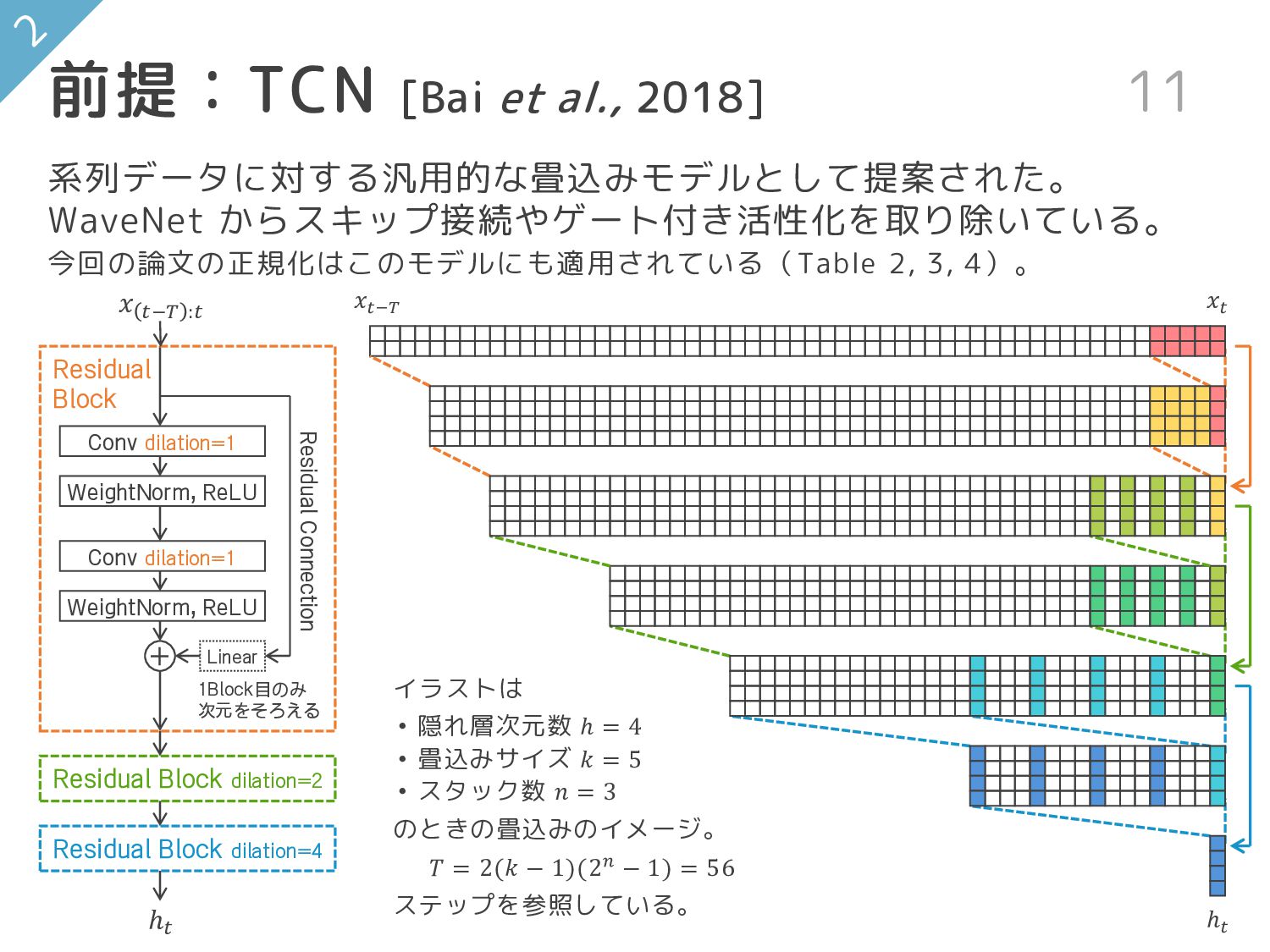
5 • スタック数 𝑛 = 3 のときの畳込みのイメージ。 𝑇 = 2(𝑘 − 1)(2𝑛 − 1) = 56 ステップを参照している。 前提:TCN [Bai et al., 2018] 11 + Conv dilation=1 WeightNorm, ReLU WeightNorm, ReLU Residual Connection Conv dilation=1 Residual Block Residual Block dilation=2 Residual Block dilation=4 𝑥 𝑡−𝑇 :𝑡 ℎ𝑡 系列データに対する汎用的な畳込みモデルとして提案された。 