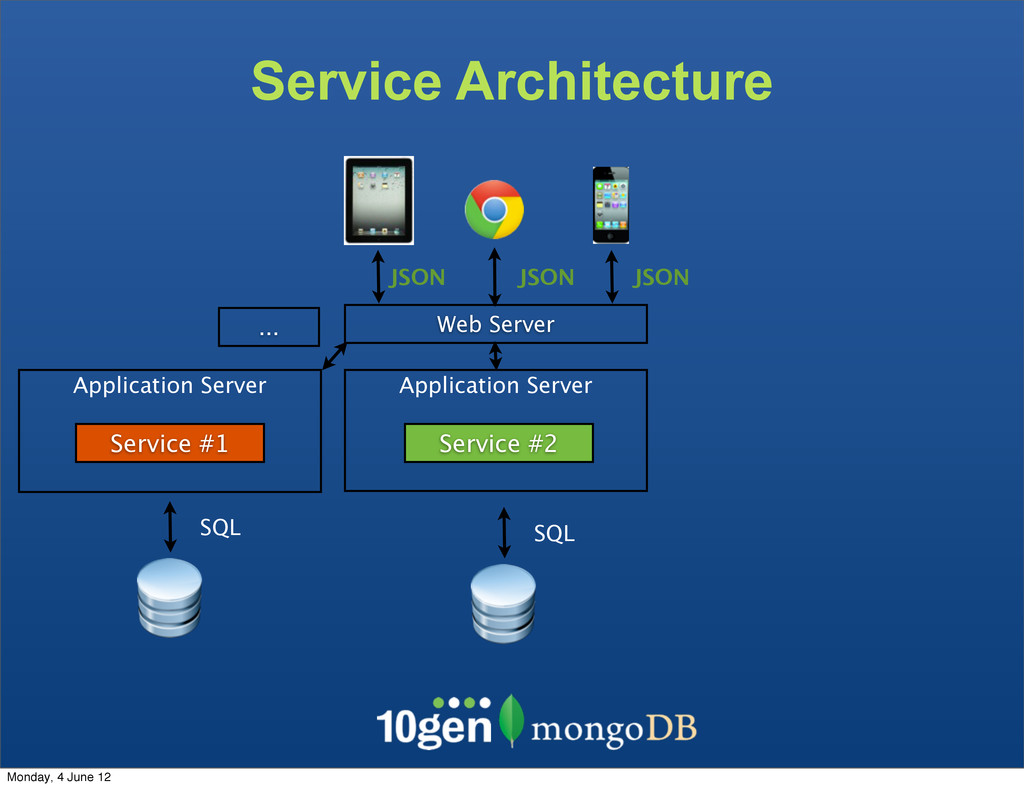
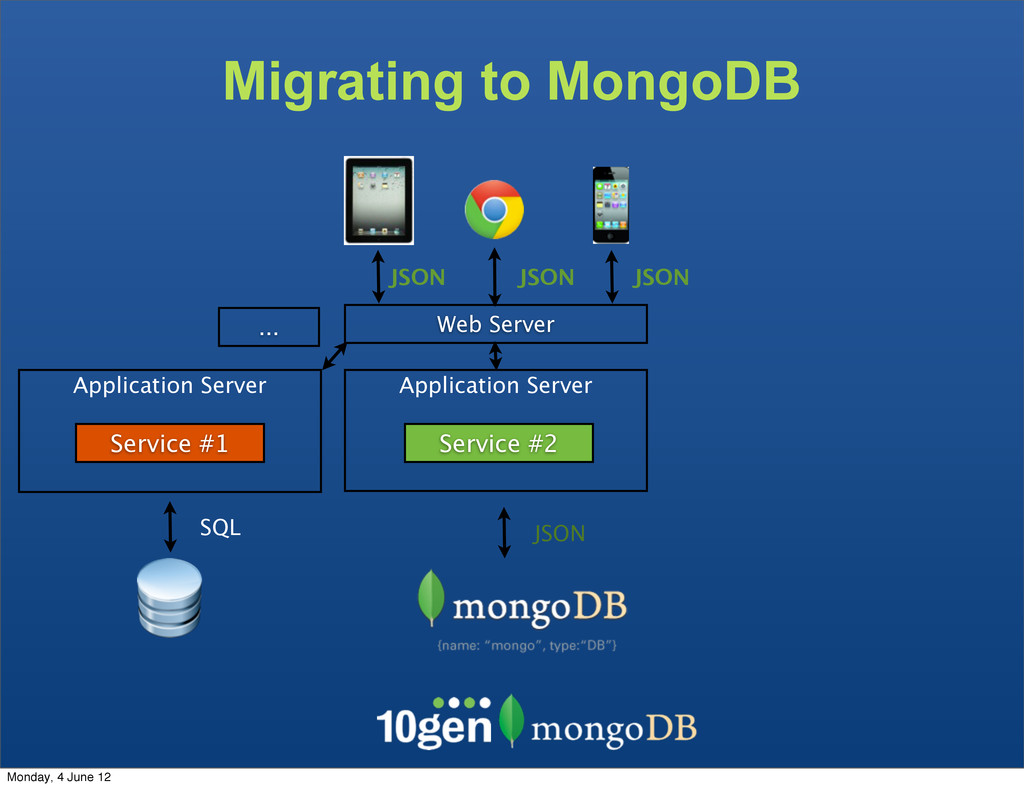
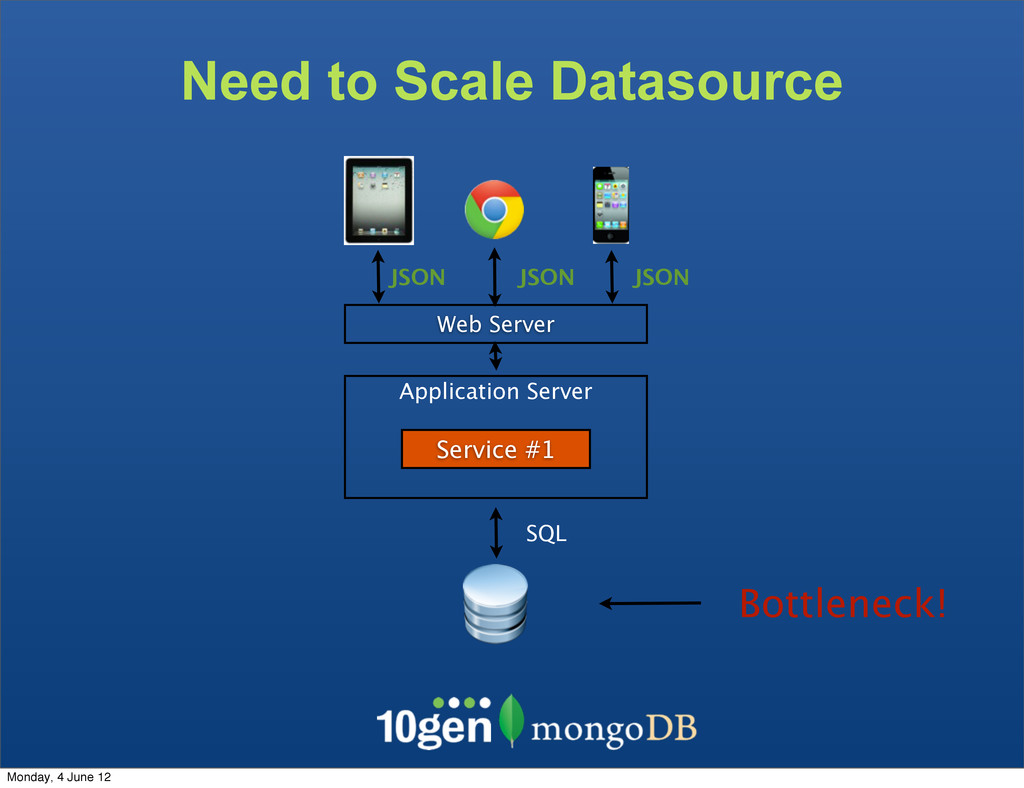
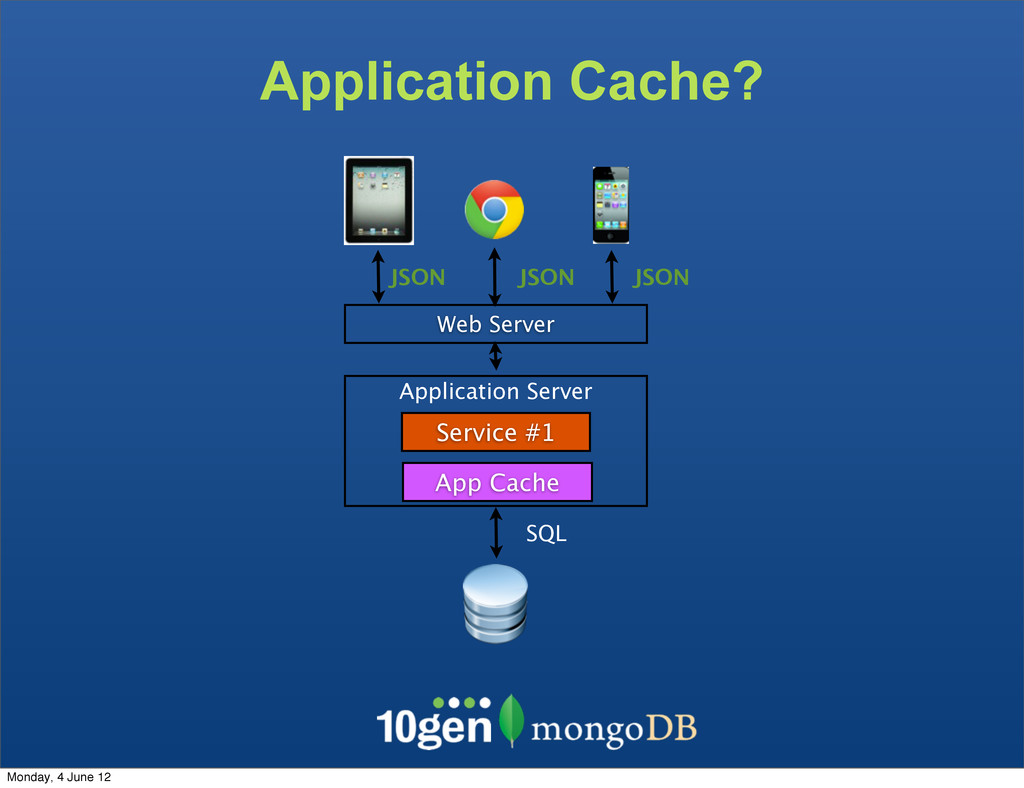
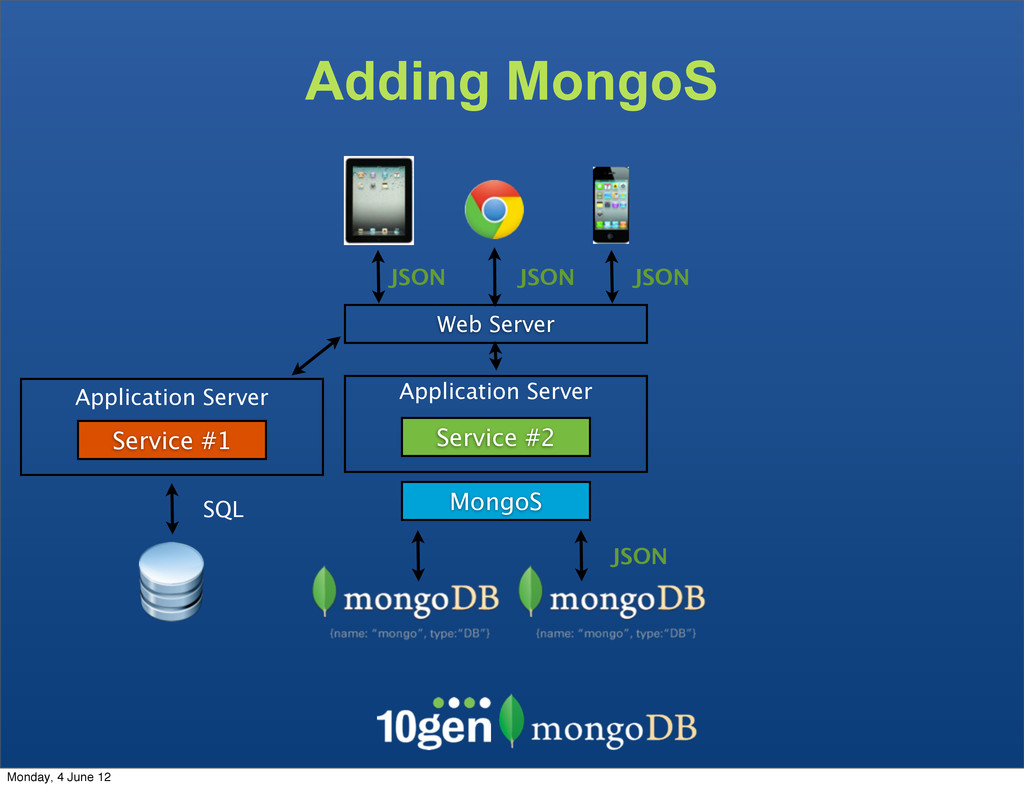
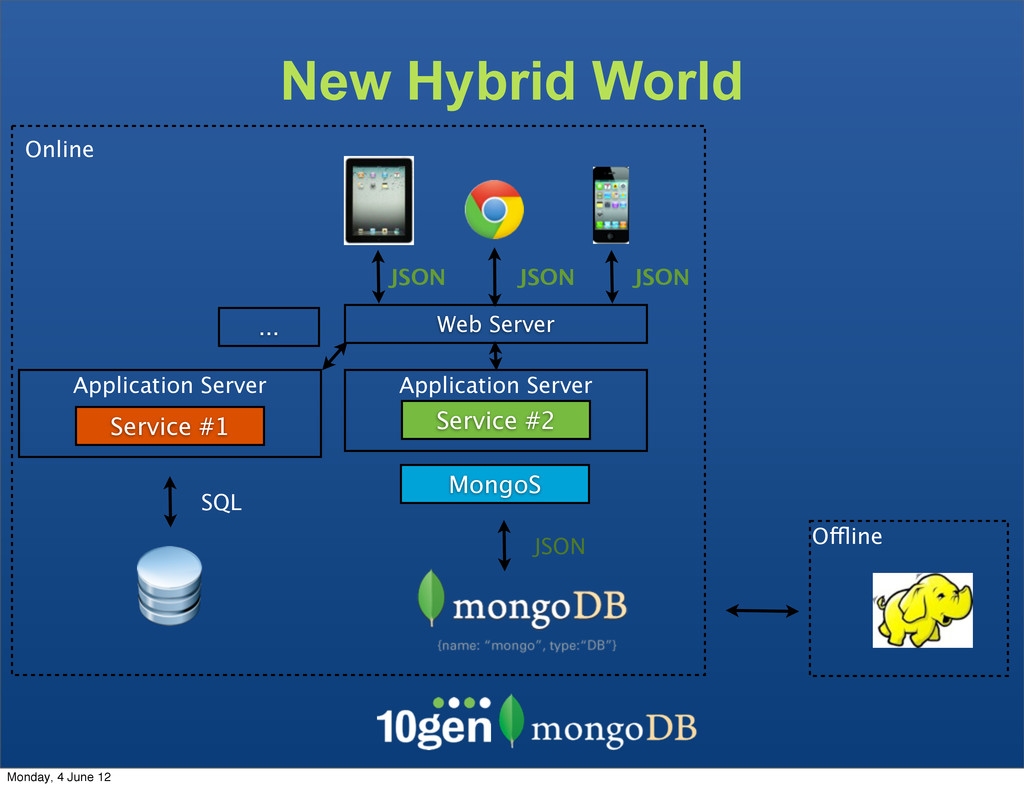
The clients are not bound to the underlaying data store The Service becomes the API - Complexity due to mismatch between the JSON and SQL Monday, 4 June 12
}, "user.followers_count": { $gt: 0 } } }, {$project: { location: "$user.location", friends: "$user.friends_count", followers: "$user.followers_count" } }, {$group: {_id: "$location", friends: {$sum: "$friends"}, followers: {$sum: "$followers"} } } ); Predicate Parts of the document you want to project Function to apply to the result set Monday, 4 June 12
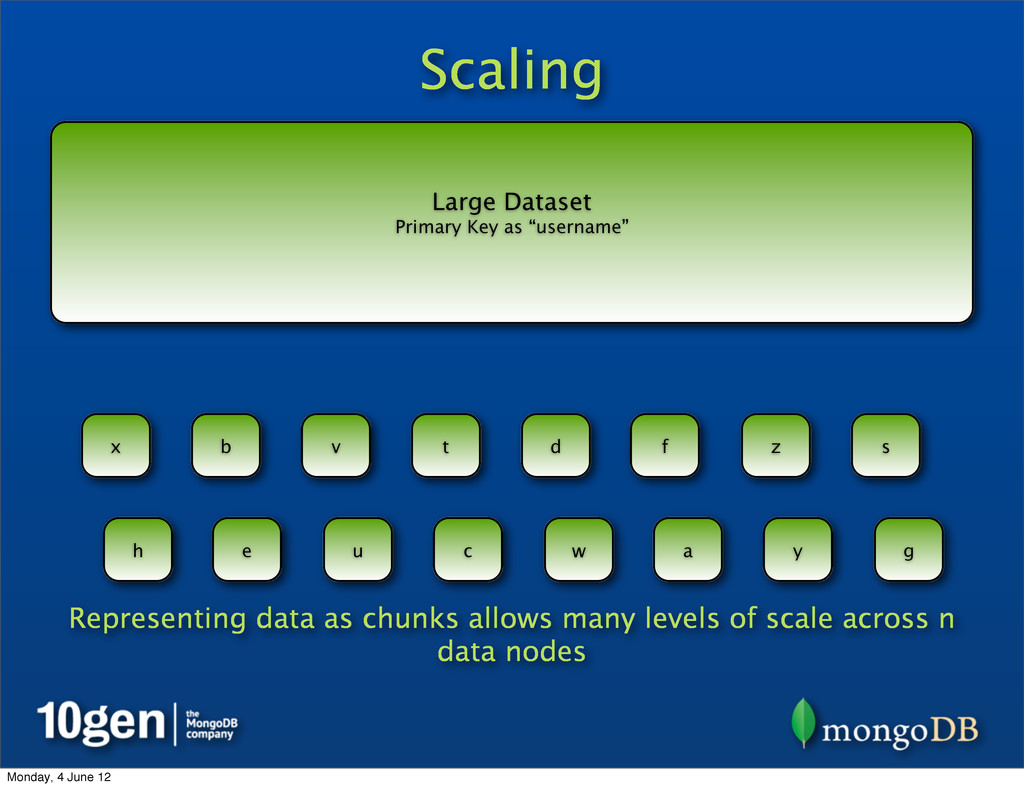
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Monday, 4 June 12
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Monday, 4 June 12
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes • Each data node contains many chunks Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Monday, 4 June 12
