The talk is about utilizing your database more so that you can offload lot of CPU intensive tasks from ruby to rails to make your application run faster.
22 official languages in India,1653 spoken language. And over 50,000 Dialects And I know three of them English, Malayalam and Tamil I am from Huge and Diverse country =)
should be • What you want in your result - SELECT id, name • Or some information about data like - SELECT average(price), max(price), min(price) Where is the decision on how the data should be fetch made.
the query you gave is executed. • Plan is the cost of running the query. The DB chooses the one with the least cost. • Query Plan assumes the plan it has is the ideal one
search engine can use to speed up data retrieval. • An Index is like a pointer to a particular row of a table. Where all the fields in the table are ordered. Database is smart even if you have indexes if it find the sequential search to be cost less then it would go for that one.
key • Index all columns you would be passing into where clause • Index the keys used to Join tables • Index the date column (if you are going to call it frequent, like rankings of a particular date) • Index the type column in an STI or polymorphism. • Add partial index to scopes
lot of read, write • Do not index tables you know that will remain small, all through out its life time • Do not index columns where you will be manipulating lot of its values.
rails. A rails view(an html page) shows data from multiple model in a single page Similarly we can show data from multiple table as a single table using the concept called views Why would we do that? Because it makes life easier
store the result as well in a table • This was first introduced by Oracle • But now found in PostgreSQL, MicrosoftSQL, IBM DB2, etc. • MySQL doesn’t have it you can create it using open source extensions.
a bit of SQL here class CreateAllTimesSalesMatView < ActiveRecord::Migration def up execute <<-SQL CREATE MATERIALIZED VIEW all_time_sales_mat_view AS SELECT sum(amount) as total_sale, DATE_TRUNC('day', invoice_adte) as date_of_sale FROM sales GROUP BY DATE_TRUNC('day', invoice_adte) SQL end def down execute("DROP MATERIALIZED VIEW IF EXISTS all_time_sales_view") end end
view as they operate on your tables primary key and a view doesn’t have it • If you want to use it then you need to one of the fields in your table as primary key class Model < ActiveRecord::Base self.primary_key = :id end
used joins & filters. • Push data intensive processing from Ruby to Database. • Allow fast and live filtering of complex associations or calculation .fields. • We can index various fields in the table.
will be using more RAM and Storage • Requires Postgres 9.3 for MatView • Requires Postgres 9.4 to refresh concurrently • Can’t have Live data • You can fix this by creating your own table and updating it with the latest information
is coming to an end • Its the era of new modern day JS frameworks • JSON is the glue that binds the fronted and our backend • So its natural to find more and more DB supporting the generation and storage of JSON.
email, ( select array_to_json(array_agg(row_to_json(user_projects))) from ( select id, name from projects where user_id=users.id order by created_at asc ) user_projects ) as projects from users where id = 1 ) result
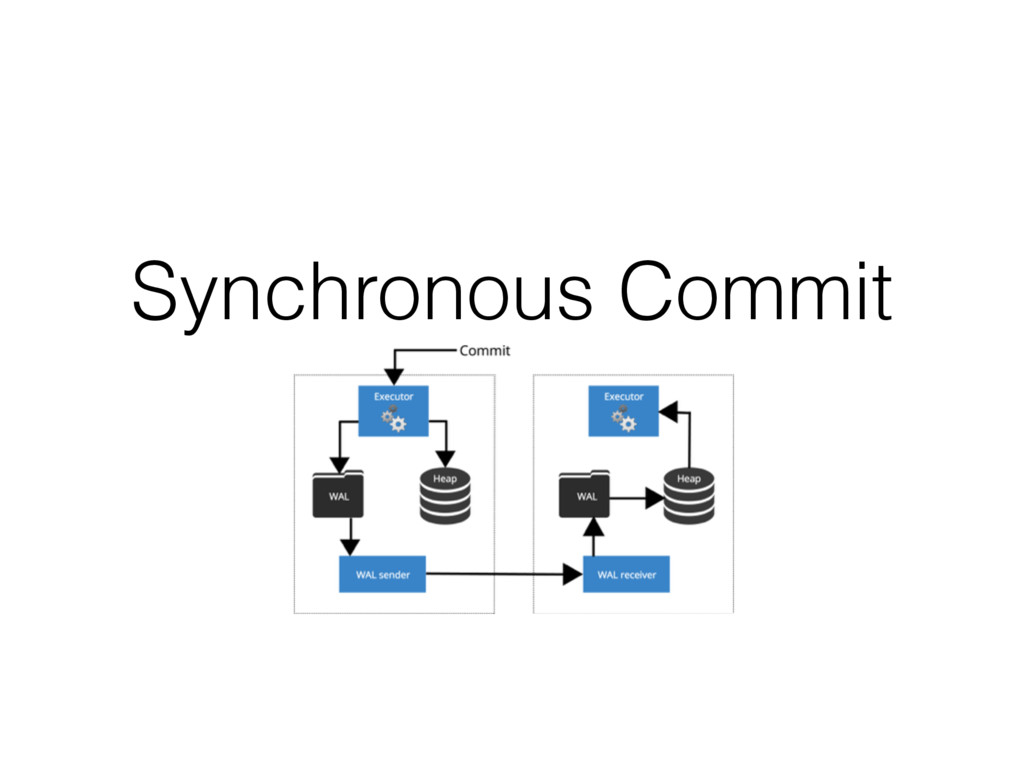
is known for its slow writes and faster readers • It has slow writes as it waits for confirmation that what we inserted has been recorded to the Hard Disk. • You can disable this confirmation check to speed up your inserts if you are inserting a lot of rows every second
can’t recover the lost data not saved to Hard Disk • It won’t corrupt the data, but you might loose some rows of your data • Not to be used in cases when you want data integrity to be 100% • Use it where you don’t mind loosing some information or where you can rebuild it from outside your DB. Like logs, or raw information.
the whole DB • Simplify the way you fetch data from the DB using views • Move complicated JSON generation to the Databases • Disable synchronous commit when you feel like it won’t cause a problem
control over all our moving parts • Try to bring about the best with your tech stack before you start throwing more money at it • SQL has been around for 40 years and its planning to say for a while longer =) • There is no golden rule. What worked for me might not work for your specific use case.
{kind=link}
![{ “name” => "Harisankar P S", “email” => ”[email protected]", “twitter”](https://files.speakerdeck.com/presentations/81ba87c3c679445b9c45902ee99120f9/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Now we can do AllTimeSalesMatView.select(:name) AllTimeSalesMatView.where(email: '[email protected]')](https://files.speakerdeck.com/presentations/81ba87c3c679445b9c45902ee99120f9/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{“id":1,"email":"[email protected]", "encrypted_password":"iwillbecrazytodisplaythat", "reset_password_token":null,"reset_password_sent_at":null, "remember_created_at":"2016-11-06T08:39:47.983222", "sign_in_count": 11,"current_sign_in_at":"2016-11-18T11:47:01.946542", "last_sign_in_at":"2016-11-16T20:46:31.110257", "current_sign_in_ip":"::1","last_sign_in_ip":"::1", "created_at":"2016-11-06T08:38:46.193417", "updated_at":"2016-11-18T11:47:01.956152",](https://files.speakerdeck.com/presentations/81ba87c3c679445b9c45902ee99120f9/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
![{ “id":1,"email":"[email protected]", "project":["id": 3, "name": “CSnipp"] } We did data](https://files.speakerdeck.com/presentations/81ba87c3c679445b9c45902ee99120f9/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}