Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
強化學習之 Q Learning
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Joy Chen
May 22, 2017
Research
140
0
Share
強化學習之 Q Learning
Joy Chen
May 22, 2017
Other Decks in Research
See All in Research
SREのためのテレメトリー技術の探究 / Telemetry for SRE
yuukit
13
3.4k
LLMアプリケーションの透明性について
fufufukakaka
0
200
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
110
ドメイン知識がない領域での自然言語処理の始め方
hargon24
1
280
都市交通マスタープランとその後への期待@熊本商工会議所・熊本経済同友会
trafficbrain
0
180
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
190
Dwangoでの漫画データ活用〜漫画理解と動画作成〜@コミック工学シンポジウム2025
kzmssk
0
200
姫路市 -都市OSの「再実装」-
hopin
0
1.7k
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
1.2k
社内データ分析AIエージェントを できるだけ使いやすくする工夫
fufufukakaka
1
1k
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
740
AI Agentの精度改善に見るML開発との共通点 / commonalities in accuracy improvements in agentic era
shimacos
6
1.5k
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
430
Site-Speed That Sticks
csswizardry
13
1.1k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
440
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
27
3.4k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
53k
Making the Leap to Tech Lead
cromwellryan
135
9.8k
Embracing the Ebb and Flow
colly
88
5k
Practical Orchestrator
shlominoach
191
11k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.7k
Navigating Team Friction
lara
192
16k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
110
Transcript
強化學習之 Q Learning 2017/5/18 ctjoy
今天的⽬目標只有⼀一個
Q Learning
None
順便便會講到 • 強化學習基本元件 • ⾺馬可夫鏈在強化學習中的⾓角⾊色 • 策略略迭代與價值迭代 • 蒙地卡羅與時間分差 •
SARSA • Q Learning
None
None