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes • Each data node contains many chunks • If a chunk gets too large or a node overloaded, data can be rebalanced Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Monday, 4 June 12
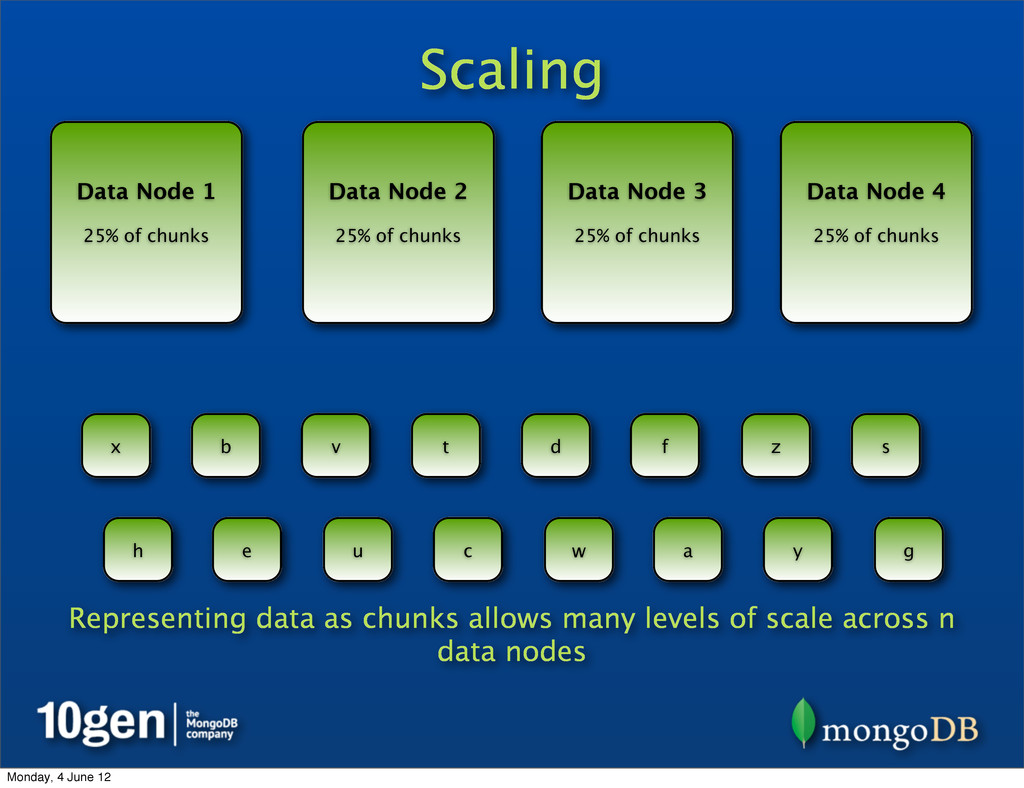
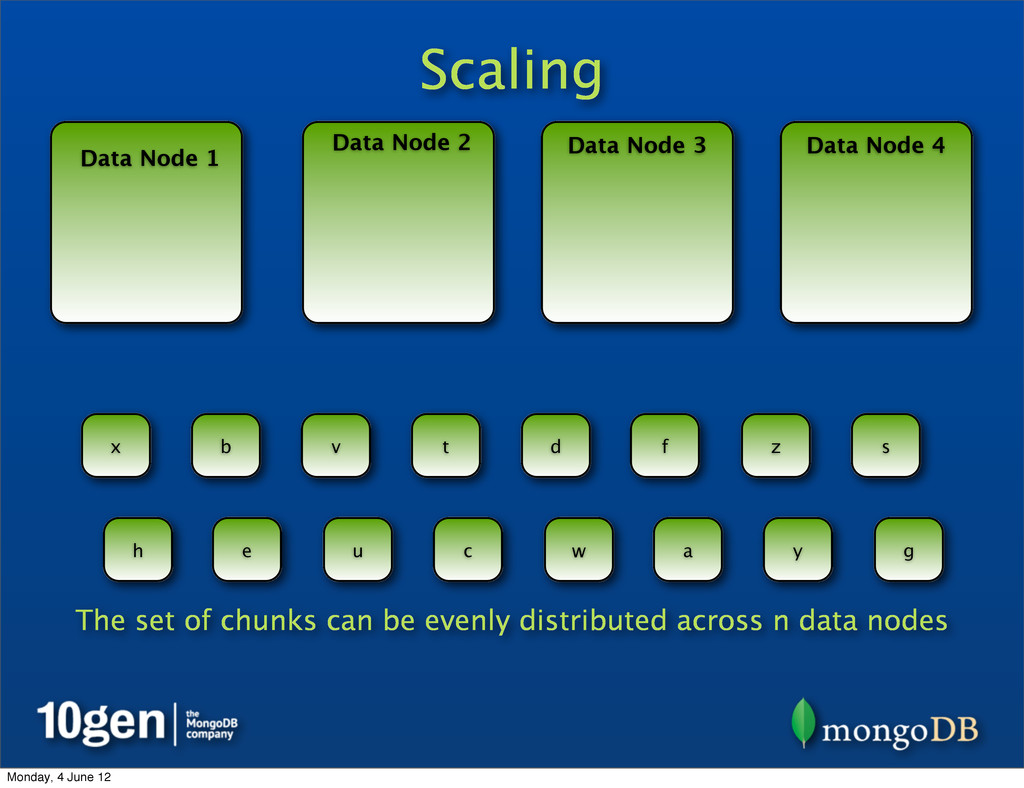
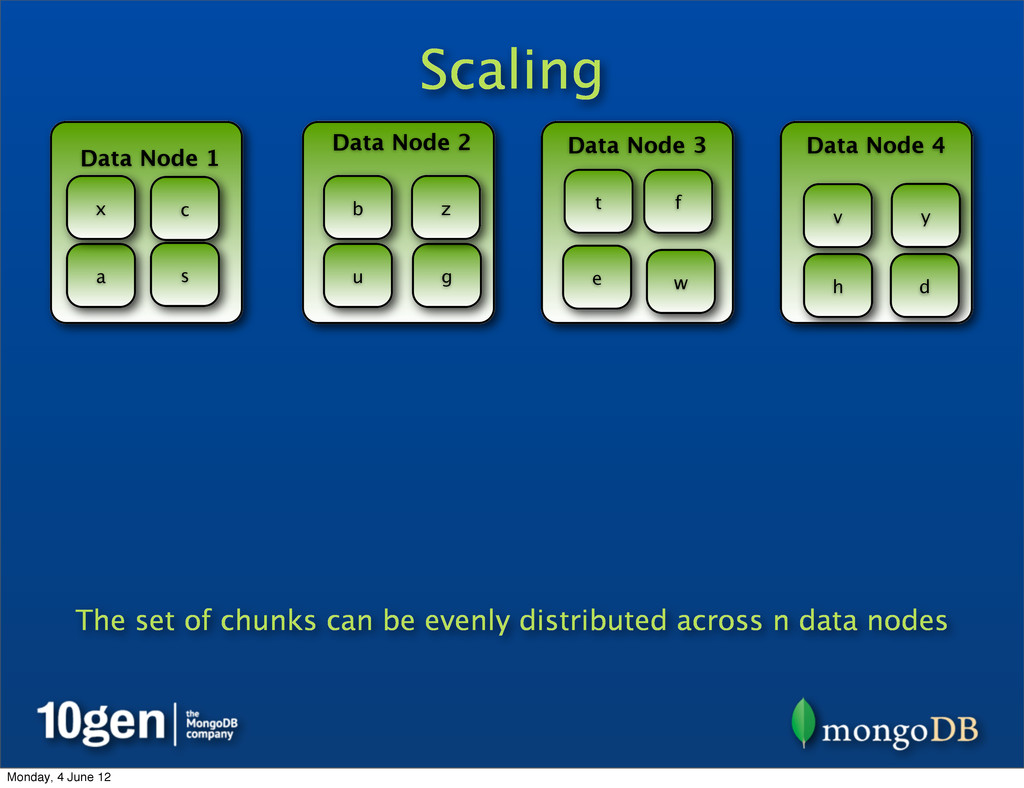
25% of chunks Data Node 2 25% of chunks Data Node 3 25% of chunks Data Node 4 25% of chunks a b c d e f g h s t u v w x y z Representing data as chunks allows many levels of scale across n data nodes Monday, 4 June 12
