変数例 • Position, shape, and color of objects • Material texture • Lighting condition • Random noise added to images • Position, orientation, and field of view of the camera in the simulator • 主に,ロボット把持のタスクで活用される [Tobin et al., 2017]
Performance タスク性能を報酬として強化学習問題を設定し,その最大化を図る (c.f., NAS, AutoAugment). • Match Real Data Distribution シミュレーション環境と実環境の状態分布をマッチするように学習する. • Guided by Data in Simulator シミュレーションデータを利用して,識別困難なデータを生成し,その上で学習する.
Optimization for Task Performance 2. Match Real Data Distribution 3. Guided by Data in Simulator • 課題: ランダム化した環境の中に実環境に近いものが含まれるという強い仮定 シミュレータが微分不可能な場合に学習が難しくなる
2019. http://lilianweng.github.io/lil-log/2019/05/04/domain-randomization.html • Josh Tobin et al. Domain randomization for transferring deep neural networks from simulation to the real world. IROS, 2017. • Nataniel Ruiz et al. Learning to simulate. ICLR, 2019. • Wenhao Yu et al. Policy transfer with strategy optimization. ICLR, 2019. • Amlan Kar et al. Meta-sim: Learning to generate synthetic datasets. arXiv, 2019. • Yevgen Chebotar et al. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. arXiv, 2019. • Stephen James et al. Sim-to-real via sim-to-sim: Data-efficient robotic grasping via randomized-to-canonical adaptation networks. CVPR, 2019.
{kind=link}
{kind=link}
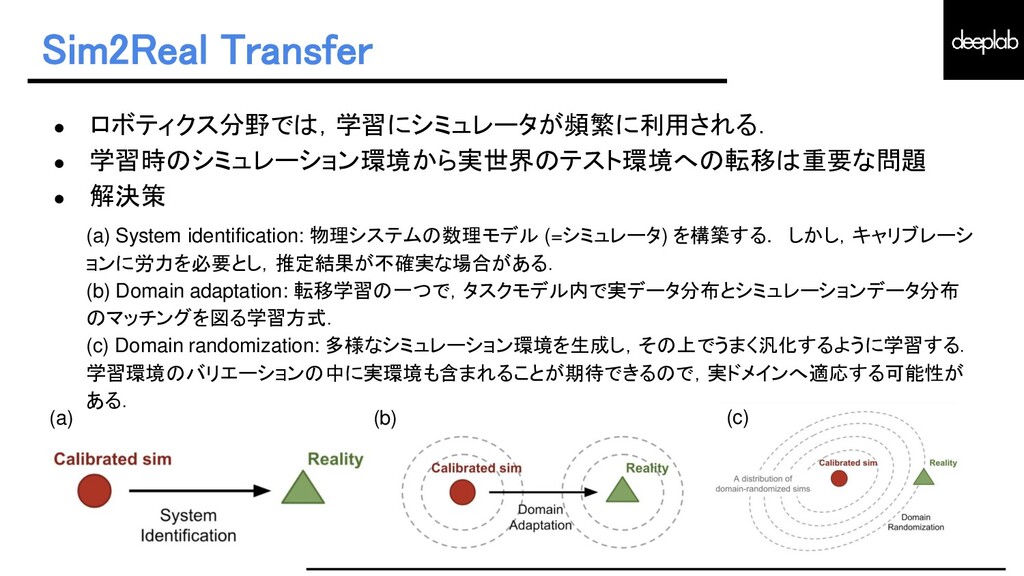{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
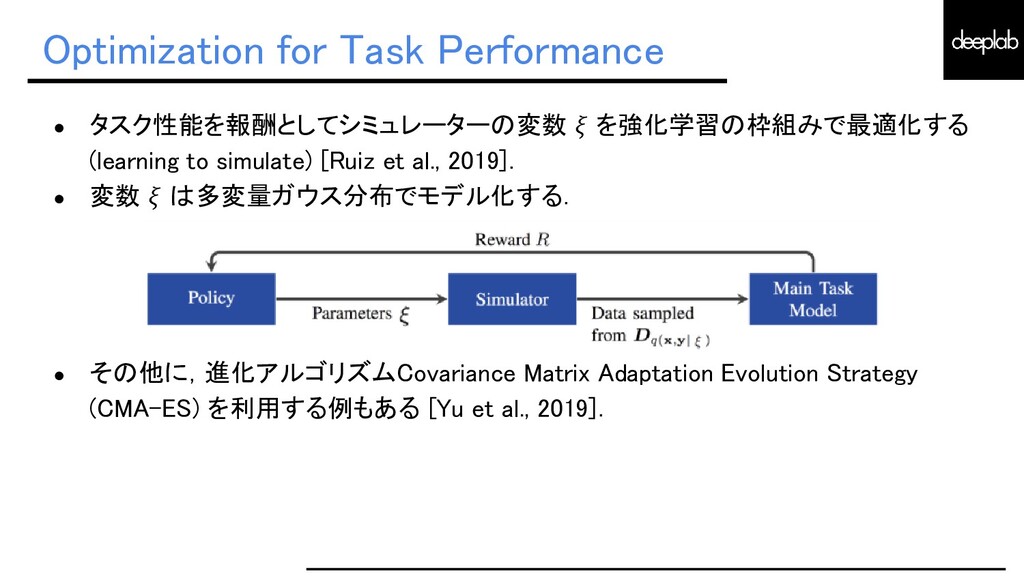{kind=link}
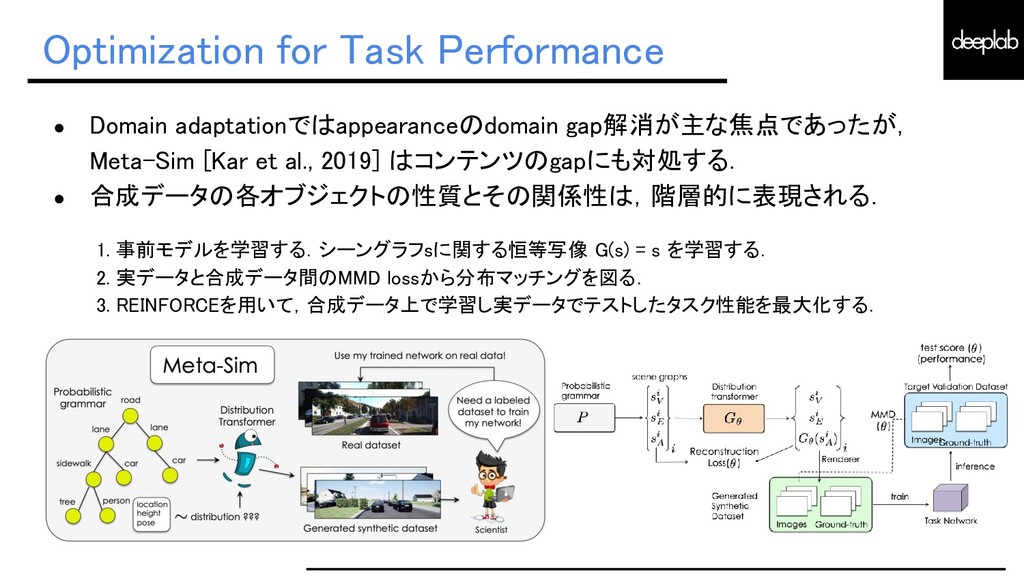{kind=link}
![Match Real Data Distribution • MetaOpt [Chebotar et al., 2019]](https://files.speakerdeck.com/presentations/5508aa2a64e645b9837137cfab5de402/slide_9.jpg){kind=link}
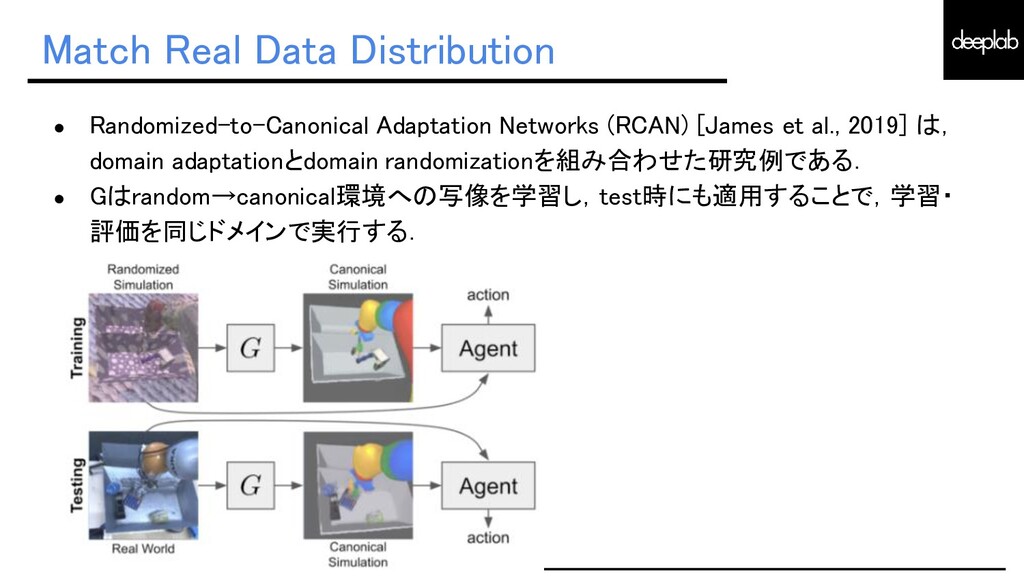{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}