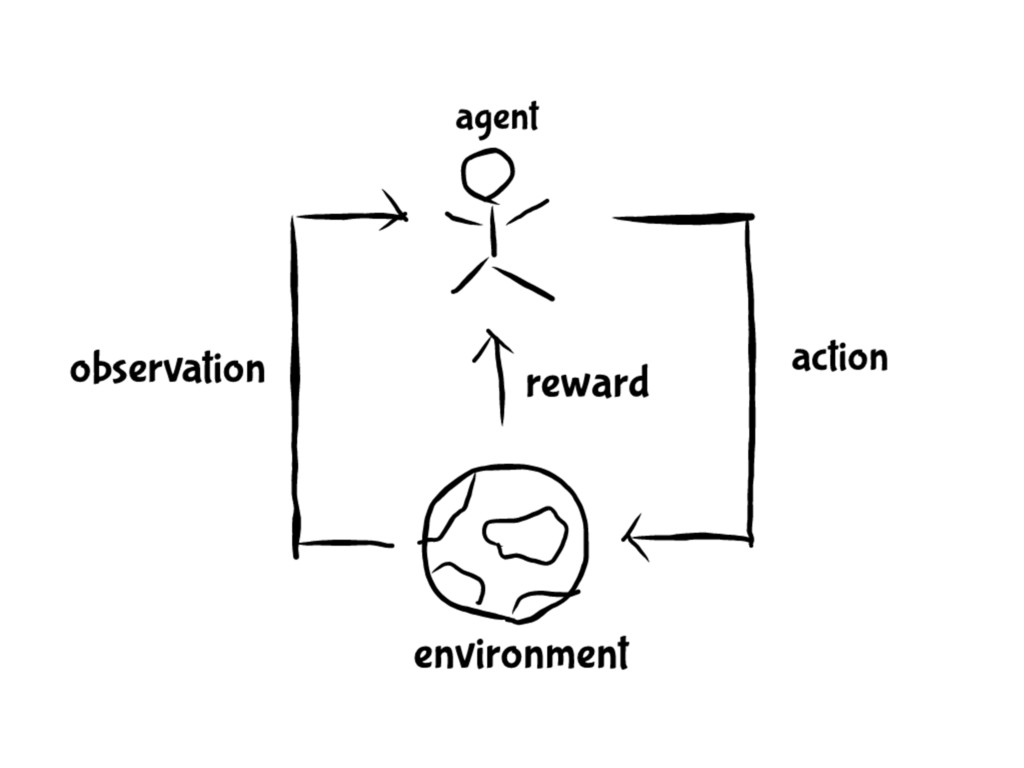
• 機器學習的⼀一個分⽀支 • 沒有答案只有獎勵 • 獎勵有可能有時間延遲且不連續 • 有時間順序 • 你選擇的動作會影響下⼀一步收到的資料
強化學習
None
⽬目標:最⼤大化累積期望獎勵 在某個時間點的⽬目標:選擇那個可 以最⼤大化未來來獎勵的動作
所以重點在機器⼈人怎麼判斷
你平常怎麼判斷要做什什麼動作? 經驗
None
發⽣生過的事稱為狀狀態 state
agent state environment state 重要 不重要 機器⼈人不⼀一定會知道 知道了了也不⼀一定有⽤用
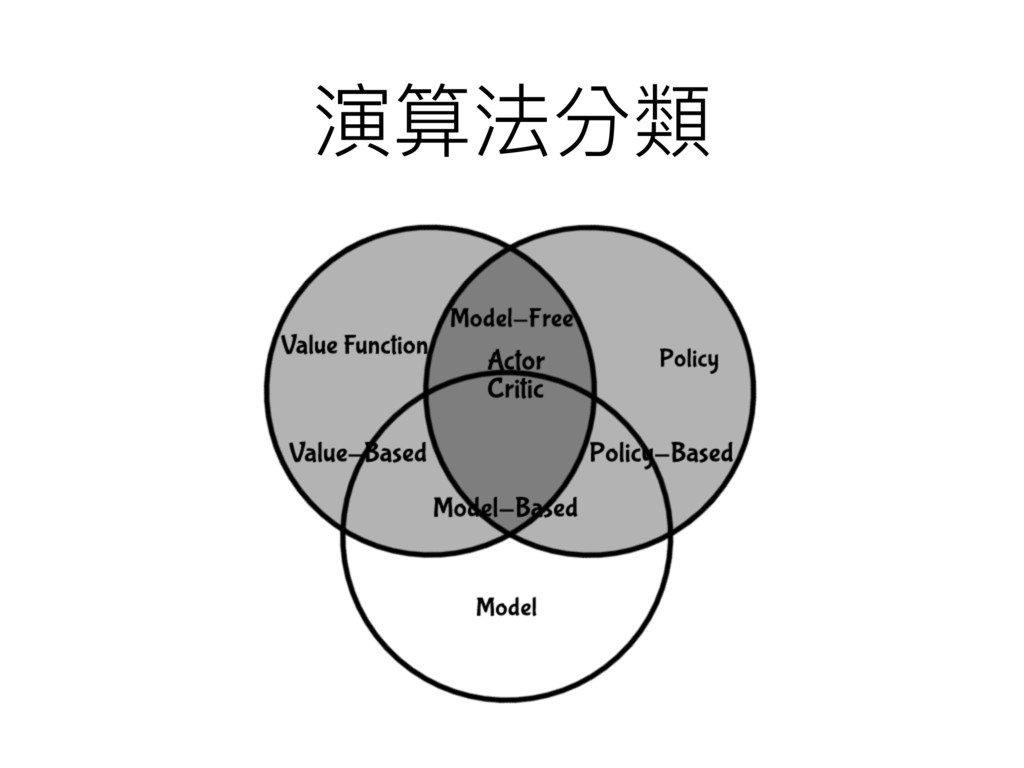
機器⼈人元件 • 模型 (model):這個機器⼈人表達環境的⽅方式 • 價值函數 (value function):評估⼀一個動作或狀狀態好 壞的函數 •
策略略 (policy):決定機器⼈人⾏行行為的函數
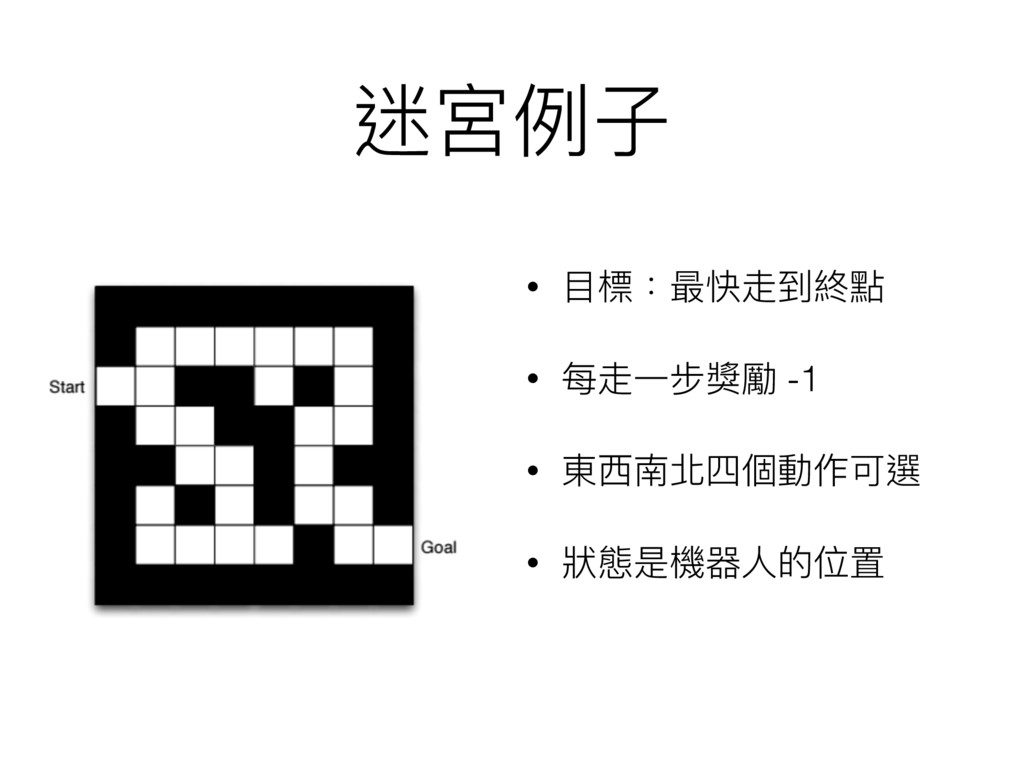
迷宮例例⼦子 • ⽬目標:最快走到終點 • 每走⼀一步獎勵 -1 • 東⻄西南北四個動作可選 • 狀狀態是機器⼈人的位置
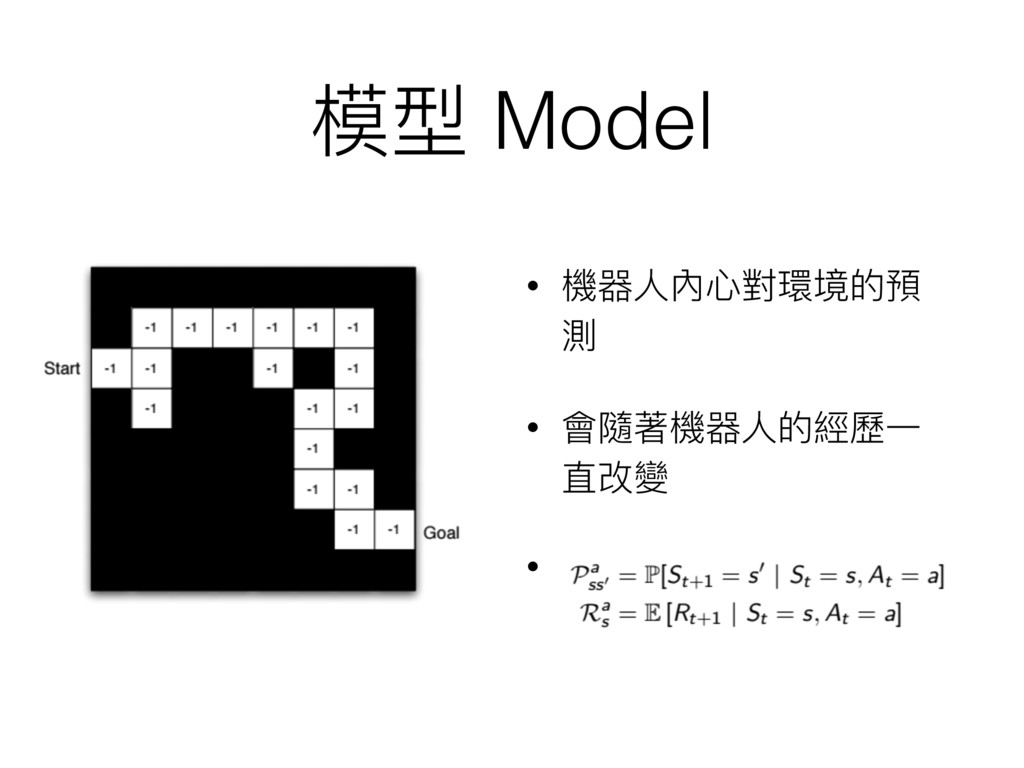
• 機器⼈人內⼼心對環境的預 測 • 會隨著機器⼈人的經歷⼀一 直改變 • 模型 Model
價值函數 Value Function • 是個對以後獎勵的預測 • ⽤用來來評估狀狀態的好壞 • 判斷做什什麼動作的依據
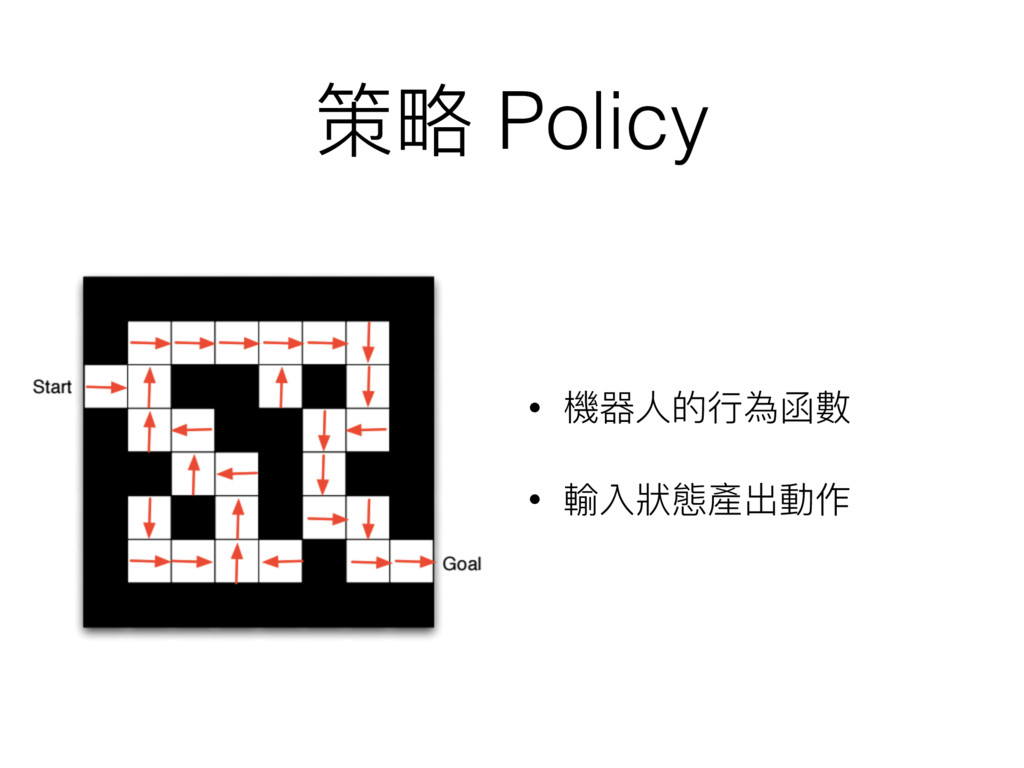
策略略 Policy • 機器⼈人的⾏行行為函數 • 輸入狀狀態產出動作
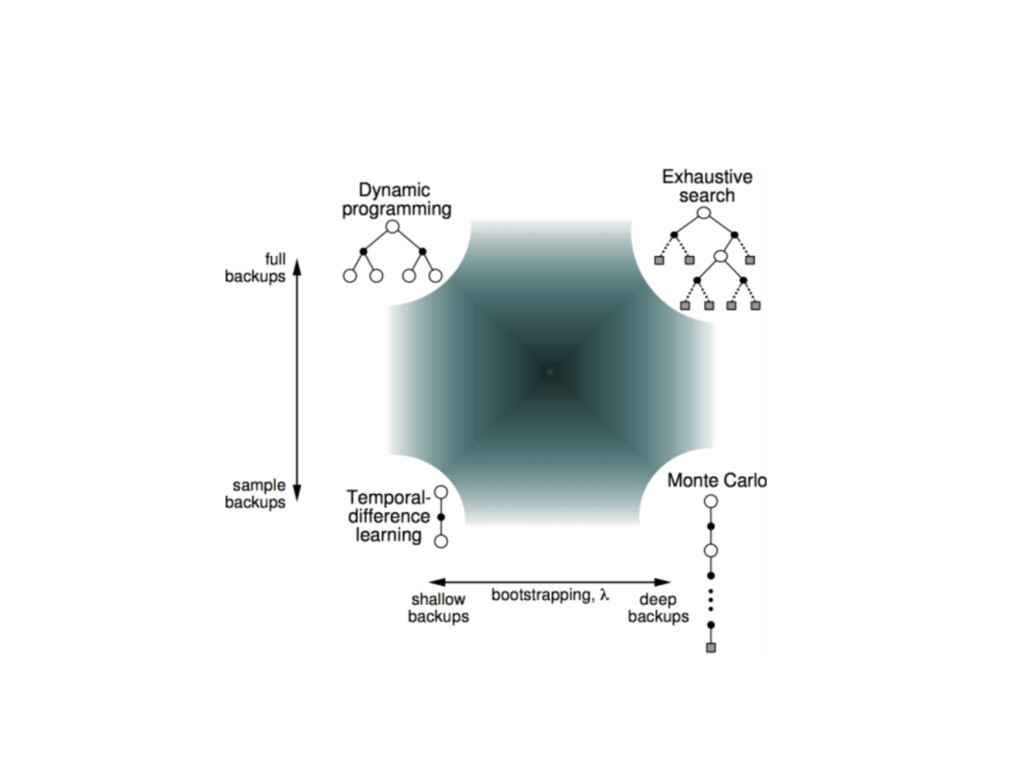
演算法分類
⽤用數學語⾔言怎麼描述這個問題?
