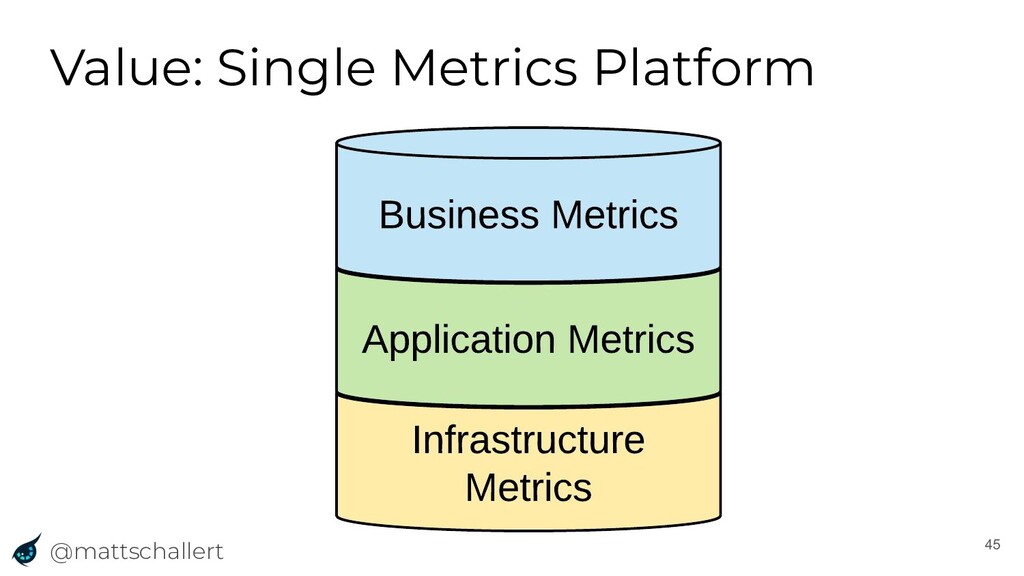
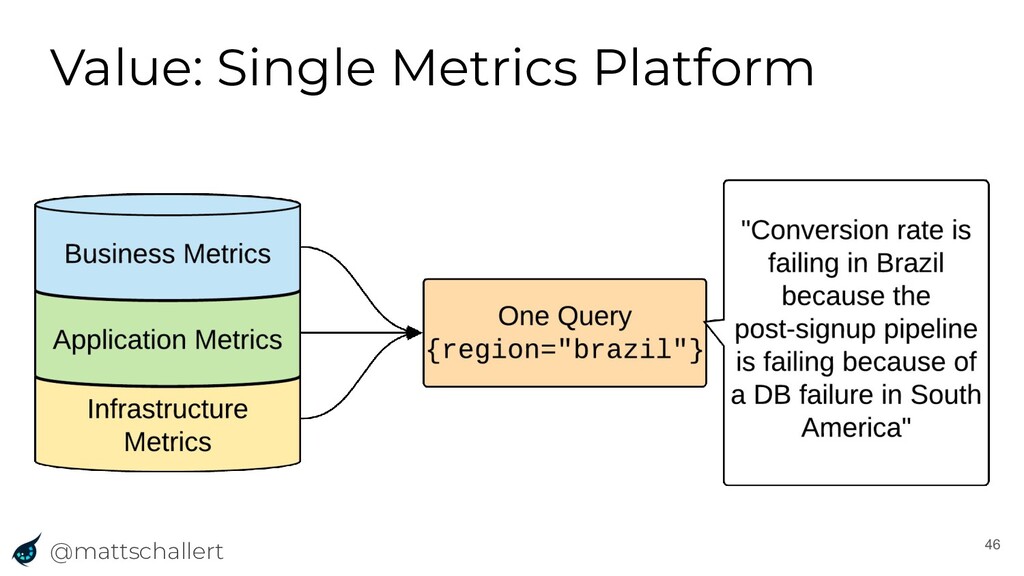
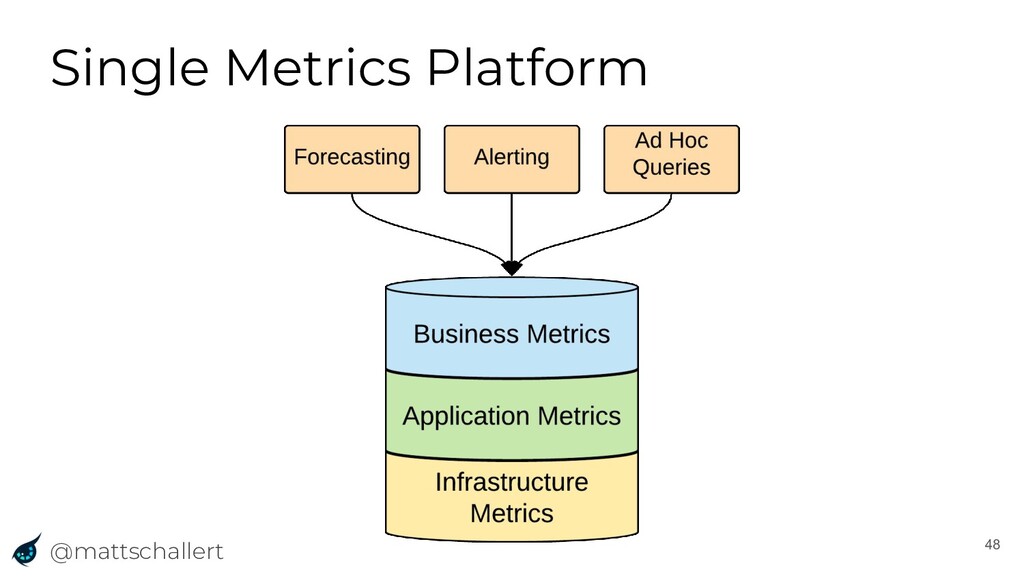
The way we run software has changed dramatically over the past few years, and as such, so has the way we monitor our applications. With the advantages of the cloud and other new technologies comes complexity that our monitoring