Original title in Spanish: Desambiguación de Palabras Polisémicas mediante Aprendizaje Semi-supervisado
Date: September 20, 2013
Venue: Córdoba, Argentina. 42nd JAIIO - Argentine Journals of Informatics and Operating Research (JAIIO '13)
Please cite, link to or credit this presentation when using it or part of it in your work.
#ML #MachineLearning #NLP #NaturalLanguageProcessing #SemiSupervisedLearning #WordSenseDisambiguation #WSD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[…] En este caso, la causa de los movimientos sísmicos](https://files.speakerdeck.com/presentations/f72865ecba574bf8b0b650e42a60158b/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
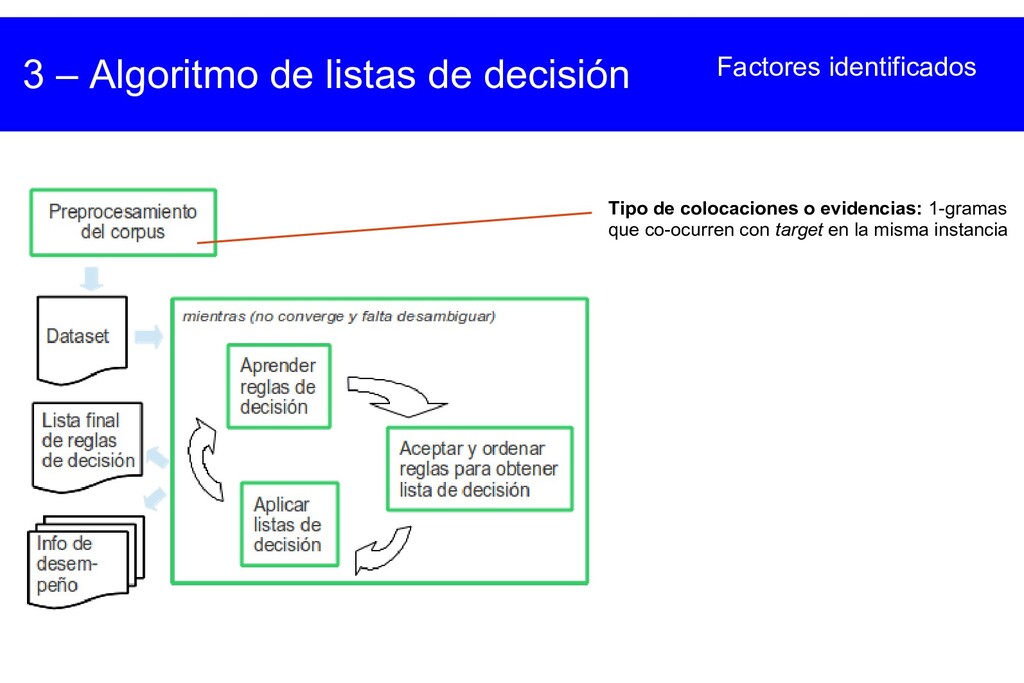{kind=link}
