Speech & Language Processingの10章前半をスライドにまとめました。
目次
introduction
10.1 The Transformer: A Self-Attention Network
10.1.1 Transformers: the intuition
10.2 Causual or backward-looking self attention
10.1.3 Self-attention more formally
10.1.4 Parallelizing self-attention using a single matrix X
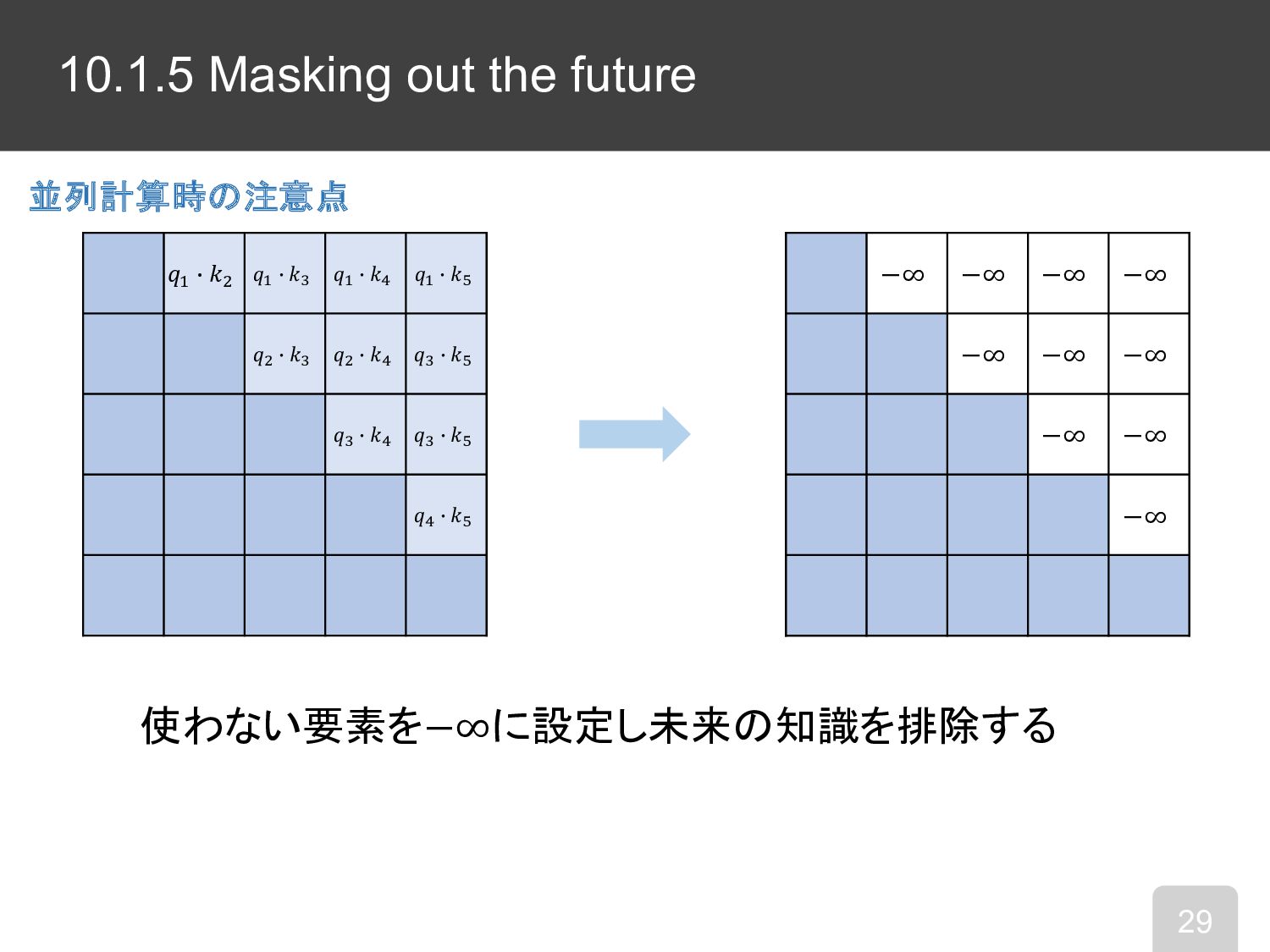
10.1.5 Masking out the future