25% of chunks Data Node 2 25% of chunks Data Node 3 25% of chunks Data Node 4 25% of chunks a b c d e f g h s t u v w x y z Representing data as chunks allows many levels of scale across n data nodes Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z The goal is equilibrium - an equal distribution. As nodes are added (or even removed) chunks can be redistributed for balance. Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z The goal is equilibrium - an equal distribution. As nodes are added (or even removed) chunks can be redistributed for balance. Monday, 4 June 12
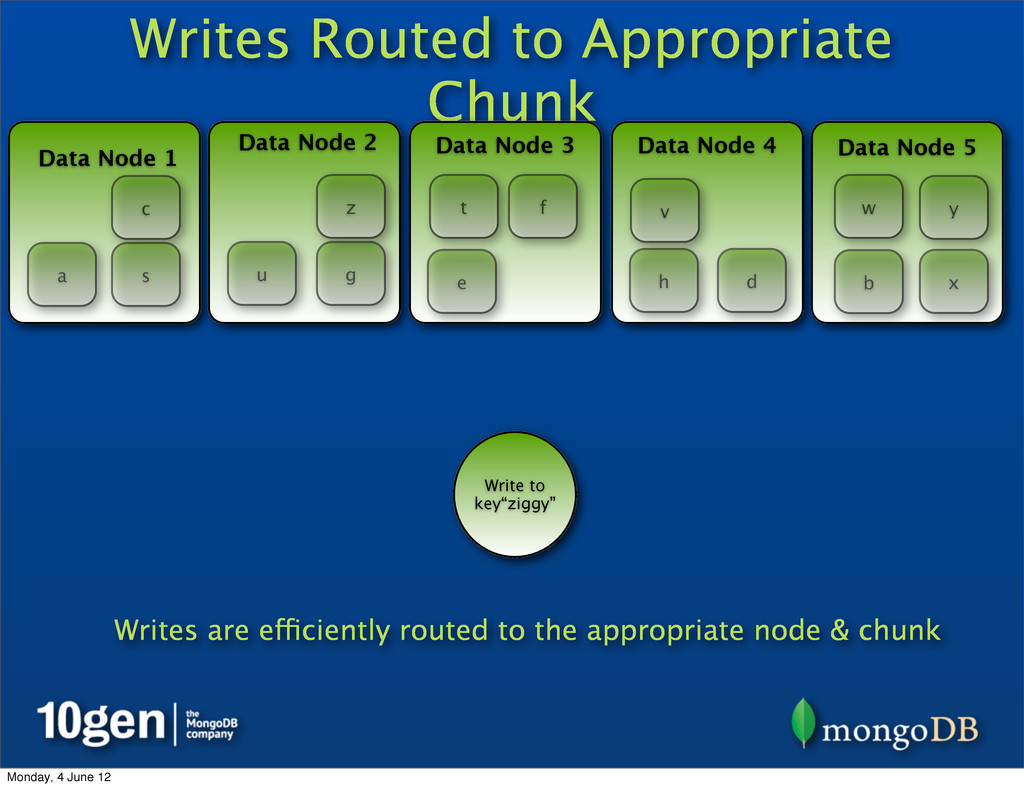
