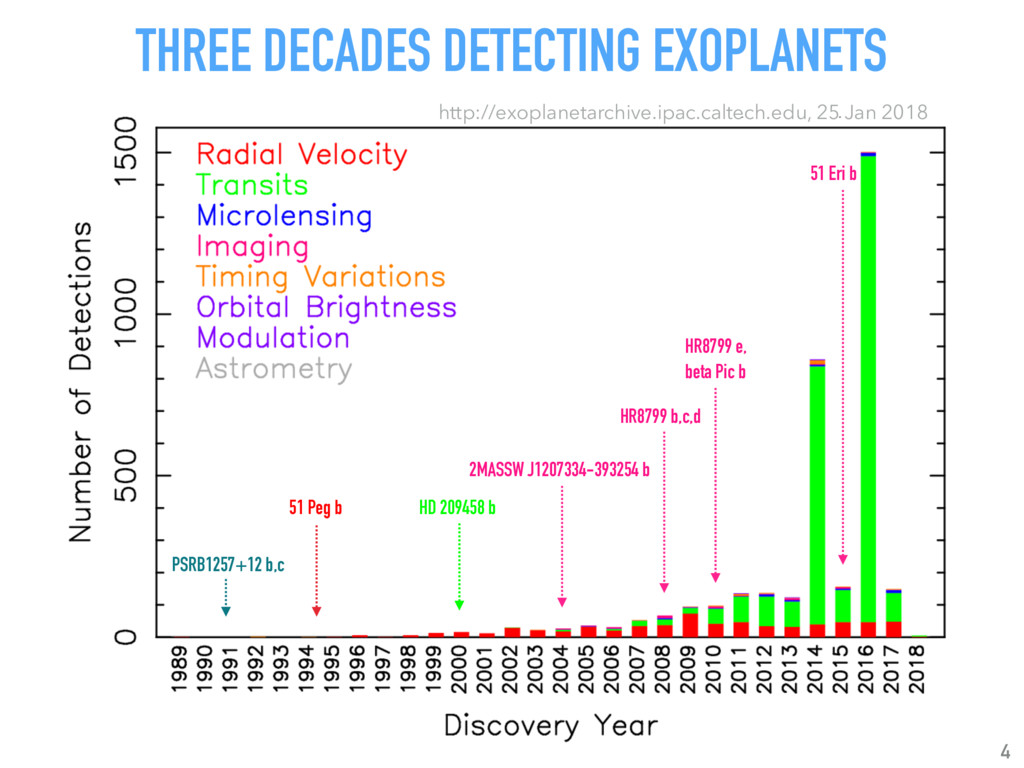
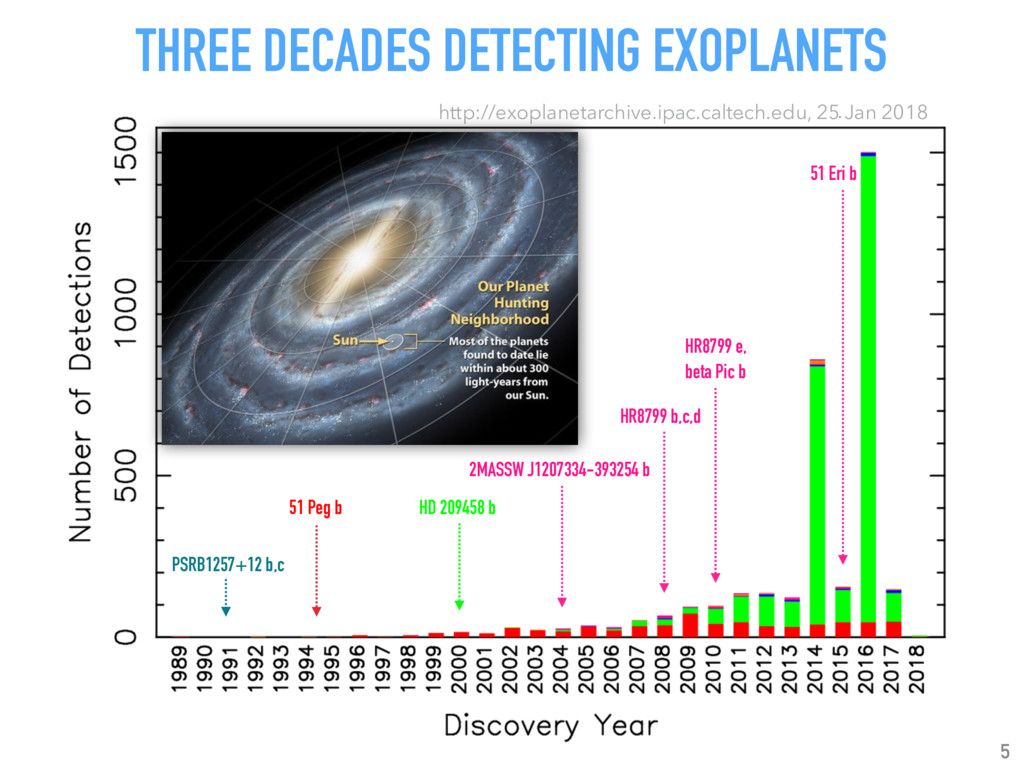
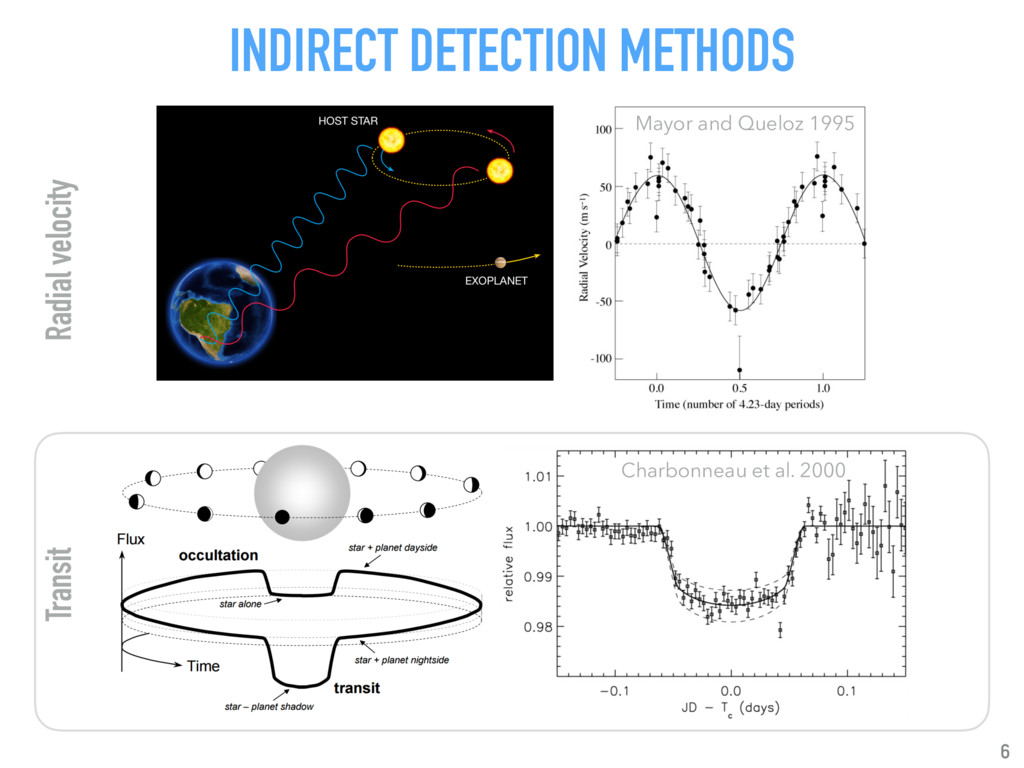
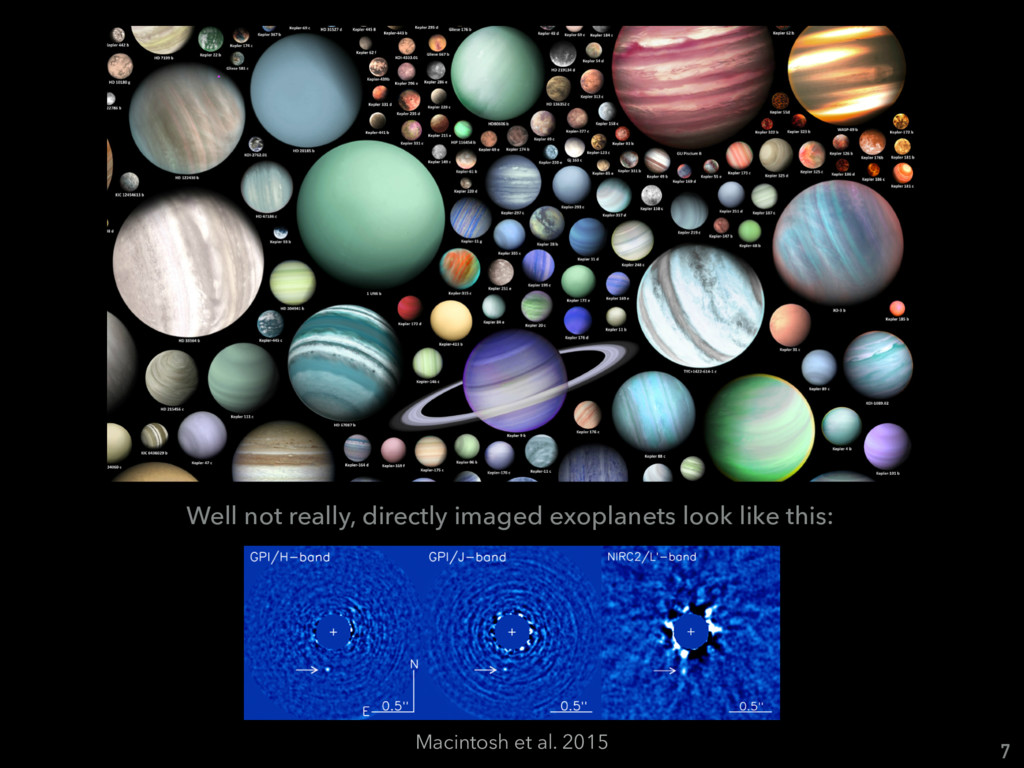
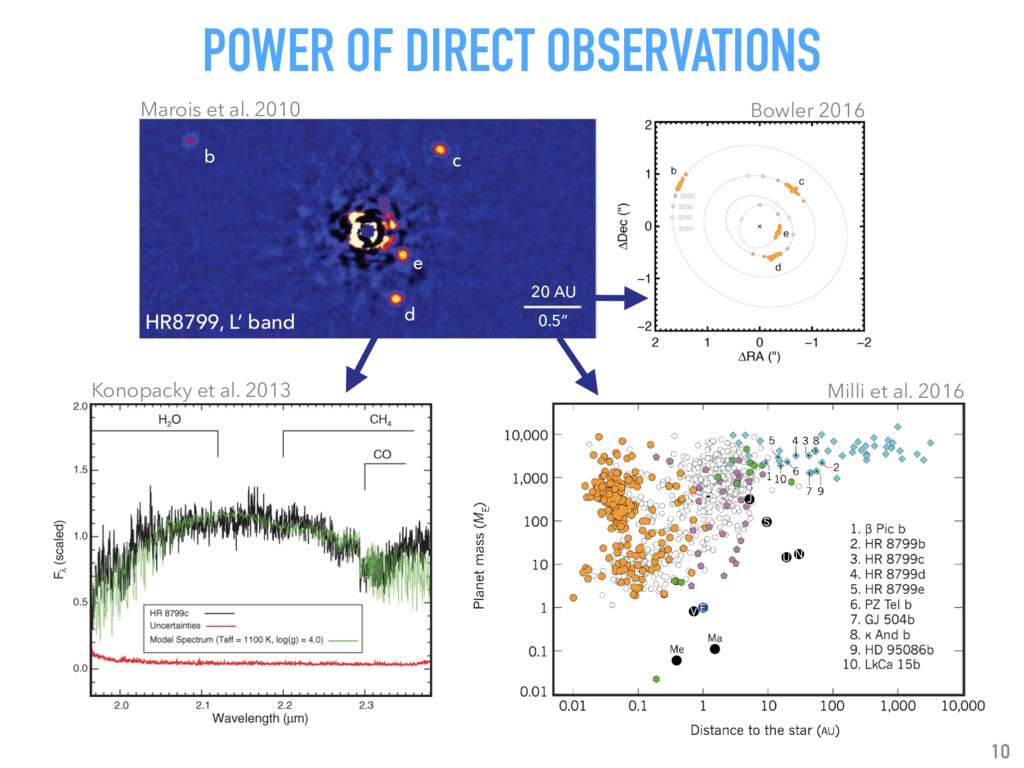
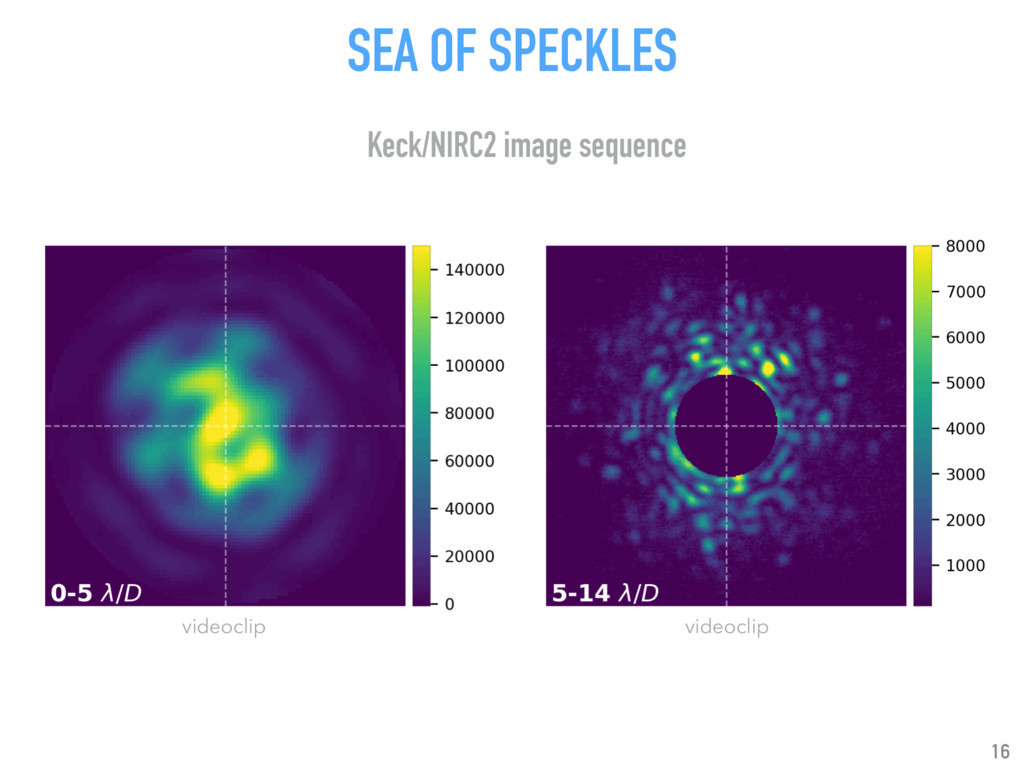
