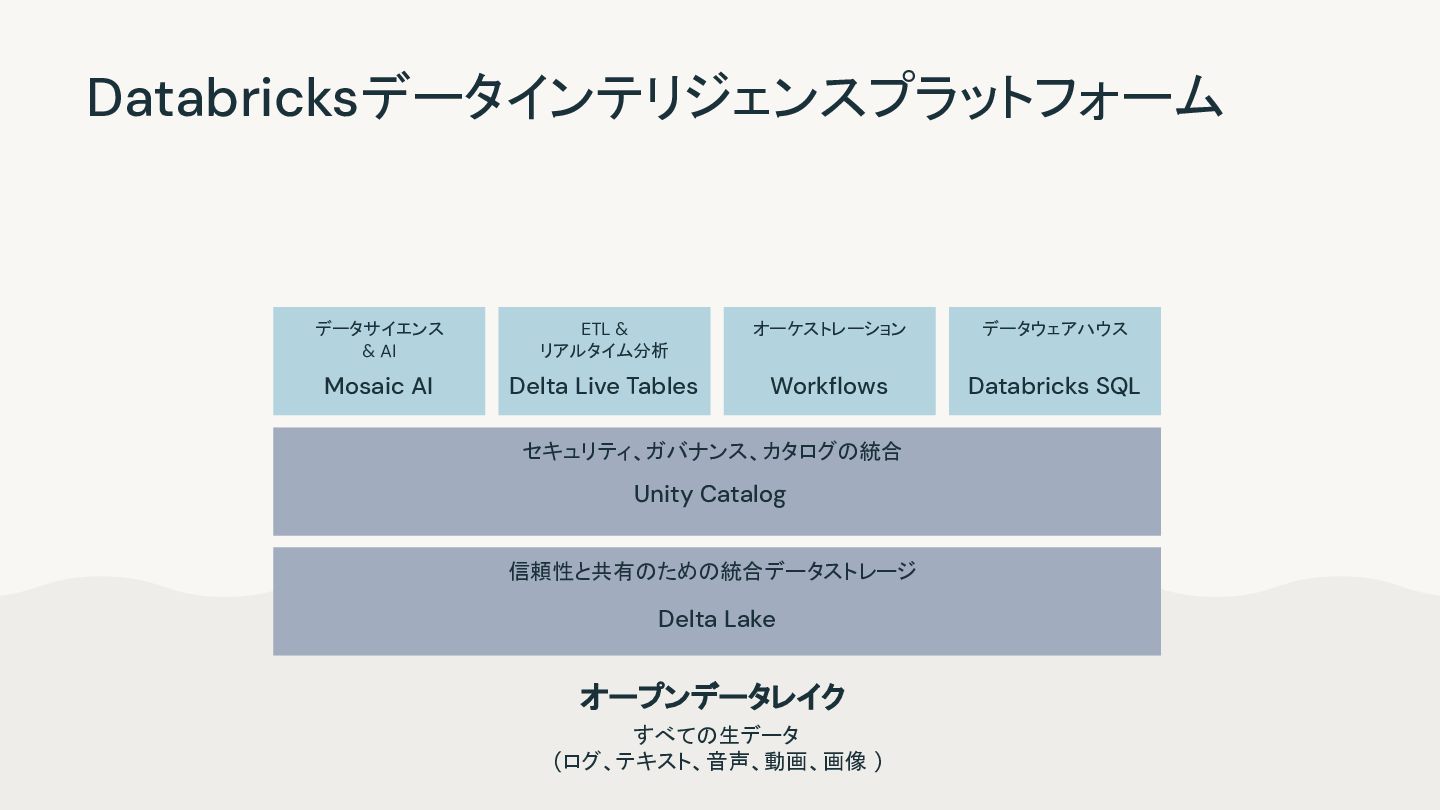
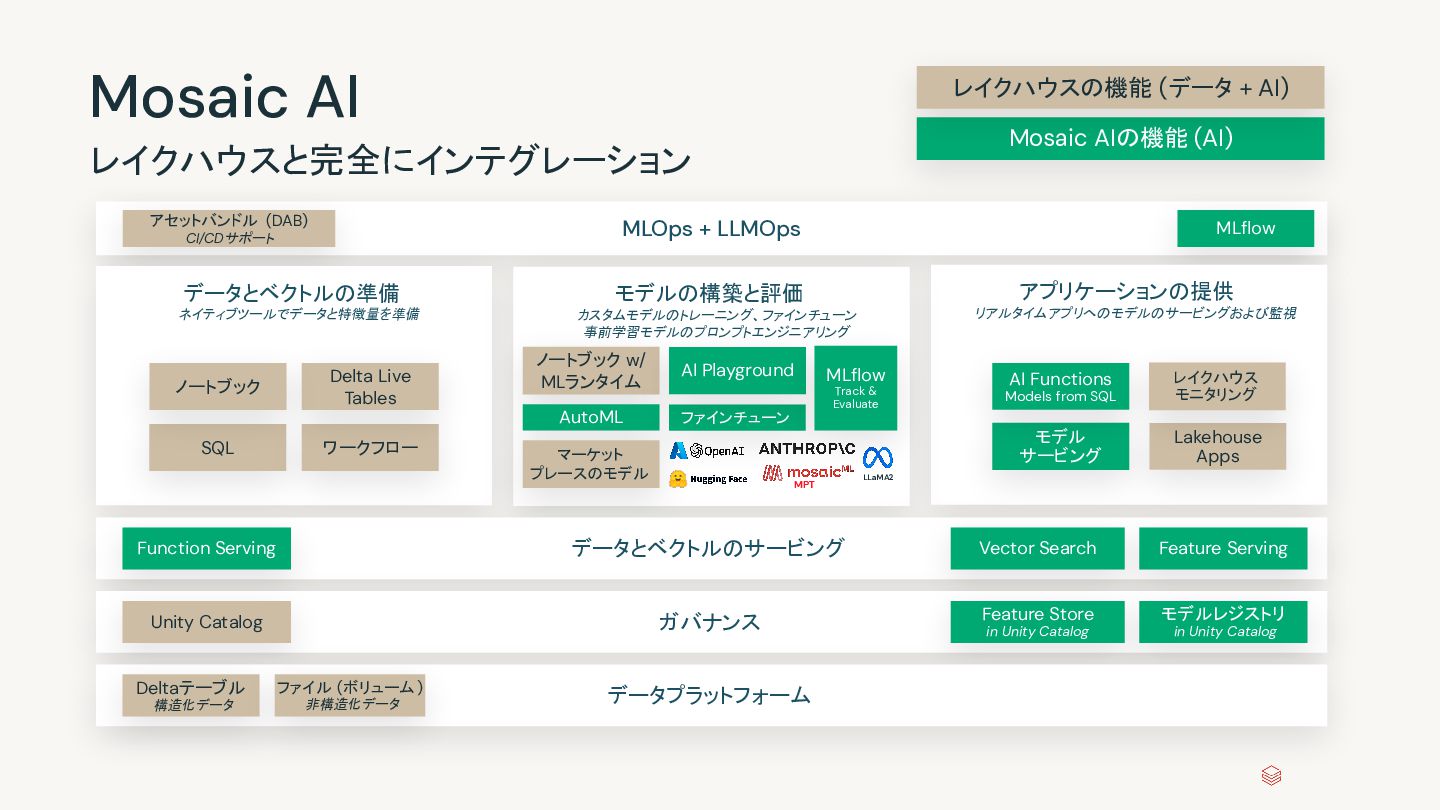
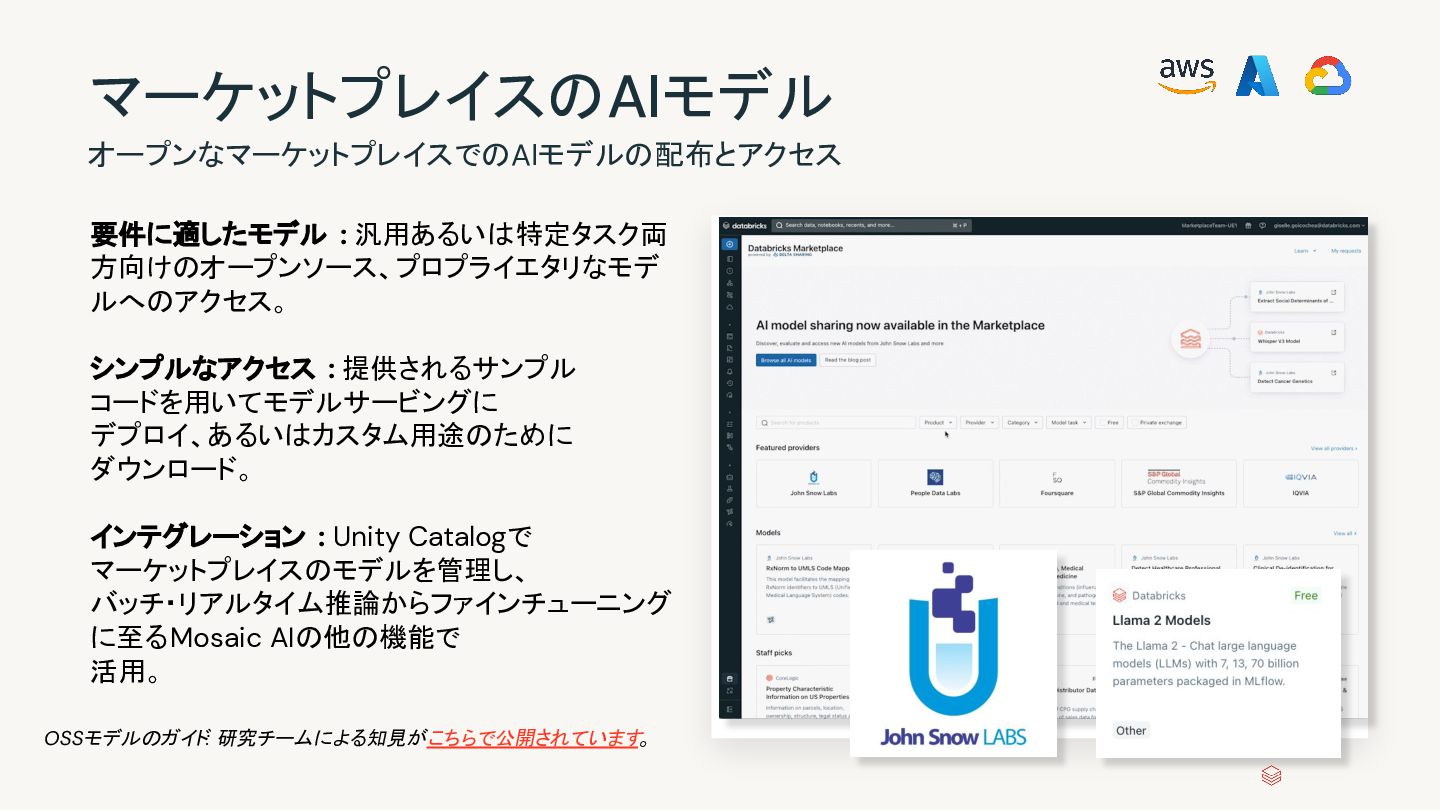
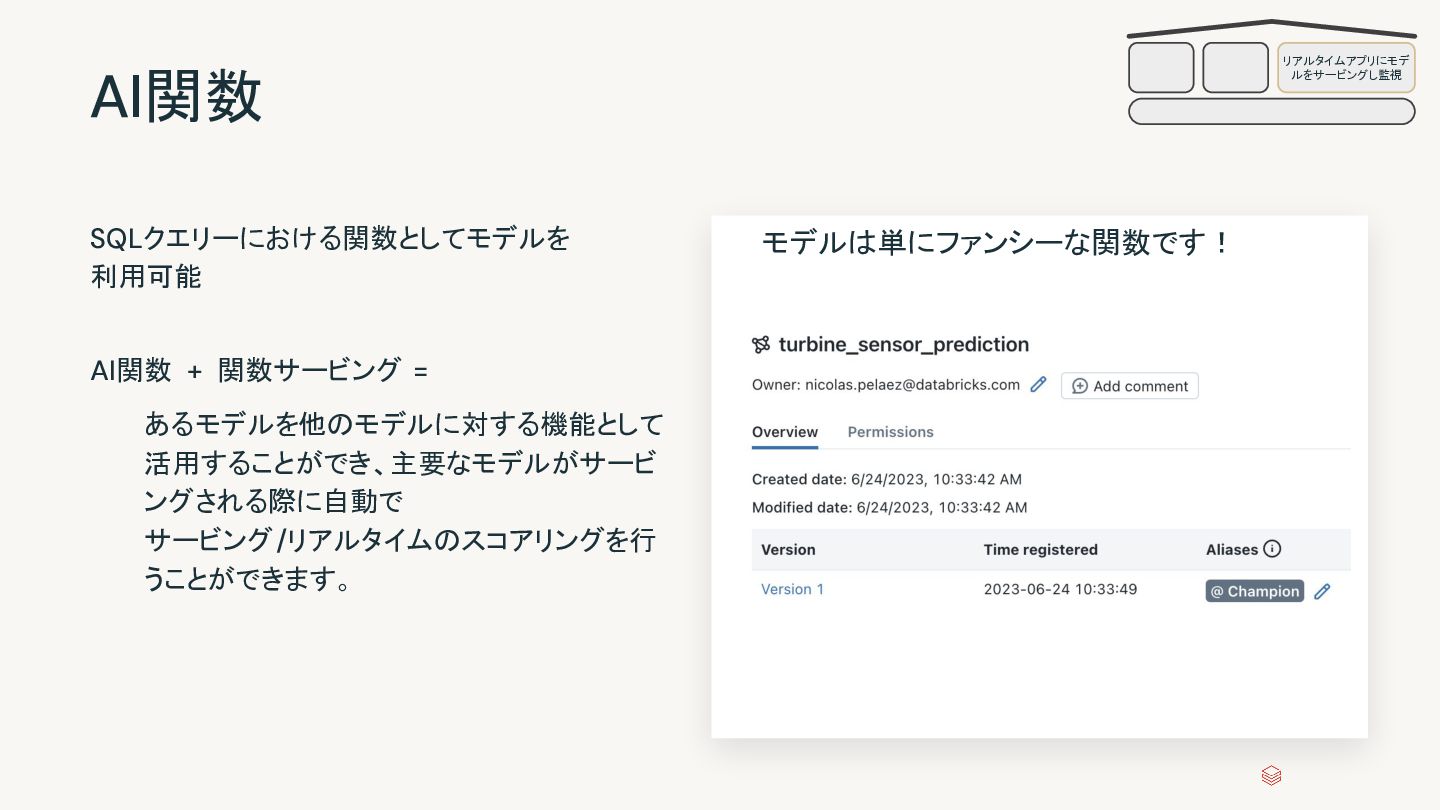
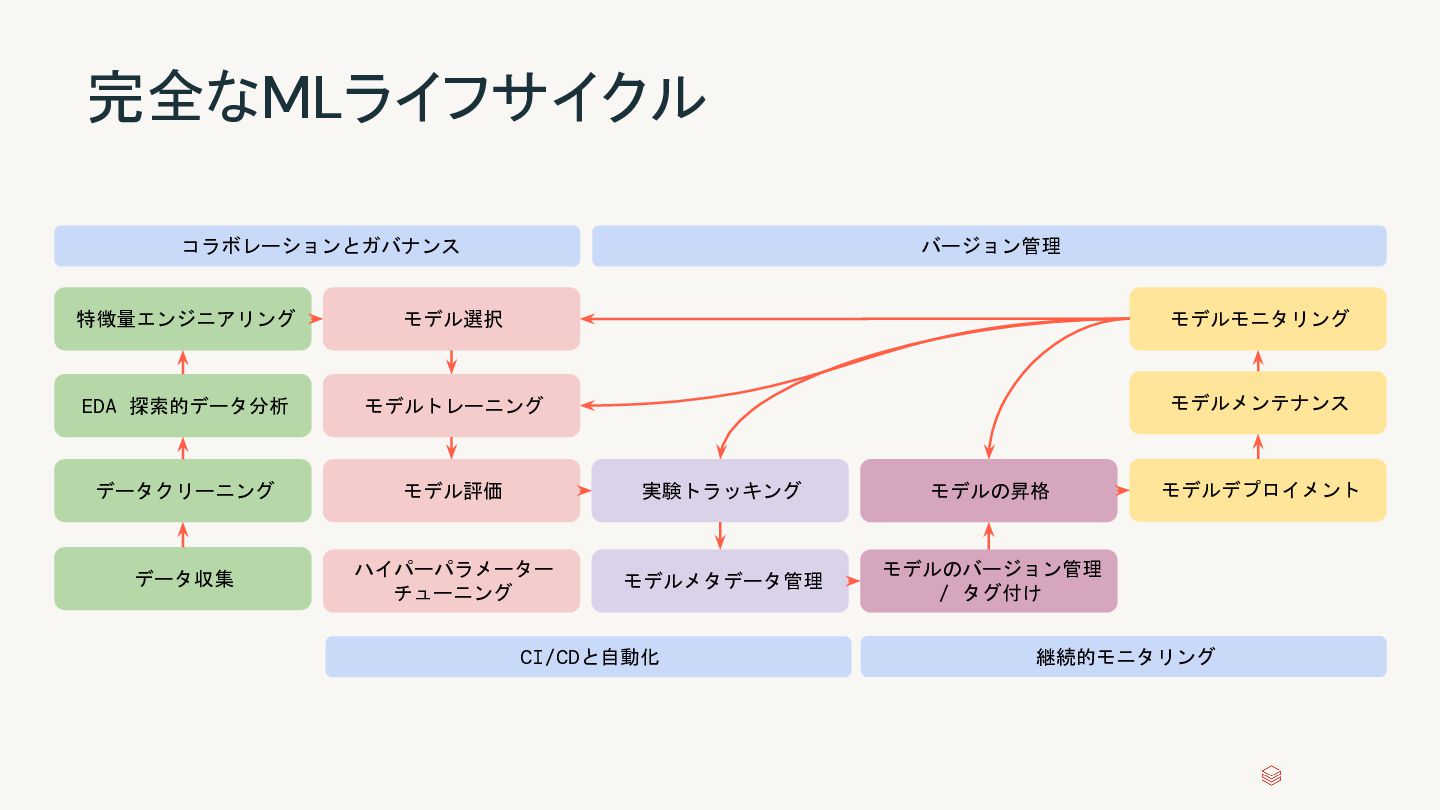
AI Mosaic AI Delta Live Tables Workflows Databricks SQL