I gave this talk at ConFESS 2013 (https://2013.con-fess.com/). This talk was not scheduled originally, but one talk got cancelled (about Lego Mindstorms programming with Java - that's why its mentioned in the Key slides) and I jumped in.
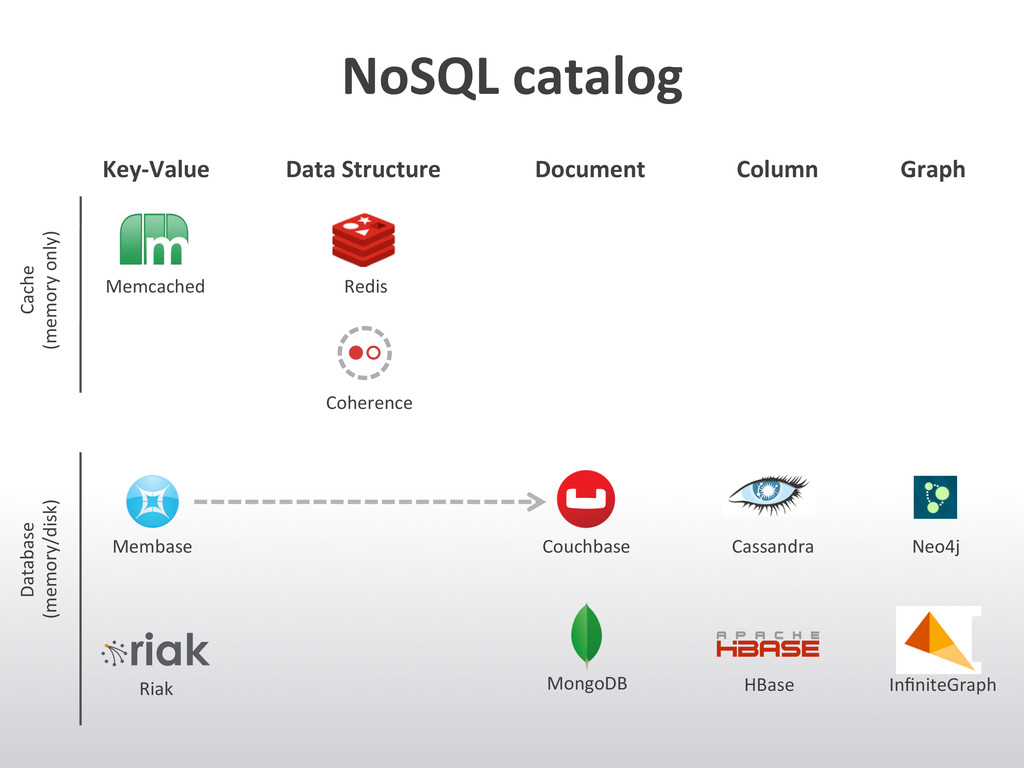
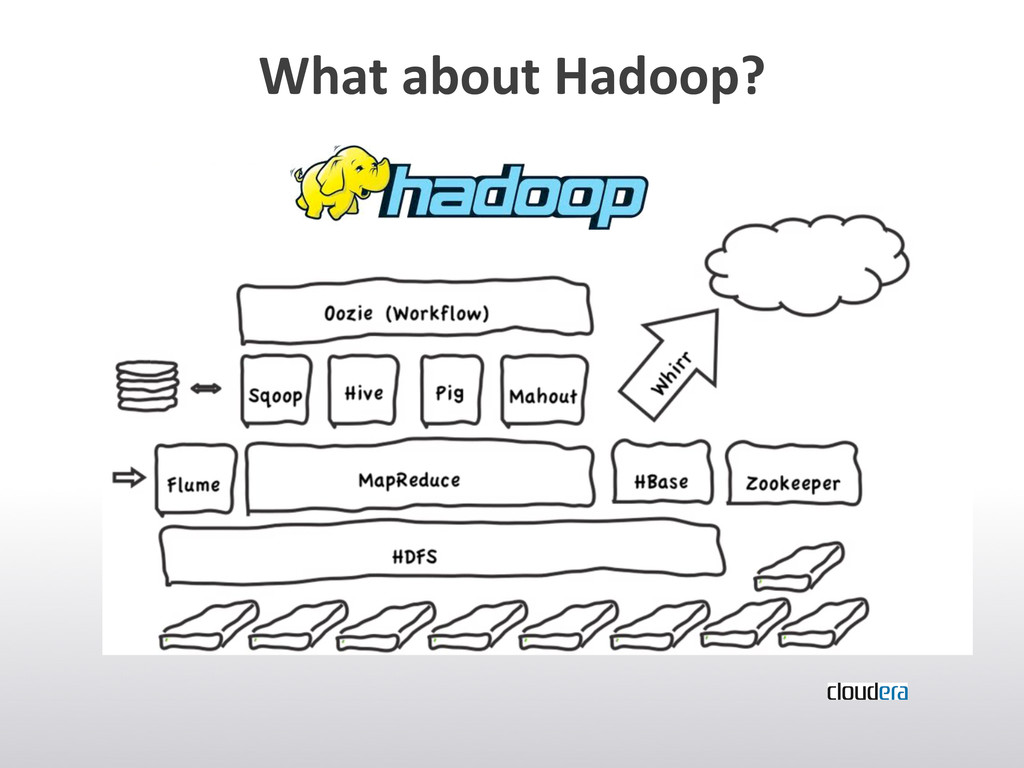
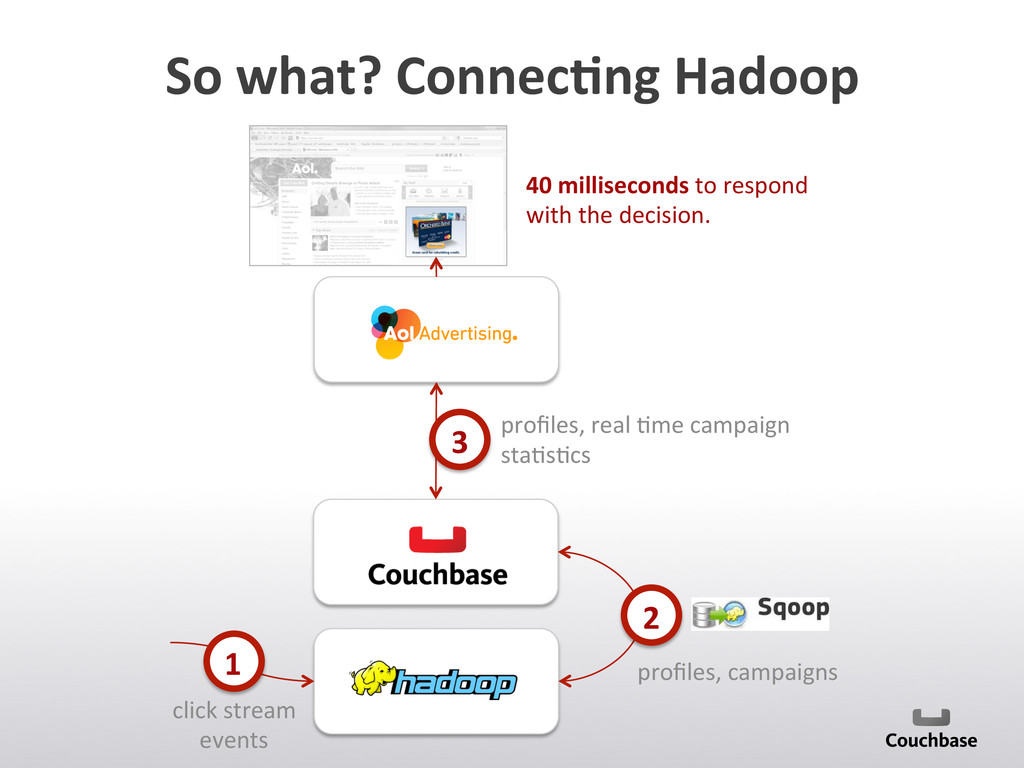
