Lecture slides for Week 10 of the Saint Louis University Course Quantitative Analysis: Applied Inferential Statistics. These slides cover the topics related to correlation analyses.
val is the number of significant digitsval Available in base Installed with base R 2. MORE WITH KNITR ROUNDING IN R Parameters: round(x, digits = val) f(x)
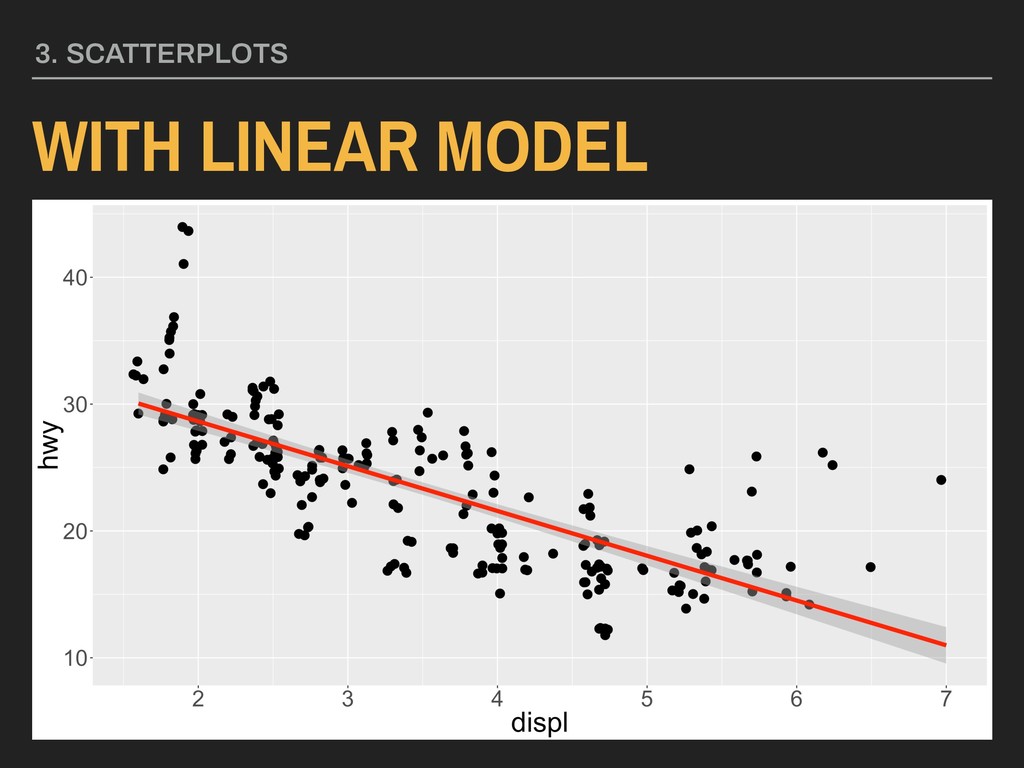
model to use; we’ll focus on using linear models (“lm”) this semester ▸ The hex value will assign a color to the line using a six digit hexadecimal code - you can look up colors on colorhexa.com ▸ You can also specify the aesthetic mapping for x and y, but if this is done in the original ggplot() call, doing so is not necessary. Available in ggplot2 Download via CRAN 3. SCATTERPLOTS WITH LINEAR MODEL Parameters: geom_smooth(method = “lm”, color = “#hex”)
model to use; we’ll focus on using linear models (“lm”) this semester ▸ The hex value will assign a color to the line using a six digit hexadecimal code - you can look up colors on colorhexa.com ▸ You can also specify the aesthetic mapping for x and y, but if this is done in the original ggplot() call, doing so is not necessary. 3. SCATTERPLOTS WITH LINEAR MODEL Parameters: geom_smooth(method = “lm”, color = “#hex”)
“#hex”) Using the hwy and displ variables from ggplot2’s mpg data with points colored by type of drive (drv): ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_point(position = “jitter”) + geom_smooth(method = “lm”, color = “#ff0000”)
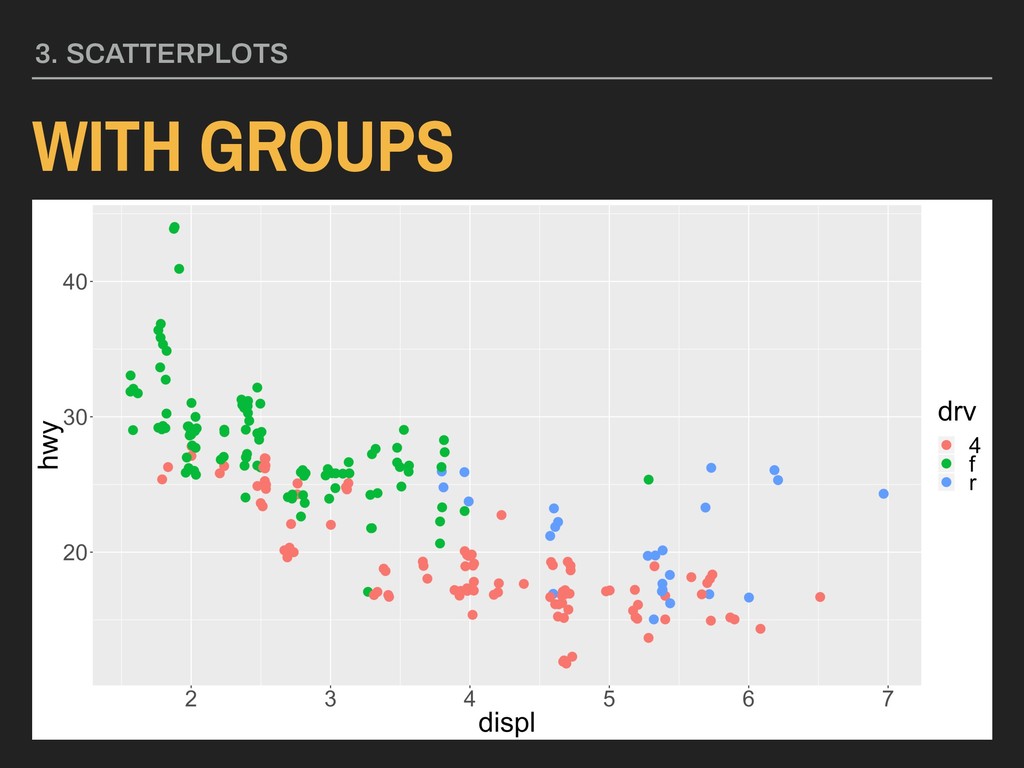
assigned • this should be specified within the aesthetic 3. SCATTERPLOTS WITH GROUPS Parameters: geom_point(mapping = aes(x = xvar, y = yvar, color = groupVar))
