Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
いち機械学習エンジニアが考える、 広告効果予測プロダクトへの 価値提供と貢献の仕方 / Pro...
Search
CyberAgent
PRO
October 05, 2023
Technology
400
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
いち機械学習エンジニアが考える、 広告効果予測プロダクトへの 価値提供と貢献の仕方 / Providing value to products that predict advertising effectiveness, as considered by ML engineers
CyberAgent
PRO
October 05, 2023
More Decks by CyberAgent
See All by CyberAgent
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
Databricks 導入から Genie 活用まで、全部やった話
cyberagentdevelopers
PRO
0
830
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める「データの民主化」-
cyberagentdevelopers
PRO
0
500
「エンジニア進化論」2028年の開発完全自動化、エンジニアはどう進化するか
cyberagentdevelopers
PRO
9
8.9k
NAB Show 2026 動画技術関連レポート / NAB Show 2026 Report
cyberagentdevelopers
PRO
0
310
Local LLM Meetup #1 Opening
cyberagentdevelopers
PRO
0
430
LocalLLMで機密データを匿名化したい
cyberagentdevelopers
PRO
1
460
Vibe Fine-Tuning Version 2 — RunPod SSH で安く学習してみた
cyberagentdevelopers
PRO
0
430
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
cyberagentdevelopers
PRO
10
12k
Other Decks in Technology
See All in Technology
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
12
3.9k
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
260
