Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Web Scraping 101
Search
Cyrus Stoller
November 17, 2015
How-to & DIY
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Web Scraping 101
Cyrus Stoller
November 17, 2015
More Decks by Cyrus Stoller
See All by Cyrus Stoller
Guide to winning a hackathon
cyrusstoller
0
2k
Other Decks in How-to & DIY
See All in How-to & DIY
JAWS-UG/AWSコミュニティ アップデート (JAWS-UG函館支部)
awsjcpm
3
170
【ふりかえりワークショップ】Tryを決めるだけじゃない!感情にフォーカスした、ふりかえりを体験しよう!
scrummasudar
0
1.5k
Node-REDで制御できるエッジカメラのreCameraを触る #iotlt #JLCPCB #recamera
n0bisuke2
0
190
How to make the Groovebox
asonas
2
2.3k
大量のiOSシミュレータにアプリをインストールする
gurrium
0
150
JAWS-UG/AWSコミュニティ JAWS-UG おおいた
awsjcpm
2
3k
移動は善 / 20260124-NGK2026S
girigiribauer
1
190
AWS Community/JAWS-UG Update - JAWS-UG 上越妙高支部リブート
awsjcpm
2
130
多摩ニュータウンを、 味わう
aokiplayer
2
720
とある地方技術勉強会に集うエンジニアたちのこれまでとこれから
pharaohkj
1
170
JAWS-UG横浜100回記念 私のAWS ジャーニーと日本からみた横浜支部
awsjcpm
0
450
生成AIは 『コードを書く』だけじゃない アーキテクチャ設計から環境構築まで——社内データ活用DXの全貌
punipuni_mint
0
210
Featured
See All Featured
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
4 Signs Your Business is Dying
shpigford
187
22k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
The Pragmatic Product Professional
lauravandoore
37
7.4k
A better future with KSS
kneath
240
18k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Unsuck your backbone
ammeep
672
58k
Transcript
Web Scraping @cyrusstoller November 17, 2015
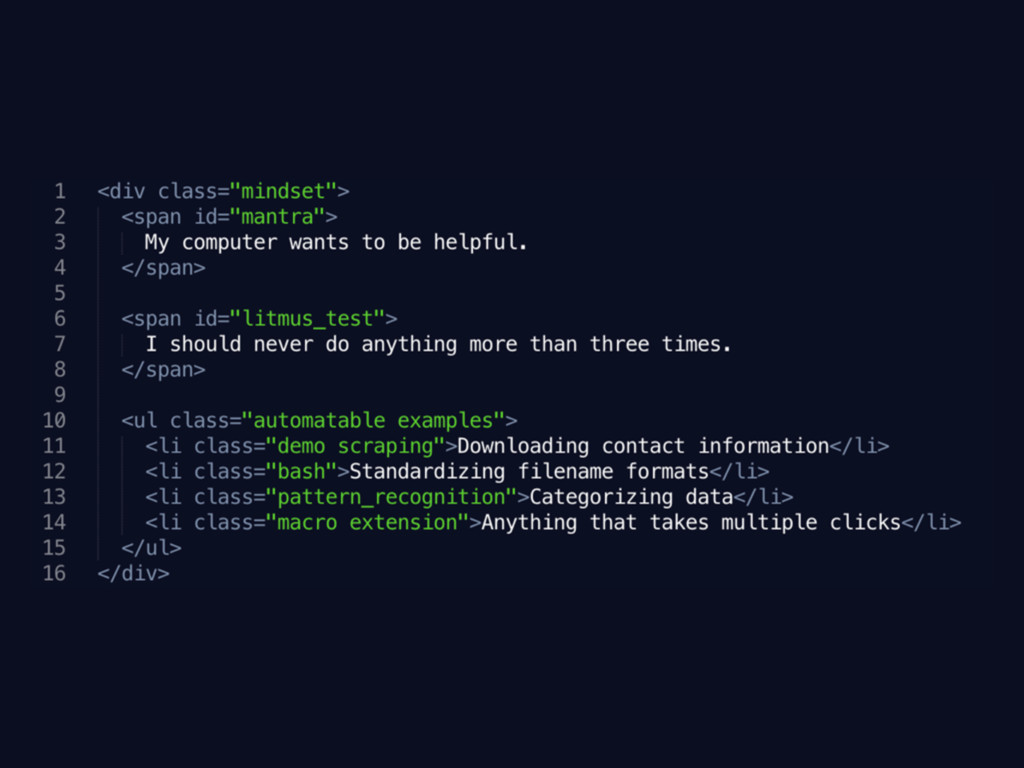
Repetitive tasks? No thank you.