systems must account for. In this talk, Matt will discuss the evolution of such monitoring systems that led Uber to build M3, an open-source metrics platform. The talk will show how the community can use M3 to leverage Uber’s years of experience monitoring complex globally distributed systems, and integration with existing tools such as Prometheus and Graphite.
About: Matt Schallert, Senior Software Engineer - Chronosphere
Matt is a Senior Software Engineer at Chronosphere and works on M3, an open source metrics platform. Recently, his efforts have been focused on improving the operational experience for users of M3. Previously, Matt was a Senior Site Reliability Engineer at Uber where he helped launch M3, and prior to that he was an SRE at Tumblr. In his spare time, Matt can be found hiking, skiing, and building data centers in his apartment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
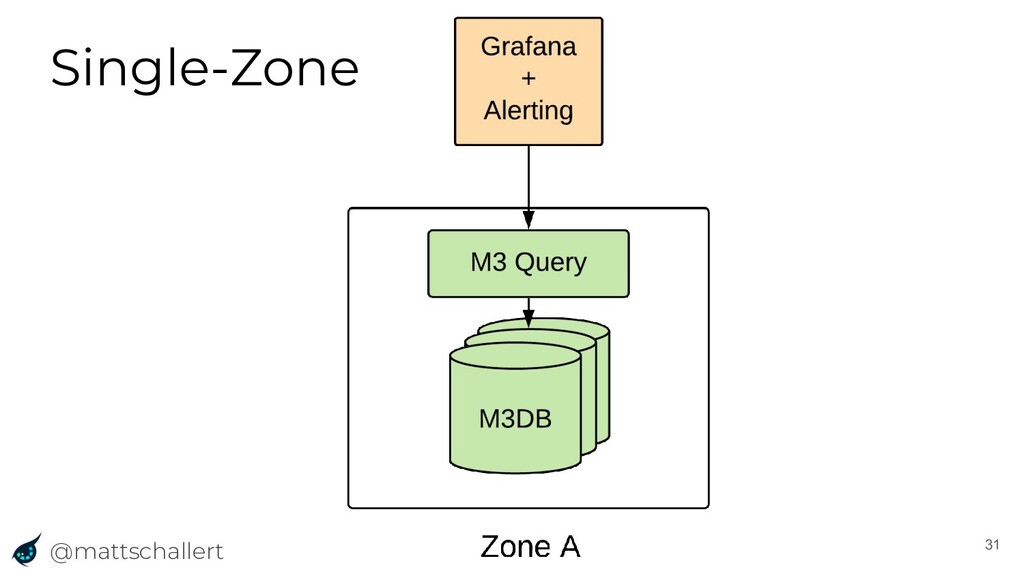{kind=link}
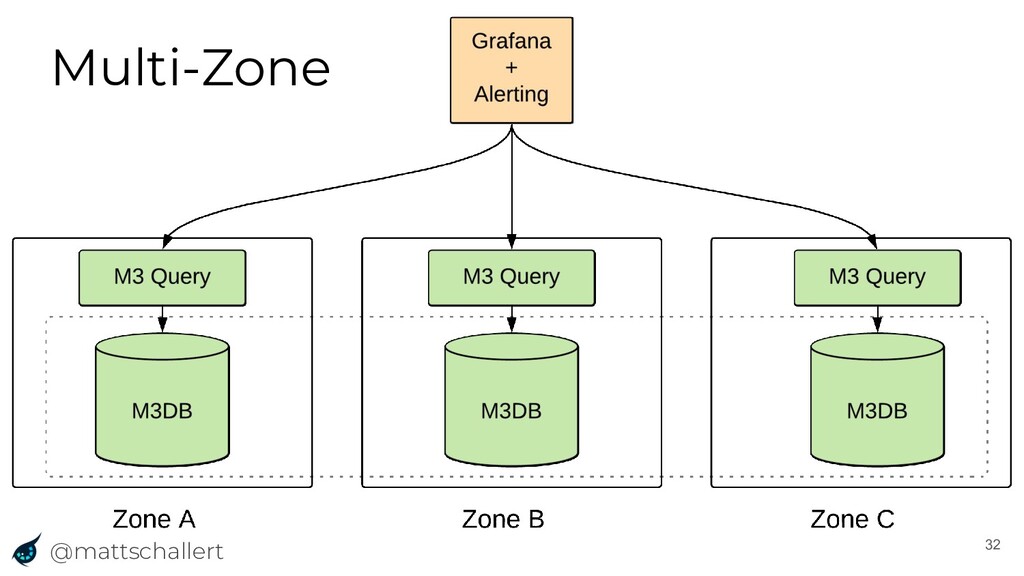{kind=link}
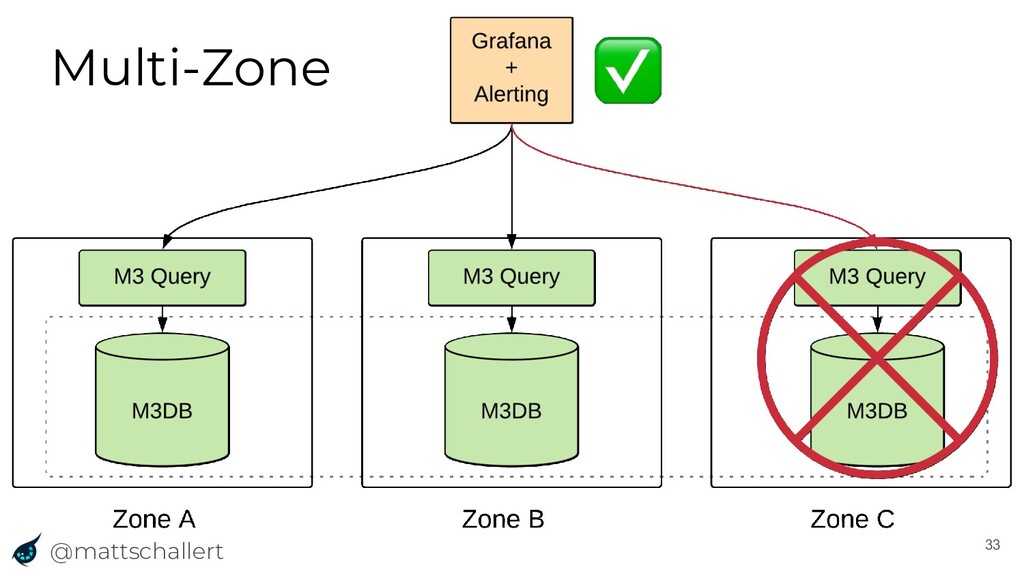{kind=link}
