SEO Consultant since 2012 Pracademic 'doing SEO every day' Information retrieval interloper since 2017 Msc Digital Marketing 2017 Currently studying for second MSc in Computer Science and Data Science Personal life Mum, step-mum, step- grandma, wife Runner (road, marathon, fells, cross- country) Baker Pomeranian lover
search ranking Ranking across all of ElasticSearch BM25 has limitations BM25F deals with long documents and multi-field weights in documents (title, body etc)
of documents •Predict which one should rank higher •Examples – RankNet, LambdaRank Pointwise •Treats ranking as a classification or a regression problem •Predict a relevance score for each document independently Listwise •Looks at the entire list of results at once •Optimises ranking specific metrics (MAP, NDCG) •Examples – LambdaMart, ListNet
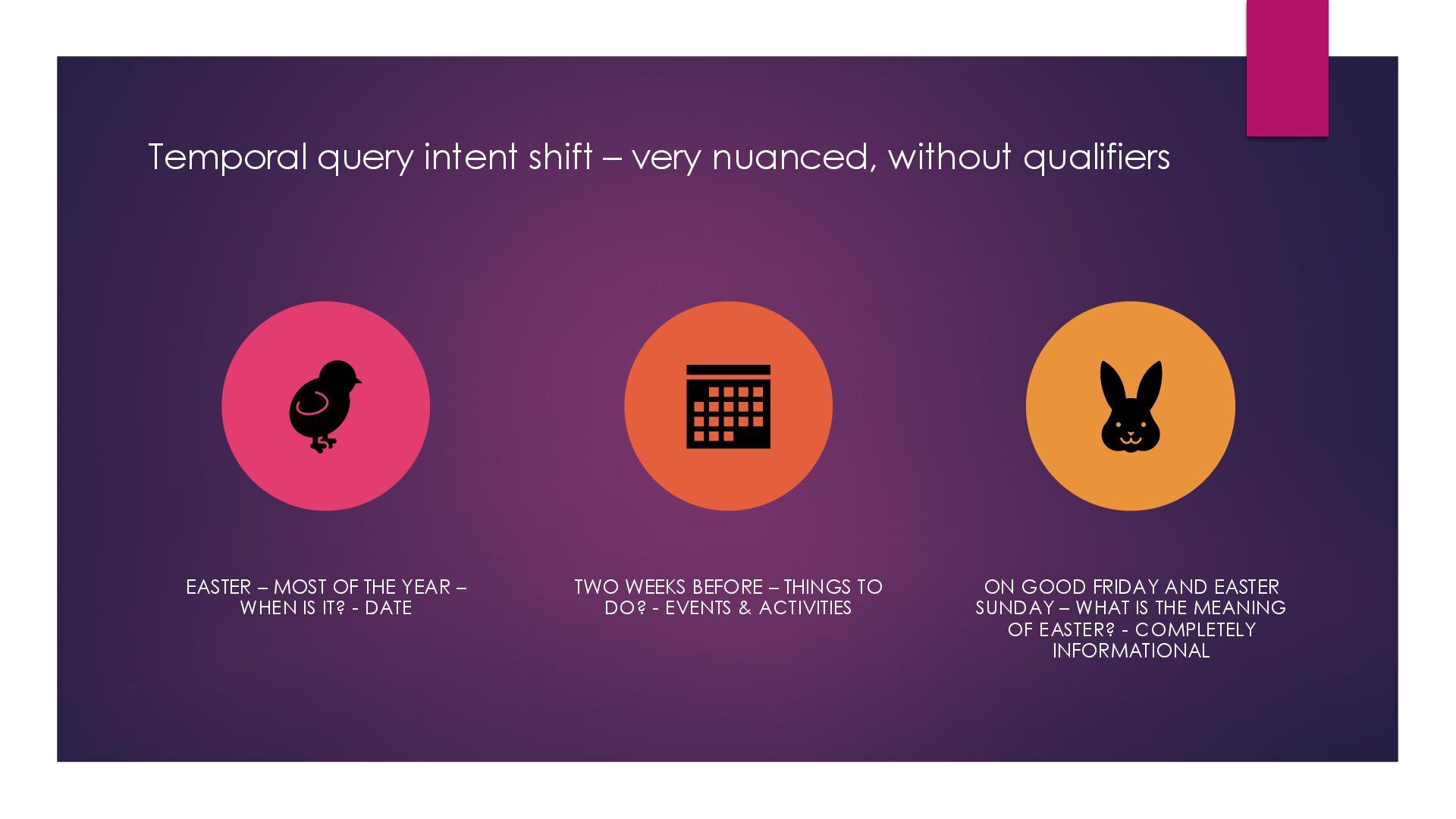
– MOST OF THE YEAR – WHEN IS IT? - DATE TWO WEEKS BEFORE – THINGS TO DO? - EVENTS & ACTIVITIES ON GOOD FRIDAY AND EASTER SUNDAY – WHAT IS THE MEANING OF EASTER? - COMPLETELY INFORMATIONAL
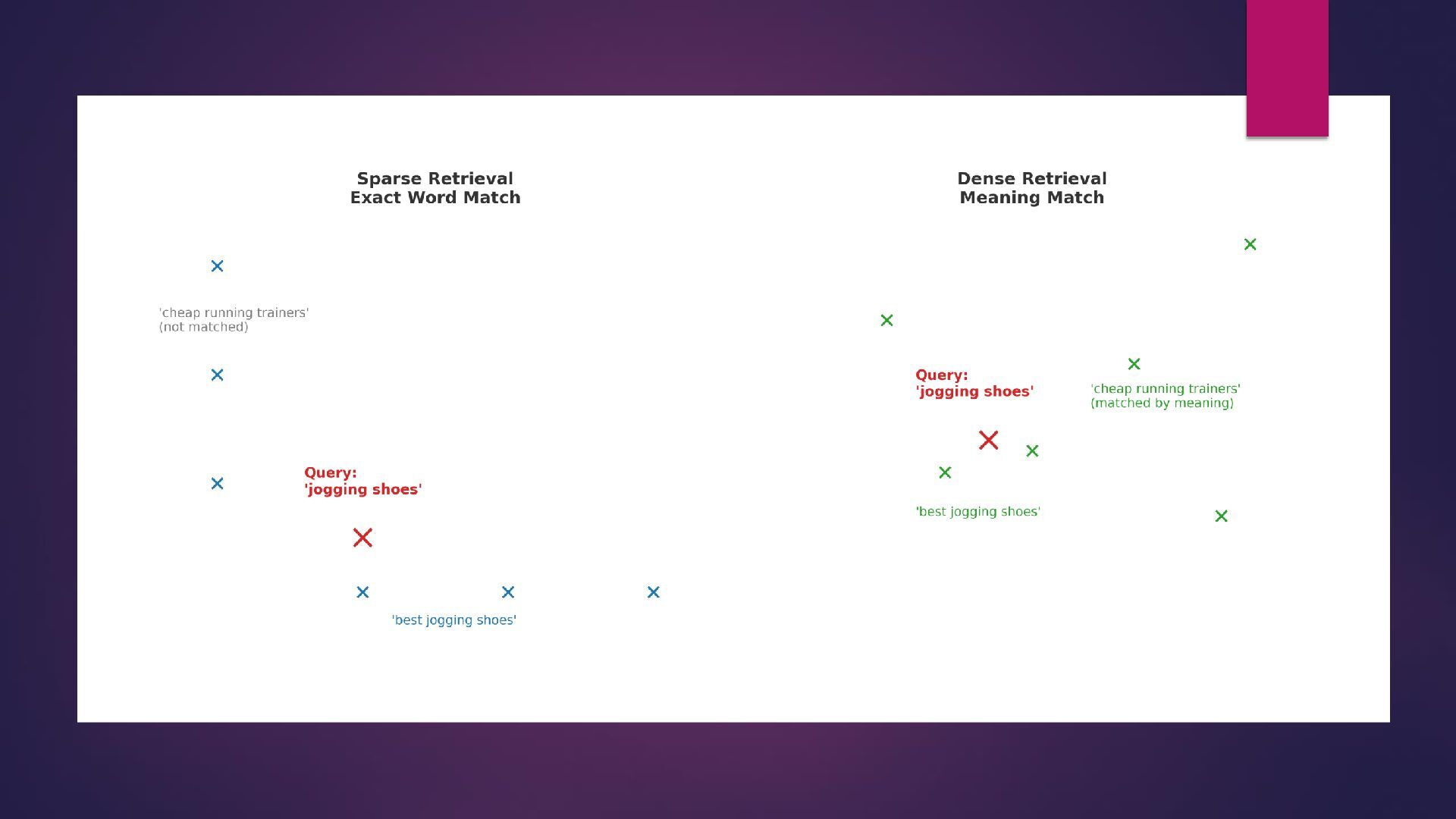
old-school librarian who flips through a card catalog to find the exact terms you wrote. Dense retrieval is like a smart assistant who understands what you meant, even if you phrased it differently. Modern search engines (like Google and Bing) actually combine both: Sparse retrieval for exact matches (important for things like names, dates, product codes). Dense retrieval for semantic understanding (important for natural questions, conversational queries, and AI search).
