1.1 million emails – 460,000 scanned documents – 230,000 loose files • $50 for hard drive to store • $10 million to review • Cheap storage → junk & duplicates
– 2 lawyers with paralegals and search engine – Aim for at least 75% recall – Got 75% recall once out of 40 tasks – Averaged 20% recall • Queries often fail to recognize all of the ways to say the same thing
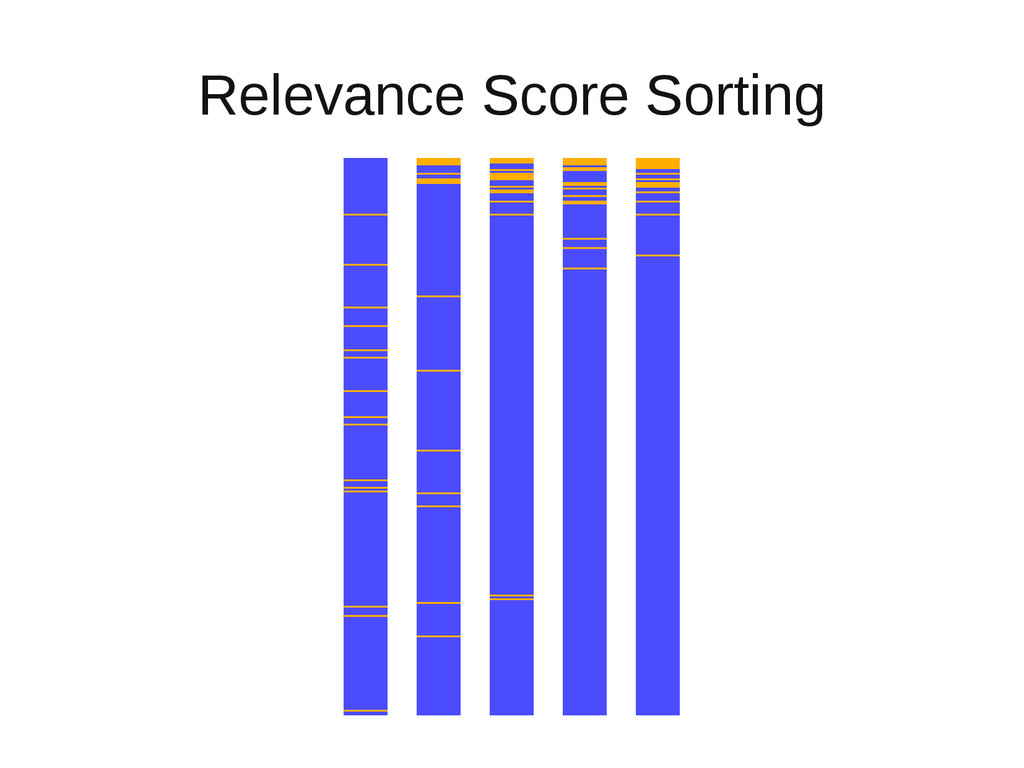
relevant docs tend to be at top of sort • Term frequency-inverse document frequency – Sorting is based on a heuristic rule – Not specific to the problem at hand
found – High recall required for defensibility • Precision – % of docs predicted to be relevant that actually are – High precision desired to reduce cost
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}