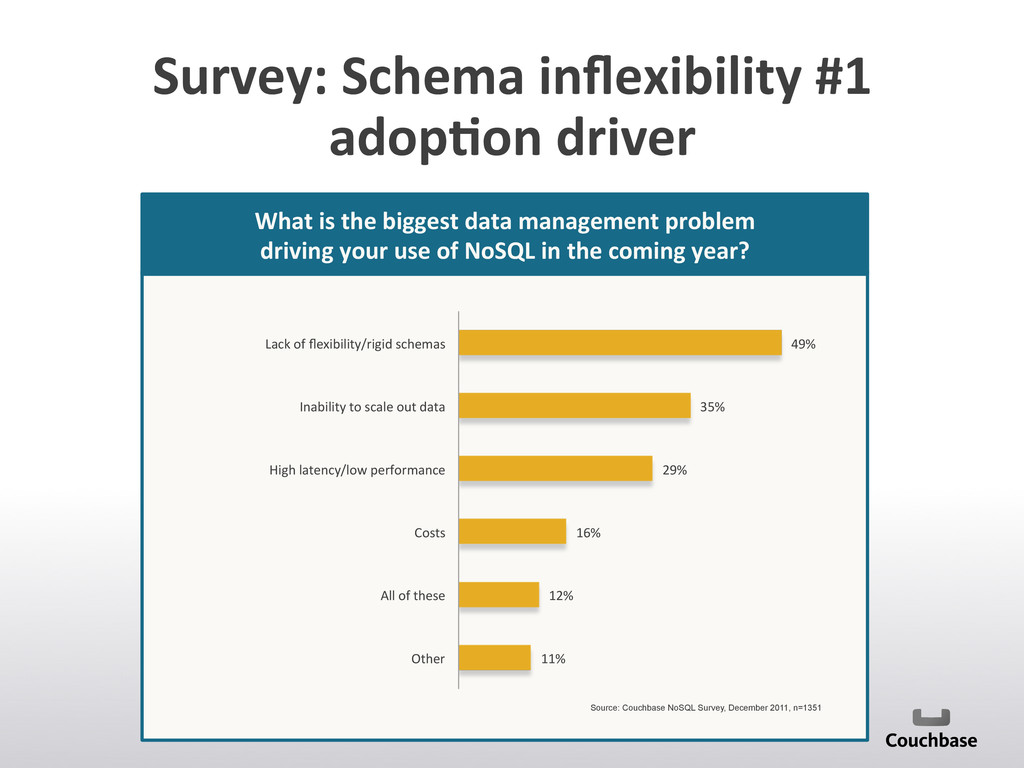
It's about a more or less large overview of the "current" NoSQL landscape and meant as a starting point where people can start their