None
None
Ruby gem install faraday nokogiri Python pip install scrapy Javascript
/ node.js npm install cheerio cURL / wget curl -o http://example.com ! wget -r --level=2 http://example.com/
None
None
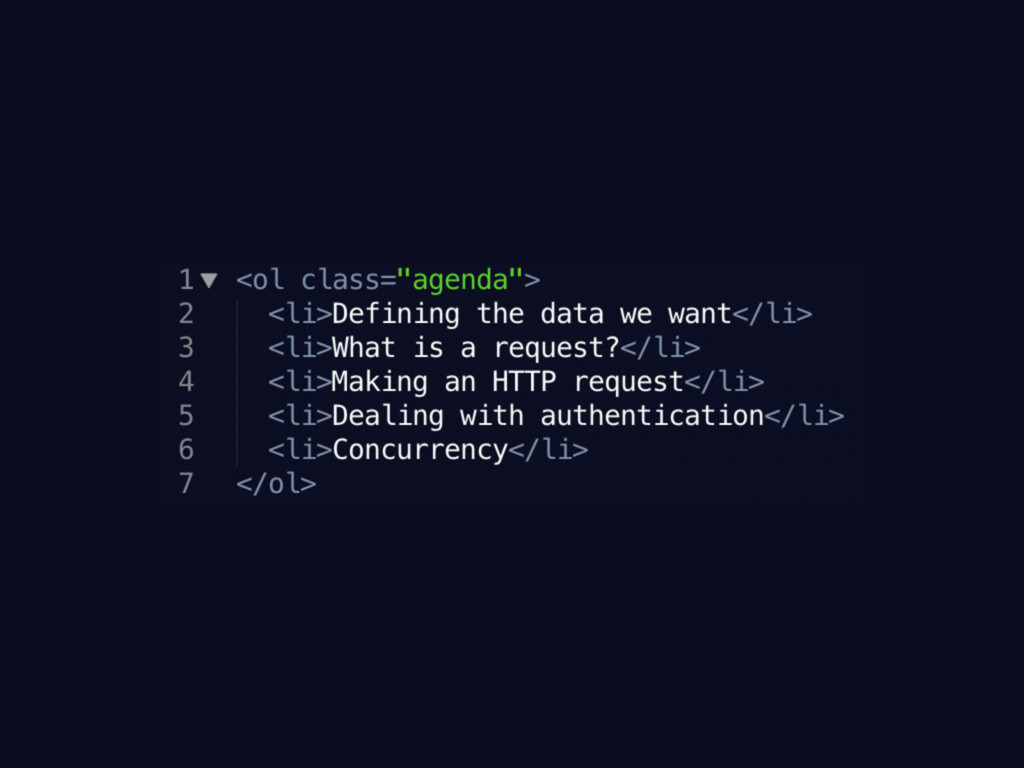
Defining the data we want
You can look this up on your own
You can look this up on your own
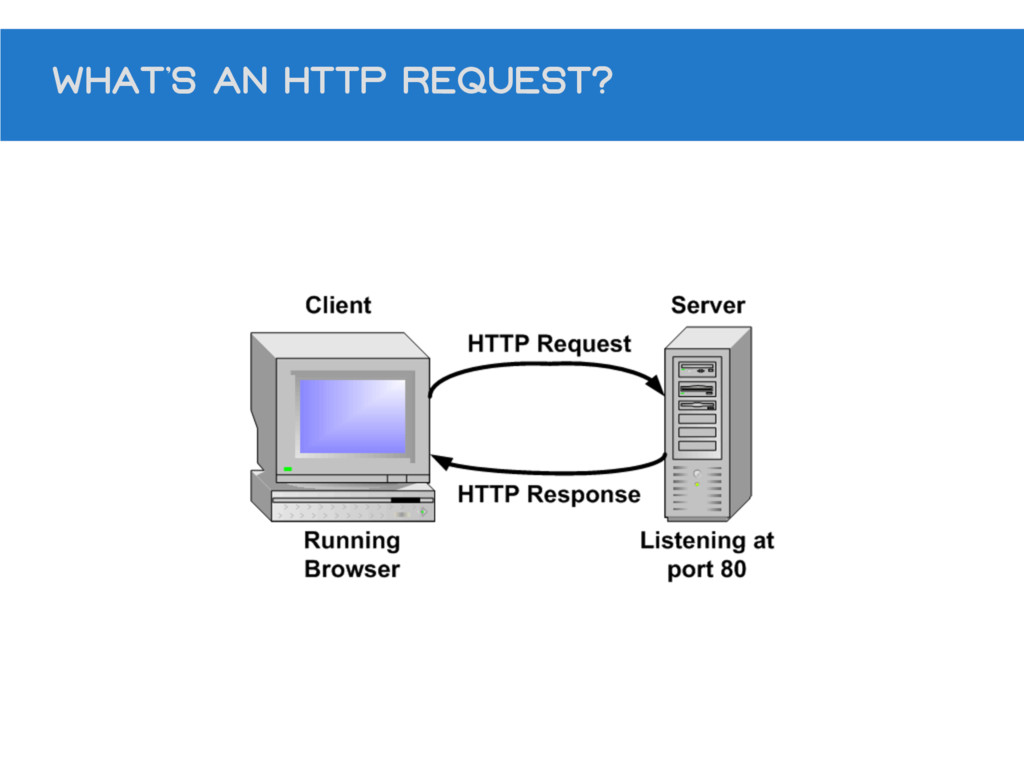
What’s an HTTP request?
