12th) 1. FRONT MATTER ANNOUNCEMENTS Please sit at the same computer you worked at last class! We’ll be putting final project workgroups together this week.
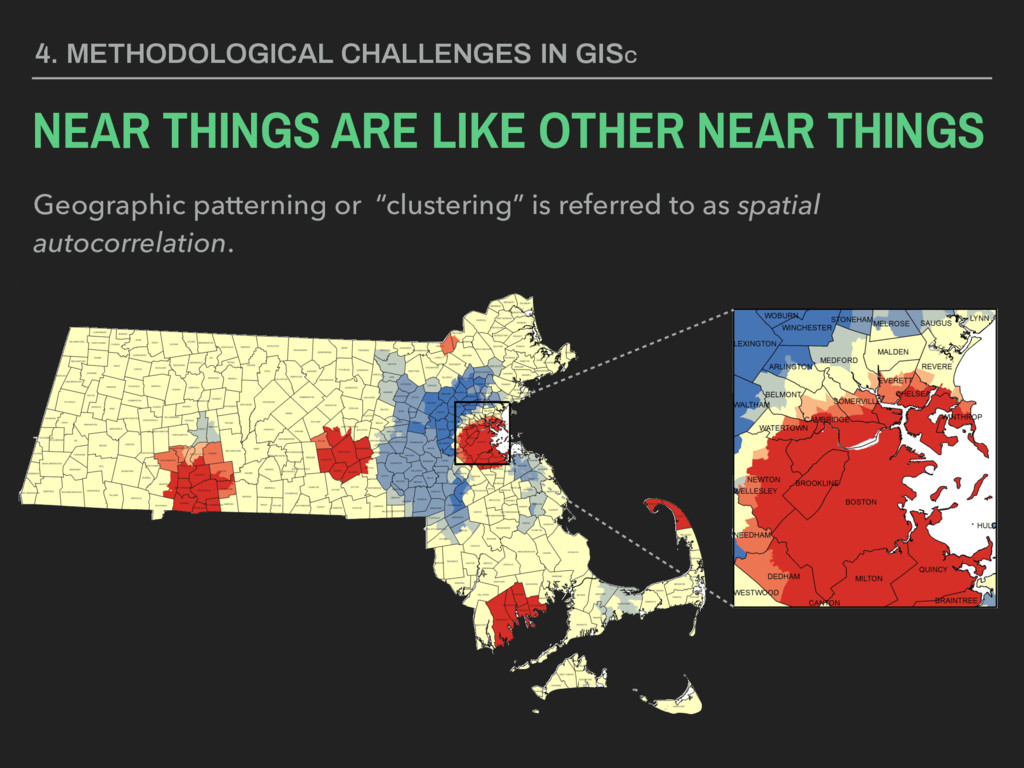
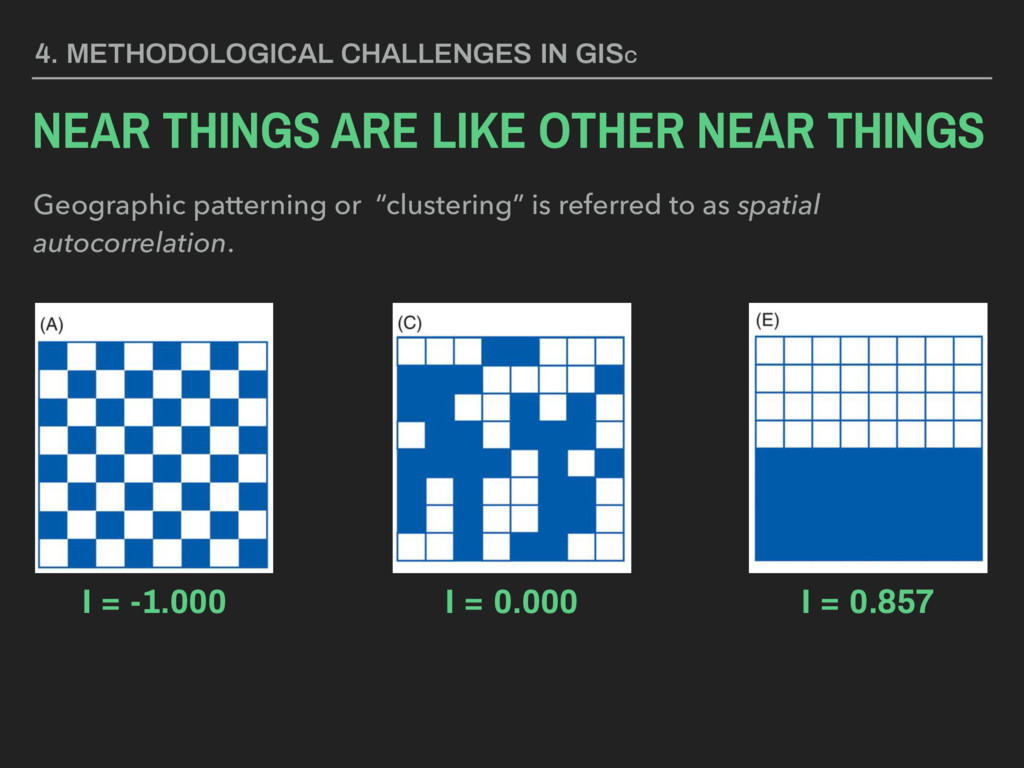
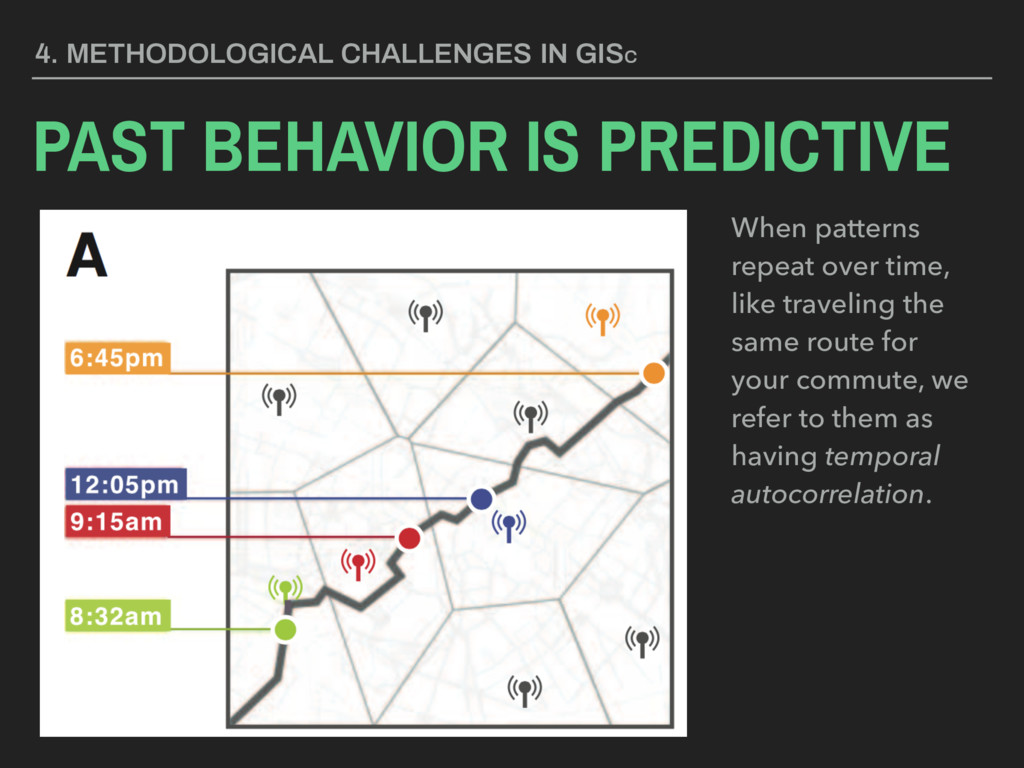