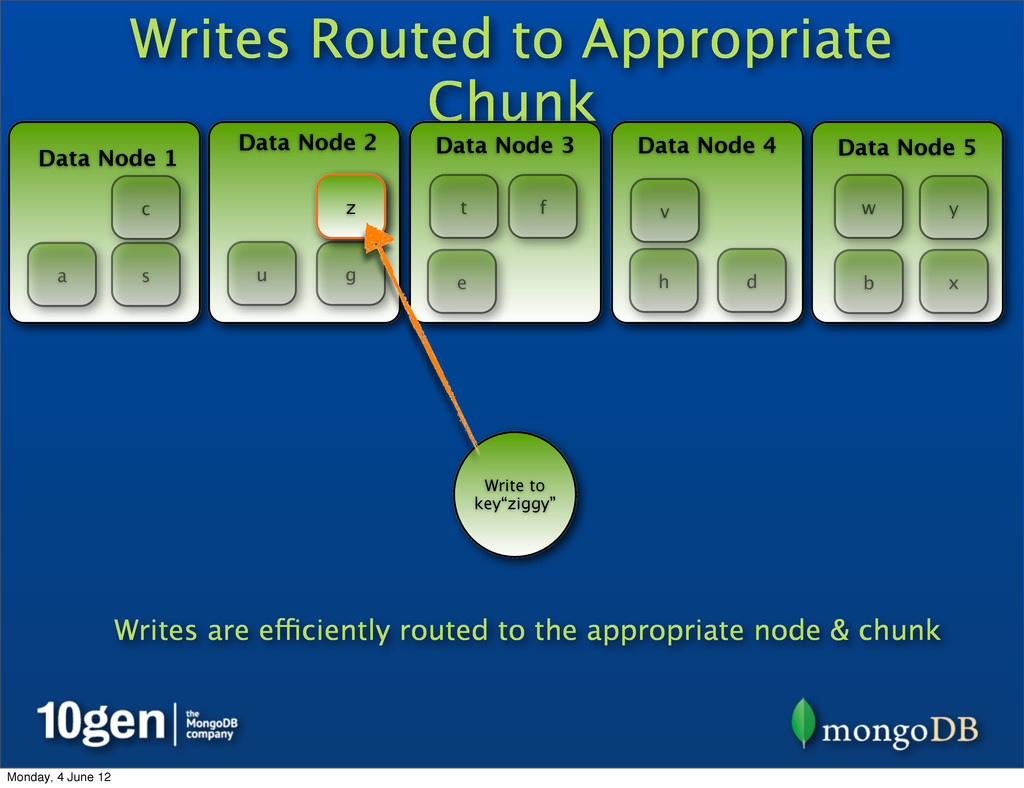
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z Writes are efficiently routed to the appropriate node & chunk Monday, 4 June 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z Writes are efficiently routed to the appropriate node & chunk Monday, 4 June 12
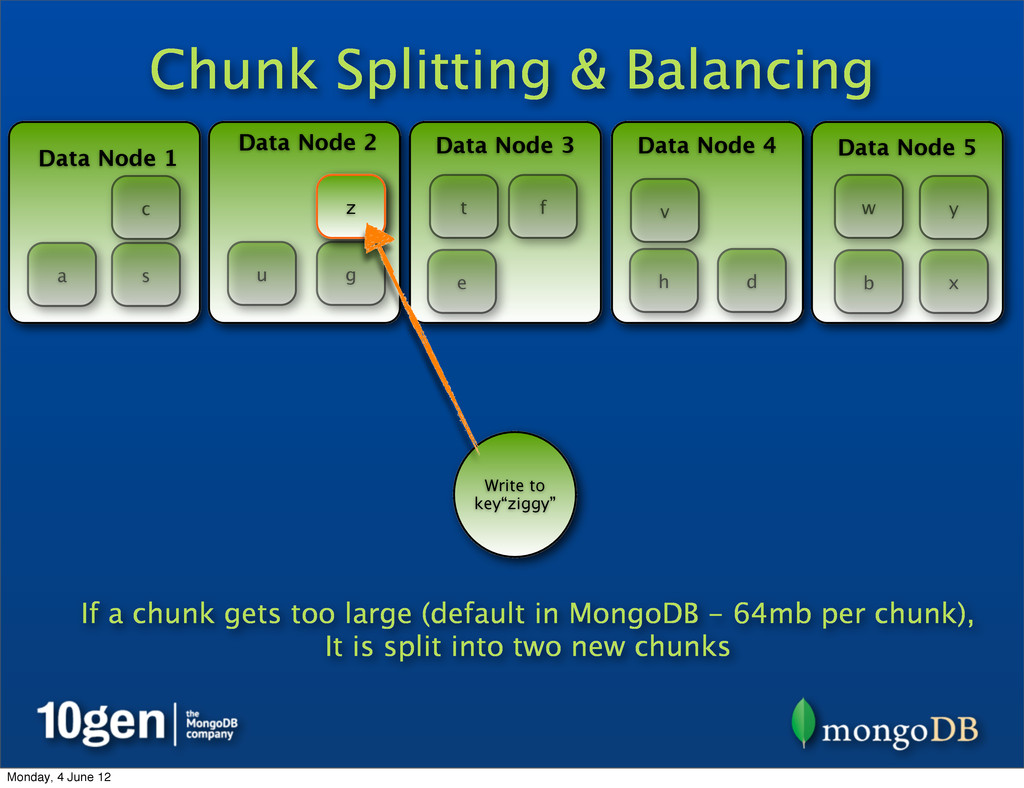
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Monday, 4 June 12
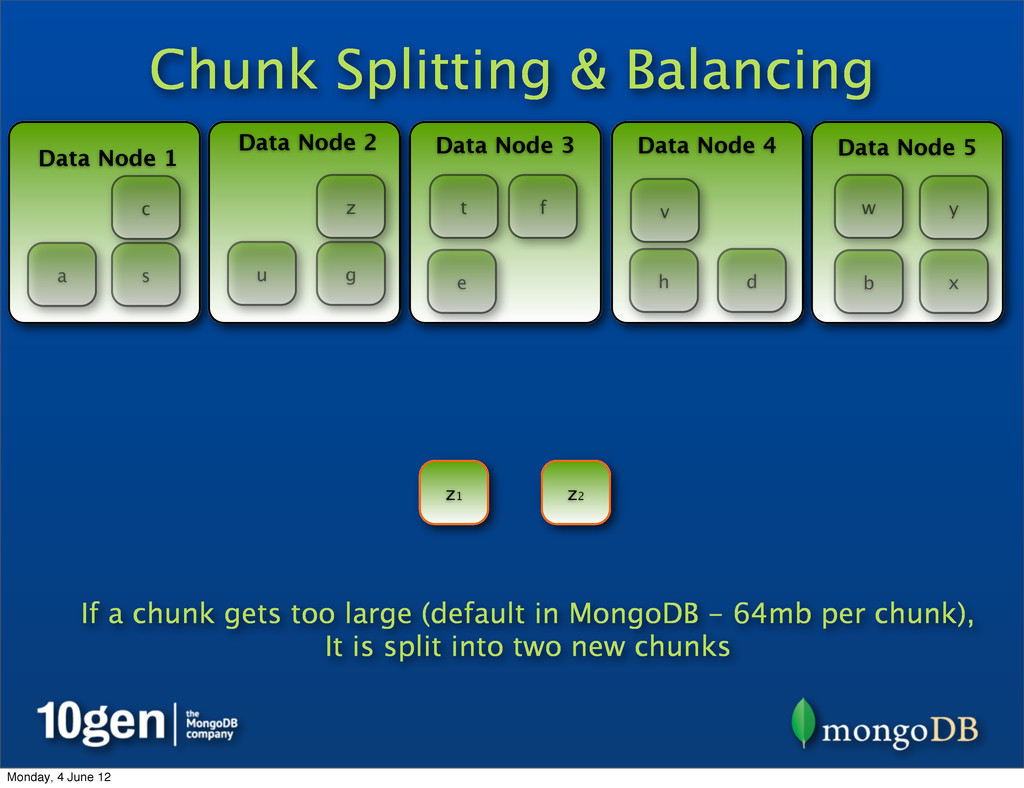
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks z1 Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks z1 Monday, 4 June 12
