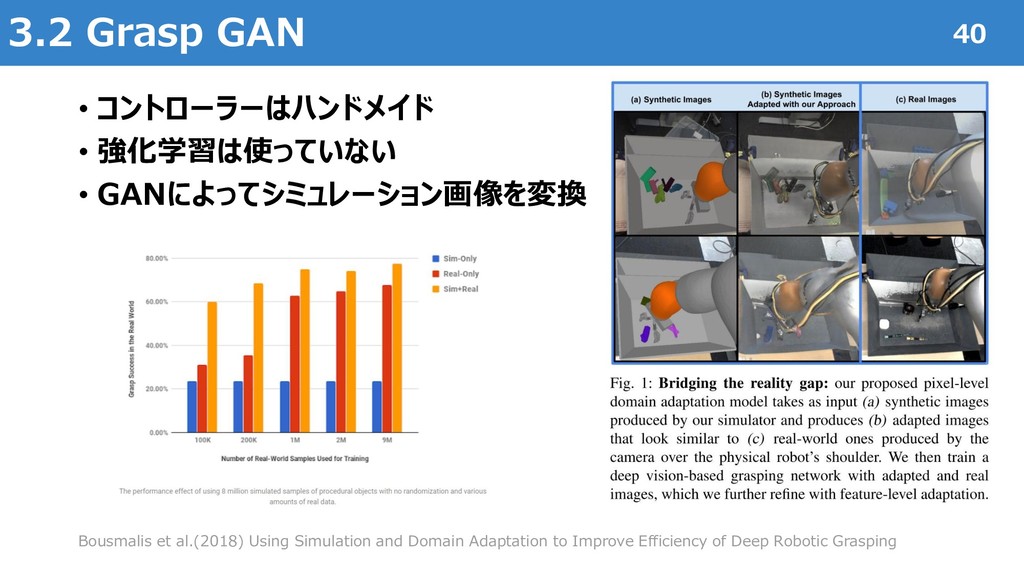
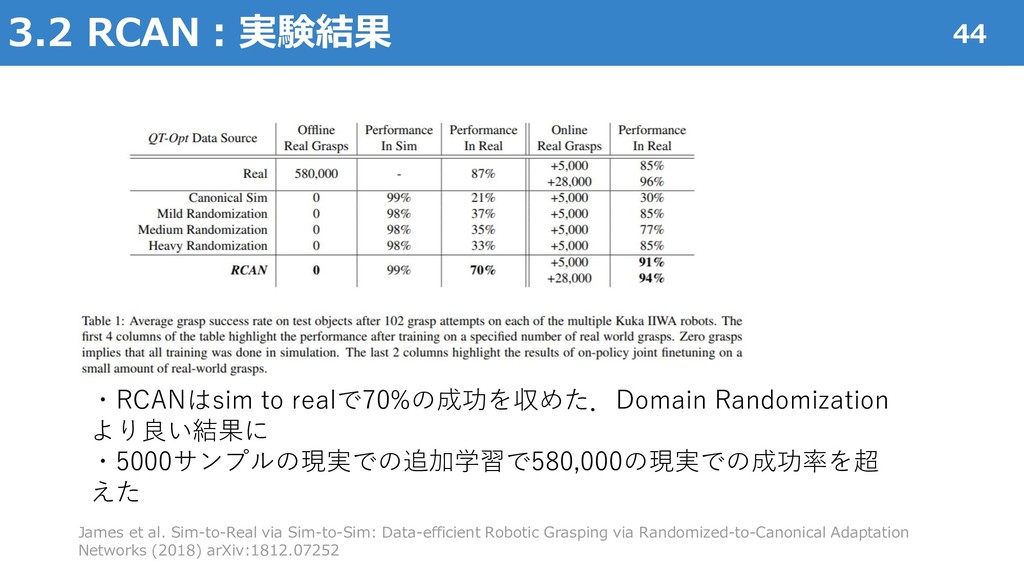
A Model-Based and Data-Efficient Approach to Policy Search" International Conference on Machine Learning (ICML), 2011 Marc Peter Deisenroth, Carl Edward Rasmussen and Dieter Fox "Learning to Control a Low-Cost Manipulator Using Data-Efficient Reinforcement Learning " Robotics: Science and Systems (RSS), 2011 Sergey Levine, Chelsea Finn, Trevor Darrell, Pieter Abbeel. "End-to-End Training of Deep Visuomotor Policies" Journal of Machine Learning Research (JMLR) 17, 2016 Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, Sergey Levine "Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations" Robotics: Science and Systems (RSS), 2017 Chelsea Finn, Xin Yu Tan, Yan