own investigations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
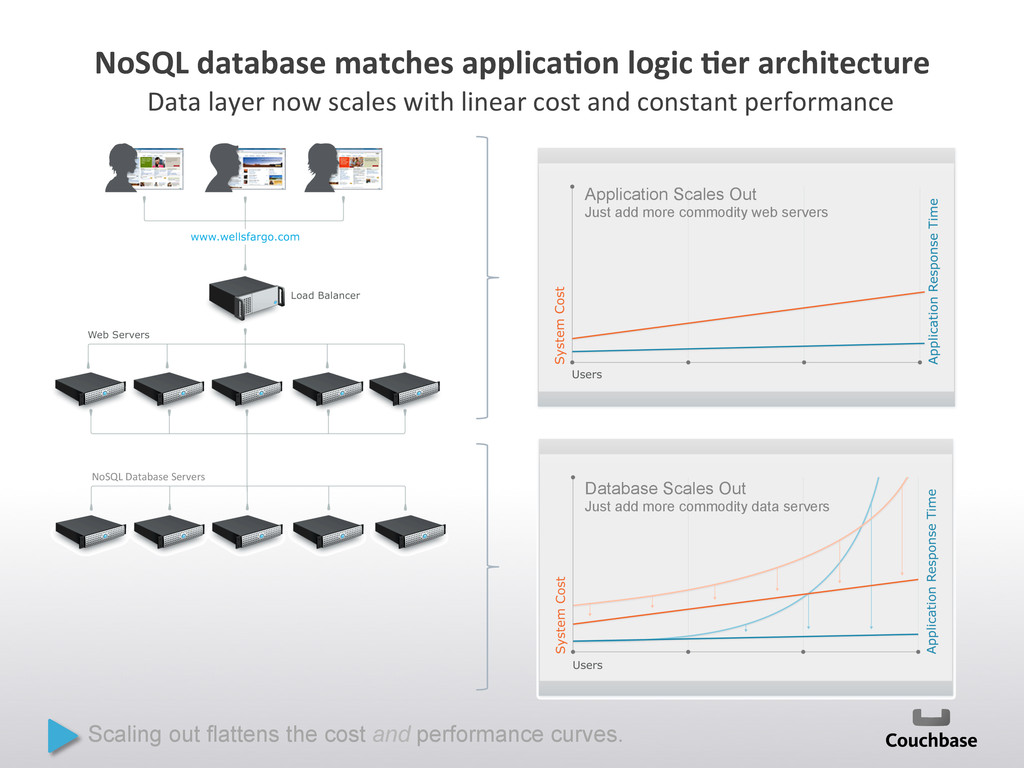{kind=link}
{kind=link}
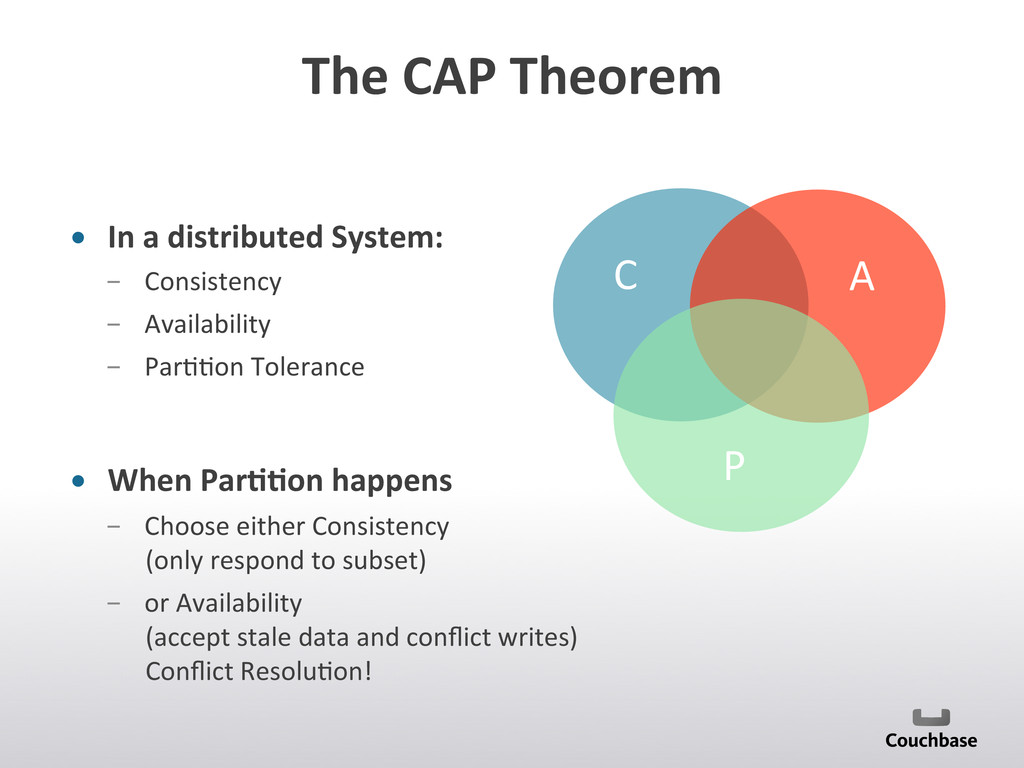{kind=link}