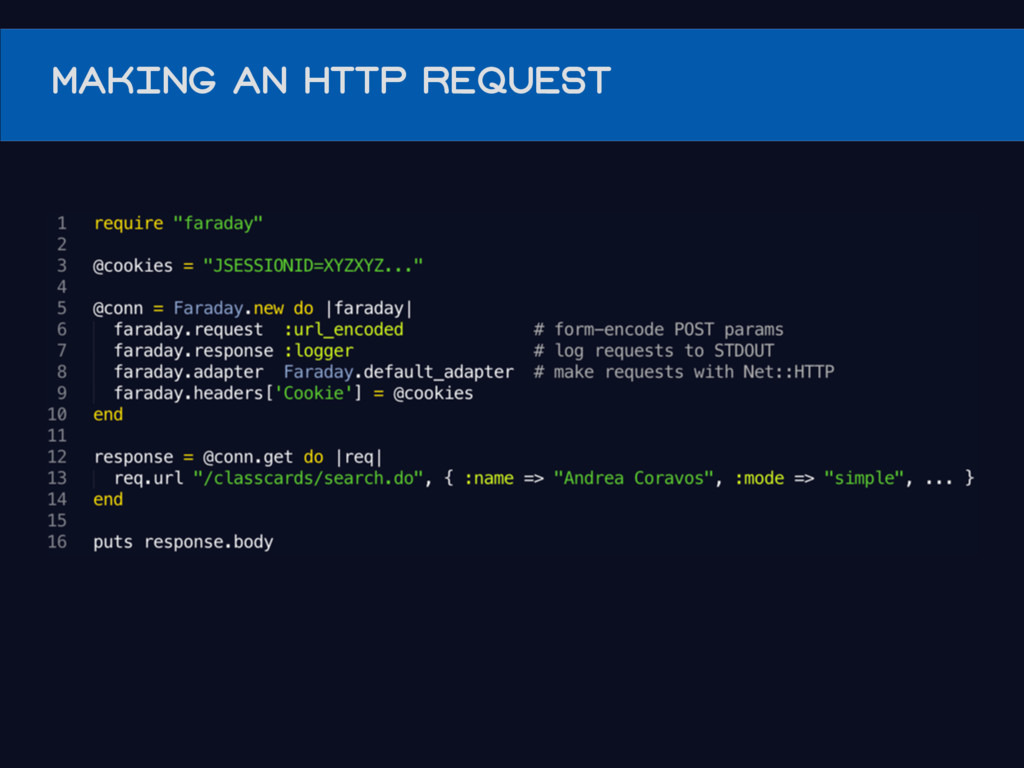
Making an HTTP request
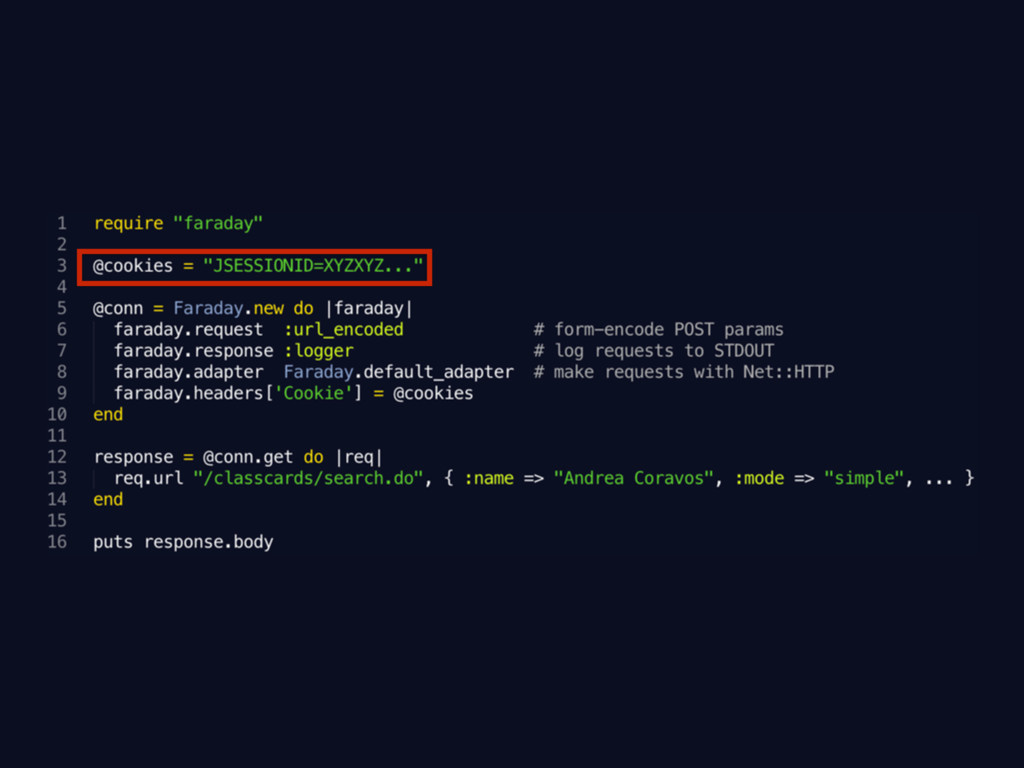
Dealing with Authentication
None
None
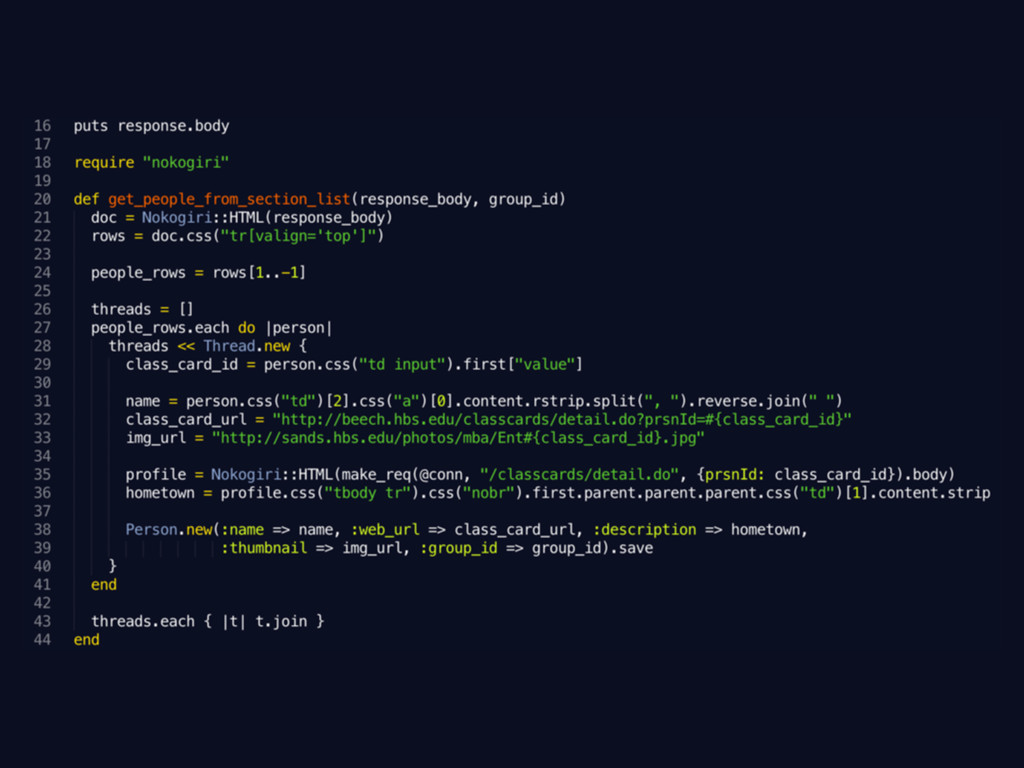
Concurrency
Picking what you want
None
<code walkthrough>
Turn it up
Questions?
twitter: @cyrusstoller github: @cyrusstoller blog: cyrusstoller.com ! possible spring workshop
series on automation and web scraping
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}