kaonavi Tech Night#1
kaonavi
0
150
「休む」重要さ
smt7174
6
1.6k
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
0
120
Kaggleで成長するために意識したこと
prgckwb
2
440
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
200
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
950
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
210
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1.1k
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
From π to Pie charts
rasagy
0
240
Leo the Paperboy
mayatellez
8
1.9k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
For a Future-Friendly Web
brad_frost
183
10k
What's in a price? How to price your products and services
michaelherold
247
13k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Typedesign – Prime Four
hannesfritz
42
3.1k
Six Lessons from altMBA
skipperchong
29
4.3k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Transcript
いち機械学習エンジニアが考える、 広告効果予測プロダクトへの 価値提供と貢献の仕方 AI事業本部 AIクリエィティブdiv 極TD事業部 西村 政輝 CA DATA
NIGHT #1
自己紹介 • 2017/12〜 アドテク本部 CA DyVE • 2019/09〜 AI事業本部 極TD
基本属性はフルスタックエンジニア サイバーエージェント入社後、Data & MLに も領域を広げる 西村 政輝
今日話すこと&話す人の属性 話す人の属性: • 仕事始めて約15年間:Webエンジニア・サーバーサイドエンジニア • 直近4年間:MLエンジニアに転向 話せること: • MLE以前の経験を活かすことで転向後にどのような成果に繋がったか =>
過去から現在までの担当システムの技術要件やシステム構成に関する話 (ビジネス貢献の話や所属プロダクトのMLモデルに関する話は薄いです)
