Share
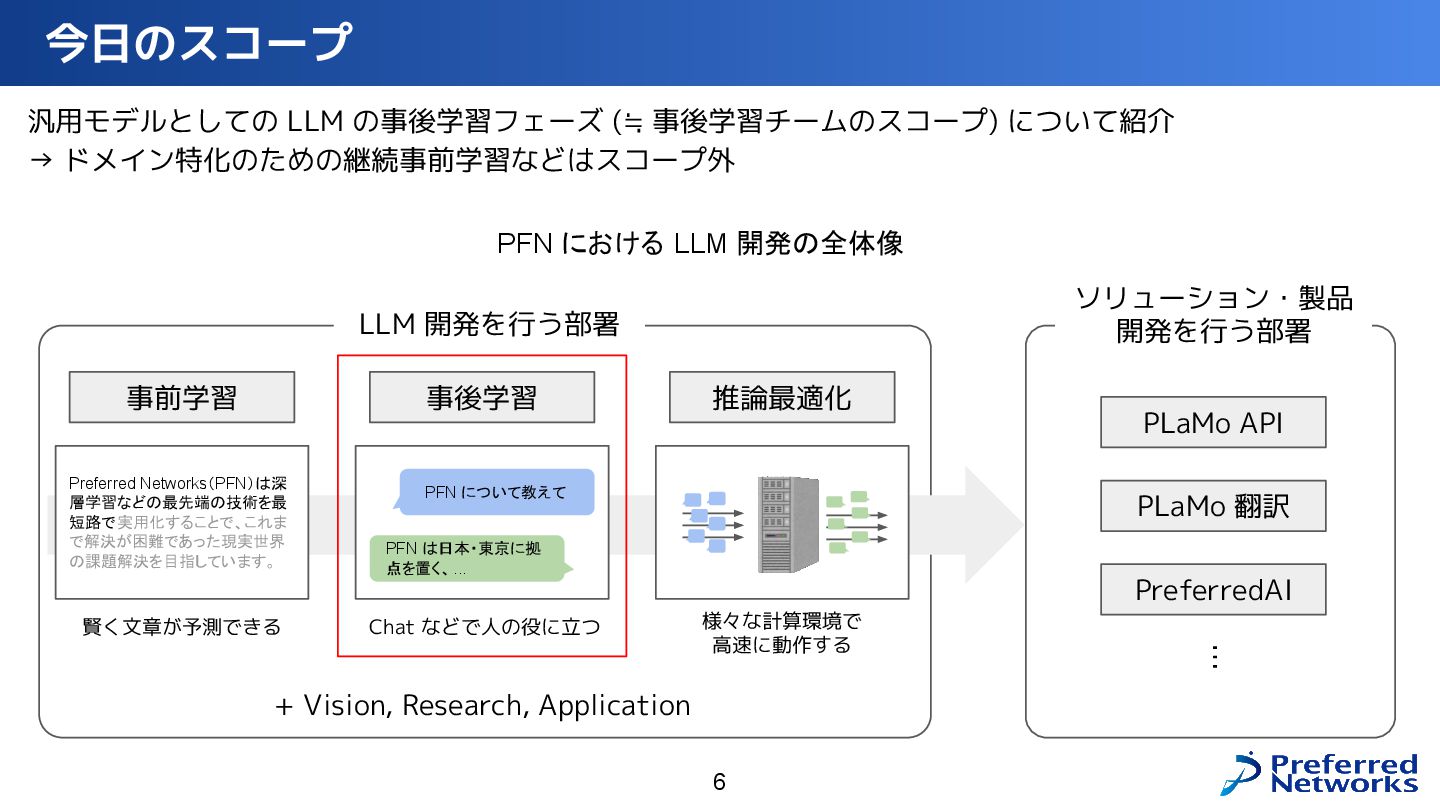
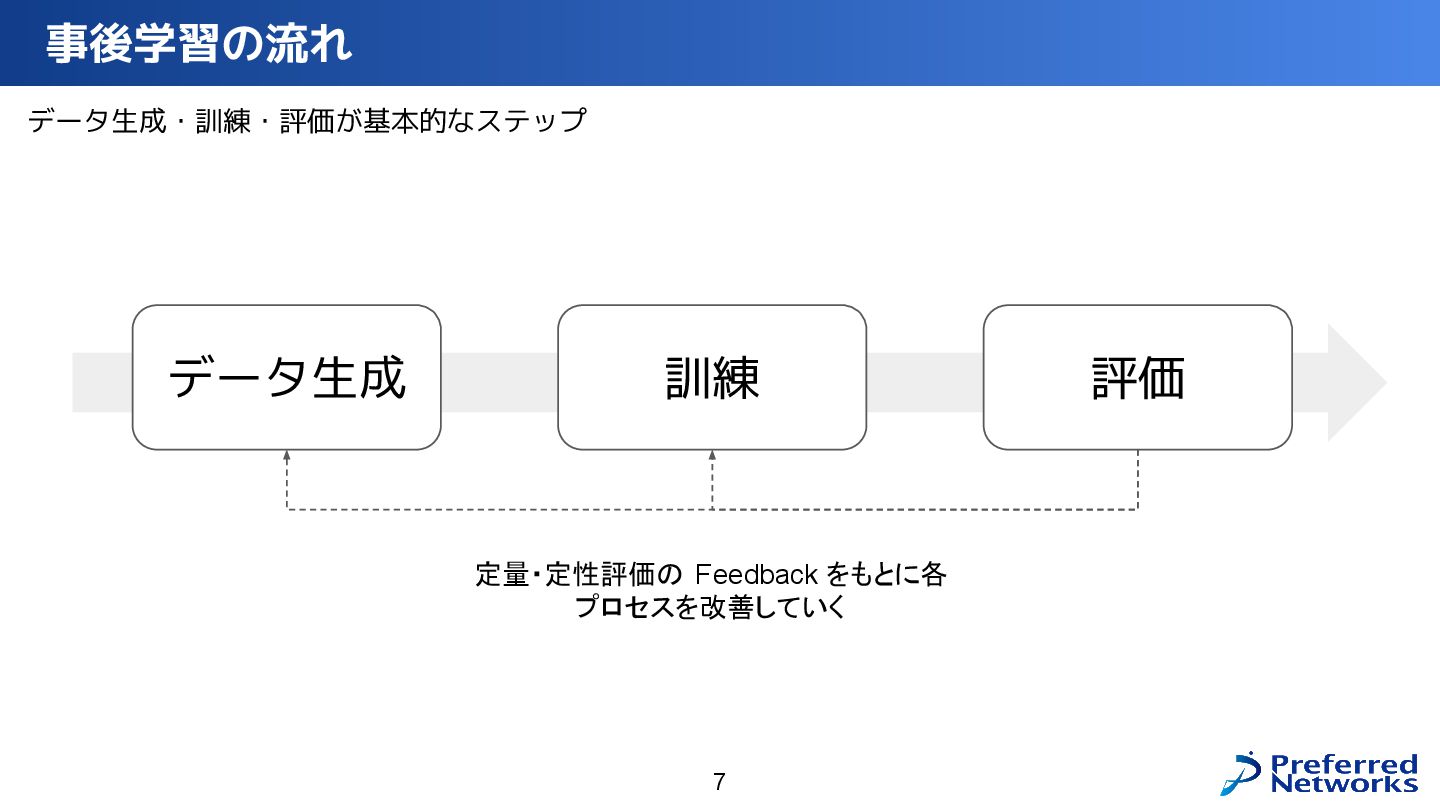