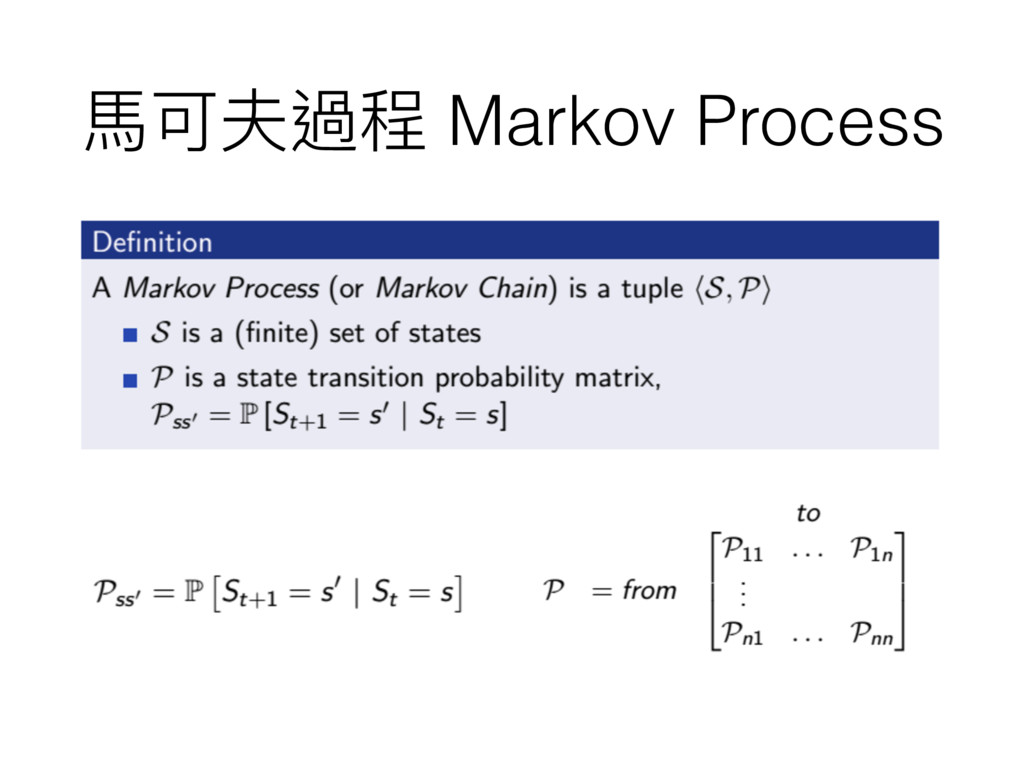
⾺馬可夫鏈 Markov Chain
⾺馬可夫性質 Markov Property ⼀一個狀狀態轉換到下⼀一個狀狀態的機率分佈只跟當前狀狀態有關 未來來跟過去沒關係 只跟現在有關係 因為現在是由過去組成的
⾺馬可夫過程 Markov Process
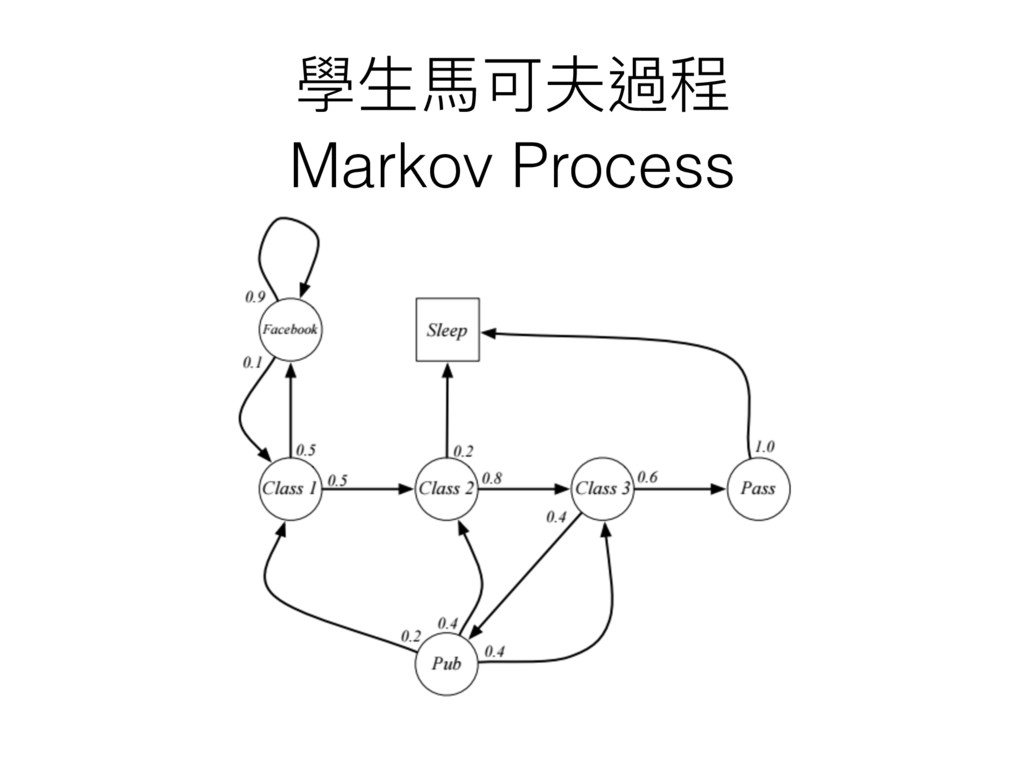
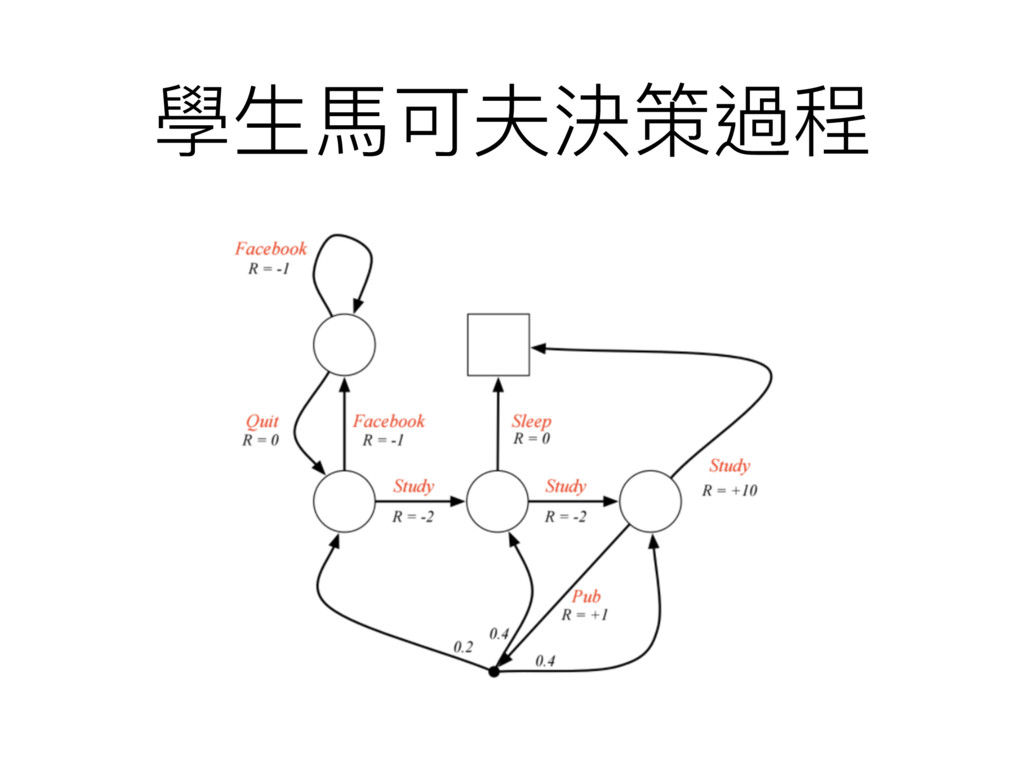
學⽣生⾺馬可夫過程 Markov Process
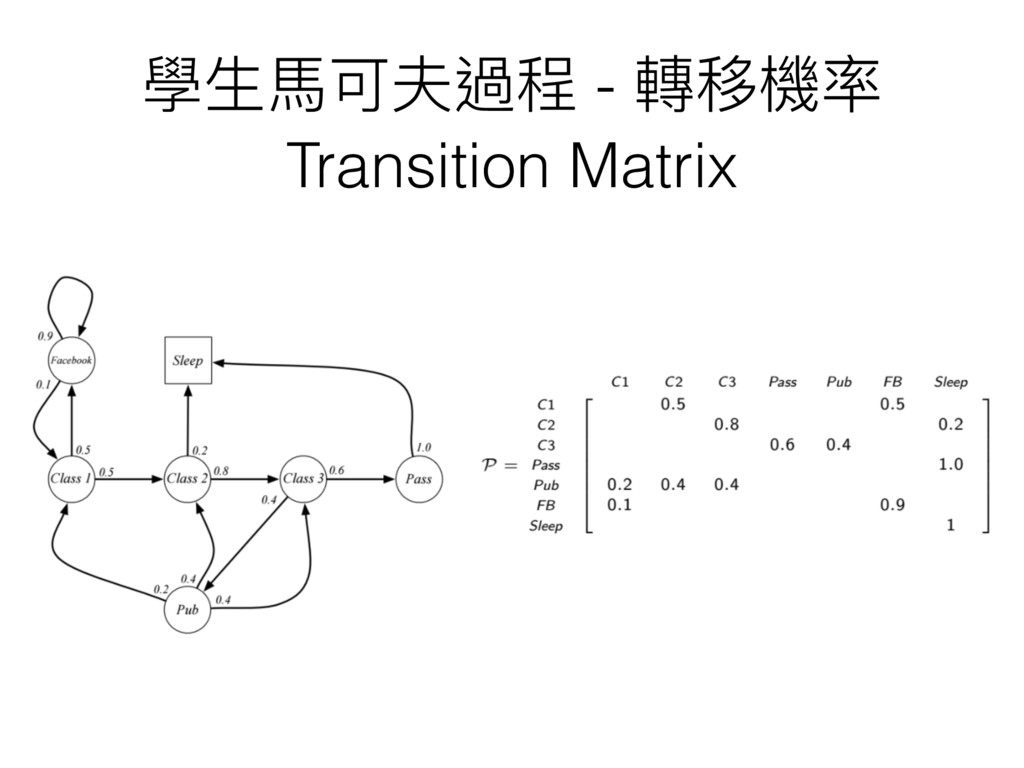
學⽣生⾺馬可夫過程 - 轉移機率 Transition Matrix
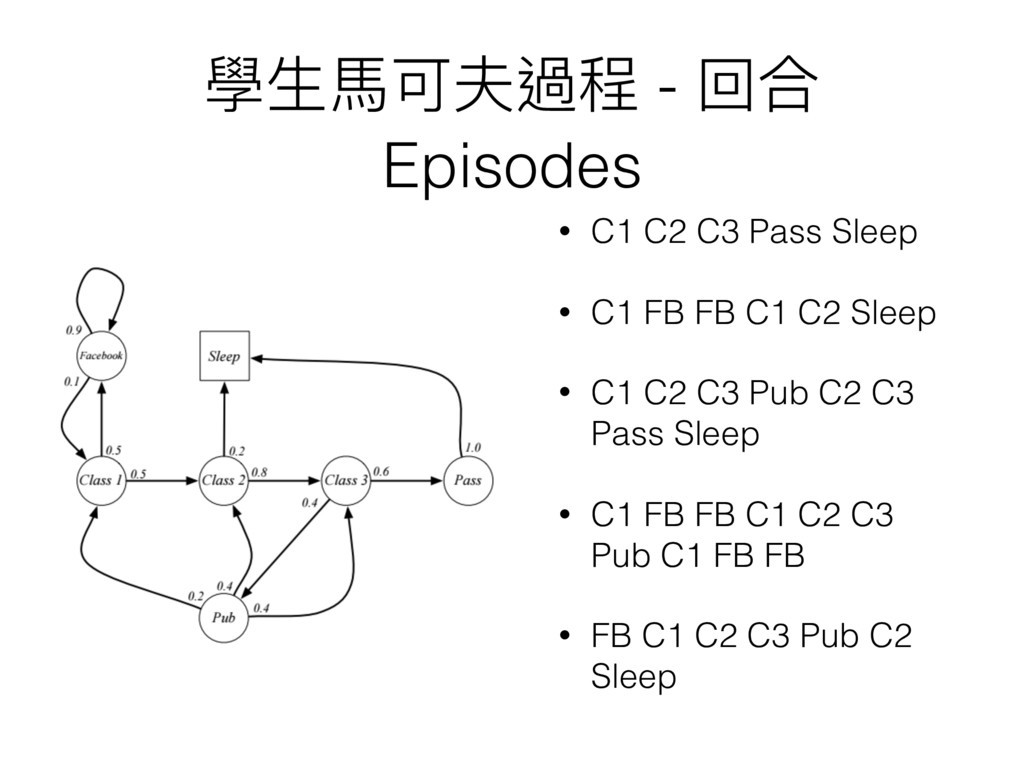
學⽣生⾺馬可夫過程 - 回合 Episodes • C1 C2 C3 Pass Sleep
• C1 FB FB C1 C2 Sleep • C1 C2 C3 Pub C2 C3 Pass Sleep • C1 FB FB C1 C2 C3 Pub C1 FB FB • FB C1 C2 C3 Pub C2 Sleep
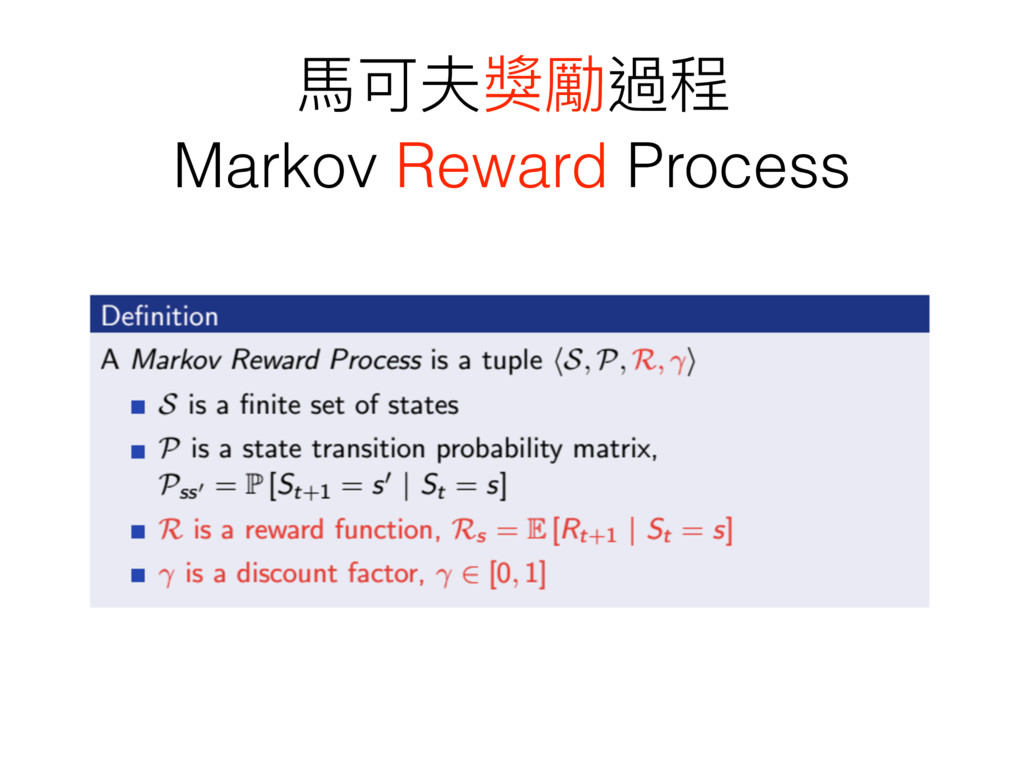
⾺馬可夫獎勵過程 Markov Reward Process
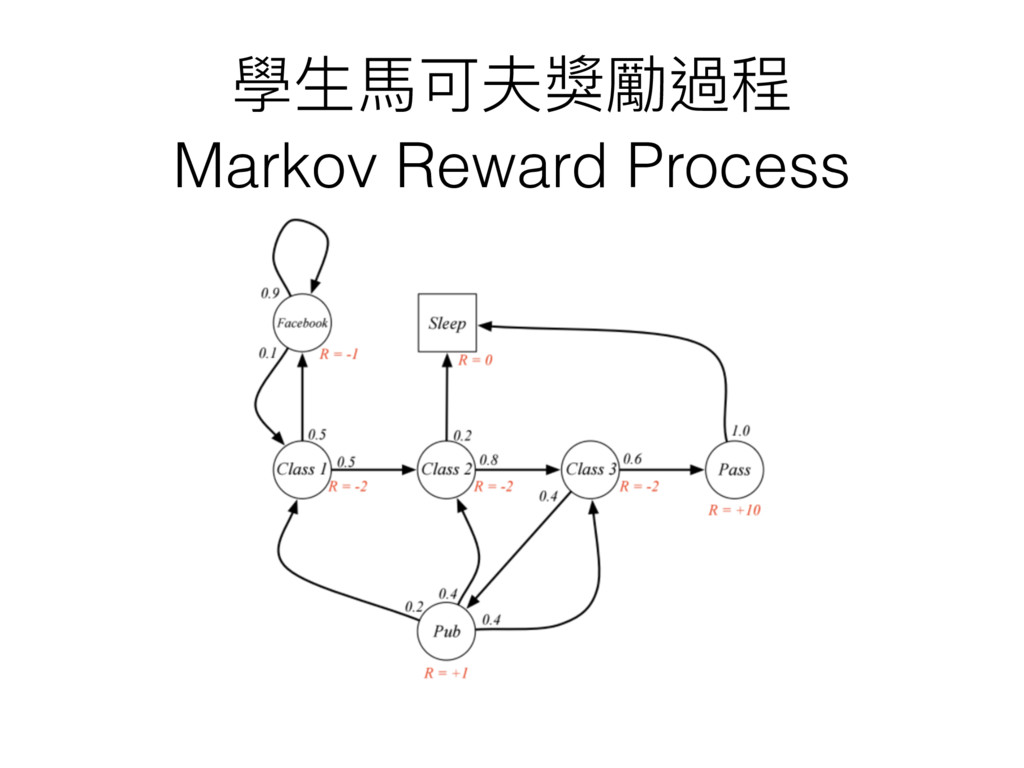
學⽣生⾺馬可夫獎勵過程 Markov Reward Process
運動對你來來說很累 獎勵應該是負的 但你為什什麼還是願意去運動?
當下獎勵不應該直接拿來來當評斷標準
報酬 Return • 報酬由獎勵累加⽽而成 • 越遠的動作或狀狀態可能越不重要 • 衰減因⼦子 (discount factor):gamma
