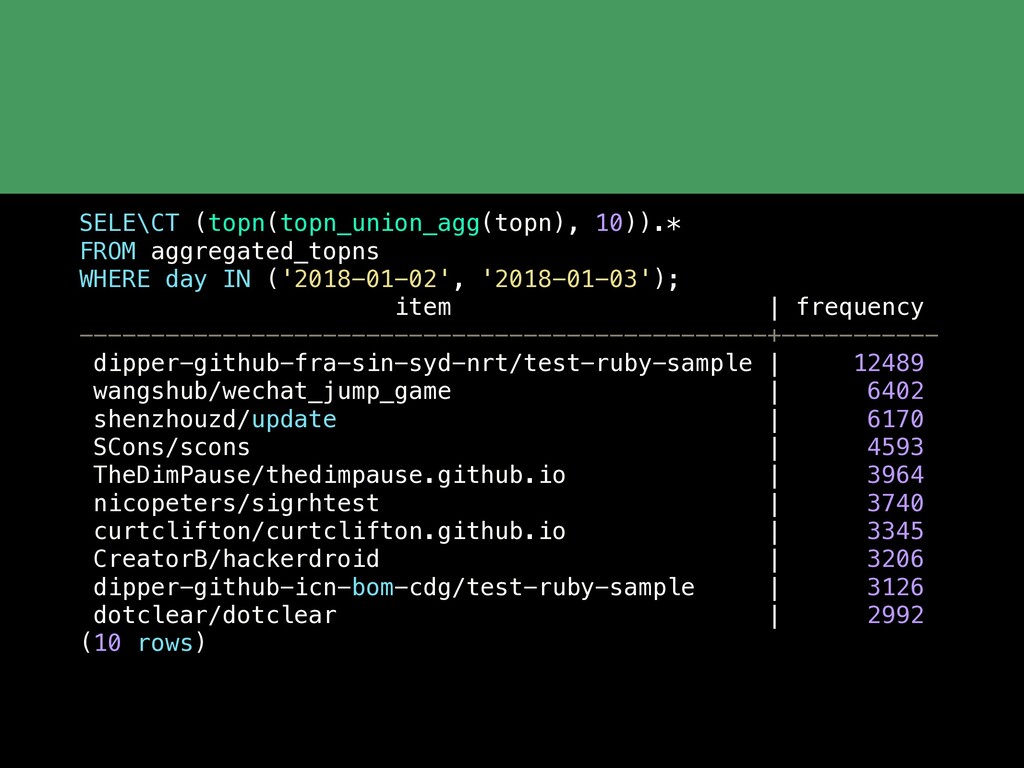
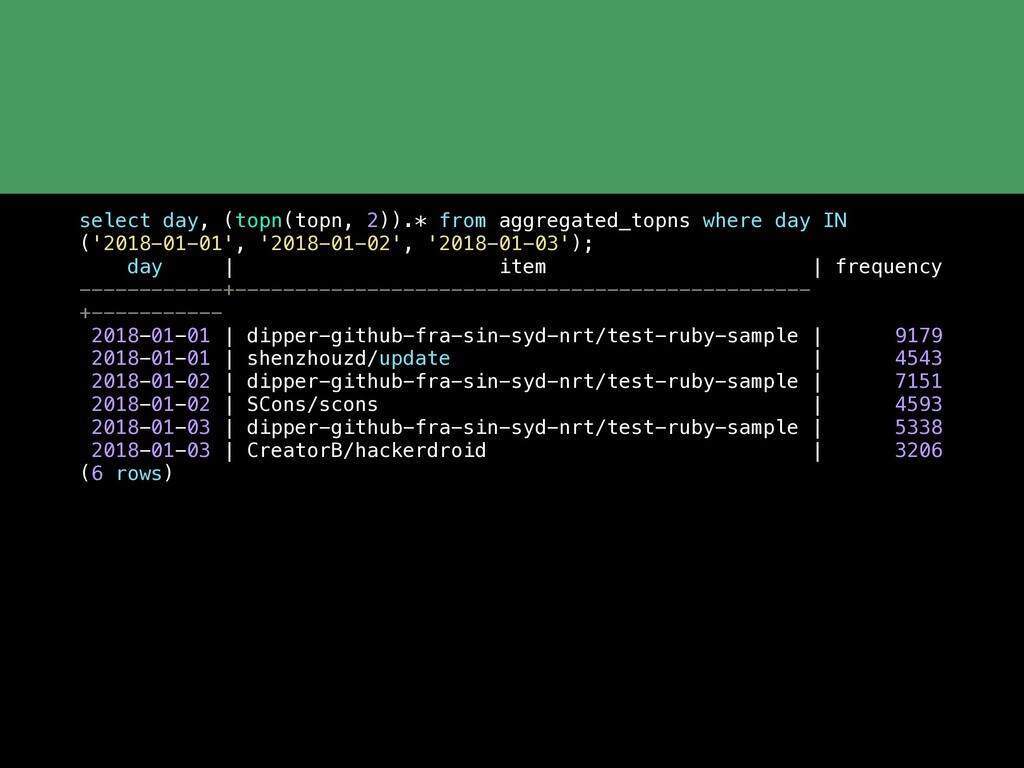
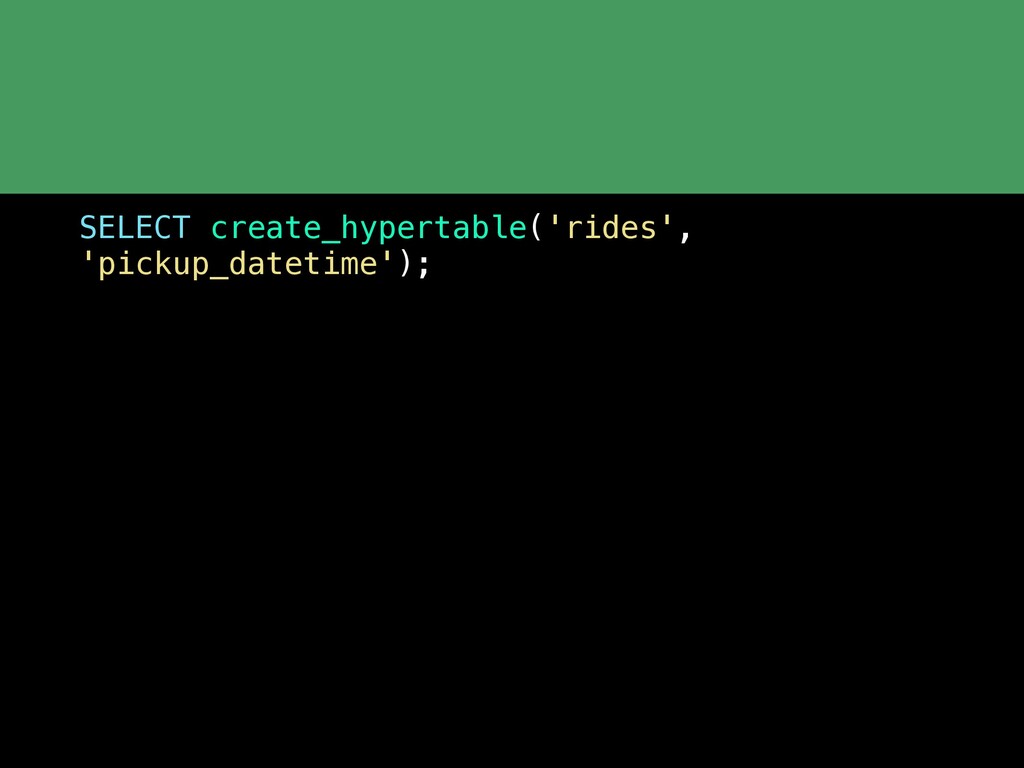
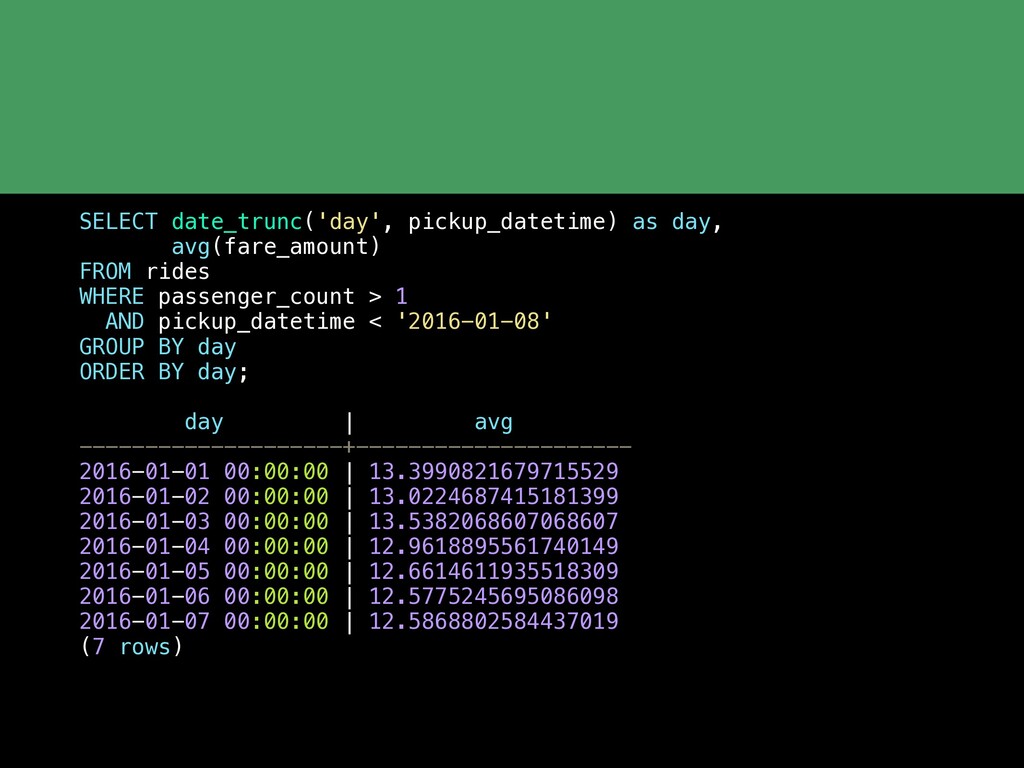
Postgres continues to get more and more