present? Used in decision trees / machine learning Used for classification Designed to identify where best to split a dataset so that it is most 'pure' to the class sought It's a measure of information impurity In decision trees 'entropy' (information gain) helps decide which features best separate the data
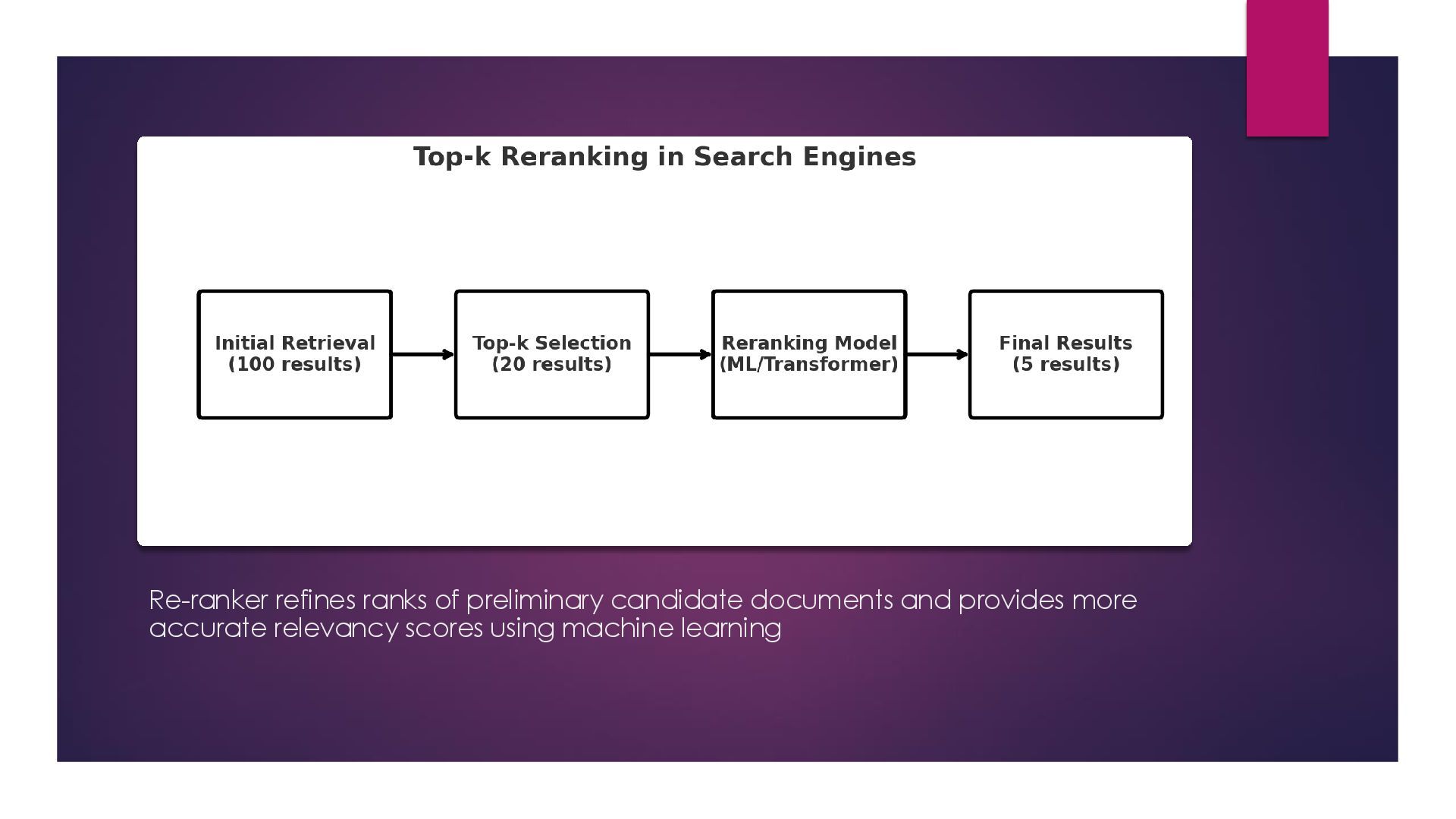
beyond the obvious Top-K and late stage re-ranking Crawl scheduling via importance prediction and spam swerving Feature engineering optimisation (understanding which factors should work together) Pairwise, pointwise and listwise ranking comparisons Learning to rank Dynamic index pruning Generative information retrieval