目次 • 簡単な前提知識の共有(プロダクト紹介とMLOps) • MLプロダクト開発においてサーバーサイド経験が活きた例 • 最後に
目次 • 簡単な前提知識の共有 ◦ 所属プロダクト(極TD)について ◦ MLプロダクト開発・運用(MLOps) • MLプロダクト開発においてサーバーサイド経験が活きた例 •
最後に
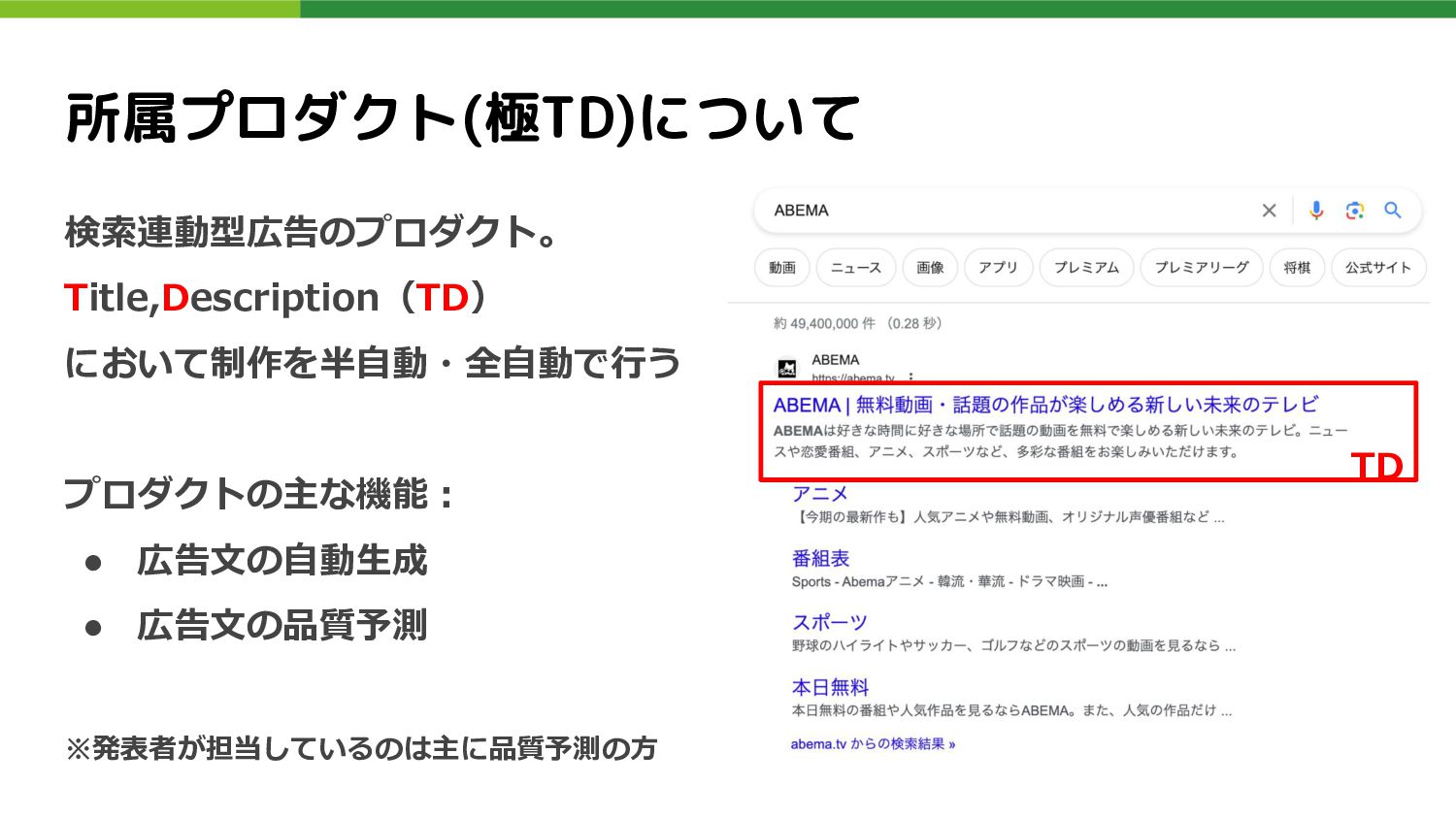
所属プロダクト(極TD)について 検索連動型広告のプロダクト。 Title,Description(TD) において制作を半自動・全自動で行う プロダクトの主な機能: • 広告文の自動生成 • 広告文の品質予測 ※発表者が担当しているのは主に品質予測の方
TD
None
MLプロダクト開発・運用(MLOps) DevOpsはプロダクトの開発と運用を密接に連携しスピード感を高める取り組み MLOpsは上記に加え、データ、MLモデルの領域に拡張したもの 出典:Neal Analytics
MLプロダクト開発・運用(MLOps) 一般的なプロダクト開発と比べMLプロダクト特有の概念やタスクが増える ただし、プロダクトの開発・運用という文脈では大枠は同じ ML未経験からでも、MLを学びながら開発・運用の方面で貢献可能 企画・設計 • 要件定義 • DWHの整備 •
PoC 開発 • モデルの訓練 • 実験管理 • モデルのサービング 運用・保守 • 監視 • 効果検証 • プロダクト改善
目次 • 簡単な前提知識の共有(プロダクト紹介とMLOps) • MLプロダクト開発においてサーバーサイド経験が活きた例 ◦ 極TD立ち上げ初期のDataOps整備 ◦ 予測モデルの効果検証のためのABnテスト基盤 ◦
Dataflowによるアセット組み合わせ大規模バッチ推論 ◦ LLM API活用 TDオンデマンド生成サーバー開発 • 最後に
極TD立ち上げ初期の DataOps整備
AI事業本部発足から 極短期間で極TDリリース スピード感のあるリリースには 必ずと言ってよいほどよくある話 今を生きるために先送りにした 技術的負債
極TD立ち上げ初期のDataOps整備 As-Is(当時): • 学習データは広告メディアの管理画面から手動CSV出力後Google Drive保存 ◦ 再学習の都度手間もかかるし、スピード感もない、人的ミスの可能性も ◦ 仮組みした学習パイプラインはあれど、MLOpsを自動化できない To-Be:
• DWH(データウェアハウス)が存在する状態 ◦ 常にデータが必要な時にプログラム等からクエリで利用できる ◦ データが最新の状態に保たれている ◦ ETL,ELTの出力先としても使え、MLの前処理済データ等も統一的に管理
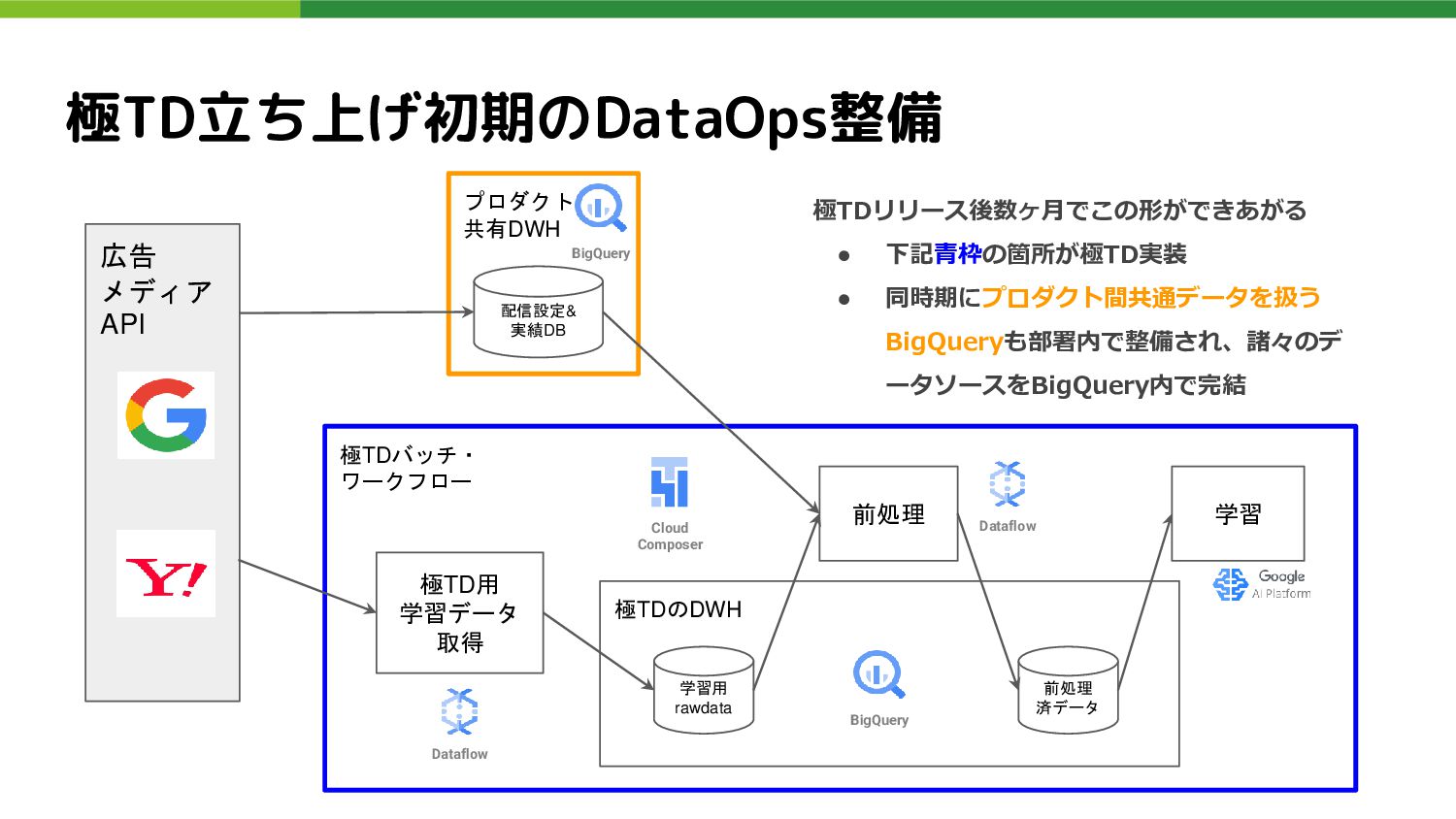
