Scott Clifford Associate Professor University of Houston [email protected] Thomas Leeper Senior Visiting Fellow London School of Economics [email protected] http://www.carlislerainey.com/talk Slides and papers at How to Generalize from Particular Experiments to a Larger Collection of Possible Experiments
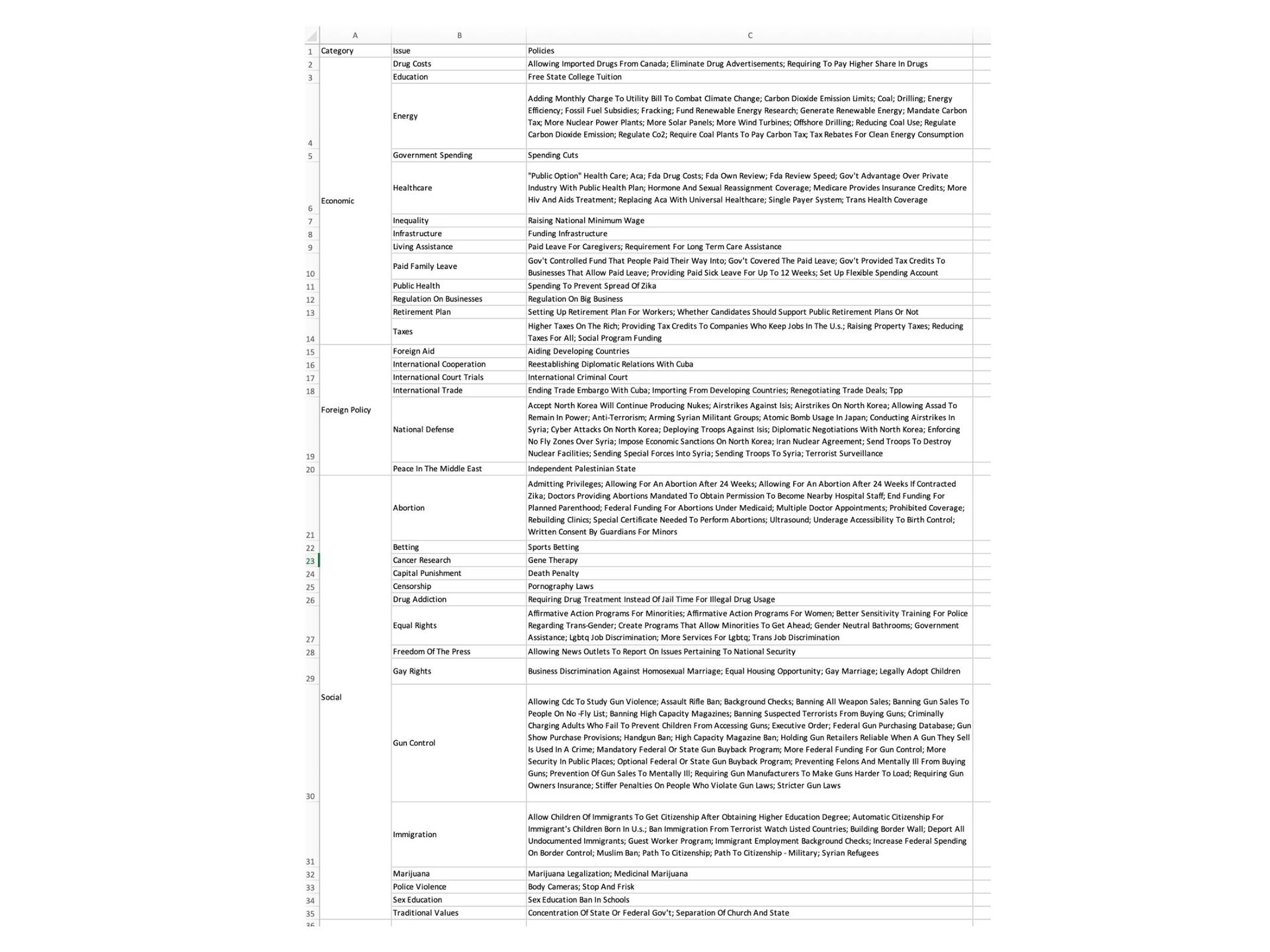
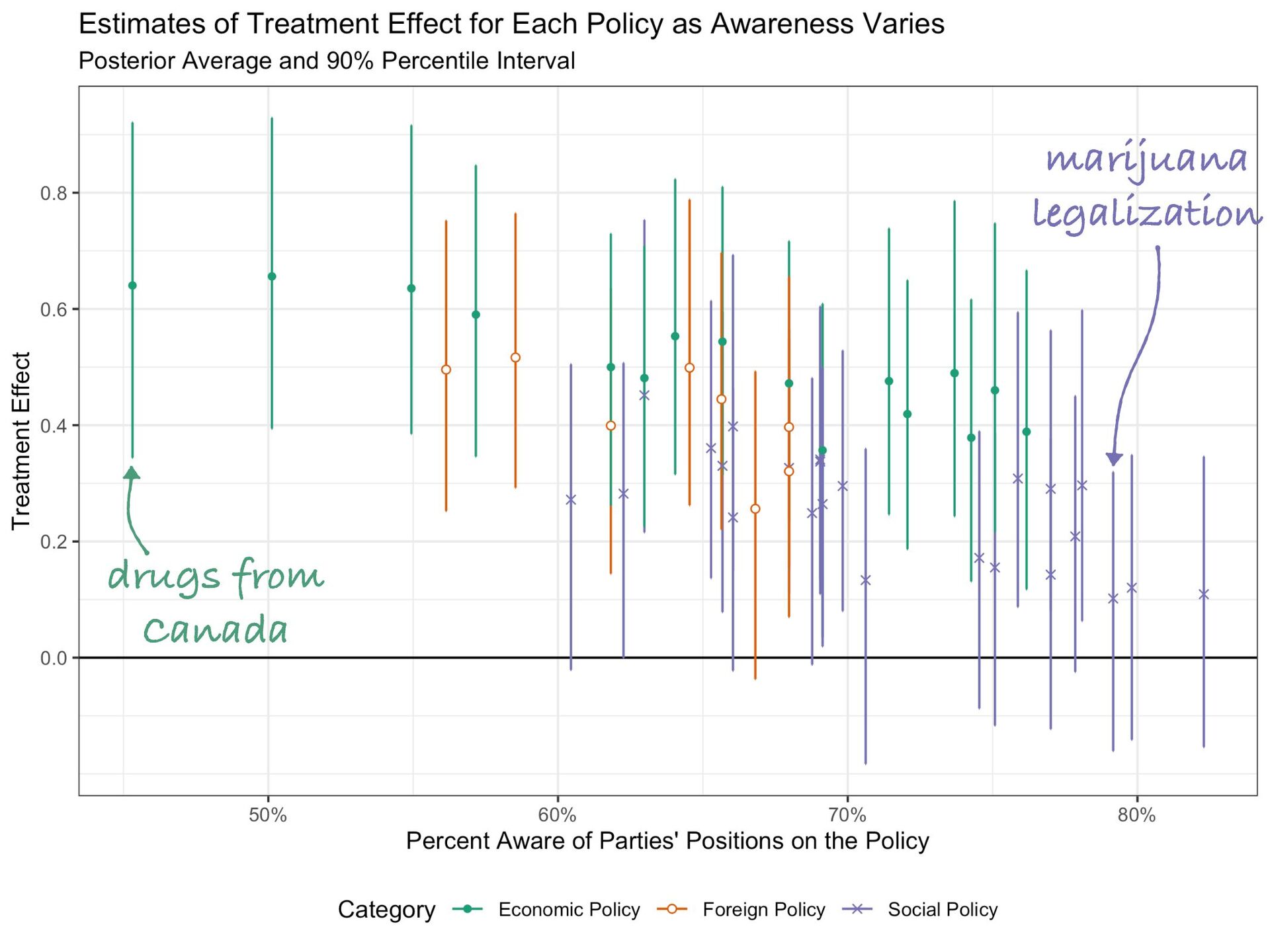
allowing imported drugs from Canada lately. Republicans are more likely to favor allowing imported drugs from Canada, while Democrats