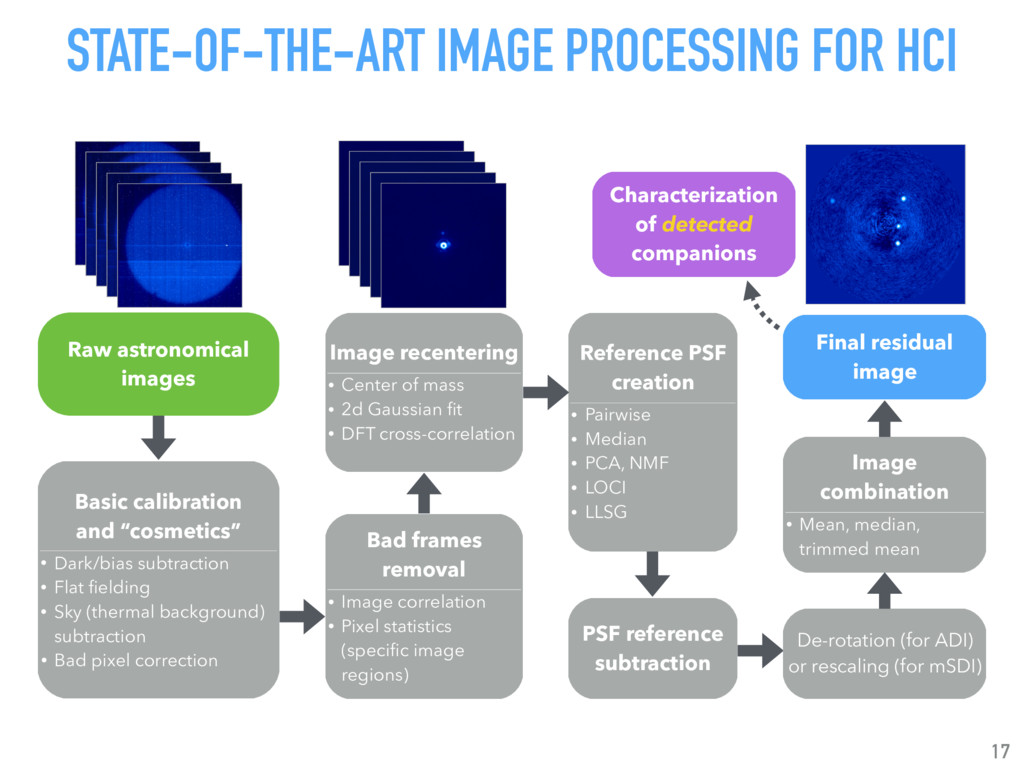
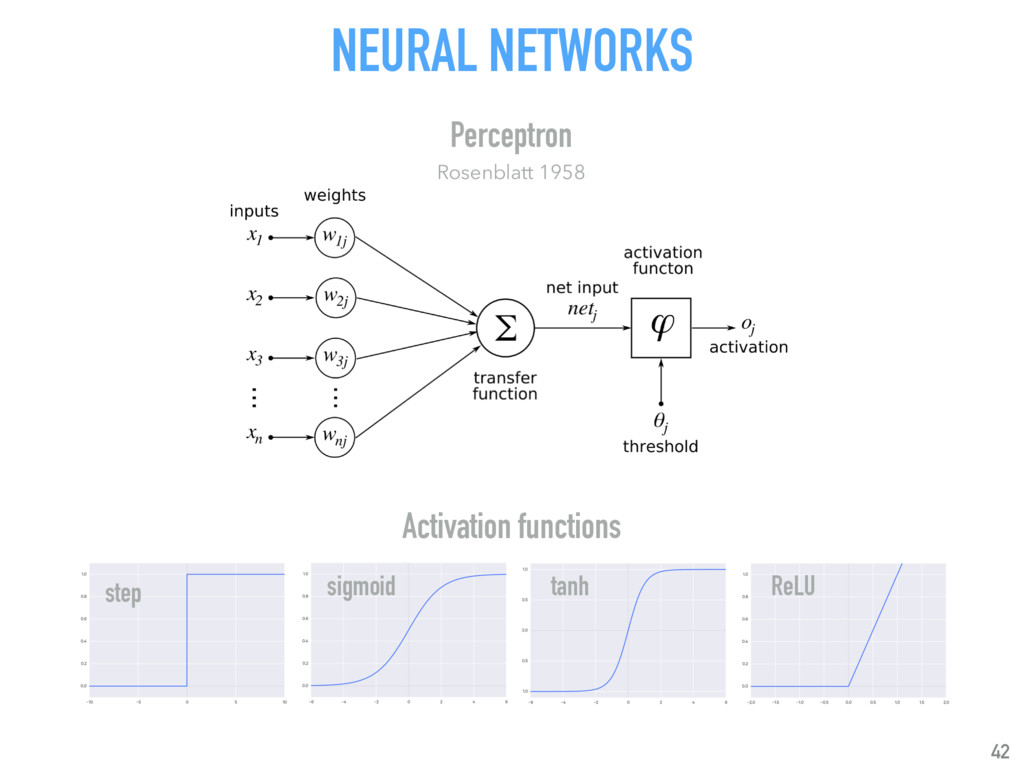
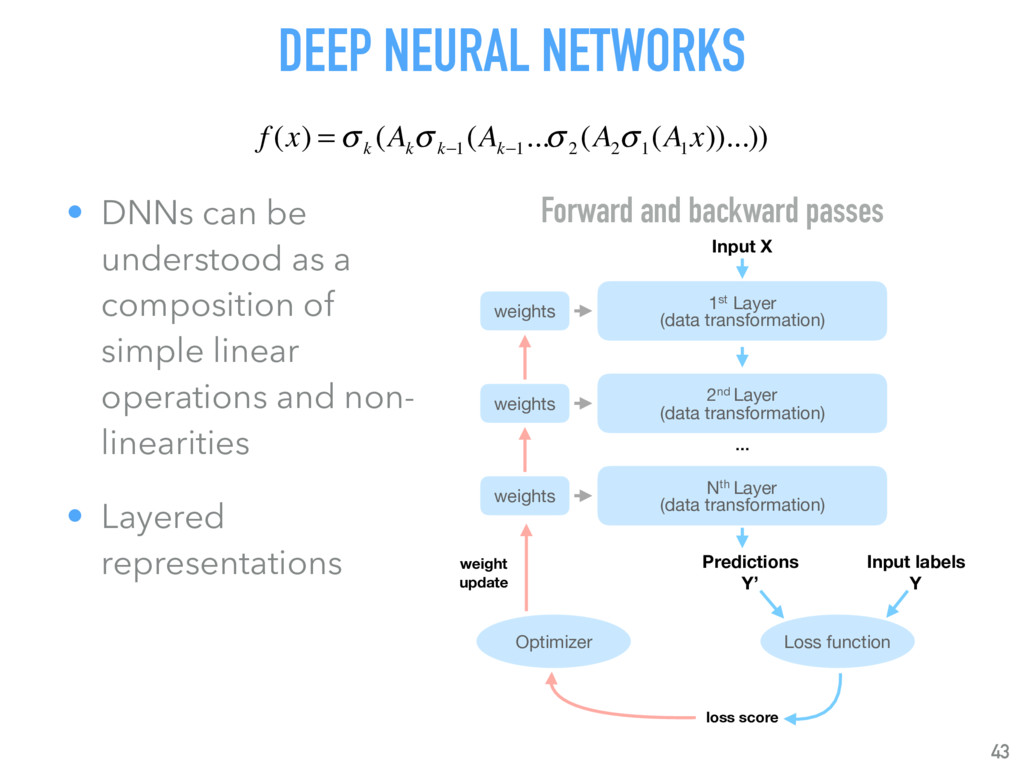
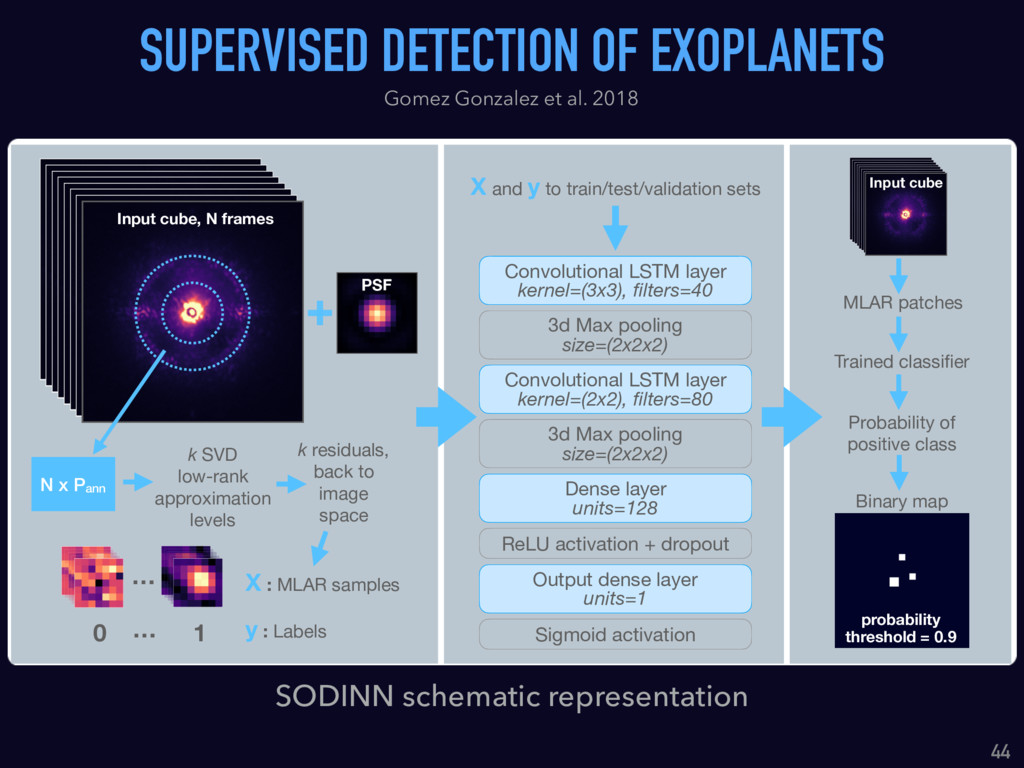
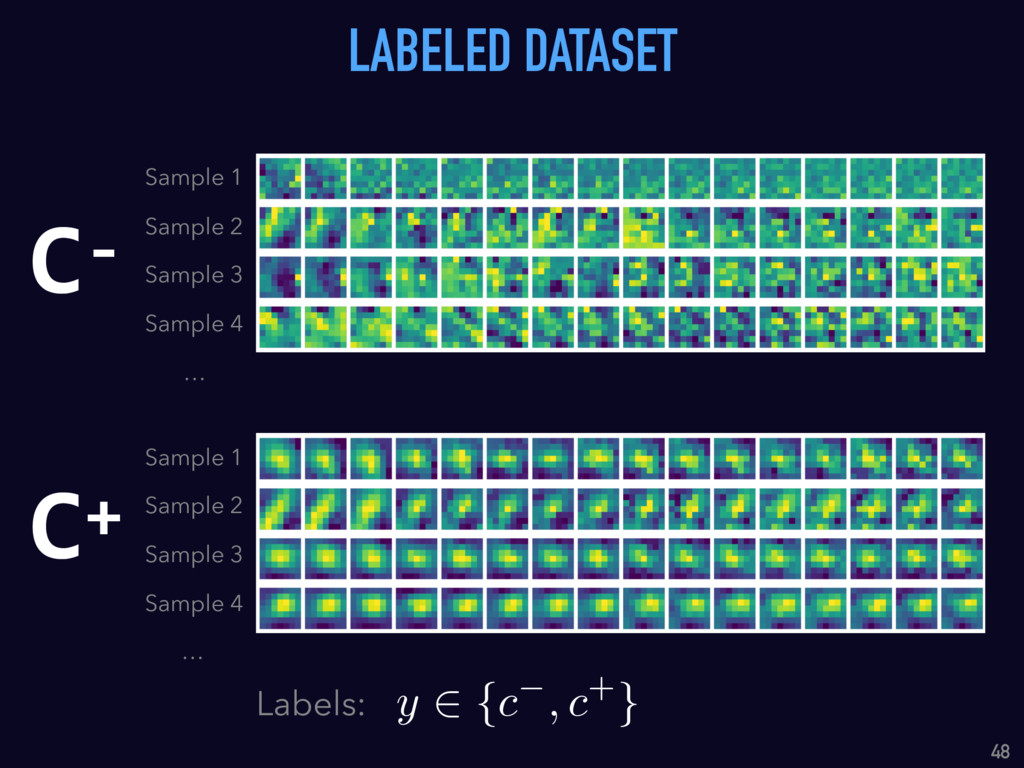
