• Provisioning Managing multiple MongoDB clusters with Chef • Snapshots • Fragmentation • Monitoring • State of the mongo cookbook • Glossary of tools Friday, April 26, 13
snapshot • mongodump Provisioning options: • snapshot • secondary sync • mongorestore (in theory) Snapshots are great and you should use them. Friday, April 26, 13
and databases • Hard on your primary, does a full table scan of all data • On > 2.2.0 you can sync from a secondary by button-mashing rs.syncFrom(“host:port”) on startup • Or use iptables to block secondary from viewing primary (all versions) • Not riskless, it resets the padding factor for all collections to 1 Friday, April 26, 13
RAID (this is hard to change later!) • Include mongodb::raid_data in your replica set recipe • Set a role attribute for mongodb[:vols] to indicate how many volumes to RAID • Set a role attribute for mongodb[:volsize] to indicate the size of the volumes • Set the mongodb[:use_piops] attribute if you want to use PIOPS volumes Friday, April 26, 13
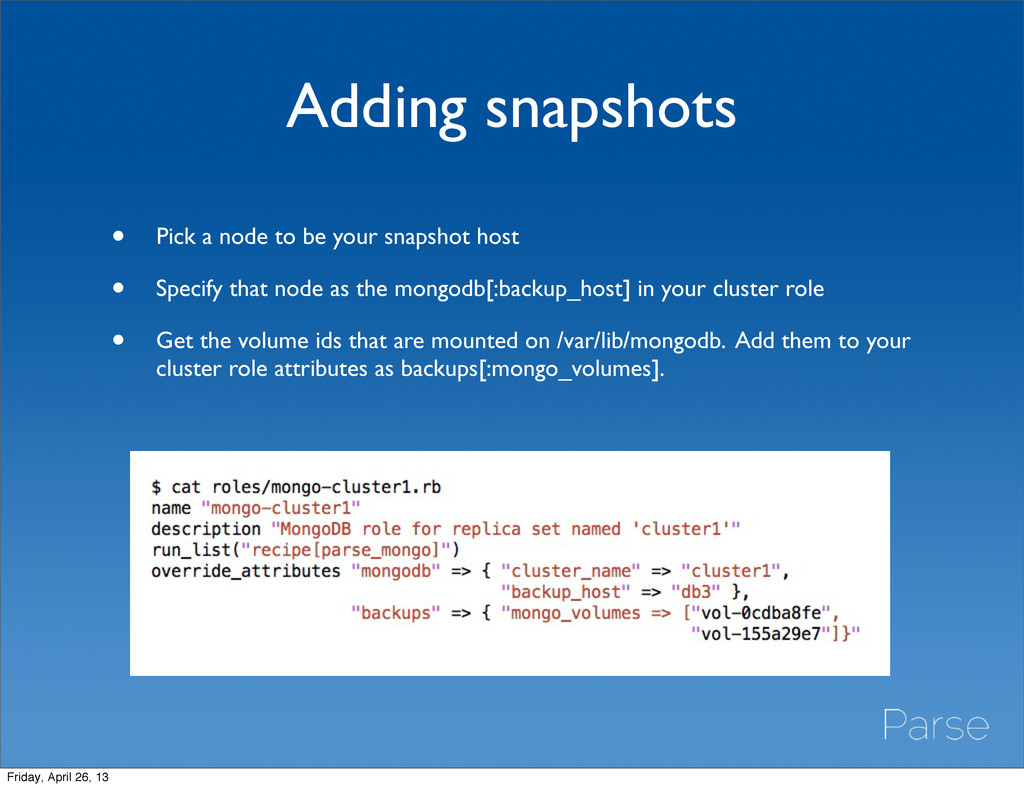
host • Specify that node as the mongodb[:backup_host] in your cluster role • Get the volume ids that are mounted on /var/lib/mongodb. Add them to your cluster role attributes as backups[:mongo_volumes]. Friday, April 26, 13