WaveNet からスキップ接続やゲート付き活性化を取り除いている。 今回の論文の正規化はこのモデルにも適用されている(Table 2, 3, 4)。 ℎ𝑡 𝑥𝑡 𝑥𝑡−𝑇 Linear 1Block目のみ 次元をそろえる
{kind=link}
{kind=link}
![先行研究 3 LogSparse Transformer [Li et al. 2019] トランスフォーマーを時系列データに応用する上で、アテンション Softmax(QK⊤/√d)](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_2.jpg){kind=link}
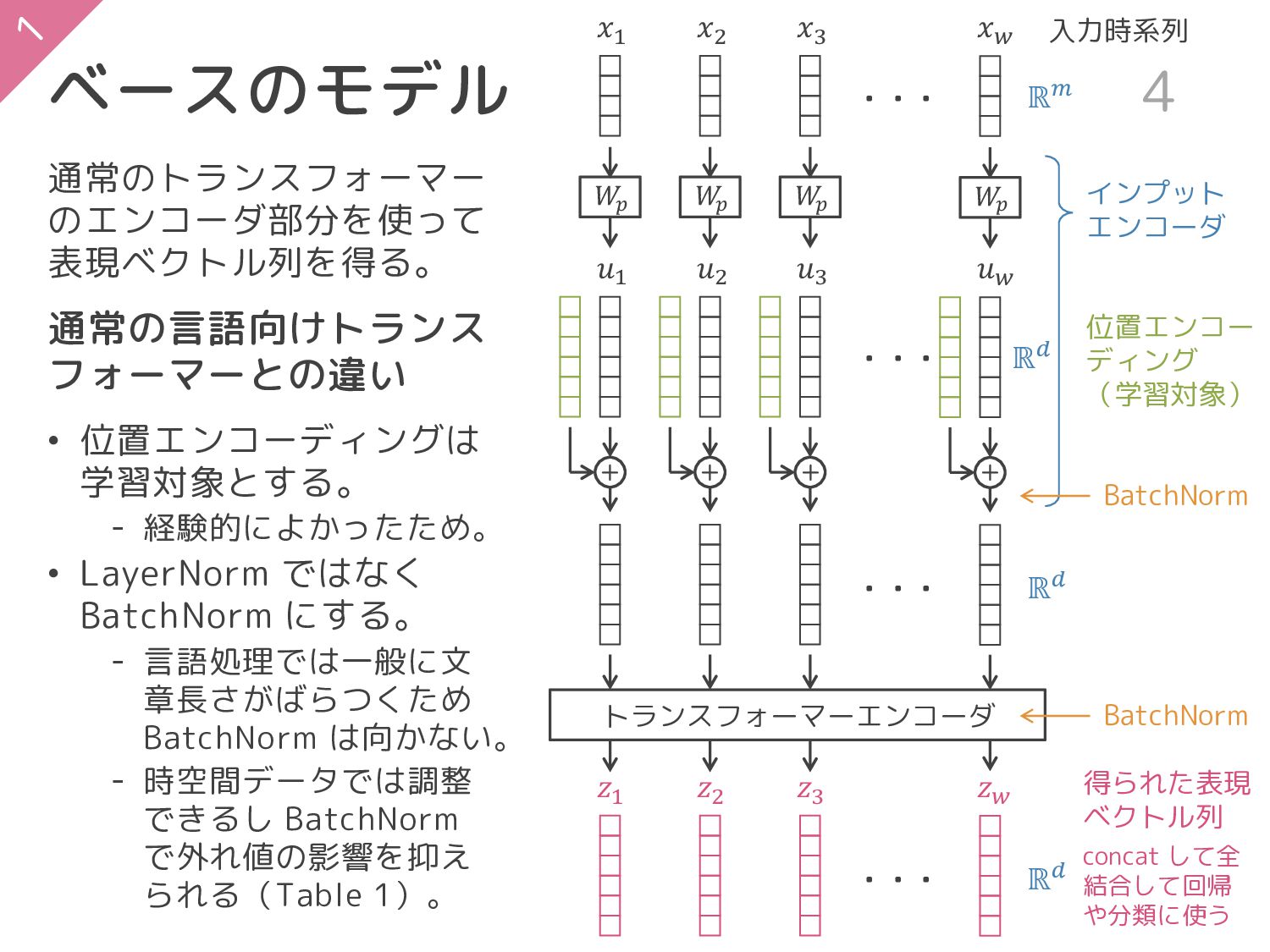{kind=link}
{kind=link}
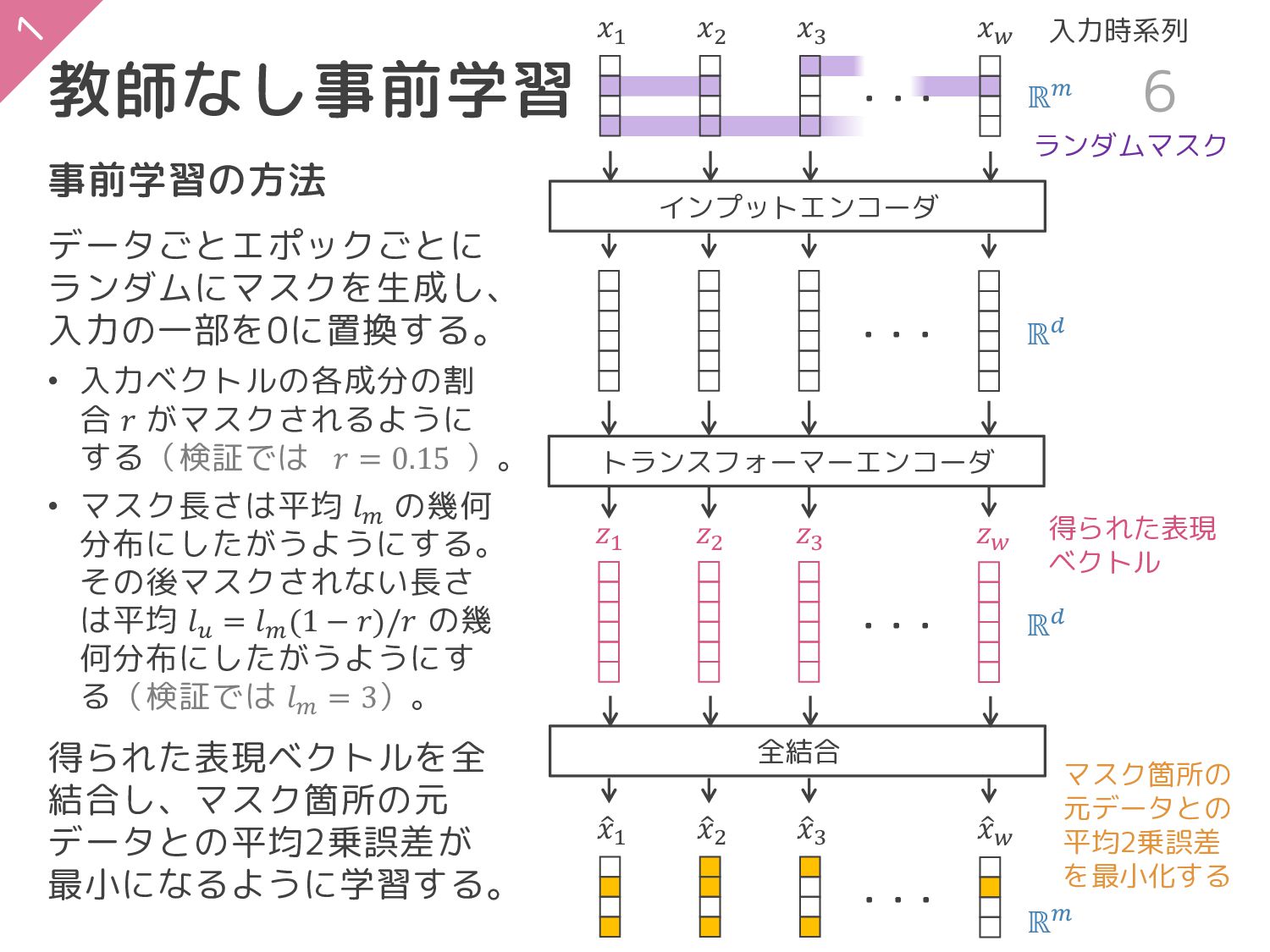{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前提:WaveNet [van den Oord et al., 2016]10 + Conv dilation=1](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