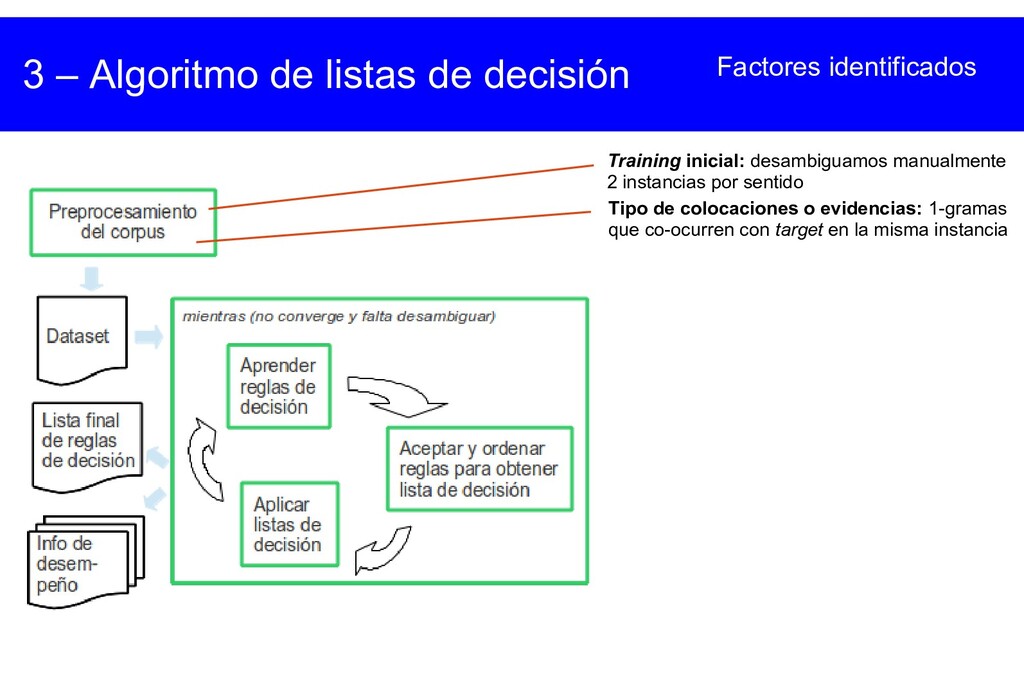{kind=link}
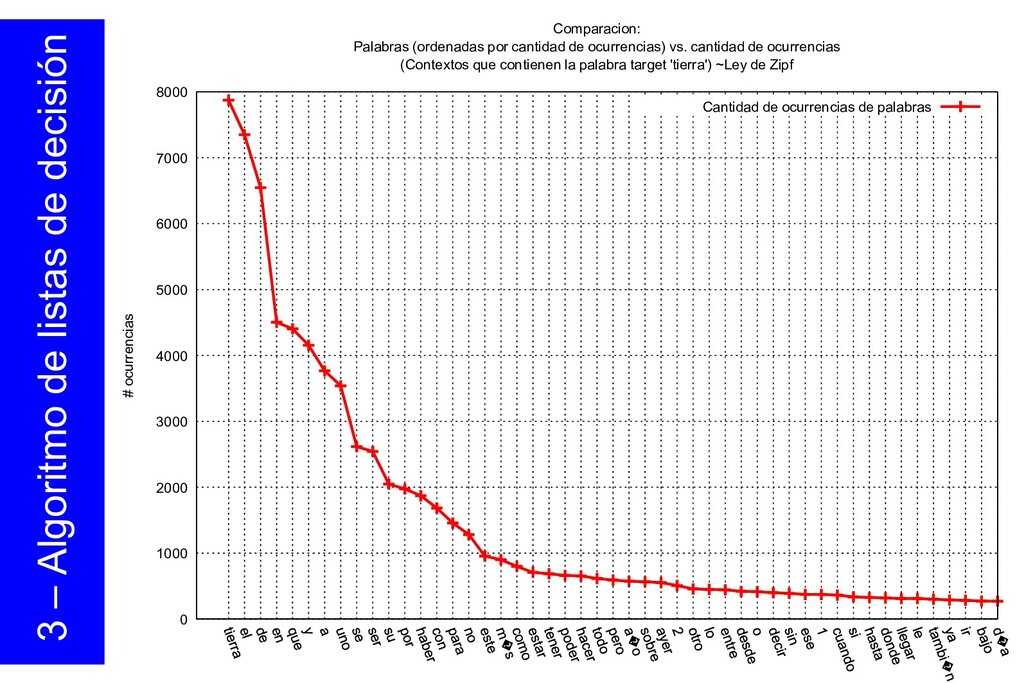{kind=link}
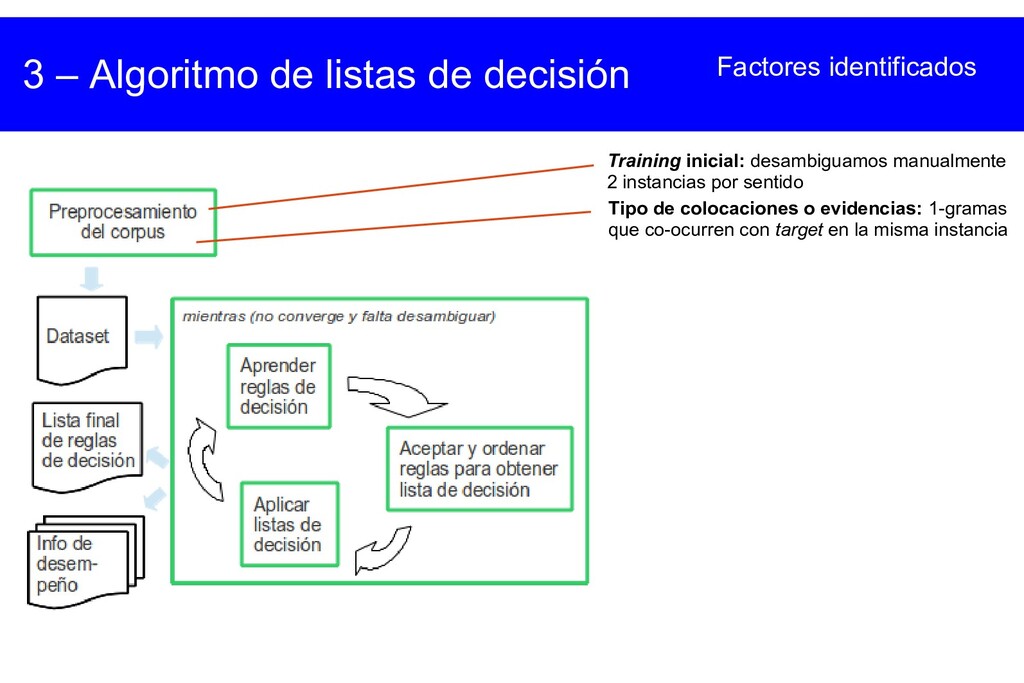{kind=link}
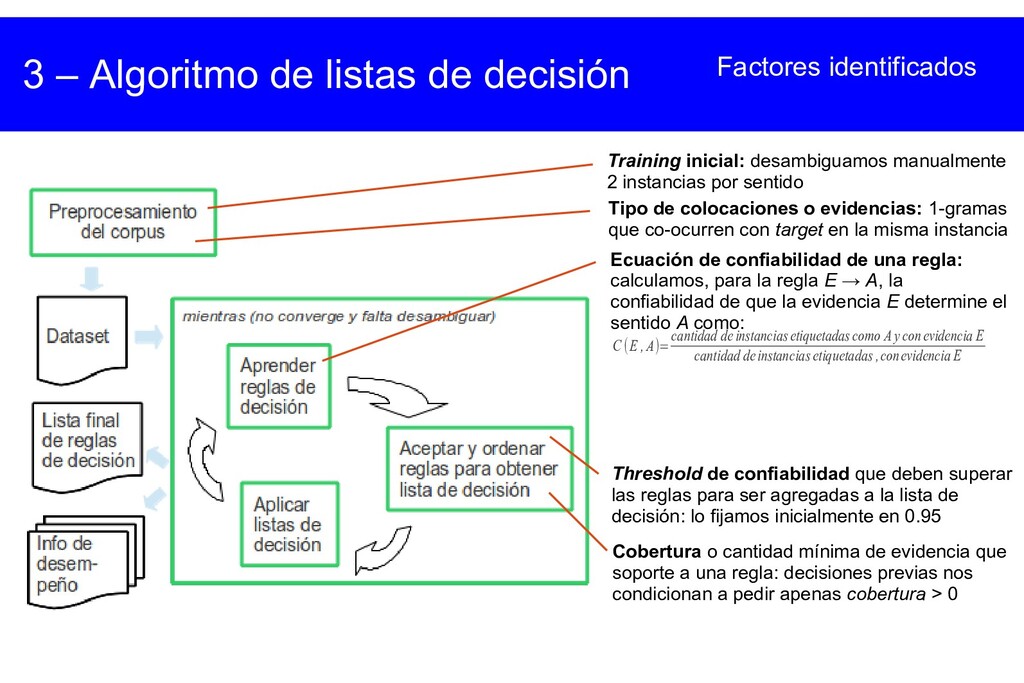{kind=link}
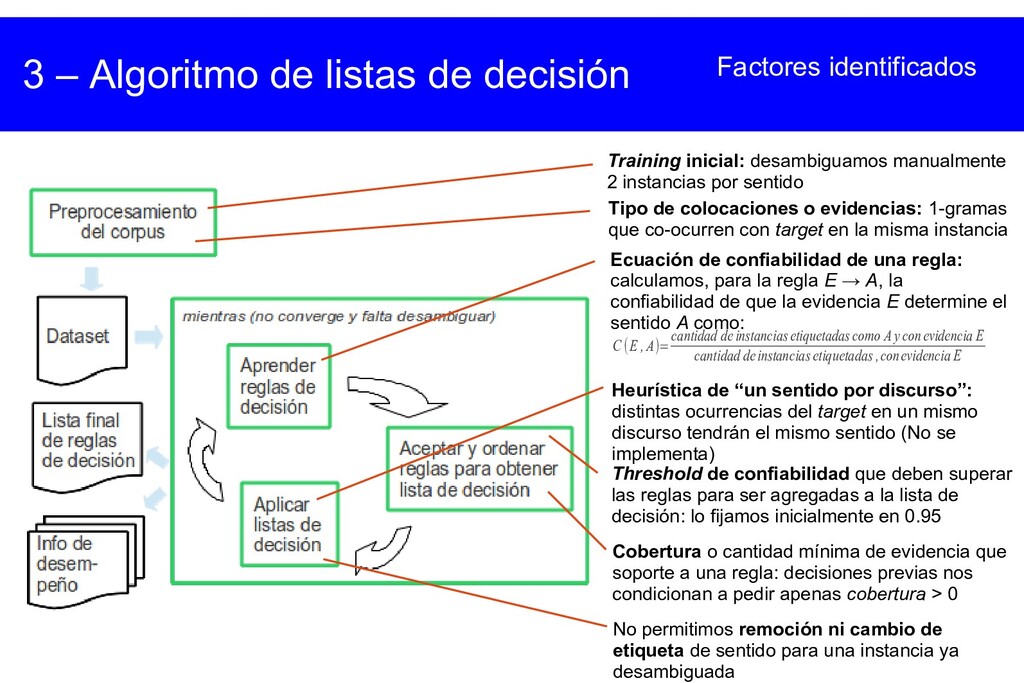{kind=link}