are more likely to oppose allowing imported drugs from Canada. We’d like to know your opinion. Do you favor or oppose imported drugs from Canada? As you may know, there has been some debate about marijuana legaliza ti on lately. Democrats are more likely to favor marijuana legaliza ti on, while Republicans are more likely to oppose marijuana legaliza ti on. We’d like to know your opinion. Do you favor or oppose marijuana legaliza ti on? Example: Party Cues
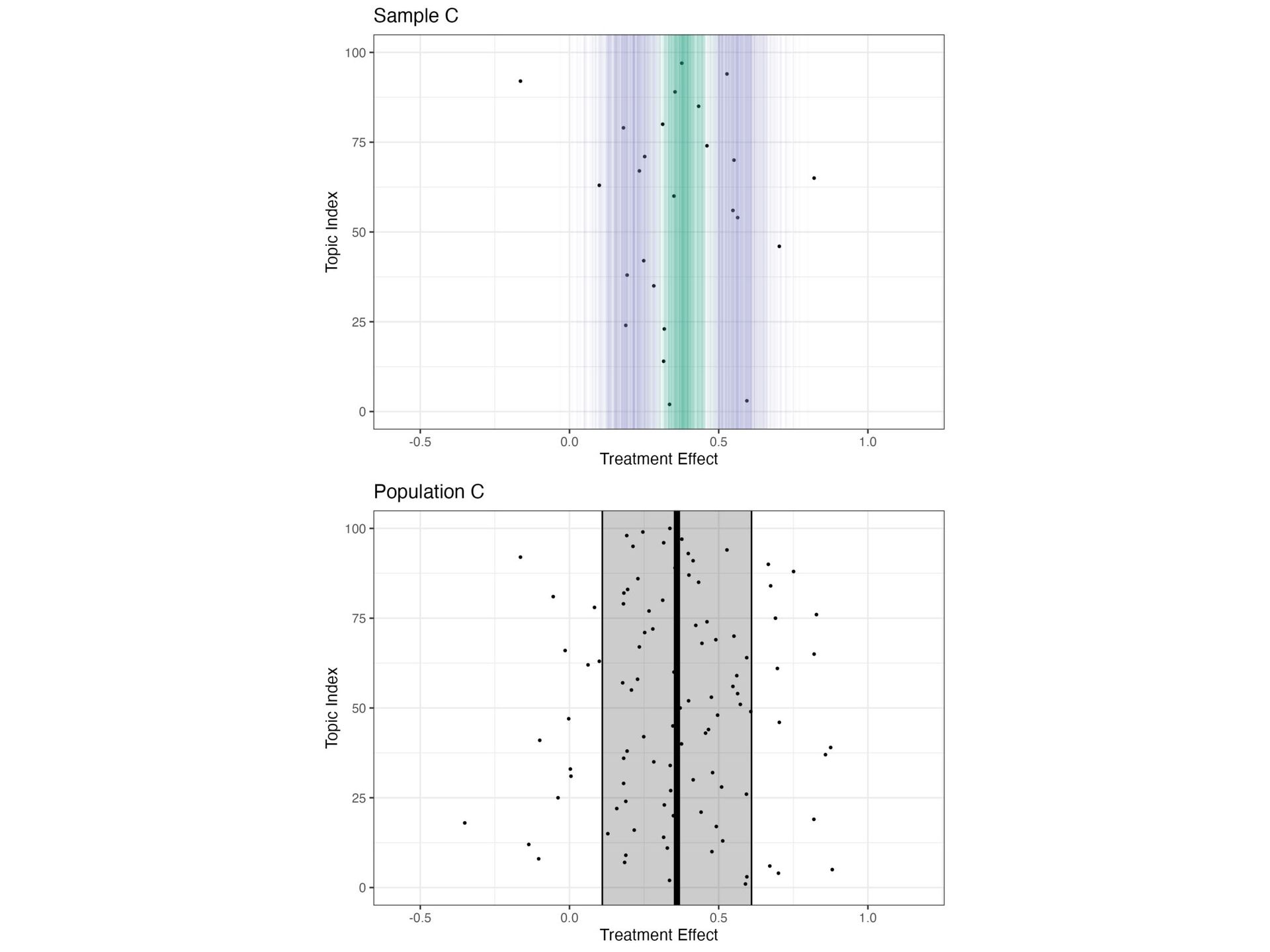
