の紹介 固有表現抽出をドメイン外の弱いラベリングたちから学習する Pierre Lison, Jeremy Barnes, Aliaksandr Hubin, Samia Touileb. Named Entity Recognition without Labelled Data: A Weak Supervision Approach. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020. https://www.aclweb.org/anthology/2020.acl-main.139/ 2020 年 08 月 05 日 三原 千尋 原論文
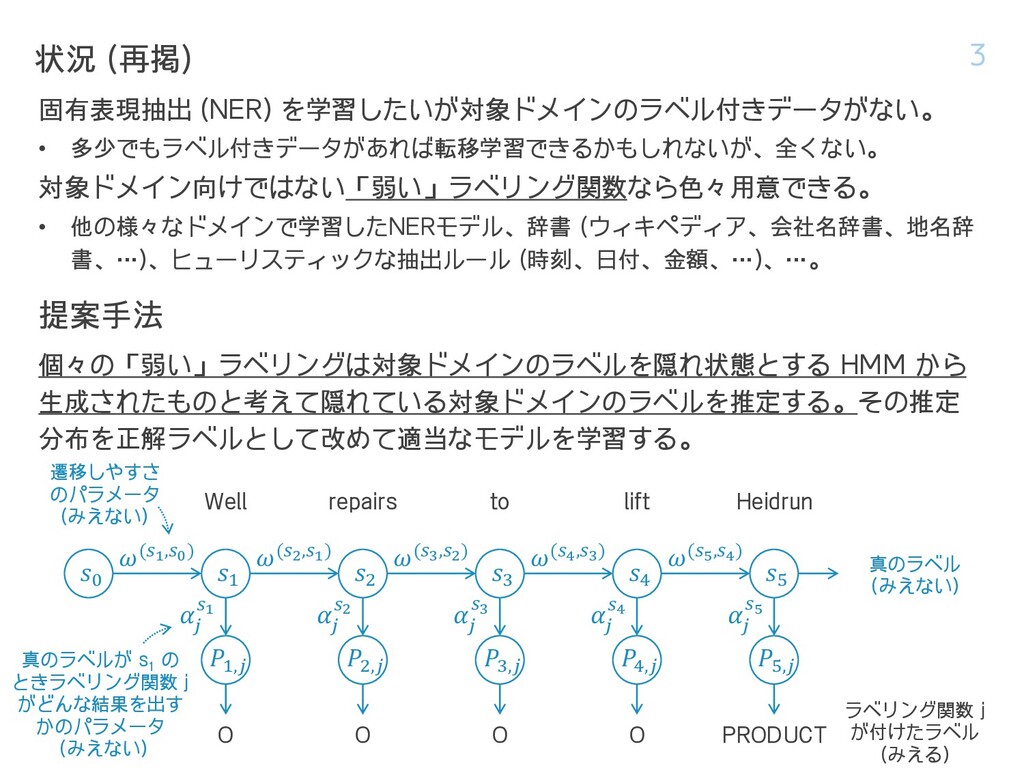
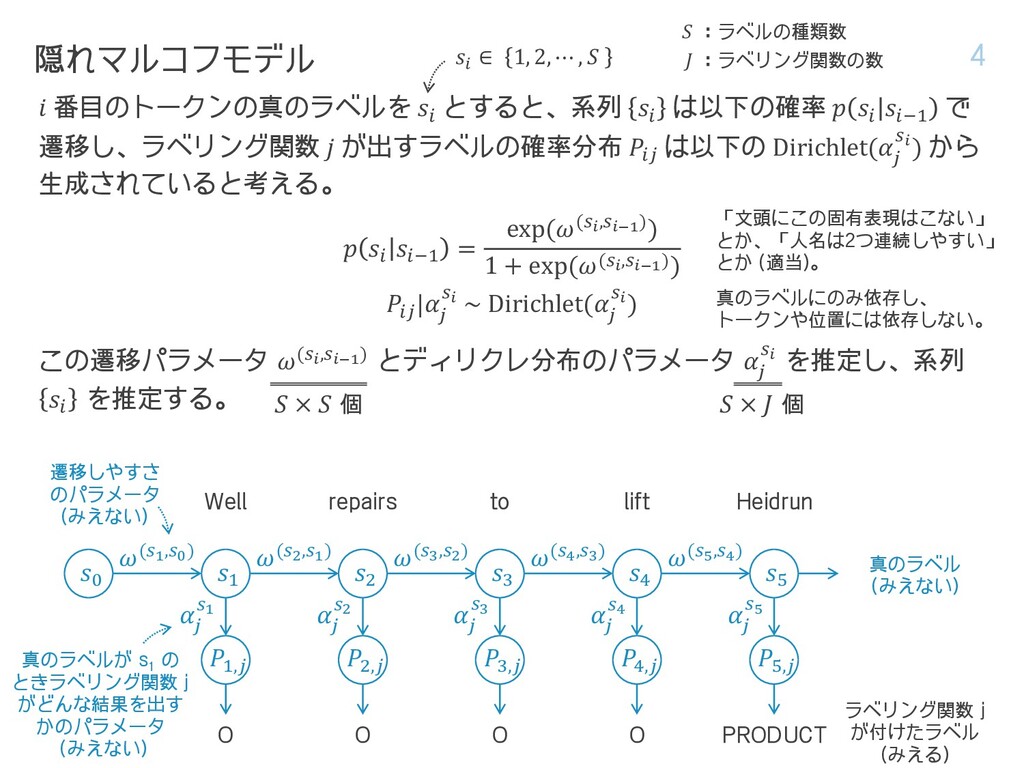
OSLO 1996-08-22 Three plugged water injection wells on the Heidrun oilfield off mid-Norway will be reopened over the next month , … 状況 2 製品名 政治的機能をもつ地名 地名 会社名 日付 その他数値 多様なジャンルの文書を含む公開 コーパスで学習した NER モデル Well repairs to lift Heidrun oil output - Statoil . OSLO 1996-08-22 Three plugged water injection wells on the Heidrun oilfield off mid-Norway will be reopened over the next month , … Well repairs to lift Heidrun oil output - Statoil . OSLO 1996-08-22 Three plugged water injection wells on the Heidrun oilfield off mid-Norway will be reopened over the next month , … Well repairs to lift Heidrun oil output - Statoil . OSLO 1996-08-22 Three plugged