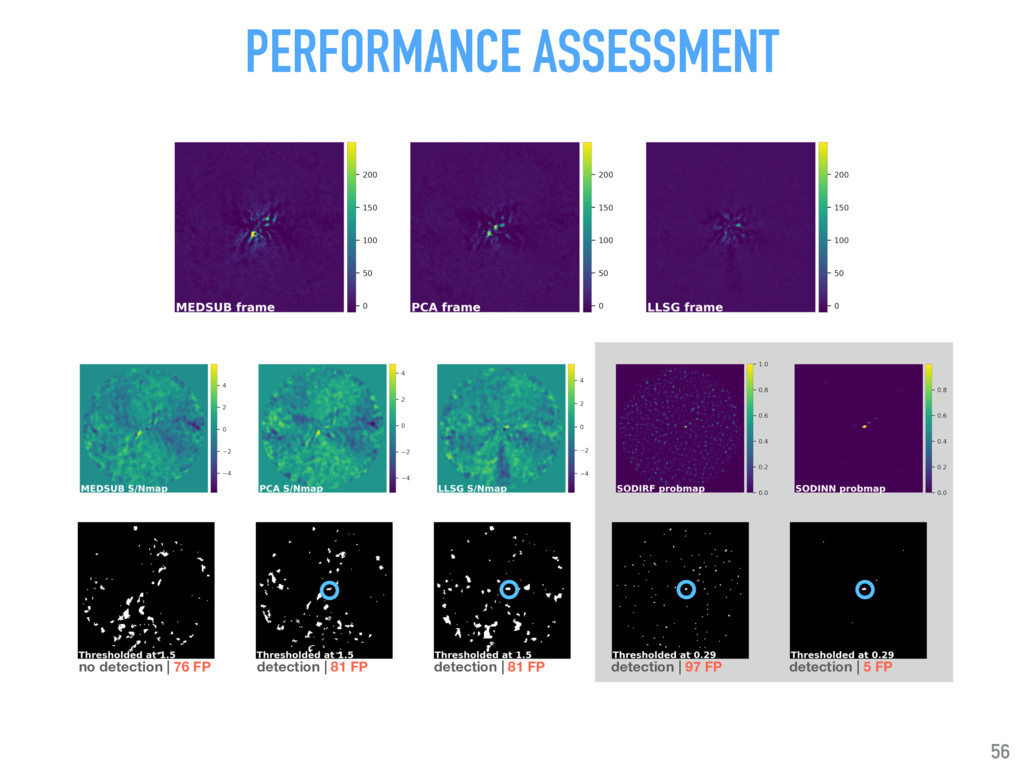
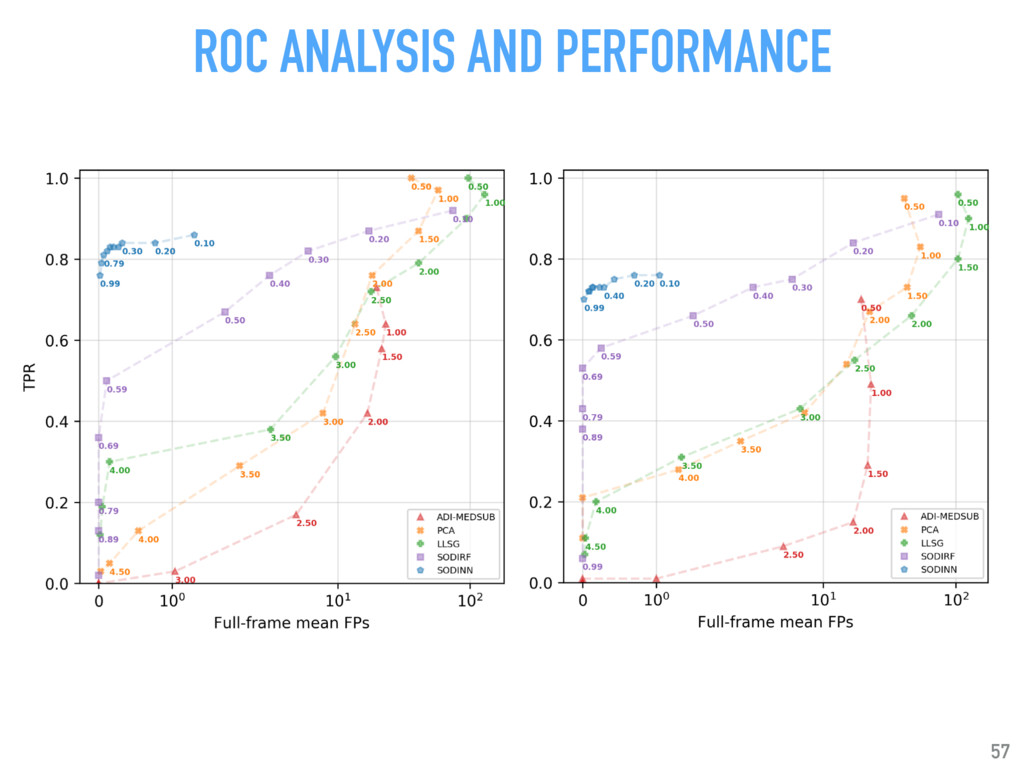
Talk given at INRIA Grenoble - Rhône-Alpes. Presents my latests results on "Supervised detection of exoplanets in high-contrast image