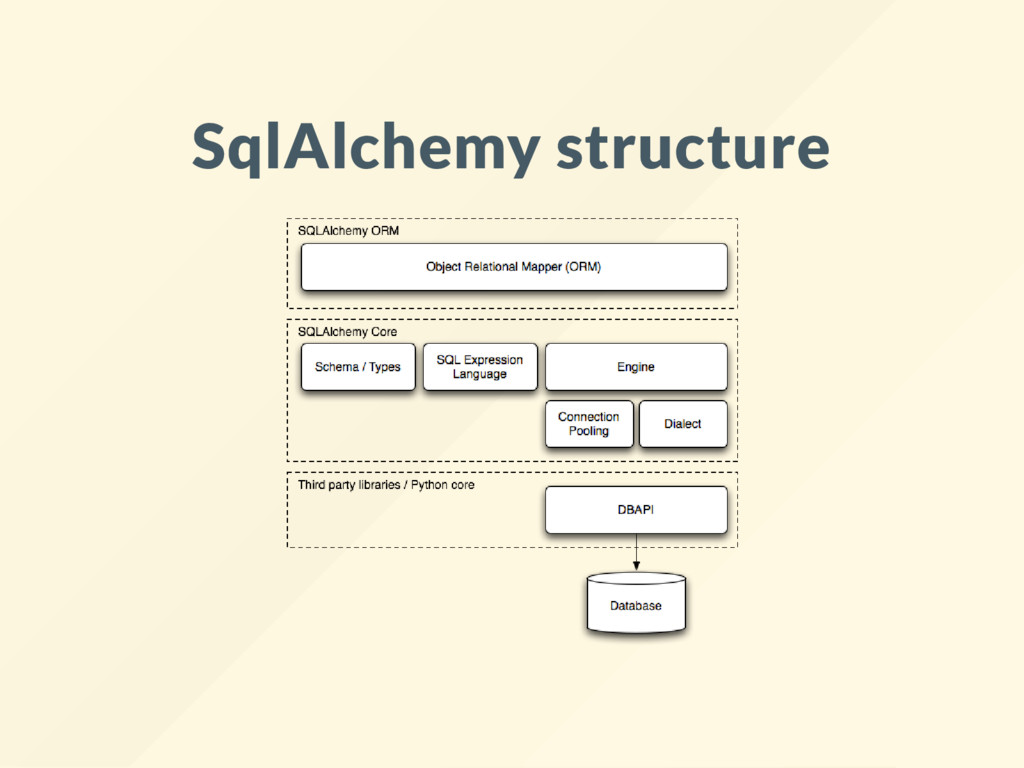
moving data between the active objects and the database) primary key is NOT automatic autocommit is OFF by default supports the same as Django ORM, also MsSql has 2 parts: ORM and Core (the ORM is built on top of the core)
MetaData from sqlalchemy.sql import select eng = create_engine('sqlite:///test.db') con = eng.connect() # load the definition of the Cars table. meta = MetaData(eng) cars = Table('Cars', meta, autoload=True) # selects all columns and rows from the provided table stm = select([cars]) # executes the statement rs = con.execute(stm) # returned data print(rs.fetchall())
sqlalchemy.orm import sessionmaker eng = create_engine('sqlite:///test.db') # create a configured "Session" class Session = sessionmaker(bind=eng) # create a Session session = Session() # work with session (saving an object) obj = SomeObject('foo') session.add(obj) session.commit()
conversations with the database and represents a “holding zone” for all the objects which you’ve loaded or associated with it during its lifespan. So, this Django query... MyModel.objects.all() would look like this in SqlAlchemy ORM: session.query(MyModel).all()
creating a QuerySet doesn’t involve any database activity. You can add lters together and Django won’t run the query until the QuerySet is evaluated. Evaluation is also done by iterating over the QuerySet, or calling Python methods on it: len(), list() or bool()
the previous query- set is cloned, the method is applied on it (for example filter() , exclude() ) and the new QuerySet is returned. In some other cases, something else is returned(for example get() , count() , first() ) When a QuerySet is evaluated, all the rows are fetched unless there is an already cached result. So, each QuerySet contains a cache, to minimize database access.
empty. The rst time a QuerySet is evaluated — and, hence, a database query happens — Django saves the query results in the QuerySet‘s cache and returns the results that have been explicitly requested (e.g., the next element, if the QuerySet is being iterated over).
example, the following will create two QuerySets, evaluate them, and throw them away: print([e.headline for e in Entry.objects.all()]) print([e.pub_date for e in Entry.objects.all()])
effectively doubling your database load. To avoid this problem, simply save the QuerySet and reuse it: queryset = Entry.objects.all() print [p.headline for p in queryset] # evaluation print [p.pub_date for p in queryset] # reuse the cache
statements generated by the ORM. Successive calls return a new Query object, a copy of the former with additional criteria and options associated with it. (similar to Django in this aspect) Query objects are normally initially generated using the query() method of Session. They do not support caching, but can be extended to do so.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}