feature rich. But equally as impressive is the network of extensions that are growing around Postgres. With the rich extension APIs you can now add advanced functionality to Postgres without having to fork the codebase or wait for the main PostgreSQL release cycle. In this talk we'll cover some of the basics of what an extension is and then take a tour through a variety of Postgres extensions including: pg_stat_statments PostGIS HyperLogLog and TopN Timescale pg_partman Citus Foreign data wrappers which are their own whole class
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
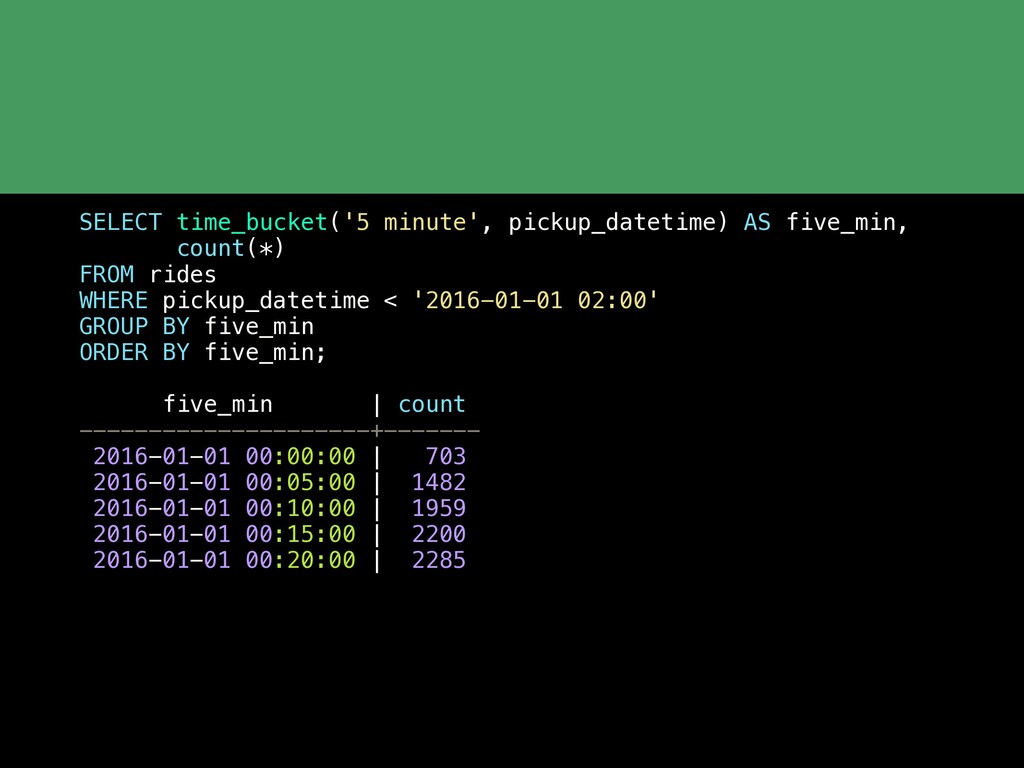{kind=link}