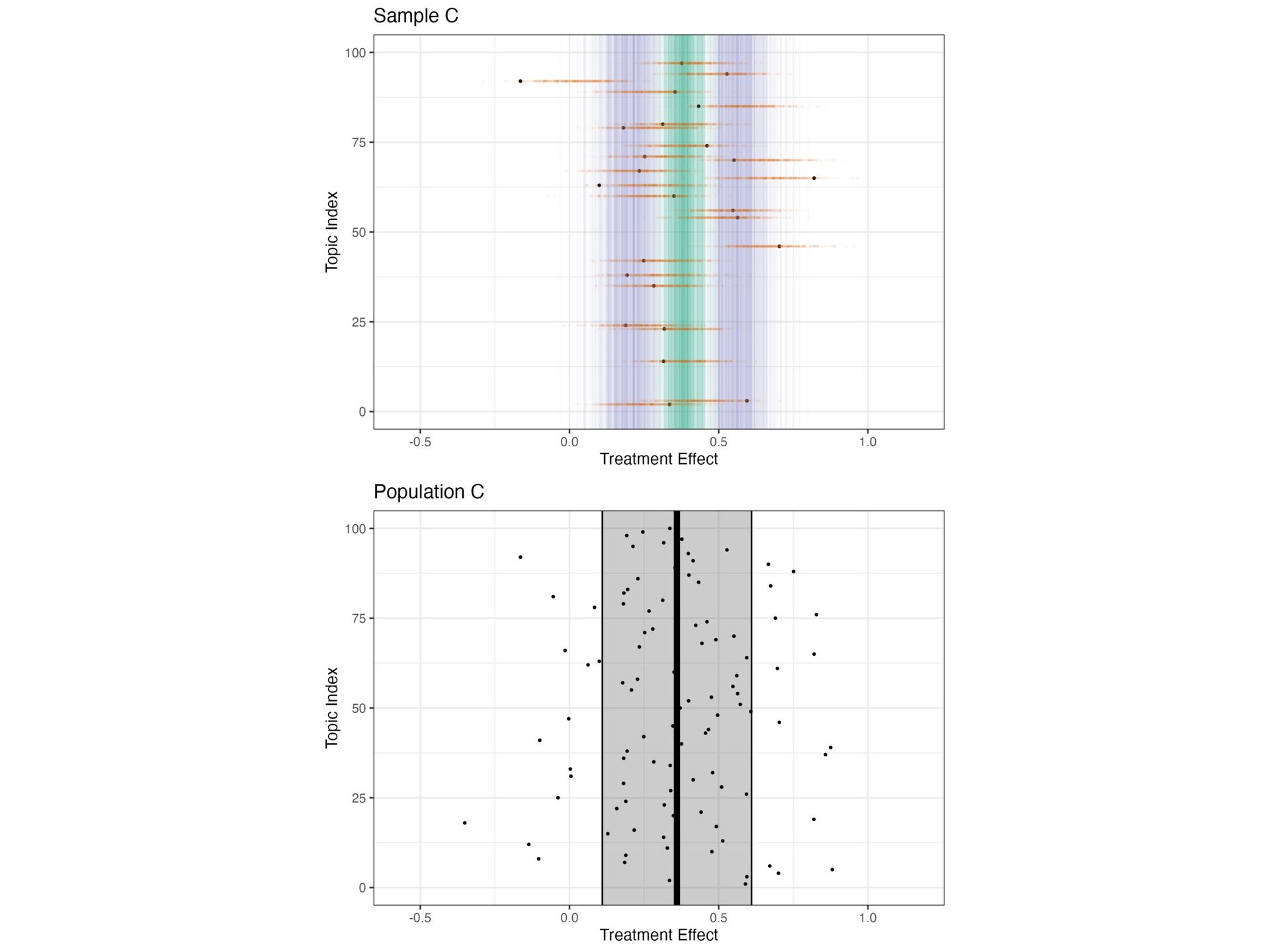
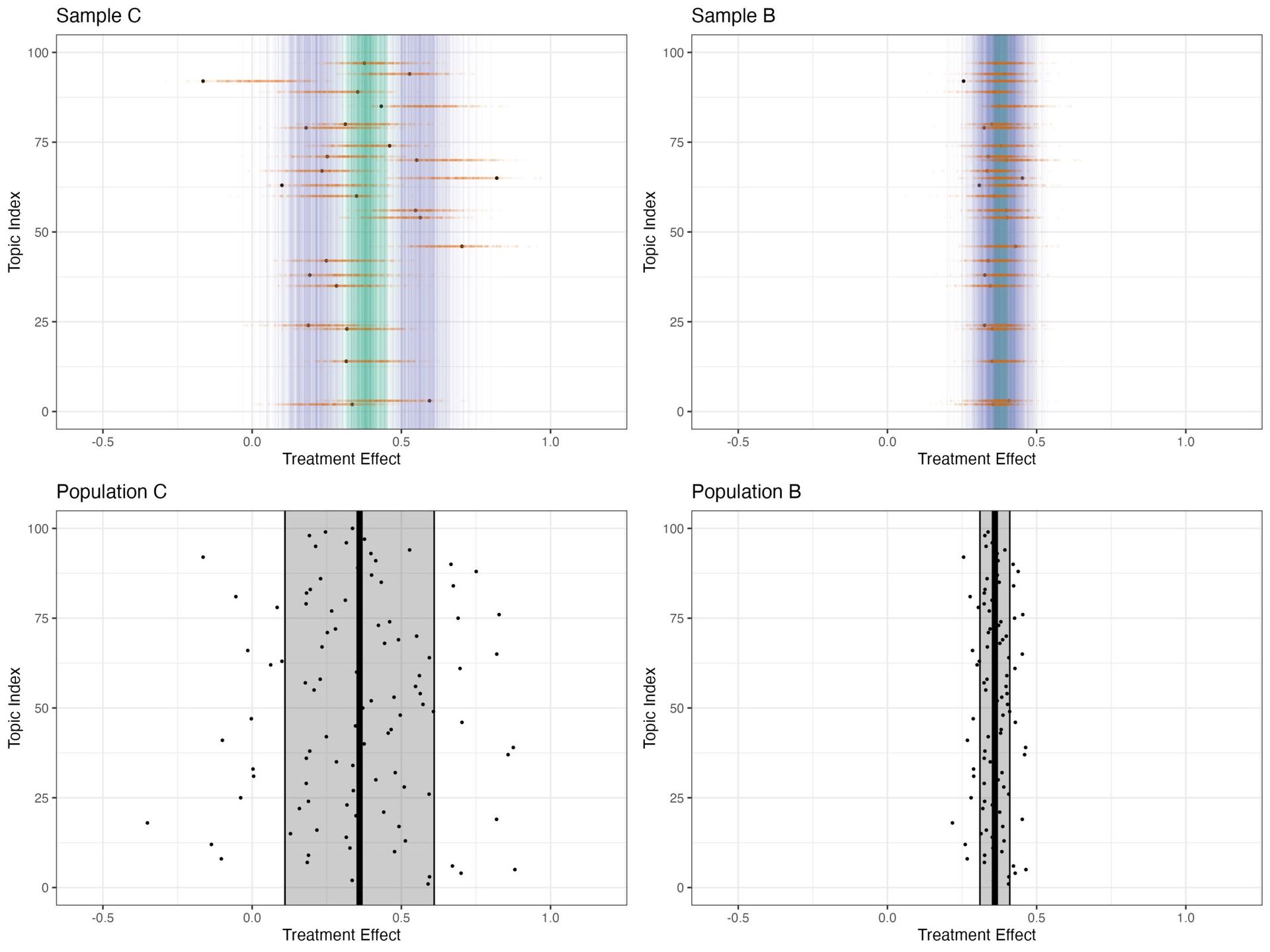
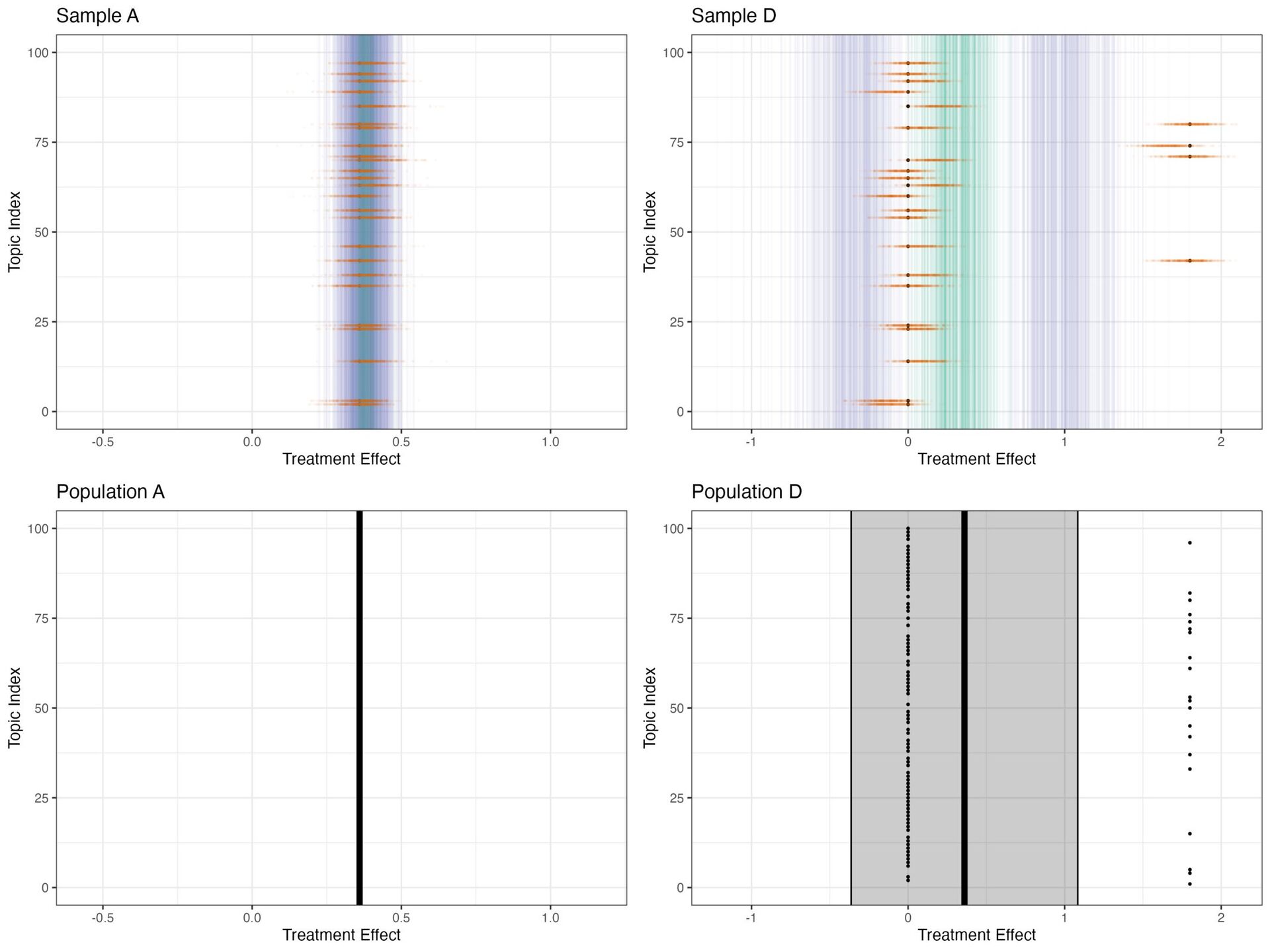
treatment + (1 + treatment | topic_id), data = sample) # fit model with Stan library(rstanarm) fit_stan <- stan_lmer(y ~ treatment + (1 + treatment | topic_id), data = sample)