= yvar, color = groupVar)) Using the hwy and displ variables from ggplot2’s mpg data with points colored by type of drive (drv): ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point(position = “jitter”)
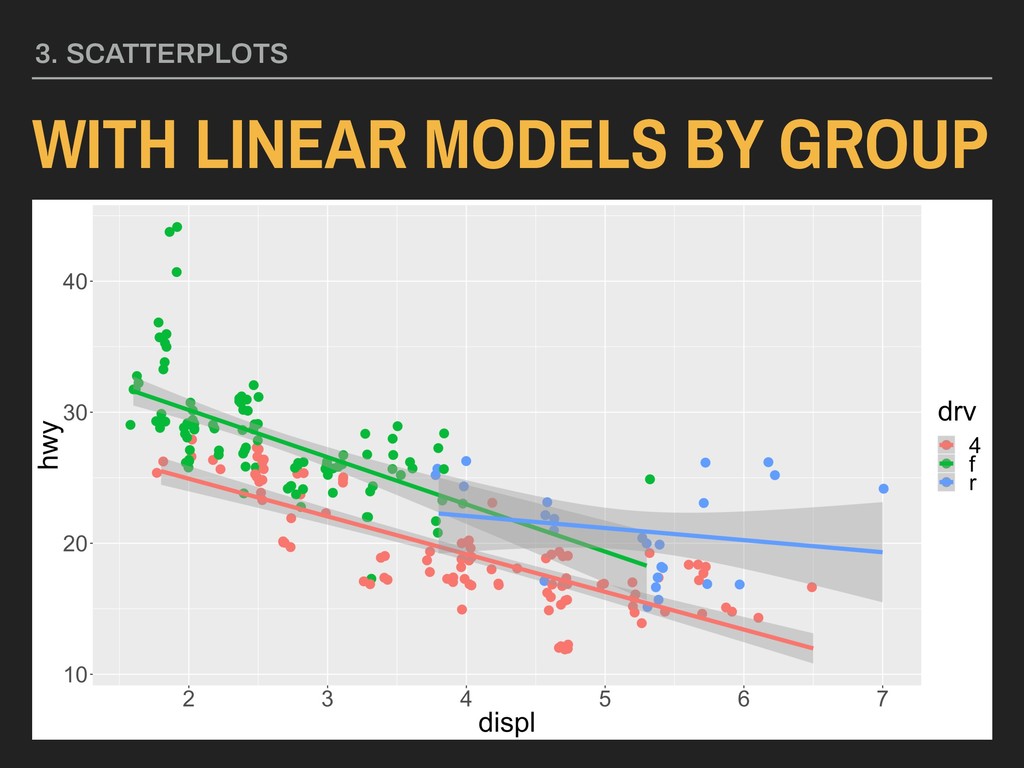
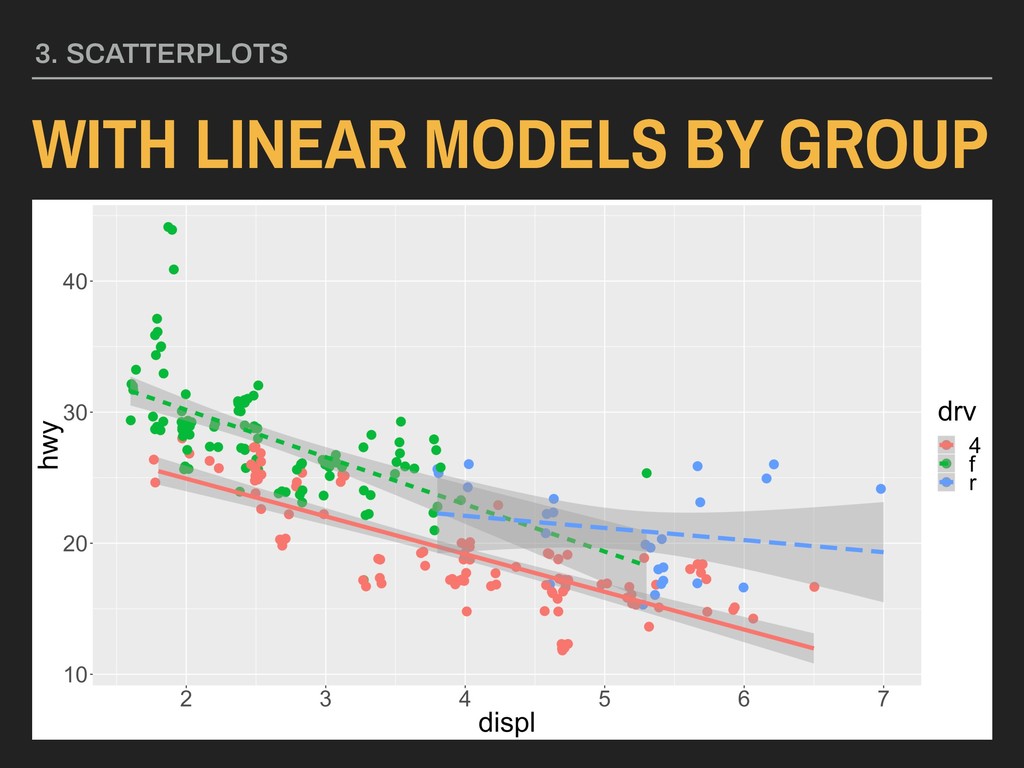
with points colored by type of drive (drv): WITH LINEAR MODELS BY GROUP 3. SCATTERPLOTS ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point(position = “jitter”) + geom_smooth(method = “lm”)
with points colored by type of drive (drv): WITH LINEAR MODELS BY GROUP 3. SCATTERPLOTS ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point(position = “jitter”) + geom_smooth(method = “lm”, mapping = aes(linetype = drv))
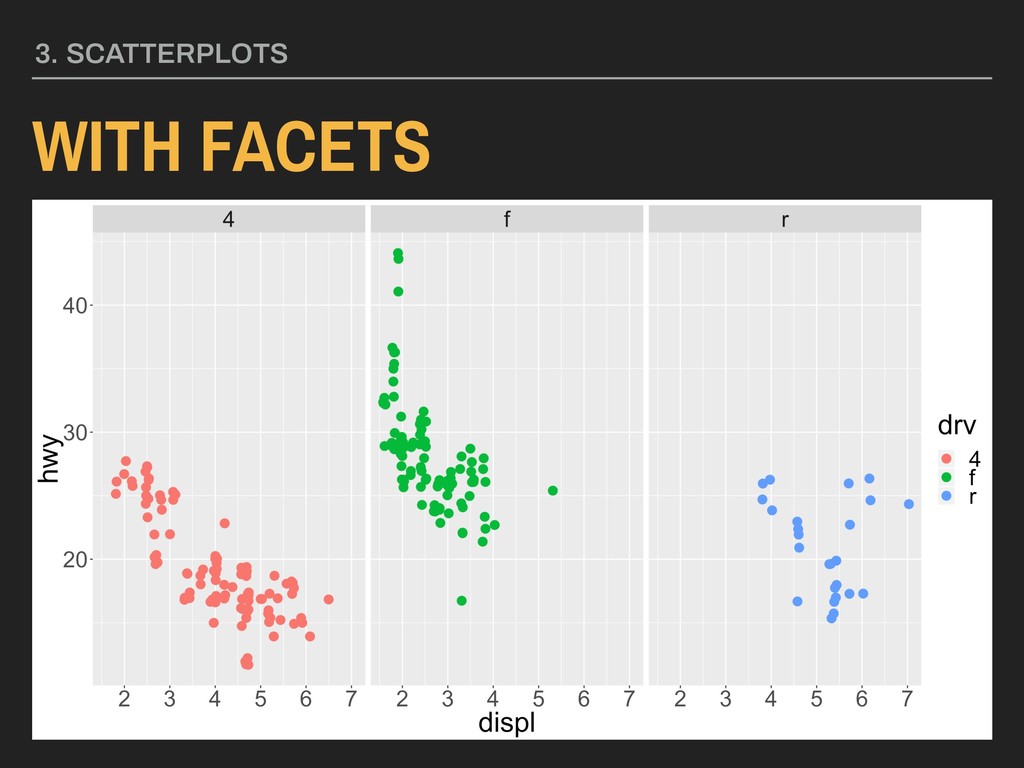
and displ variables from ggplot2’s mpg data with points colored by type of drive (drv): ggplot(data = mpg) + geom_point(aes(x = displ, y = hwy, color = drv), position = “jitter”) + facet_grid(. ~ drv)
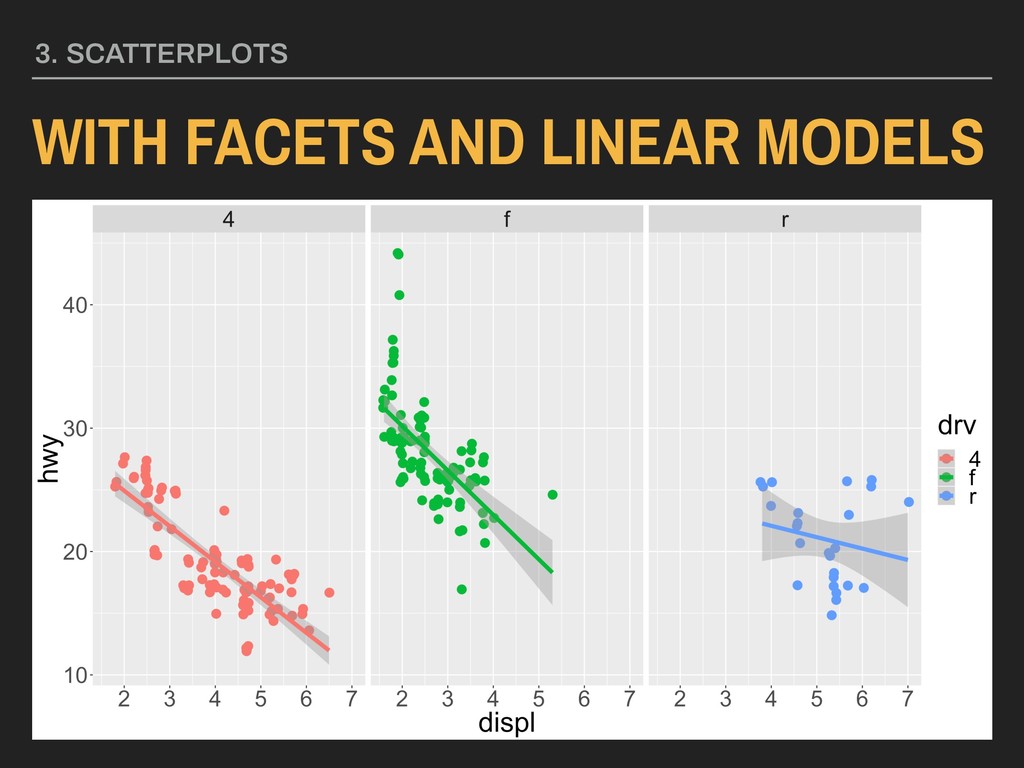
Using the hwy and displ variables from ggplot2’s mpg data with points colored by type of drive (drv): ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point(position = “jitter”) + geom_smooth(method = “lm”) + facet_grid(. ~ drv)
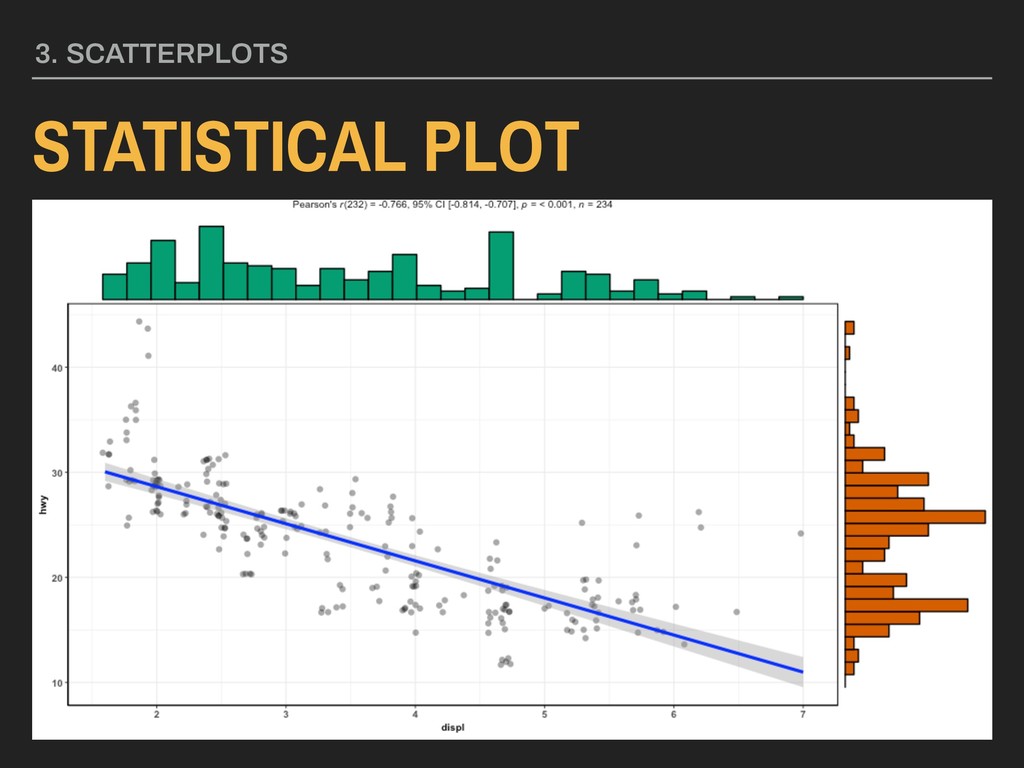
is the x variable ▸ yvar is the y variable Available in ggstatsplot Download via CRAN 3. SCATTERPLOTS STATISTICAL PLOT Parameters: ggscatterstats(data = data, x = xvar, y = yvar)
y = yvar) Using the hwy and displ variables from ggplot2’s mpg data: ggscatterstats(data = mpg, x = hwy, y = displ) This will not create a ggplot object (and will return an error confirming this). Saving process is a bit different.