sequences" (https://arxiv.org/abs/1712.02841) to experts in computer vision and machine (deep) learning (http://thoth.inrialpes.fr/).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
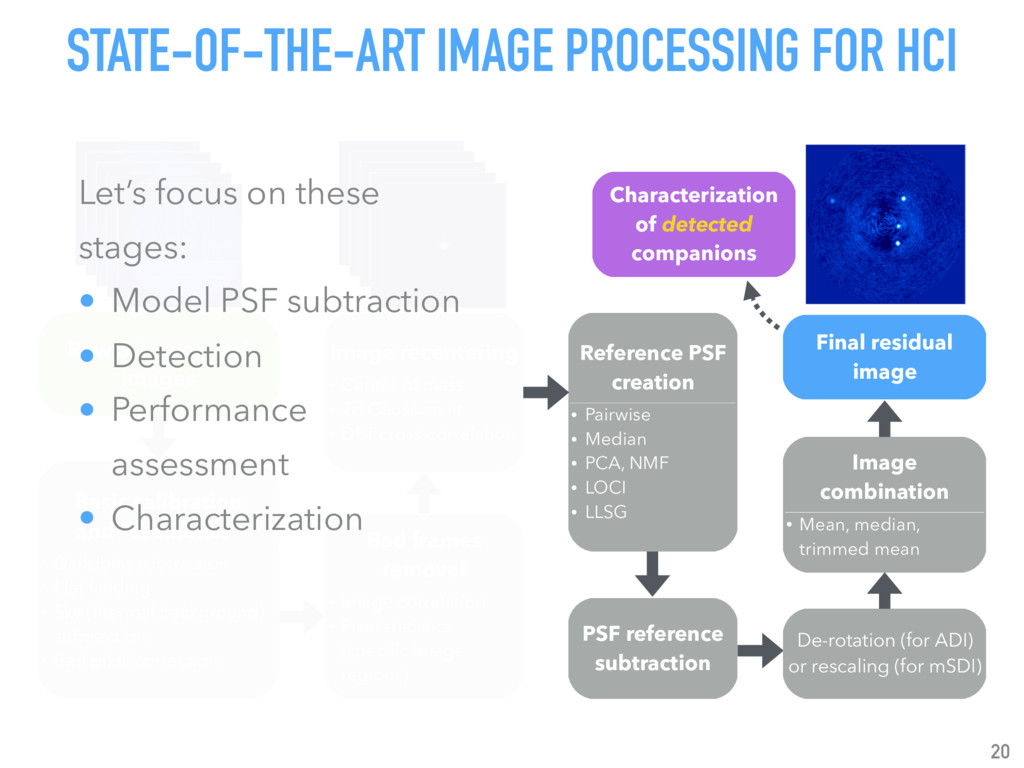{kind=link}
