When writing resilient Elixir applications one of our major concerns is state: where do we store it, what happens to it when a process crashes, how do we efficiently recreate it.
In this talk, we'll look at an example application and apply different techniques that can be used to protect and recover state, each one with specific implications and tradeoffs.
All of the techniques shown in this talk can be applied to everyday development.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
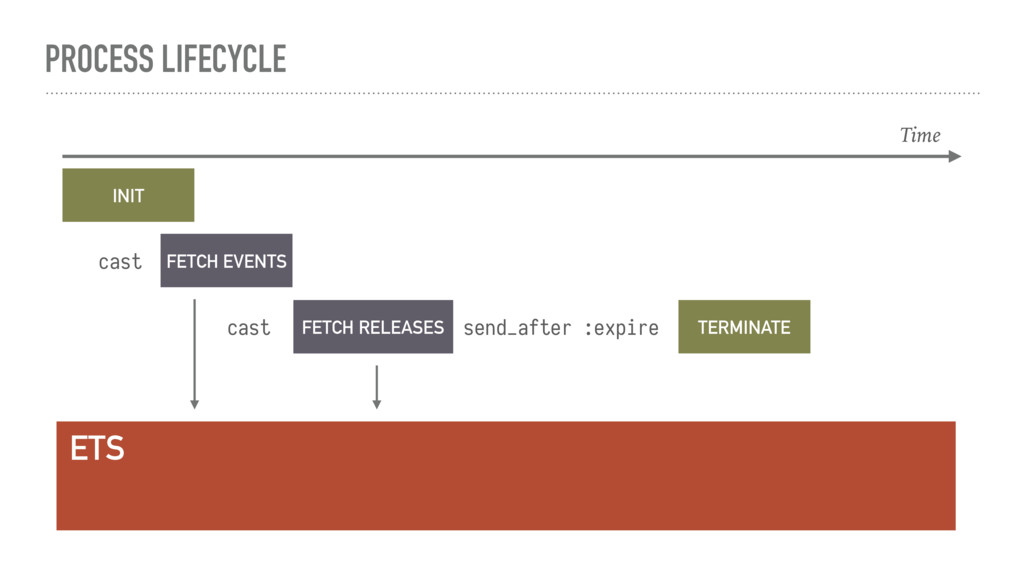{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
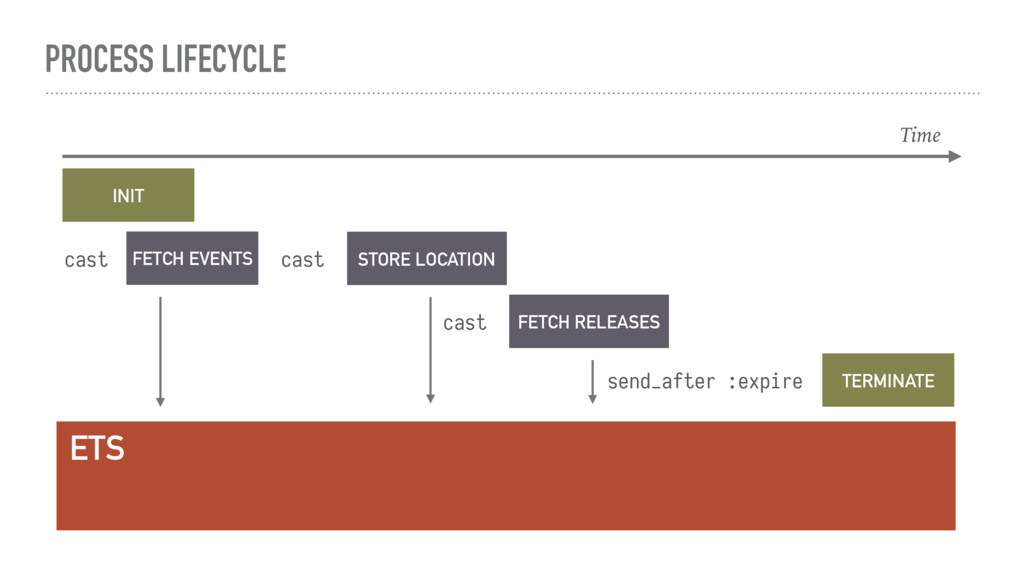{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}