{kind=link}
{kind=link}
{kind=link}
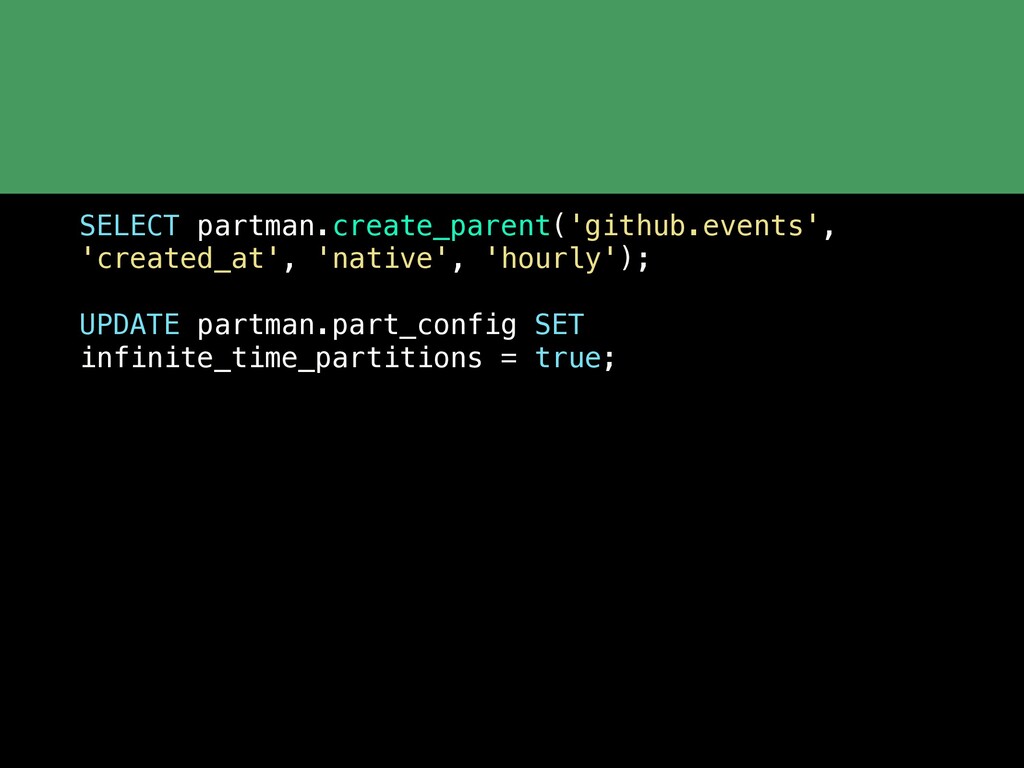{kind=link}
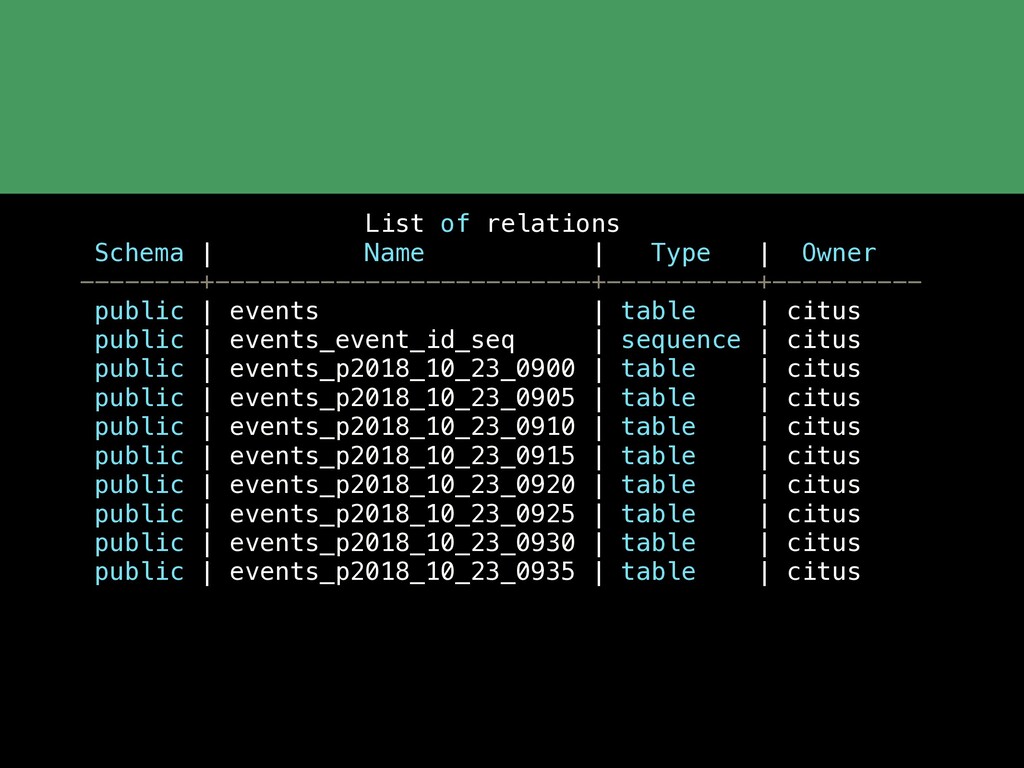{kind=link}
![SELECT * from partman.part_config; -[ RECORD 1 ]--------------+------------------------------- parent_table |](https://files.speakerdeck.com/presentations/2290a35413db4d868c409f32307c39cb/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
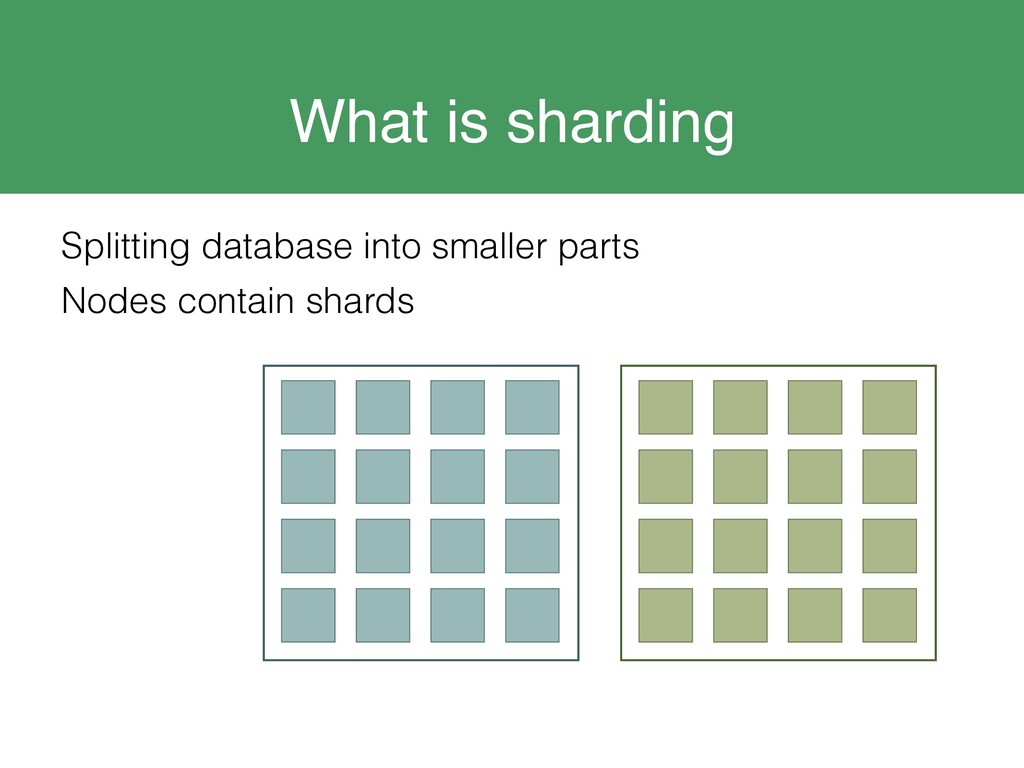{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
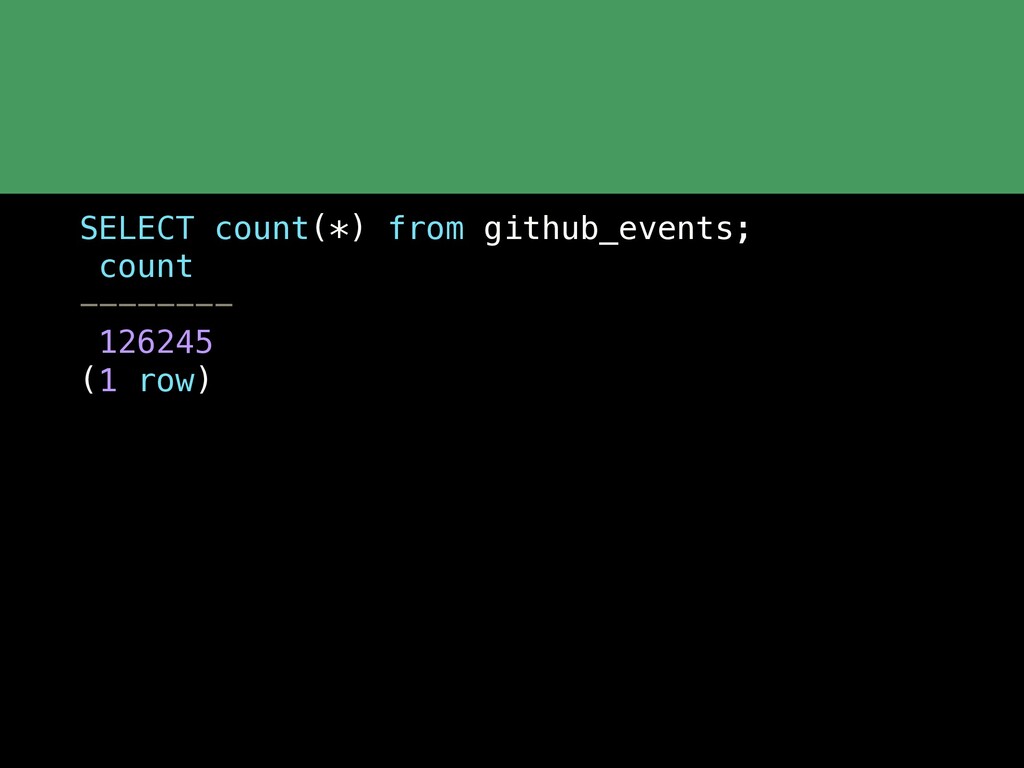{kind=link}
{kind=link}
{kind=link}
{kind=link}
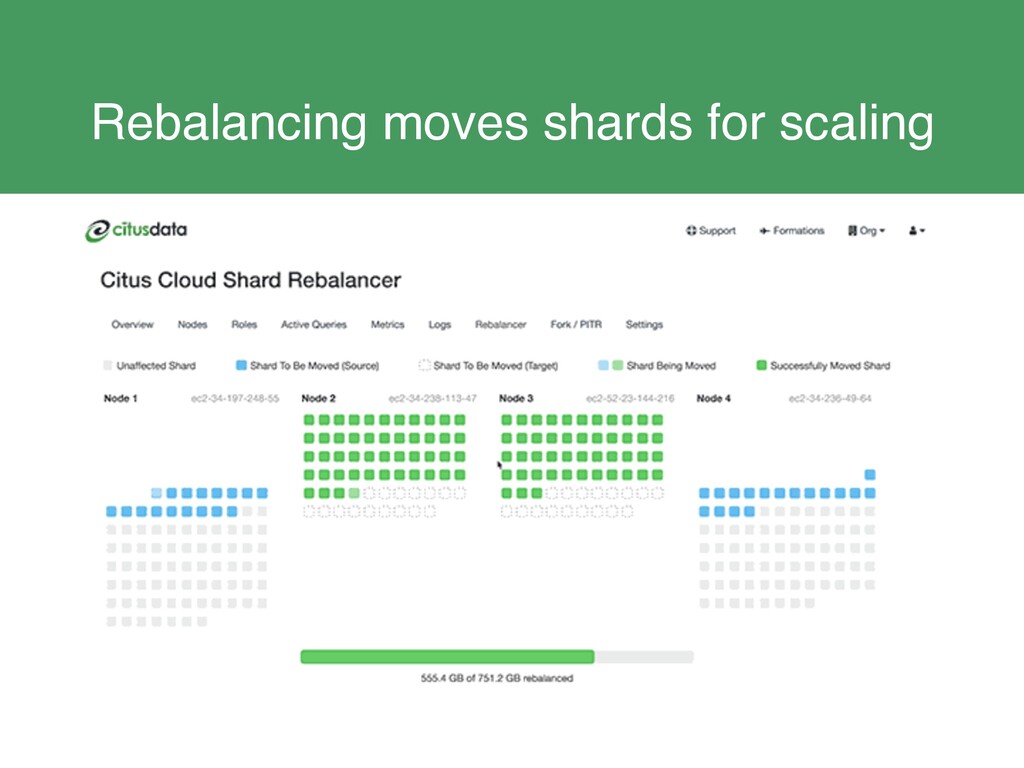