Model Carlisle Rainey Assistant Professor Texas A&M University Daniel K. Baissa Ph.D. Student Harvard University Paper, code, and data at carlislerainey.com/research
is the Gauss-Markov theorem, which proves that when the assumptions are met, the least squares estimators of regression parameters are unbiased and efficient.”
{kind=link}
{kind=link}
{kind=link}
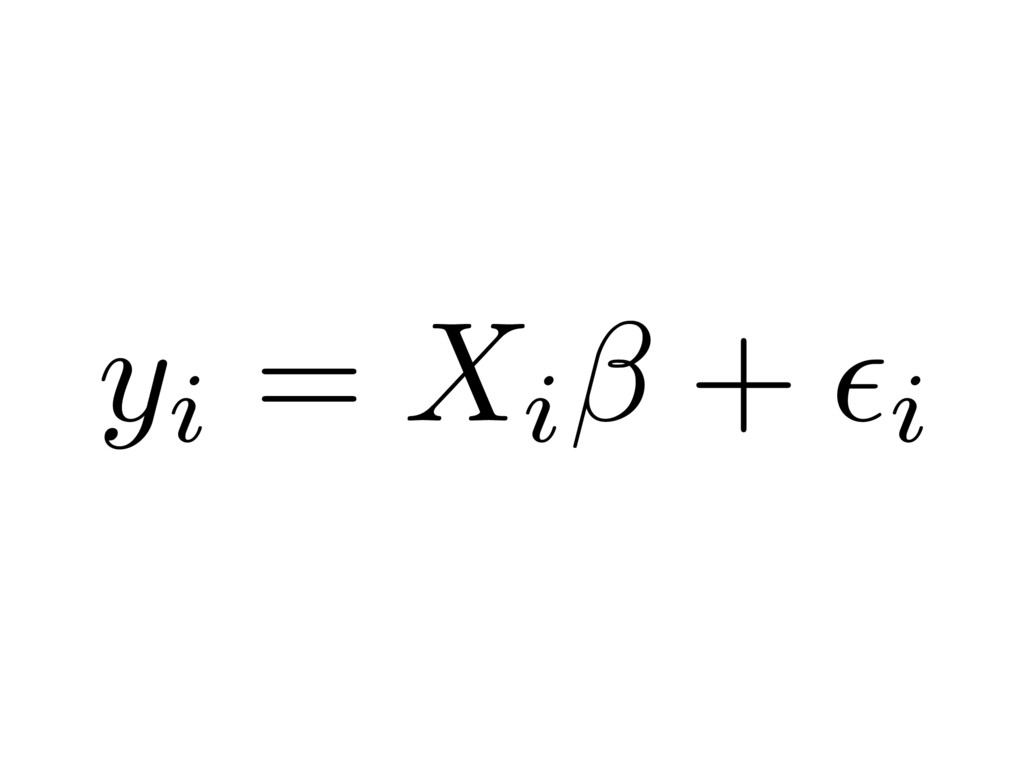{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
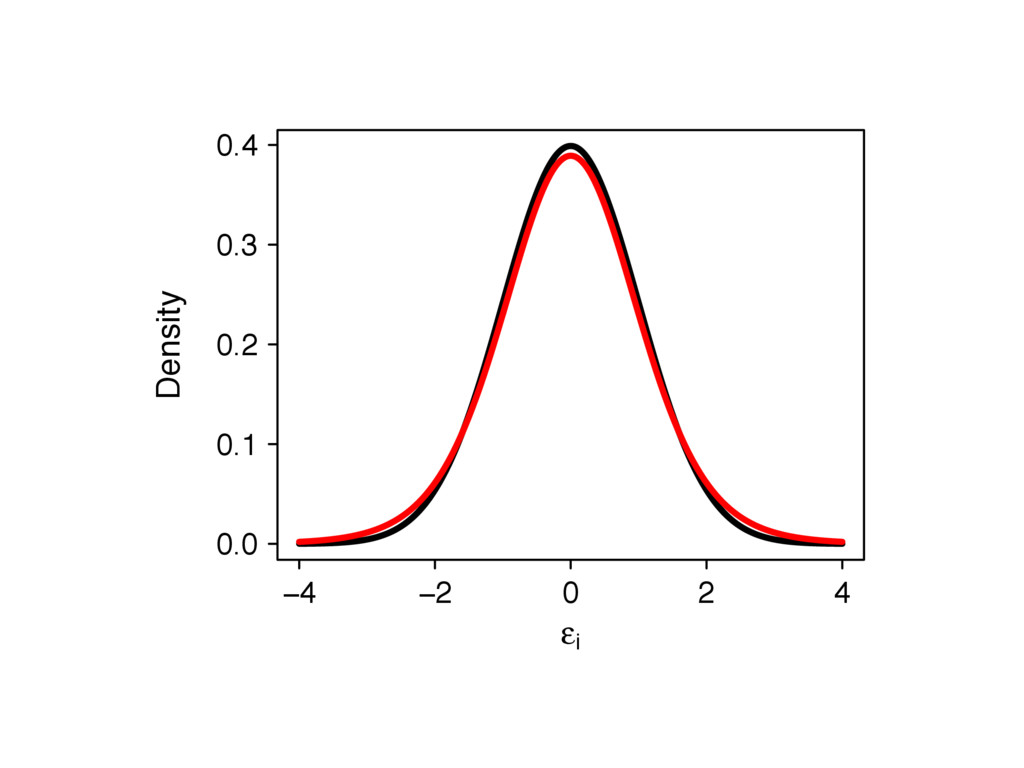{kind=link}
{kind=link}
![–Berry (1993) “[Even without normally distributed errors] OLS coefficient estimators](https://files.speakerdeck.com/presentations/b058a64986c3494997965a4c1cb5175b/slide_17.jpg){kind=link}