セキュリティ、ガバナンス、カタログの統合 Unity Catalog 信頼性と共有のための統合データストレージ Delta Lake Databricksデータインテリジェンスプラットフォーム オープンデータレイク
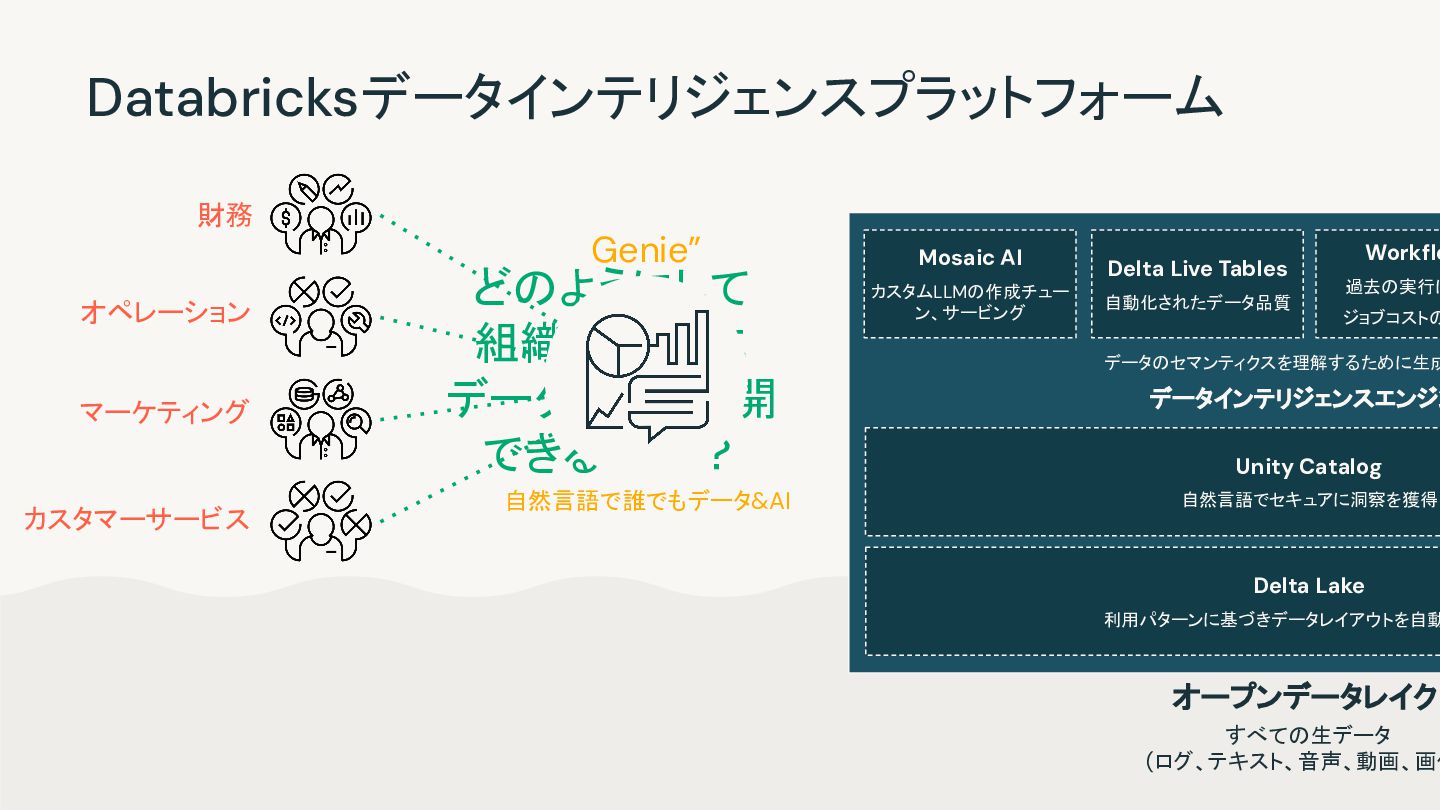
AI Mosaic AI Workflows Databricks SQL Unified security, governance, and cataloging Unity Catalog