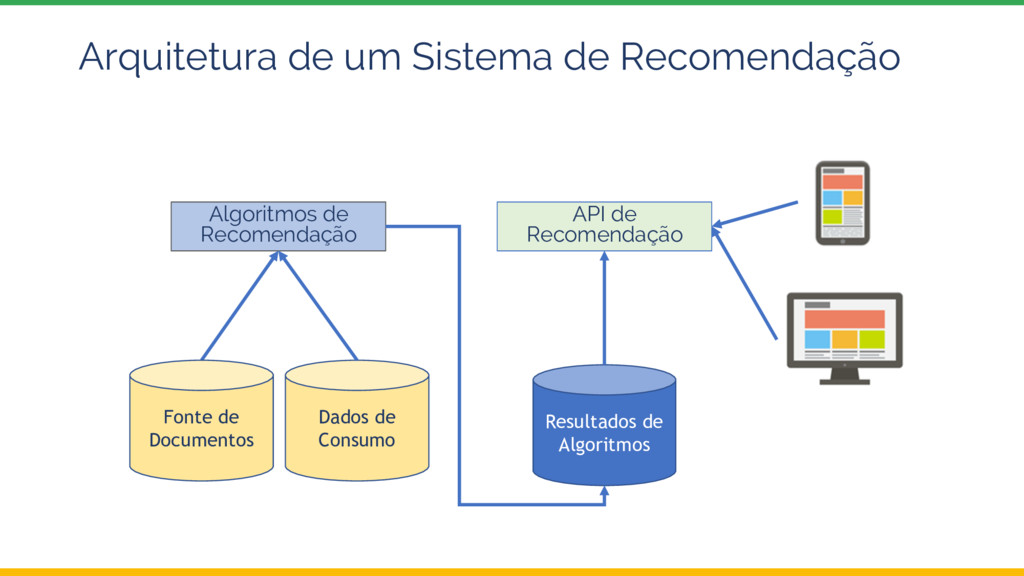
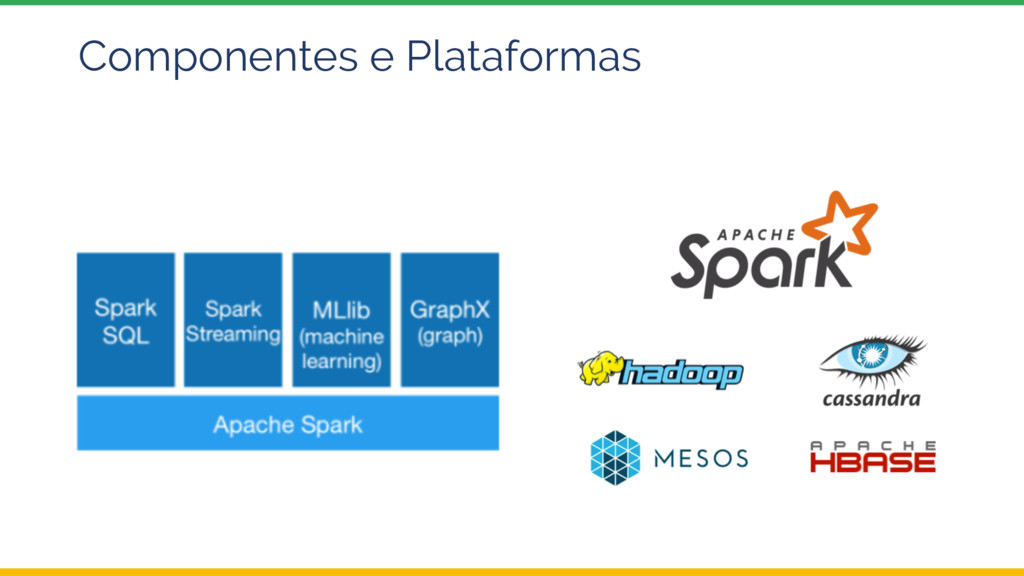
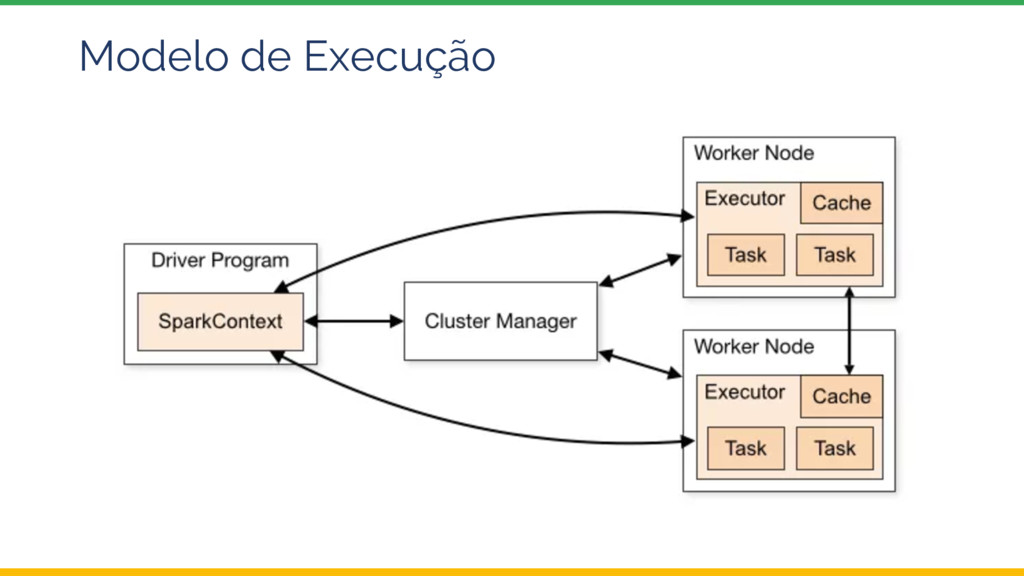
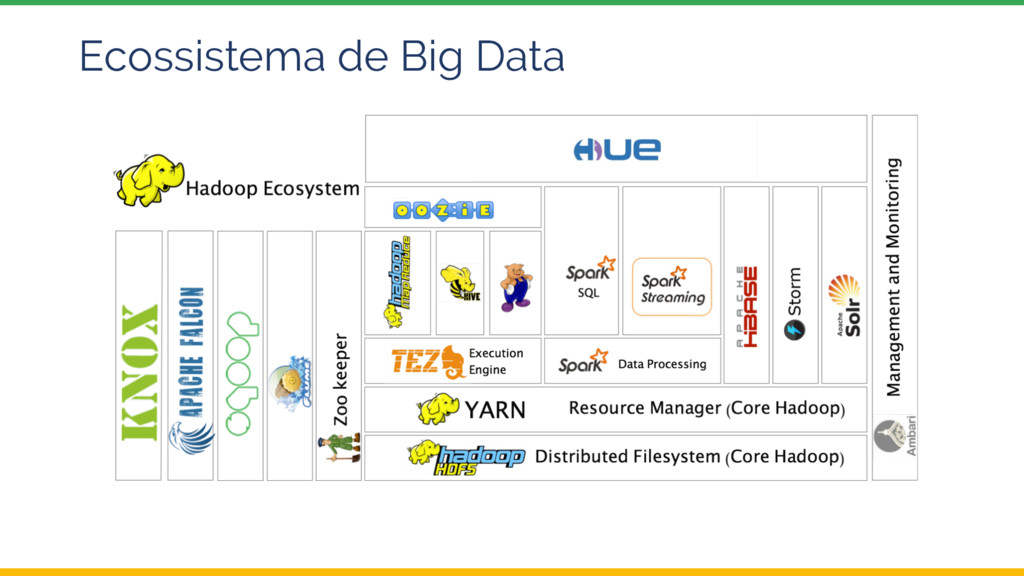
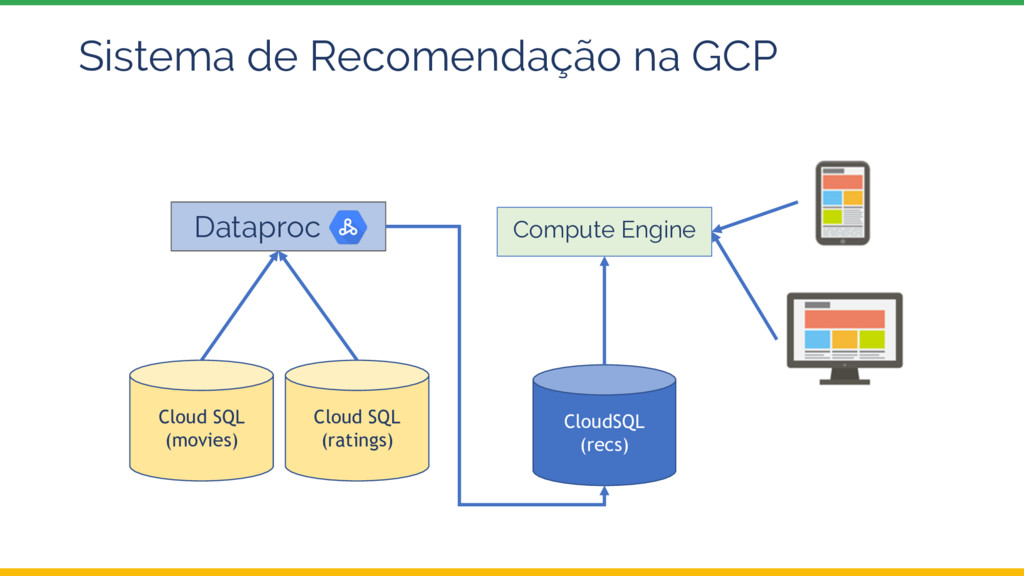
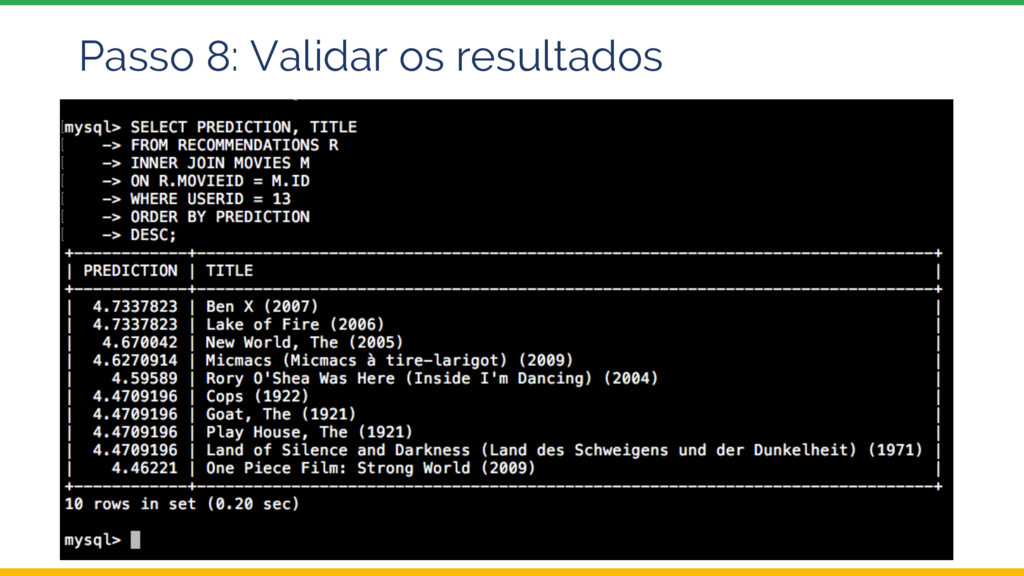
