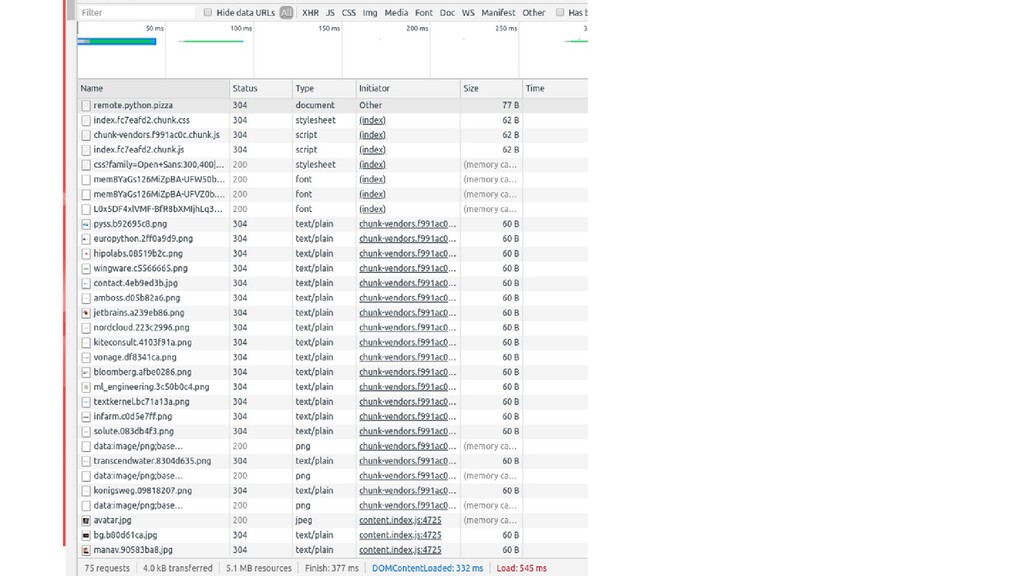
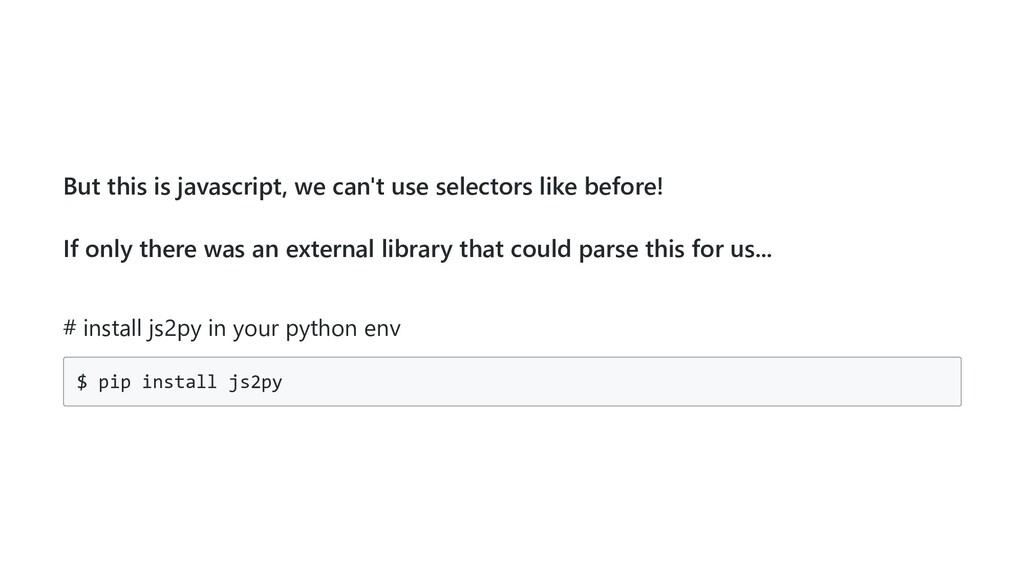
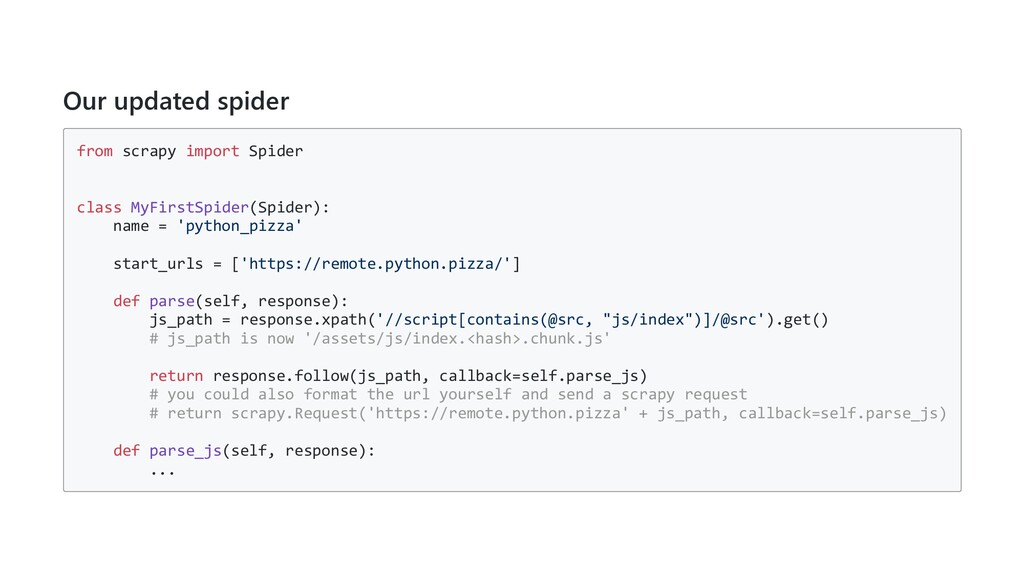
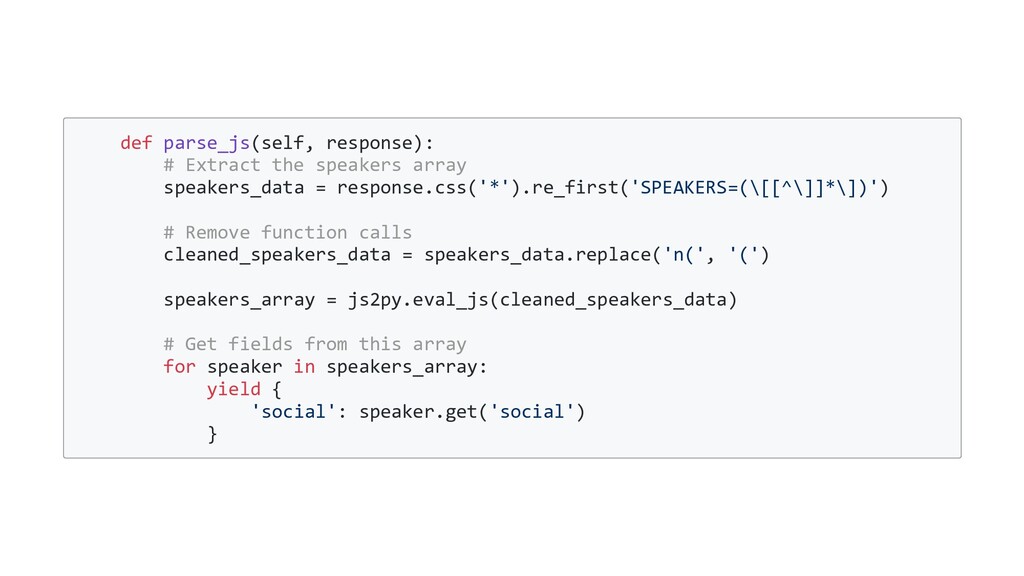
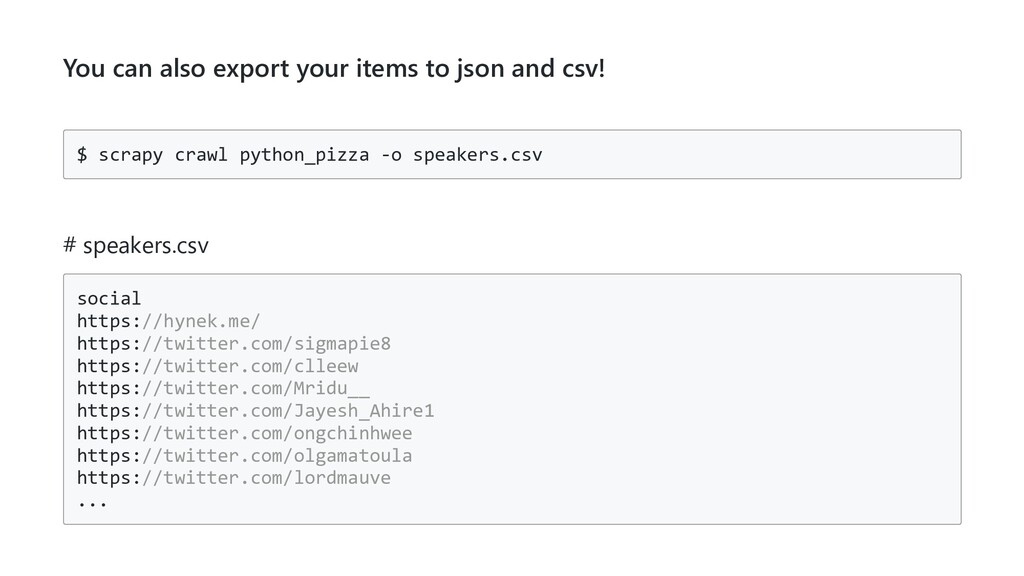
= 'python_pizza' start_urls = ['https://remote.python.pizza/'] def parse(self, response): js_path = response.xpath('//script[contains(@src, "js/index")]/@src').get() # js_path is now '/assets/js/index.<hash>.chunk.js' return response.follow(js_path, callback=self.parse_js) # you could also format the url yourself and send a scrapy request # return scrapy.Request('https://remote.python.pizza' + js_path, callback=self.parse_js) def parse_js(self, response): ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}