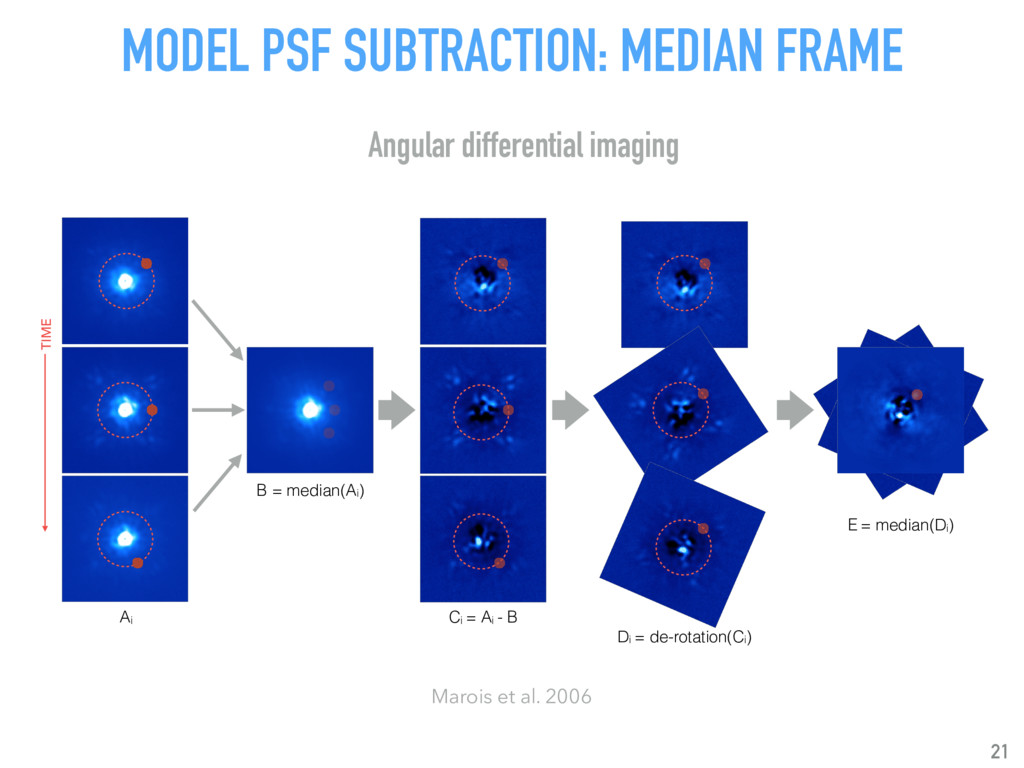{kind=link}
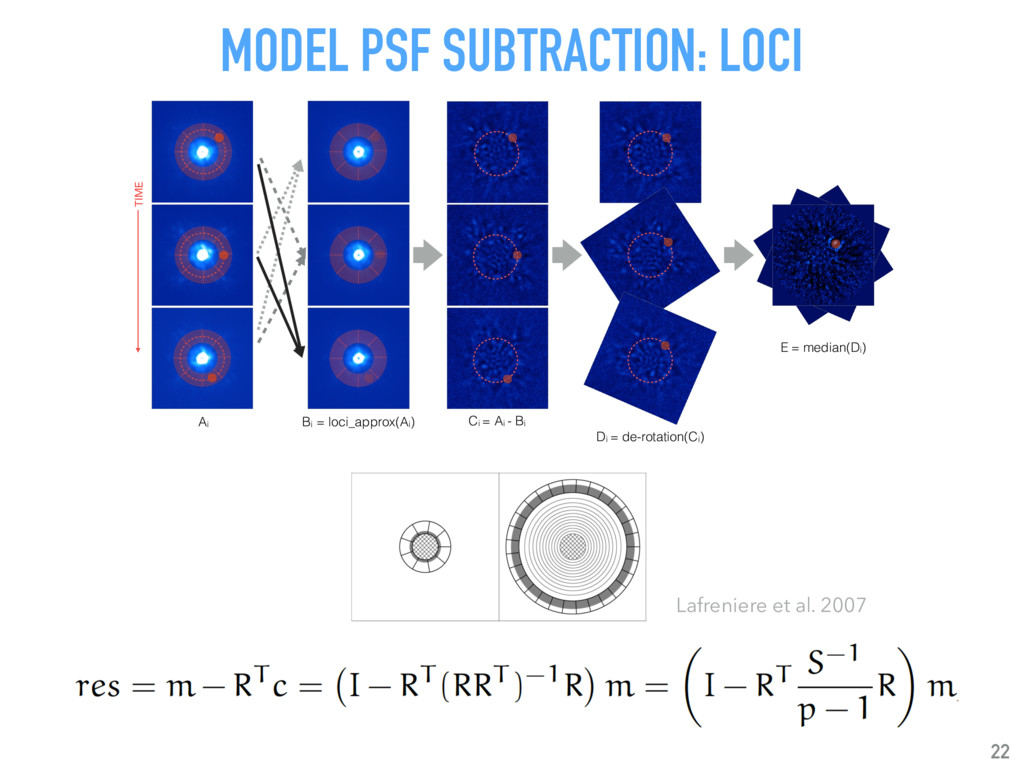{kind=link}
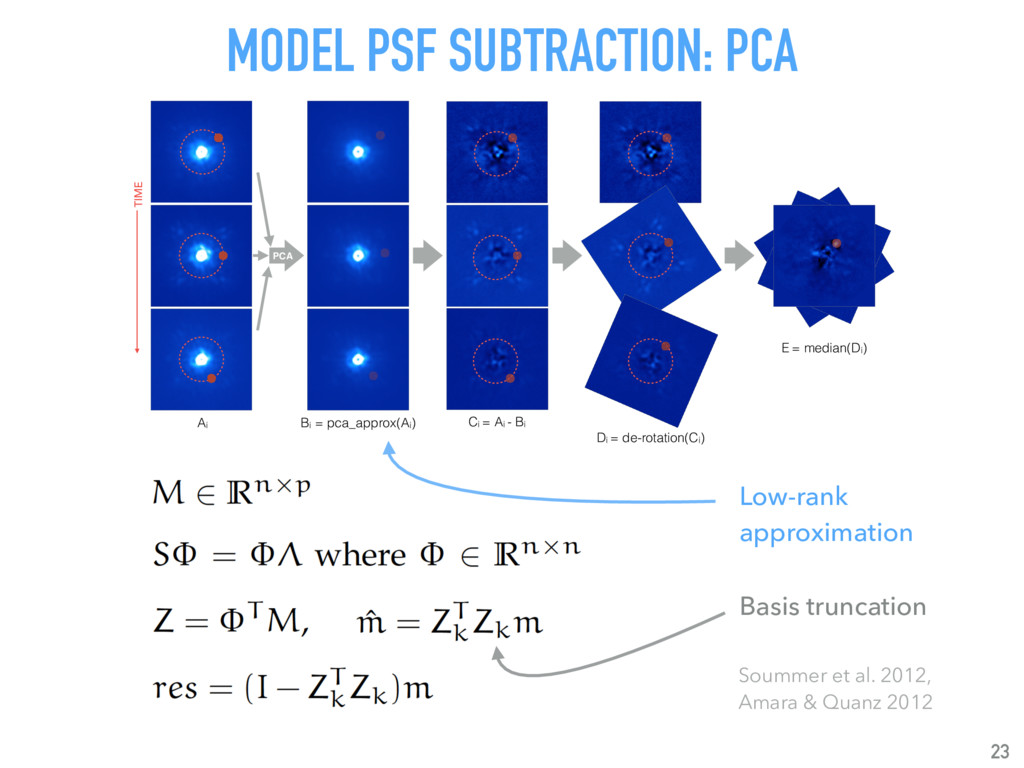{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
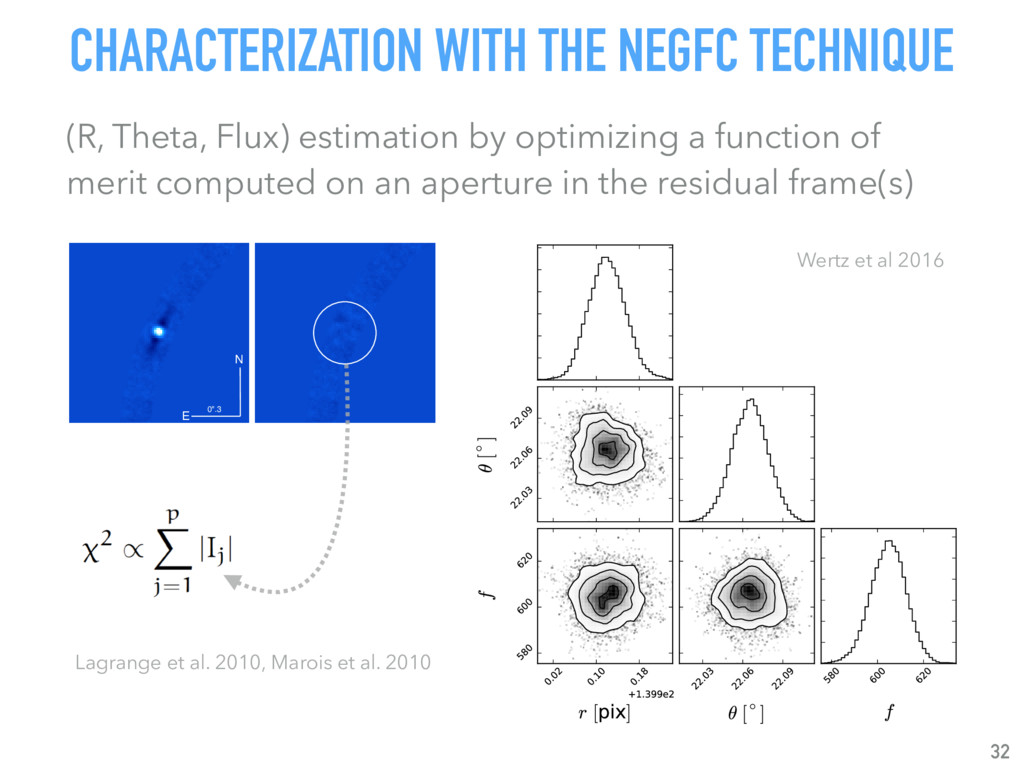{kind=link}