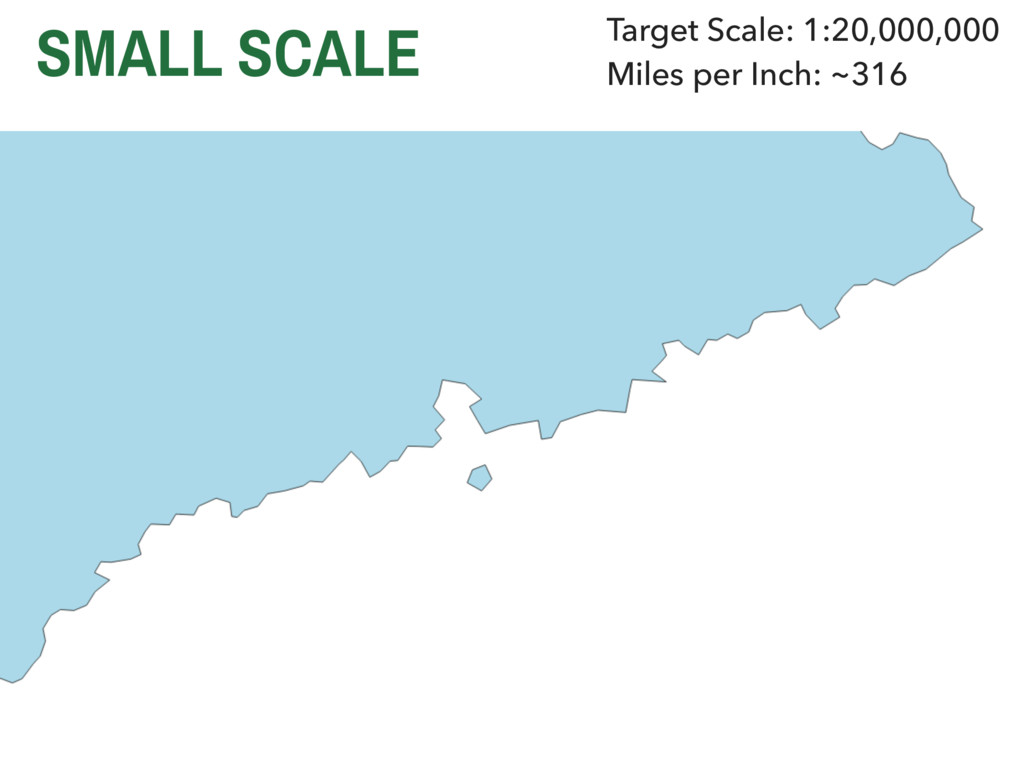
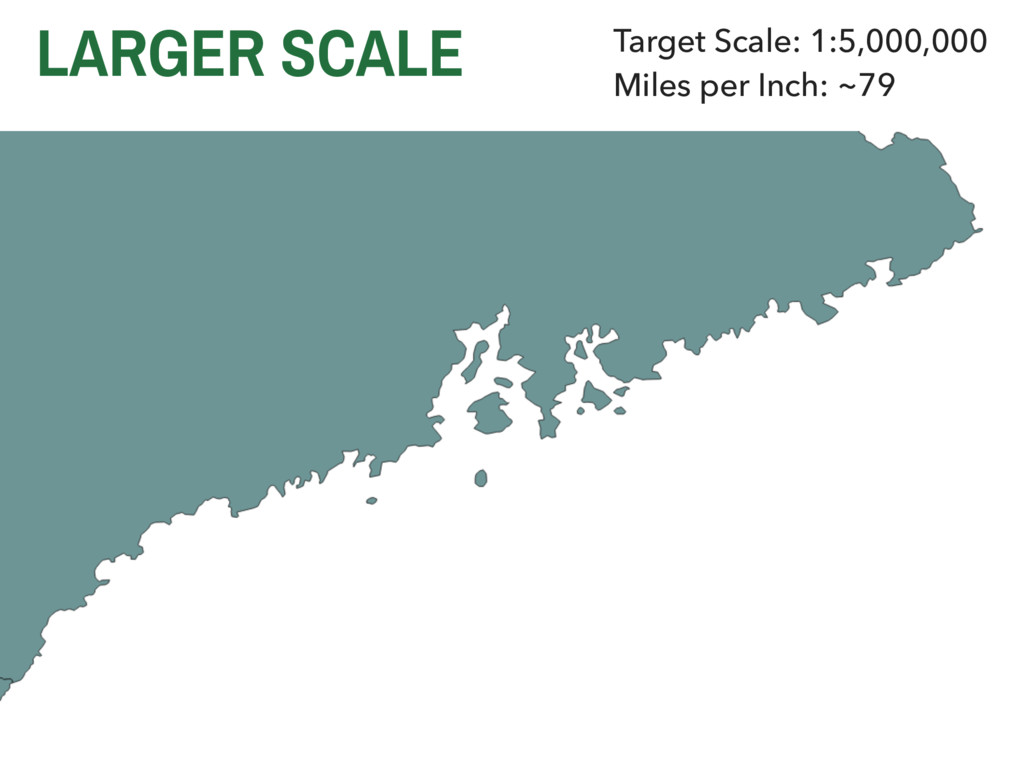
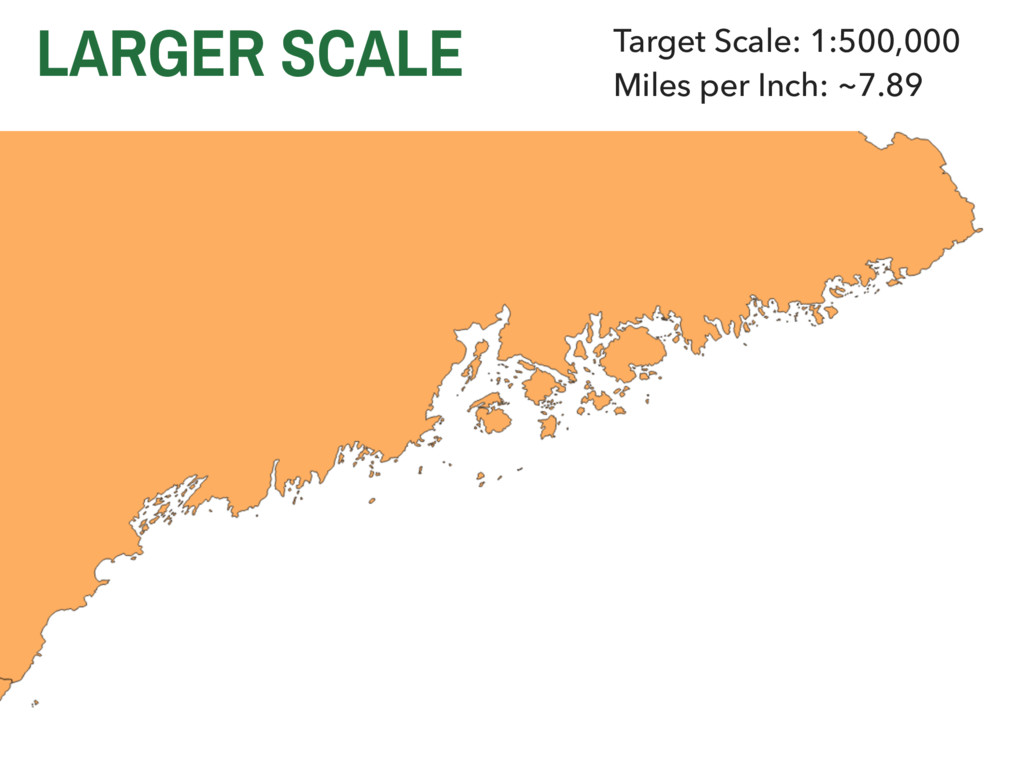
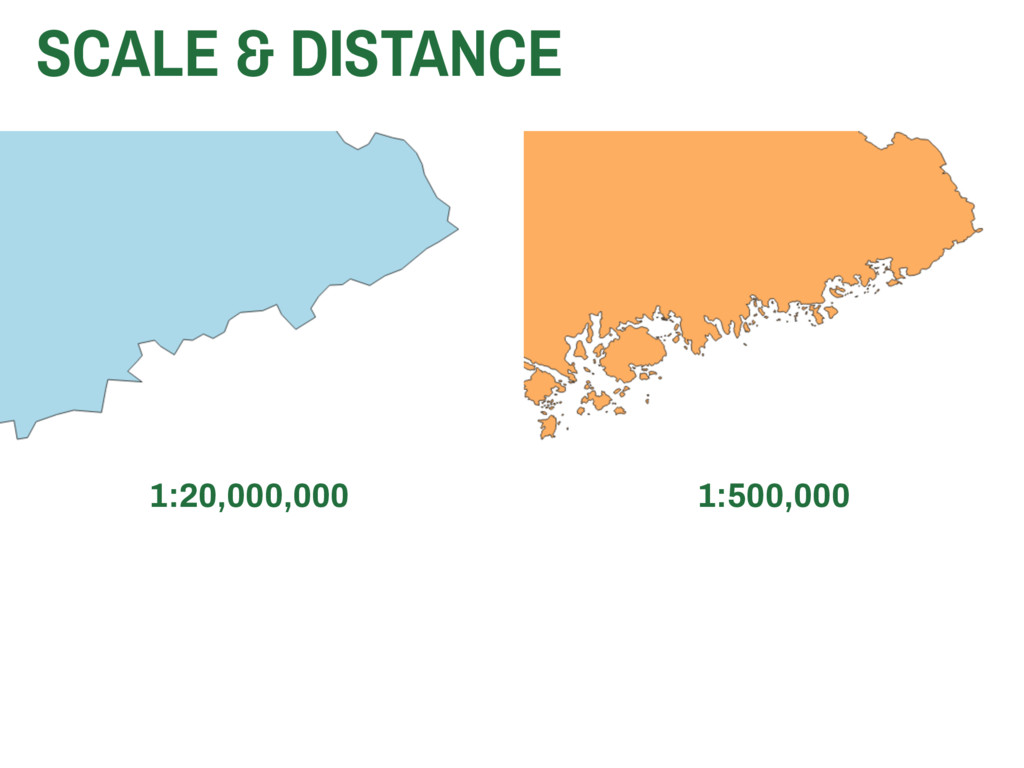
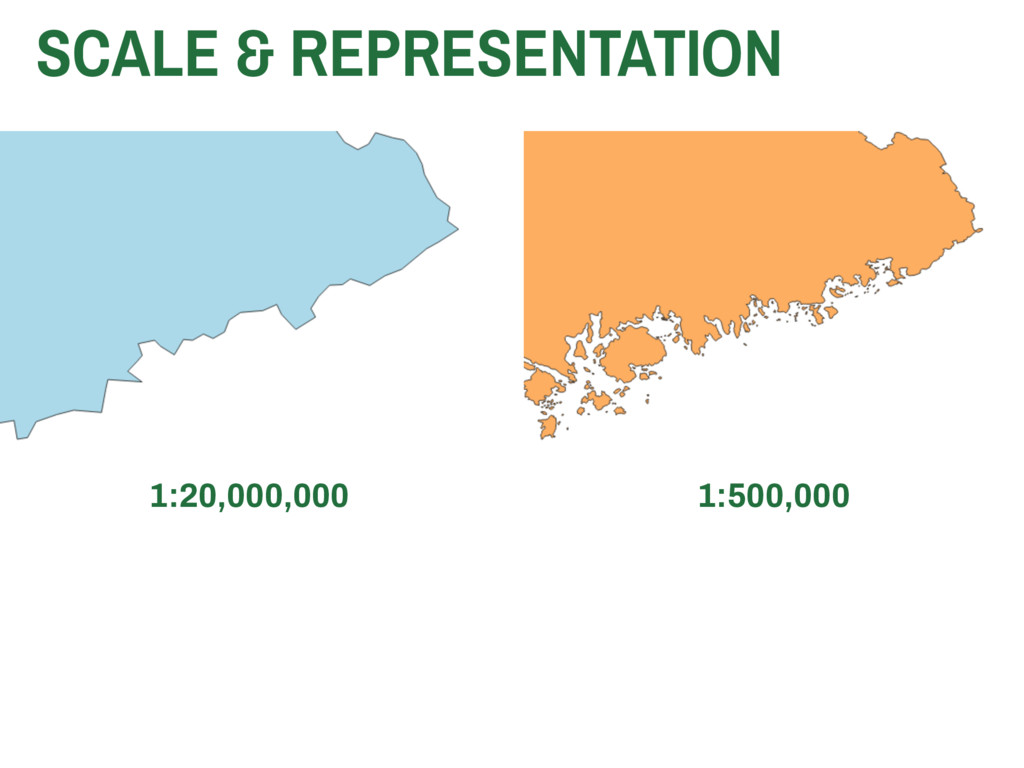
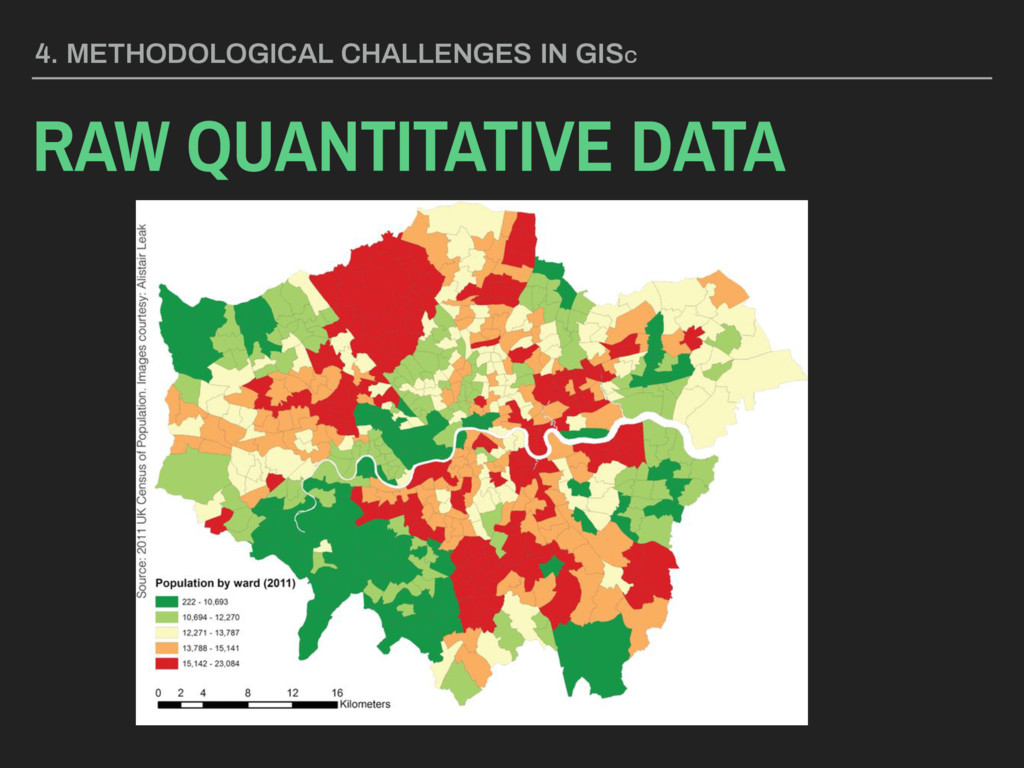
