https://lilianweng.github.io/lil-log/2020/01/29/curriculum-for-reinforcement- learning.html • Yoshua Bengio et al. Curriculum learning. ICML, 2009. • Daphna Weinshall et al. Curriculum learning by transfer learning: Theory and experiments with deep networks. ICML, 2018. • Wojciech Zaremba & Ilya Sutskever. Learning to execute. arXiv, 2014. • Tambet Matiisen et al. Teacher-student curriculum learning. IEEE Trans. on neural networks and learning systems, 2017. • Remy Portelas et al. Teacher algorithms for curriculum learning of Deep RL in continuously parameterized environments. CoRL, 2019.
Automatic Curricula via Asymmetric Self-Play. ICLR, 2018. • Carlos Florensa et al. Automatic Goal Generation for Reinforcement Learning Agents ICML, 2019. • Allan Jabri et al. Unsupervised Curricula for Visual Meta-Reinforcement Learning. NeurIPS, 2019. • Andrei A. Rusu et al. Progressive Neural Networks. arXiv, 2016. • Andrei A. Rusu et al. Sim-to-Real Robot Learning from Pixels with Progressive Nets. CoRL, 2017.
{kind=link}
{kind=link}
![Curriculum Learning • Curriculum: 複雑な知識を体系的に分解し、難易度に応じて提供する. • 人間同様, 機械学習においてもCurriculumを導入することが重要 [Elman, 1993].](https://files.speakerdeck.com/presentations/1bd92cc7beca4165be3017e24baa1b0e/slide_2.jpg){kind=link}
![Curriculum Learning • Curriculum Learningの例 [RL, supervised] サブタスクを与える agentを学習することで Curriculumを自動的に構築.](https://files.speakerdeck.com/presentations/1bd92cc7beca4165be3017e24baa1b0e/slide_3.jpg){kind=link}
{kind=link}
![Task-Specific Curriculum • (例1) 他のタスクで学習されたモデルによる損失をデータの難しさとする [Weinshall et al., 2018]. curriculum](https://files.speakerdeck.com/presentations/1bd92cc7beca4165be3017e24baa1b0e/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![Teacher-Guided Curriculum • タスク空間が連続な場合 [Portelas et al., 2019] • タスクのパラメータ𝑝をサンプリングし,](https://files.speakerdeck.com/presentations/1bd92cc7beca4165be3017e24baa1b0e/slide_8.jpg){kind=link}
![Curriculum through Self-Play • 非対称なself-playによってCurriculum Learningを行う [Sukhbaatar et al., 2017].](https://files.speakerdeck.com/presentations/1bd92cc7beca4165be3017e24baa1b0e/slide_9.jpg){kind=link}
{kind=link}
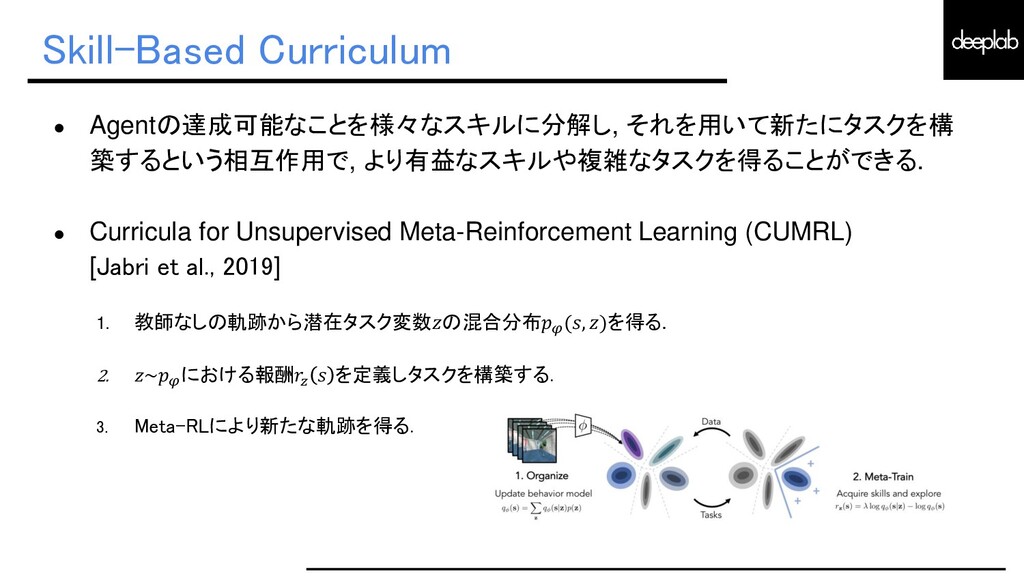{kind=link}
{kind=link}
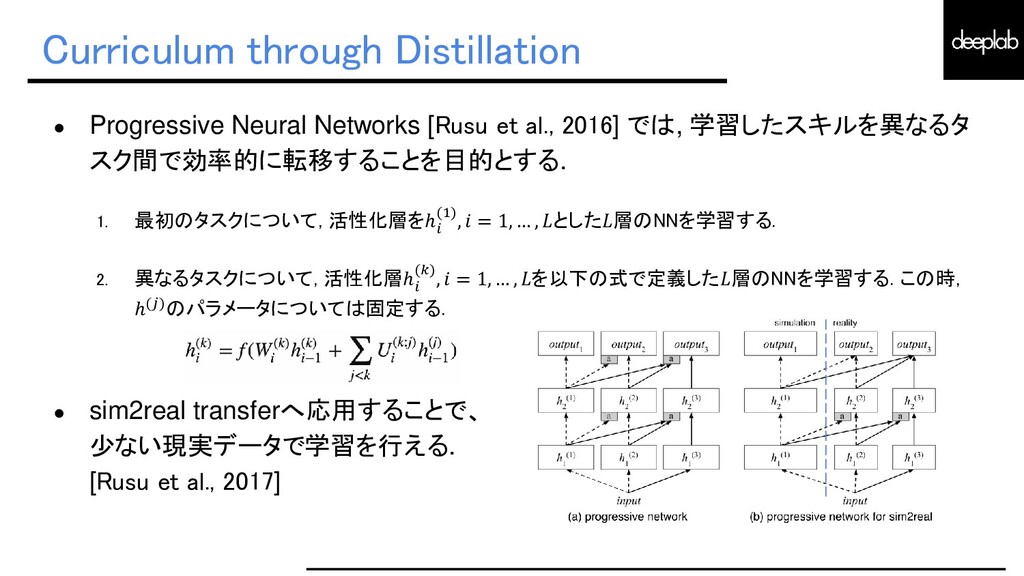{kind=link}
{kind=link}
{kind=link}
{kind=link}