Apresentação realizada no meetup SouJava.
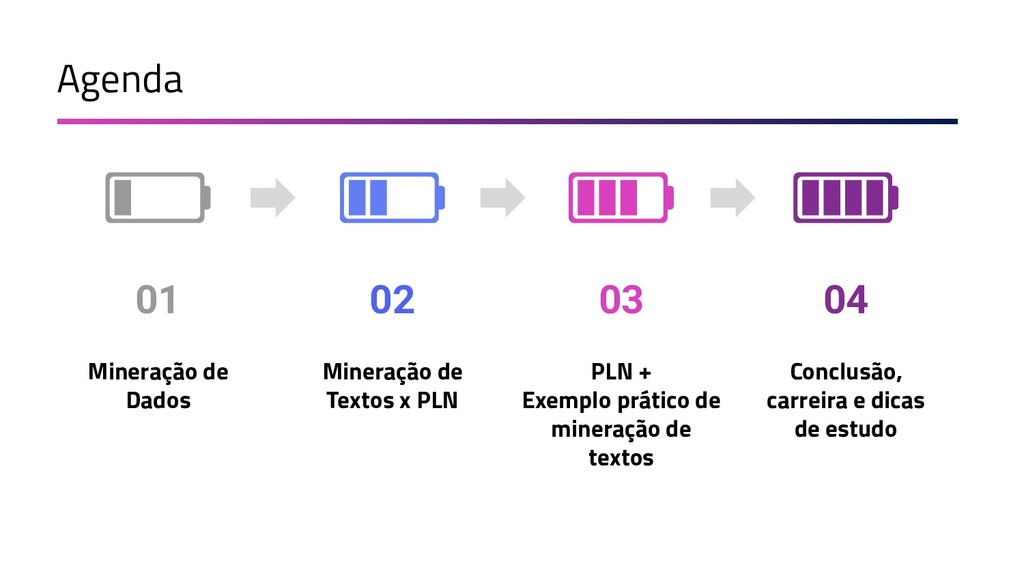
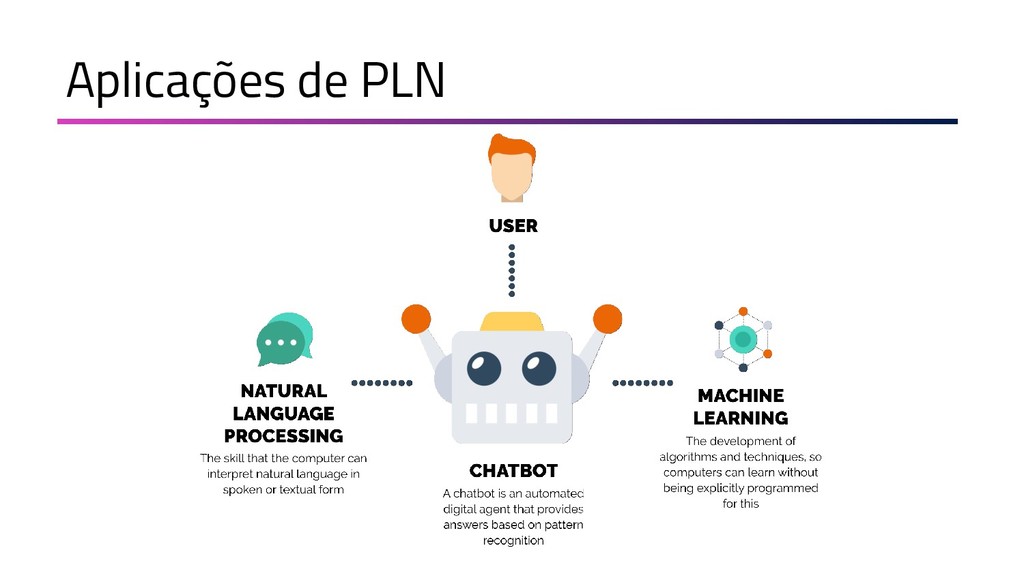
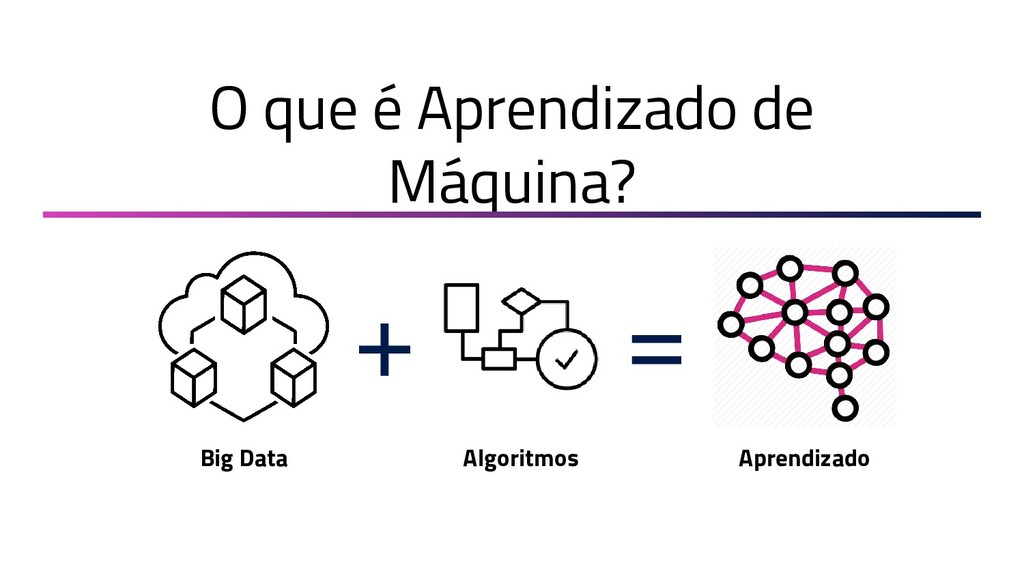
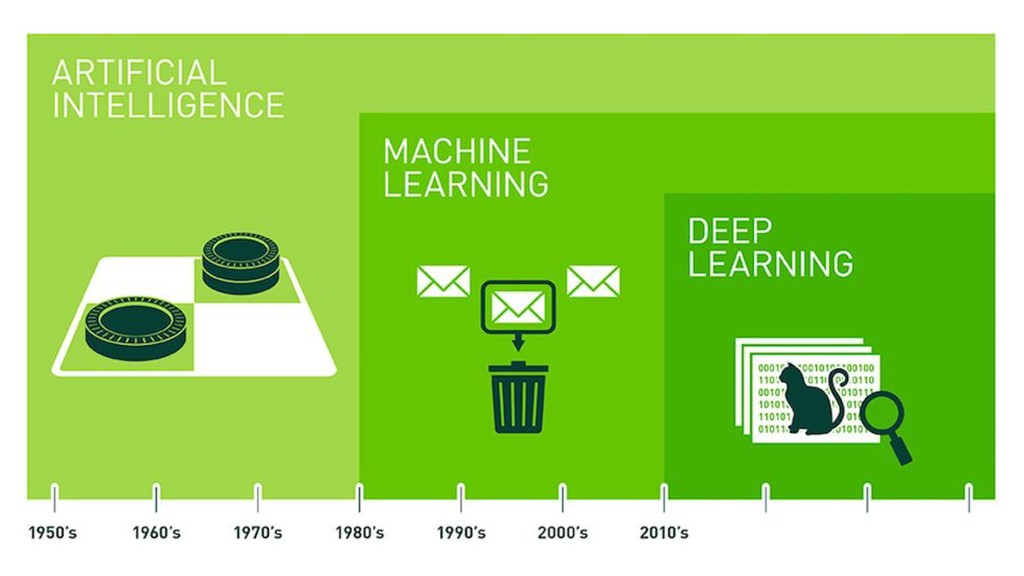
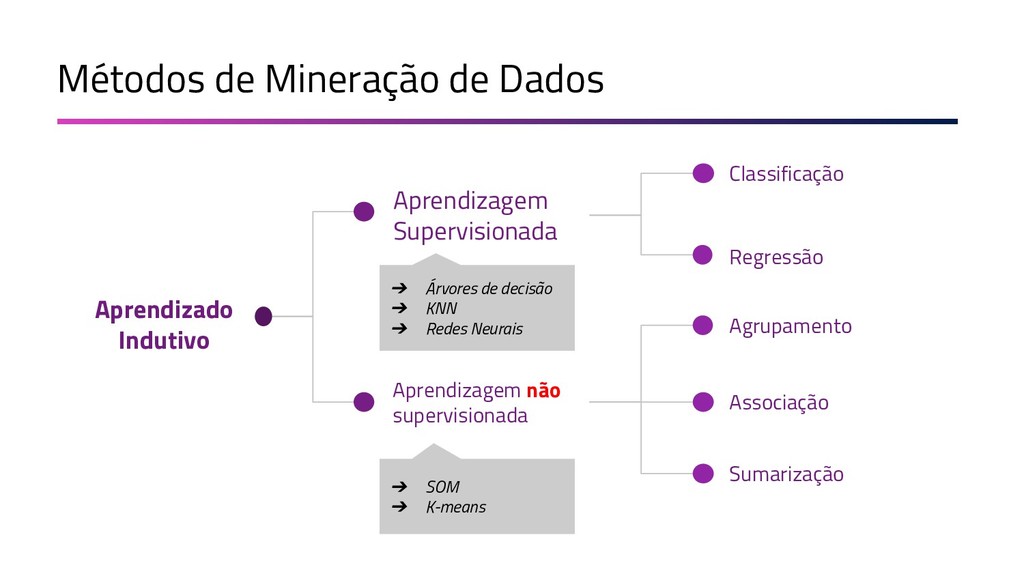
A Mineração de Textos é uma das subáreas da Inteligência Artificial que tem como objetivo extrair padrões e conhecimento útil em textos. Para isso, utilizamos uma série de técnicas de Processamento de Linguagem Natural (PLN). O objetivo do PLN é fornecer aos computadores a capacidade de entender esses textos, criar resumos, extrair informações, analisar sentimentos e até aprender conceitos com os textos processados. Essa palestra apresenta uma visão geral sobre as técnicas de aprendizado de máquina, PLN e como podem ser utilizadas em ambientes de mineração de dados. Toda a apresentação será baseada em exemplos práticos e ao final será mostrado um case real, em que aplicamos técnicas de machine learning e PLN para minerar notícias de jornal da BBC utilizando Java.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigada! Carla Vieira [email protected] | @carlaprvieira bit.ly/soujava-carla-slides bit.ly/soujava-carla (feedback)](https://files.speakerdeck.com/presentations/7d78a11f559e491b8bd0a837d483d99b/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}