they collected? ▸ Are these data valid? ▸ How are these data measured? ▸ Are they representative? ▸ Are these data appropriate for the question or application at hand? 4. METHODOLOGICAL CHALLENGES IN GISC SPATIAL SAMPLING
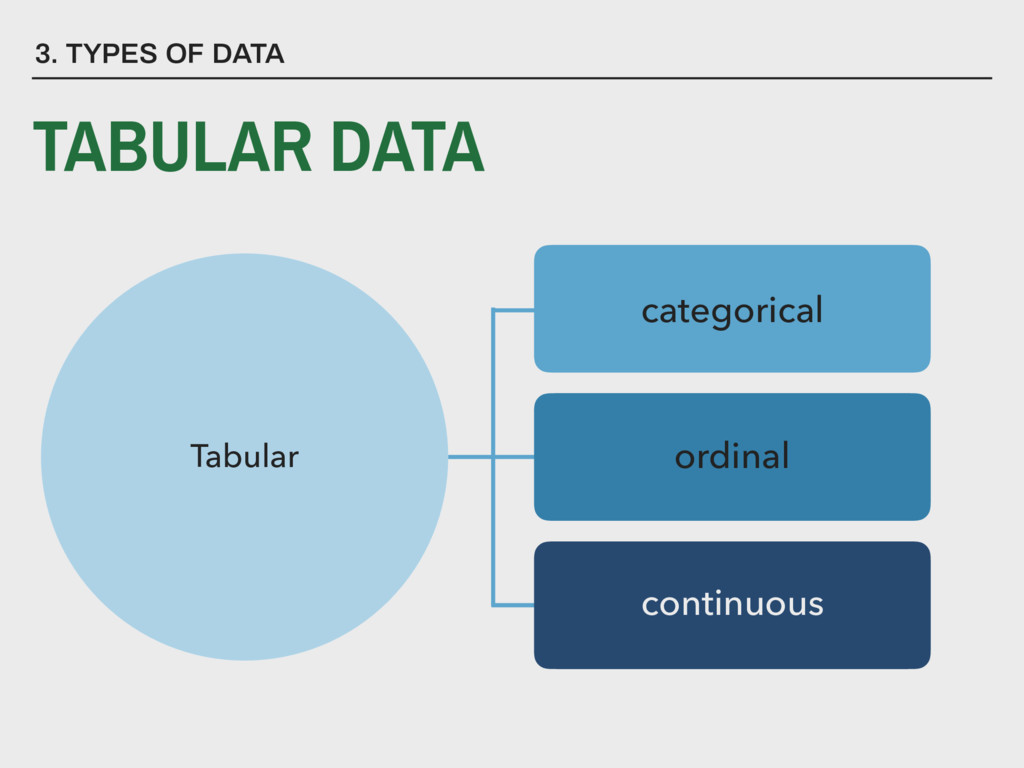
