letter, Lovelace suggests an example of a calculation which “may be worked out by the engine without having been worked out by human head and hands first”.
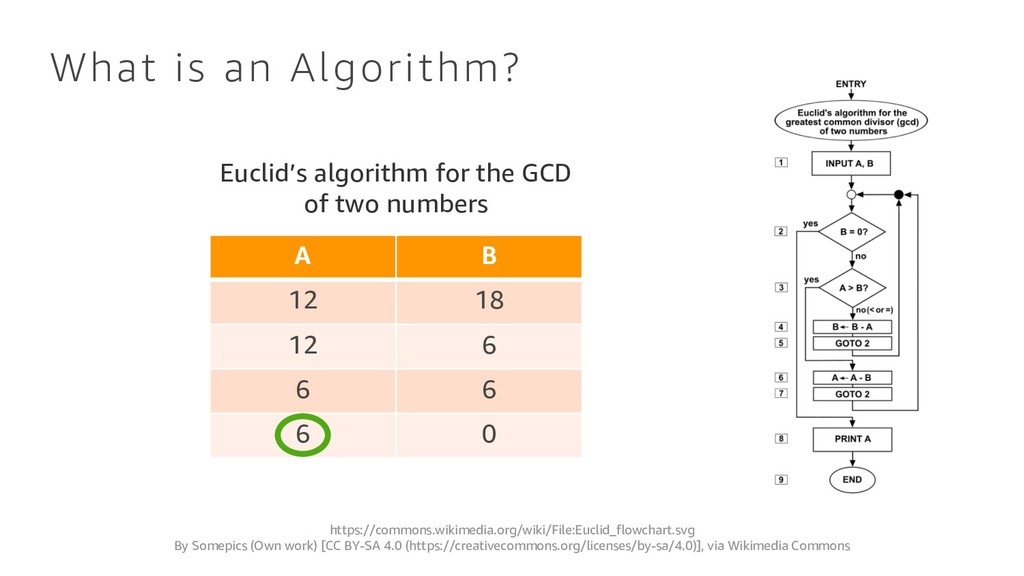
BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], via Wikimedia Commons A B 12 18 12 6 6 6 6 0 Euclid’s algorithm for the GCD of two numbers
Before you write code you need an algorithm. An algorithm is a list of rules to follow in order to solve a problem.” BBC Bitesize What is an Algorithm? https://commons.wikimedia.org/wiki/File:Euclid_flowchart.svg By Somepics (Own work) [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], via Wikimedia Commons
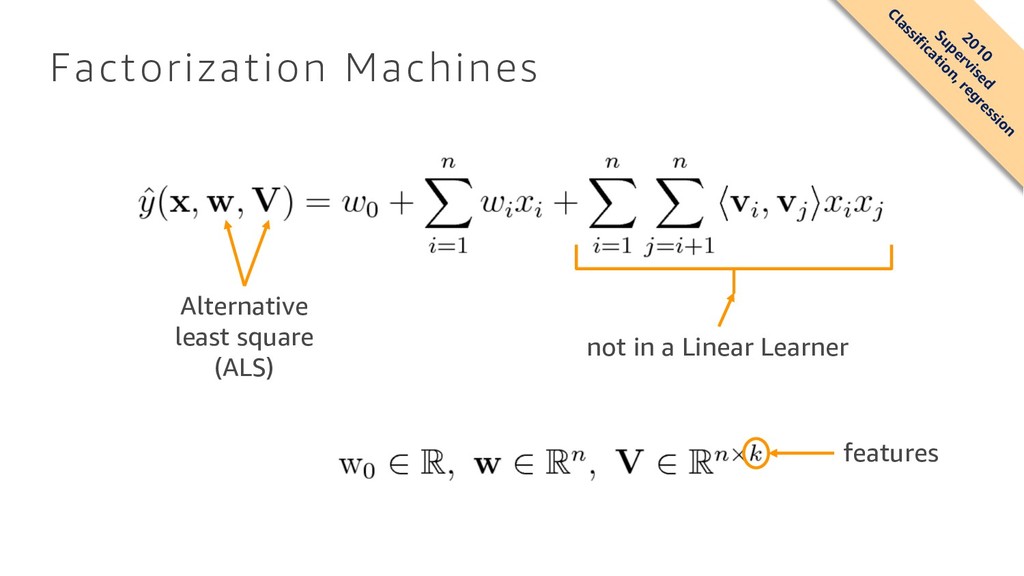
model that is designed to parsimoniously capture interactions between features within high dimensional sparse datasets • Factorization machines are a good choice for tasks such as click prediction and item recommendation • They are usually trained by stochastic gradient descent (SGD), alternative least square (ALS), or Markov chain Monte Carlo (MCMC) Factorization Machines Steffen Rendle Department of Reasoning for Intelligence The Institute of Scientific and Industrial Research Osaka University, Japan [email protected] Abstract—In this paper, we introduce Factorization Machines (FM) which are a new model class that combines the advantages of Support Vector Machines (SVM) with factorization models. Like SVMs, FMs are a general predictor working with any real valued feature vector. In contrast to SVMs, FMs model all interactions between variables using factorized parameters. Thus they are able to estimate interactions even in problems with huge sparsity (like recommender systems) where SVMs fail. We show that the model equation of FMs can be calculated in linear time and thus FMs can be optimized directly. So unlike nonlinear SVMs, a transformation in the dual form is not necessary and the model parameters can be estimated directly without the need of any support vector in the solution. We show the relationship to SVMs and the advantages of FMs for parameter estimation in sparse settings. On the other hand there are many different factorization mod- els like matrix factorization, parallel factor analysis or specialized models like SVD++, PITF or FPMC. The drawback of these models is that they are not applicable for general prediction tasks but work only with special input data. Furthermore their model equations and optimization algorithms are derived individually for each task. We show that FMs can mimic these models just by specifying the input data (i.e. the feature vectors). This makes FMs easily applicable even for users without expert knowledge in factorization models. Index Terms—factorization machine; sparse data; tensor fac- torization; support vector machine I. INTRODUCTION Support Vector Machines are one of the most popular predictors in machine learning and data mining. Nevertheless in settings like collaborative filtering, SVMs play no important role and the best models are either direct applications of standard matrix/ tensor factorization models like PARAFAC [1] or specialized models using factorized parameters [2], [3], [4]. In this paper, we show that the only reason why standard SVM predictors are not successful in these tasks is that they cannot learn reliable parameters (‘hyperplanes’) in complex (non-linear) kernel spaces under very sparse data. On the other hand, the drawback of tensor factorization models and even more for specialized factorization models is that (1) they are not applicable to standard prediction data (e.g. a real valued feature vector in Rn.) and (2) that specialized models are usually derived individually for a specific task requiring effort in modelling and design of a learning algorithm. In this paper, we introduce a new predictor, the Factor- ization Machine (FM), that is a general predictor like SVMs but is also able to estimate reliable parameters under very high sparsity. The factorization machine models all nested variable interactions (comparable to a polynomial kernel in SVM), but uses a factorized parametrization instead of a dense parametrization like in SVMs. We show that the model equation of FMs can be computed in linear time and that it depends only on a linear number of parameters. This allows direct optimization and storage of model parameters without the need of storing any training data (e.g. support vectors) for prediction. In contrast to this, non-linear SVMs are usually optimized in the dual form and computing a prediction (the model equation) depends on parts of the training data (the support vectors). We also show that FMs subsume many of the most successful approaches for the task of collaborative filtering including biased MF, SVD++ [2], PITF [3] and FPMC [4]. In total, the advantages of our proposed FM are: 1) FMs allow parameter estimation under very sparse data where SVMs fail. 2) FMs have linear complexity, can be optimized in the primal and do not rely on support vectors like SVMs. We show that FMs scale to large datasets like Netflix with 100 millions of training instances. 3) FMs are a general predictor that can work with any real valued feature vector. In contrast to this, other state-of- the-art factorization models work only on very restricted input data. We will show that just by defining the feature vectors of the input data, FMs can mimic state-of-the-art models like biased MF, SVD++, PITF or FPMC. II. PREDICTION UNDER SPARSITY The most common prediction task is to estimate a function y : Rn → T from a real valued feature vector x ∈ Rn to a target domain T (e.g. T = R for regression or T = {+, −} for classification). In supervised settings, it is assumed that there is a training dataset D = {(x(1), y(1)), (x(2), y(2)), . . .} of examples for the target function y given. We also investigate the ranking task where the function y with target T = R can be used to score feature vectors x and sort them according to their score. Scoring functions can be learned with pairwise training data [5], where a feature tuple (x(A), x(B)) ∈ D means that x(A) should be ranked higher than x(B). As the pairwise ranking relation is antisymmetric, it is sufficient to use only positive training instances. In this paper, we deal with problems where x is highly sparse, i.e. almost all of the elements xi of a vector x are zero. Let m(x) be the number of non-zero elements in the 2010 Supervised Classification, regression