water injection wells on the Heidrun oilfield off mid-Norway will be reopened over the next month , … 固有表現の凡例: 会社名辞書 日付、時刻、金額などの数詞に特 化したヒューリスティックな抽出 ルール 各エンティティに対して、色々な ラベリング関数の結果を文書レベ ルで多数決したもの Heidrun (地名) を製品名に誤っている。 Statoil 社を拾えていない。 会社名特化型で Statoil 社を拾えるが、 それしか拾えない。 数字特化型でこの範囲は正しそうだが…。 この範囲は正しそうだが…。 固有表現抽出 (NER) を学習したいが対象ドメインのラベル付きデータがない。 • 多少でもラベル付きデータがあれば転移学習できるかもしれないが、全くない。 対象ドメイン向けではない「弱い」ラベリング関数なら色々用意できる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
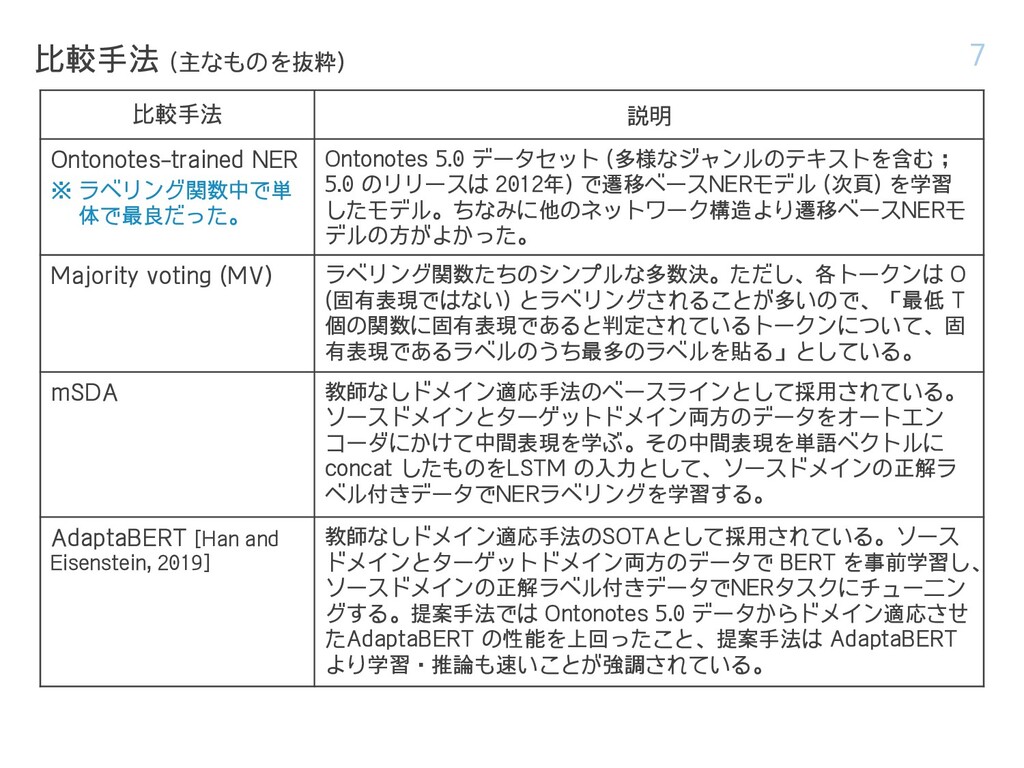
{kind=link}
{kind=link}
![【参考】Transition-Based NER [Lample 2016] 8 スタックLSTM アクション スタック バッファ アウトプット](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_7.jpg){kind=link}
![【参考】LSTM + CRF層モデル [Lample 2016] 9 ニューラルネットによる系列ラベリング (固有表現抽出、品詞タグ付け) では、単に各ステッ プの予測確率最大のラベルを拾ったのでは系列として整合性が取れない場合があるので、各](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![参考文献 12 • [Lample 2016] Guillaume Lample, Miguel Ballesteros, Sandeep](https://files.speakerdeck.com/presentations/63cb5aaf51a443b49faa8315aa35c6ea/slide_11.jpg){kind=link}