• gamma:0 代表非常短視近利利,只看前⼀一步的獎勵 • gamma:1 代表非常深謀遠慮,把每⼀一步的獎勵都看成相同的價值
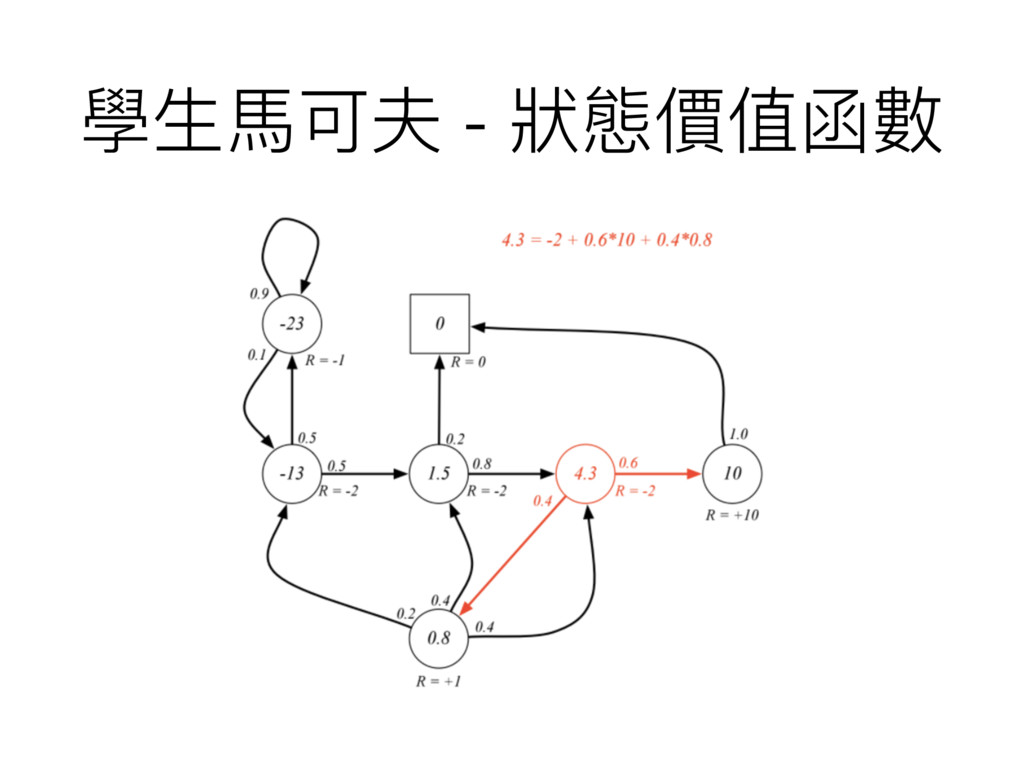
狀狀態價值函數 State Value Function • 如果從那個狀狀態開始走的⾺馬可夫獎勵過程報酬期望值 • ⽤用⼀一個較長遠的眼光看待某個狀狀態的價值
⾙貝爾曼⽅方程式 Bellman Equation 當下的獎勵加上未來來狀狀態的狀狀態價值函數值乘上衰減因 ⼦子的期望值
None
學⽣生⾺馬可夫 - 狀狀態價值函數
該加入動作了了
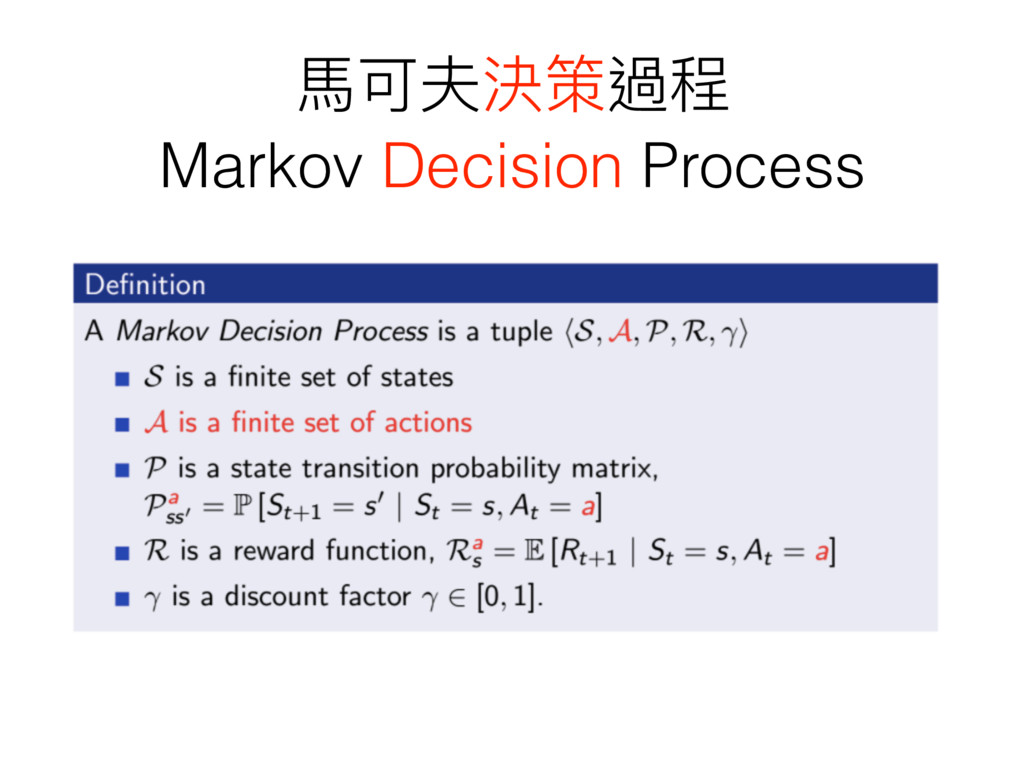
⾺馬可夫決策過程 Markov Decision Process
學⽣生⾺馬可夫決策過程
策略略 Policy 定義機器⼈人在什什麼狀狀態會選什什麼動作
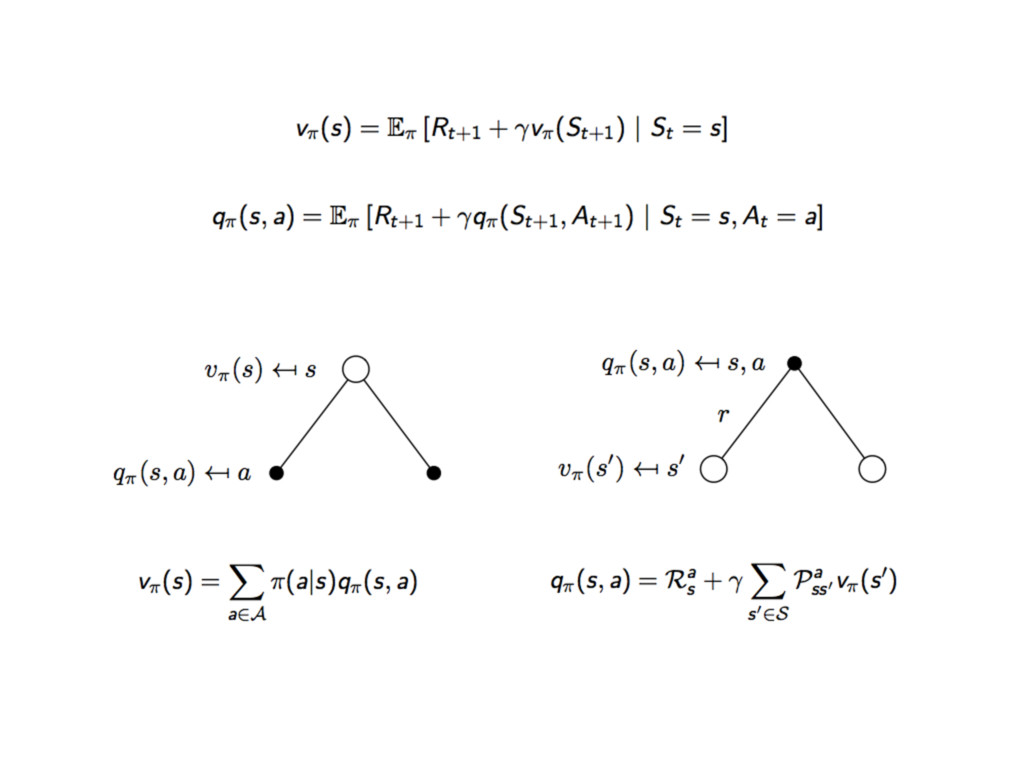
動作價值函數 Action Value Function
動作價值函數 ⾙貝爾曼⽅方程式
None
⾙貝爾曼期望等式 Bellman Expectation Equation
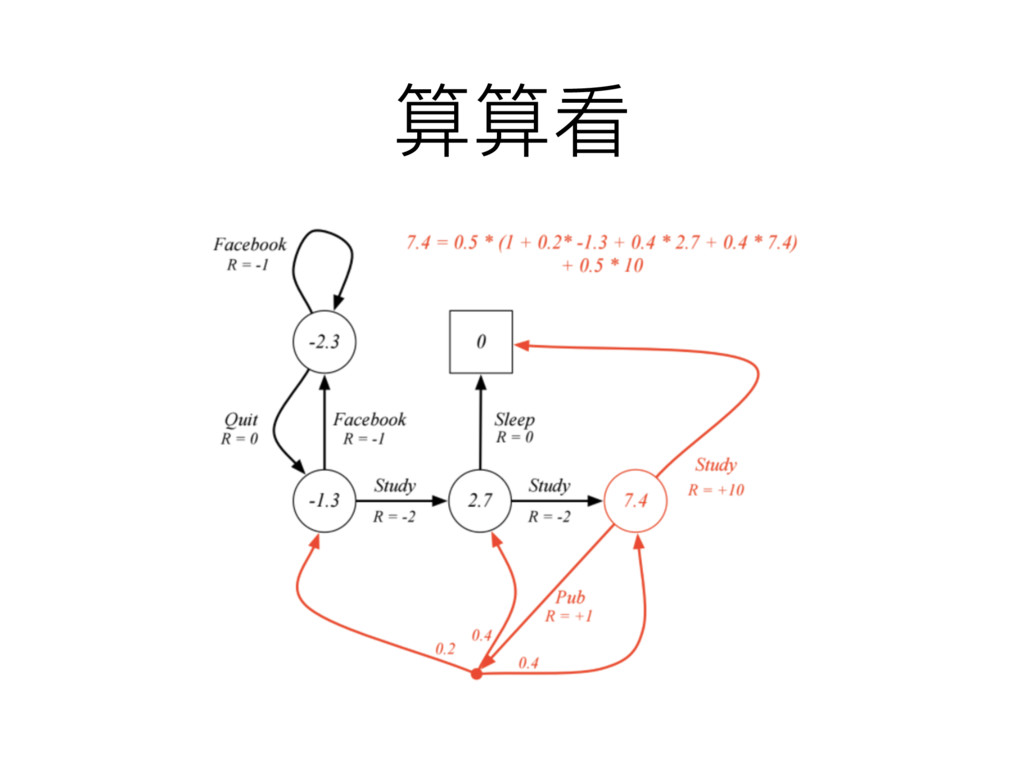
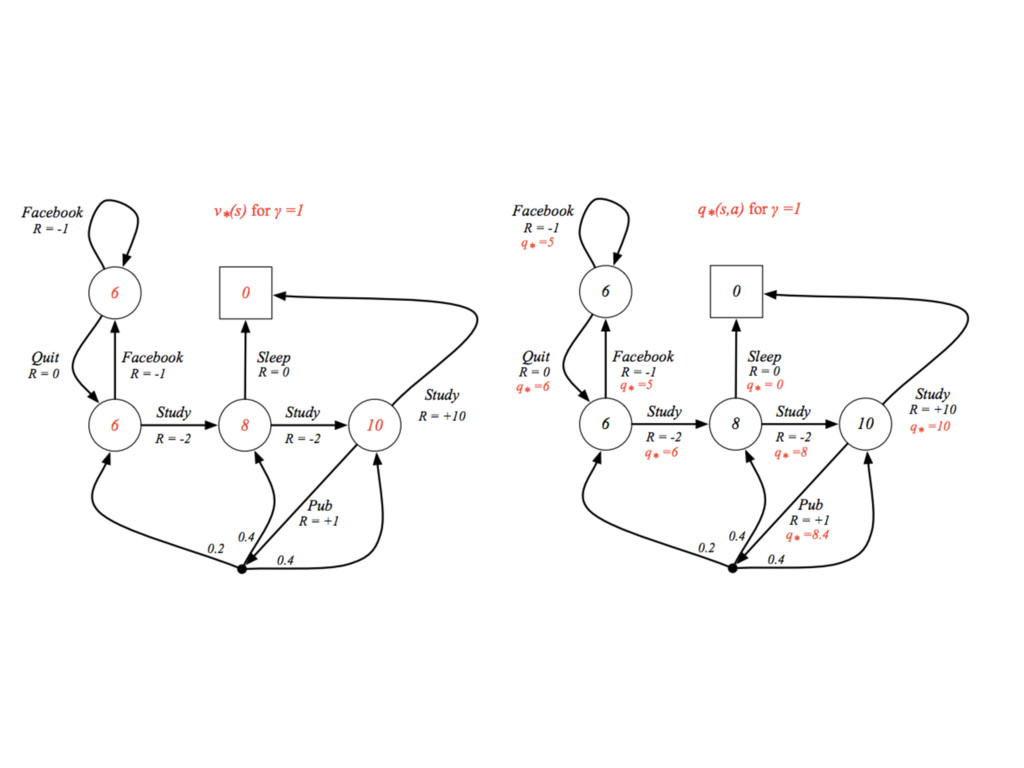
算算看
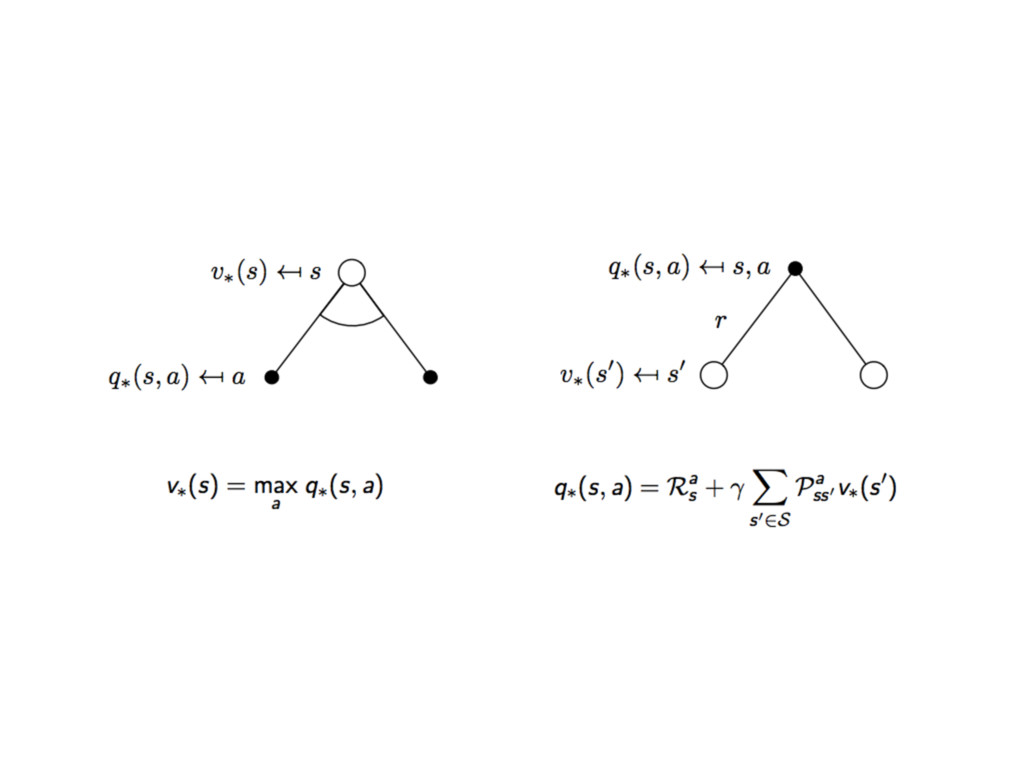
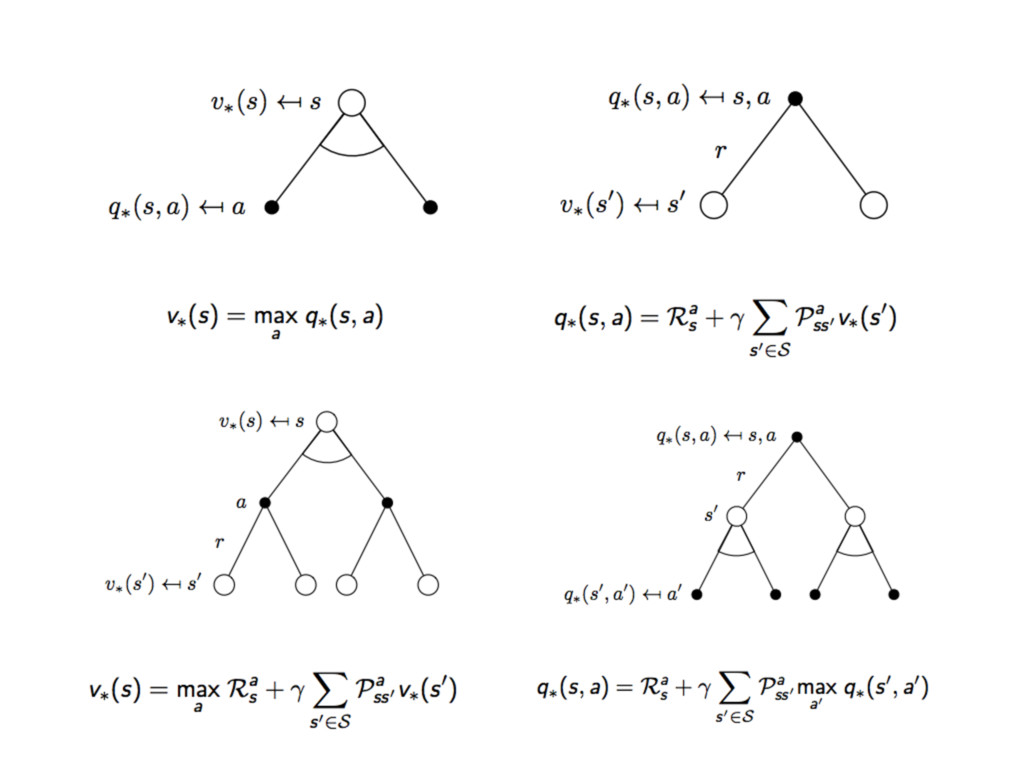
最佳價值函數 Optimal Value Function
None
None
⾙貝爾曼最佳等式 Bellman Optimality Equation
None
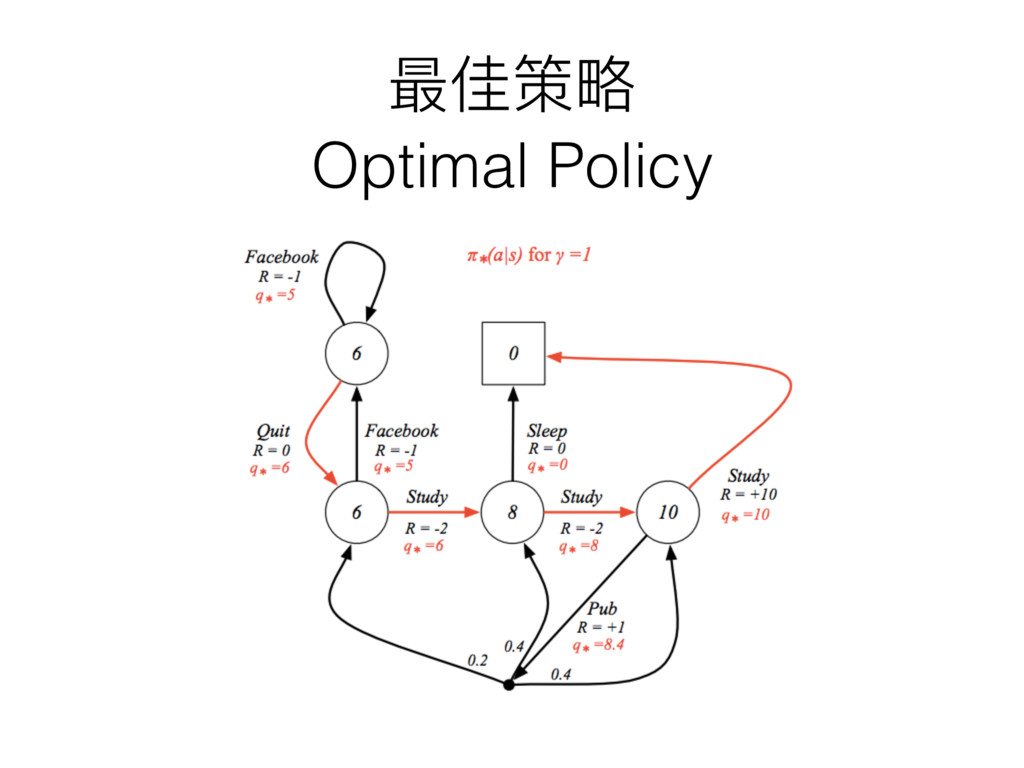
最佳策略略 Optimal Policy
這樣就結束了了?