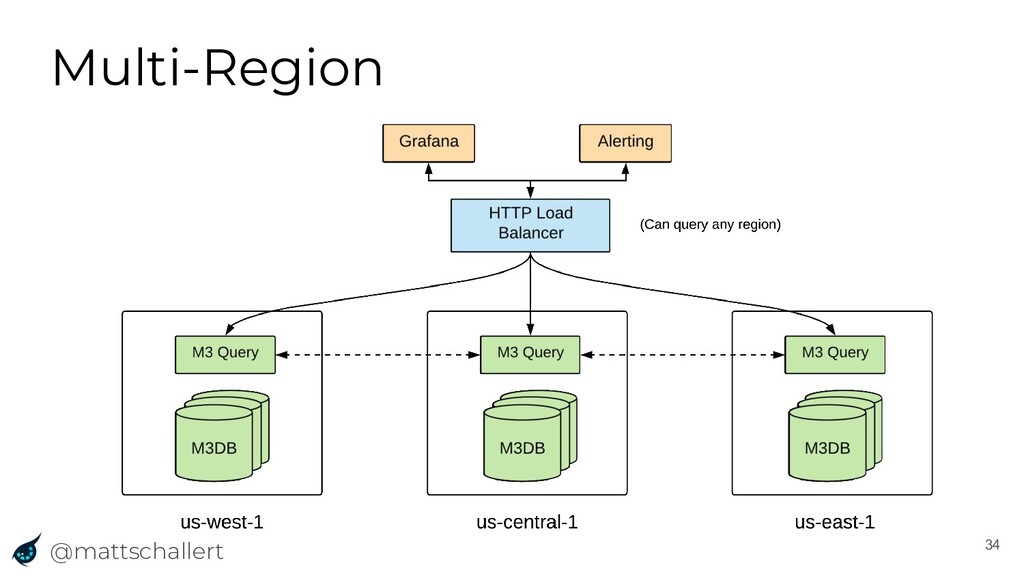{kind=link}
{kind=link}
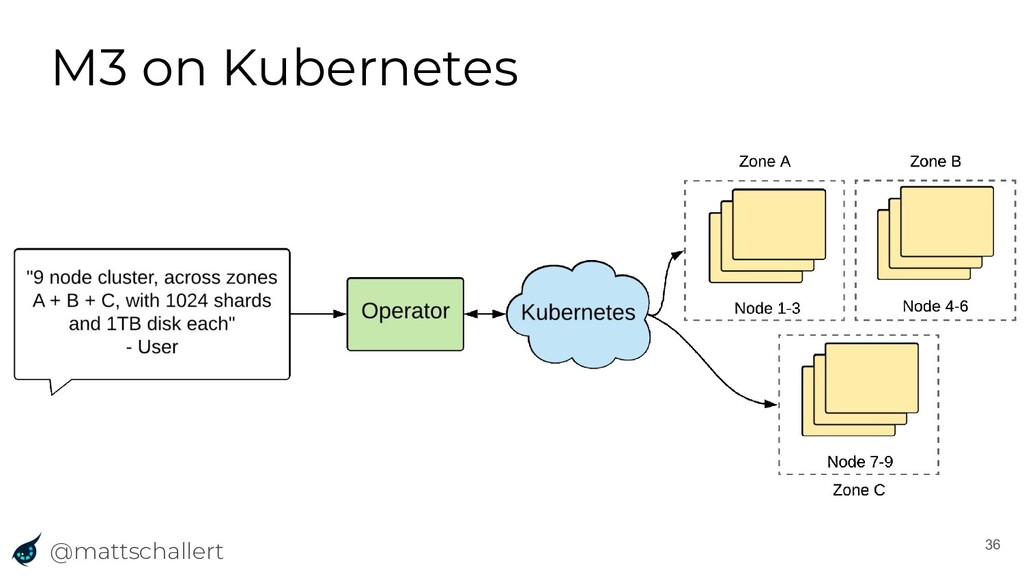{kind=link}
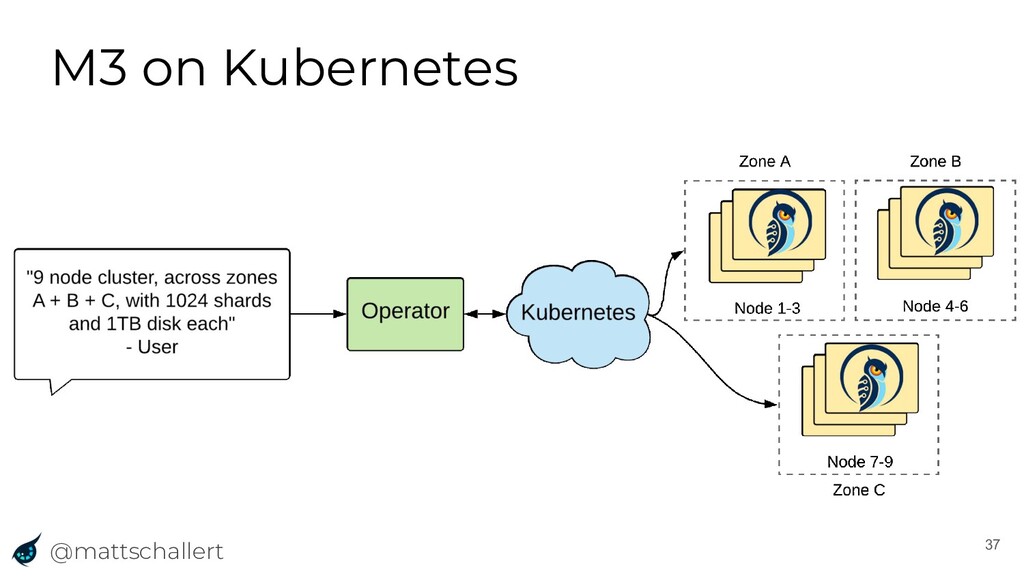{kind=link}
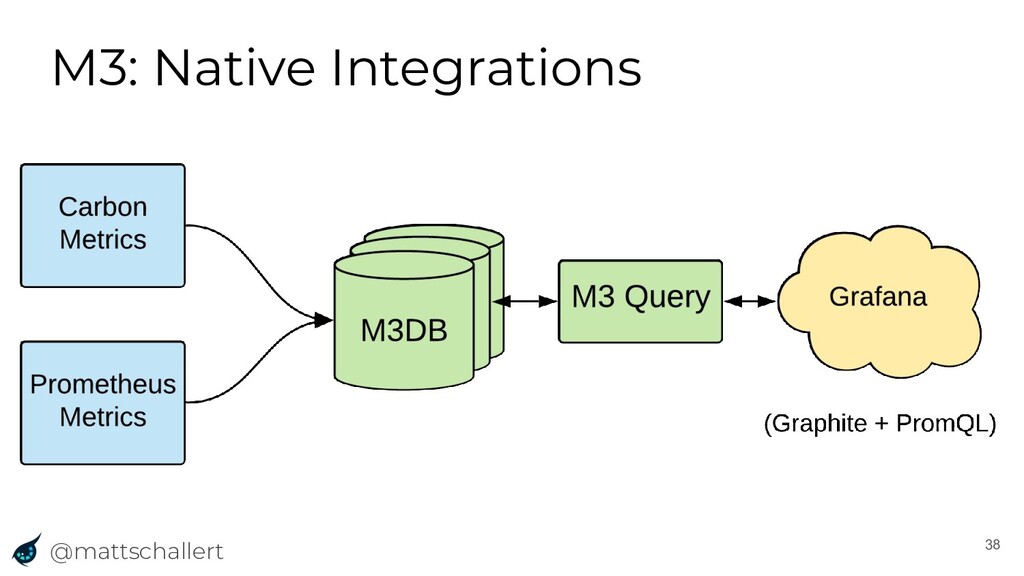{kind=link}
{kind=link}
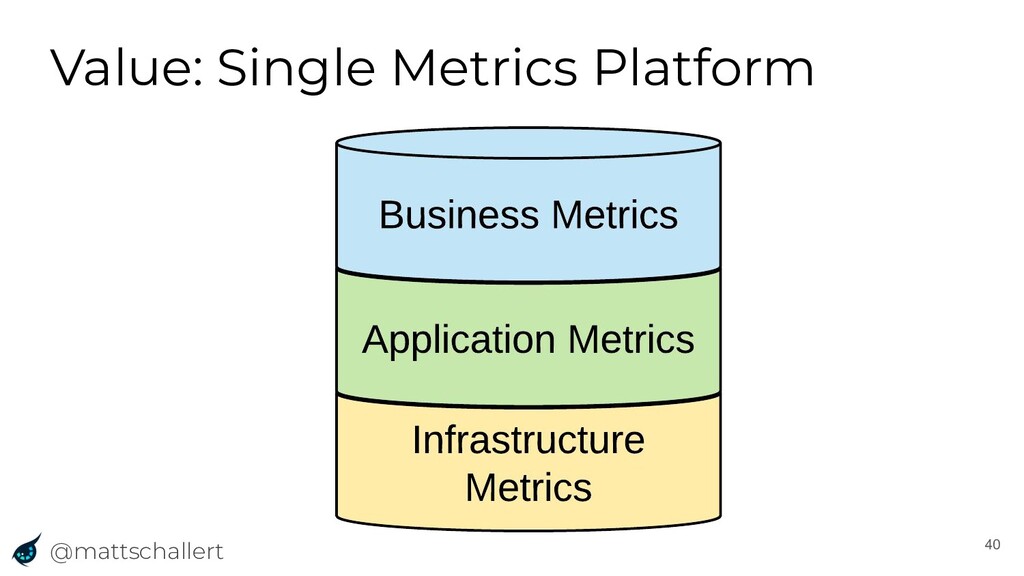{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}