Databricksデータインテリジェンスプラットフォーム Unified data storage for reliability and sharing Delta Lake データのセマンティクスを理解するために生成AIを活用 データインテリジェンスエンジン オープンデータレイク すべての生データ (ログ、テキスト、音声、動画、画像 ) Unity Catalog 自然言語でセキュアに洞察を獲得 Delta Lake 利用パターンに基づきデータレイアウトを自動で最適化 Databricks SQL Text-to-SQL Workflows 過去の実行に基づく ジョブコストの最適化 Delta Live Tables 自動化されたデータ品質 Mosaic AI カスタムLLMの作成、チュー ン、サービング
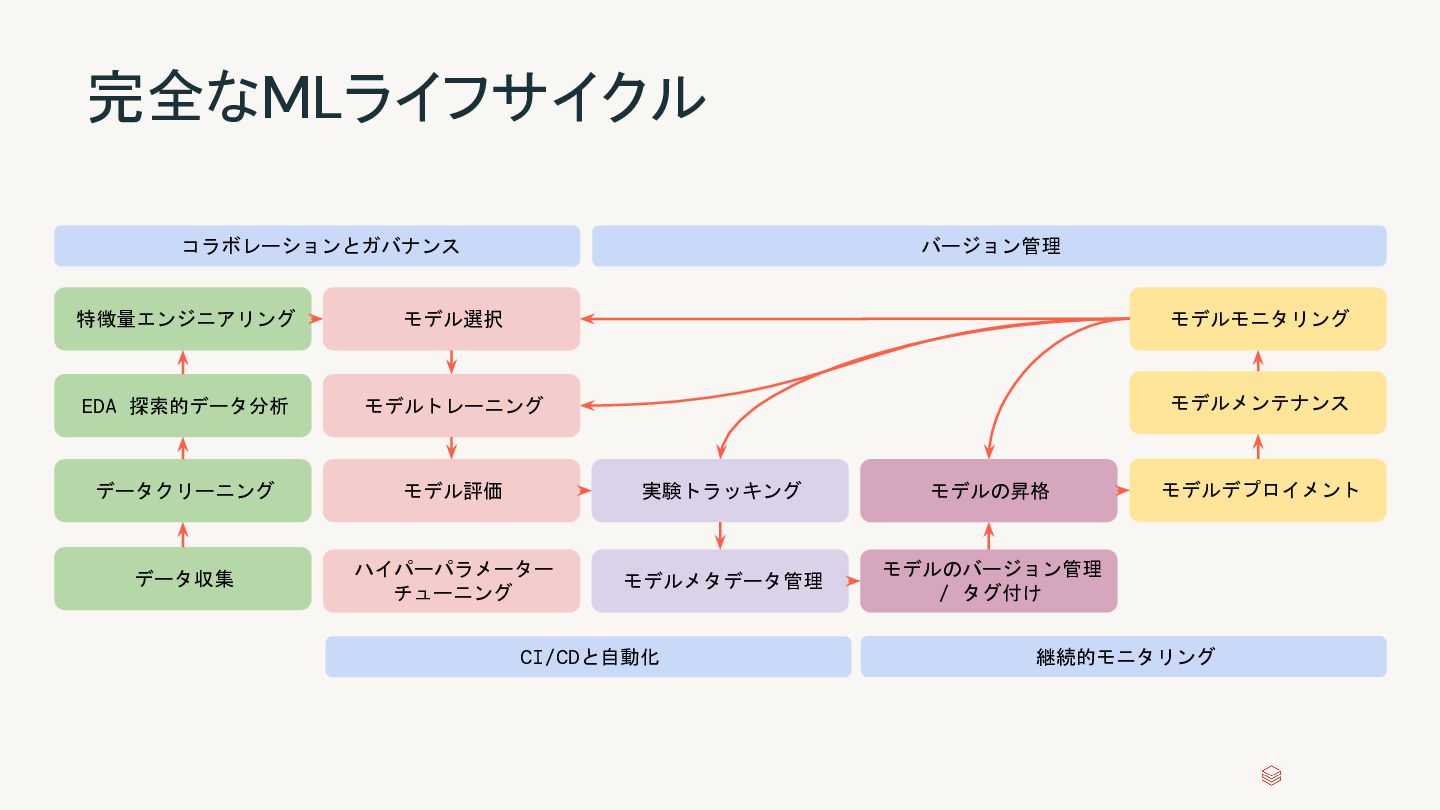
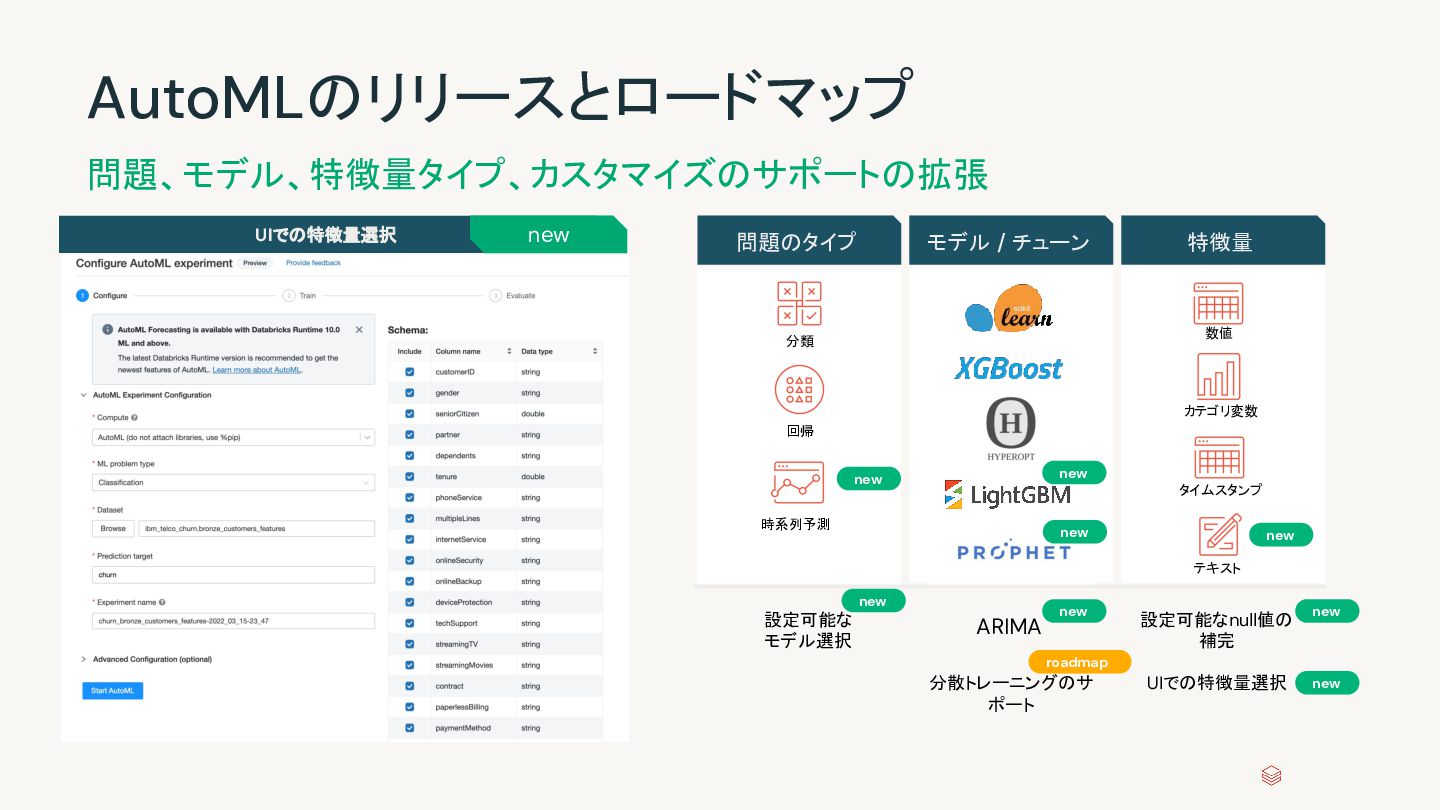
テキスト タイムスタンプ ARIMA UIでの特徴量選択 設定可能なnull値の 補完 設定可能な モデル選択 new new new new 分散トレーニングのサ ポート