問題 • ⾙貝爾曼期望等式 Bellman Expectation Equation • 線性⽅方程式 • 但當⾺馬可夫鏈變得龐⼤大時算太久
• ⾙貝爾曼最佳等式 Bellman Optimality Equation • 非線性⽅方程式
怎麼解? • 策略略迭代 (policy iteration) • 價值迭代 (value iteration) •
SARSA • Q Learning
先聚焦在最簡單的 Bellman Optimality Equation Bellman Expectation Equation
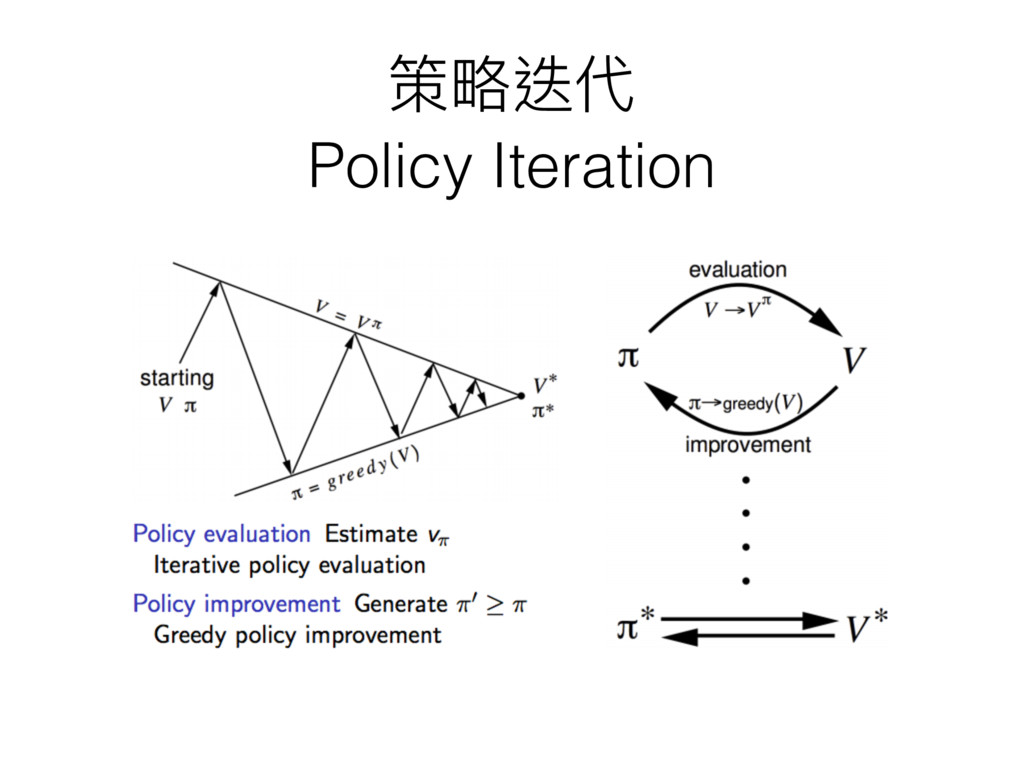
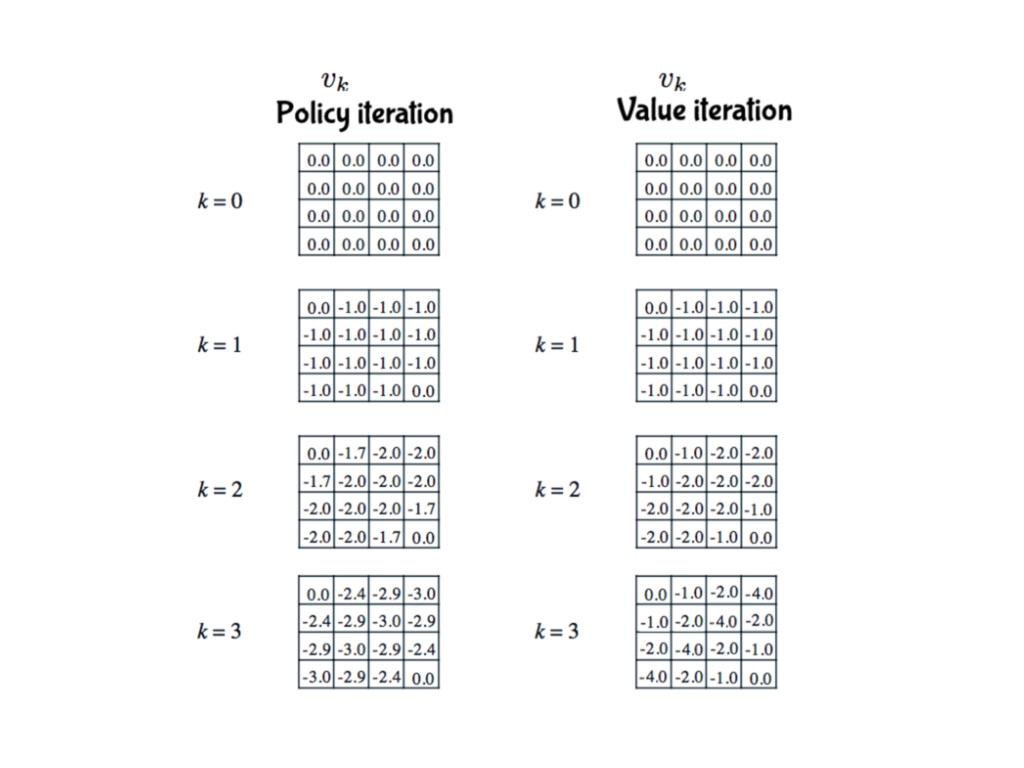
策略略迭代 Policy Iteration
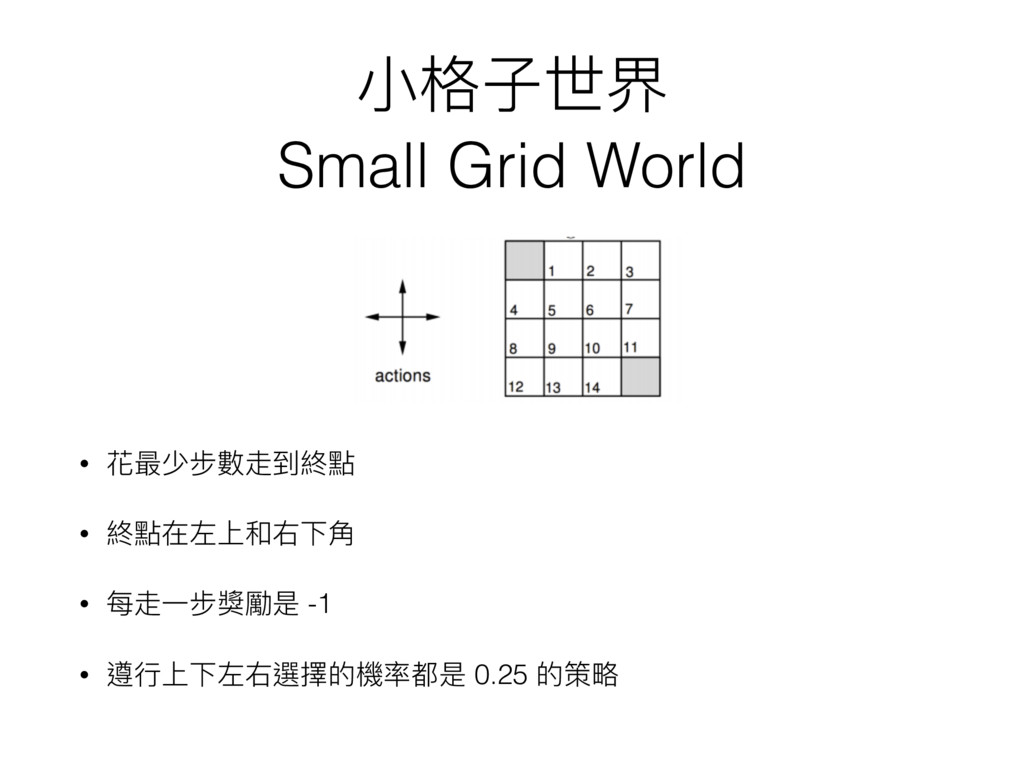
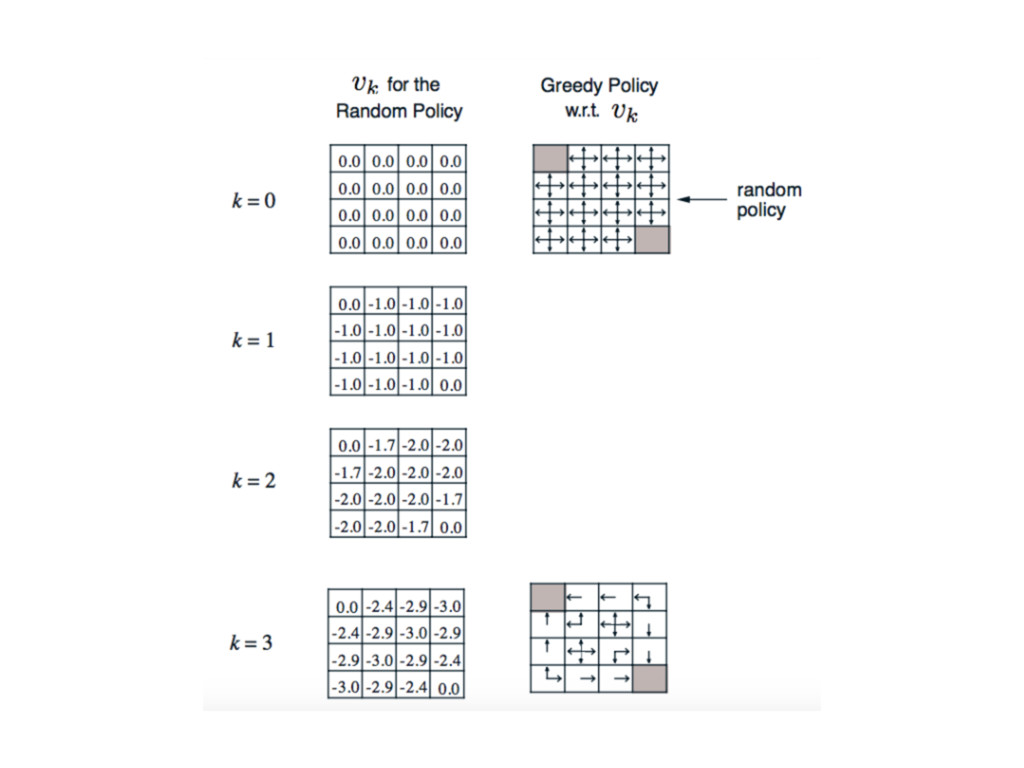
⼩小格⼦子世界 Small Grid World • 花最少步數走到終點 • 終點在左上和右下⾓角 • 每走⼀一步獎勵是
-1 • 遵⾏行行上下左右選擇的機率都是 0.25 的策略略
None
貪婪⽅方法就是選擇當下最好的 那為何不把這個想法 直接放在更更新 v 值時使⽤用呢?