4 horror Blade Runner 0.4 0.3 0.5 0.2 Notting Hill 0.2 0.8 0.1 0.01 Arrival 0.2 0.4 0.3 0.1 But you cannot really control how features are used! 2010 Supervised Classification, regression Intuitively, each “feature” describes a property of the “items”
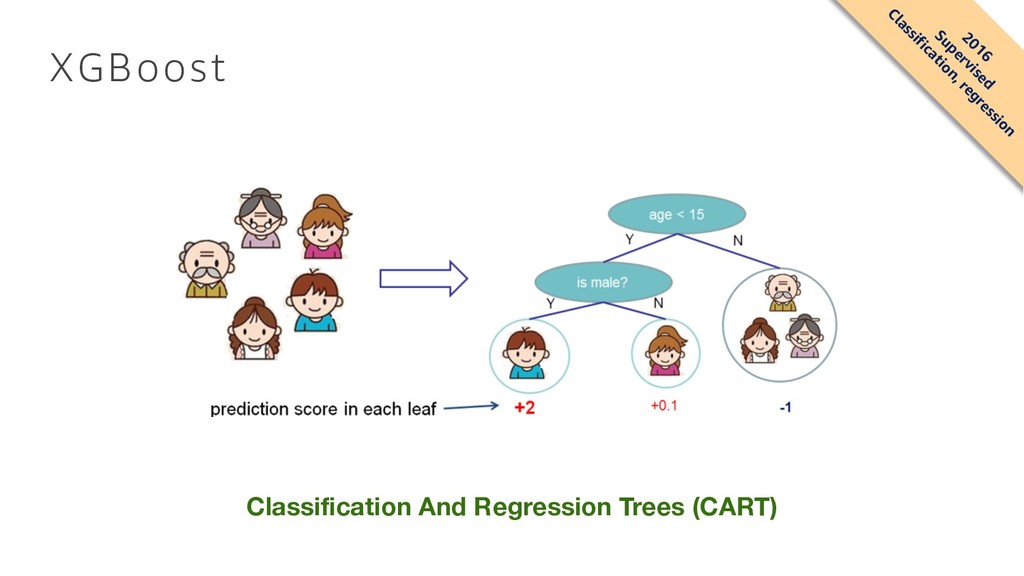
predictions • Boosting: “Can a set of weak learners create a single strong learner?” • Gradient Boosting: using gradient descent over a function space • eXtreme Gradient Boosting • https://github.com/dmlc/xgboost • Supports regression, classification, ranking and user defined objectives XGBoost: A Scalable Tree Boosting System Tianqi Chen University of Washington [email protected] Carlos Guestrin University of Washington [email protected] ABSTRACT Tree boosting is a highly e↵ective and widely used machine learning method. In this paper, we describe a scalable end- to-end tree boosting system called XGBoost, which is used widely by data scientists to achieve state-of-the-art results on many machine learning challenges. We propose a novel sparsity-aware algorithm for sparse data and weighted quan- tile sketch for approximate tree learning. More importantly, we provide insights on cache access patterns, data compres- sion and sharding to build a scalable tree boosting system. By combining these insights, XGBoost scales beyond billions of examples using far fewer resources than existing systems. Keywords Large-scale Machine Learning 1. INTRODUCTION Machine learning and data-driven approaches are becom- ing very important in many areas. Smart spam classifiers protect our email by learning from massive amounts of spam data and user feedback; advertising systems learn to match the right ads with the right context; fraud detection systems protect banks from malicious attackers; anomaly event de- tection systems help experimental physicists to find events that lead to new physics. There are two important factors that drive these successful applications: usage of e↵ective (statistical) models that capture the complex data depen- dencies and scalable learning systems that learn the model of interest from large datasets. Among the machine learning methods used in practice, gradient tree boosting [10]1 is one technique that shines in many applications. Tree boosting has been shown to give state-of-the-art results on many standard classification benchmarks [16]. LambdaMART [5], a variant of tree boost- ing for ranking, achieves state-of-the-art result for ranking 1Gradient tree boosting is also known as gradient boosting machine (GBM) or gradient boosted regression tree (GBRT) Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the owner/author(s). KDD ’16, August 13-17, 2016, San Francisco, CA, USA c 2016 Copyright held by the owner/author(s). ACM ISBN . DOI: problems. Besides being used as a stand-alone predictor, it is also incorporated into real-world production pipelines for ad click through rate prediction [15]. Finally, it is the de- facto choice of ensemble method and is used in challenges such as the Netflix prize [3]. In this paper, we describe XGBoost, a scalable machine learning system for tree boosting. The system is available as an open source package2. The impact of the system has been widely recognized in a number of machine learning and data mining challenges. Take the challenges hosted by the ma- chine learning competition site Kaggle for example. Among the 29 challenge winning solutions 3 published at Kaggle’s blog during 2015, 17 solutions used XGBoost. Among these solutions, eight solely used XGBoost to train the model, while most others combined XGBoost with neural nets in en- sembles. For comparison, the second most popular method, deep neural nets, was used in 11 solutions. The success of the system was also witnessed in KDDCup 2015, where XGBoost was used by every winning team in the top-10. Moreover, the winning teams reported that ensemble meth- ods outperform a well-configured XGBoost by only a small amount [1]. These results demonstrate that our system gives state-of- the-art results on a wide range of problems. Examples of the problems in these winning solutions include: store sales prediction; high energy physics event classification; web text classification; customer behavior prediction; motion detec- tion; ad click through rate prediction; malware classification; product categorization; hazard risk prediction; massive on- line course dropout rate prediction. While domain depen- dent data analysis and feature engineering play an important role in these solutions, the fact that XGBoost is the consen- sus choice of learner shows the impact and importance of our system and tree boosting. The most important factor behind the success of XGBoost is its scalability in all scenarios. The system runs more than ten times faster than existing popular solutions on a single machine and scales to billions of examples in distributed or memory-limited settings. The scalability of XGBoost is due to several important systems and algorithmic optimizations. These innovations include: a novel tree learning algorithm is for handling sparse data ; a theoretically justified weighted quantile sketch procedure enables handling instance weights in approximate tree learning. Parallel and distributed com- puting makes learning faster which enables quicker model ex- ploration. More importantly, XGBoost exploits out-of-core 2https://github.com/dmlc/xgboost 3Solutions come from of top-3 teams of each competitions. arXiv:1603.02754v3 [cs.LG] 10 Jun 2016 2016 Supervised Classification, regression
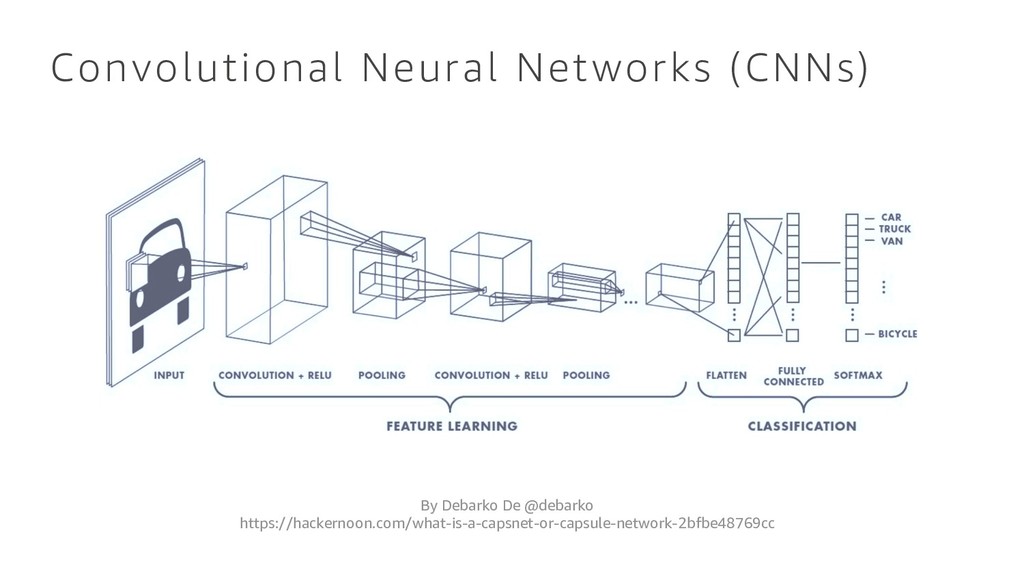