empirical application. Coming out in Political Behavior. Technical details focused on the estimators (bias, RMSE, coverage) and power calculations. Paper 2 Paper 1 http://www.carlislerainey.com/research/ http://www.carlislerainey.com/talk
![Topic Sampling Carlisle Rainey Associate Professor Florida State University [email protected]](https://files.speakerdeck.com/presentations/b110396ced4c4b80a6c7455064890203/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
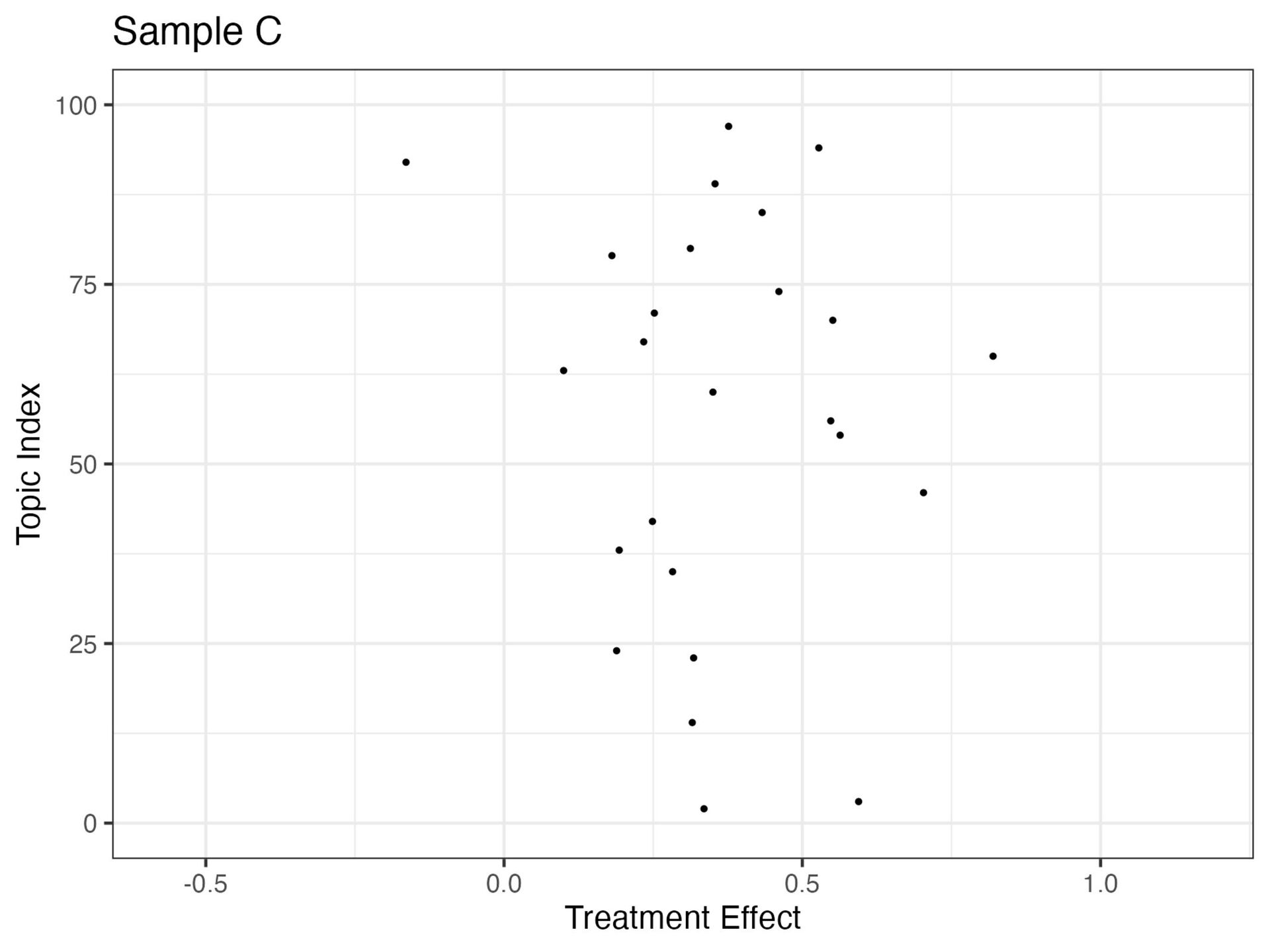{kind=link}