Esta palestra introduz o tema Sistemas de Recomendação e depois explora uma possível arquitetura e implementação utilizando ferramentas da Google Cloud Platform, com ênfase no Dataproc, a oferta Apache Spark do Google.
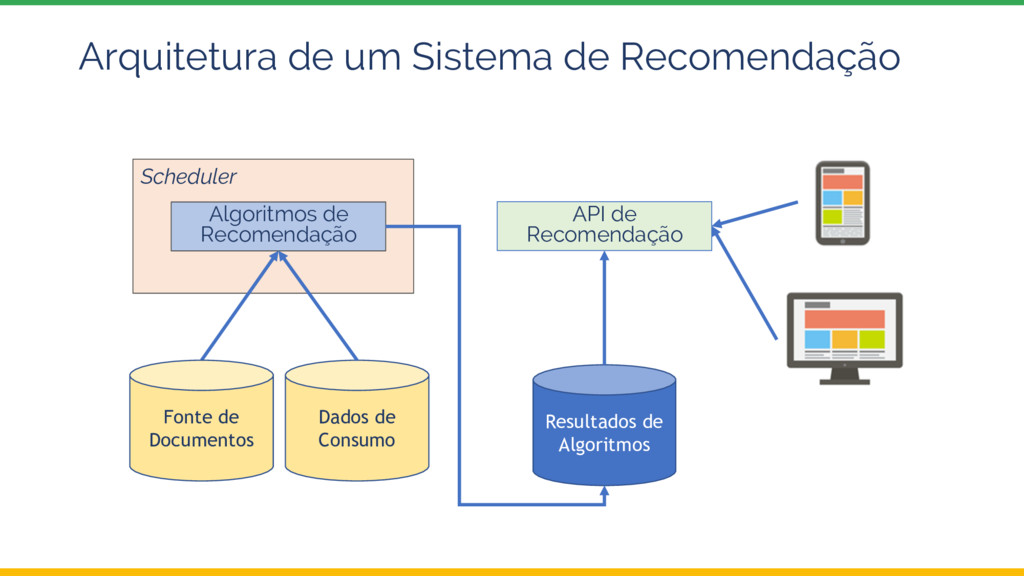