the backup host • Cron job does an ec2-consistent-snapshot of the volumes specified in backups[:mongo_volumes] • Locks mongo during snapshot • Tags a “daily” snapshot once a day, so you can easily prune hourly snapshot sets while keeping raid array sets coherent Friday, April 26, 13
see if mongo $dbpath is mounted • if not, grab the latest completed set of snapshots for the volumes in backup[:mongo_volumes] • provision and attach a new volume from each snapshot • assemble the RAID array, mount on $dbpath To reprovision, just delete the aws attributes from the node, detach the old volumes, and re-run chef-client. Friday, April 26, 13
analytics) • different performance characteristics or hardware requirements • collection-level sharding isn’t appropriate, collections need to stay locally intact • staging or test clusters • remove as much as possible from the critical path Why use multiple clusters instead of just sharding? Multiple MongoDB clusters Friday, April 26, 13
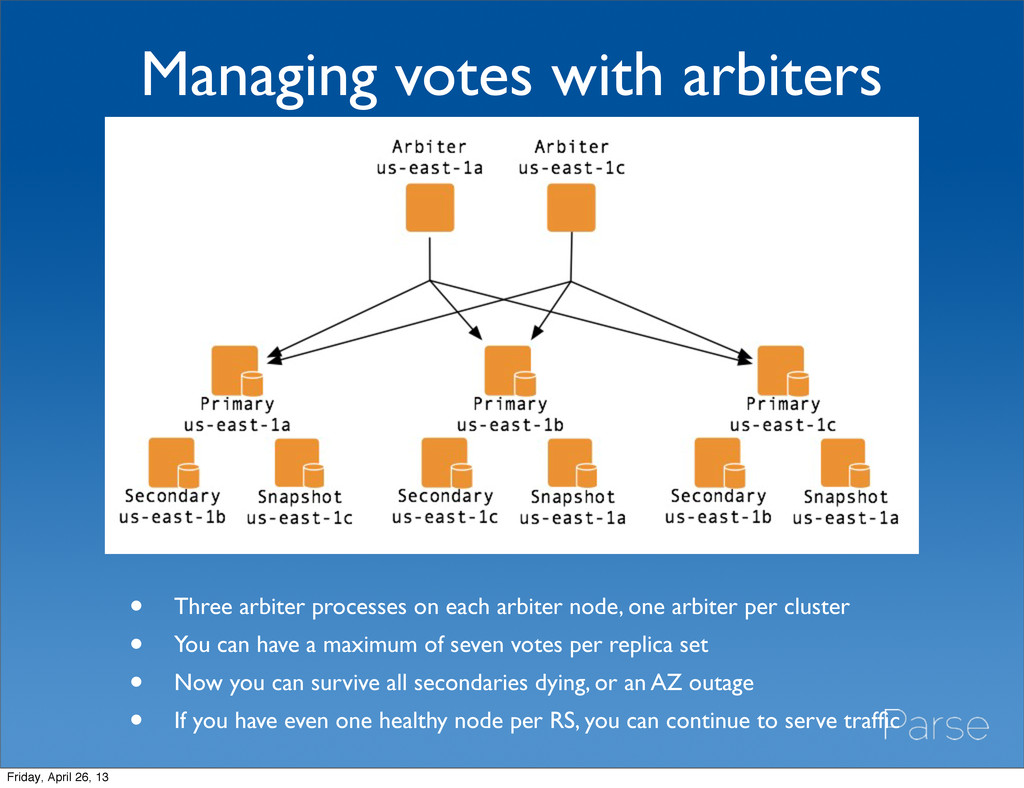
but vote. • They are awesome. They give you more flexibility and reliability. • To provision an arbiter, use the LWRP. • If you have lots of clusters, you may want to run arbiters for multiple clusters on each arbiter host. • Arbiters tend to be more reliable than nodes because they have less to do. Friday, April 26, 13