UIでの特徴量選択 new new new new new roadmap AutoMLのリリースとロードマップ 問題、モデル、特徴量タイプ、カスタマイズのサポートの拡張
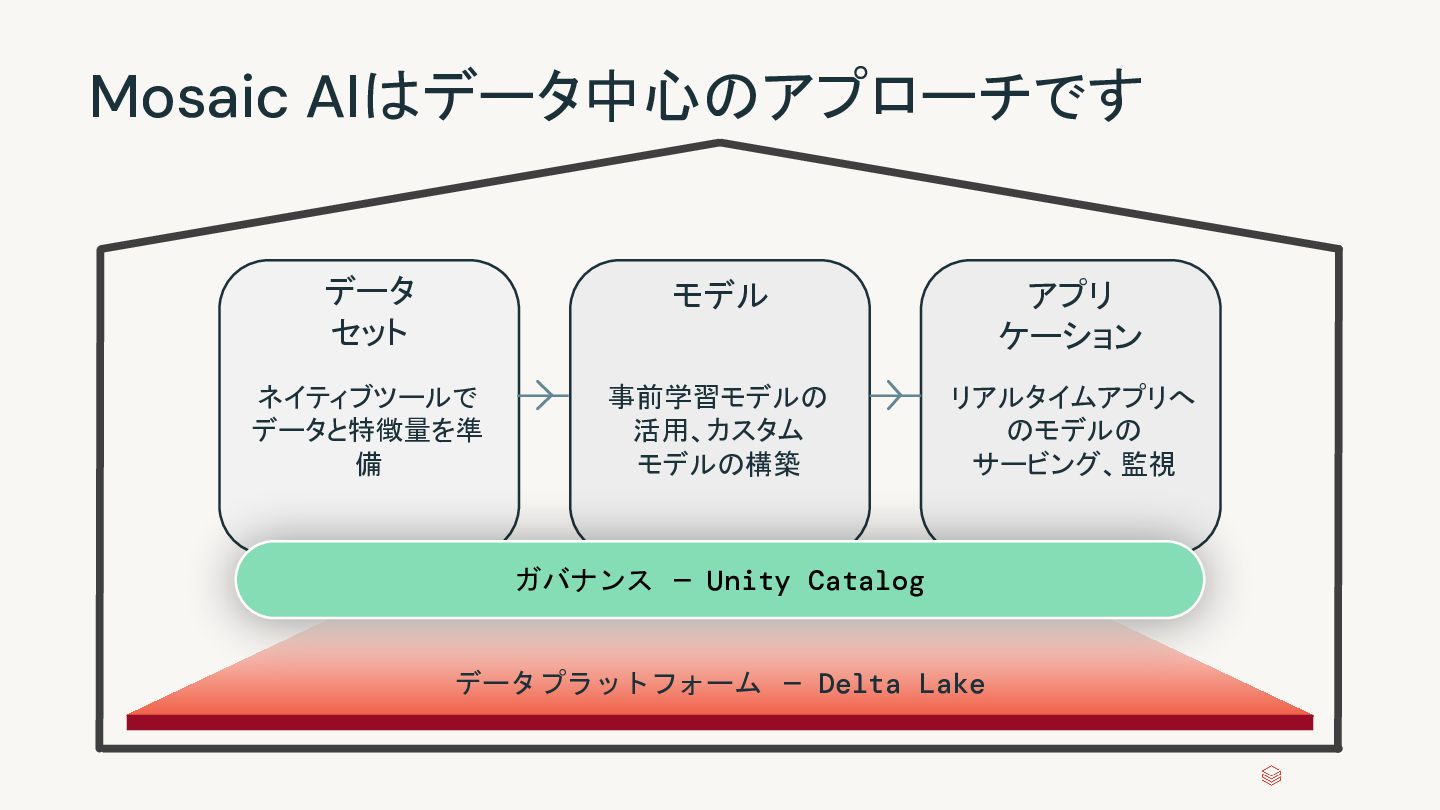
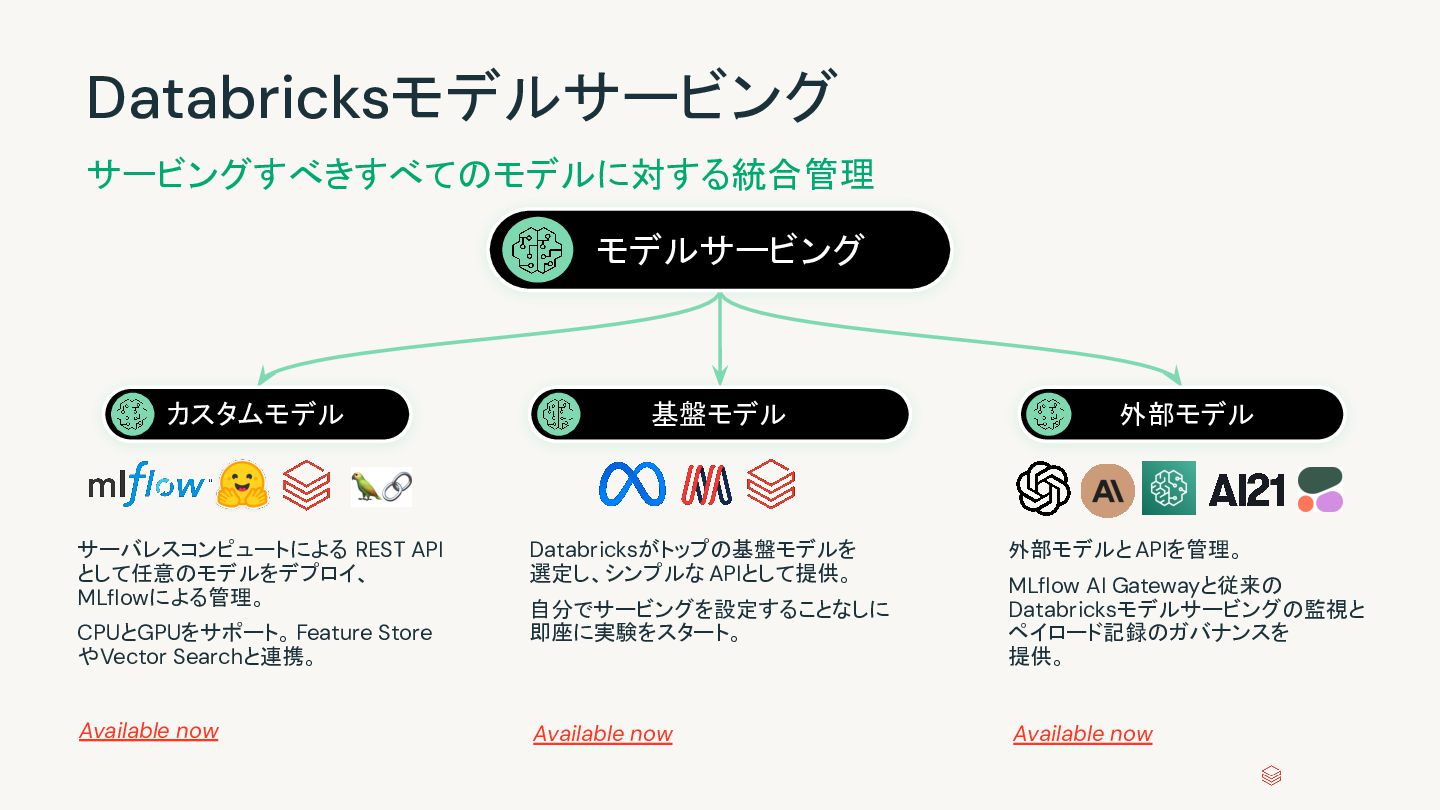
MLflowによる管理。 CPUとGPUをサポート。Feature Store やVector Searchと連携。 外部モデルとAPIを管理。 