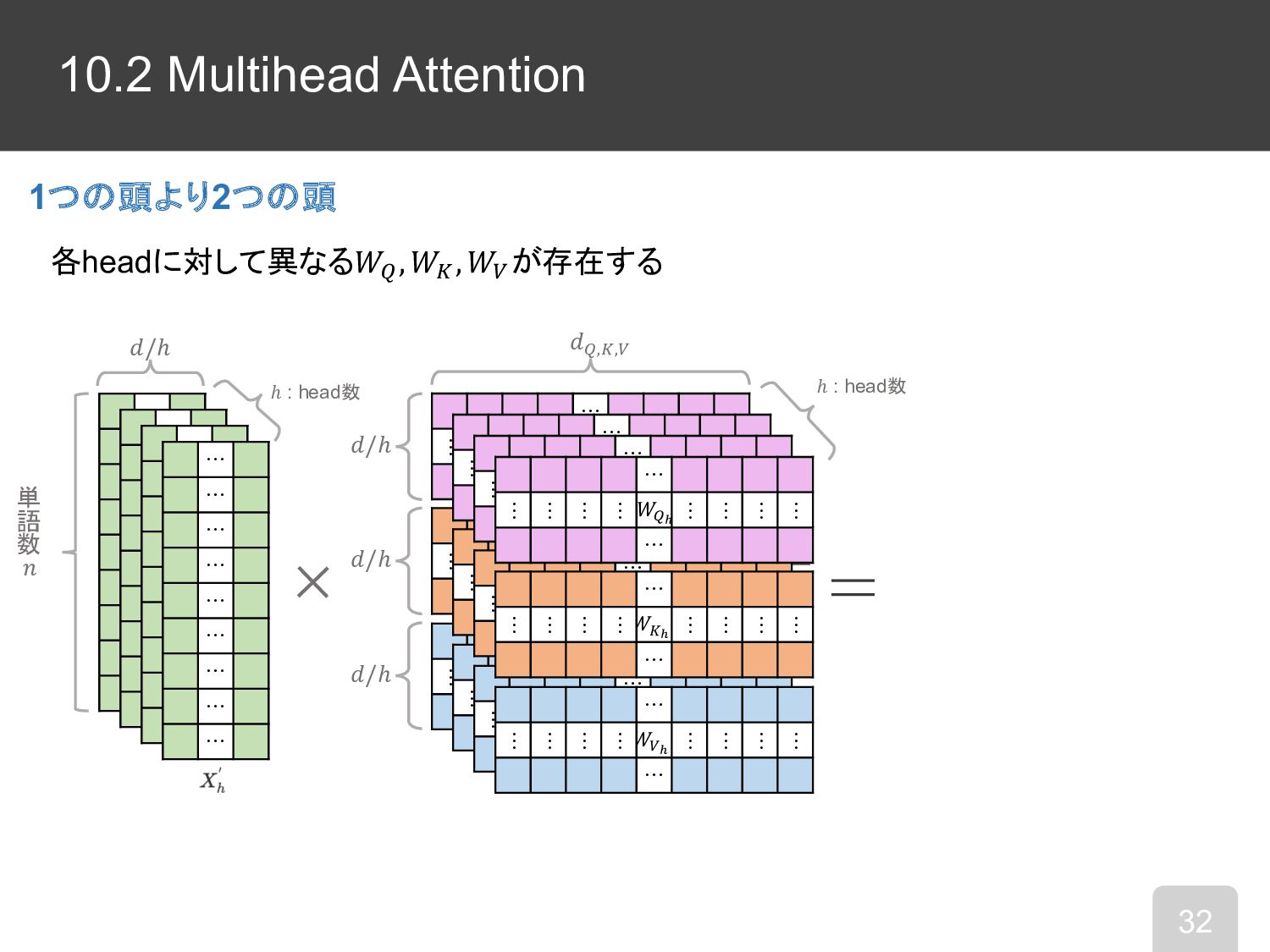
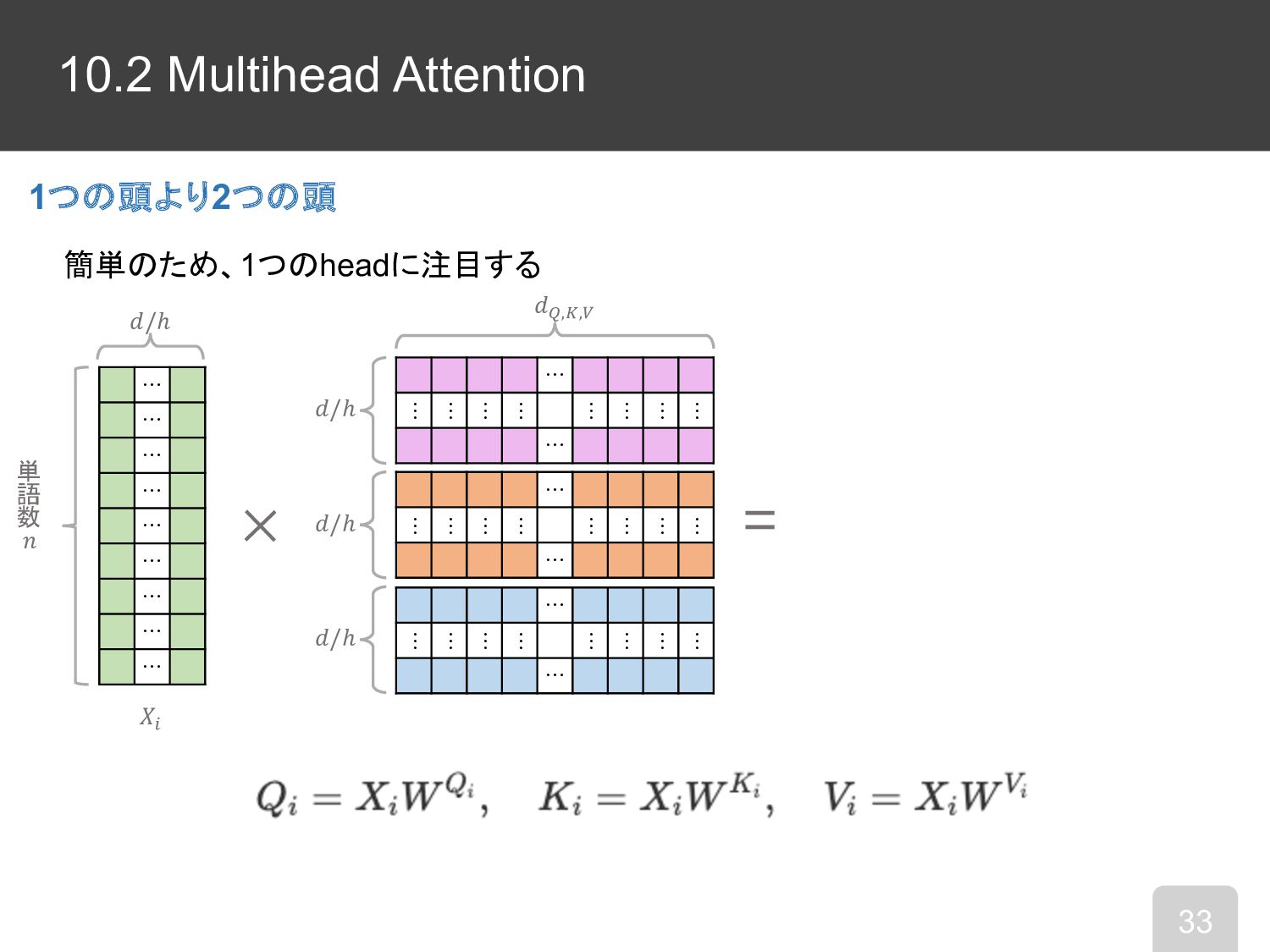
10.2 Multi-Head Attention
10.3 Transformer Blocks
10.4 The Residual Stream view of the Transformer Block