價值迭代 Value Iteration
None
None
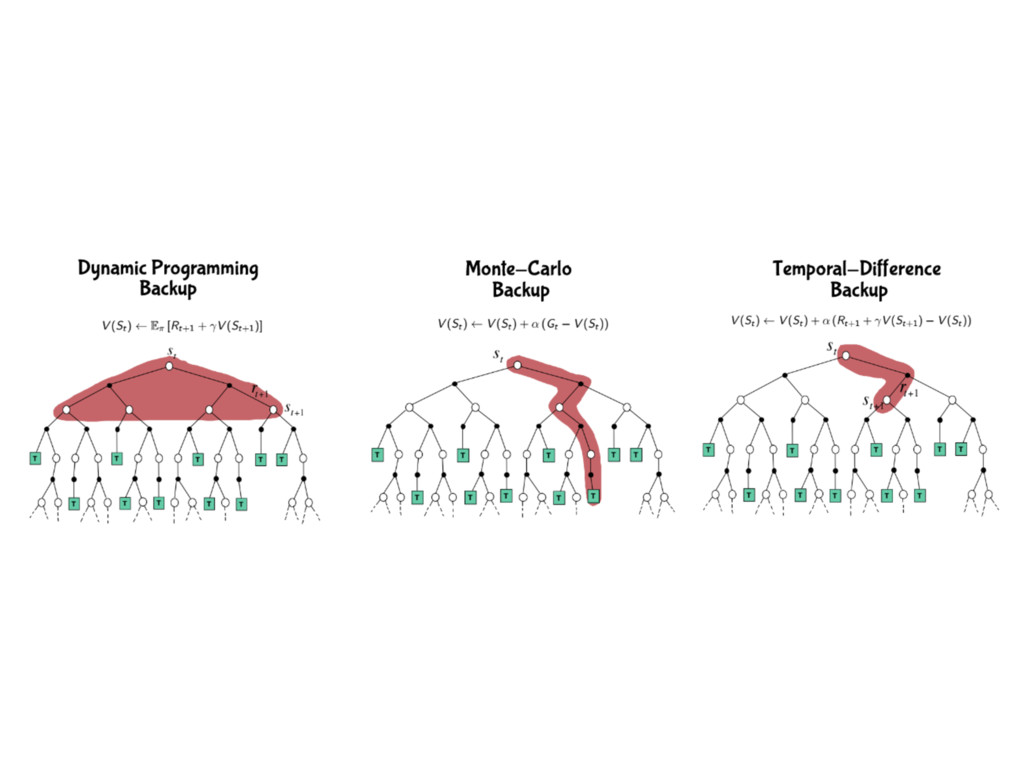
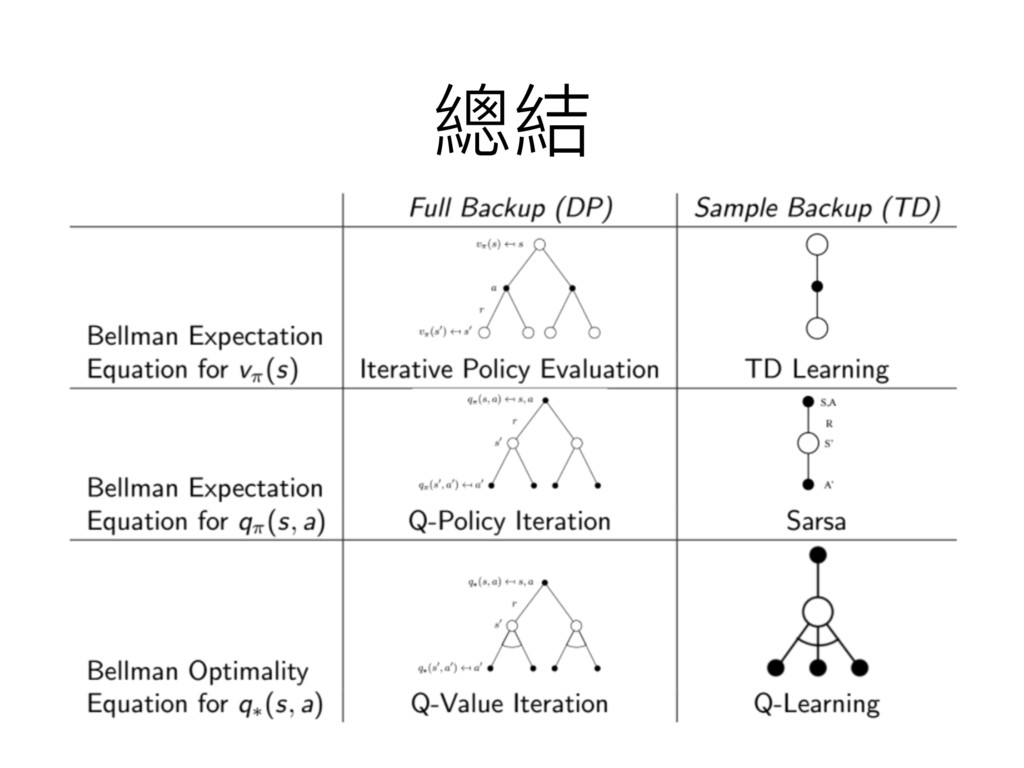
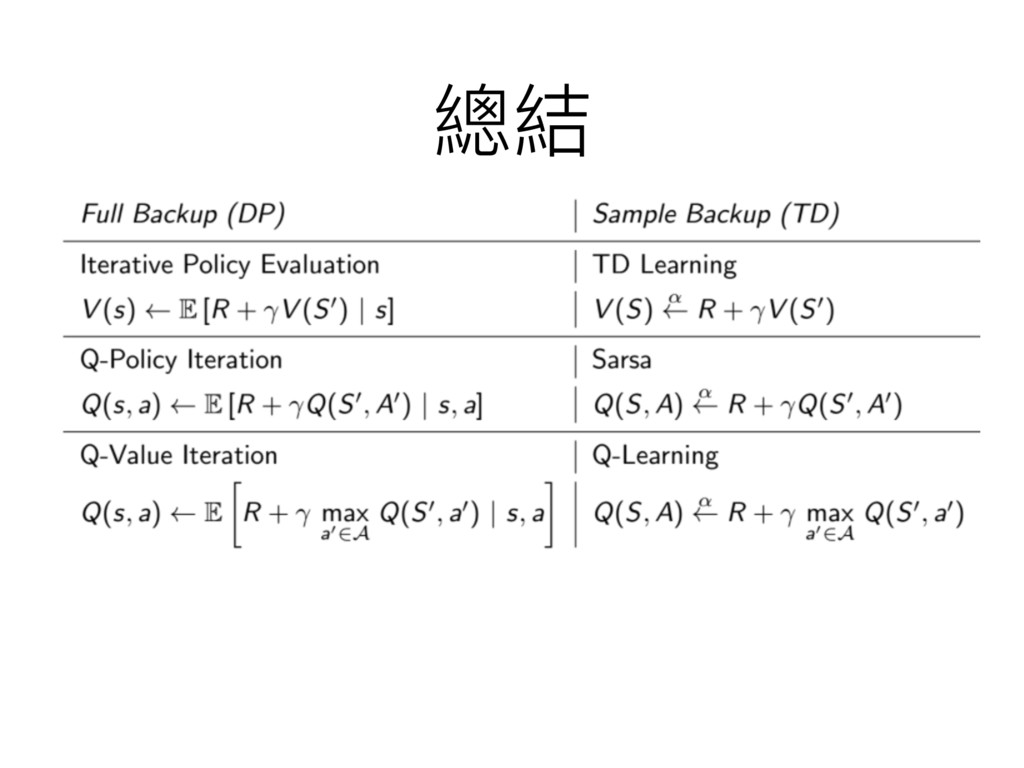
策略略迭代與價值迭代 • 統稱動態規劃 (dynamic programming) 更更新⽅方式 • 也稱為全域的更更新 (full-width backup)
⽅方式 • 需要預先知道⾺馬可夫鏈的所有轉移機率與獎勵 預先
能不能從經驗中學習就好了了?
抽樣的更更新⽅方式 Sample Backup • 相對於全域的更更新⽅方式 (full-width backup) • 走過的路路更更新就好,沒走過就算了了吧 •
從經驗中學習 • 如何更更新?