{kind=link}
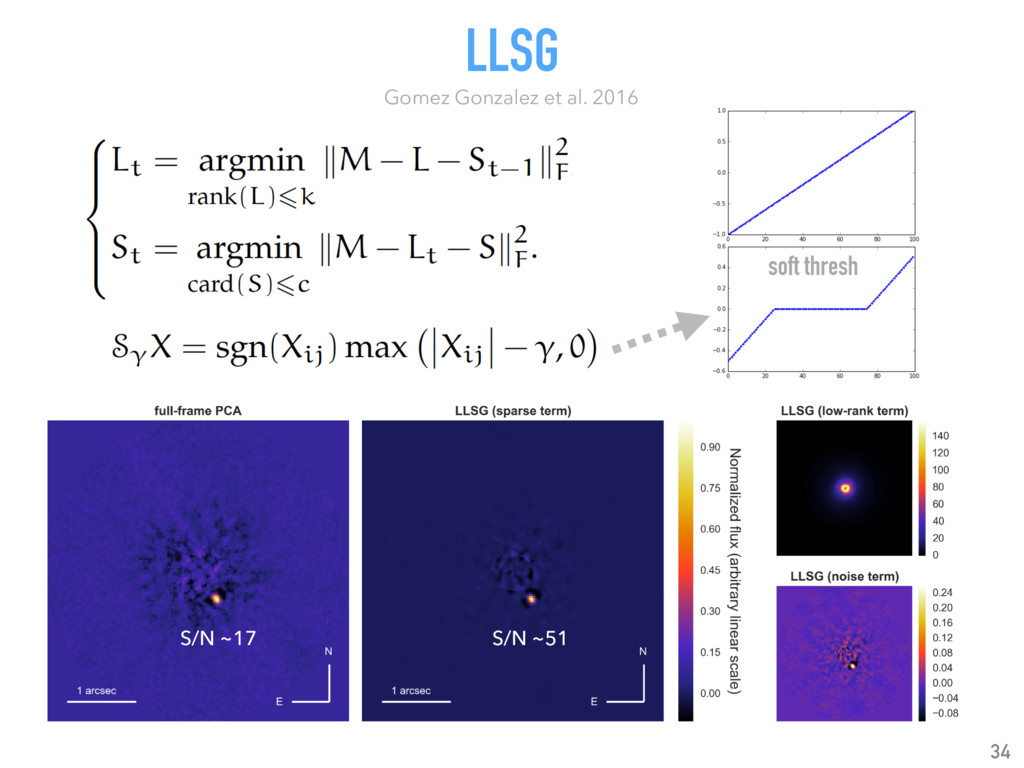{kind=link}
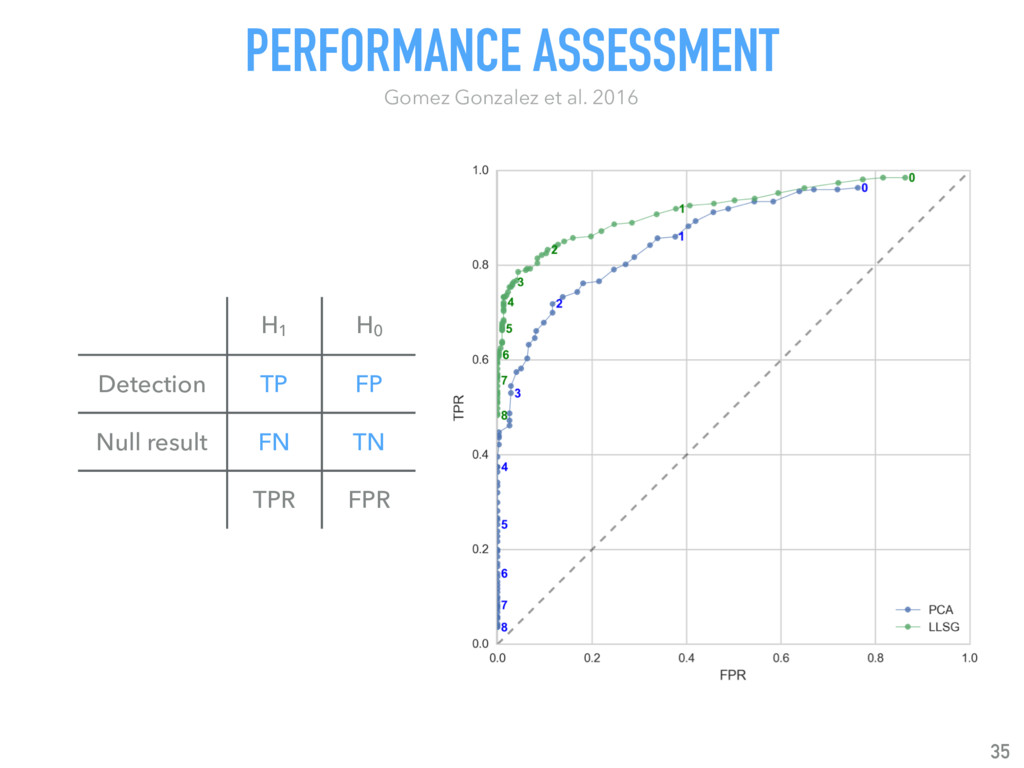{kind=link}
{kind=link}
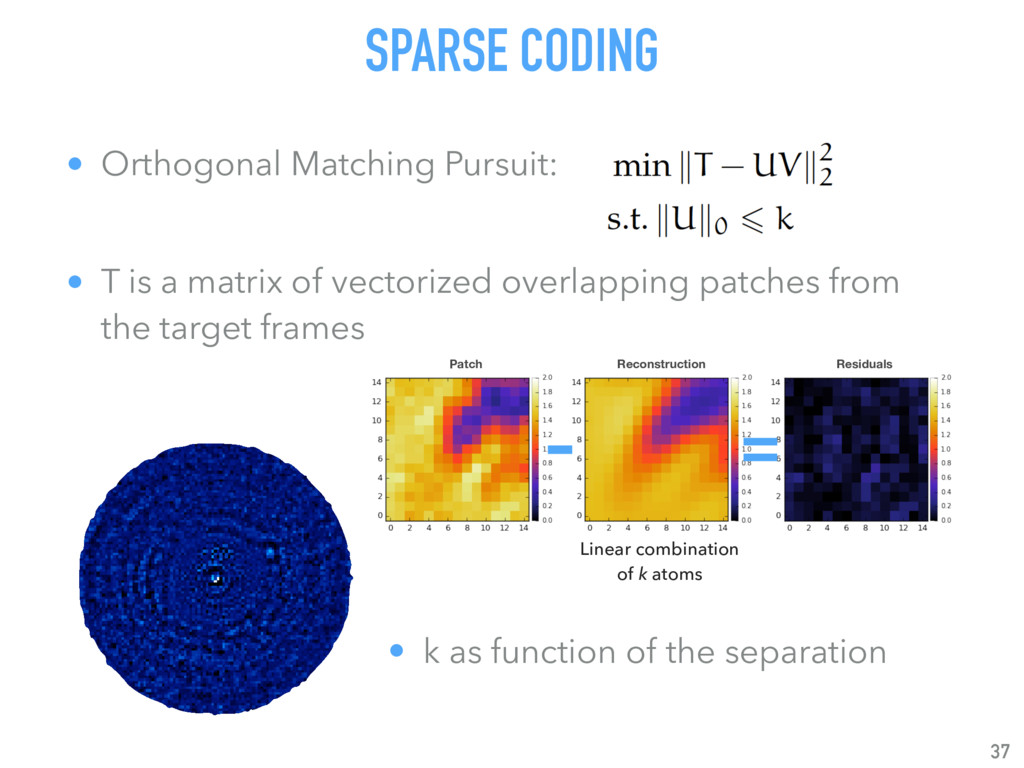{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