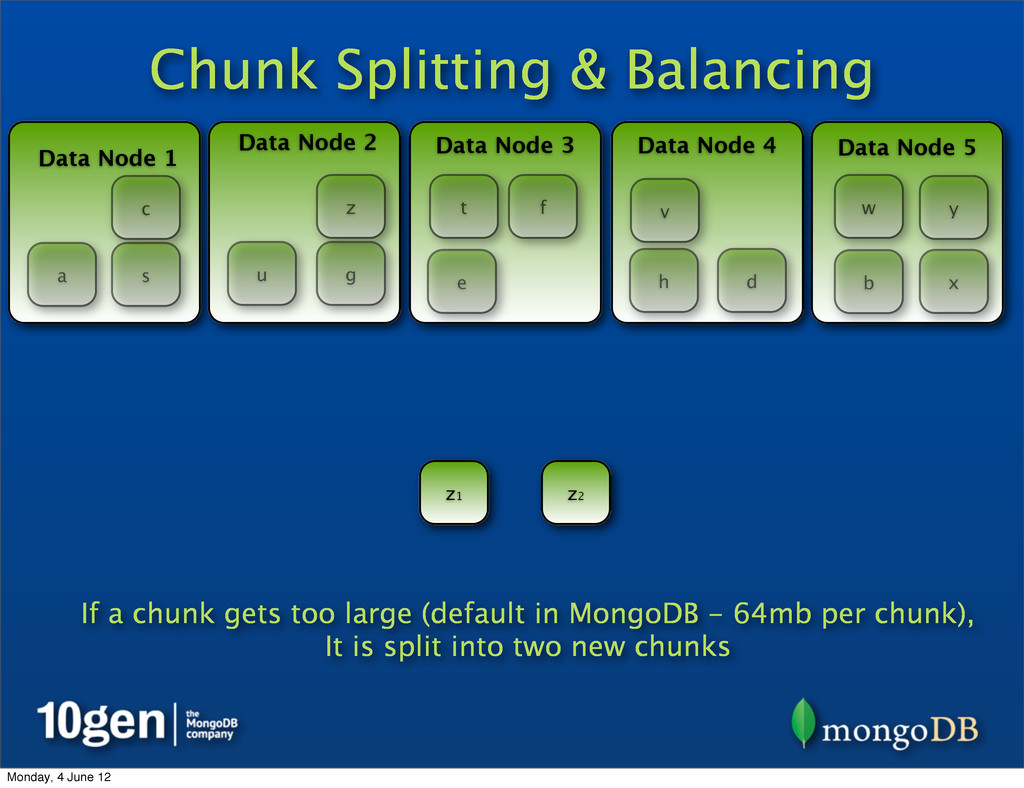
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 z1 Each new part of the Z chunk (left & right) now contains half of the keys Monday, 4 June 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 z1 As chunks continue to grow and split, they can be rebalanced to keep an equal share of data on each server. Monday, 4 June 12
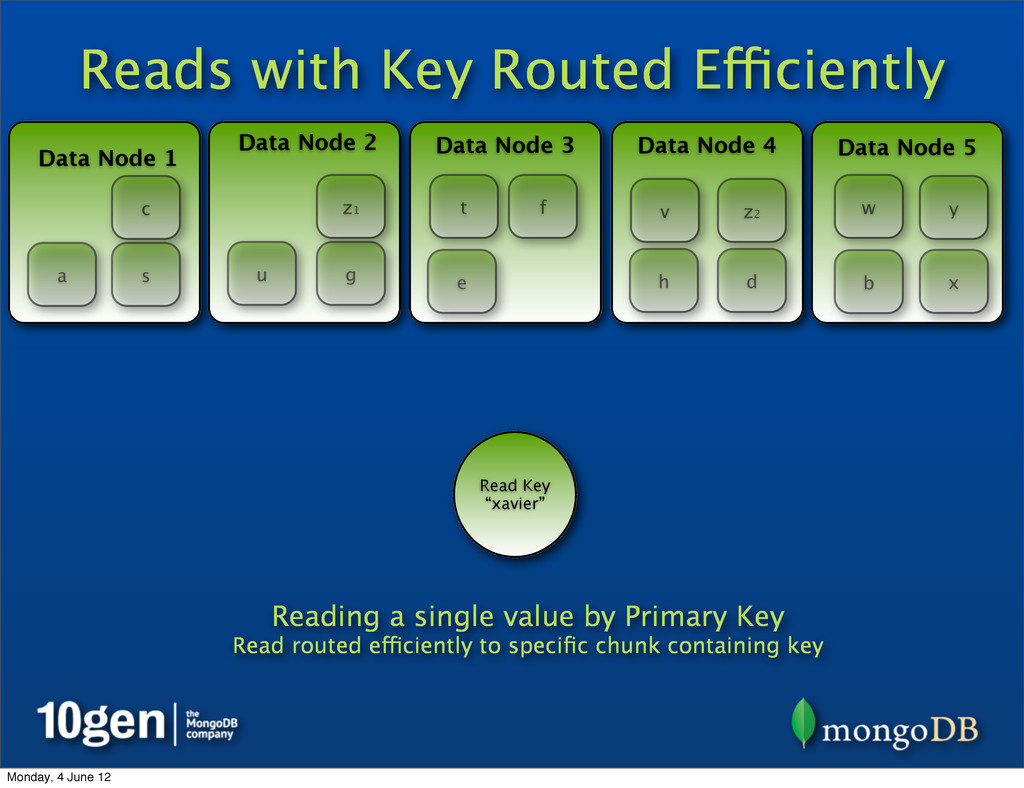
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z1 Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z2 Monday, 4 June 12