MLflow AI Gatewayと従来の Databricksモデルサービングの監視と ペイロード記録のガバナンスを 提供。 Databricksがトップの基盤モデルを 選定し、シンプルな APIとして提供。 自分でサービングを設定することなしに 即座に実験をスタート。 Available now Available now Available now
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
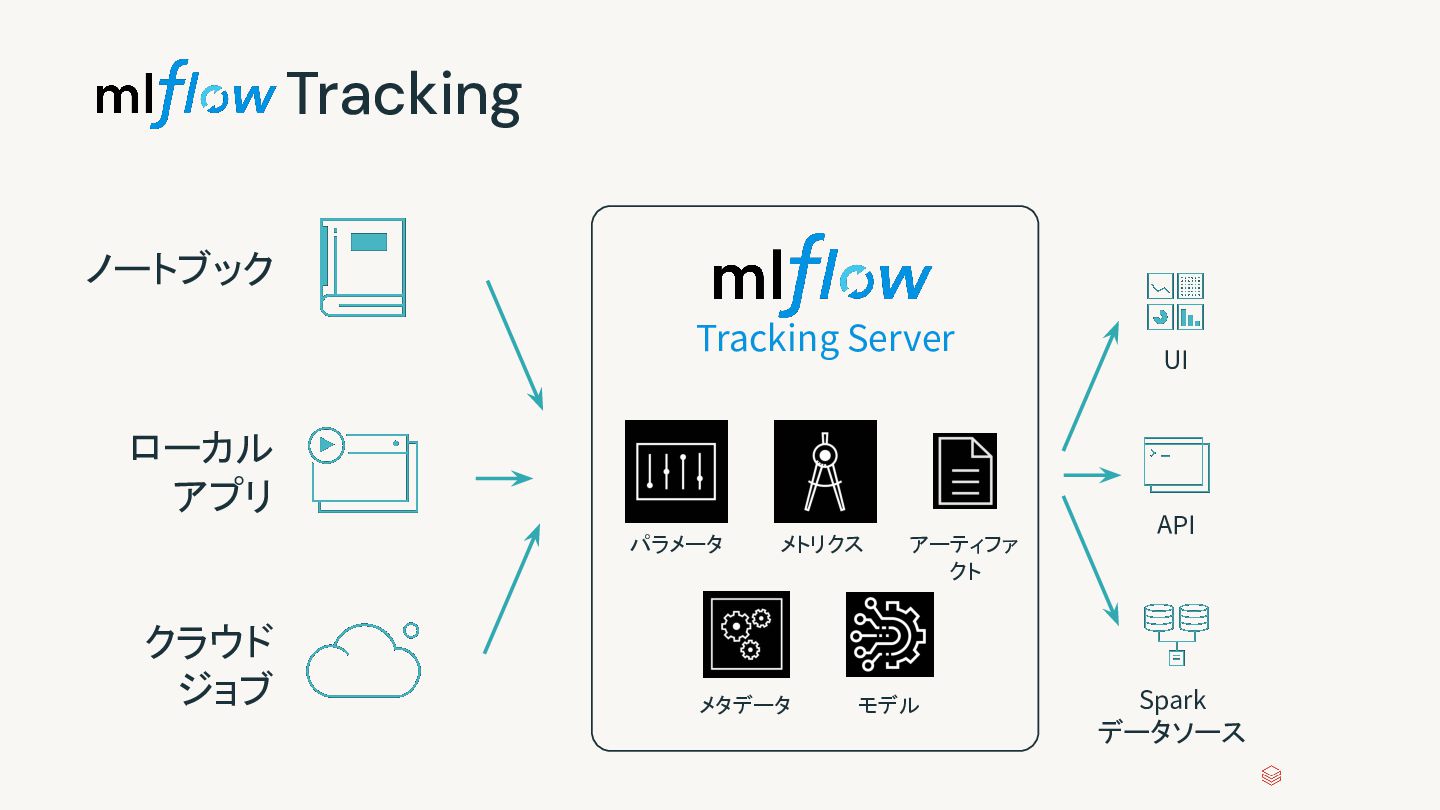{kind=link}