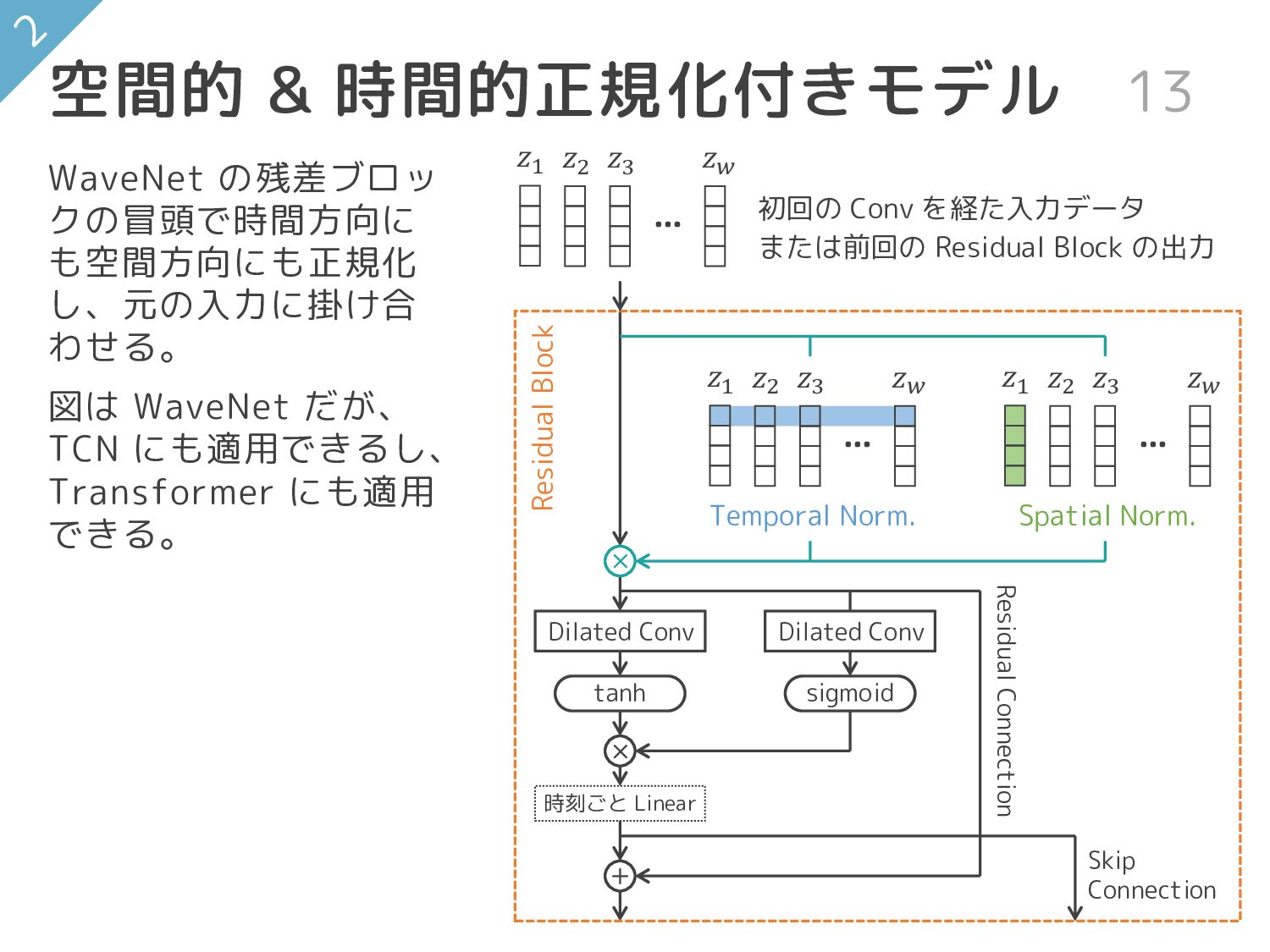{kind=link}
{kind=link}
![概要 15 何かを予測するとき予測値だけでなくその予測がどれだけ不確かなのか もほしいことがある。判断を誤ると致命的なドメインでは重要。 ニューラルネットでも予測の不確かさを扱おうという研究は色々なされ てきた [17, 47, 55, 60]。](https://files.speakerdeck.com/presentations/4cbe9918d92d44549277bb009468bd31/slide_14.jpg){kind=link}