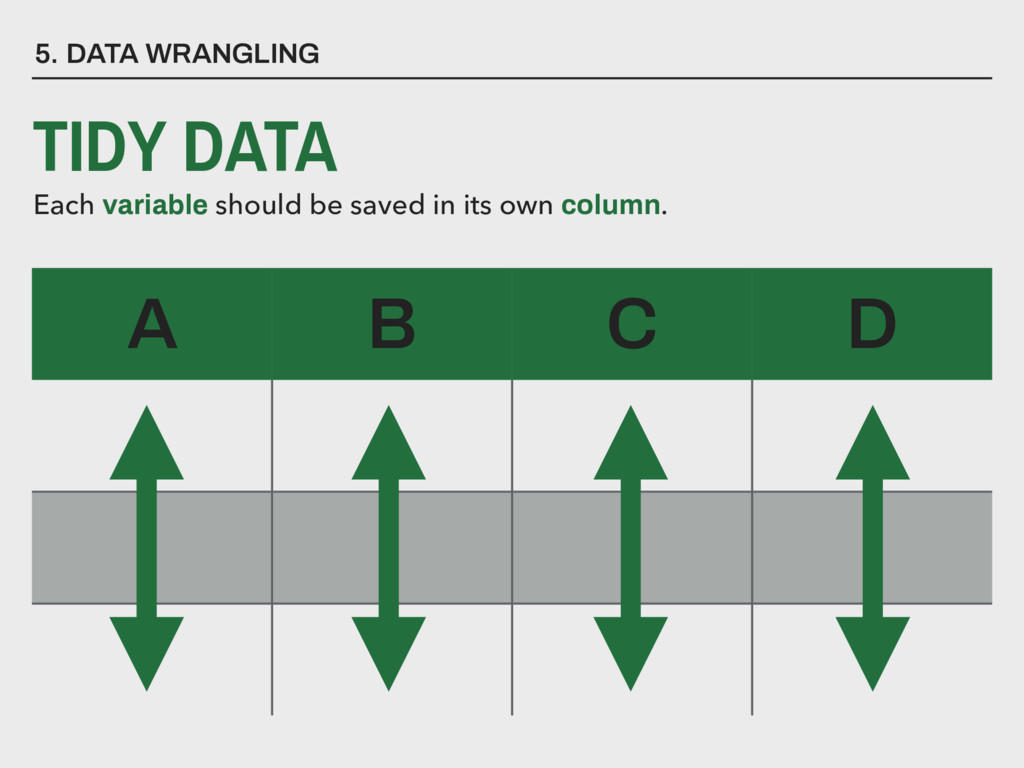
▸ Are variables stored in the format that makes the most sense for their data? ▸ Do variables represent one and only one construct? ▸ Is there a unique identification variable? ▸ Is there missing or incomplete data? 5. DATA WRANGLING A B VARIABLES