Xiangyu Zhang Shaoqing Ren Jian Sun Microsoft Research {kahe, v-xiangz, v-shren, jiansun}@microsoft.com Abstract Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learn- ing residual functions with reference to the layer inputs, in- stead of learning unreferenced functions. We provide com- prehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8⇥ deeper than VGG nets [41] but still having lower complex- ity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our ex- tremely deep representations, we obtain a 28% relative im- provement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions1, where we also won the 1st places on the tasks of ImageNet detection, ImageNet local- ization, COCO detection, and COCO segmentation. 1. Introduction Deep convolutional neural networks [22, 21] have led to a series of breakthroughs for image classification [21, 50, 40]. Deep networks naturally integrate low/mid/high- level features [50] and classifiers in an end-to-end multi- layer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth). Recent evidence [41, 44] reveals that network depth is of crucial importance, and the leading results [41, 44, 13, 16] on the challenging ImageNet dataset [36] all exploit “very deep” [41] models, with a depth of sixteen [41] to thirty [16]. Many other non- trivial visual recognition tasks [8, 12, 7, 32, 27] have also 1http://image-net.org/challenges/LSVRC/2015/ and http://mscoco.org/dataset/#detections-challenge2015. 0 1 2 3 4 5 6 0 10 20 iter. (1e4) training error (%) 0 1 2 3 4 5 6 0 10 20 iter. (1e4) test error (%) 56-layer 20-layer 56-layer 20-layer Figure 1. Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer “plain” networks. The deeper network has higher training error, and thus test error. Similar phenomena on ImageNet is presented in Fig. 4. greatly benefited from very deep models. Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initial- ization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start con- verging for stochastic gradient descent (SGD) with back- propagation [22]. When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher train- ing error, as reported in [11, 42] and thoroughly verified by our experiments. Fig. 1 shows a typical example. The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that 1 arXiv:1512.03385v1 [cs.CV] 10 Dec 2015 Densely Connected Convolutional Networks Gao Huang⇤ Cornell University [email protected] Zhuang Liu⇤ Tsinghua University [email protected] Laurens van der Maaten Facebook AI Research [email protected] Kilian Q. Weinberger Cornell University [email protected] Abstract Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observation and introduce the Dense Convo- lutional Network (DenseNet), which connects each layer to every other layer in a feed-forward fashion. Whereas traditional convolutional networks with L layers have L connections—one between each layer and its subsequent layer—our network has L(L+1) 2 direct connections. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers. DenseNets have several com- pelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage fea- ture reuse, and substantially reduce the number of parame- ters. We evaluate our proposed architecture on four highly competitive object recognition benchmark tasks (CIFAR-10, CIFAR-100, SVHN, and ImageNet). DenseNets obtain sig- nificant improvements over the state-of-the-art on most of them, whilst requiring less computation to achieve high per- formance. Code and pre-trained models are available at https://github.com/liuzhuang13/DenseNet . 1. Introduction Convolutional neural networks (CNNs) have become the dominant machine learning approach for visual object recognition. Although they were originally introduced over 20 years ago [18], improvements in computer hardware and network structure have enabled the training of truly deep CNNs only recently. The original LeNet5 [19] consisted of 5 layers, VGG featured 19 [29], and only last year Highway ⇤Authors contributed equally x0 x1 H1 x2 H2 H3 H4 x3 x4 Figure 1: A 5-layer dense block with a growth rate of k = 4. Each layer takes all preceding feature-maps as input. Networks [34] and Residual Networks (ResNets) [11] have surpassed the 100-layer barrier. As CNNs become increasingly deep, a new research problem emerges: as information about the input or gra- dient passes through many layers, it can vanish and “wash out” by the time it reaches the end (or beginning) of the network. Many recent publications address this or related problems. ResNets [11] and Highway Networks [34] by- pass signal from one layer to the next via identity connec- tions. Stochastic depth [13] shortens ResNets by randomly dropping layers during training to allow better information and gradient flow. FractalNets [17] repeatedly combine sev- eral parallel layer sequences with different number of con- volutional blocks to obtain a large nominal depth, while maintaining many short paths in the network. Although these different approaches vary in network topology and training procedure, they all share a key characteristic: they create short paths from early layers to later layers. 1 arXiv:1608.06993v5 [cs.CV] 28 Jan 2018 Inception Recurrent Convolutional Neural Network for Object Recognition Md Zahangir Alom [email protected] University of Dayton, Dayton, OH, USA Mahmudul Hasan [email protected] Comcast Labs, Washington, DC, USA Chris Yakopcic [email protected] University of Dayton, Dayton, OH, USA Tarek M. Taha [email protected] University of Dayton, Dayton, OH, USA Abstract Deep convolutional neural networks (DCNNs) are an influential tool for solving various prob- lems in the machine learning and computer vi- sion fields. In this paper, we introduce a new deep learning model called an Inception- Recurrent Convolutional Neural Network (IR- CNN), which utilizes the power of an incep- tion network combined with recurrent layers in DCNN architecture. We have empirically eval- uated the recognition performance of the pro- posed IRCNN model using different benchmark datasets such as MNIST, CIFAR-10, CIFAR- 100, and SVHN. Experimental results show sim- ilar or higher recognition accuracy when com- pared to most of the popular DCNNs including the RCNN. Furthermore, we have investigated IRCNN performance against equivalent Incep- tion Networks and Inception-Residual Networks using the CIFAR-100 dataset. We report about 3.5%, 3.47% and 2.54% improvement in classifi- cation accuracy when compared to the RCNN, equivalent Inception Networks, and Inception- Residual Networks on the augmented CIFAR- 100 dataset respectively. 