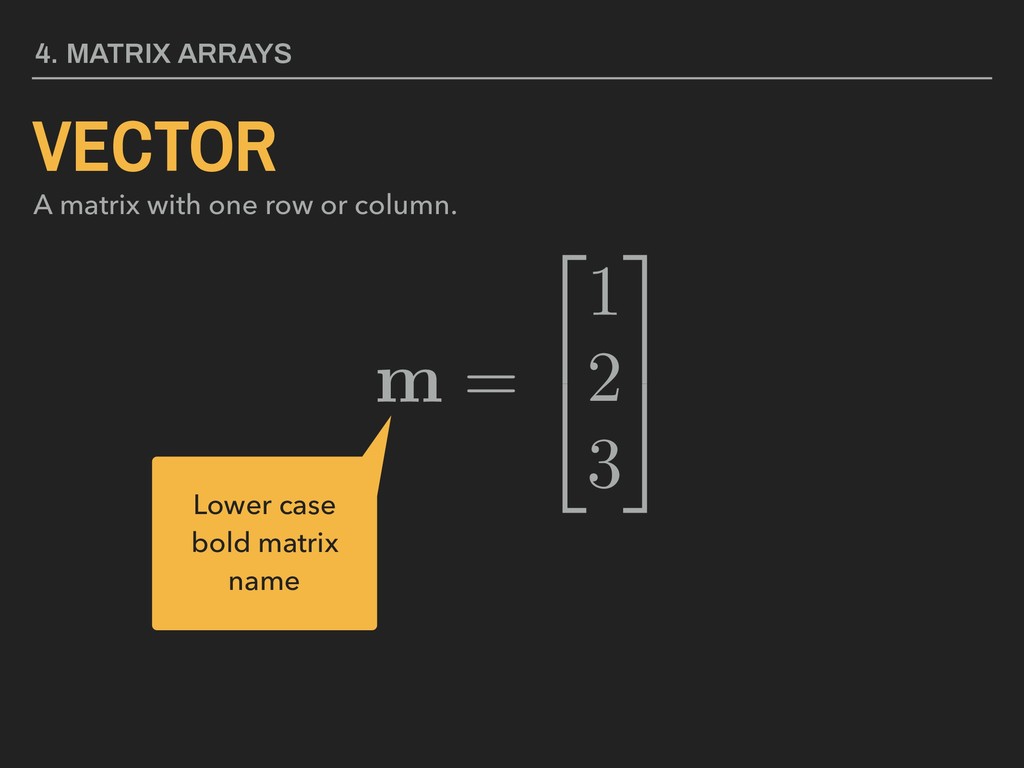
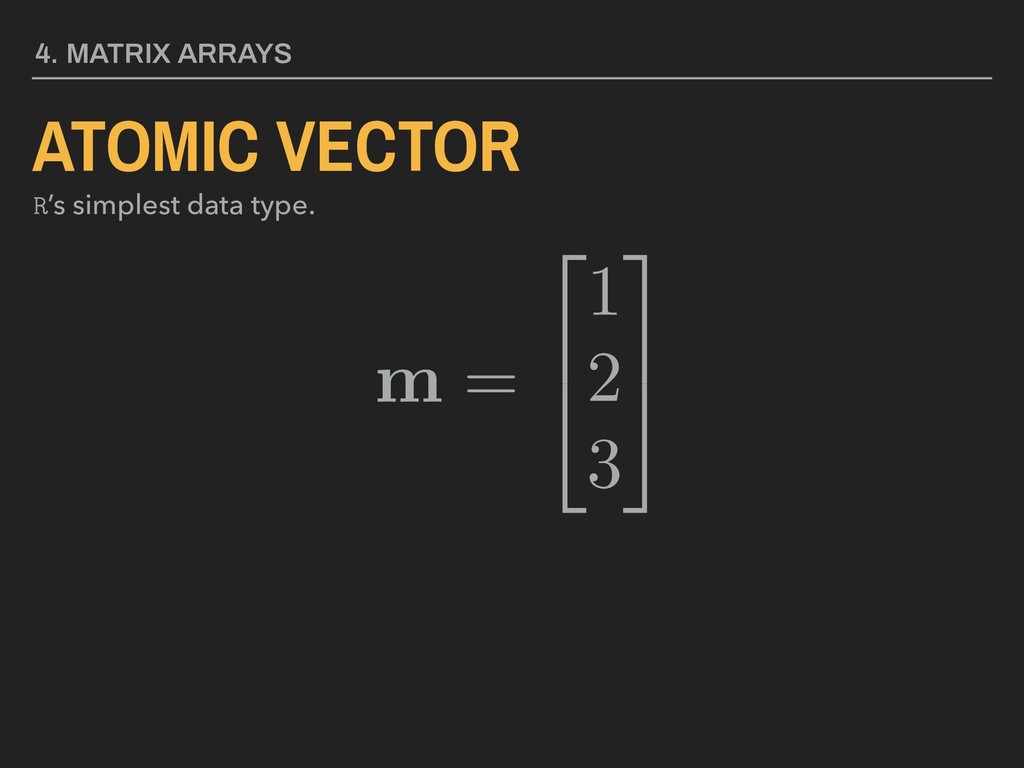
3 5 4. MATRIX ARRAYS MATRIX A collection of values in rows and columns. All values must be of the same data type. Matrix name in bold, upper case lettering Brackets, parentheses, or braces used to enclose values Element
a collection of multiple atomic vectors. Lists may contain vectors of different dimensions and types of data. M = 0 @a = 2 4 1 2 3 3 5 , b = 2 4 2 4 6 3 5 1 A
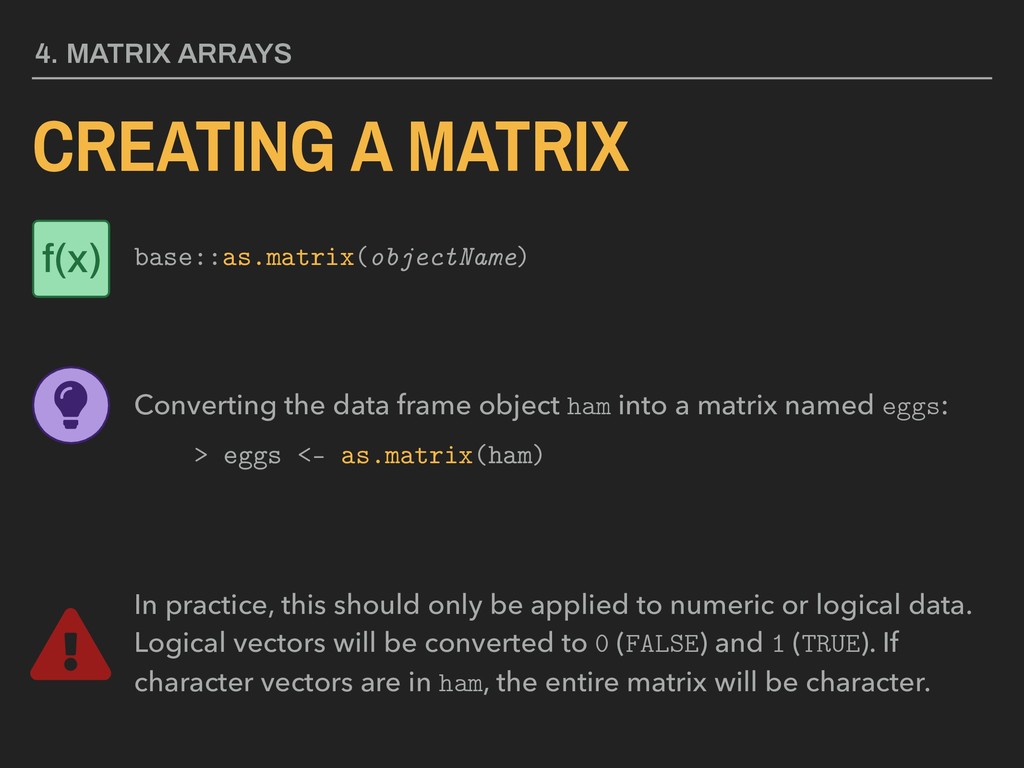
frame object ham into a matrix named eggs: > eggs <- as.matrix(ham) In practice, this should only be applied to numeric or logical data. Logical vectors will be converted to 0 (FALSE) and 1 (TRUE). If character vectors are in ham, the entire matrix will be character. f(x)
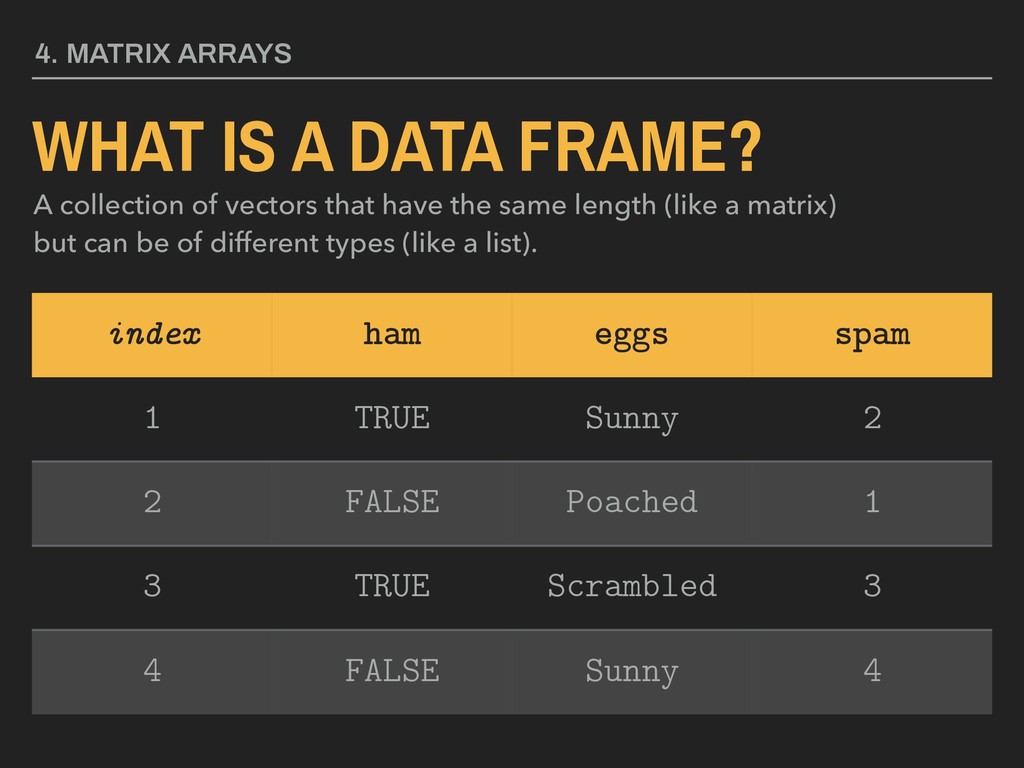
of vectors that have the same length (like a matrix) but can be of different types (like a list). index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1 3 TRUE Scrambled 3 4 FALSE Sunny 4
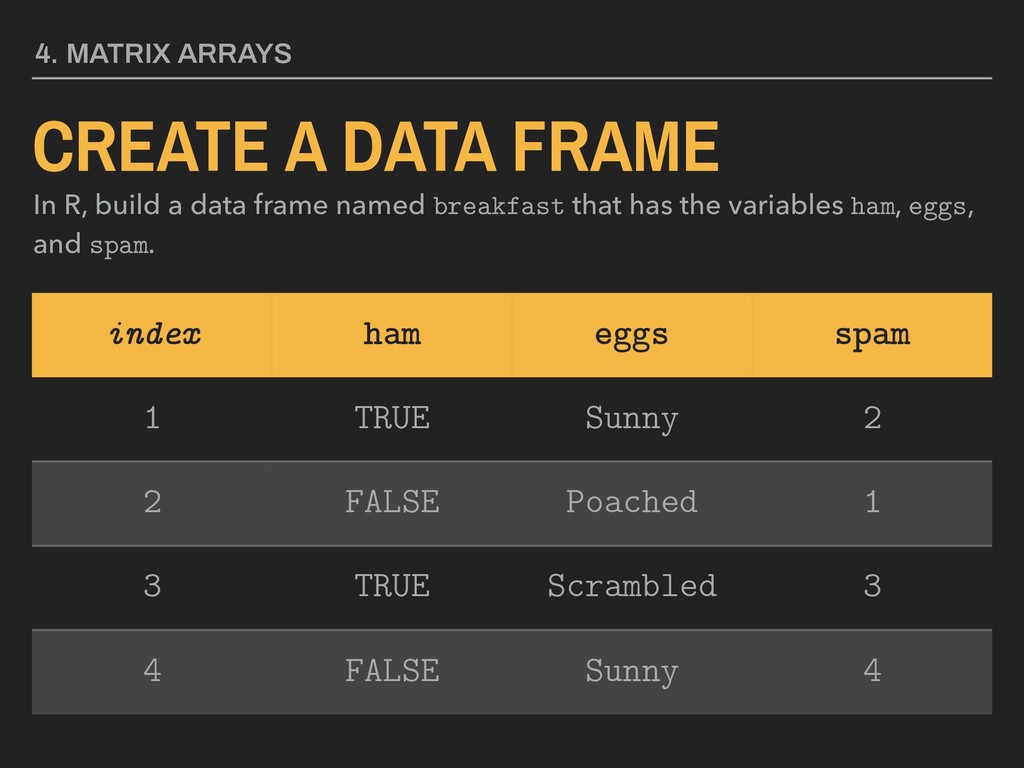
