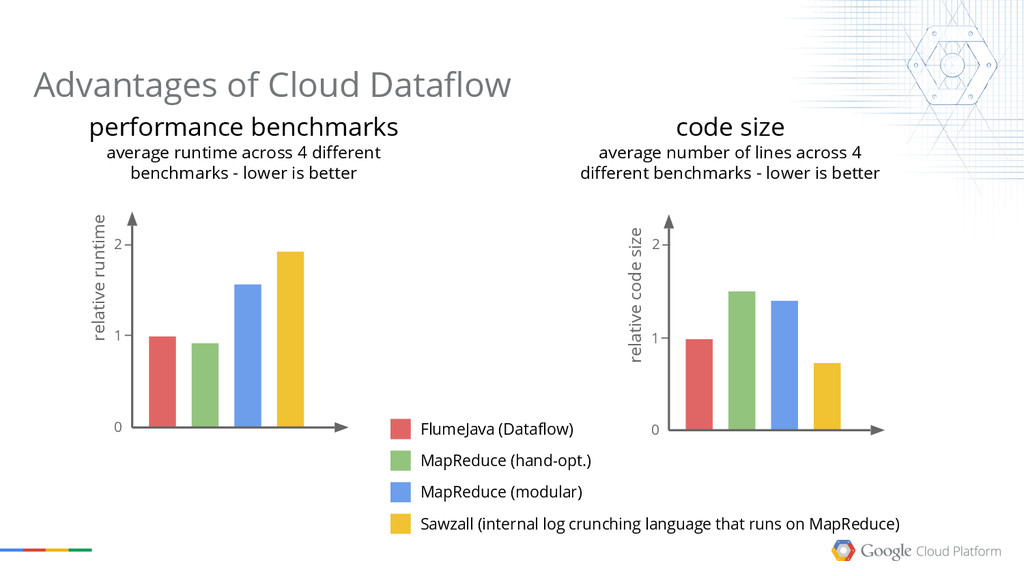{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@francesc google.com/+FrancescCampoyFlores [email protected] Thanks!](https://files.speakerdeck.com/presentations/e6aa53432f2d40f4a002c607c17be4e9/slide_56.jpg){kind=link}