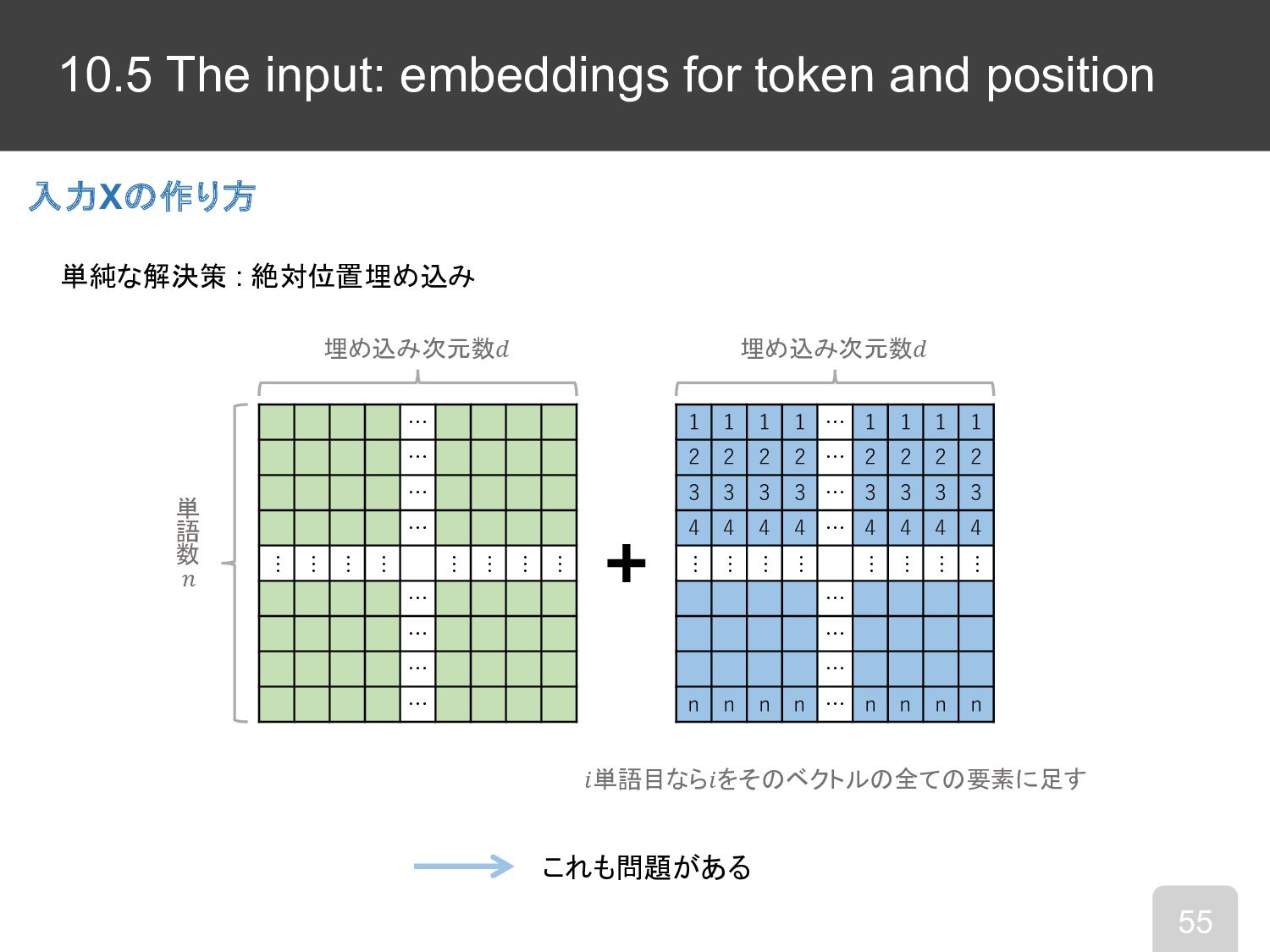
10.5 The input: embeddings for token and position
※学部生が作った資料なので間違いがある可能性があります。誤りを見つけた場合はコメントなどで指摘していただけると幸いです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}