極TDバッチ・ ワークフロー 極TDのDWH 極TD立ち上げ初期のDataOps整備 プロダクト 共有DWH 広告 メディア API BigQuery
配信設定& 実績DB 学習用 rawdata 前処理 済データ 前処理 BigQuery 極TD用 学習データ 取得 Dataflow Dataflow Cloud Composer 極TDリリース後数ヶ月でこの形ができあがる • 下記青枠の箇所が極TD実装 • 同時期にプロダクト間共通データを扱う BigQueryも部署内で整備され、諸々のデ ータソースをBigQuery内で完結 学習
極TD立ち上げ初期のDataOps整備 得られた成果: • BigQueryを軸としCloud Dataflow, Cloud ComposerといったGCPスタ ックに乗る形で、設計思想が統一されたDataOps環境が構築できた • 上記によるシステム面の運用自動化が速やかに達成できた
• 実験・データ分析の際に欲しいデータが常に速やかに手に入る形になった SWE経験が活かされたところ: • 直前に所属していた広告配信プロダクトで既にBigQuery, Cloud Dataflowの実務経験があり、ここで得たDataOpsのノウハウを活用できた
予測モデルの 効果検証のための ABnテスト基盤
予測モデルの効果検証のためのABnテスト基盤 要求/要件: • 予測モデル単体の正しい貢献度を測定できること ◦ PoC、実験コード上のオフライン評価で優秀なモデルができたとしても それがオンライン上で正しく寄与できているというエビデンスが必要 配 信 実
績 時系列 導入前 導入後 外部要因(何もしなくても上がってた) 予測モデルが寄与した分 ← これを明るみに 極予測TDを用いた制作プロセス自身が寄与した分
予測モデルの効果検証のためのABnテスト基盤 制約事項: • 入稿=>配信=>実績取得のタイムラグがどうしてもある ◦ リアルタイムに結果を得られるプロダクトならABn結果をもとに 早いスパンで予測アルゴリズムを切り替えていくが、今回はできない ▪ モデル性能についてオンライン評価によるエビデンスをとる ▪
ゆっくりながらも優れたモデルを残していくPDCAサイクルを回していく
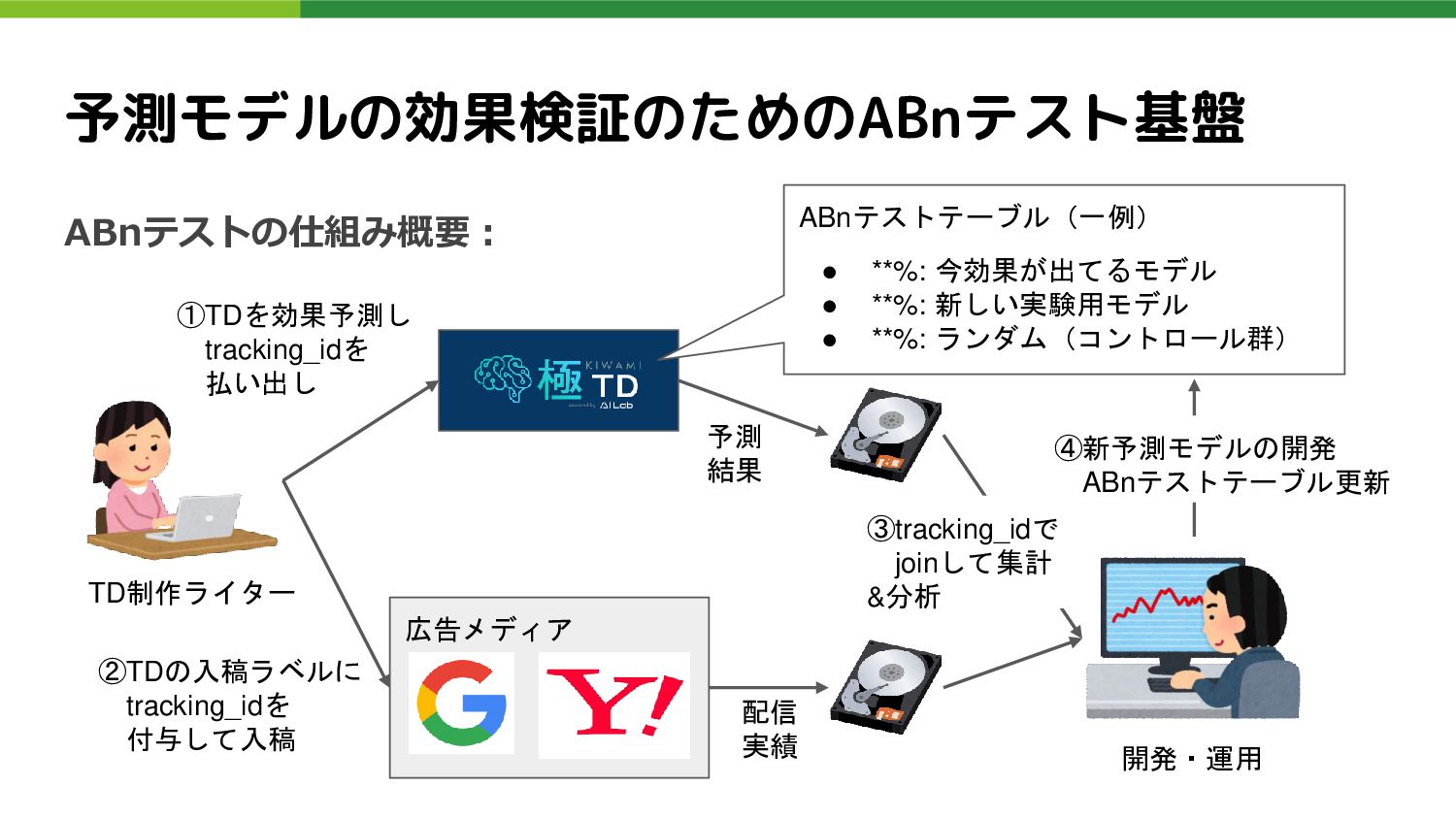
広告メディア ABnテストテーブル(一例) • **%: 今効果が出てるモデル • **%: 新しい実験用モデル • **%:
ランダム(コントロール群) ①TDを効果予測し tracking_idを 払い出し ②TDの入稿ラベルに tracking_idを 付与して入稿 予測 結果 配信 実績 TD制作ライター 開発・運用 ④新予測モデルの開発 ABnテストテーブル更新 ③tracking_idで joinして集計 &分析 予測モデルの効果検証のためのABnテスト基盤 ABnテストの仕組み概要:
予測モデルの効果検証のためのABnテスト基盤 実験設定が異なる予測モデルがデプロイされた効果予測エンドポイント群に対し ABnテスト設定ファイルに従い予測モデルを振り分けるプロキシを開発 極予測TD 制作画面 estimator- proxy estimator-v1 estimator-v2 estimator-v3
{ campaign_id: “...”, adgroup_id: “…”, title: “...”, description: “...” } { endpoint: “...”, model_name:“...”, pred_score: “...”, } proxy- config .yaml request response
予測モデルの効果検証のためのABnテスト基盤 実験設定が異なる予測モデルがデプロイされた効果予測エンドポイント群に対し ABnテスト設定ファイルに従い予測モデルを振り分けるプロキシを開発
予測モデルの効果検証のためのABnテスト基盤 得られた成果: • オンラインで得られたデータをもとにT検定が実施できるようになった • ランダム化比較試験ができるようになった ◦ 配信実績で強いリフトが得られる予測モデルが発見できた • ダッシュボードでモデル間の性能差を確認できるようになった
• 複数モデル間の性能差を明るみにし、有効なモデルのみ残すPDCAサイクル を回すことができるようになった
予測モデルの効果検証のためのABnテスト基盤 SWE経験が活かされたところ: • TDの入稿ラベルにトラッキングIDを与え配信実績を追跡する設計上の着想 は、SWEとして分散トレーシングが馴染み深かったことから得られた • 今回の要件にあったプロキシサーバの実装難易度は高めだが実装力でカバー ◦ ABnテストのyaml定義ファイルをプログラムに落とし込む ▪
Interpriter, Decorator, Chain Of Responsibility @ GoFデザパタ ◦ 非同期プログラミング、ノンブロッキングIOの意味と特性を理解した上 での分散・並行リクエスト (Pytyonならコルーチン・Async/Await) ◦ 諸々の複雑寄りの実装を支えるためのコンストラクタDIとテスト実装
Dataflowによる アセット組み合わせ 大規模バッチ推論
None
None
広告の有効性:広告メディア側で定 義されている、配信効果の指標 (低い〜非常に高いの4値)
Dataflowによるアセット組み合わせ大規模バッチ推論 技術要件: • 1実行あたり、数億の自動生成アセットの組み合わせパターンに対して推論 ◦ 各adに対し広告アセットの最適な組み合わせを探索するバッチ ▪ 広告数 x 組み合わせ各nパターンずつ推論を試行
• 1実行あたりの推論コストは決して低くない ◦ モデル側の推論はともかく、NLP絡みの前処理が少し重い • 予測対象増加やモデルアップデートに備え、処理能力をスケール可能