{kind=link}
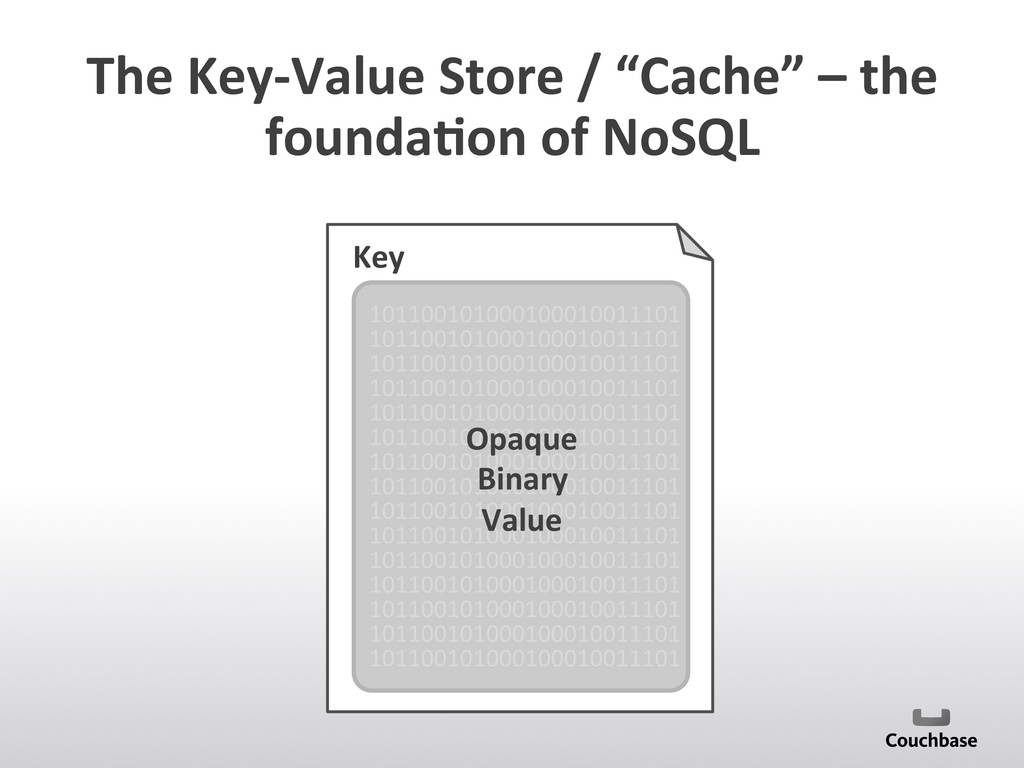{kind=link}
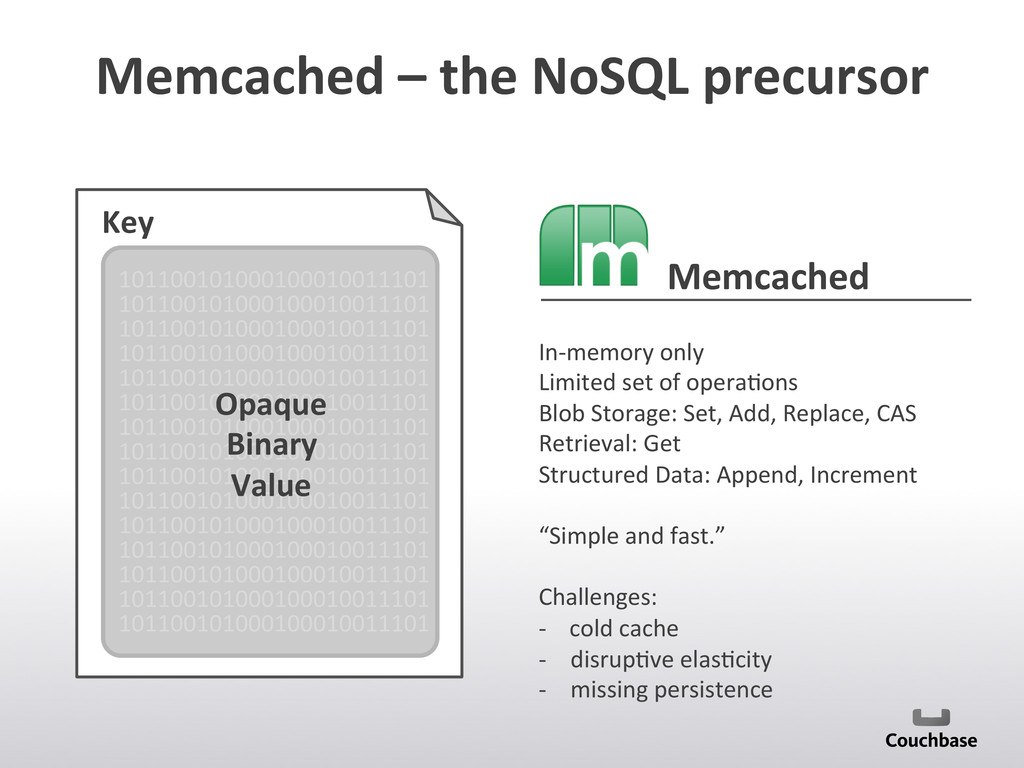{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