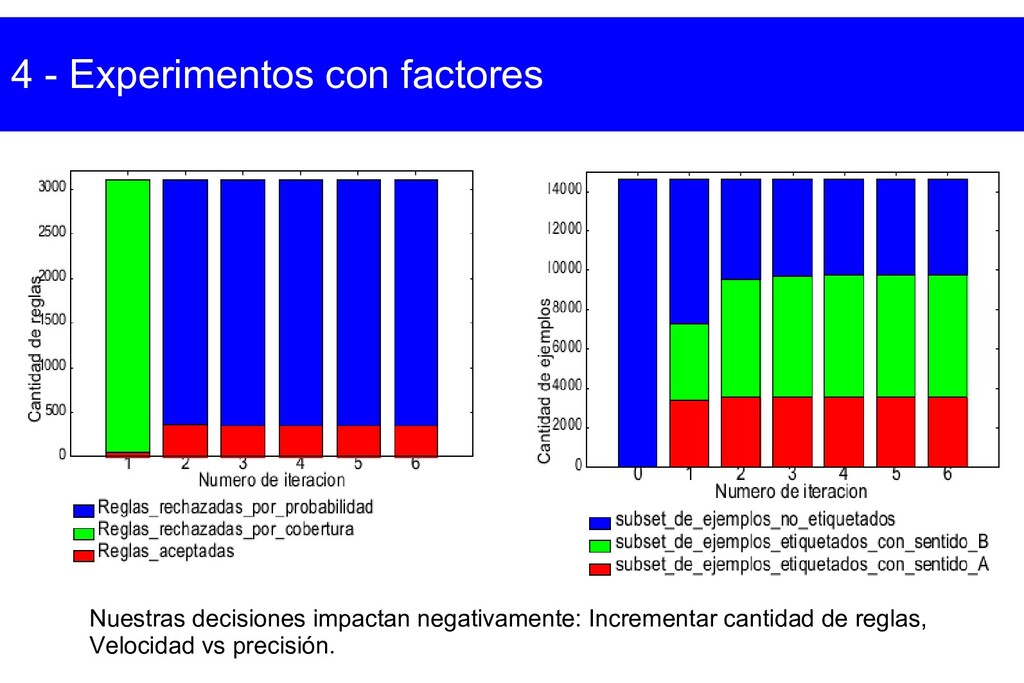{kind=link}
{kind=link}
{kind=link}
{kind=link}
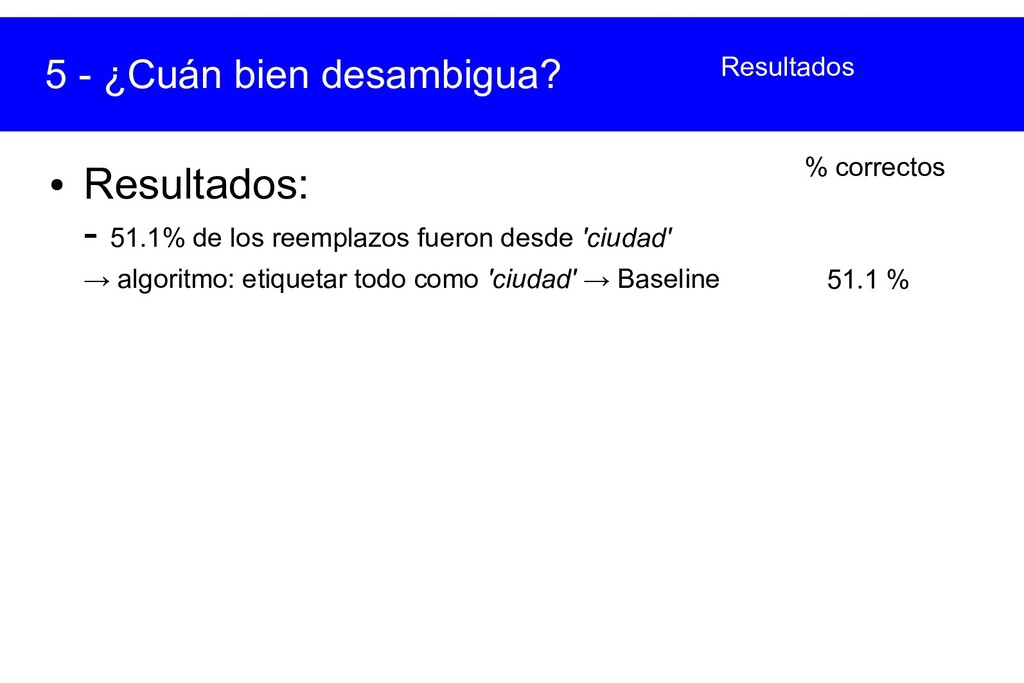{kind=link}
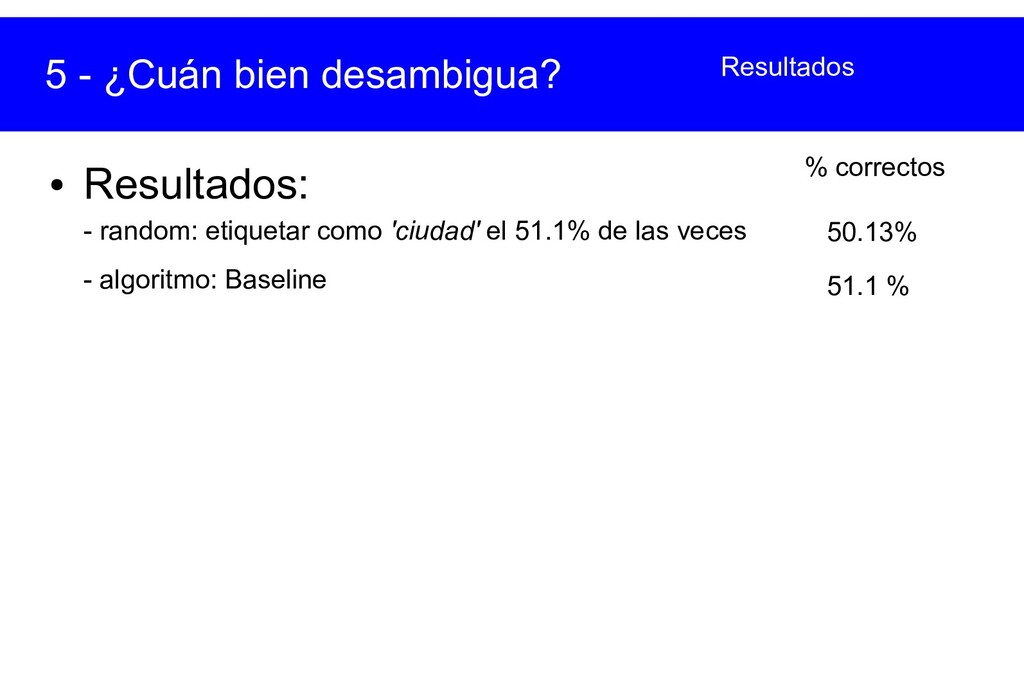{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}