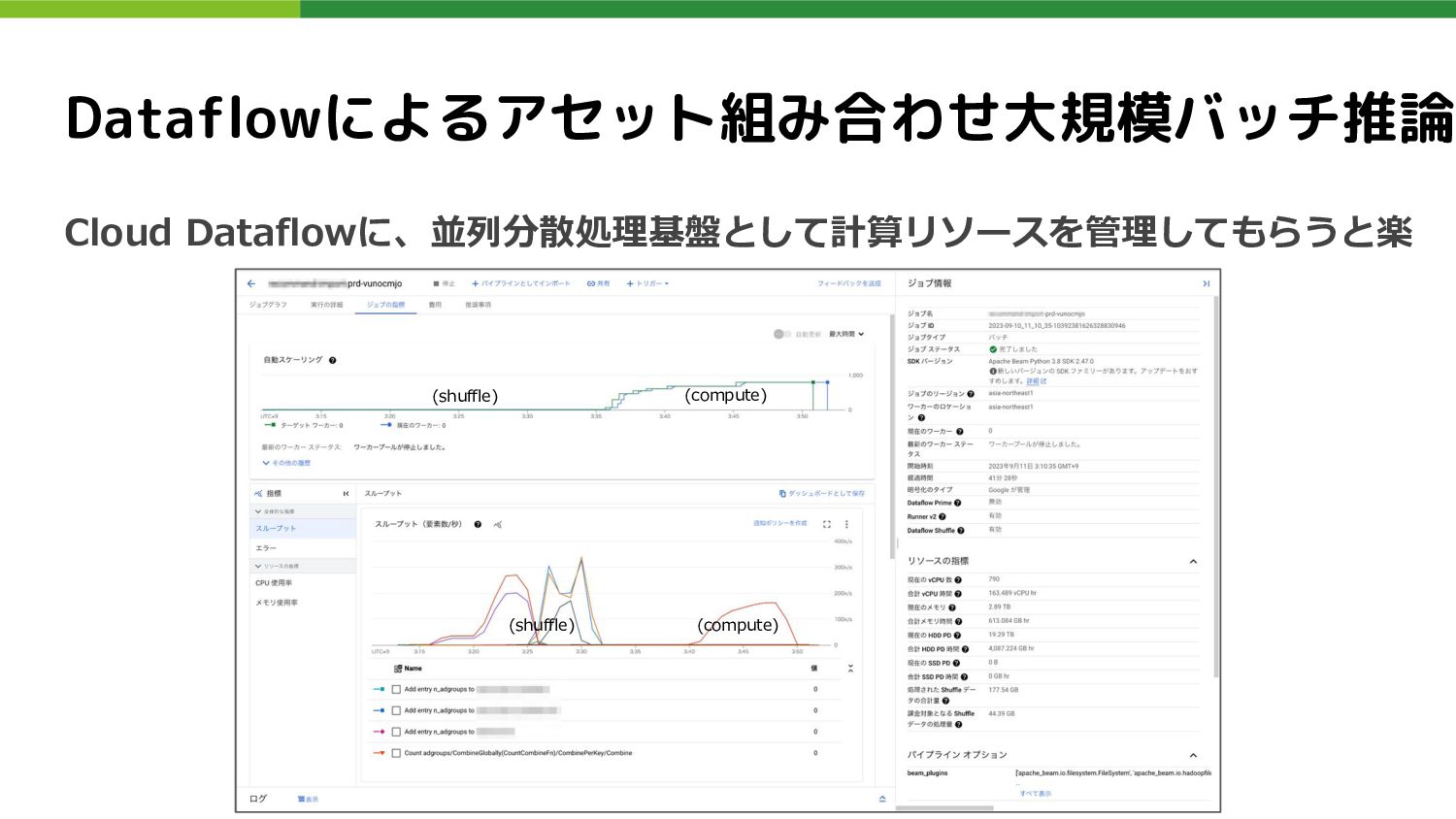
Dataflowによるアセット組み合わせ大規模バッチ推論 Cloud Dataflowに、並列分散処理基盤として計算リソースを管理してもらうと楽 (shuffle) (shuffle) (compute) (compute)
Dataflowによるアセット組み合わせ大規模バッチ推論 得られた成果: • 数億件単位の前処理と推論を1時間以内で完了させる ◦ PCollection操作でデータを適切な粒度にシャーディング ◦ 各シャードに対し最大1,000ワーカーで並列分散処理を行い推論 SWE経験が活かされたところ: •
分散処理自体はここに至るまでたまに携わっていたことが活きた • Cloud Dataflow(Apache Beam)使用歴は前プロダクトから5年程あり、 このような用途に適性がある事を予め知っていた
LLM API活用 TDオンデマンド生成 サーバー開発
None
None
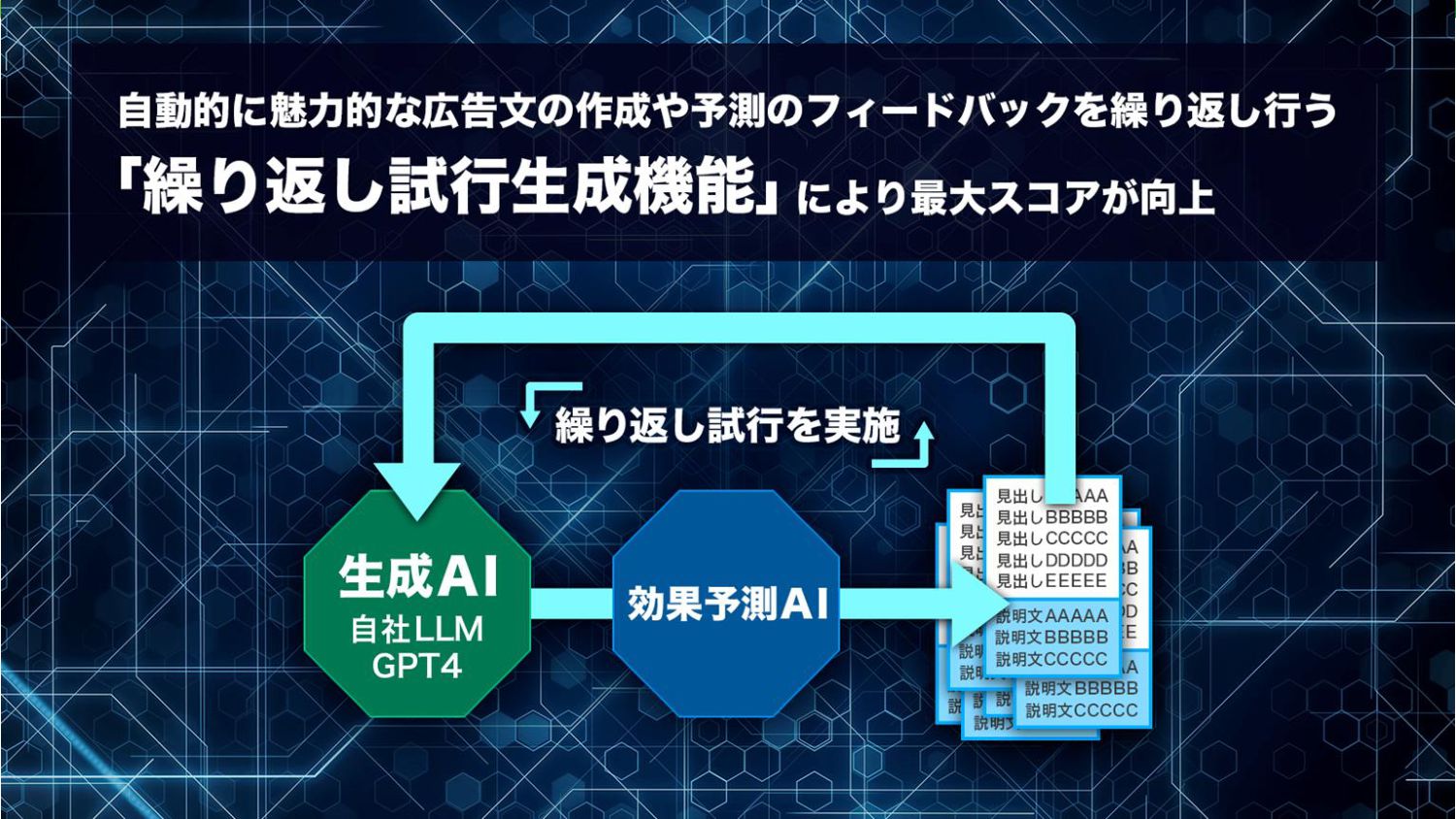
LLM API活用 TDオンデマンド生成サーバー開発 技術要件: • 今回開発するサーバーはクライアントに非同期APIを提供すること ◦ LLMの応答は各プロンプトあたり数十秒〜掛かる ◦ サーバはjob_idを返し、クライアントはjob_idで生成進捗を問い合わせる
• LLM APIコールのタイムライントレースログを記録できること • 運用形態によりそのスケール幅に柔軟に対応できること ◦ 社内外の様々なLLM APIに対応しつつ大量の生成タスクを同時実行 ◦ 1jobあたりの処理は I/O waitがほぼ全てでCPUが遊んでいる ▪ サーバー内で複数jobをマルチプロセスで処理できるとよし
BigQuery Cloud Storage worker ElastiCache Redis LLM API 推論結果 キャッシュ
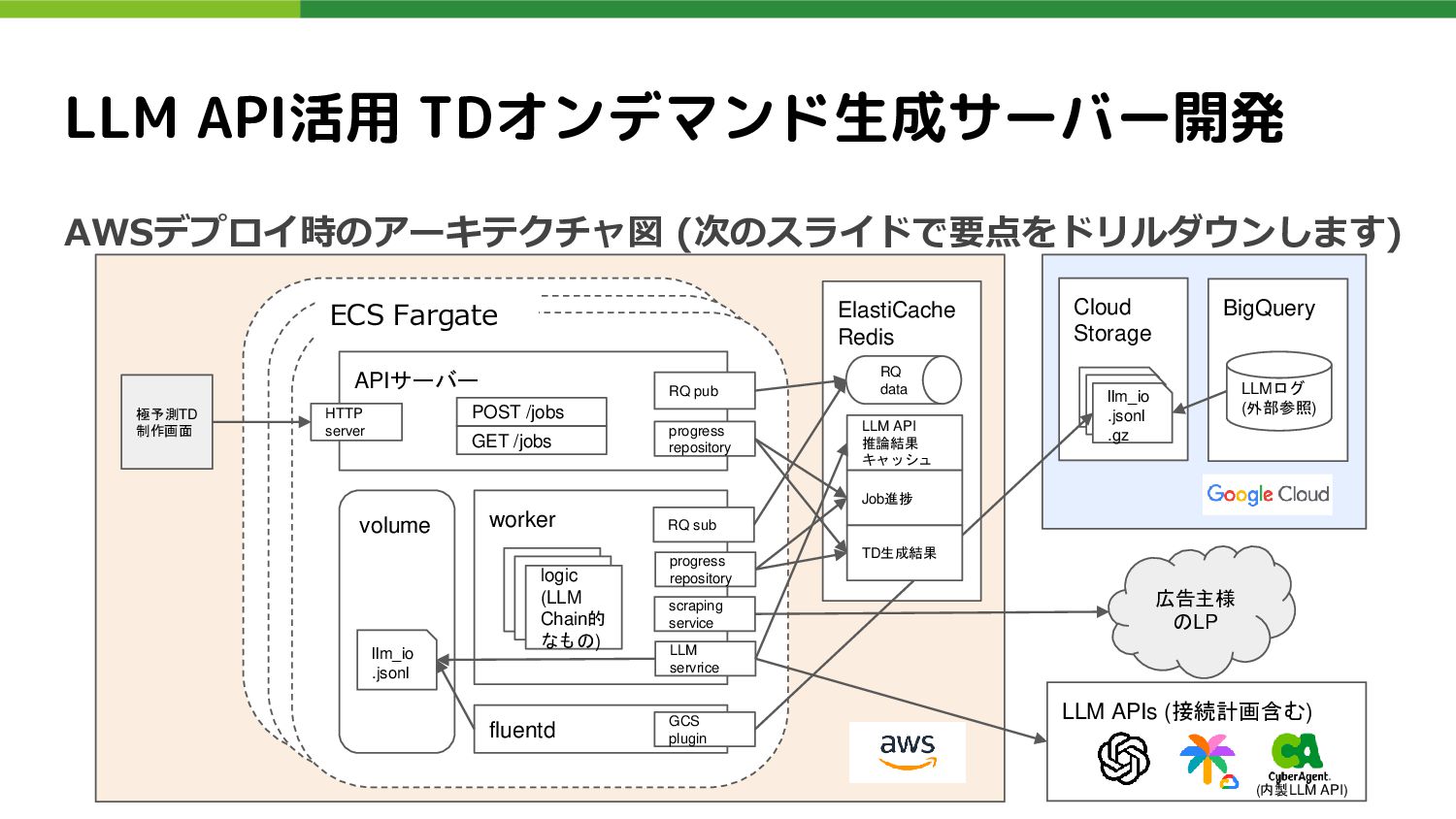
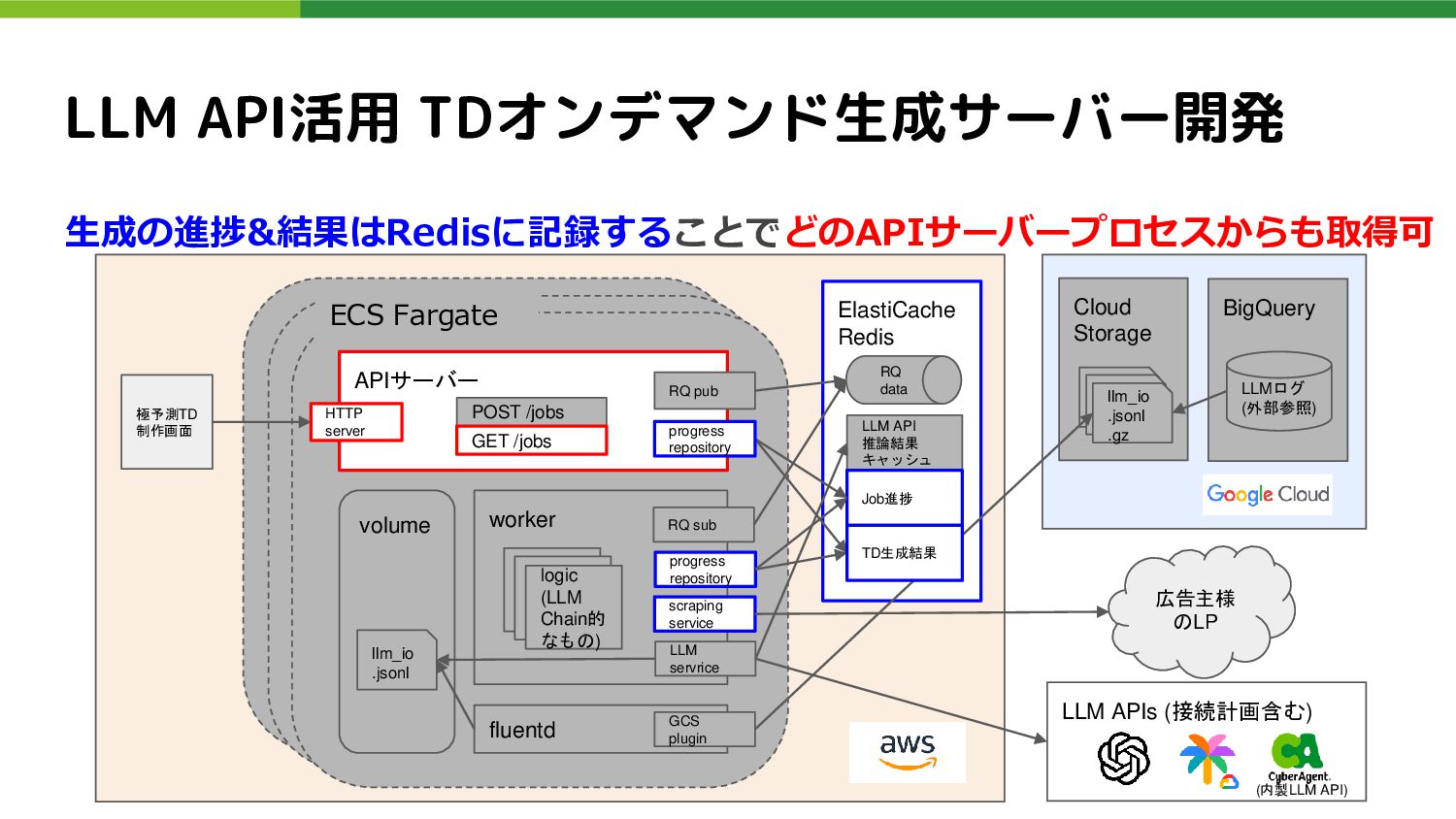
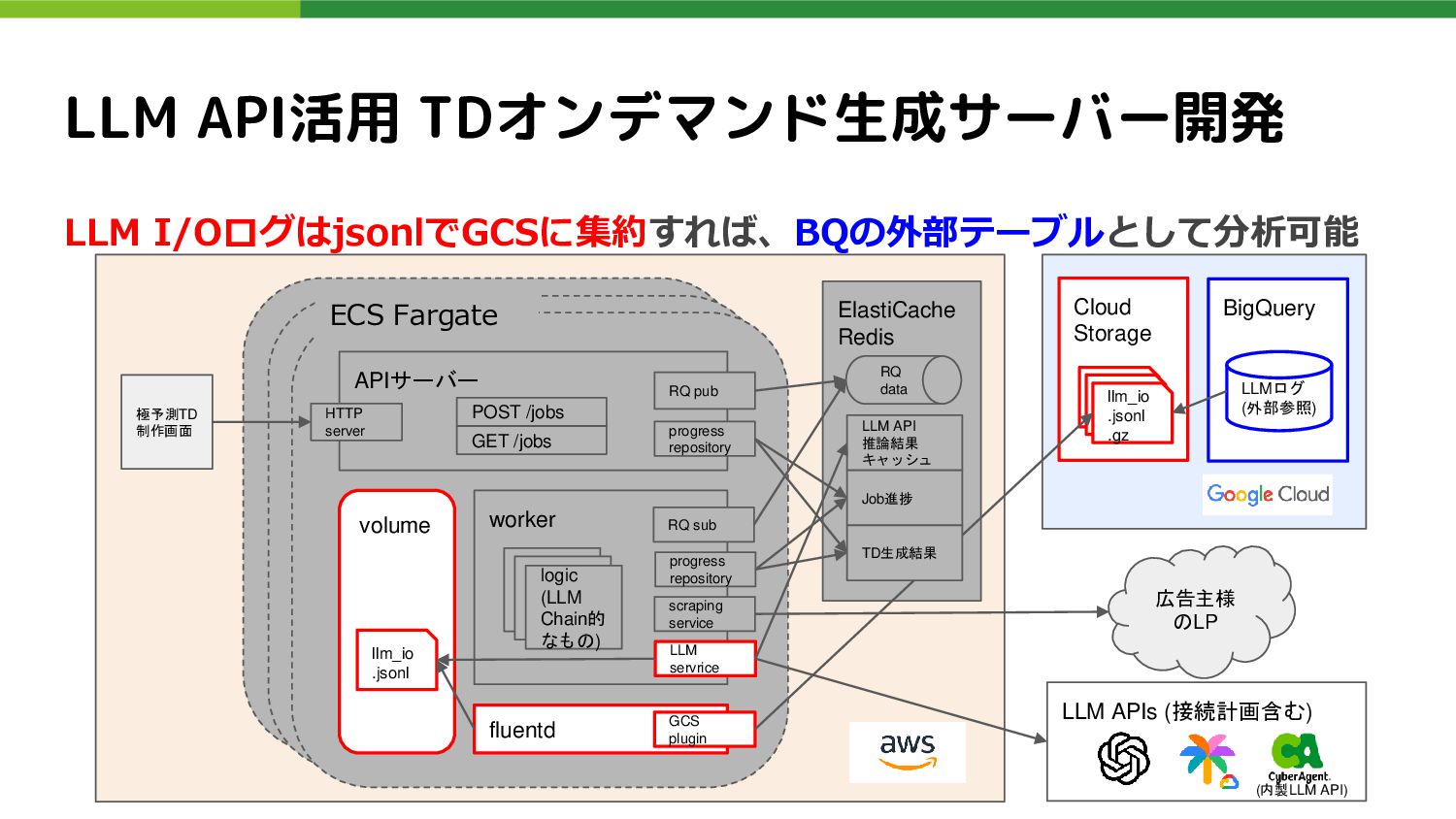
Job進捗 RQ data RQ sub LLM servrice volume llm_io .jsonl scraping service logic (LLM Chain的 なもの) fluentd progress repository GCS plugin 広告主様 のLP LLM APIs (接続計画含む) llm_io .jsonl llm_io .jsonl llm_io .jsonl .gz TD生成結果 極予測TD 制作画面 LLM API活用 TDオンデマンド生成サーバー開発 LLMログ (外部参照) ECS Fargate APIサーバー RQ pub progress repository HTTP server POST /jobs GET /jobs AWSデプロイ時のアーキテクチャ図 (次のスライドで要点をドリルダウンします) (内製LLM API)