1. Introduction In recent years, deep learning using Convolutional Neu- ral Networks (CNNs) has shown enormous success in the field of machine learning and computer vision. CNNs pro- vide state-of-the-art accuracy in various image recognition tasks including object recognition (Schmidhuber, 2015; Krizhevsky et al., 2012; Simonyan & Zisserman, 2014; Szegedy et al., 2015), object detection (Girshick et al., 2014), tracking (Wang et al., 2015), and image caption- ing (Xu et al., 2014). In addition, this technique has been applied massively in computer vision tasks such as video representation and classification of human activity (Bal- las et al., 2015). Machine translation and natural language processing are applied deep learning techniques that show great success in this domain (Collobert & Weston, 2008; Manning et al., 2014). Furthermore, this technique has been used extensively in the field of speech recognition (Hinton et al., 2012). Moreover, deep learning is not lim- ited to signal, natural language, image, and video process- ing tasks, it has been applying successfully for game devel- opment (Mnih et al., 2013; Lillicrap et al., 2015). There is a lot of ongoing research for developing even better perfor- mance and improving the training process of DCNNs (Lin et al., 2013; Springenberg et al., 2014; Goodfellow et al., 2013; Ioffe & Szegedy, 2015; Zeiler & Fergus, 2013). In some cases, machine intelligence shows better perfor- mance compared to human intelligence including calcula- tion, chess, memory, and pattern matching. On the other hand, human intelligence still provides better performance in other fields such as object recognition, scene under- standing, and more. Deep learning techniques (DCNNs in particular) perform very well in the domains of detec- tion, classification, and scene understanding. There is a still a gap that must be closed before human level intelli- gence is reached when performing visual recognition tasks. Machine intelligence may open an opportunity to build a system that can process visual information the way that a human brain does. According to the study on the visual processing system within a human brain by James DiCarlo et al. (Zoccolan & Rust, 2012) the brain consists of sev- eral visual processing units starting with the visual cortex arXiv:1704.07709v1 [cs.CV] 25 Apr 2017 2015-2017 Supervised Im age Classification
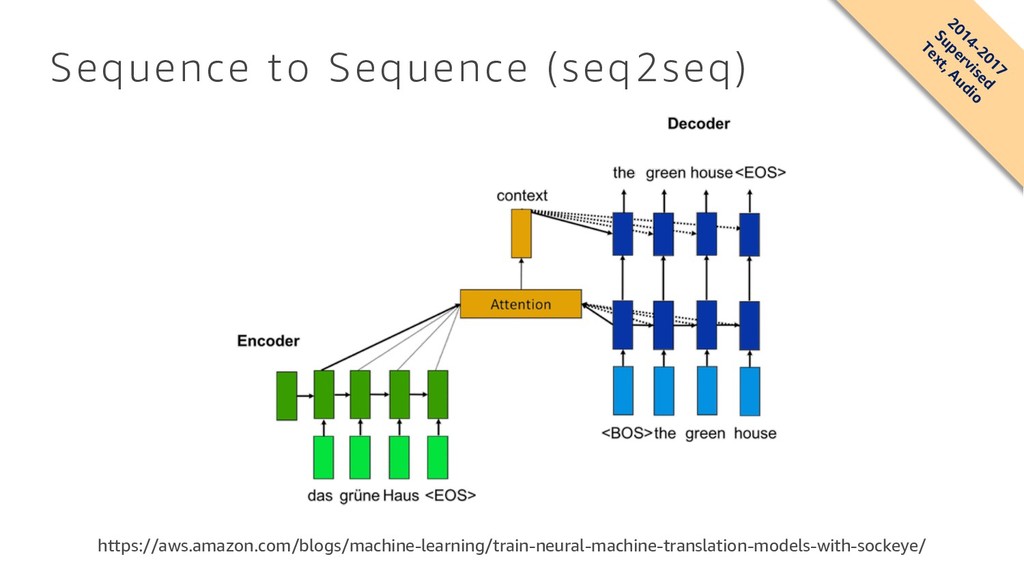
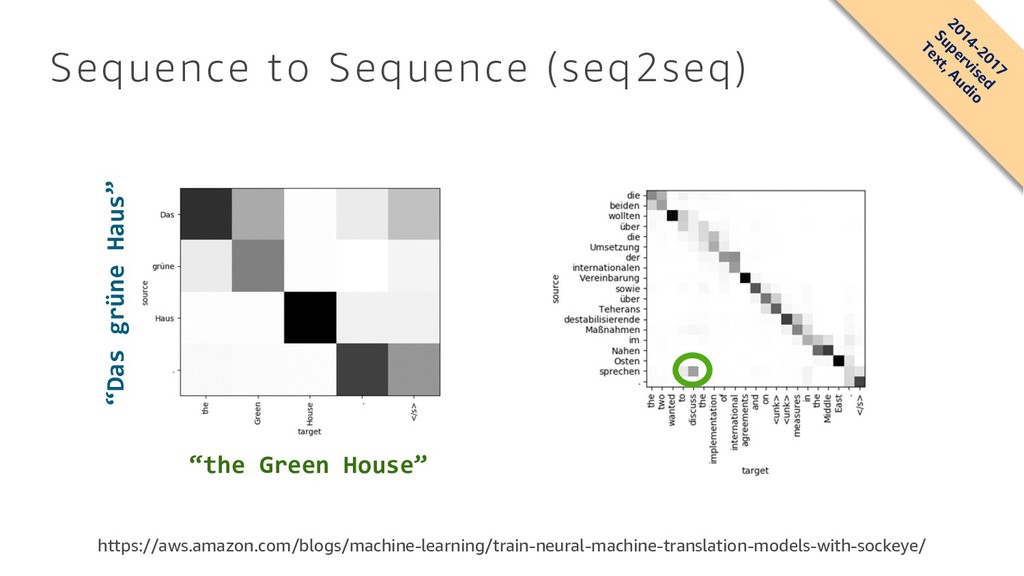
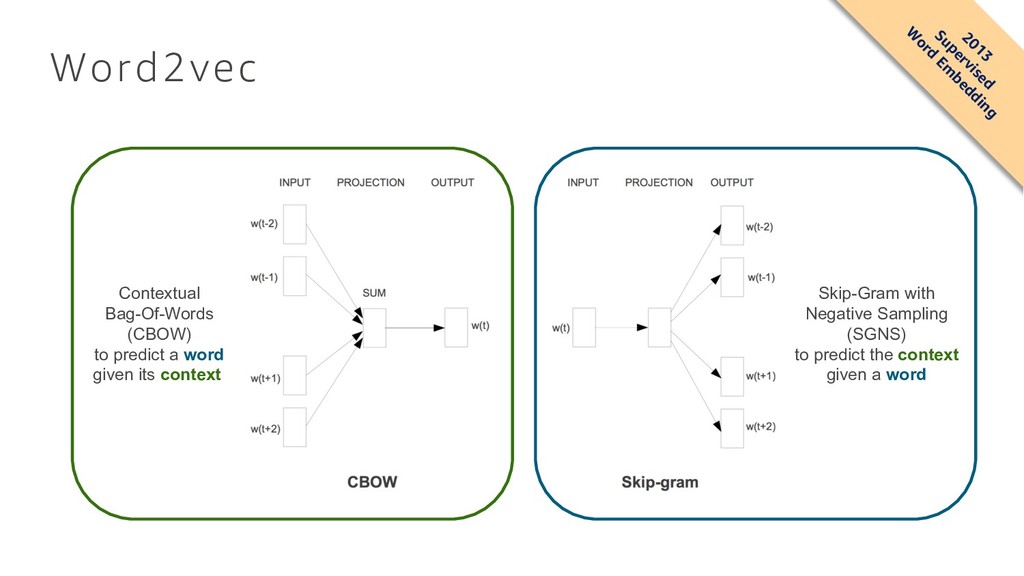
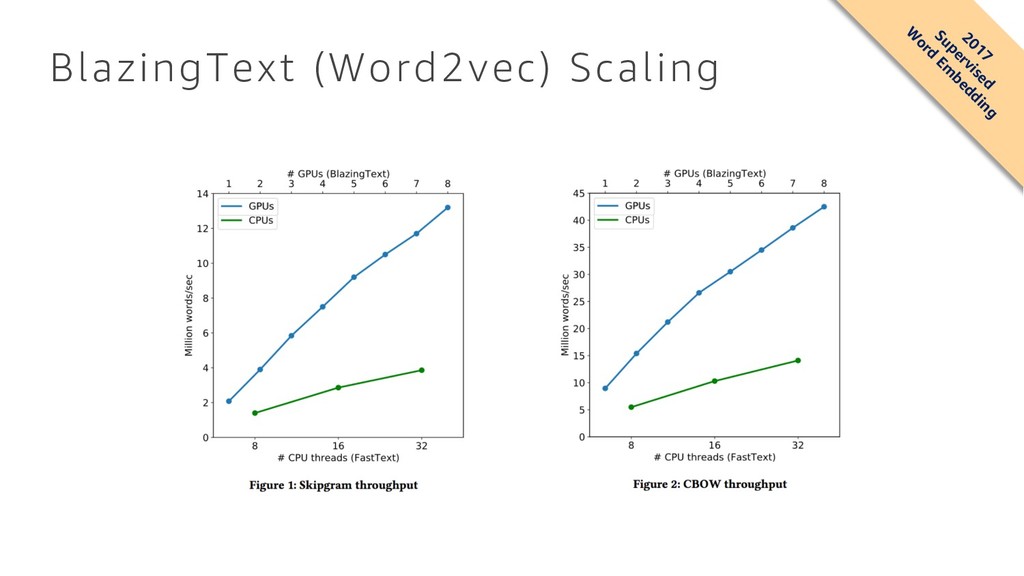
Domhan, Michael Denkowski, David Vilar, Artem Sokolov, Ann Clifton, Matt Post { fhieber , domhant , mdenkows , dvilar , artemsok , acclift , mattpost } @amazon.com Abstract We describe SOCKEYE,1 an open-source sequence-to-sequence toolkit for Neural Machine Translation (NMT). SOCKEYE is a production-ready framework for training and applying models as well as an experimental platform for researchers. Written in Python and built on MXNET, the toolkit offers scalable training and inference for the three most prominent encoder-decoder architectures: attentional recurrent neural networks, self-attentional transformers, and fully convolutional networks. SOCKEYE also supports a wide range of optimizers, normalization and regularization techniques, and inference improvements from current NMT literature. Users can easily run standard training recipes, explore different model settings, and incorporate new ideas. In this paper, we highlight SOCKEYE’s features and bench- mark it against other NMT toolkits on two language arcs from the 2017 Conference on Machine Translation (WMT): English–German and Latvian–English. We report competitive BLEU scores across all three architectures, including an overall best score for SOCKEYE’s transformer implementation. To facilitate further comparison, we release all system outputs and training scripts used in our experiments. The SOCKEYE toolkit is free software released under the Apache 2.0 license. 1 Introduction The past two years have seen a deep learning revolution bring rapid and dramatic change to the field of machine translation. For users, new neural network-based models consistently deliver better quality translations than the previous generation of phrase-based systems. For researchers, Neural Machine Translation (NMT) provides an exciting new landscape where training pipelines are simplified and unified models can be trained directly from data. The promise of moving beyond the limitations of Statistical Machine Translation (SMT) has energized the community, leading recent work to focus almost exclusively on NMT and seemingly advance the state of the art every few months. For all its success, NMT also presents a range of new challenges. While popular encoder-decoder models are attractively simple, recent literature and the results of shared evaluation tasks show that a significant amount of engineering is required to achieve “production-ready” performance in both translation quality and computational efficiency. In a trend that carries over from SMT, the strongest NMT systems benefit from subtle architecture modifications, hyper-parameter tuning, and empirically effective heuristics. Unlike SMT, there is no “de-facto” toolkit that attracts most of the community’s attention and thus contains all the best ideas from recent literature.2 Instead, the presence of many independent toolkits3 brings diversity to the field, but also makes it difficult to compare architectural and algorithmic improvements that are each implemented in different toolkits. 1 https://github.com/awslabs/sockeye (version 1.12) 2For SMT, this role was largely filled by MOSES [Koehn et al., 2007]. 3 https://github.com/jonsafari/nmt-list arXiv:1712.05690v1 [cs.CL] 15 Dec 2017 Sequence to Sequence (seq2seq) • seq2seq is a supervised learning algorithm where the input is a sequence of tokens (for example, text, audio) and the output generated is another sequence of tokens. • Example applications include: • machine translation (input a sentence from one language and predict what that sentence would be in another language) • text summarization (input a longer string of words and predict a shorter string of words that is a summary) • speech-to-text (audio clips converted into output sentences in tokens).