不能⽤用期望值了了 因為我們不知道發⽣生不同狀狀態的機率 那就⽤用平均值吧
蒙地卡羅學習⽅方式 Monte-Carlo Learning • 走完所有回合更更新 • 最終狀狀態價值為平均每回合得到的狀狀態價值
累計的蒙地卡羅 Incrementally Monte-Carlo
再改寫⼀一下 • ⽤用 alpha 來來調整對新經驗的看重 • alpha:0 代表不要參參考這次回合的結果 • alpha:1
代表非常看重這次回合的結果
每個回合結束後才能更更新 這樣有點慢 ⽽而且如果這個遊戲是沒有回合的 像是⼈人⽣生只能過⼀一次 怎麼辦?
時間分差學習法 Temporal-Difference Learning
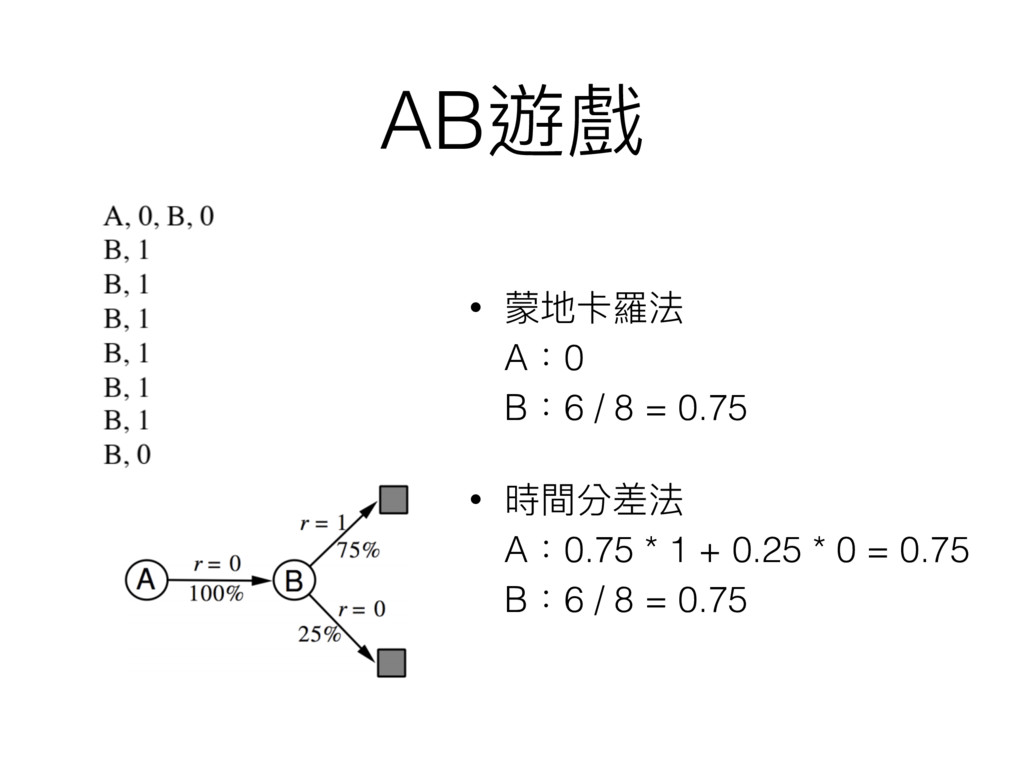
AB遊戲
AB遊戲 • 蒙地卡羅法 A:0 B:6 / 8 = 0.75 •
時間分差法 A:0.75 * 1 + 0.25 * 0 = 0.75 B:6 / 8 = 0.75
None
None
終於可以把動作加進來來了了
狀狀態 to 動作
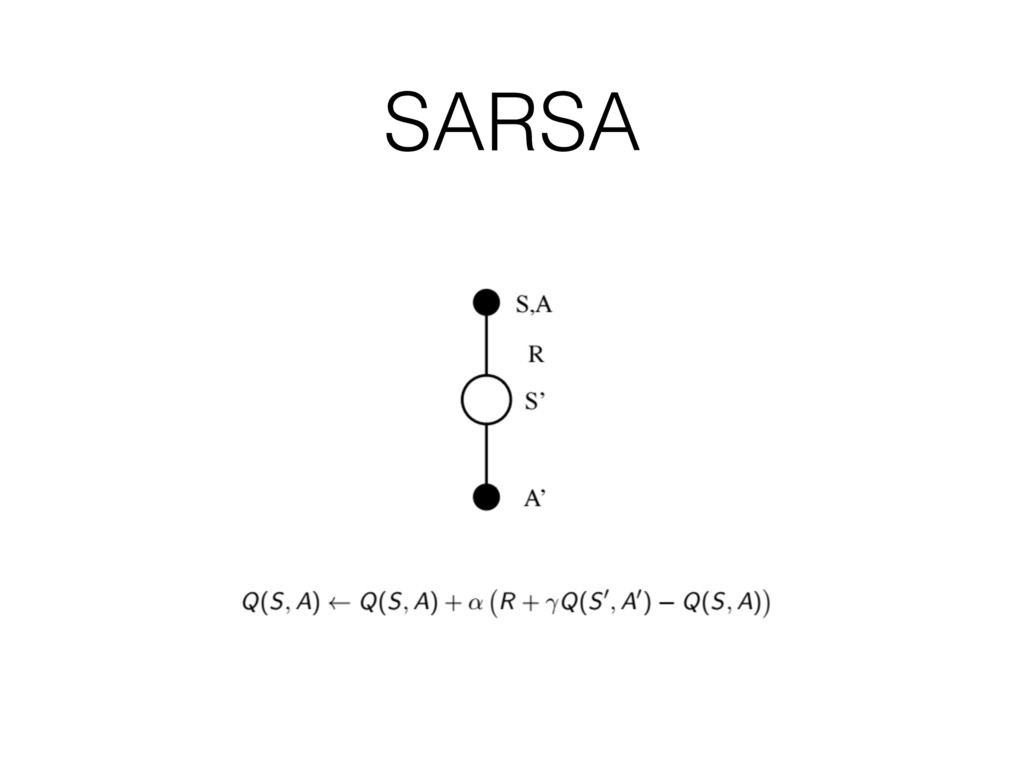
SARSA
SARSA Algorithm
跟策略略迭代到價值迭代的思維⼀一樣 何不把貪婪的概念念放到更更新價值中?
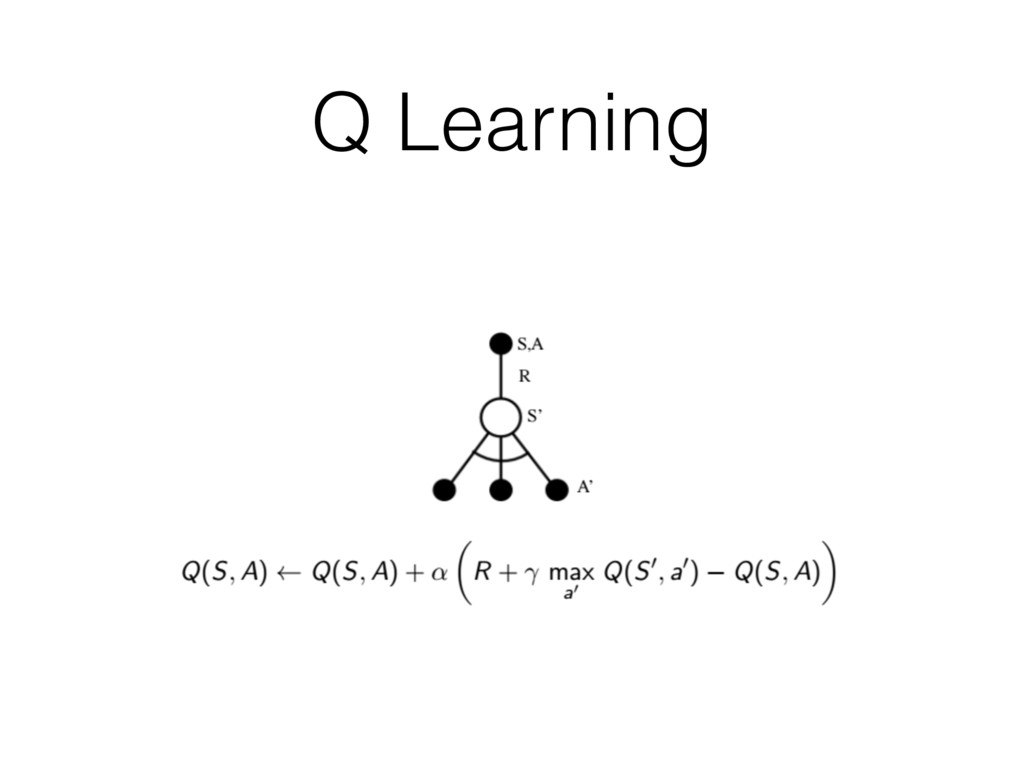
SARSA to Q Learning
Q Learning
Q Learning
總結
總結
謝謝收看
Reference • David Silver RL 課程
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
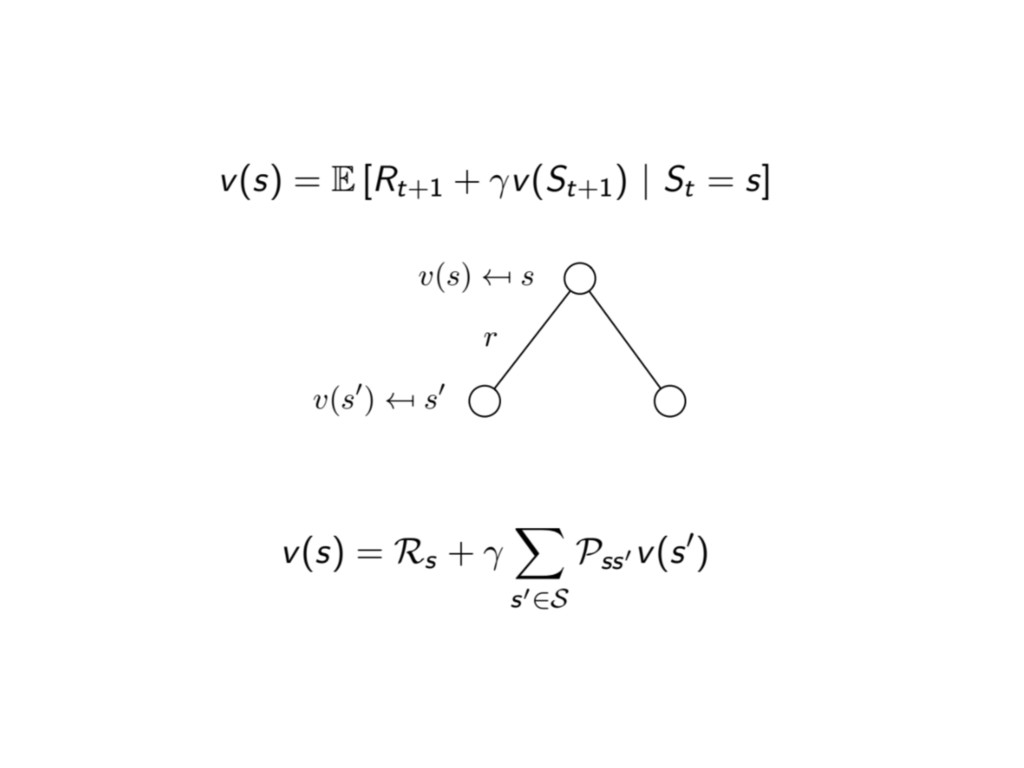{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}