{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
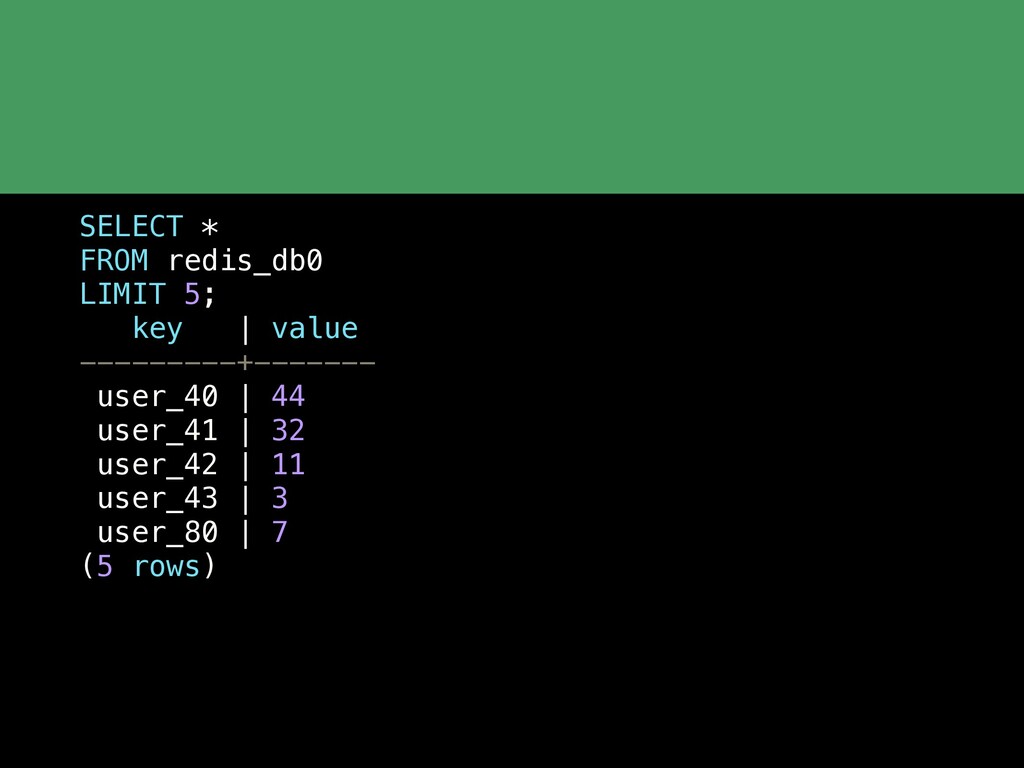{kind=link}
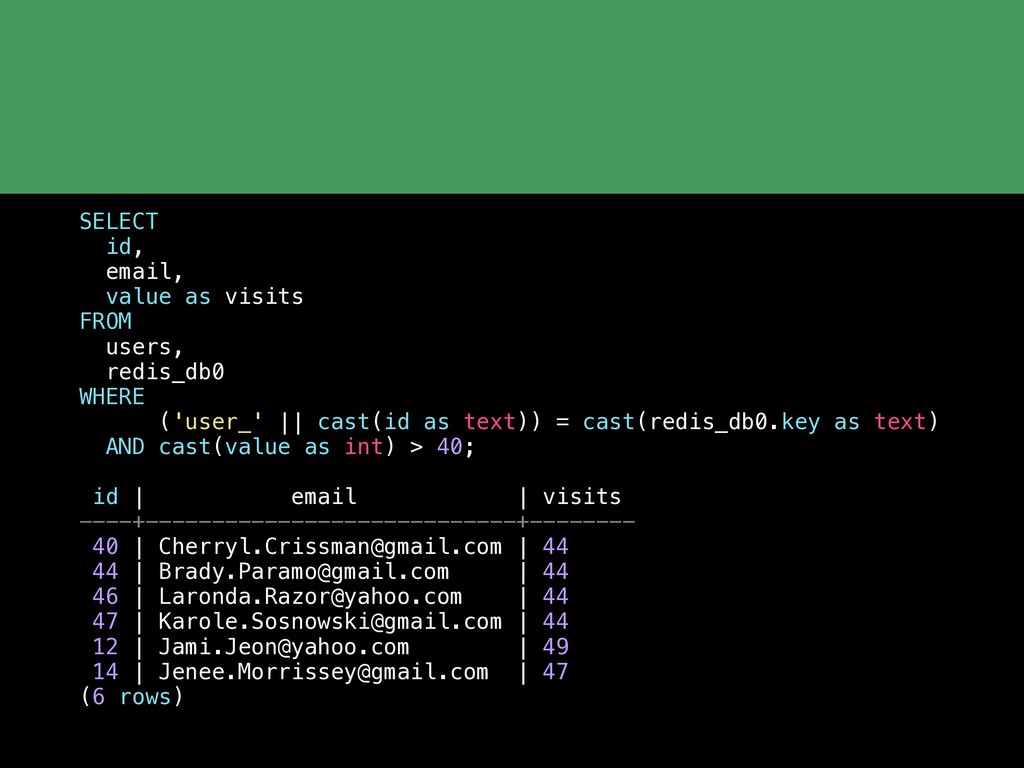{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}