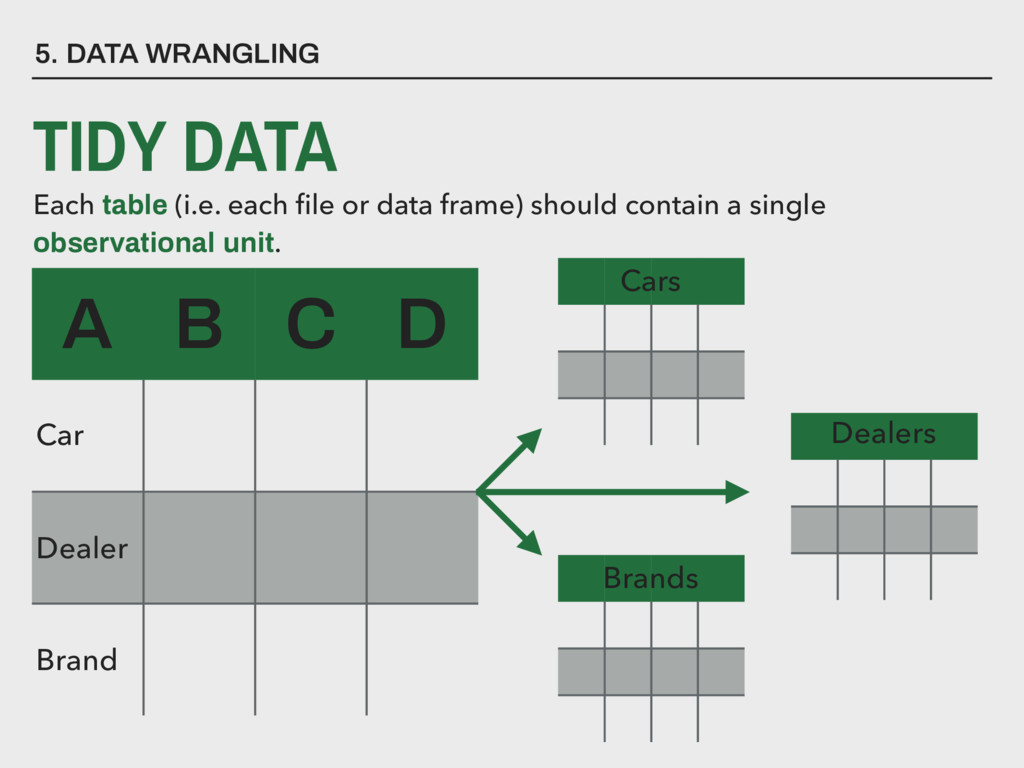
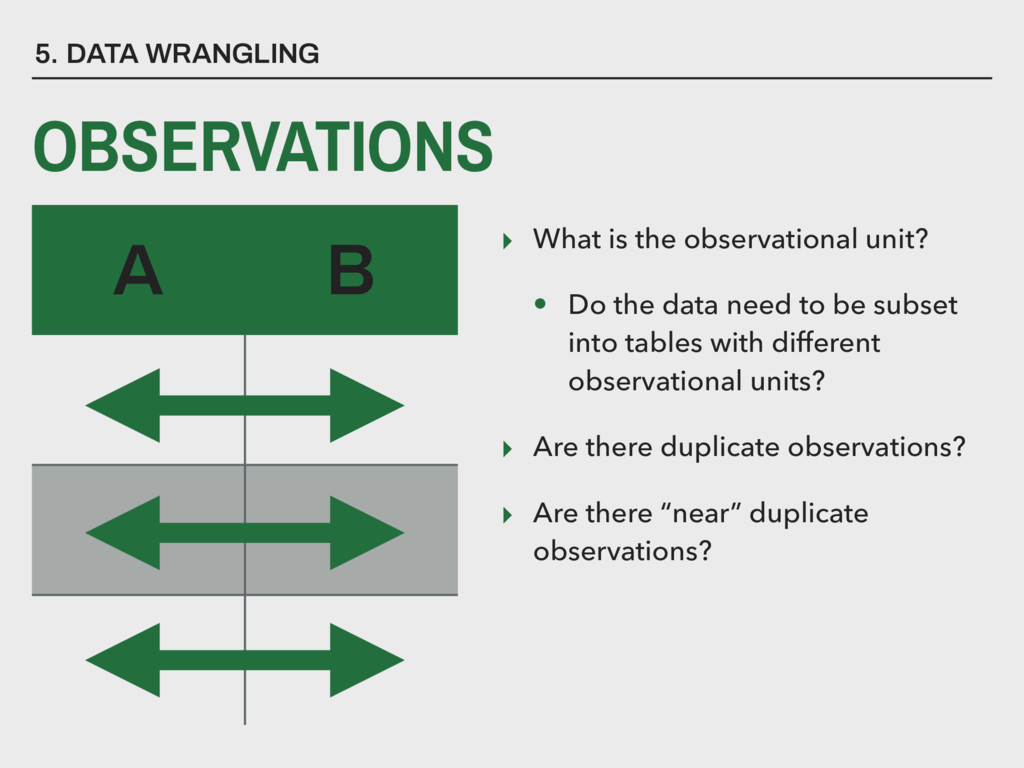
need to be subset into tables with different observational units? ▸ Are there duplicate observations? ▸ Are there “near” duplicate observations? 5. DATA WRANGLING A B OBSERVATIONS
operator, but we don’t need to load it explicitly ▸ janitor for its data cleaning functions ▸ dplyr for data wrangling functions ▸ naniar for missing data analyses 5. DATA WRANGLING PACKAGES
to load Available in readr Download via CRAN as part of tidyverse 5. DATA WRANGLING READING IN TABULAR DATA Parameters: read_csv(“data/filename.csv”) f(x)
a hypothetical file: > leadData <- read_csv(“data/leadData.csv”) The read_csv() is easily confused with read.csv() - these are not the same functions and produce slightly different data frames!