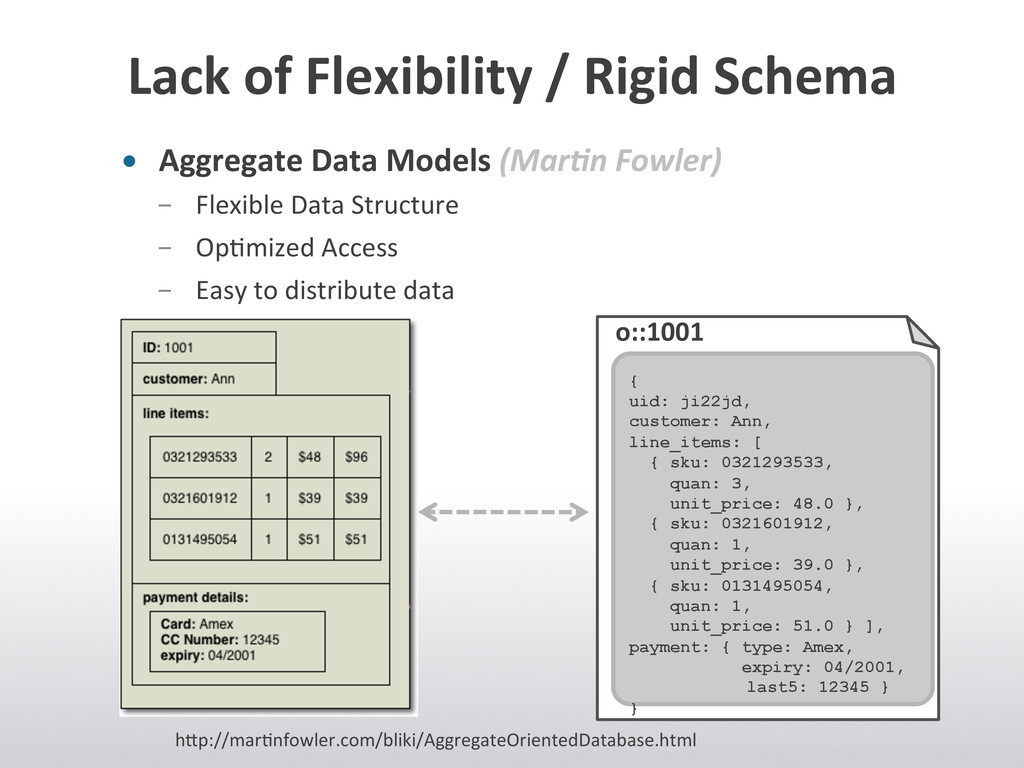{kind=link}
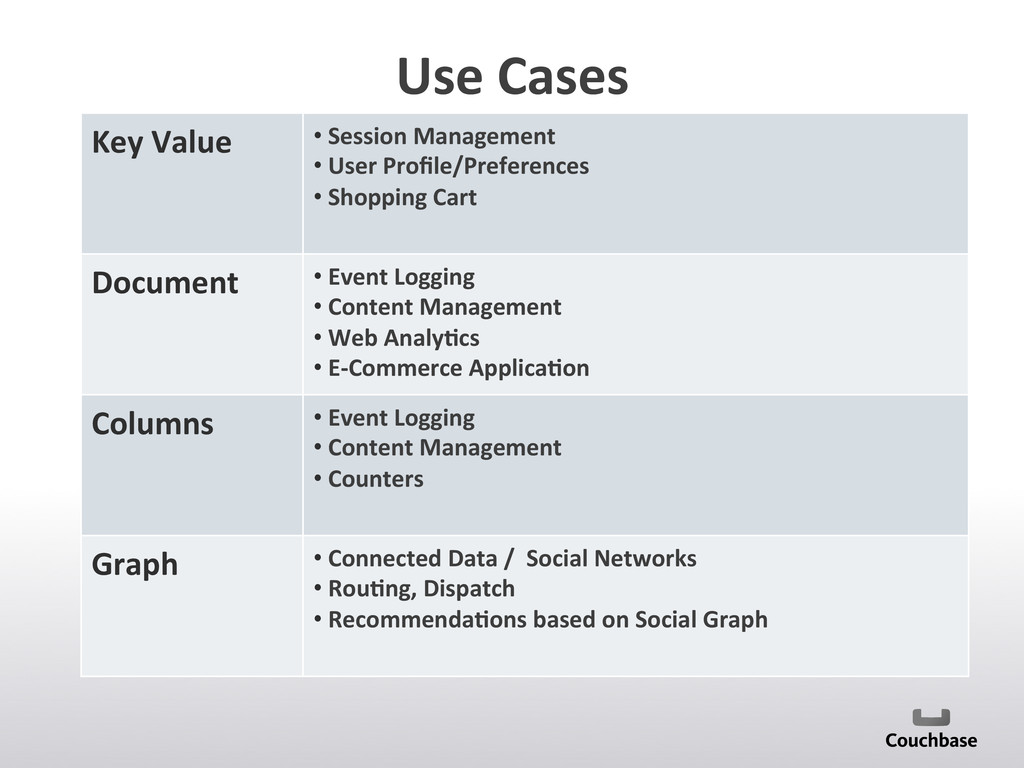{kind=link}
{kind=link}
{kind=link}
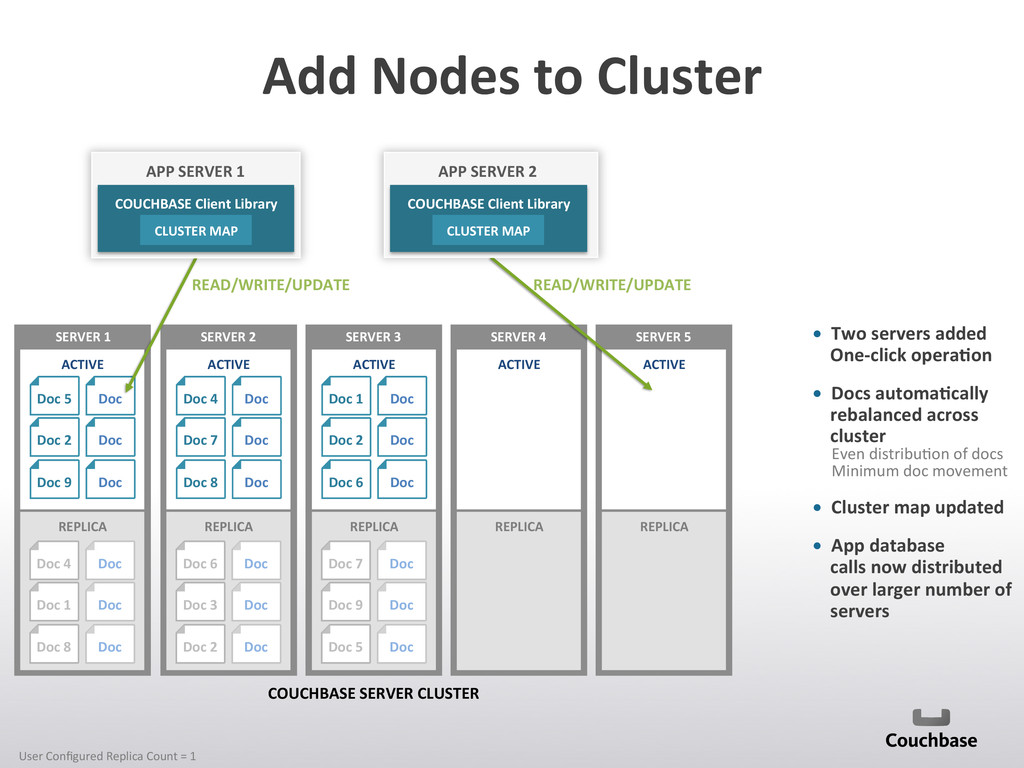{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected] @daschl Get Couchbase](https://files.speakerdeck.com/presentations/622ea3c07ffa01309fec12313933796a/slide_50.jpg){kind=link}
{kind=link}