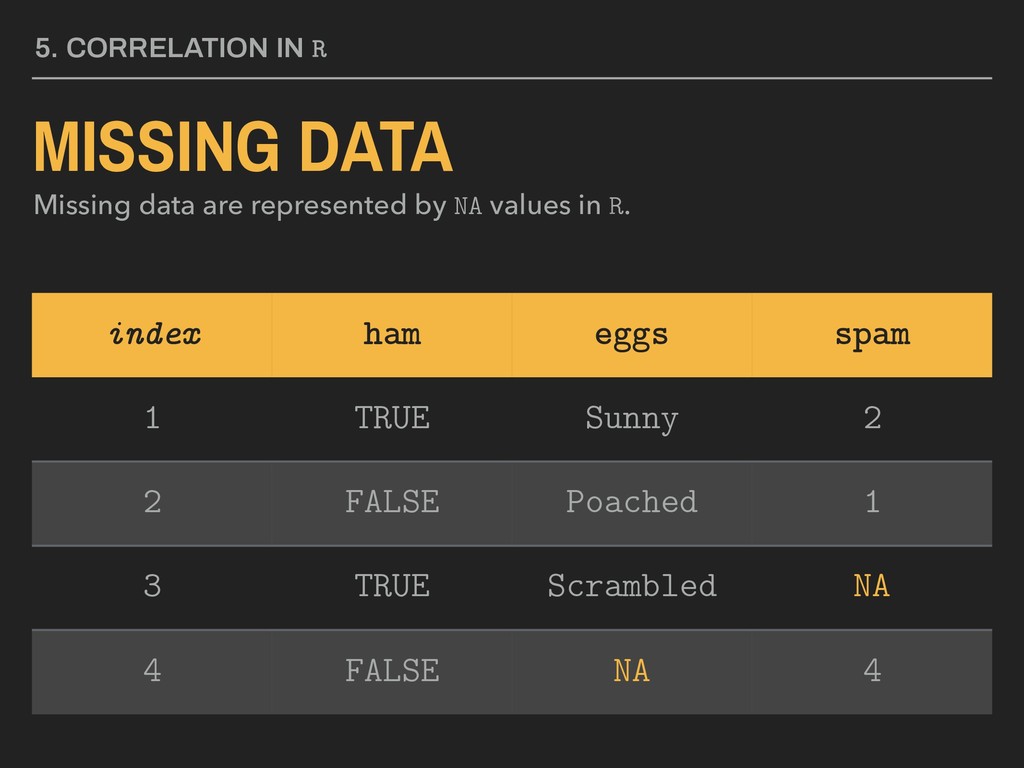
a data frame named breakfast that has the variables ham, eggs, and spam. index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1 3 TRUE Scrambled 3 4 FALSE Sunny 4
functions are often vectorized. But what the $%&# does that mean? f <- function(x){ x*2 } m <- c(2, 4, 6) Let: Output: > f(m) [1] 4 8 12 f(m[1]) f(m[2]) f(m[3]) Under the hood: 4 8 12
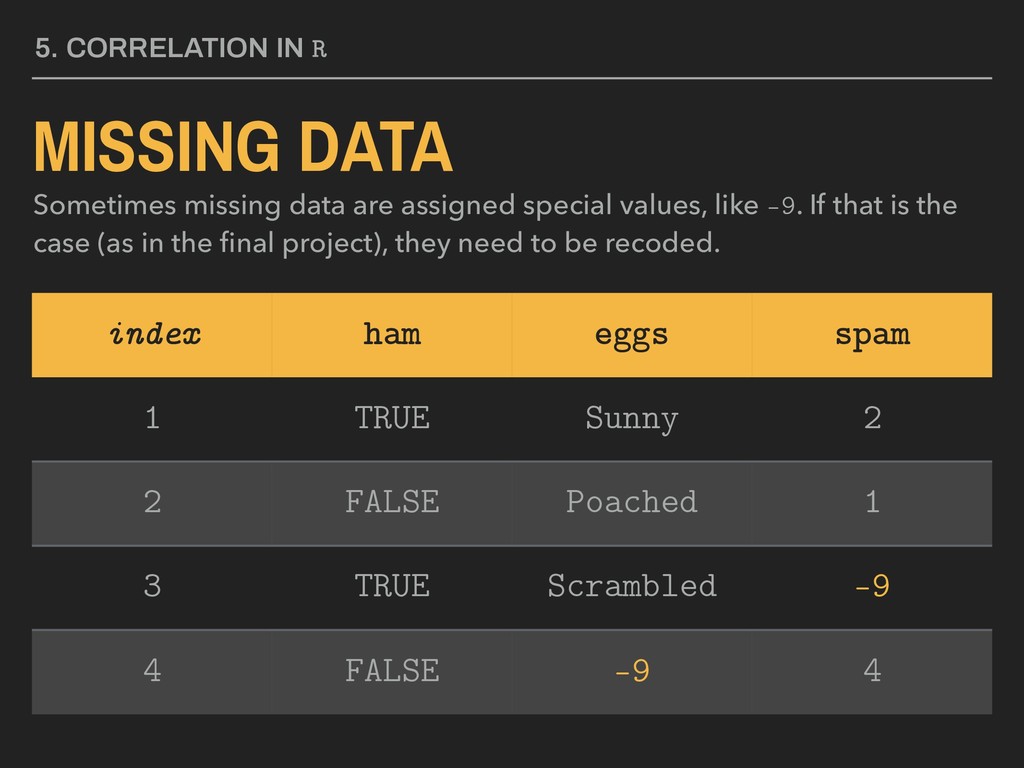
assigned special values, like -9. If that is the case (as in the final project), they need to be recoded. index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1 3 TRUE Scrambled -9 4 FALSE -9 4
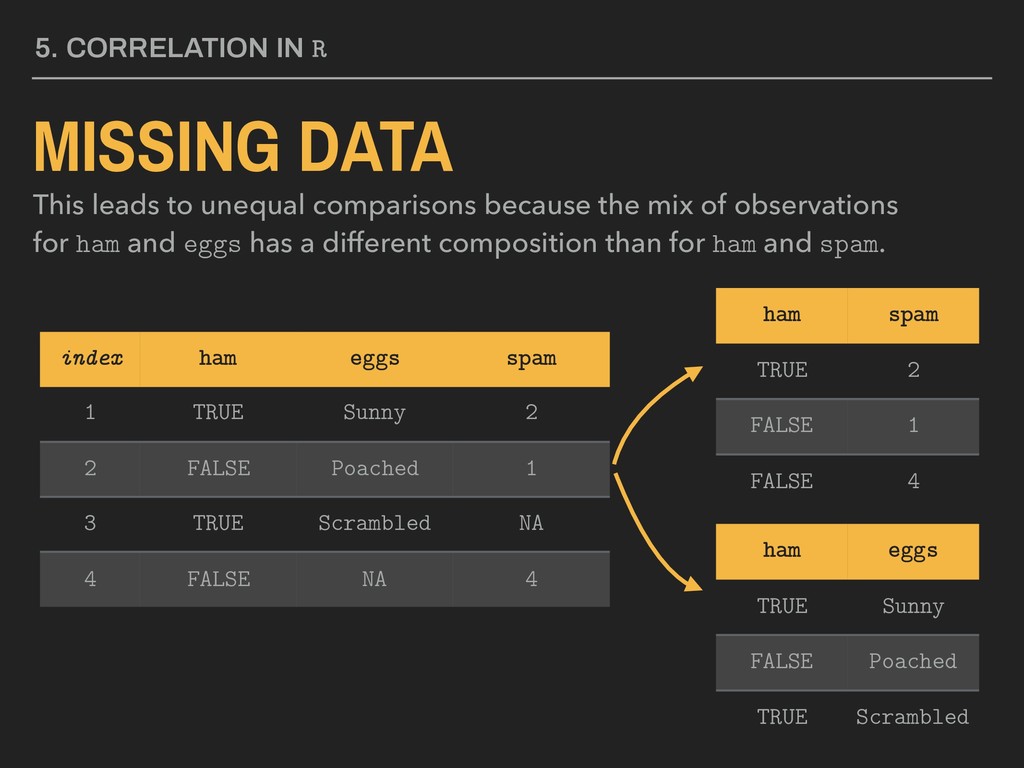
data on a case-by-case basis. ham eggs TRUE Sunny FALSE Poached TRUE Scrambled ham spam TRUE 2 FALSE 1 FALSE 4 index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1 3 TRUE Scrambled NA 4 FALSE NA 4
comparisons because the mix of observations for ham and eggs has a different composition than for ham and spam. ham eggs TRUE Sunny FALSE Poached TRUE Scrambled ham spam TRUE 2 FALSE 1 FALSE 4 index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1 3 TRUE Scrambled NA 4 FALSE NA 4