case can take on a range of options, but I recommend using either snake for snake_case or small_camel for camelCase. Available in janitor Download via CRAN 5. DATA WRANGLING RENAMING VARIABLES EN MASSE Parameters: clean_names(.data, case) f(x)
case can take on a range of options, but I recommend using either snake for snake_case or small_camel for camelCase. 5. DATA WRANGLING RENAMING VARIABLES EN MASSE Parameters: clean_names(.data, case) f(x)
Using the stlLead data from stlData: > leadData <- clean_names(leadData, case = “snake”) It doesn’t really matter how you name variables as long as there are (a) no spaces in the name and (b) you name them consistently and clearly.
newName is the new variable name you want to use ▸ oldName is the current name of the variable Available in dplyr Download via CRAN as part of tidyverse 5. DATA WRANGLING RENAMING A SINGLE VARIABLE Parameters: rename(.data, newName = oldName) f(x)
newName is the new variable name you want to use ▸ oldName is the current name of the variable 5. DATA WRANGLING RENAMING A SINGLE VARIABLE Parameters: rename(.data, newName = oldName) f(x)
= oldName) Using the povertyU18 variable from stlData’s stlLead data: > leadData <- rename(leadData, povertyKids = povertyU18) It doesn’t really matter how you name variables as long as there are (a) no spaces in the name and (b) you name them consistently and clearly.
“snake”) %>% rename(pvty_u18 = poverty_u_18) %>% rename(pvty_u18_moe = poverty_u_18_moe) -> leadData ``` 1. Take the leadData data frame, then 2. standardize all of the variable names to snake_case, then 3. rename poverty_u_18 to pvty_u18, then 4. rename poverty_u_18_moe to pvty_u18_moe, and 5. assign the changes to leadData.
them focused on a single group of tasks, like renaming variables 3. Remember not to include the data frame reference for functions in the pipeline 4. Some functions are not compatible (or at least easily compatible) with the pipe operator
varList can be optionally specified to look for duplicates in only one variable or in a list of variables Available in janitor Download via CRAN 5. DATA WRANGLING FIND DUPLICATE VALUES Parameters: get_dupes(.data, varList) f(x)
varList can be optionally specified to look for duplicates in only one variable or in a list of variables 5. DATA WRANGLING FIND DUPLICATE VALUES Parameters: get_dupes(.data, varList) f(x)
varName is either an existing variable you want to edit or a new variable you want to create ▸ expression is the current name of the variable Available in dplyr Download via CRAN as part of tidyverse 5. DATA WRANGLING SELECTING VARIABLES Parameters: select(.data, varList) f(x)
stlLead data from stlData: > elevateData <- select(leadData, geoID, pctElevated) This variation of select() will keep the listed variables in your data frame.
stlLead data from stlData: > demoData <- select(leadData, -countTested, —pctElevated) This variation of select() will remove the listed variables in your data frame.
varName is a variable whose characteristics will be used to identify rows to retain ▸ expression provides instructions on how to evaluate that variable (see cookbook handout) 5. DATA WRANGLING SUBSETTING OBSERVATIONS Parameters: filter(.data, expression) f(x)
stlLead data from stlData: > highData <- filter(leadData, pctElevated >= 15) The filter() function will always keep the observations that are evaluated as TRUE.
stlLead data from stlData: > highData <- filter(leadData, pctElevated >= 15) This example evaluates each observation of pctElevated to see if its greater than or equal to 15. If it is, it retains that row. If it is not, it removes that row.
varName is either an existing variable you want to edit or a new variable you want to create ▸ expression provides instructions on how to alter the variable (see cookbook handout) 5. DATA WRANGLING ALTERING A VARIABLE Parameters: mutate(.data, varName = expression) f(x)
expression) Using the pctElevated variable from stlData’s stlLead data: > leadData <- mutate(leadData, leadData = ifelse(pctElevated >= 15, “high”, “low”)) The ifelse() function evaluates a statement to be either TRUE or FALSE for each observation. If TRUE, it returns the first value (high in this case). If FALSE, it returns the second.
expression) Using the pctElevated variable from stlData’s stlLead data: > leadData <- mutate(leadData, leadData = ifelse(pctElevated >= 15, “high”, “low”)) This example evaluates each observation of pctElevated to see if its greater than or equal to 15. If it is, it enters a value of high in the new variable highLead. If it is not, it enters a value of low in the new variable. Note how quotes are used.
expression) Using the countTested variable from stlData’s stlLead data: > leadData <- mutate(leadData, countTested = ifelse(geoID == 29510118100, 445, countTested)) This example edits a single observation of countTested by using a unique identification variable geoID. It changes the errant value in that observation to 445 while retaining the original values in the remaining observations.
expression) Using the countTested variable from stlData’s stlLead data: > leadData <- mutate(leadData, countTested = as.character(countTested)) This example edits a single observation of countTested by using a unique identification variable geoID. It changes the errant value in that observation to 445 while retaining the original values in the remaining observations.
ifelse(pctElevated >= 15, “high”, “low”)) %>% mutate(countTested = ifelse(geoID == 29510118100, 445, countTested)) -> leadData ``` 1. Take the leadData data frame, then 2. create a new variable named highLead, then 3. fix an errant value in countTested, then 4. assign the changes to leadData.
due next class (February 12th) We’ll be putting final project workgroups together this week. Please close any open GitHub Issues in your assignment repository!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}