{kind=link}
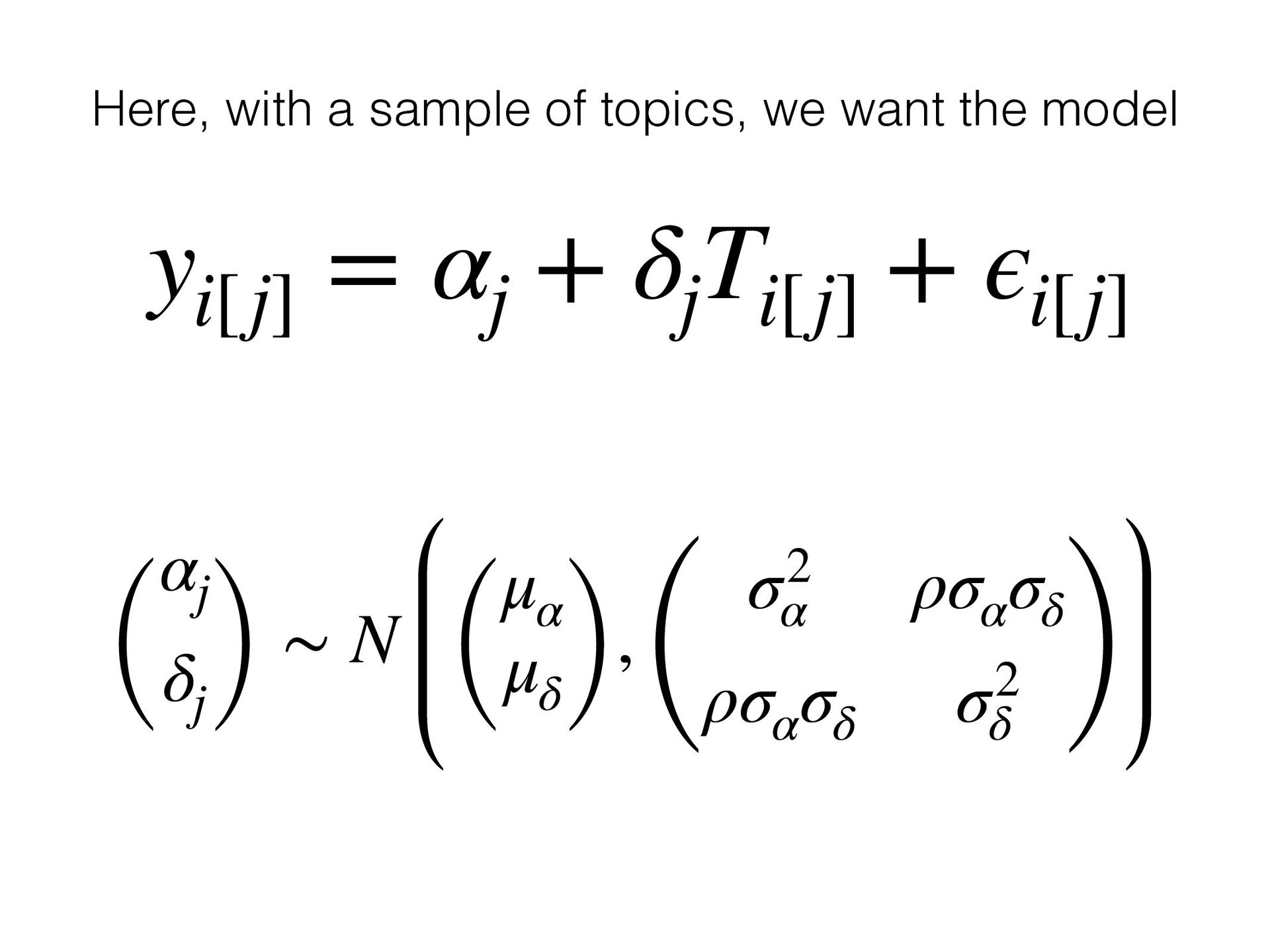{kind=link}
{kind=link}
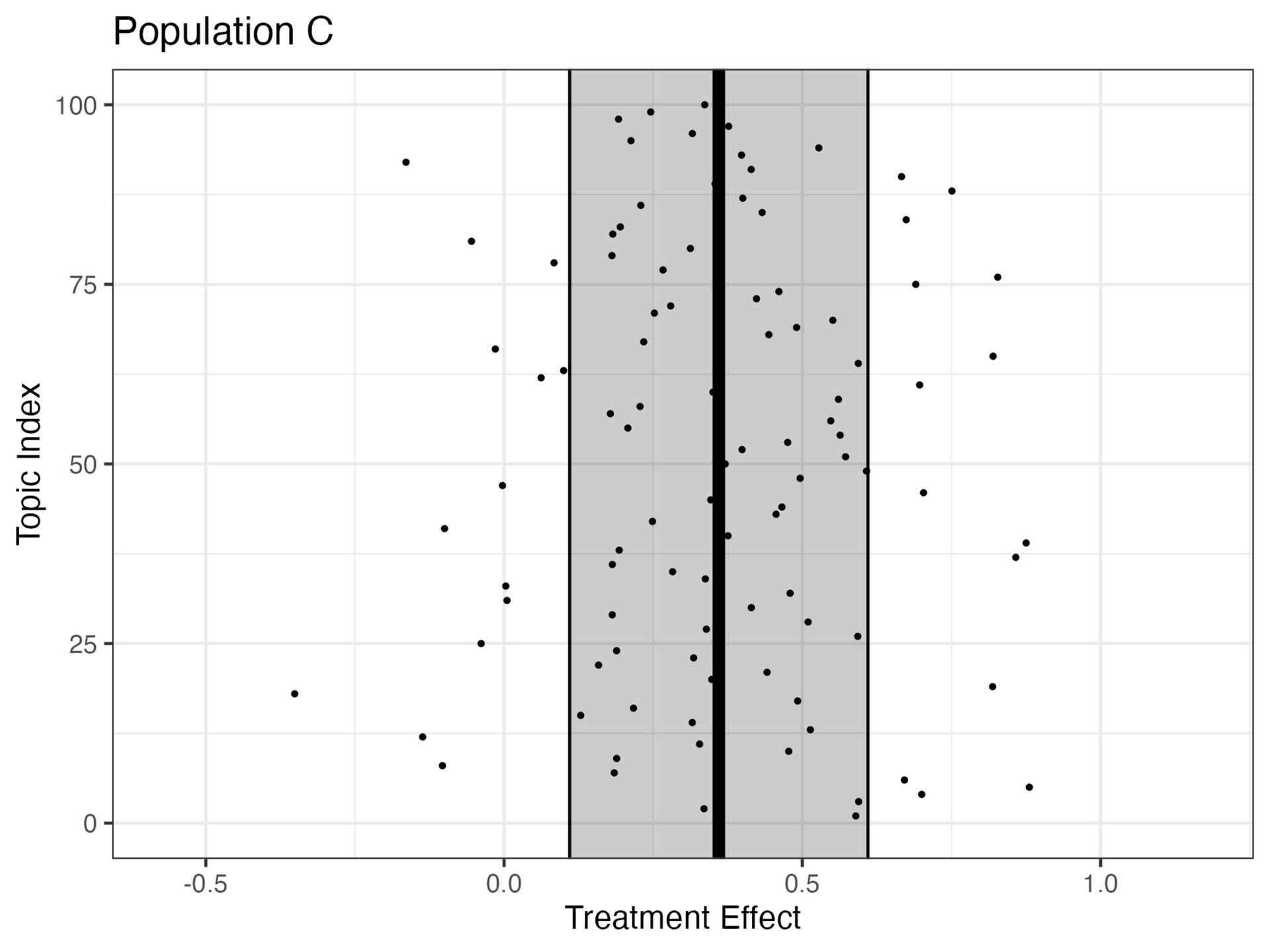{kind=link}
{kind=link}
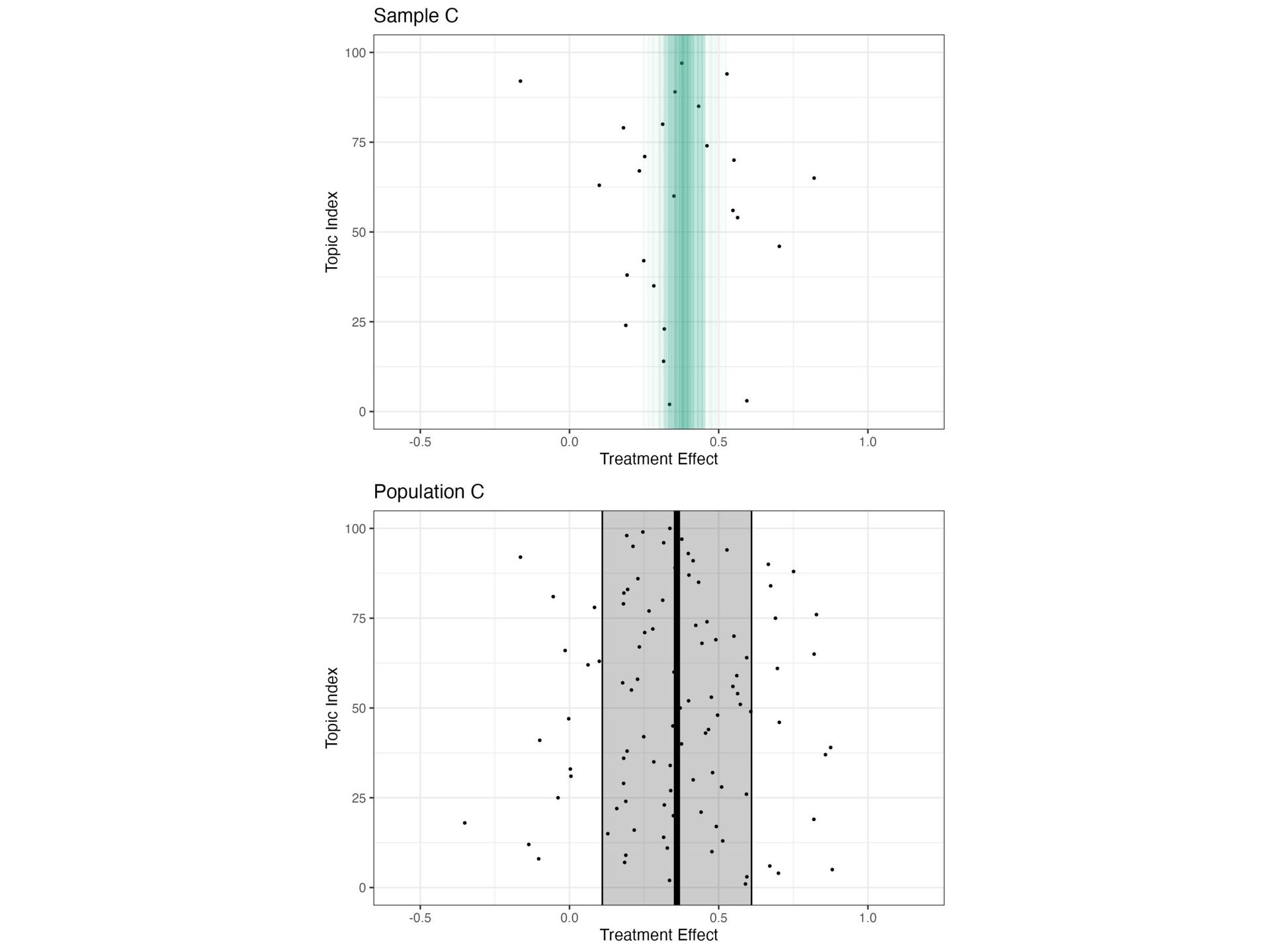{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}