![–Wooldridge (2013) “[The Gauss-Markov theorem] justifies the use of the](https://files.speakerdeck.com/presentations/b058a64986c3494997965a4c1cb5175b/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
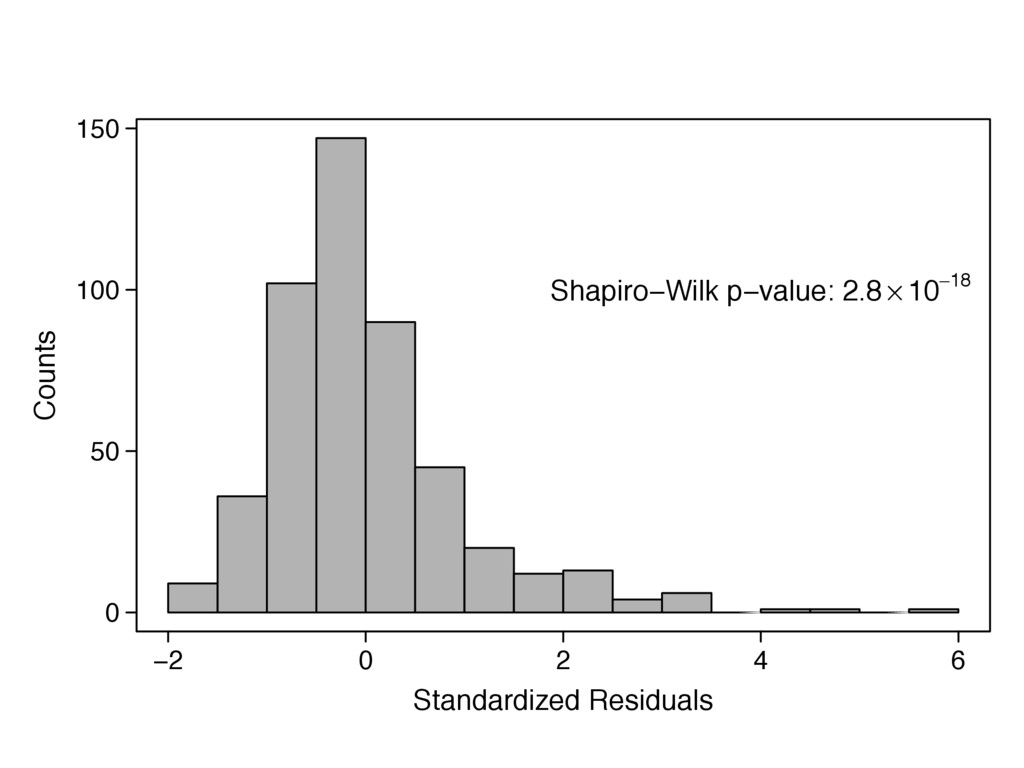{kind=link}
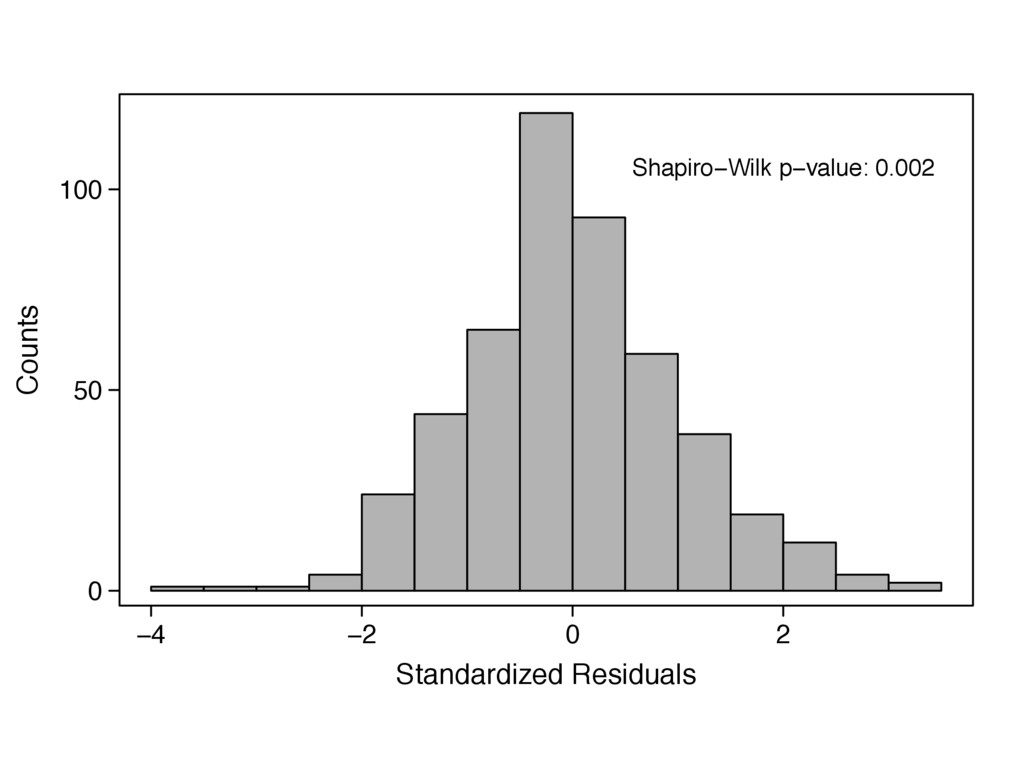{kind=link}
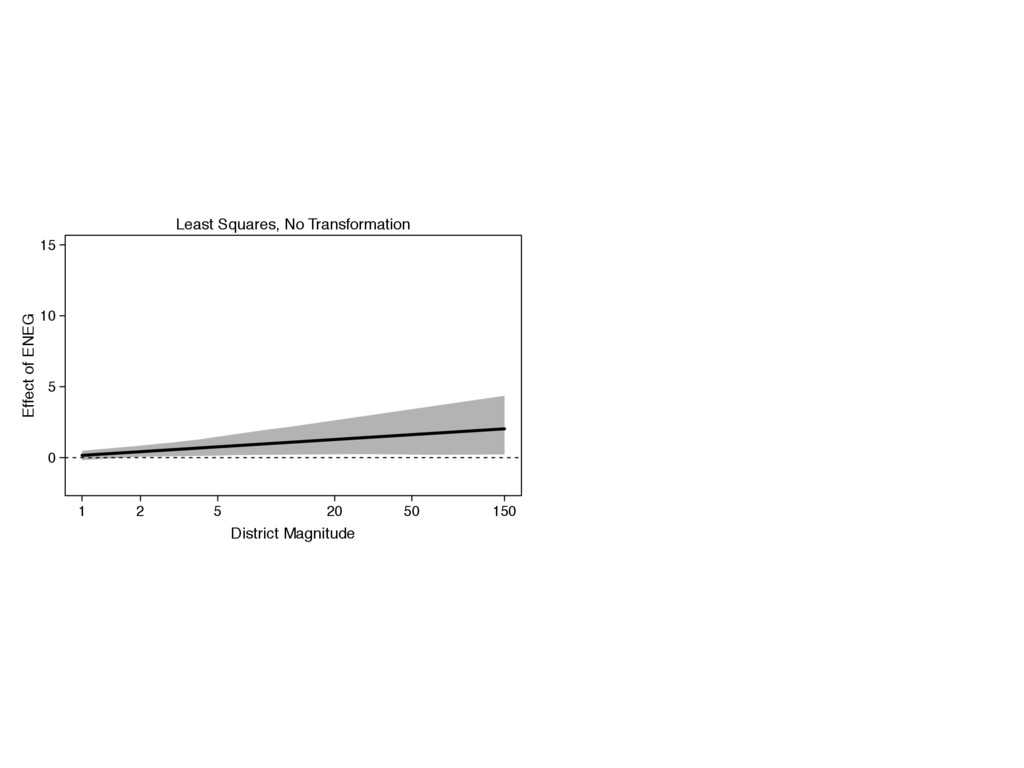{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}