(Junseong Kim) Crazy at NLP! Open-Domain Dialog System / Chatbot Sentence Representation Model Neural Machine Translation Machine Learning on Service github.com/codertimo fb.com/codertimo linkedin.com/in/codertimo codertimo.github.io
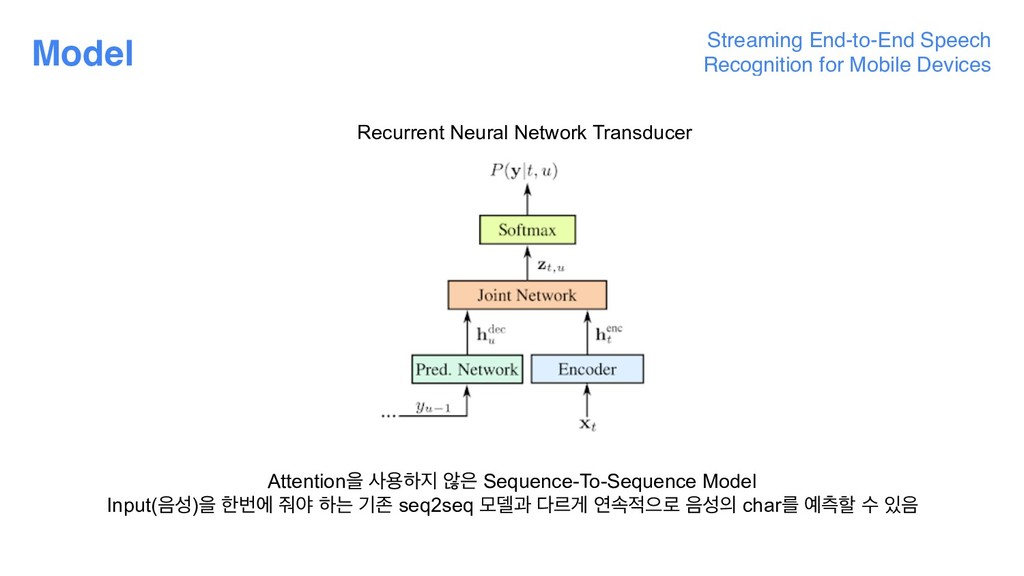
Transformers for Language Understanding • Evolved Transformer : NAS for better BERT model • Vision • Self-Supervised Tracking via Video Colorization • Speech Generation • Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron • Direct speech-to-speech translation with a sequence-to-sequence model • Speech Recognition • Streaming End-to-end Speech Recognition For Mobile Devices
(2000~) 3. Bi-LSTM Language Modeling (2012~) 4. Multi-Layer BI-LSTM Language Modeling (2014) 5. ELMo: Deep Contextualized word representation (2017) 6. Universal Language Model Fine-Tuning for Text Classification (2018) 7. BERT: Pre-training of Deep Bidirectional Transformer for Language Modeling (2018) 8. GPT-2 : Language Models are Unsupervised Multitask Learners 8. XLNet: Generalized Autoregressive Pre-training for Language Modeling (2019) Transfer Learning History of NLP
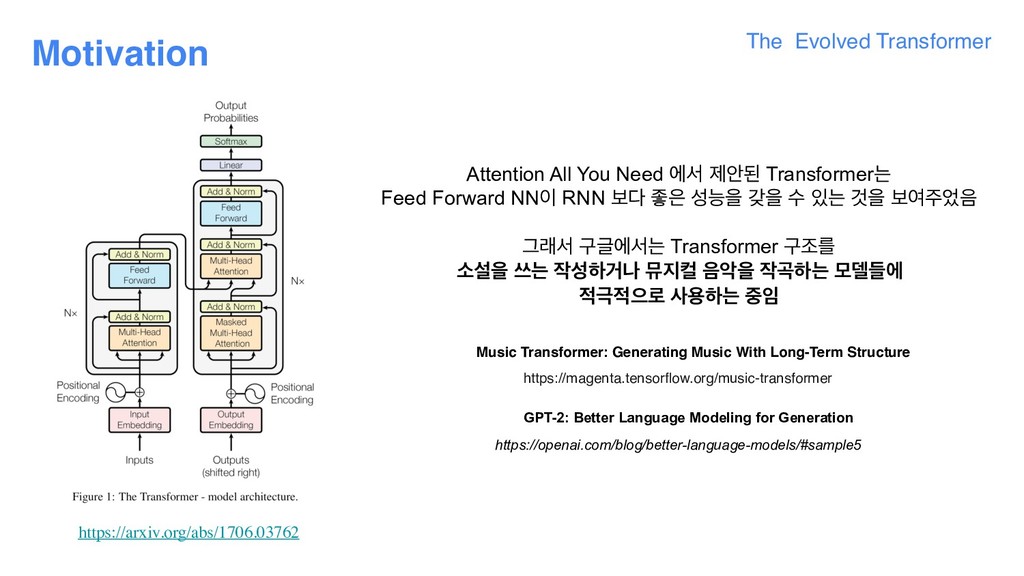
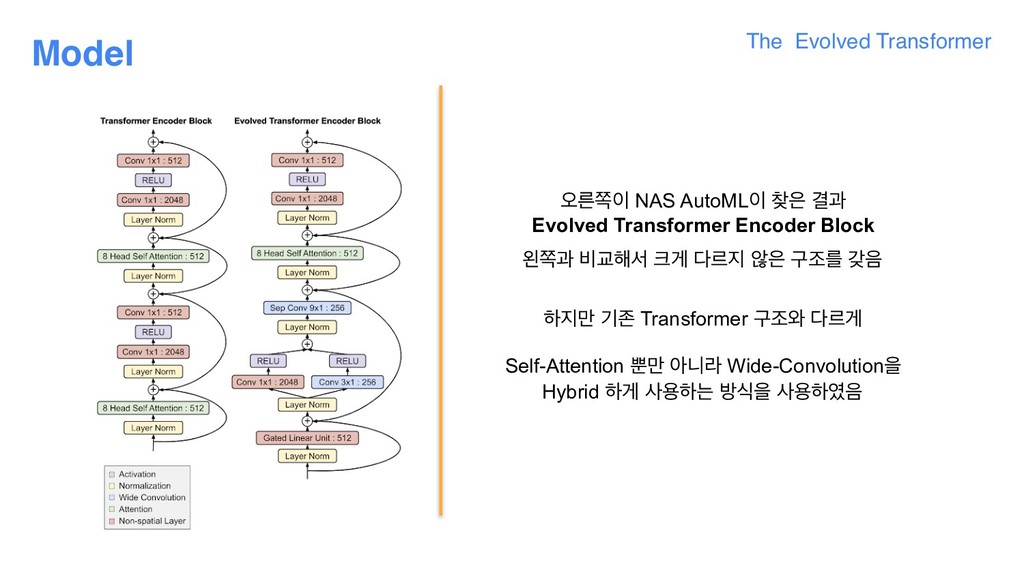