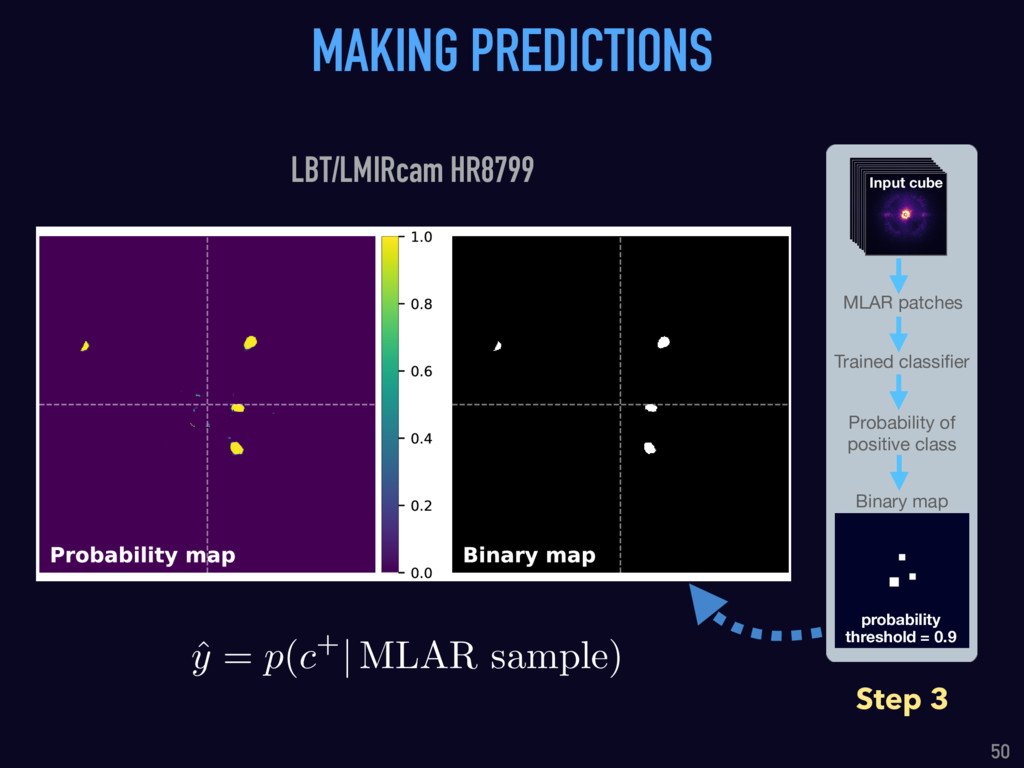{kind=link}
{kind=link}
{kind=link}
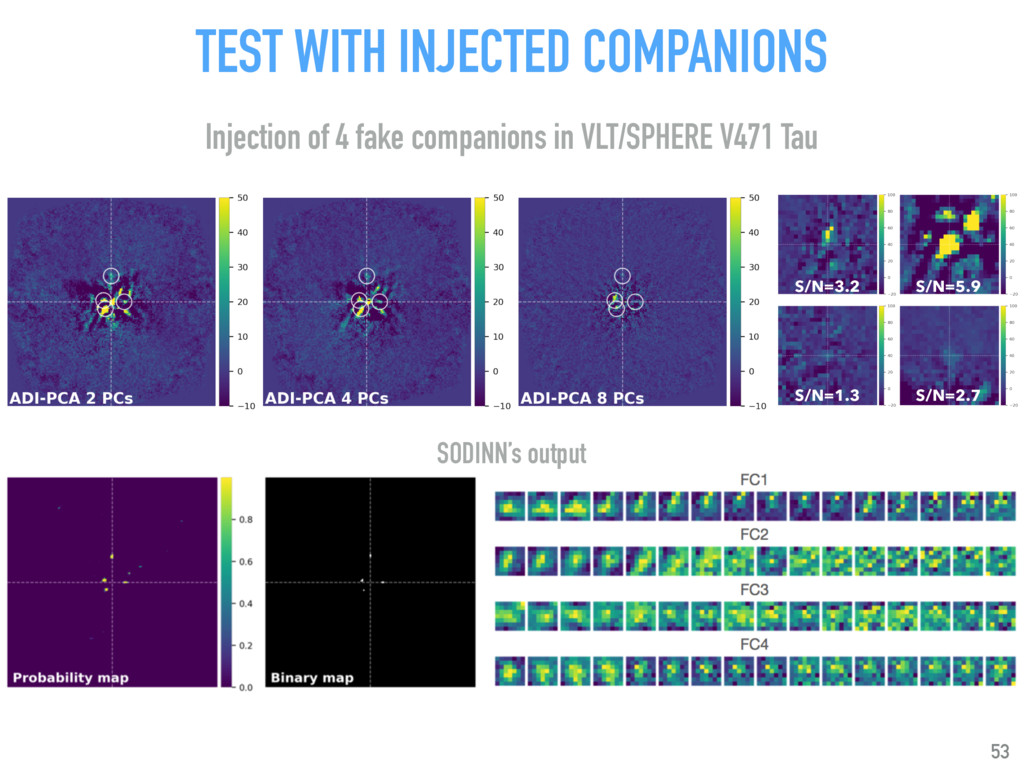{kind=link}
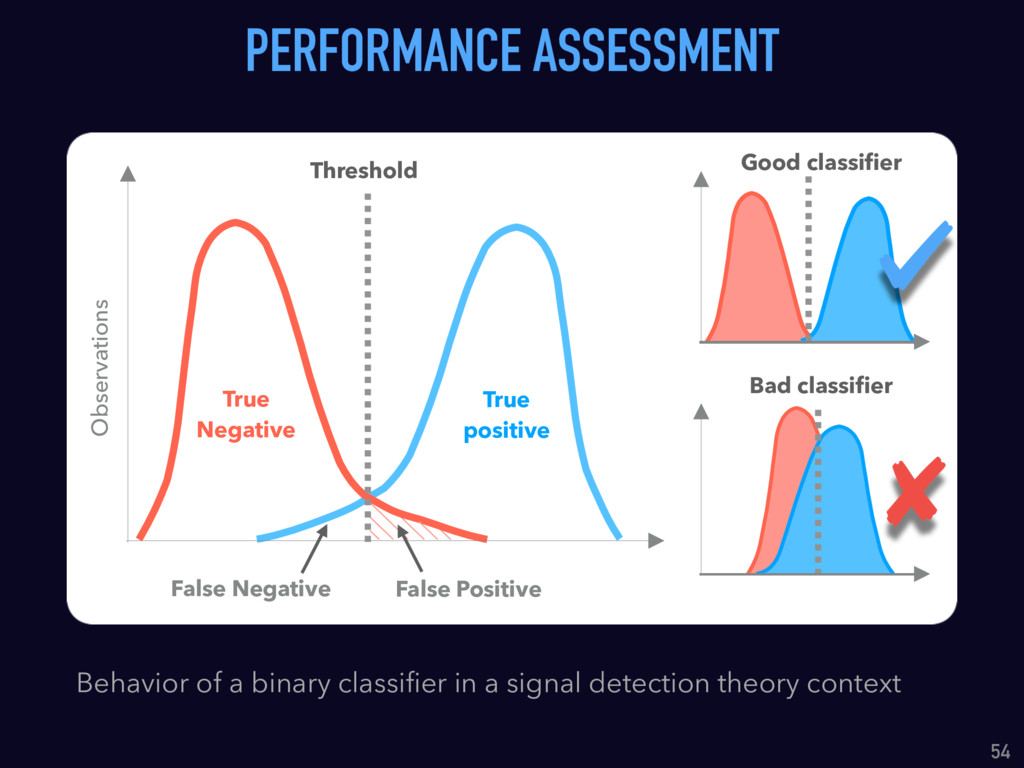{kind=link}
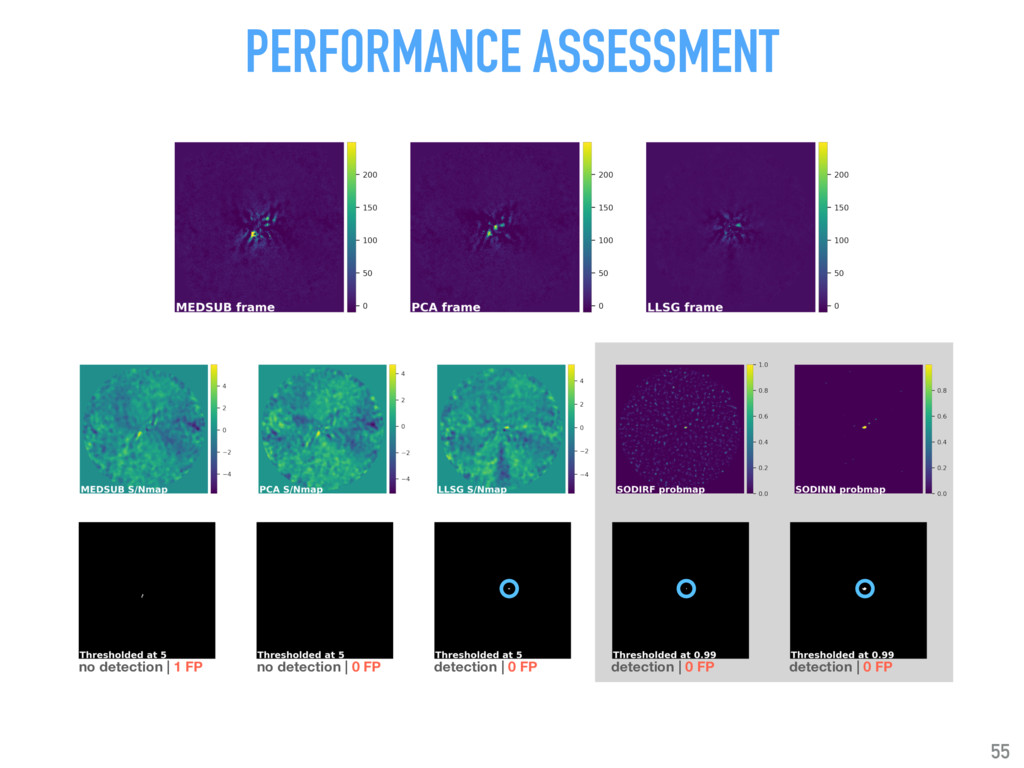{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] carlgogo carlosalbertogomezgonzalez https://carlgogo.github.io/ ¡Gracias!](https://files.speakerdeck.com/presentations/a7a63b63ac354fdaac062d0069dc7b16/slide_62.jpg){kind=link}