the 'search' cost burden on searchers • Particularly Gen Z and Millennials tempted to defect to ChatGPT et al Rethinking search • Take the knowledge to the searcher rather than make them search
evolution' (Ricardo Baeza-Yates) Google are "rushing ahead" (Bender & Shah) Searchers still want to learn and search for themselves (Bender & Shah) Generative IR (e.g. AI Overviews) takes away the agency (control) of searchers Generative IR doesn't meet Belkin's -16 information seeking strategies 'Rethinking Search' paper by Google team rebuked by many reviewers
(DSI) is a self-learning search system where the index itself is part of the AI’s training process. Instead of just storing documents, it adapts how queries and documents are matched, improving continuously from user interactions.
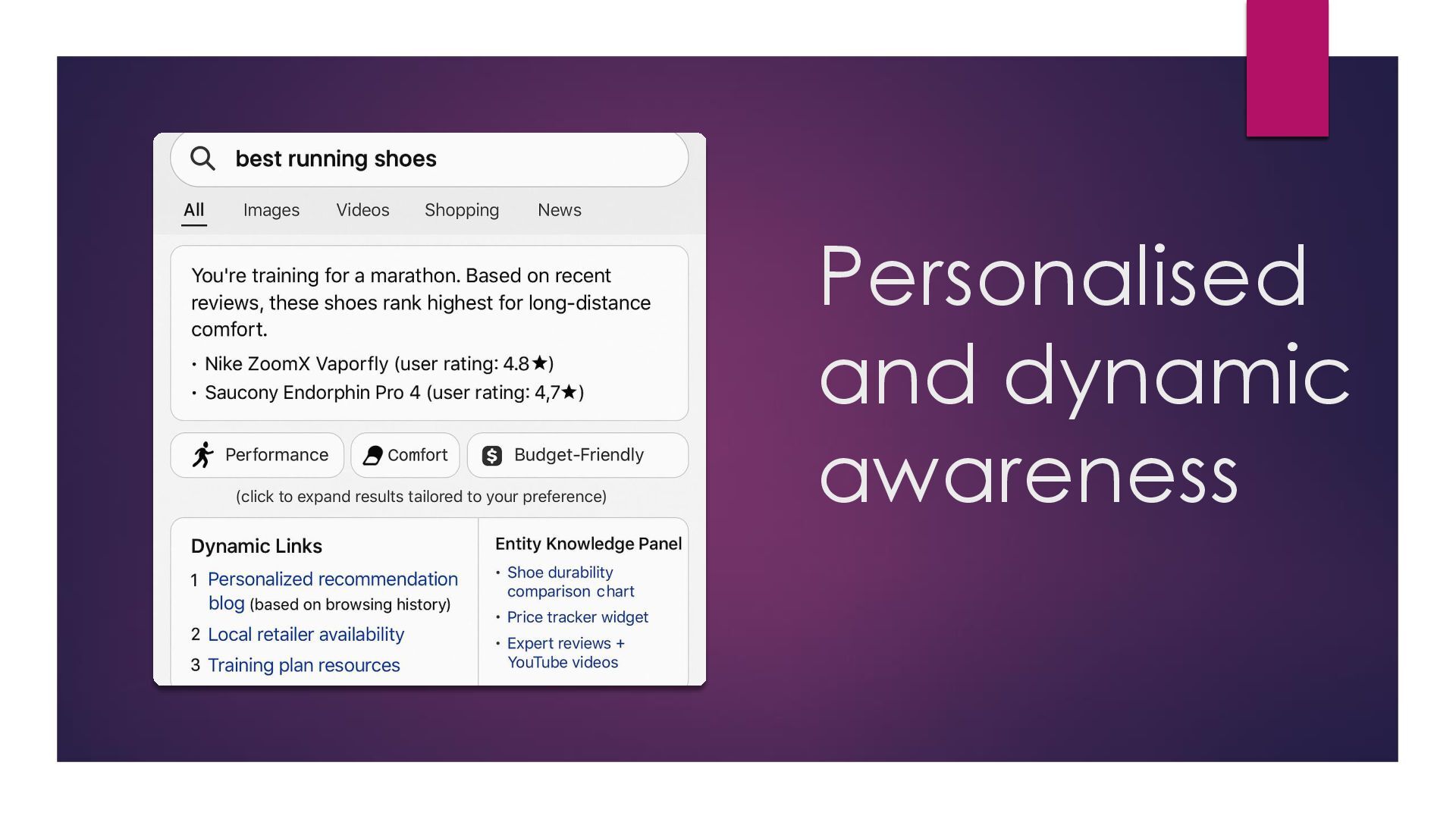