arbiter node, one arbiter per cluster • You can have a maximum of seven votes per replica set • Now you can survive all secondaries dying, or an AZ outage • If you have even one healthy node per RS, you can continue to serve traffic Friday, April 26, 13
to priority = 0, hidden = 1 • Lock Mongo or stop mongod during snapshot • Always warm up a snapshot before promoting • in mongodb 2.4 you can use db.touch() • warm up both indexes and data, use dd on data files to pull from S3 • http://blog.parse.com/2013/03/07/techniques-for-warming-up-mongodb/ • Run continuous compaction on your snapshot node Friday, April 26, 13
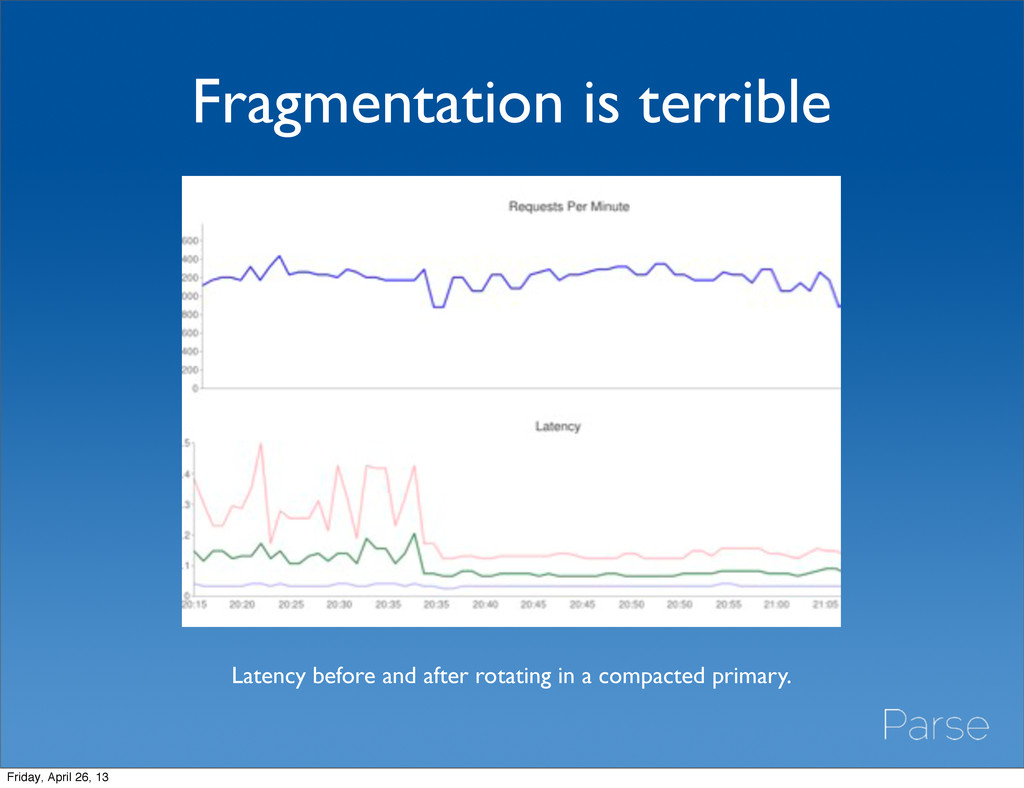
underuse of memory • Deletes are not the only source of fragmentation • db.<collection>.stats to find the padding factor (between 1 - 2, the higher the more fragmentation) • Repair, compact, or reslave regularly (db.printReplicationInfo() to get the length of your oplog to see if repair is a viable option) Friday, April 26, 13