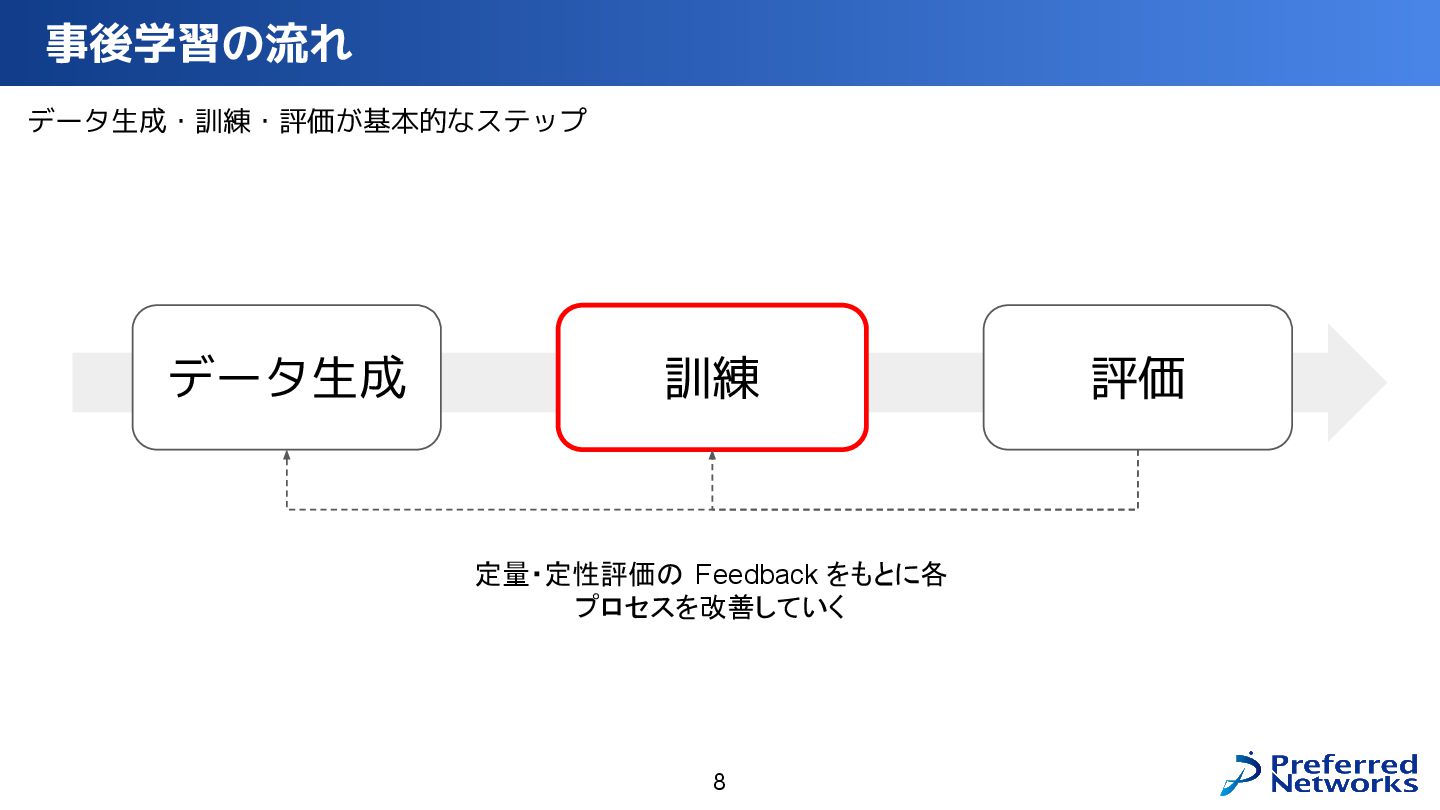
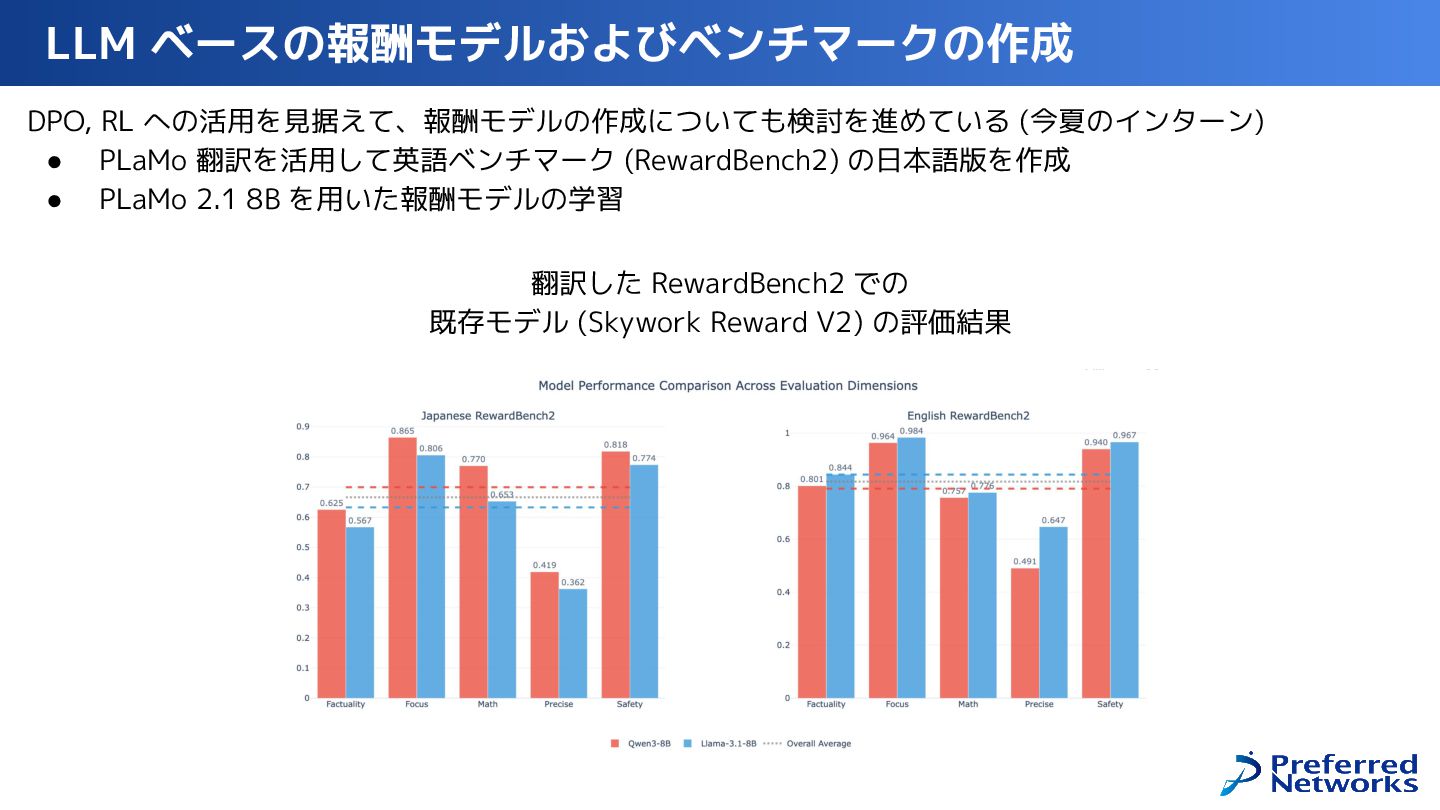
PLaMo を人の役に立つ形に Fine-Tuning していく事後学習の全体像と、そこで使われている技術について、データ生成・学習・評価などの各プロセスを掘り下げてご紹介します。
イベントサイト: https://preferred-networks.connpass.com/event/368829/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}