§ MapR provides the industry’s best Hadoop Distribu6on – Combines the best of the Hadoop community contribu6ons with significant internally financed infrastructure development § Background of Team – Deep management bench with extensive analy6c, storage, virtualiza6on, and open source experience – Google, EMC, Cisco, VMWare, Network Appliance, IBM, Microso[, Apache Founda6on, Aster Data, Brio, ParAccel § Proven – MapR used across industries (Financial Services, Media, Telcom, Health Care, Internet Services, Government) – Strategic OEM rela6onship with EMC and Cisco – Over 1,000 installs
§ A certain bank – had lots of customers – had lots of prospec6ve customers – had a non-‐trivial number of fraudulent customers – had a non-‐trivial number of fraudulent merchants § They also – collected data – built models – collected more data – built more models
§ Find the k nearest training examples § Use the average value of the target variable from them § This is easy … but hard – easy because it is so conceptually simple and you don’t have knobs to turn or models to build – hard because of the stunning amount of math – also hard because we need top 50,000 results § Ini6al prototype was massively too slow – 3K queries x 200K examples takes hours – needed 20M x 25M in the same 6me
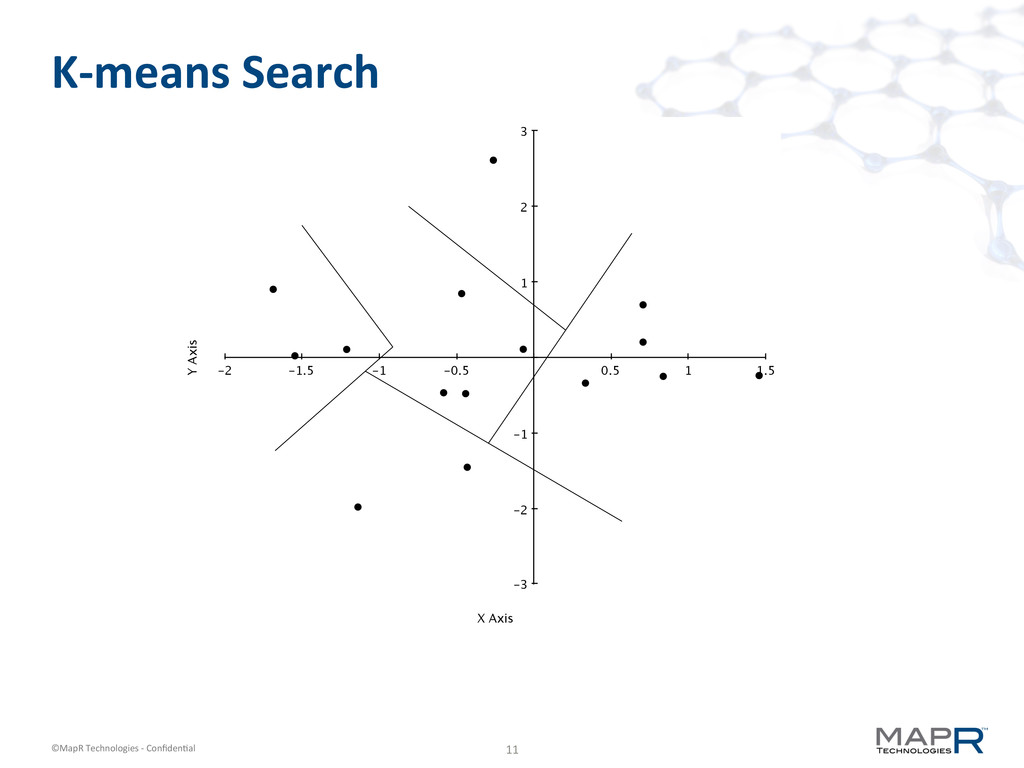
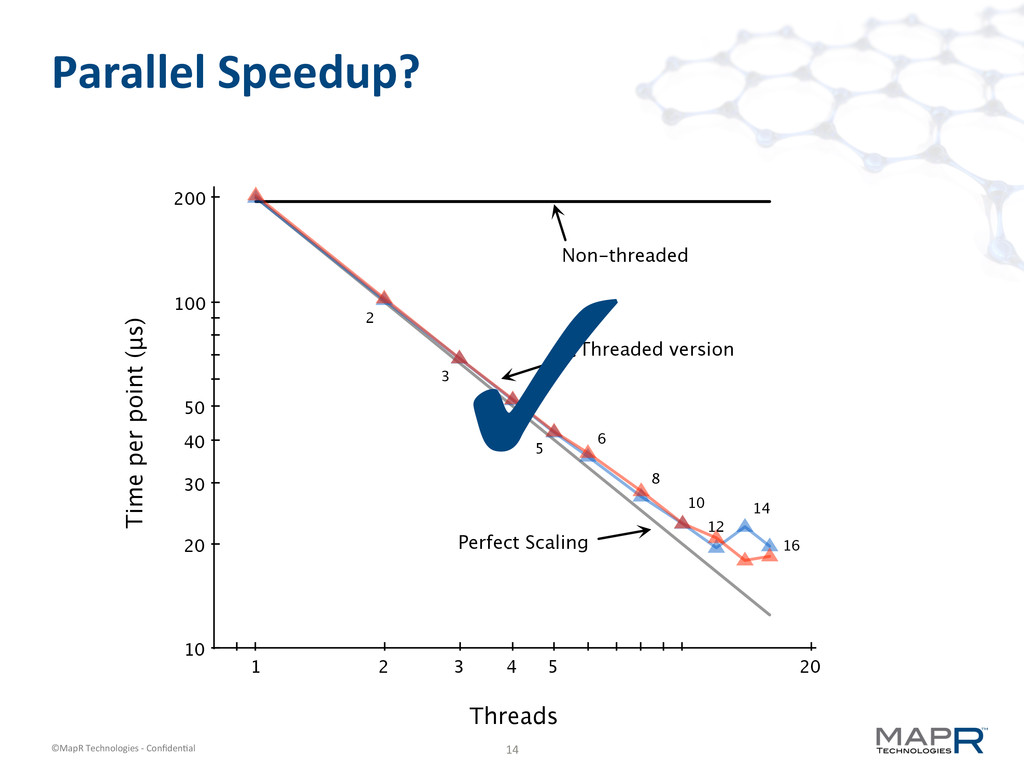
k-‐means! § Need a new k-‐means algorithm to get speed § Streaming k-‐means is – One pass (through the original data) – Very fast (20 us per data point with threads) – Very parallelizable
§ For each point – Find approximately nearest centroid (distance = d) – If d > threshold, new centroid – Else possibly new cluster – Else add to nearest centroid § If centroids > K ~ C log N – Recursively cluster centroids with higher threshold § Result is large set of centroids – these provide approxima6on of original distribu6on – we can cluster centroids to get a close approxima6on of clustering original – or we can just use the result directly
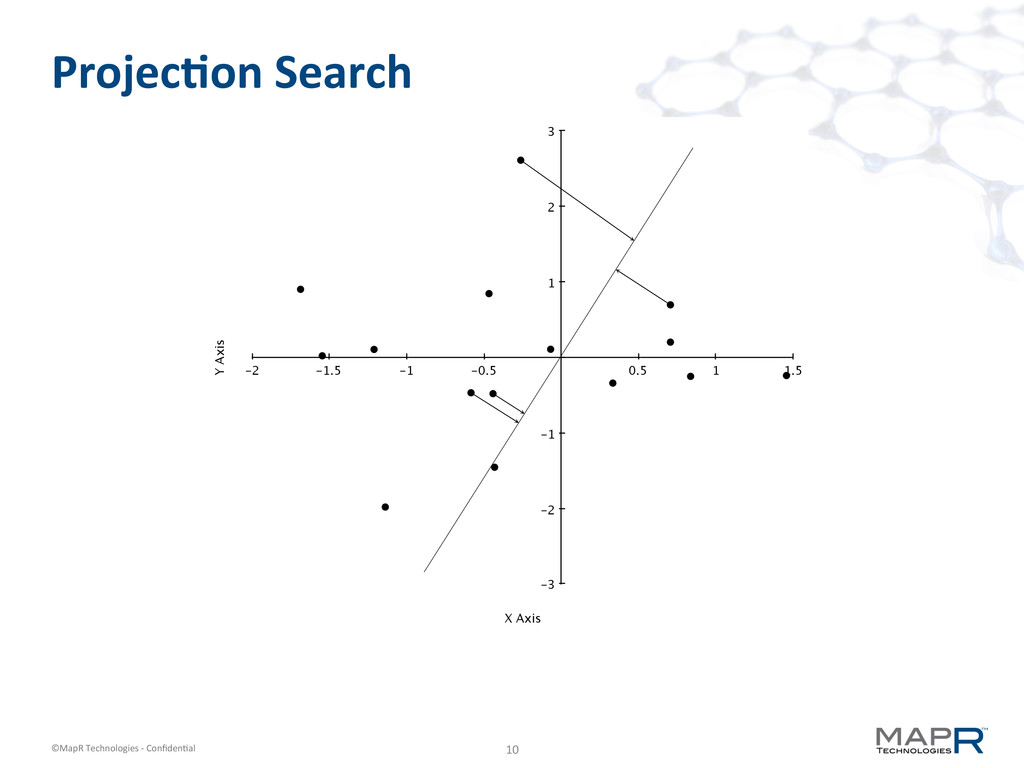
§ Inner loop requires finding nearest centroid § With lots of centroids, this is slow § But wait, we have classes to accelerate that! (Let’s not use k-‐means searcher, though)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}