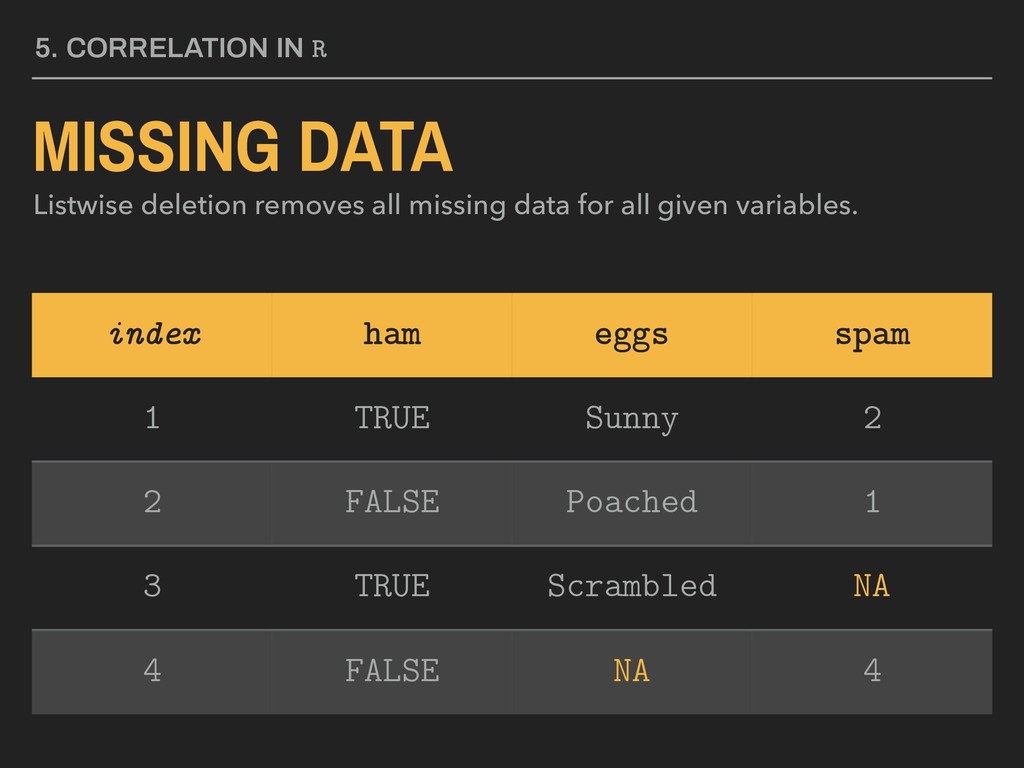
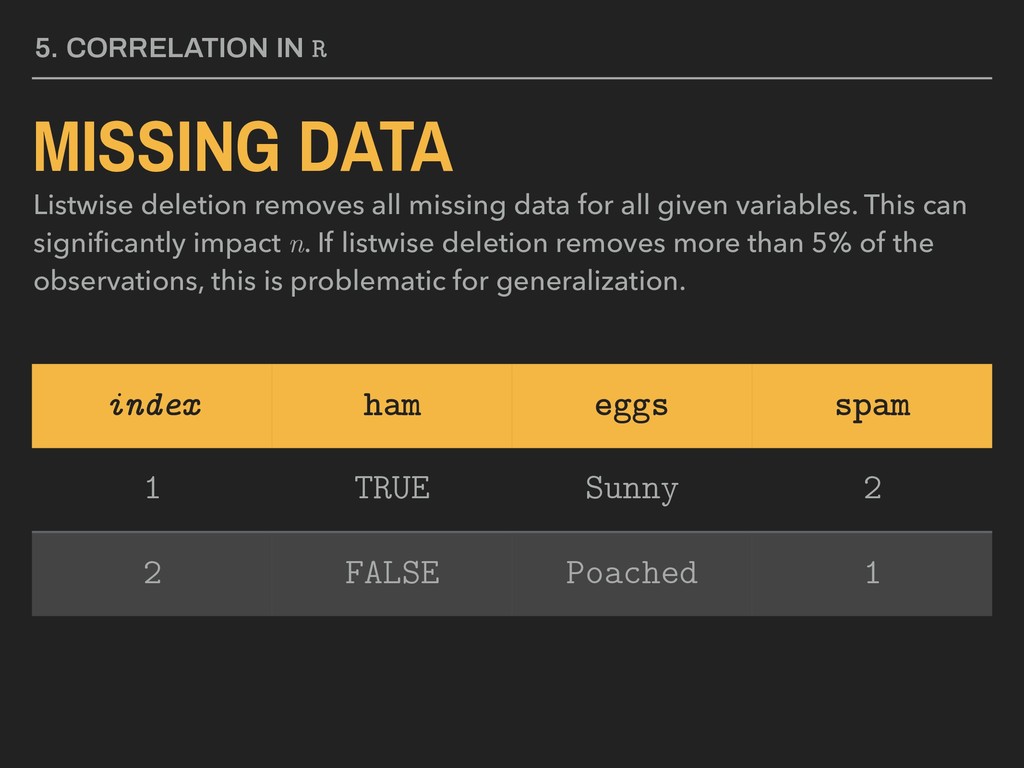
missing data for all given variables. This can significantly impact n. If listwise deletion removes more than 5% of the observations, this is problematic for generalization. index ham eggs spam 1 TRUE Sunny 2 2 FALSE Poached 1
data from dplyr’s starwars data: > sw_listwise <- na.omit(starwars) Document how this impacts your sample size by using the base::nrow() function both before and after you use na.omit(). f(x)
data from dplyr’s starwars data: > sw_listwise <- na.omit(starwars) Make sure to remove all unneeded variables (with dplyr::select()) before performing listwise deletion to avoid inadvertently removing too many observations. f(x)
normally distributed variables ▸ There should be a linear relationship between x and y ▸ Sufficiently large sample size (n >= 30) ▸ There should be no extreme outliers 5. CORRELATION IN R What are the assumptions for Pearson’s r?