Duan, Trevor Darrell, Sergey Levine, Pieter Abbeel "Deep Spatial Autoencoders for Visuomotor Learning" IEEE International Conference on Robotics and Automation (ICRA), 2016 Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, Sergey Levine "Soft Actor-Critic Algorithms and Applications" arXiv:1812.05905, 2018 OpenAI, Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob McGrew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, Jonas Schneider, Szymon Sidor, Josh Tobin, Peter Welinder, Lilian Weng, Wojciech Zaremba "Learning Dexterous In-Hand Manipulation", arXiv:1808.00177, 2018 Konstantinos Bousmalis, Alex Irpan, Paul Wohlhart, Yunfei Bai, Matthew Kelcey, Mrinal Kalakrishnan, Laura Downs, Julian Ibarz, Peter Pastor, Kurt Konolige, Sergey Levine, Vincent Vanhoucke "Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping" IEEE International Conference on Robotics and Automation (ICRA), 2018 Stephen James, Paul Wohlhart, Mrinal Kalakrishnan, Dmitry Kalashnikov, Alex Irpan, Julian Ibarz, Sergey Levine, Raia Hadsell, Konstantinos Bousmalis "Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks" arXiv:1812.07252, 2018 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
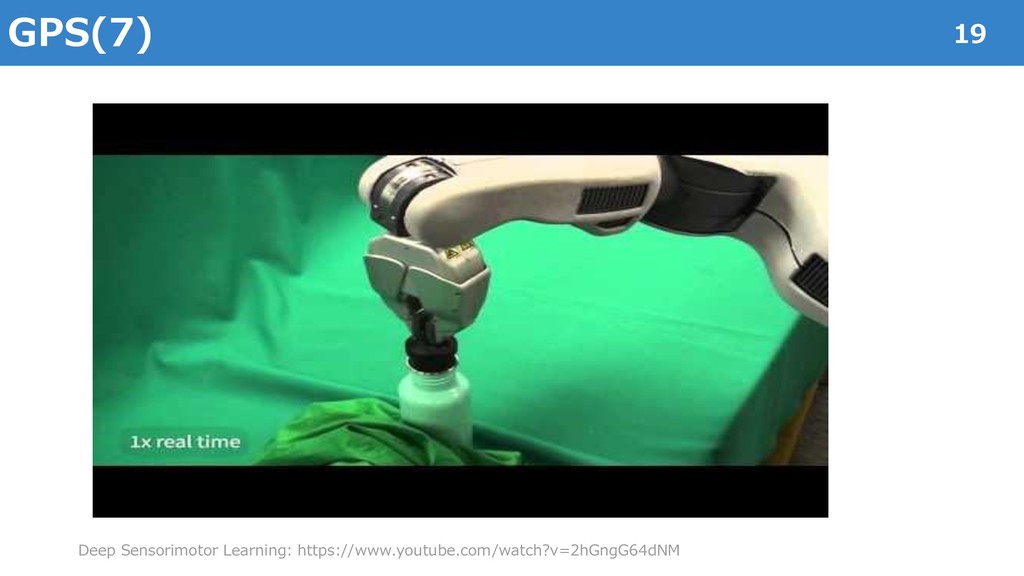{kind=link}
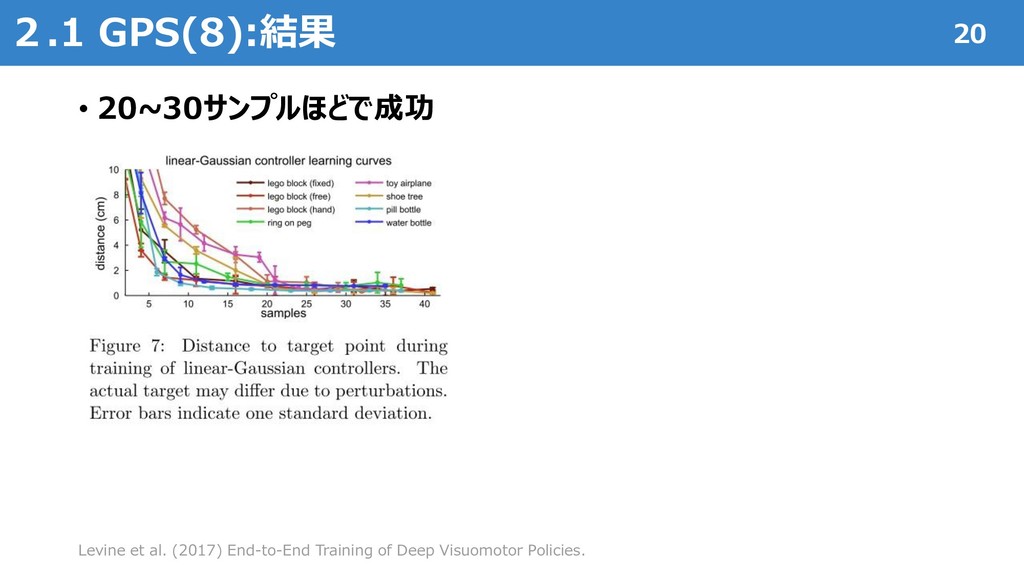{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
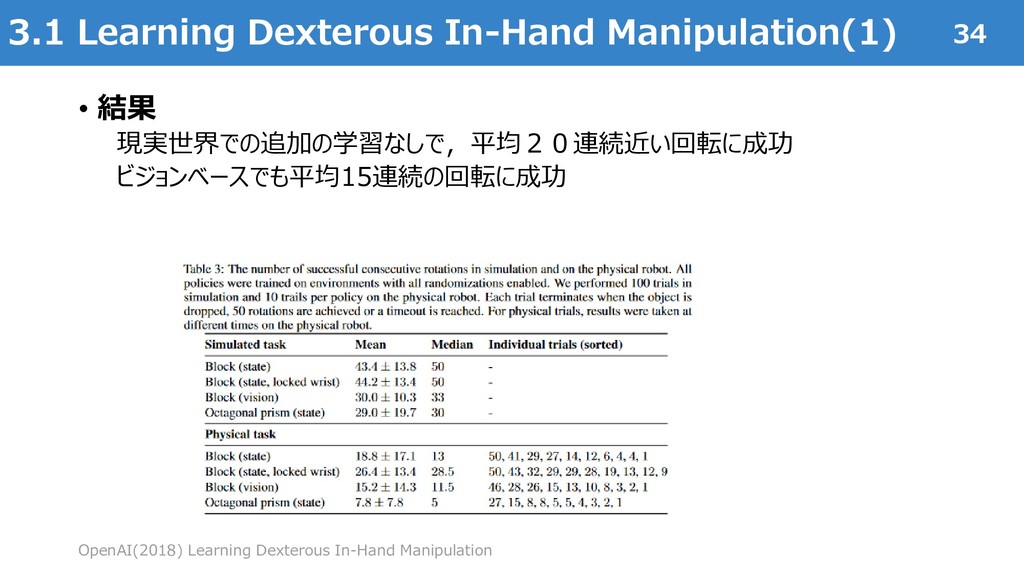{kind=link}
{kind=link}
{kind=link}
{kind=link}
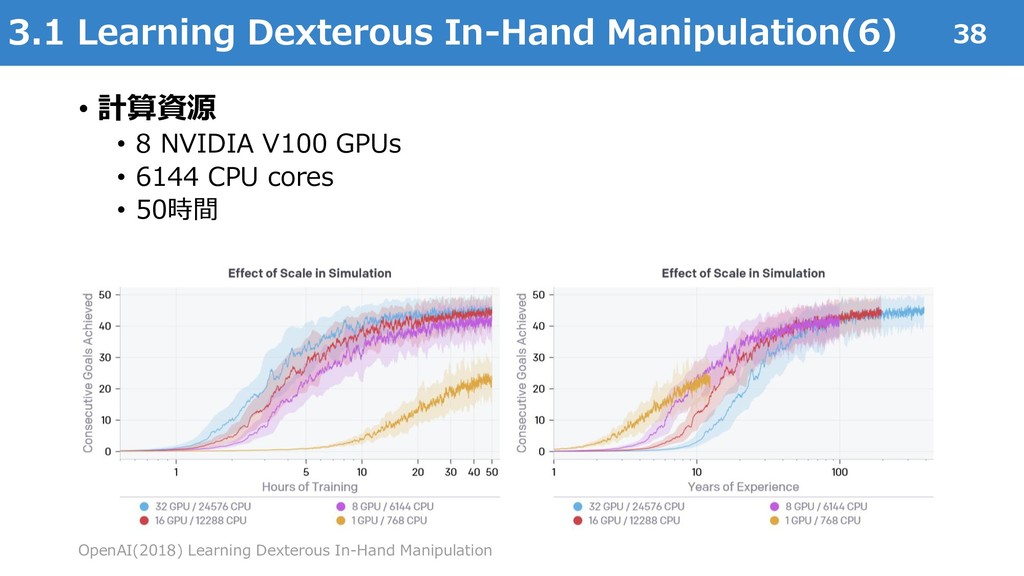{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}