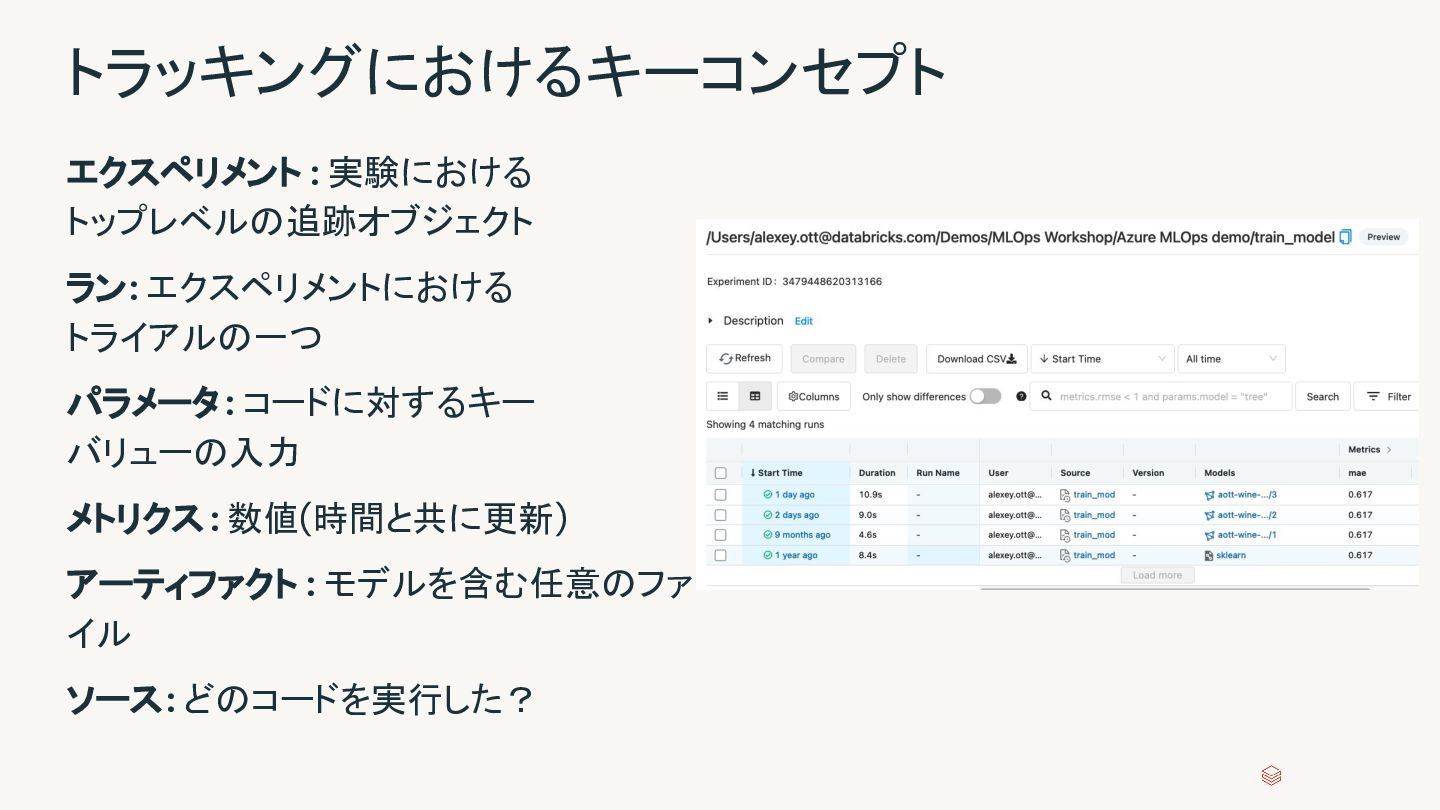{kind=link}
{kind=link}
{kind=link}
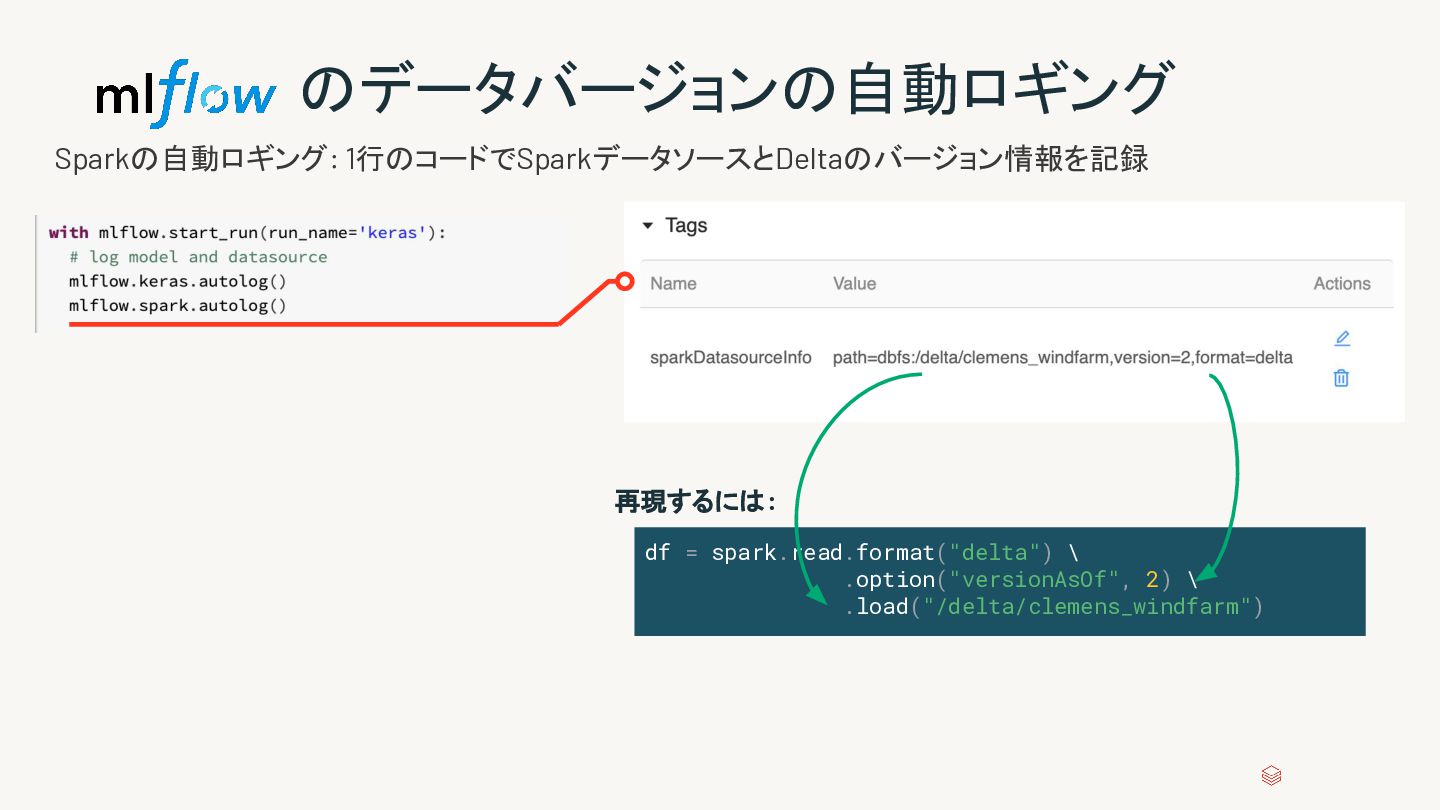{kind=link}
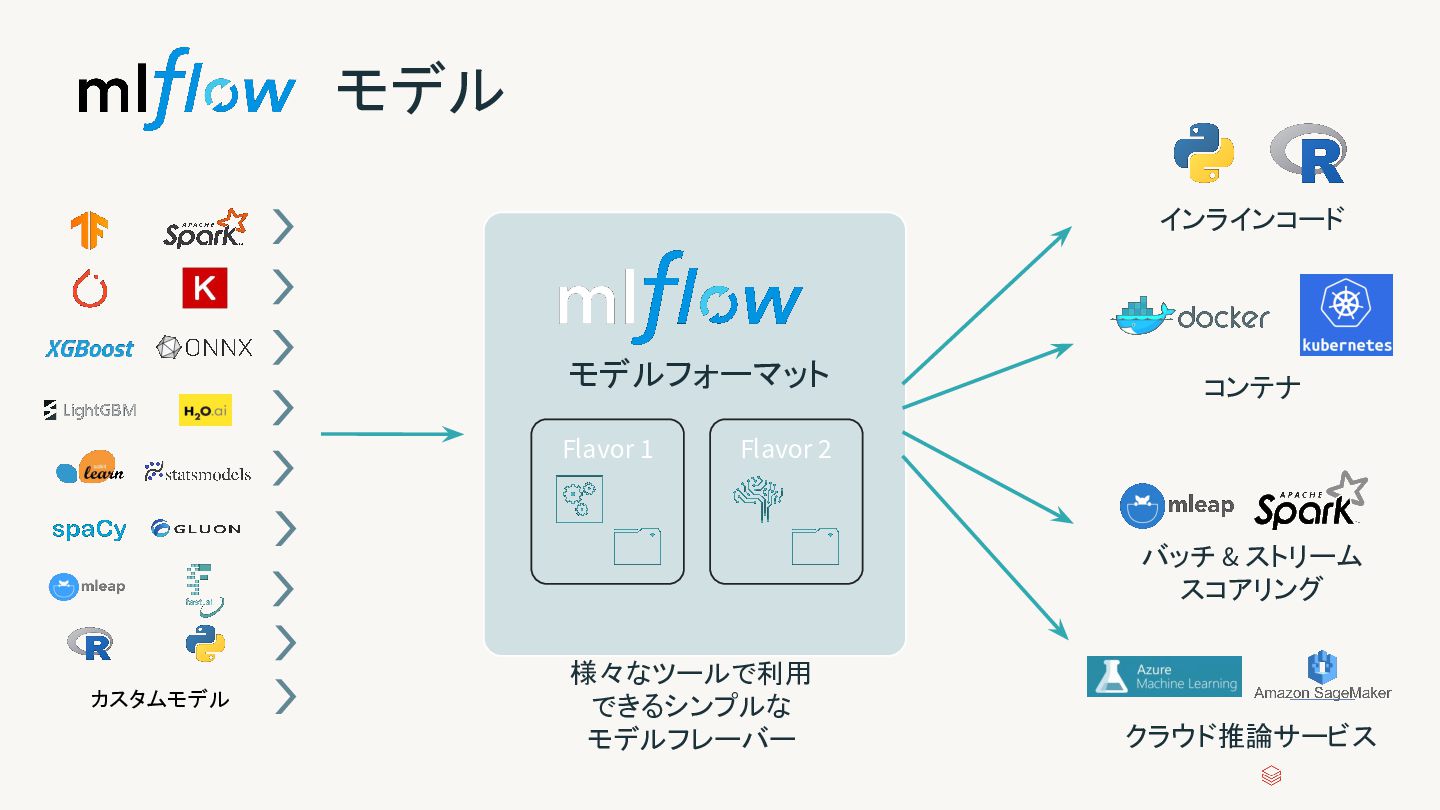{kind=link}
{kind=link}
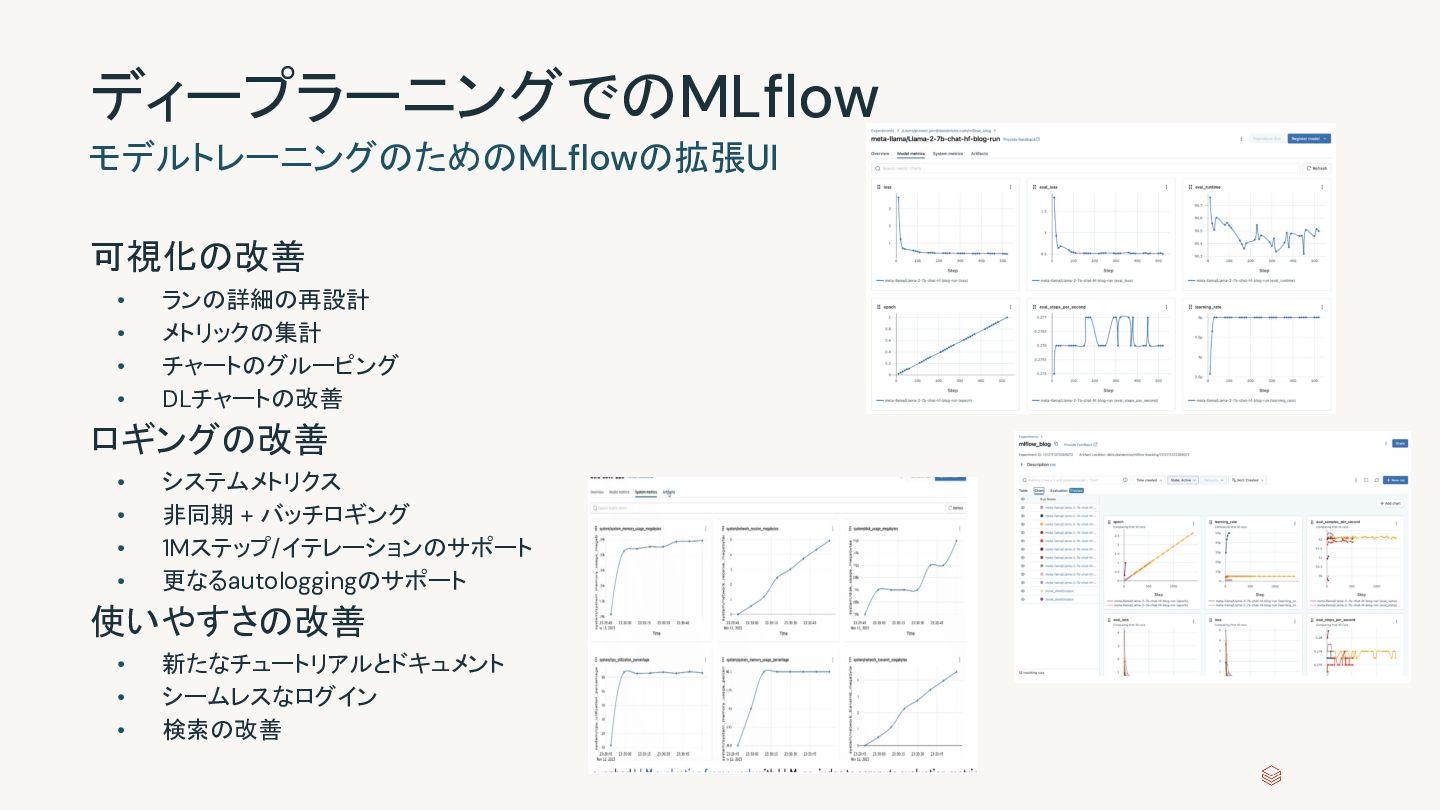{kind=link}
{kind=link}