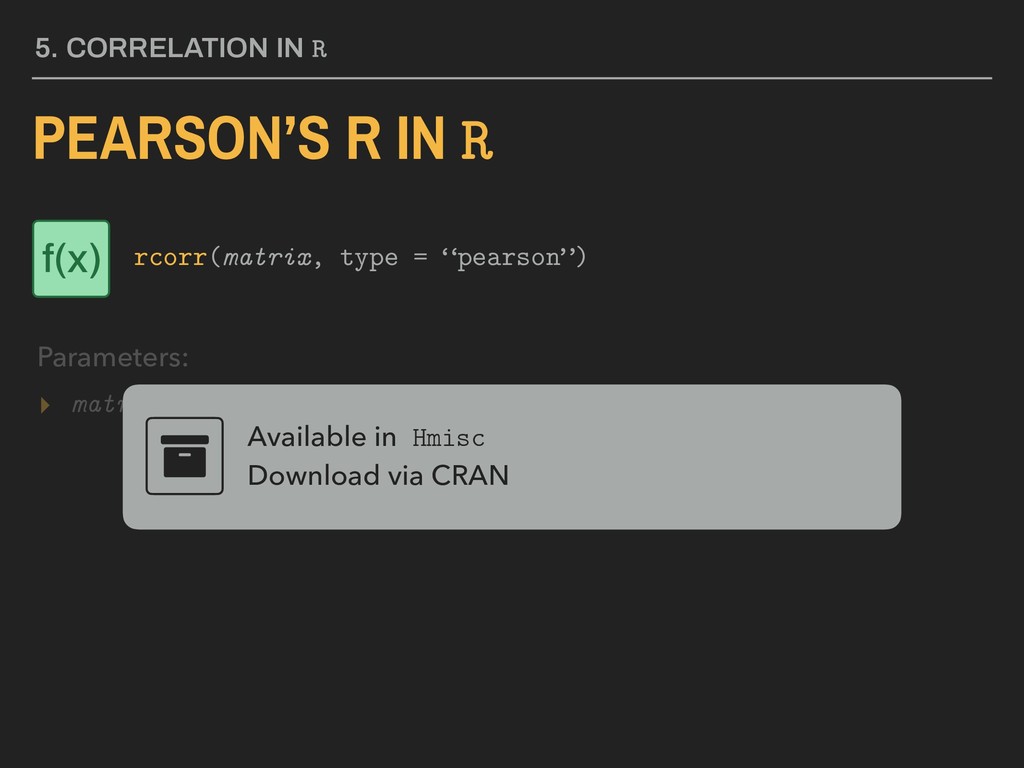
▸ use is set equal to either “complete.obs” (listwise deletion) or “pairwise.complete.obs” (pairwise deletion) Available in stats Installed with base R 5. CORRELATION IN R PEARSON’S R IN R Parameters: corr(data, use, method = “pearson”) f(x)
▸ use is set equal to either “complete.obs” (listwise deletion) or “pairwise.complete.obs” (pairwise deletion) 5. CORRELATION IN R PEARSON’S R IN R Parameters: corr(data, use, method = “pearson”) f(x)
These can be obtained with a second function, cor.test(), but this only works on a single pair of variables at a time. ▸ Unwanted variables must be removed from the data frame. ▸ Rounds to 7 decimal places. 5. CORRELATION IN R PEARSON’S R IN R Problems: corr(data, use, method = “pearson”) f(x)
must be removed from the data frame ahead of time. • The error produced when you forget about the matrix requirement is utterly unhelpful. ▸ No option for listwise deletion. ▸ P-values returned in a separate part of list output. ▸ Rounds to two decimal places. 5. CORRELATION IN R PEARSON’S R IN R Problems: rcorr(matrix, type = “pearson”) f(x)
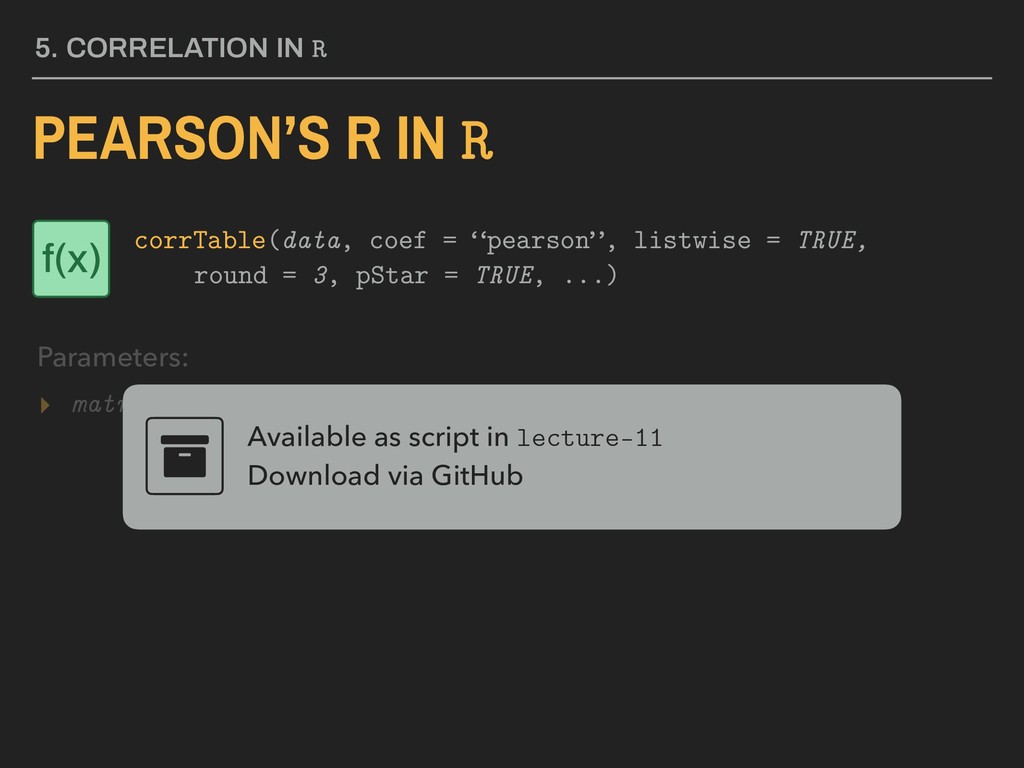
used Available as script in lecture-11 Download via GitHub 5. CORRELATION IN R PEARSON’S R IN R Parameters: corrTable(data, coef = “pearson”, listwise = TRUE, round = 3, pStar = TRUE, ...) f(x)
▸ listwise is set equal to either TRUE (listwise deletion) or FALSE (pairwise deletion) ▸ round is set equal to the number of significant digits to display ▸ pStar is set equal to either TRUE (show stars) or FALSE (no statistical significance indicators) ▸ ... optionally provides a space for unquoted names to be added, separated by commas, to limit output to specific variables. 5. CORRELATION IN R PEARSON’S R IN R Parameters: corrTable(data, coef = “pearson”, listwise = TRUE, round = 3, pStar = TRUE, ...) f(x)
= “pearson”, listwise = TRUE, round = 3, pStar = TRUE, ...) Using the cyl, hwy, and cty variables from ggplot2’s mpg data: corrTable(mpg, coef = “pearson”, listwise = TRUE, round = 3, pStar = TRUE, cyl, hwy, cty) f(x) Can be followed with %>% knitr::kable() to create a nicely formatted table of correlation coefficients.