infraestrutura da GCP abstrai muito a complexidade da arquitetura de Big Data • Faltam algumas features para ser production ready: • Suporte a outros algoritmos (ensemble) • Scheduler • Testes A/B • Ingestão de dados reais • API para consumo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
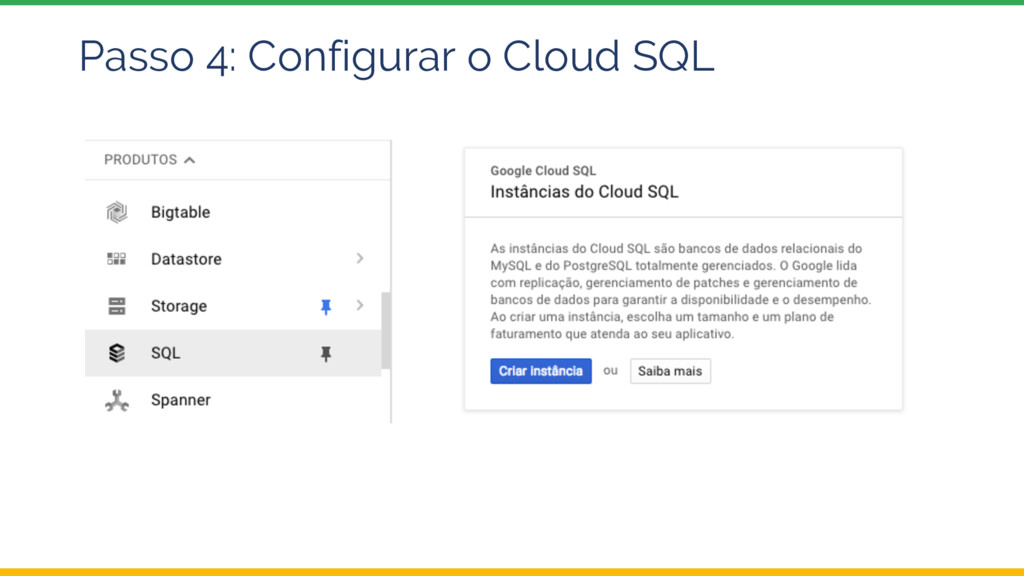{kind=link}
{kind=link}
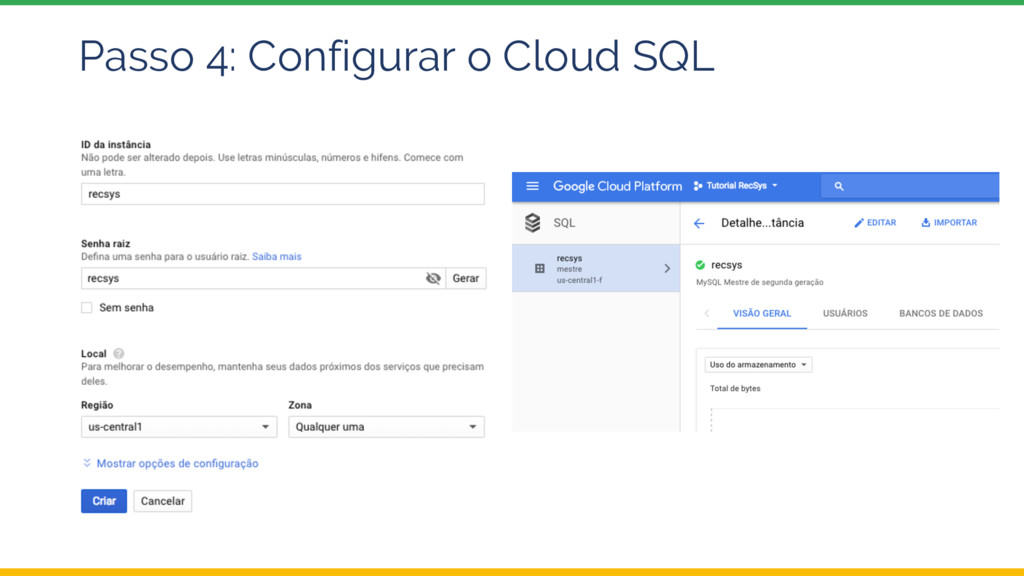{kind=link}
{kind=link}
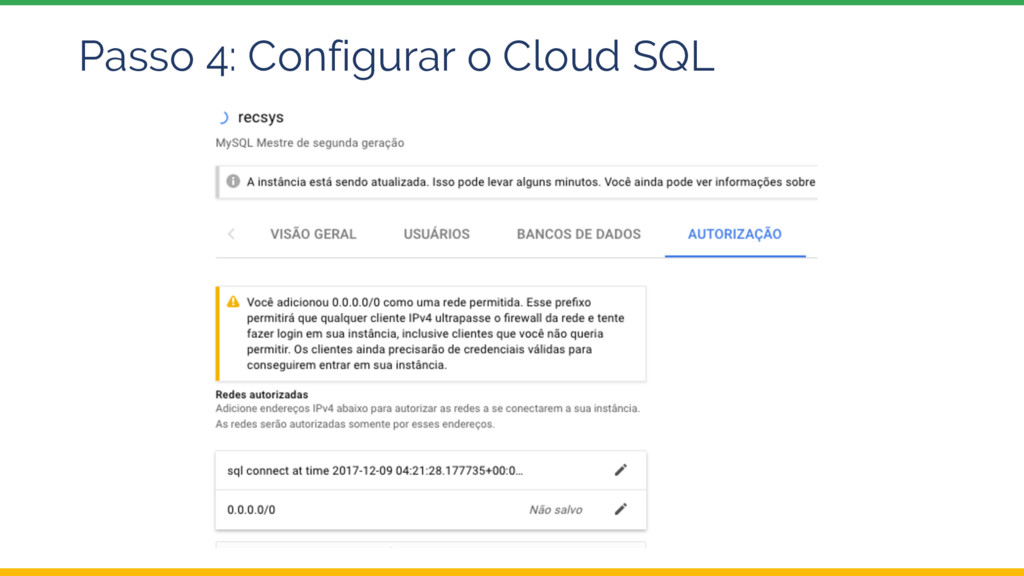{kind=link}
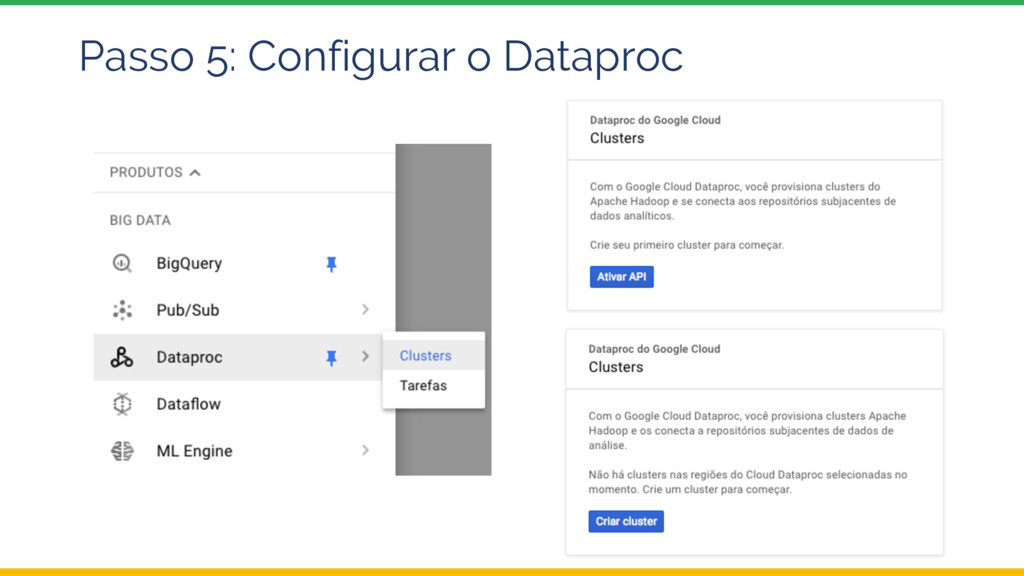{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigada! [email protected] https://linkedin.com/in/petruzalek https://twitter.com/danicat83 https://github.com/danicat](https://files.speakerdeck.com/presentations/252d8f2244c2455f8bd1af44c7ed505e/slide_37.jpg){kind=link}