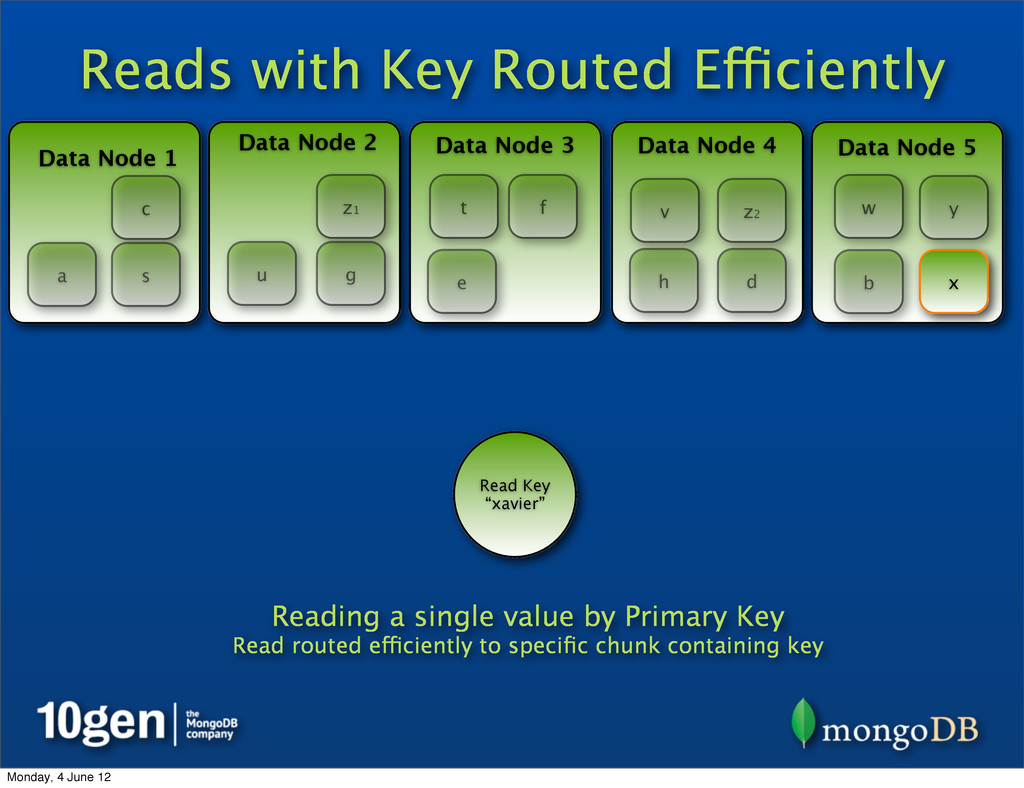
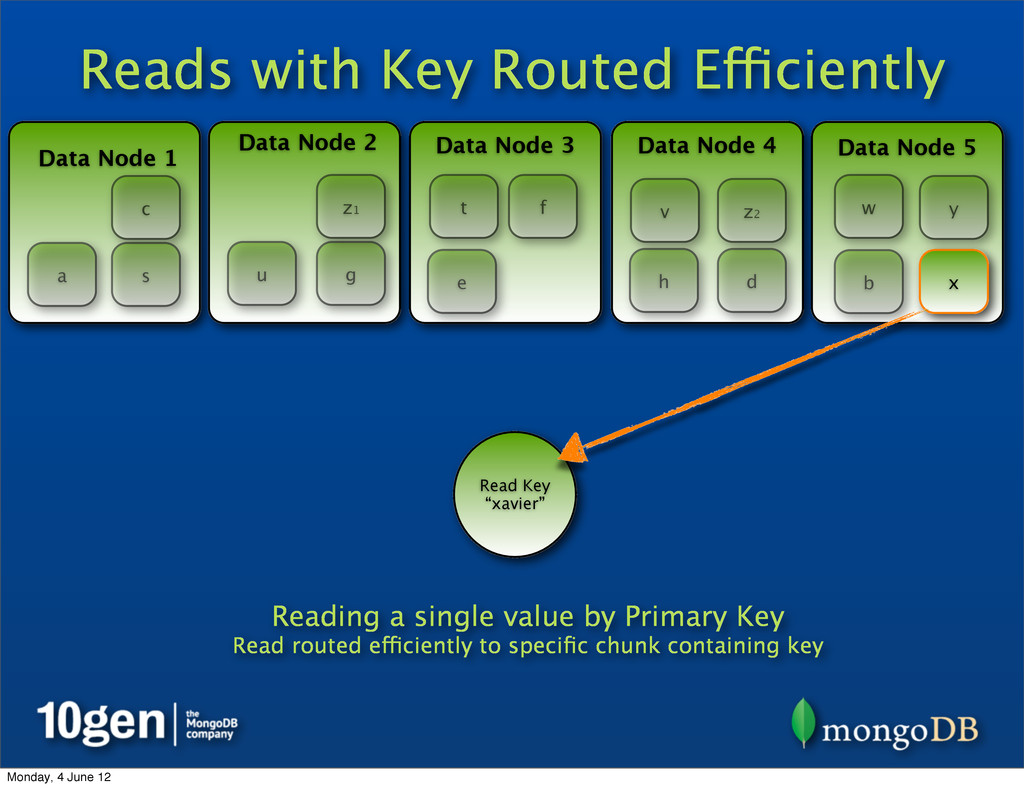
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z1 z2 Monday, 4 June 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z1 z2 Monday, 4 June 12
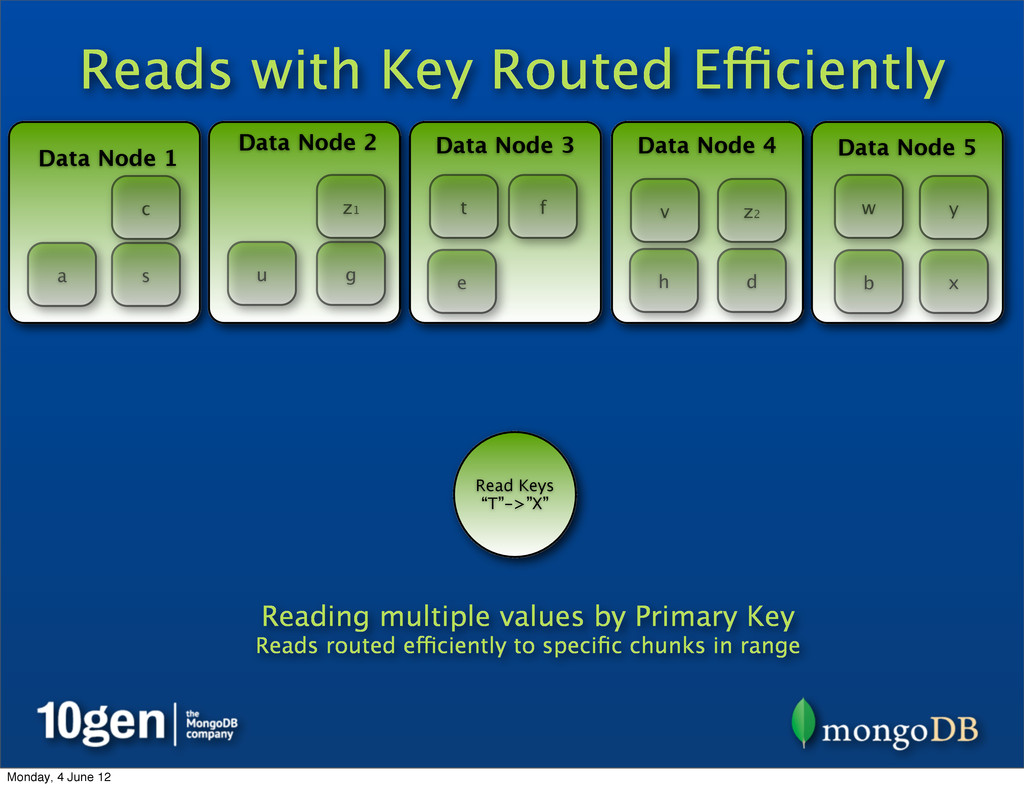
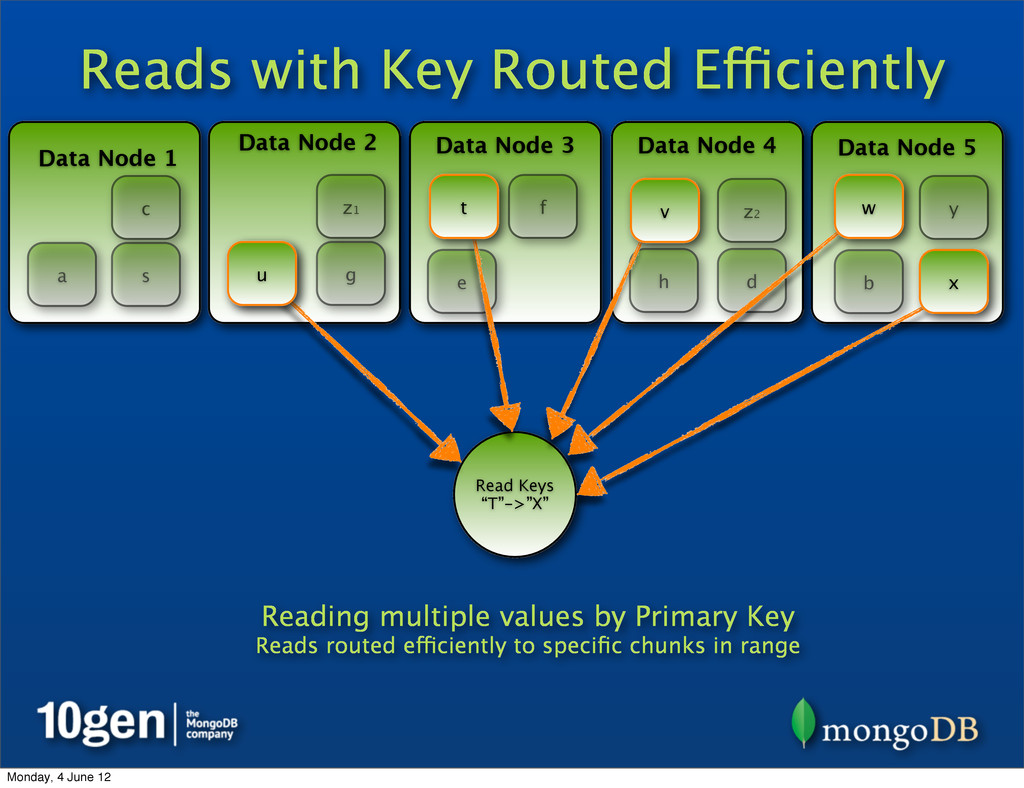
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Keys “T”->”X” Reading multiple values by Primary Key Reads routed efficiently to specific chunks in range t u v w x z1 z2 Monday, 4 June 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Keys “T”->”X” Reading multiple values by Primary Key Reads routed efficiently to specific chunks in range t u v w x z1 z2 Monday, 4 June 12
Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException{ int sum = 0; for ( final IntWritable val : values ){ sum += val.get(); } context.write( key, new IntWritable(sum)); } Classic Hadoop Word Count - Reduce Monday, 4 June 12
![Chris Harris Email : [email protected] Twitter : cj_harris5 Hybrid Datastore](https://files.speakerdeck.com/presentations/4fcc8bceb1fbaf001f004f02/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}