= “pearson”, listwise = TRUE, round = 3, pStar = TRUE, ...) Using the cyl, hwy, and cty variables from ggplot2’s mpg data: corrTable(mpg, coef = “pearson”, listwise = TRUE, round = 3, pStar = TRUE, cyl, hwy, cty) You will need to save the .R script from GitHub to source/ and then source the function call before using corrTable()! f(x)
coefficient ▸ sig.level should be set to the needed alpha value, which is typically .05 ▸ power should be set equal to the needed power value (1-β, where β is the probability of Type II error); values of 80% to 90% are typically desired. ▸ alternative is used to specify whether significance testing will be done using one- or two-sided tests Available in pwr Download via CRAN 6. POWER ANALYSES FOR CORRELATION SAMPLE SIZE ESTIMATES Parameters: pwr(r = rVal, sig.level = .05, power = powerVal, alternative = "two.sided") f(x)
coefficient ▸ sig.level should be set to the needed alpha value, which is typically .05 ▸ power should be set equal to the needed power value (1-β, where β is the probability of Type II error); values of 80% to 90% are typically desired. ▸ alternative is used to specify whether significance testing will be done using one- or two-sided tests 6. POWER ANALYSES FOR CORRELATION SAMPLE SIZE ESTIMATES Parameters: pwr(r = rVal, sig.level = .05, power = powerVal, alternative = "two.sided") f(x)