BigQuery Cloud Storage worker ElastiCache Redis LLM API 推論結果 キャッシュ
Job進捗 RQ data RQ sub LLM servrice volume llm_io .jsonl scraping service logic (LLM Chain的 なもの) fluentd progress repository GCS plugin 広告主様 のLP LLM APIs (接続計画含む) llm_io .jsonl llm_io .jsonl llm_io .jsonl .gz TD生成結果 極予測TD 制作画面 LLM API活用 TDオンデマンド生成サーバー開発 LLMログ (外部参照) ECS Fargate APIサーバー RQ pub progress repository HTTP server GET /jobs サーバーとワーカーを分離し、MQ(今回はRQ)経由でjobを配布することでスケール POST /jobs (内製LLM API)
BigQuery Cloud Storage worker ElastiCache Redis LLM API 推論結果 キャッシュ
Job進捗 RQ data RQ sub LLM servrice volume llm_io .jsonl scraping service logic (LLM Chain的 なもの) fluentd progress repository GCS plugin 広告主様 のLP LLM APIs (接続計画含む) llm_io .jsonl llm_io .jsonl llm_io .jsonl .gz TD生成結果 極予測TD 制作画面 LLM API活用 TDオンデマンド生成サーバー開発 LLMログ (外部参照) ECS Fargate APIサーバー RQ pub progress repository HTTP server POST /jobs GET /jobs 生成の進捗&結果はRedisに記録することでどのAPIサーバープロセスからも取得可 (内製LLM API)
BigQuery Cloud Storage worker ElastiCache Redis LLM API 推論結果 キャッシュ