Domhan, Michael Denkowski, David Vilar, Artem Sokolov, Ann Clifton, Matt Post { fhieber , domhant , mdenkows , dvilar , artemsok , acclift , mattpost } @amazon.com Abstract We describe SOCKEYE,1 an open-source sequence-to-sequence toolkit for Neural Machine Translation (NMT). SOCKEYE is a production-ready framework for training and applying models as well as an experimental platform for researchers. Written in Python and built on MXNET, the toolkit offers scalable training and inference for the three most prominent encoder-decoder architectures: attentional recurrent neural networks, self-attentional transformers, and fully convolutional networks. SOCKEYE also supports a wide range of optimizers, normalization and regularization techniques, and inference improvements from current NMT literature. Users can easily run standard training recipes, explore different model settings, and incorporate new ideas. In this paper, we highlight SOCKEYE’s features and bench- mark it against other NMT toolkits on two language arcs from the 2017 Conference on Machine Translation (WMT): English–German and Latvian–English. We report competitive BLEU scores across all three architectures, including an overall best score for SOCKEYE’s transformer implementation. To facilitate further comparison, we release all system outputs and training scripts used in our experiments. The SOCKEYE toolkit is free software released under the Apache 2.0 license. 1 Introduction The past two years have seen a deep learning revolution bring rapid and dramatic change to the field of machine translation. For users, new neural network-based models consistently deliver better quality translations than the previous generation of phrase-based systems. For researchers, Neural Machine Translation (NMT) provides an exciting new landscape where training pipelines are simplified and unified models can be trained directly from data. The promise of moving beyond the limitations of Statistical Machine Translation (SMT) has energized the community, leading recent work to focus almost exclusively on NMT and seemingly advance the state of the art every few months. For all its success, NMT also presents a range of new challenges. While popular encoder-decoder models are attractively simple, recent literature and the results of shared evaluation tasks show that a significant amount of engineering is required to achieve “production-ready” performance in both translation quality and computational efficiency. In a trend that carries over from SMT, the strongest NMT systems benefit from subtle architecture modifications, hyper-parameter tuning, and empirically effective heuristics. Unlike SMT, there is no “de-facto” toolkit that attracts most of the community’s attention and thus contains all the best ideas from recent literature.2 Instead, the presence of many independent toolkits3 brings diversity to the field, but also makes it difficult to compare architectural and algorithmic improvements that are each implemented in different toolkits. 1 https://github.com/awslabs/sockeye (version 1.12) 2For SMT, this role was largely filled by MOSES [Koehn et al., 2007]. 3 https://github.com/jonsafari/nmt-list arXiv:1712.05690v1 [cs.CL] 15 Dec 2017 Sequence to Sequence (seq2seq) • Recently, problems in this domain have been successfully modeled with deep neural networks that show a significant performance boost over previous methodologies. • Amazon released in open source the Sockeye package, which uses Recurrent Neural Networks (RNNs) and Convolutional Neural Network (CNN) models with attention as encoder-decoder architectures. • https://github.com/awslabs/sockeye 2014-2017 Supervised Text, Audio
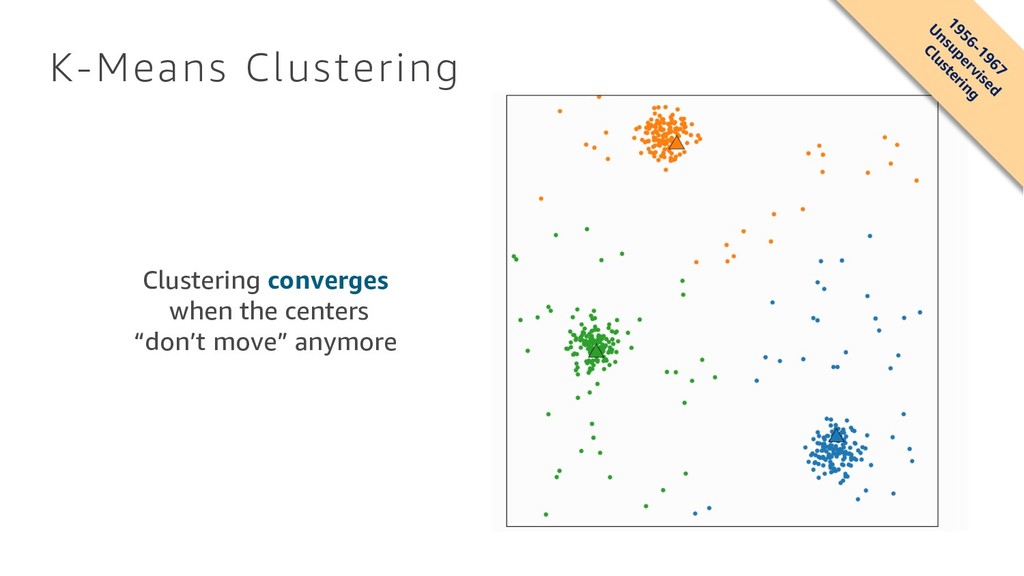
OBSERVATIONS J. MACQUEEN UNIVERSITY OF CALIFORNIA, Los ANGELES 1. Introduction The main purpose of this paper is to describe a process for partitioning an N-dimensional population into k sets on the basis of a sample. The process, which is called 'k-means,' appears to give partitions which are reasonably efficient in the sense of within-class variance. That is, if p is the probability mass function for the population, S = {S1, S2, - * *, Sk} is a partition of EN, and ui, i = 1, 2, * - , k, is the conditional mean of p over the set Si, then W2(S) = ff=ISi f z - u42 dp(z) tends to be low for the partitions S generated by the method. We say 'tends to be low,' primarily because of intuitive considerations, corroborated to some extent by mathematical analysis and practical computa- tional experience. Also, the k-means procedure is easily programmed and is computationally economical, so that it is feasible to process very large samples on a digital computer. Possible applications include methods for similarity grouping, nonlinear prediction, approximating multivariate distributions, and nonparametric tests for independence among several variables. In addition to suggesting practical classification methods, the study of k-means has proved to be theoretically interesting. The k-means concept represents a generalization of the ordinary sample mean, and one is naturally led to study the pertinent asymptotic behavior, the object being to establish some sort of law of large numbers for the k-means. This problem is sufficiently interesting, in fact, for us to devote a good portion of this paper to it. The k-means are defined in section 2.1, and the main results which have been obtained on the asymptotic behavior are given there. The rest of section 2 is devoted to the proofs of these results. Section 3 describes several specific possible applications, and reports some preliminary results from computer experiments conducted to explore the possibilities inherent in the k-means idea. The extension to general metric spaces is indicated briefly in section 4. The original point of departure for the work described here was a series of problems in optimal classification (MacQueen [9]) which represented special This work was supported by the Western Management Science Institute under a grant from the Ford Foundation, and by the Office of Naval Research under Contract No. 233(75), Task No. 047-041. 281 Bulletin de l’acad´ emie polonaise des sciences Cl. III — Vol. IV, No. 12, 1956 MATH´ EMATIQUE Sur la division des corps mat´ eriels en parties 1 par H. STEINHAUS Pr´ esent´ e le 19 Octobre 1956 Un corps Q est, par d´ efinition, une r´ epartition de mati` ere dans l’espace, donn´ ee par une fonction f ( P ) ; on appelle cette fonction la densit´ e du corps en question ; elle est d´ efinie pour tous les points P de l’espace ; elle est non- n´ egative et mesurable. On suppose que l’ensemble caract´ eristique du corps E =E P { f ( P ) > 0} est born´ e et de mesure positive ; on suppose aussi que l’int´ egrale de f ( P ) sur E est finie : c’est la masse du corps Q . On consid` ere comme identiques deux corps dont les densit´ es sont ´ egales ` a un ensemble de mesure nulle pr` es. En d´ ecomposant l’ensemble caract´ eristique d’un corps Q en n sous-ensembles Ei ( i = 1 , 2 , . . . , n ) de mesures positives, on obtient une division du corps en question en n corps partiels ; leurs ensembles caract´ eristiques respectifs sont les Ei et leurs densit´ es sont d´ efinies par les valeurs que prend la