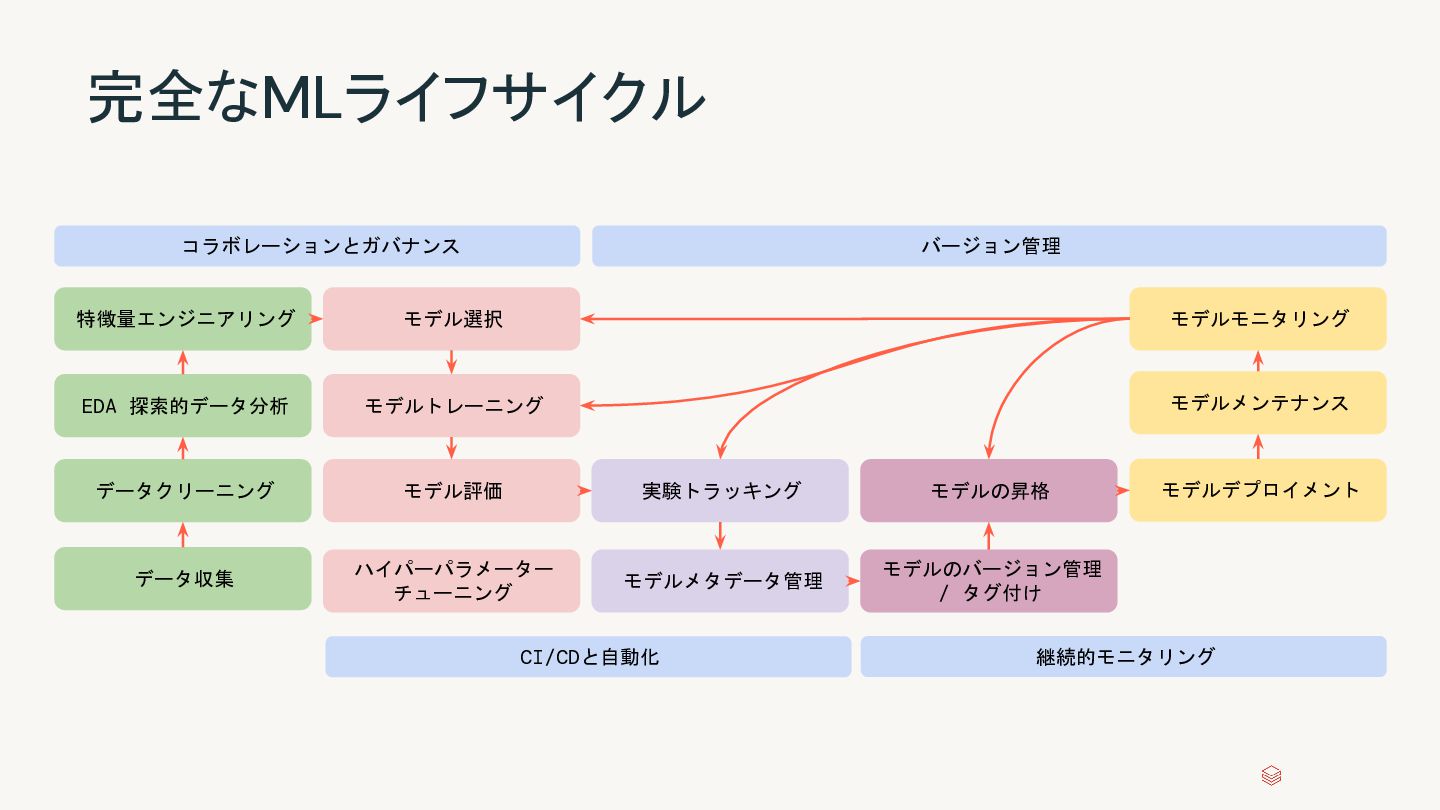{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
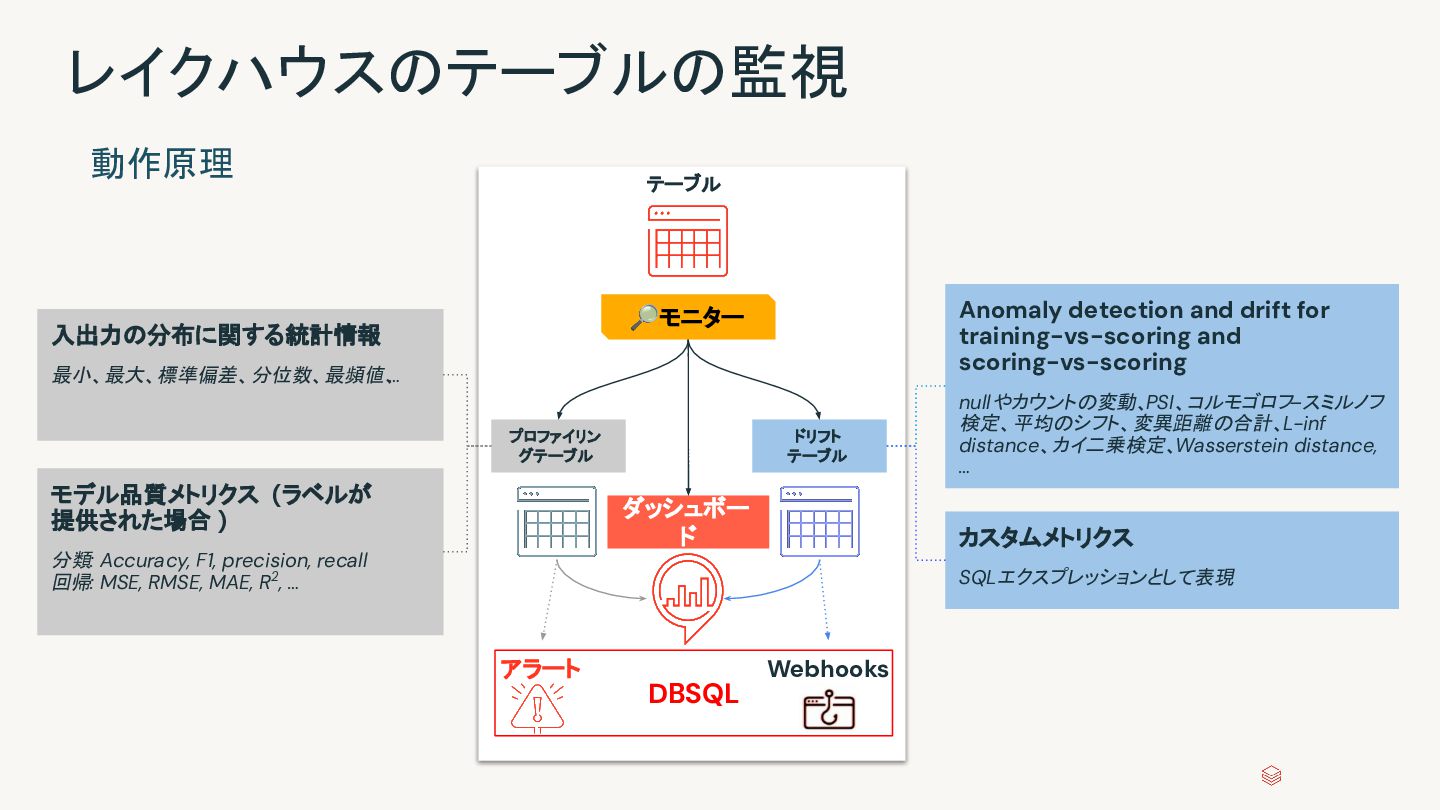{kind=link}
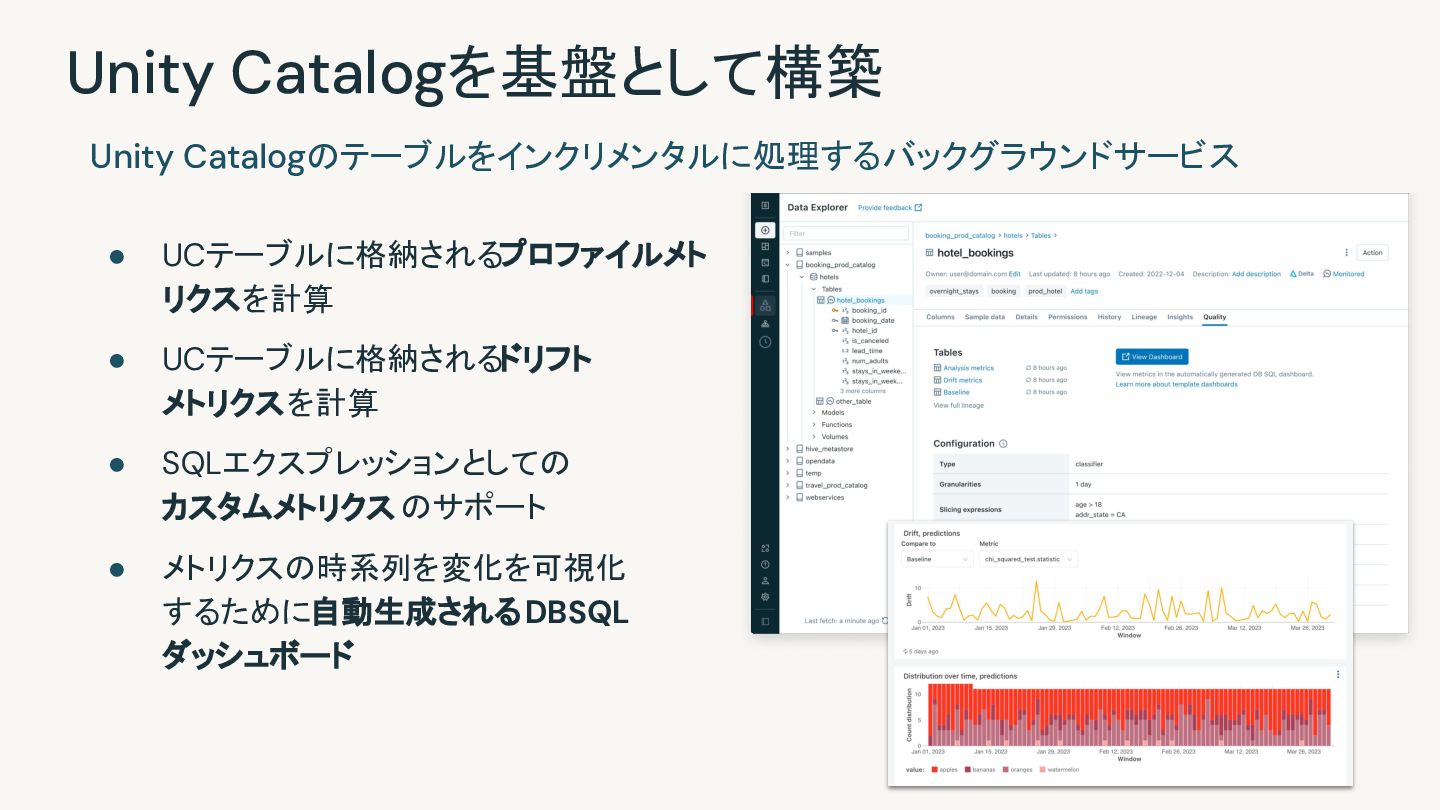{kind=link}
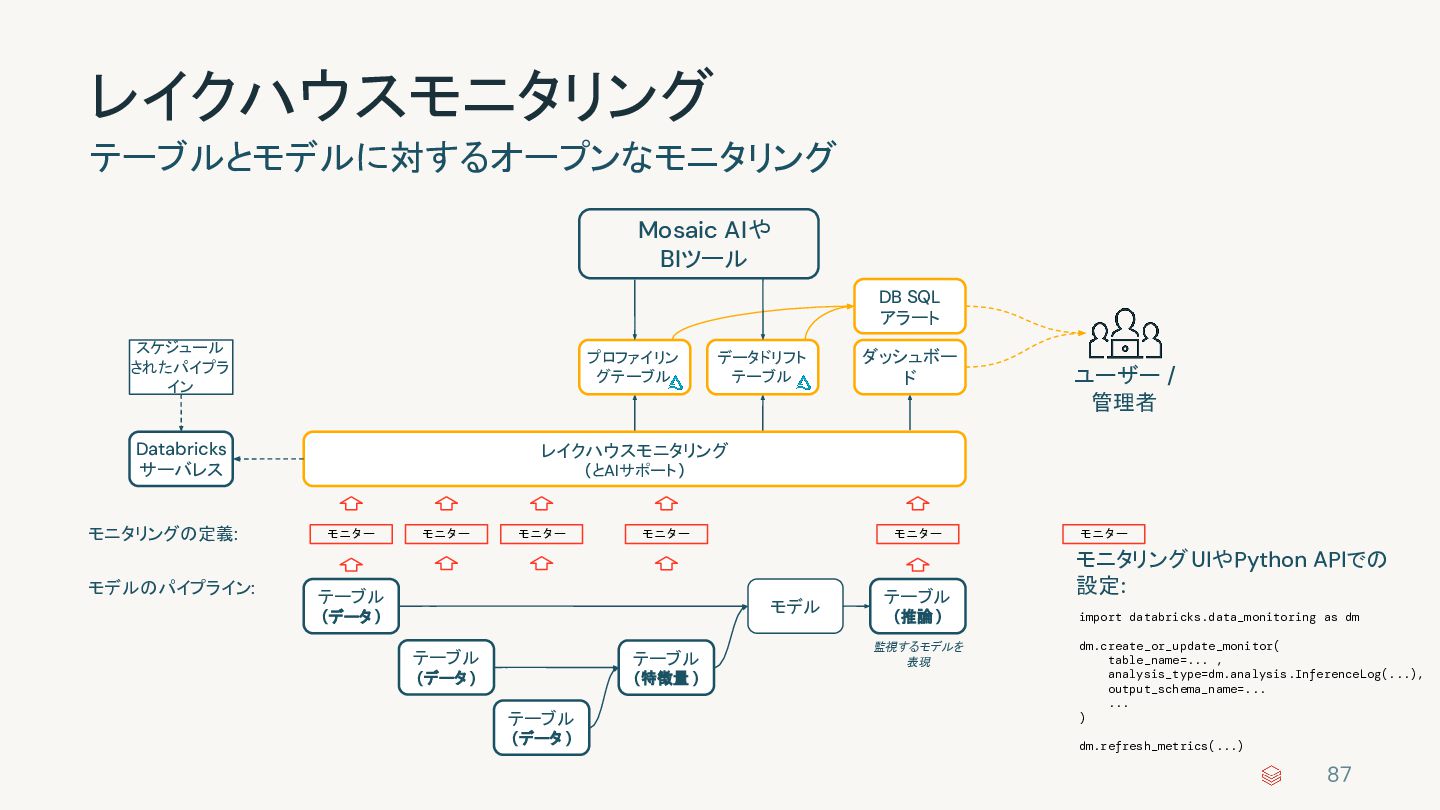{kind=link}
{kind=link}