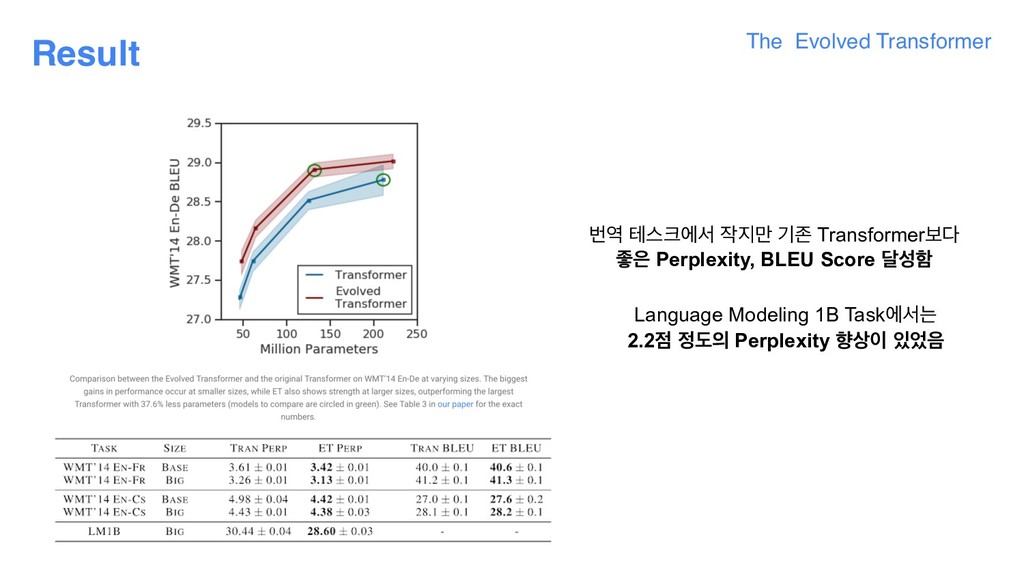
the evolutionary NAS, it was necessary for us to develop new techniques, due to the fact that the task used to evaluate the “fitness” of each architecture, WMT’14 English-Germantranslation, is computationally expensive. This makes the searches more expensive than similar searches executed in the vision domain, which can leverage smaller datasets, like CIFAR-10. The first of these techniques is warm starting— seeding the initial evolution population with the Transformer architecture instead of random models. This helps ground the search in an area of the search space we know is strong, thereby allowing it to find better models faster. The second technique is a new method we developed called Progressive Dynamic Hurdles (PDH), an algorithm that augments the evolutionary search to allocate more resources to the strongest candidates, in contrast to previous works, where each candidate model of the NAS is allocated the same amount of resources when it is being evaluated. PDH allows us to terminate the evaluation of a model early if it is flagrantly bad, allowing promising architectures to be awarded more resources. 1. ׳ࢿೞҊ ೞח పझо ߣ పझӝ ٸޙী Trainingਸ ೠߣೡ ٸ ݃ য়ے ण ਃೣ 2. Ӓؘ۠ Random Modelࠗఠ Searching ਸ दೞݶ Spaceо ցޖ և 3. Transformer ݽ؛ਸ ച द(warm-up)ਵ۽ ࣁೞҊ ইࠁ! (ण ߑߨ 1) 4. ചܳ ೞݶࢲ ؊ ੜೞח ݽ؛ٜী ਵ۽ ܻࣗझܳ ೣ (࢜۽ ઁউೠ / ण ߑߨ 2) ਃড:
Work Our results show that video colorization provides a signal that can be used for learning to track objects in videos without supervision. Moreover, we found that the failures from our system are correlated with failures to colorize the video, which suggests that further improving the video colorization model can advance progress in self-supervised tracking. ખ ؊ ࣁೞѱ ࠁפӬ Colorization ੜ উغࢲ Tracking ੜ উػ ҃о ࠗ࠙ Colorizationਸ ؊ ੜೡ ࣻ ח ݽ؛ਸ ৌब ٜ݅ (ۨ࠶ਸ ؊ ೞחѱ ইפۄ)
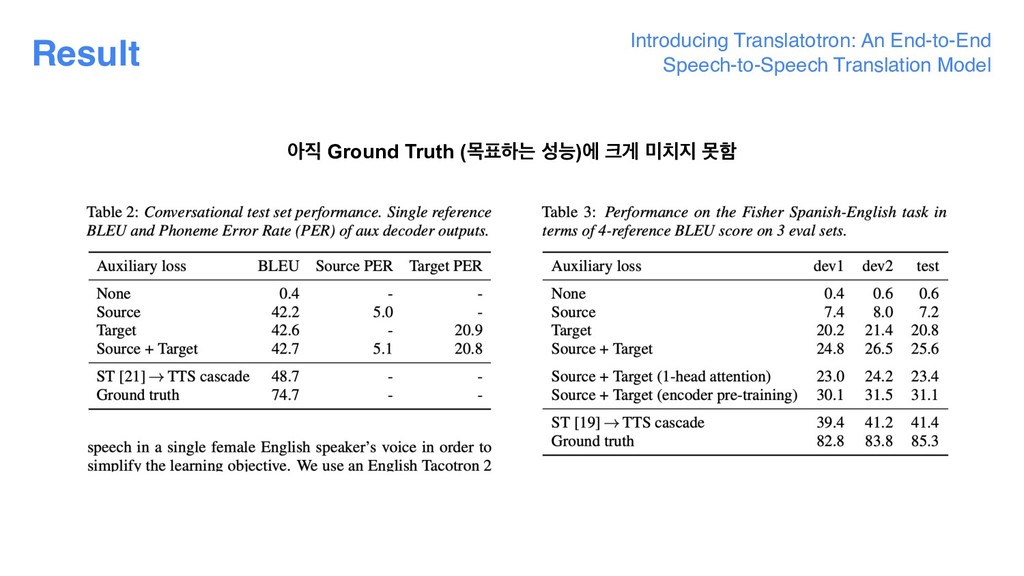
K., et al. "Attention-based models for speech recognition." Advances in neural information processing systems. 2015. Chan, William, et al. "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016. р ݽ؛ হ End-to-End ࢿੋध ݽ؛ٜب ৌब োҳغਵա ইөח ӝઓ ࢿੋध ࢿמਸ ٮۄৢ ࣻ হ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![хࢎפ! github.com/codertimo fb.com/codertimo linkedin.com/in/codertimo codertimo.github.io [email protected]](https://files.speakerdeck.com/presentations/be277cedaf8d47a7b23f4e0f86b45318/slide_82.jpg){kind=link}