densit´ e du corps Q dans ces ensembles partiels. En d´ esignant les corps partiels par Qi , on ´ ecrira Q = Q1 + Q2 + . . . + Qn . Quand on donne d’abord n corps Qi , dont les ensembles caract´ eristiques sont disjoints deux ` a deux ` a la mesure nulle pr` es, il existe ´ evidemment un corps Q ayant ces Qi comme autant de parties ; on ´ ecrira Q1 + Q2 + . . . + Qn = Q . Ces remarques su sent pour expliquer la division et la composition des corps. Le probl` eme de cette Note est la division d’un corps en n parties Ki ( i = 1 , 2 , . . . , n ) et le choix de n points Ai de mani` ere ` a rendre aussi petite que possible la somme (1) S ( K, A ) = n X i=1 I ( Ki, Ai ) ( K ⌘ { Ki } , A ⌘ { Ai }) , o` u I ( Q, P ) d´ esigne, en g´ en´ eral, le moment d’inertie d’un corps quelconque Q par rapport ` a un point quelconque P . Pour traiter ce probl` eme ´ el´ ementaire nous aurons recours aux lemmes suivants : 1. Cet article de Hugo Steinhaus est le premier formulant de mani` ere explicite, en dimen- sion finie, le probl` eme de partitionnement par les k-moyennes (k-means), dites aussi “nu´ ees dynamiques”. Son algorithme classique est le mˆ eme que celui de la quantification optimale de Lloyd-Max. ´ Etant di cilement accessible sous format num´ erique, le voici transduit par Maciej Denkowski, transmis par J´ erˆ ome Bolte, transcrit par Laurent Duval, en juillet/aoˆ ut 2015. Un e↵ort a ´ et´ e fourni pour conserver une proximit´ e avec la pagination originale. 801 1956-1967 U nsupervised Clustering
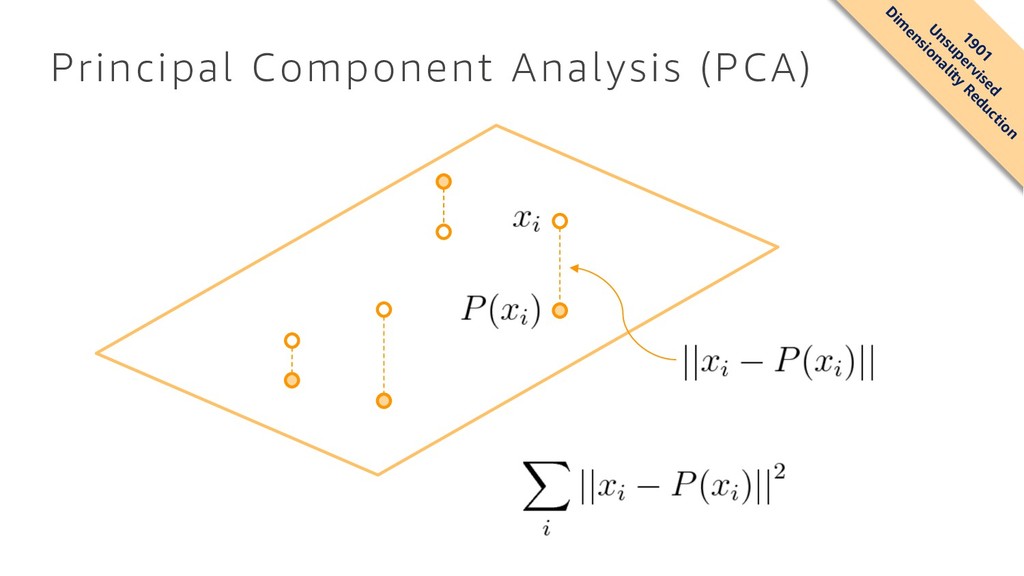
algorithm that attempts to reduce the dimensionality (number of features) within a dataset while still retaining as much information as possible • This is done by finding a new set of features called components, which are composites of the original features that are uncorrelated with one another • They are also constrained so that the first component accounts for the largest possible variability in the data, the second component the second most variability, and so on Pearson, K. 1901. On lines and planes of closest fit to systems of points in space. Philosophical Magazine 2:559-572. http://pbil.univ-lyon1.fr/R/pearson1901.pdf 1901 U nsupervised D im ensionality Reduction
Society of America Inference of Population Structure Using Multilocus Genotype Data Jonathan K. Pritchard, Matthew Stephens and Peter Donnelly Department of Statistics, University of Oxford, Oxford OX1 3TG, United Kingdom Manuscript received September 23, 1999 Accepted for publication February 18, 2000 ABSTRACT We describe a model-based clustering method for using multilocus genotype data to infer population structure and assign individuals to populations. We assume a model in which there are K populations (where K may be unknown), each of which is characterized by a set of allele frequencies at each locus. Individuals in the sample are assigned (probabilistically) to populations, or jointly to two or more popula- tions if their genotypes indicate that they are admixed. Our model does not assume a particular mutation process, and it can be applied to most of the commonly used genetic markers, provided that they are not closely linked. Applications of our method include demonstrating the presence of population structure, assigning individuals to populations, studying hybrid zones, and identifying migrants and admixed individu- als. We showthat the method can produce highlyaccurate assignments using modest numbers of loci—e.g., seven microsatellite loci in an example using genotype data from an endangered bird species. The software used for this article is available from http:// www.stats.ox.ac.uk/ zpritch/ home.html. IN applications of population genetics, it is often use- populationsbased on these subjective criteria represents a natural assignment in genetic terms, and it would be ful to classify individuals in a sample into popula- tions. In one scenario, the investigator begins with a useful to be able to confirm that subjective classifications are consistent with genetic information and hence ap- sample of individuals and wants to say something about the properties of populations. For example, in studies propriate for studying the questions of interest. Further, there are situations where one is interested in “cryptic” of human evolution, the population is often considered to be the unit of interest, and a great deal of work has population structure—i.e., population structure that is difficult to detect using visible characters, but may be focused on learning about the evolutionary relation- ships of modern populations (e.g., Caval l i et al. 1994). significant in genetic terms. For example, when associa- tion mapping is used to find disease genes, the presence In a second scenario, the investigator begins with a set of predefined populations and wishes to classifyindivid- of undetected population structure can lead to spurious associations and thus invalidate standard tests (Ewens uals of unknown origin. This type of problem arises in many contexts (reviewed by Davies et al. 1999). A and Spiel man 1995). The problem of cryptic population structure also arises in the context of DNA fingerprint- standard approach involves sampling DNA from mem- bers of a number of potential source populations and ing for forensics, where it is important to assess the degree of population structure to estimate the probabil- using these samples to estimate allele frequencies in ity of false matches (Bal ding and Nich ol s 1994, 1995; each population at a series of unlinked loci. Using the For eman et al. 1997; Roeder et al. 1998). estimated allele frequencies, it is then possible to com- Pr it ch ar d and Rosenber g (1999) considered how pute the likelihood that a given genotype originated in genetic information might be used to detect the pres- each population. Individuals of unknown origin can be ence of cryptic population structure in the association assigned to populations according to these likelihoods mapping context. More generally, one would like to be Paet kau et al. 1995; Rannal a and Mount ain 1997). able to identify the actual subpopulations and assign In both situations described above, a crucial first step individuals (probabilistically) to these populations. In is to define a set of populations. The definition of popu- this article we use a Bayesian clustering approach to lations is typically subjective, based, for example, on tackle this problem. We assume a model in which there linguistic, cultural, or physical characters, as well as the are K populations (where K may be unknown), each of geographic location of sampled individuals. This subjec- which is characterized by a set of allele frequencies at tive approach is usually a sensible way of incorporating each locus. Our method attempts to assign individuals diverse types of information. However, it maybe difficult to populations on the basis of their genotypes, while to know whether a given assignment of individuals to simultaneously estimating population allele frequen- cies. The method can be applied to various types of markers [e.g., microsatellites, restriction fragment Corresponding author: Jonathan Pritchard, Department of Statistics, length polymorphisms (RFLPs), or single