scratch • limited by the size of your data & oplog • very hard on your primary, use rs.syncFrom() or iptables to sync from secondary • Repair your node • also limited by the size of your oplog • can cause small discrepancies in your data • Run continuous compaction on your snapshot node • http://blog.parse.com/2013/03/26/always-be-compacting/ Friday, April 26, 13
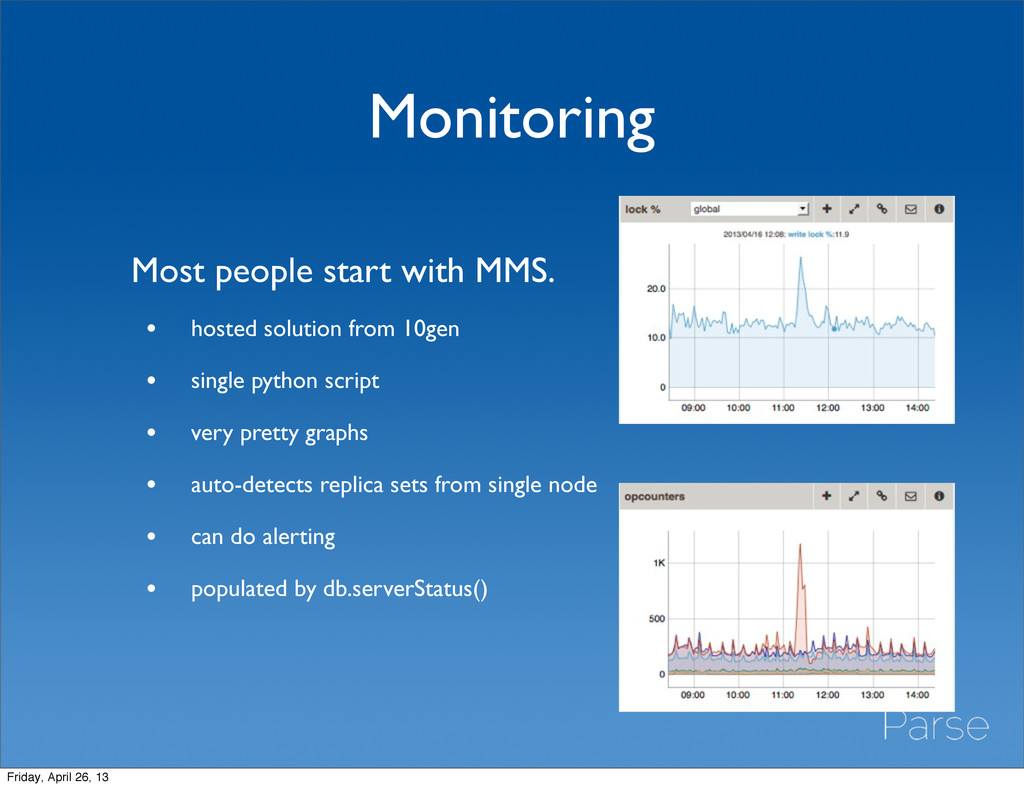
10gen • single python script • very pretty graphs • auto-detects replica sets from single node • can do alerting • populated by db.serverStatus() Friday, April 26, 13
actually goes down, or secondaries are lagging • We use check_mongodb.py extensively • Automatically apply all mongo checks to all mongo nodes with a hostgroup: Friday, April 26, 13
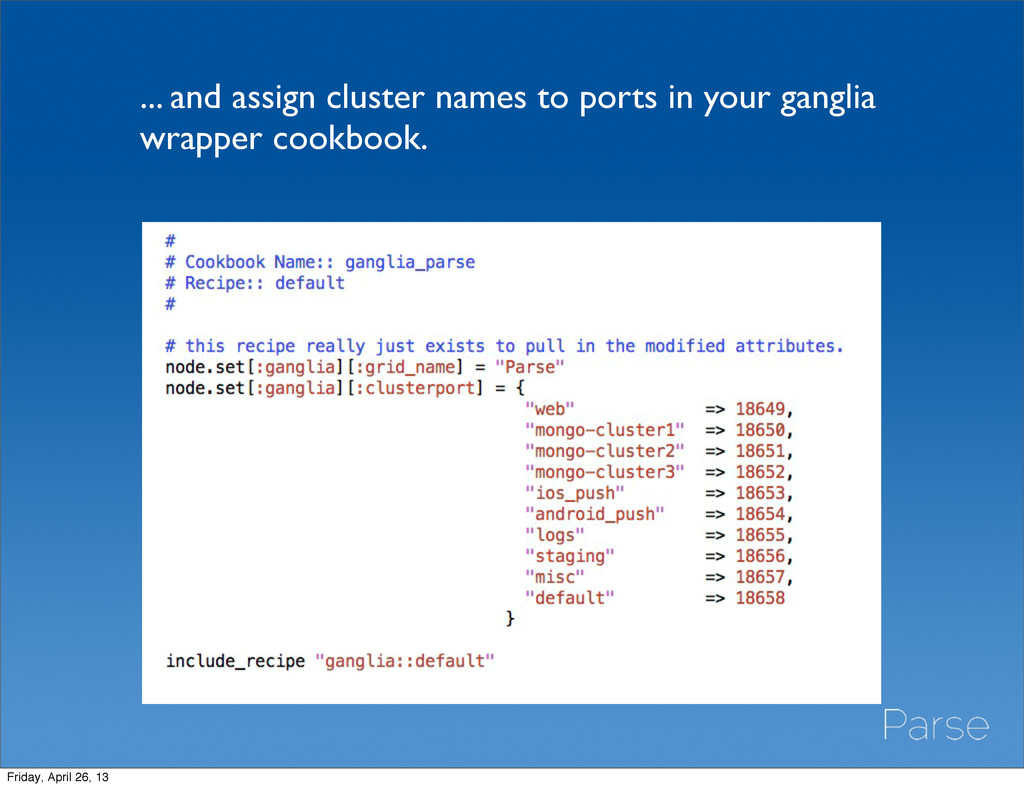
• use mongodb gmond python modules • our fork of the ganglia cookbook supports multiple clusters. Add the cluster name as a role attribute. Friday, April 26, 13
fully upstreamed • Use LWRPs for mongod, mongos, mongoc • Add better support for ephemeral storage • Populate backup volume attributes from backup host • Support bringing up nodes with secondary initial sync • Choose which secondary to sync from via attribute • Optionally auto-join the cluster • Make EBS raid a LWRP • Add ebs_optimized support for PIOPS • ... and more. Friday, April 26, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}