Job進捗 RQ data RQ sub LLM servrice volume llm_io .jsonl scraping service logic (LLM Chain的 なもの) fluentd progress repository GCS plugin 広告主様 のLP LLM APIs (接続計画含む) llm_io .jsonl llm_io .jsonl llm_io .jsonl .gz TD生成結果 極予測TD 制作画面 LLM API活用 TDオンデマンド生成サーバー開発 LLMログ (外部参照) ECS Fargate APIサーバー RQ pub progress repository HTTP server POST /jobs GET /jobs LLM I/OログはjsonlでGCSに集約すれば、BQの外部テーブルとして分析可能 (内製LLM API)
LLM API活用 TDオンデマンド生成サーバー開発 得られた成果: • あらゆる実行環境に適応できるコンパクトかつelasticなシステムとなった ◦ ローカルでDocker Compose等で小さく起動 ◦
極TD画面からの1APIサービスとして起動 ◦ バッチ実行向けに大きくスケールアウト(OpenAIのTPMリミットに注意) SWE経験が活かされたところ: • 非同期仕様のAPIはたまによく作るもの。今回もその延長線上にあり • クリーンアーキテクチャで実装し、コードの運用・保守性を担保
目次 • 簡単な前提知識の共有(プロダクト紹介とMLOps) • MLプロダクト開発においてサーバーサイド経験が活きた例 • 最後に ◦ MLエンジニア転向を決めた原体験 ◦
まとめ
MLエンジニア転向を決めた原体験 原体験: • 前所属の広告配信プロダクトでML方面で力になれなかった ◦ DSと一つのMLタスクをこなすことになったときは力不足を痛感 ◦ その頃から、MLEという職種に強い憧れを抱く • AI事業本部発足に伴い所属プロダクトのクローズ
◦ このタイミングでML未経験からのMLE転向を志願し、叶った
MLエンジニア転向を決めた原体験 実際MLEになってみて: • やはり数学が少しきつかった・・(学部卒から十数年のブランクやむなし) ◦ 逆に言うと、モチベ次第で文系からの転向も問題ないと思います • ソフトウェア設計やコーディングはエンジニアとして一日の長ありは実感 • 前プロダクトでDataOpsのノウハウがあったことは大きな助けになった
まとめ • SWEからMLEへの転向は、MLを学びながらでも問題なく、実務でSWEとし てのノウハウやプレゼンスを発揮できる局面がたくさんあり、この方向性で 十分に貢献できることを示しました • MLE、DataOps、MLOpsしたい同士求む! 今回触れませんでしたが、予測モデルの設計・実験も業務で行っています 性質上ほぼ社外秘ですが懇親会レベルではMLの方でも少し情報交換できること もあるかもしれません
ご清聴 ありがとう ございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}