nucleotide University of Oxford, 1 S. Parks Rd., Oxford OX1 3TG, United King- dom. E-mail: [email protected] polymorphisms (SNPs)], but it assumes that the marker Genetics 155: 945–959 ( June 2000) Journal of Machine Learning Research 3 (2003) 993-1022 Submitted 2/02; Published 1/03 Latent Dirichlet Allocation David M. Blei [email protected] Computer Science Division University of California Berkeley, CA 94720, USA Andrew Y. Ng [email protected] Computer Science Department Stanford University Stanford, CA 94305, USA Michael I. Jordan [email protected] Computer Science Division and Department of Statistics University of California Berkeley, CA 94720, USA Editor: John Lafferty Abstract We describe latent Dirichlet allocation (LDA), a generative probabilistic model for collections of discrete data such as text corpora. LDA is a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics. Each topic is, in turn, modeled as an infinite mixture over an underlying set of topic probabilities. In the context of text modeling, the topic probabilities provide an explicit representation of a document. We present efficient approximate inference techniques based on variational methods and an EM algorithm for empirical Bayes parameter estimation. We report results in document modeling, text classification, and collaborative filtering, comparing to a mixture of unigrams model and the probabilistic LSI model. 1. Introduction In this paper we consider the problem of modeling text corpora and other collections of discrete data. The goal is to find short descriptions of the members of a collection that enable efficient processing of large collections while preserving the essential statistical relationships that are useful for basic tasks such as classification, novelty detection, summarization, and similarity and relevance judgments. Significant progress has been made on this problem by researchers in the field of informa- tion retrieval (IR) (Baeza-Yates and Ribeiro-Neto, 1999). The basic methodology proposed by IR researchers for text corpora—a methodology successfully deployed in modern Internet search engines—reduces each document in the corpus to a vector of real numbers, each of which repre- sents ratios of counts. In the popular tf-idf scheme (Salton and McGill, 1983), a basic vocabulary of “words” or “terms” is chosen, and, for each document in the corpus, a count is formed of the number of occurrences of each word. After suitable normalization, this term frequency count is compared to an inverse document frequency count, which measures the number of occurrences of a c 2003 David M. Blei, Andrew Y. Ng and Michael I. Jordan. 2000-2003 U nsupervised Topic M odeling
given a set of documents where the only words that occur within them are eat, sleep, play, meow, and bark, LDA might produce topics like the following: Topic eat sleep play meow bark Cats? Topic 1 0.1 0.3 0.2 0.4 0.0 Dogs? Topic 2 0.2 0.1 0.4 0.0 0.3 2000-2003 U nsupervised Topic M odeling
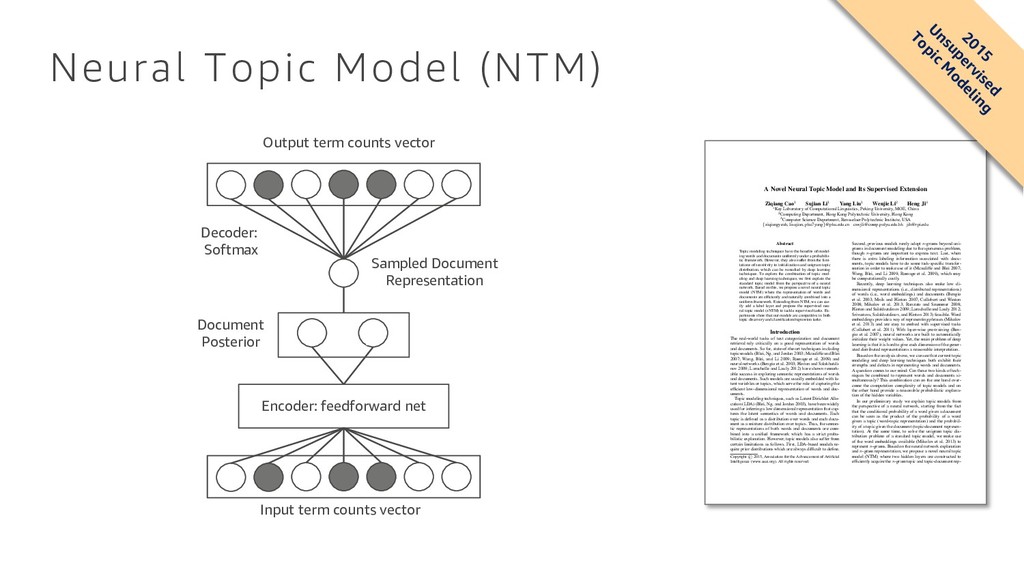
vector µ z Document Posterior Sampled Document Representation Decoder: Softmax Output term counts vector A Novel Neural Topic Model and Its Supervised Extension Ziqiang Cao1 Sujian Li1 Yang Liu1 Wenjie Li2 Heng Ji3 1Key Laboratory of Computational Linguistics, Peking University, MOE, China 2Computing Department, Hong Kong Polytechnic University, Hong Kong 3Computer Science Department, Rensselaer Polytechnic Institute, USA {ziqiangyeah, lisujian, pku7yang}@pku.edu.cn [email protected][email protected] Abstract Topic modeling techniques have the benefits of model- ing words and documents uniformly under a probabilis- tic framework. However, they also suffer from the limi- tations of sensitivity to initialization and unigram topic distribution, which can be remedied by deep learning techniques. To explore the combination of topic mod- eling and deep learning techniques, we first explain the standard topic model from the perspective of a neural network. Based on this, we propose a novel neural topic model (NTM) where the representation of words and documents are efficiently and naturally combined into a uniform framework. Extending from NTM, we can eas- ily add a label layer and propose the supervised neu- ral topic model (sNTM) to tackle supervised tasks. Ex- periments show that our models are competitive in both topic discovery and classification/regression tasks. Introduction The real-world tasks of text categorization and document retrieval rely critically on a good representation of words and documents. So far, state-of-the-art techniques including topic models (Blei, Ng, and Jordan 2003; Mcauliffe and Blei 2007; Wang, Blei, and Li 2009; Ramage et al. 2009) and neural networks (Bengio et al. 2003; Hinton and Salakhutdi- nov 2009; Larochelle and Lauly 2012) have shown remark- able success in exploring semantic representations of words and documents. Such models are usually embedded with la- tent variables or topics, which serve the role of capturing the efficient low-dimensional representation of words and doc- uments. Topic modeling techniques, such as Latent Dirichlet Allo- cation (LDA) (Blei, Ng, and Jordan 2003), have been widely used for inferring a low dimensional representation that cap- tures the latent semantics of words and documents. Each topic is defined as a distribution over words and each docu- ment as a mixture distribution over topics. Thus, the seman- tic representations of both words and documents are com- bined into a unified framework which has a strict proba- bilistic explanation. However, topic models also suffer from certain limitations as follows. First, LDA-based models re- quire prior distributions which are always difficult to define. Copyright c 2015, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved. Second, previous models rarely adopt n -grams beyond uni- grams in document modeling due to the sparseness problem, though n -grams are important to express text. Last, when there is extra labeling information associated with docu- ments, topic models have to do some task-specific transfor- mation in order to make use of it (Mcauliffe and Blei 2007; Wang, Blei, and Li 2009; Ramage et al. 2009), which may be computationally costly. Recently, deep learning techniques also make low di- mensional representations (i.e., distributed representations) of words (i.e., word embeddings) and documents (Bengio et al. 2003; Mnih and Hinton 2007; Collobert and Weston 2008; Mikolov et al. 2013; Ranzato and Szummer 2008; Hinton and Salakhutdinov 2009; Larochelle and Lauly 2012; Srivastava, Salakhutdinov, and Hinton 2013) feasible. Word embeddings provide a way of representing phrases (Mikolov et al. 2013) and are easy to embed with supervised tasks (Collobert et al. 2011). With layer-wise pre-training (Ben- gio et al. 2007), neural networks are built to automatically initialize their weight values. Yet, the main problem of deep learning is that it is hard to give each dimension of the gener- ated distributed representations a reasonable interpretation. Based on the analysis above, we can see that current topic modeling and deep learning techniques both exhibit their strengths and defects in representing words and documents. A question comes to our mind: Can these two kinds of tech- niques be combined to represent words and documents si- multaneously? This combination can on the one hand over- come the computation complexity of topic models and on the other hand provide a reasonable probabilistic explana- tion of the hidden variables. In our preliminary study we explain topic models from the perspective of a neural network, starting from the fact that the conditional probability of a word given a document can be seen as the product of the probability of a word given a topic (word-topic representation) and the probabil- ity of a topic given the document (topic-document represen- tation). At the same time, to solve the unigram topic dis- tribution problem of a standard topic model, we make use of the word embeddings available (Mikolov et al. 2013) to represent n -grams. Based on the neural network explanation and n -gram representation, we propose a novel neural topic model (NTM) where two hidden layers are constructed to efficiently acquire the n -gram topic and topic-document rep- 2015 U nsupervised Topic M odeling