rVal, sig.level = .05, power = powerVal, alternative = "two.sided") An estimate to detect a moderate effect size (r = .55) with high statistical power (.9): pwr.r.test(r = .55, sig.level = .05, power = .9, alternative = "two.sided") f(x)
power = .9, alternative = "two.sided") approximate correlation power calculation (arctangh transformation) n = 50.24877 r = 0.55 sig.level = 0.05 power = 0.99 alternative = two.sided 6. POWER ANALYSES FOR CORRELATION
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
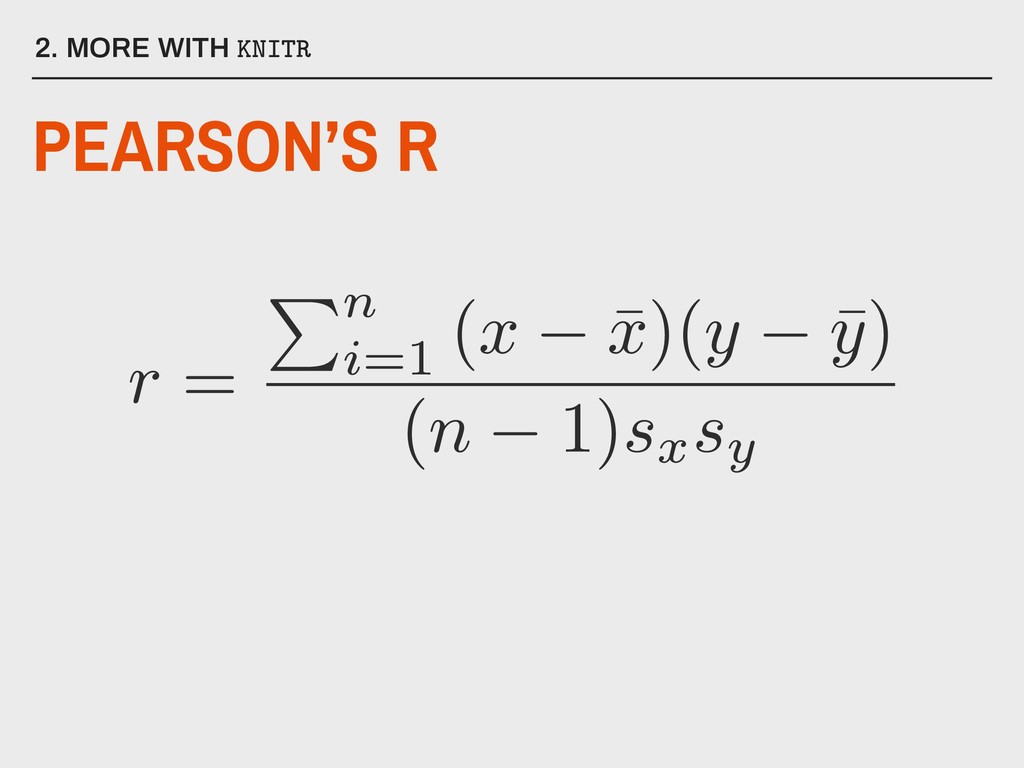{kind=link}
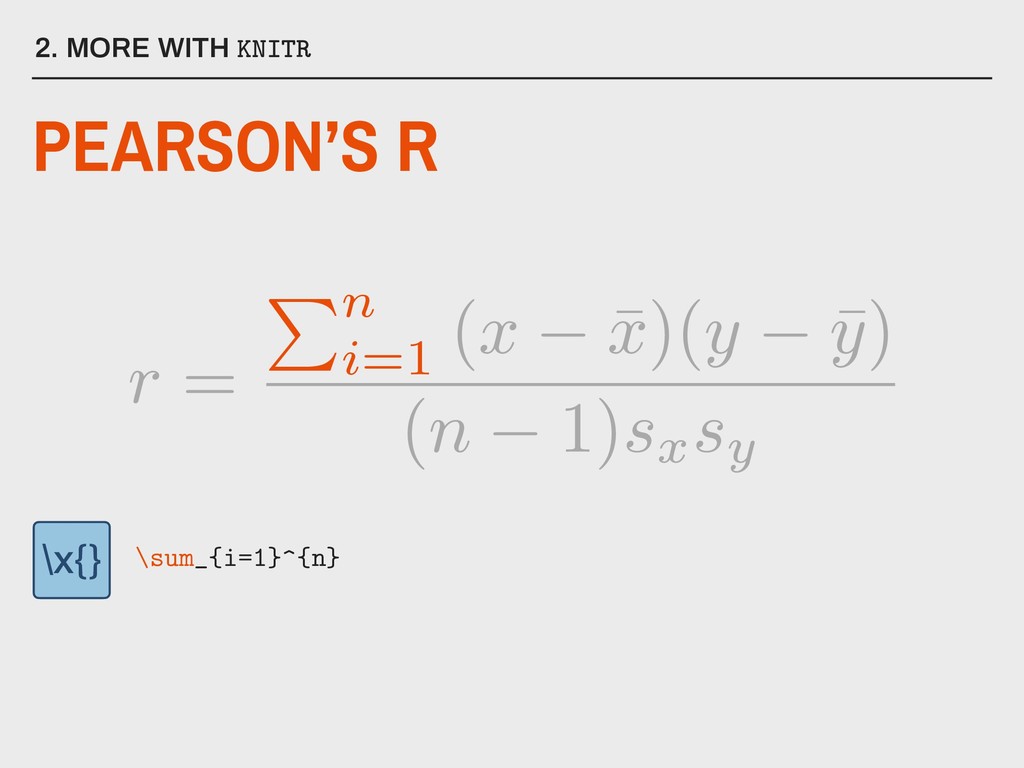{kind=link}
{kind=link}
{kind=link}
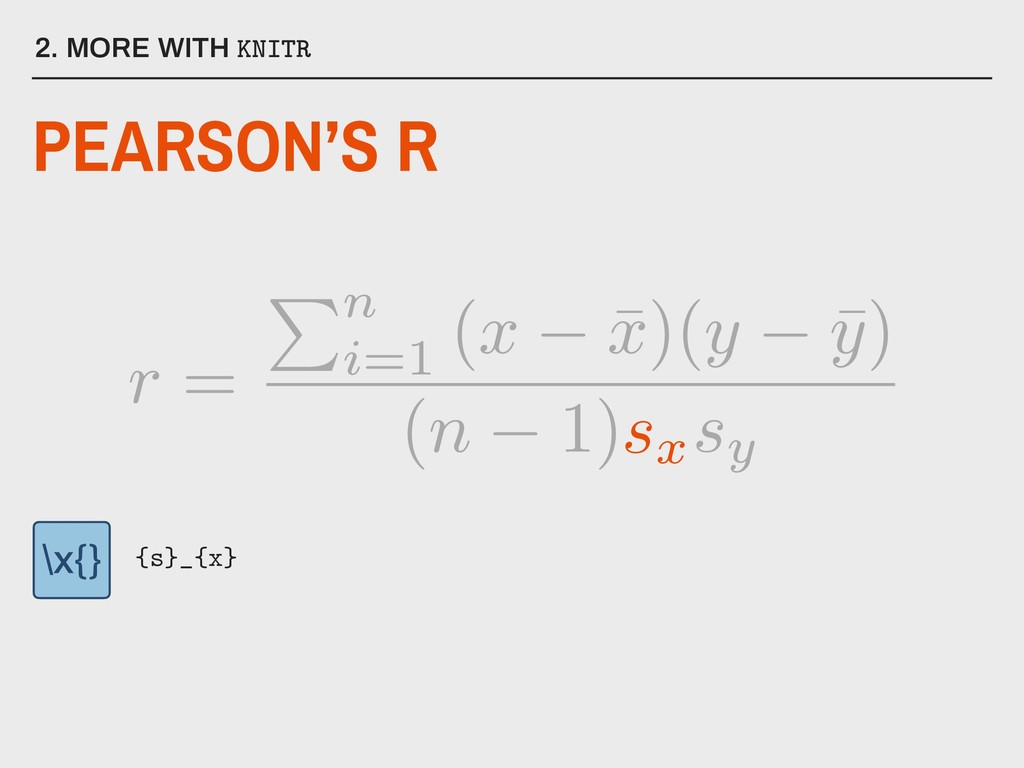{kind=link}
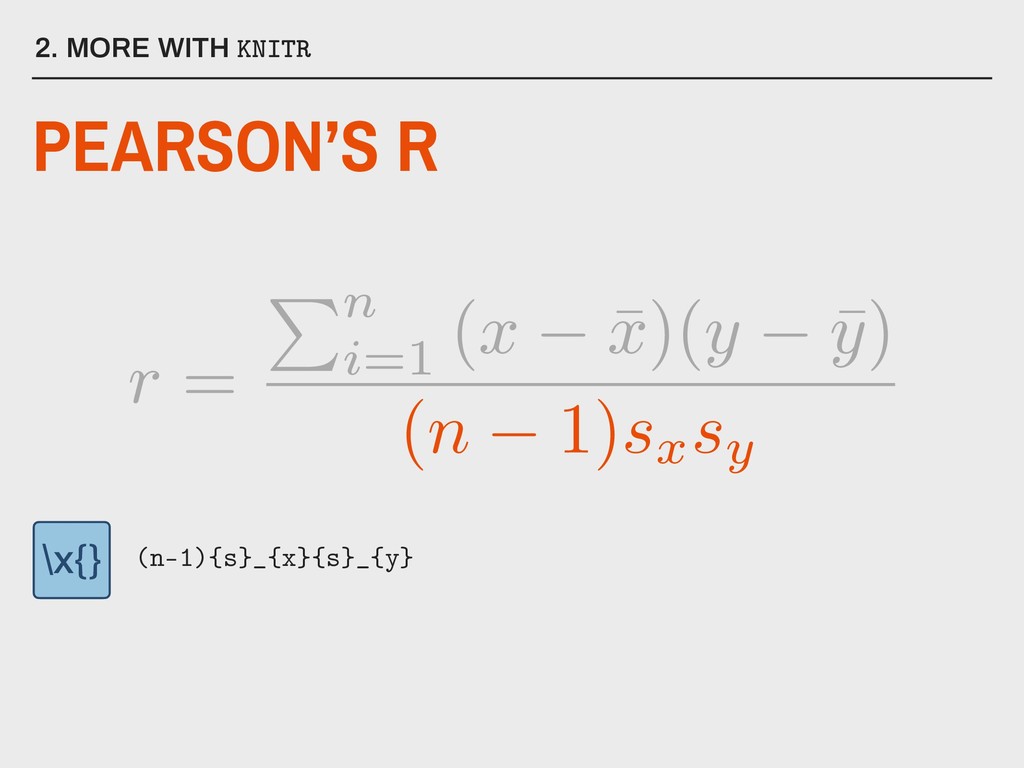{kind=link}
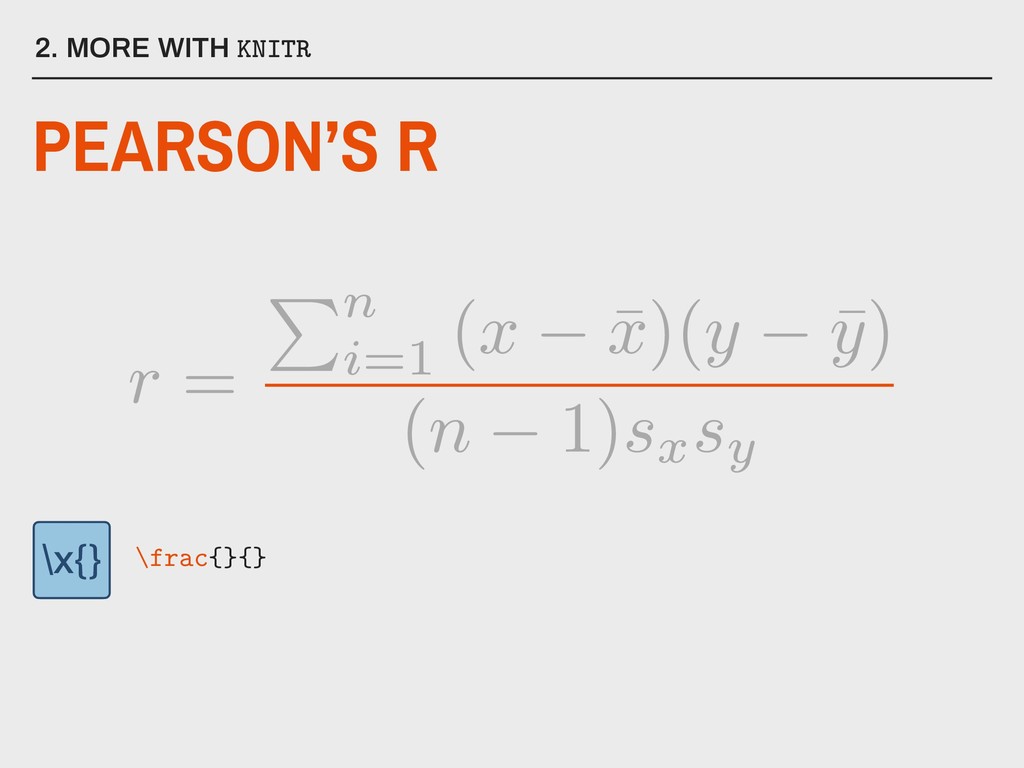{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
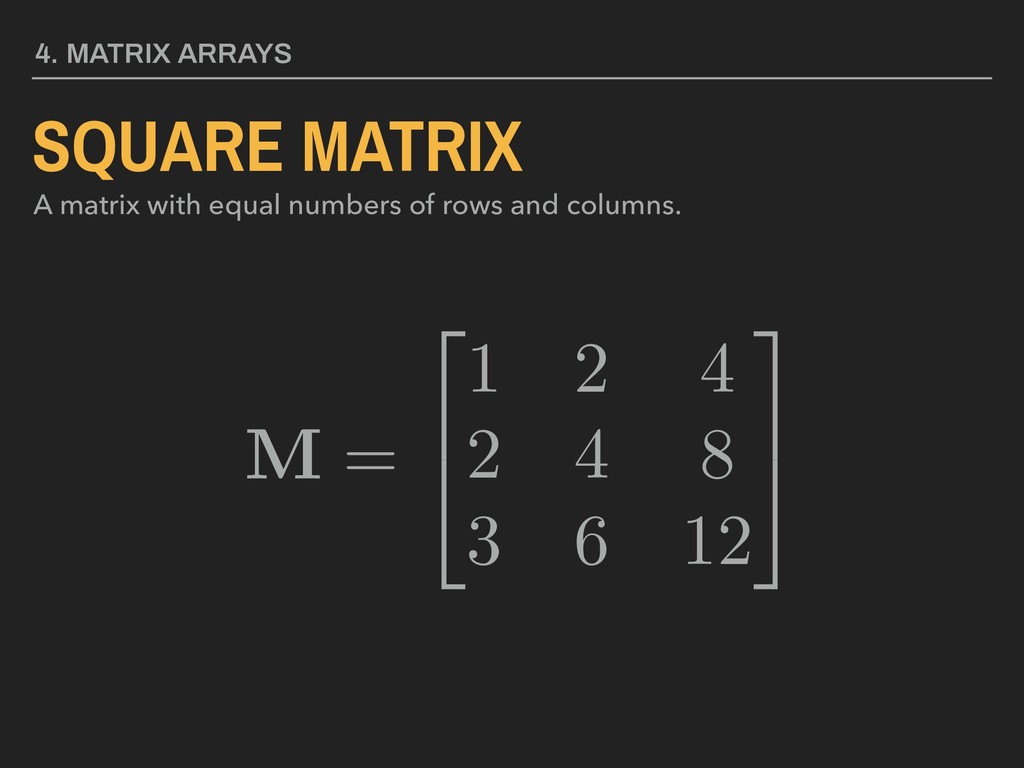{kind=link}
{kind=link}
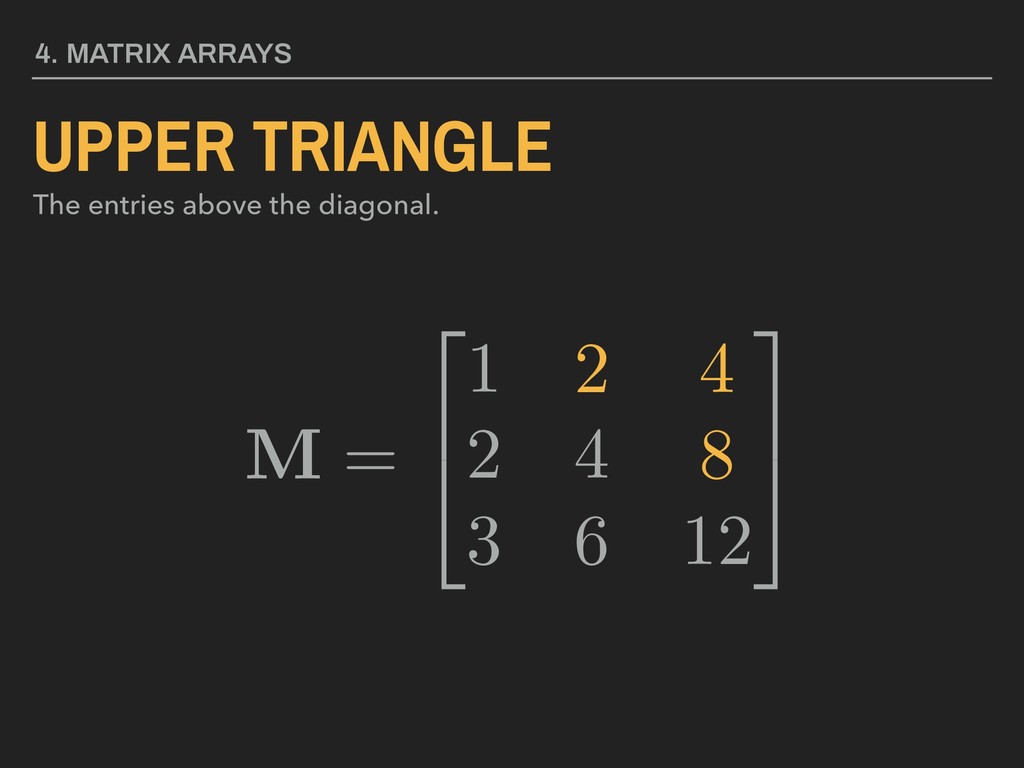{kind=link}
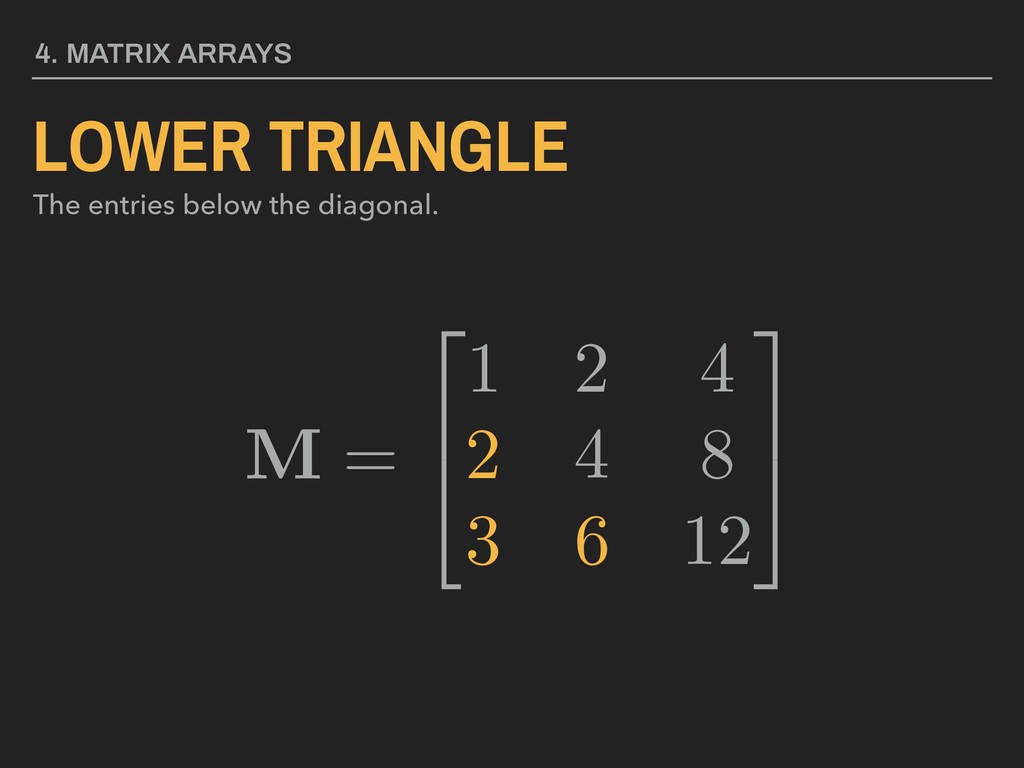{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}