When we start programming we are happy when our code just runs. As we get more experienced, we begin to add more structure to our projects. We start off by dumping all our files into a folder, then we might create subfolders to help organize our work. We might even structure our projects so we can share our work easily with potential collaborators. As our projects grow, we might need to reuse bits and pieces in other projects, and finally consolidate our work into some written report. R has given us the tools to make your projects more structured and organized. And as we start to become more familiar with these tools, you realize that many people converge on very similar project templates. They all aim to make projects clearer, shareable, and simply "work". It doesn't matter where you are in your learning path, you can always benefit from adding a little more structure to your data science projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RStudio projects assume everyone is using RStudio TRUE ## [1]](https://files.speakerdeck.com/presentations/cdb39956b18b4f4dbc58dd3b6d5f4a21/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
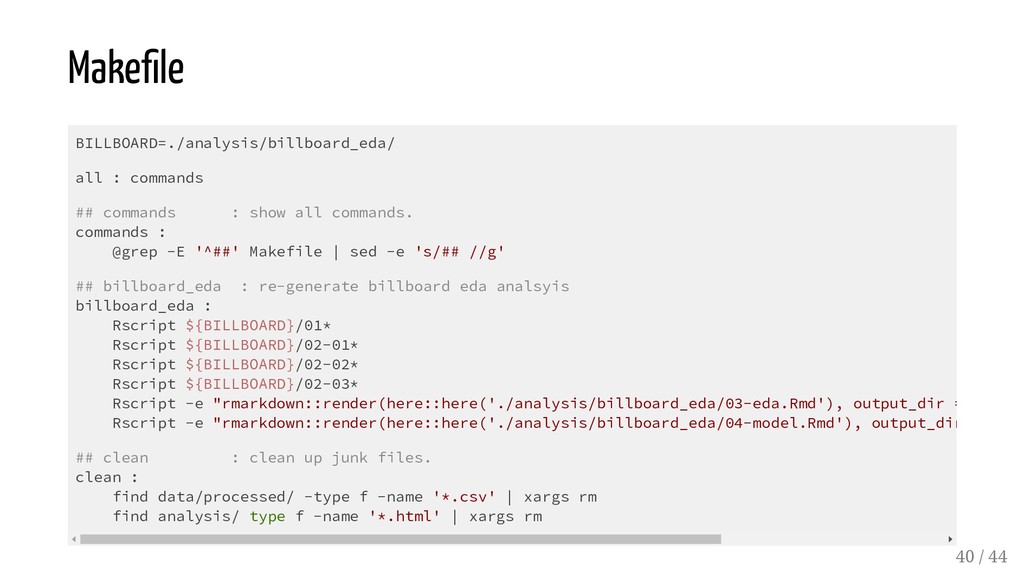{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}