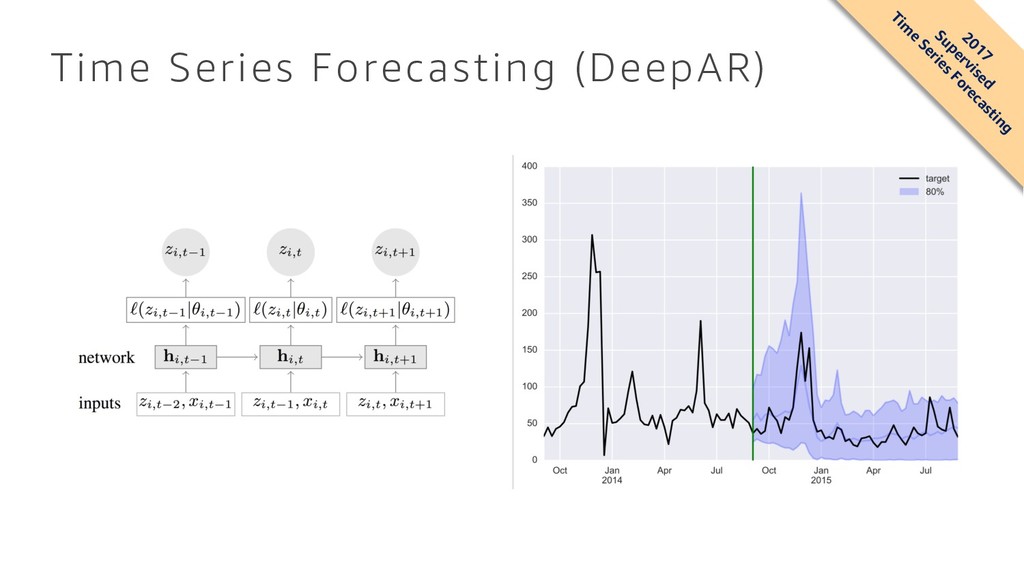
Networks Valentin Flunkert ⇤ , David Salinas ⇤ , Jan Gasthaus Amazon Development Center Germany <dsalina,flunkert,[email protected]> Abstract Probabilistic forecasting, i.e. estimating the probability distribution of a time se- ries’ future given its past, is a key enabler for optimizing business processes. In retail businesses, for example, forecasting demand is crucial for having the right inventory available at the right time at the right place. In this paper we propose DeepAR, a methodology for producing accurate probabilistic forecasts, based on training an auto-regressive recurrent network model on a large number of related time series. We demonstrate how by applying deep learning techniques to fore- casting, one can overcome many of the challenges faced by widely-used classical approaches to the problem. We show through extensive empirical evaluation on several real-world forecasting data sets that our methodology produces more accu- rate forecasts than other state-of-the-art methods, while requiring minimal manual work. 1 Introduction Forecasting plays a key role in automating and optimizing operational processes in most businesses and enables data driven decision making. In retail for example, probabilistic forecasts of product supply and demand can be used for optimal inventory management, staff scheduling and topology planning [17], and are more generally a crucial technology for most aspects of supply chain opti- mization. The prevalent forecasting methods in use today have been developed in the setting of forecasting individual or small groups of time series. In this approach, model parameters for each given time series are independently estimated from past observations. The model is typically manually selected to account for different factors, such as autocorrelation structure, trend, seasonality, and other ex- planatory variables. The fitted model is then used to forecast the time series into the future according to the model dynamics, possibly admitting probabilistic forecasts through simulation or closed-form expressions for the predictive distributions. Many methods in this class are based on the classical Box-Jenkins methodology [3], exponential smoothing techniques, or state space models [11, 18]. In recent years, a new type of forecasting problem has become increasingly important in many appli- cations. Instead of needing to predict individual or a small number of time series, one is faced with forecasting thousands or millions of related time series. Examples include forecasting the energy consumption of individual households, forecasting the load for servers in a data center, or forecast- ing the demand for all products that a large retailer offers. In all these scenarios, a substantial amount of data on past behavior of similar, related time series can be leveraged for making a forecast for an individual time series. Using data from related time series not only allows fitting more complex (and hence potentially more accurate) models without overfitting, it can also alleviate the time and labor intensive manual feature engineering and model selection steps required by classical techniques. ⇤equal contribution arXiv:1704.04110v2 [cs.AI] 5 Jul 2017 2017 Supervised Tim e Series Forecasting • DeepAR is a supervised learning algorithm for forecasting scalar time series using recurrent neural networks (RNN) • Classical forecasting methods fit one model to each individual time series, and then use that model to extrapolate the time series into the future • In many applications you might have many similar time series across a set of cross-sectional units • For example, demand for different products, load of servers, requests for web pages, and so on • In this case, it can be beneficial to train a single model jointly over all of these time series • DeepAR takes this approach, training a model for predicting a time series over a large set of (related) time series
160M events daily in the ML pipeline and run training over the last 15 days and need it to complete in one hour. Effectively there's 100M features in the model.” Valentino Volonghi, CTO “We process 3 million ad requests a second, 100,000 features per request. That’s 250 trillion per day. Not your run of the mill Data science problem!” Bill Simmons, CTO “Our data warehouse is 100TB and we are processing 2TB daily. We're running mostly gradient boosting (trees), LDA and K-Means clustering and collaborative filtering.“ Shahar Cizer Kobrinsky, VP Architecture
so that you can start processing your training dataset and developing your algorithms immediately • One-click, on-demand distributed training that sets up and tears down the cluster after training. • Built-in, high-performance ML algorithms, re-engineered for greater, speed, accuracy, and data-throughput Exploration Training Hosting
automatically adjust hundreds of different combinations of algorithm parameters • An elastic, secure, and scalable environment to host your models, with one-click deployment
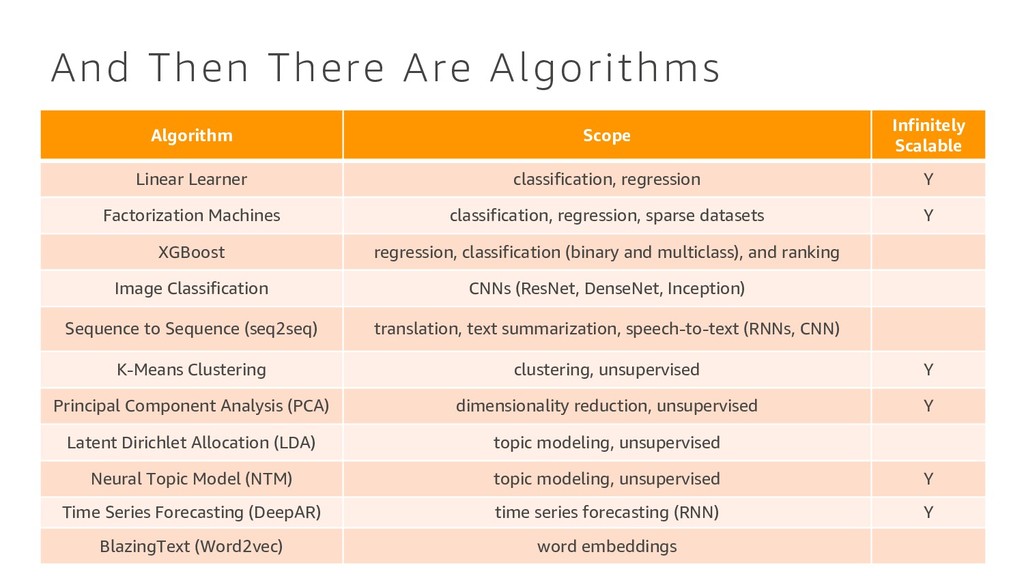
Learner classification, regression Y Factorization Machines classification, regression, sparse datasets Y XGBoost regression, classification (binary and multiclass), and ranking Image Classification CNNs (ResNet, DenseNet, Inception) Sequence to Sequence (seq2seq) translation, text summarization, speech-to-text (RNNs, CNN) K-Means Clustering clustering, unsupervised Y Principal Component Analysis (PCA) dimensionality reduction, unsupervised Y Latent Dirichlet Allocation (LDA) topic modeling, unsupervised Neural Topic Model (NTM) topic modeling, unsupervised Y Time Series Forecasting (DeepAR) time series forecasting (RNN) Y BlazingText (Word2vec) word embeddings
![And Then There Are Algorithms Danilo Poccia Evangelist, Serverless [email protected]](https://files.speakerdeck.com/presentations/432723bca4da4d879518144fc72bccea/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![And Then There Are Algorithms Danilo Poccia Evangelist, Serverless [email protected]](https://files.speakerdeck.com/presentations/432723bca4da4d879518144fc72bccea/slide_65.jpg){kind=link}