of links + fixed snippet. Future: living, adaptive SERP that reorders, expands, or hides elements in real time as the system learns from you and other users.
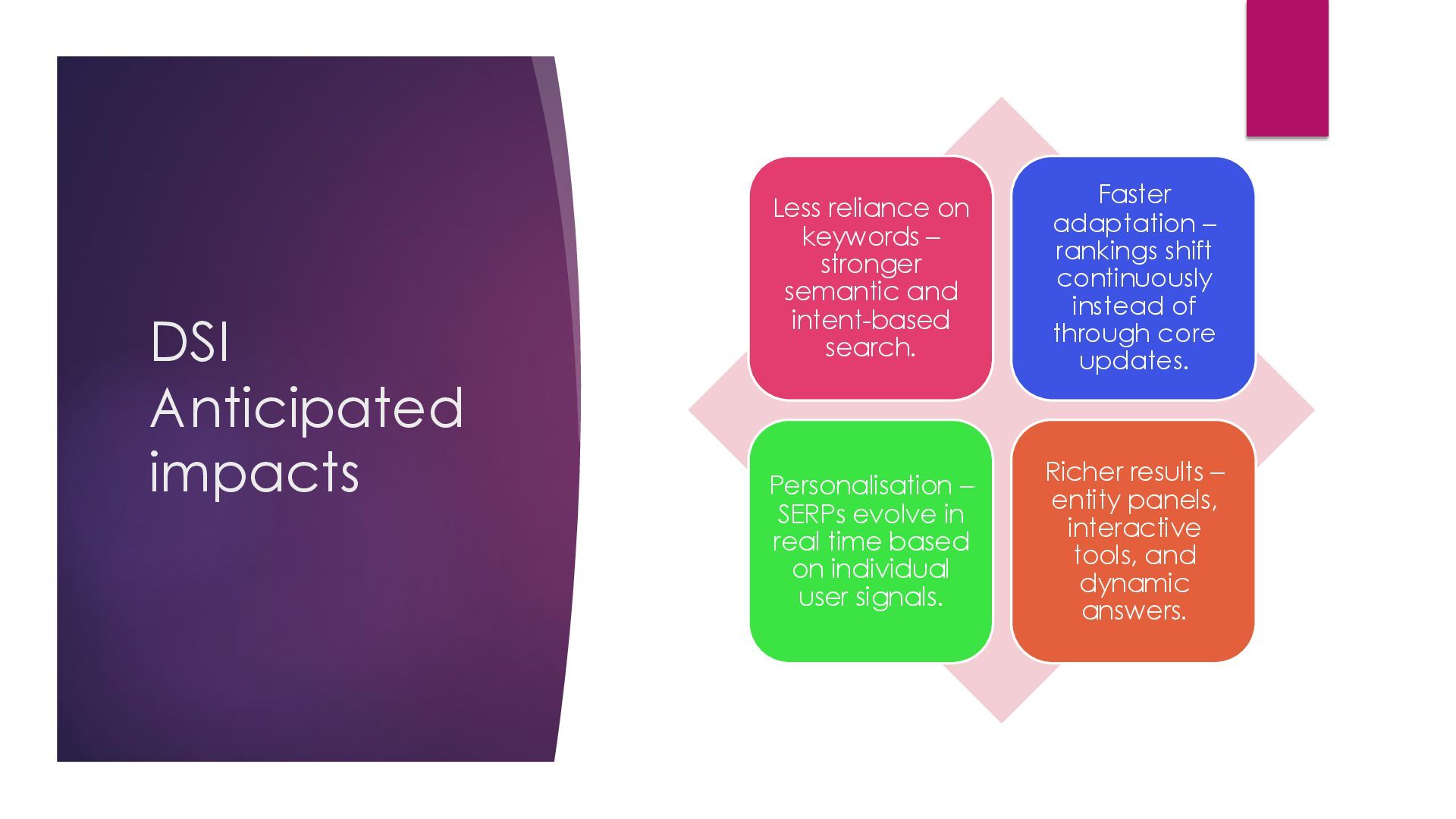
and intent-based search. Faster adaptation – rankings shift continuously instead of through core updates. Personalisation – SERPs evolve in real time based on individual user signals. Richer results – entity panels, interactive tools, and dynamic answers.
Seq2Seq Use DSI when your dataset is fixed and small-to- medium scale. Use Use RAG when you need scalability + easy updates. Use Use kNN-LM when you need dynamic adaptation without retraining. Use Use Seq2Seq generative retrievers when you want sequence modeling flexibility with some retrieval grounding. Use
Not Just Keywords 2. Feed the Feedback Loop with satisfying UX 3. Build Stickier Authoritativeness with expertise and freshness 4. Strengthen Contextual Relevance with schema and entity links 5. Drive Engagement with interactive content 6. Stay Adaptable with continuous refreshes and testing
U., 2009. Do not crawl in the DUST: Different URLs with similar text. ACM Transactions on the Web (TWEB), 3(1), pp.1-31. 'On the efficient determination of most nearneighbors: horseshoes, hand grenades, web searchand other situations when close is close enough'(Manasse, 2022) 'Web crawling (Olston, C. and Najork, M., 2010) 'High performance web crawling' (Najork,2002) 'Modern information retrieval' (1999) - Baeza-Yeates
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}