robust features with denoising autoencoders. ICML, 2008. • Richard Zhang et al. Split-brain autoencoders: unsupervised learning by cross- channel prediction. CVPR, 2017. • Jeff Donahue et al. Adversarial feature learning. ICLR, 2017. • Olivier J. Henaff et al. Data-efficient image recognition with contrastive predictive coding. arXiv, 2019. • Kaiming He et al. Momentum contrast for unsupervised visual representation learning. CVPR, 2020. • Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos. ICCV, 2015.
unsupervised learning using temporal order verification. ECCV, 2016. • Carl Vondrick et al. Tracking emerges by colorizing videos. ECCV, 2018. • Eric Jang et al. Grasp2Vec: learning object representations from self-supervised grasping. CoRL, 2018. • Pierre Sermanet et al. Time-contrastive networks: self-supervised learning from video. CVPR, 2018. • Ashvin Nair et al. Visual reinforcement learning with imagined goals. NeurIPS, 2018. • Carles Gelada et al. DeepMDP: learning continuous latent space models for representation learning. ICML, 2019. • Amy Zhang et al. Learning invariant representations for reinforcement learning without reconstruction. arXiv, 2020.
{kind=link}
{kind=link}
![Self-Supervised Learning • ラベル付きデータの拡張性の問題から教師なし学習の利用が期待されている. • 教師あり学習のタスクを特別に設計することで自己教師あり学習を行う. • 自然言語処理において入力データのみを用いた自己教師あり学習がよく行われる. [LeCun, 2018]](https://files.speakerdeck.com/presentations/f37dbbc9ec98468eb952bab8f9e2f2ef/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
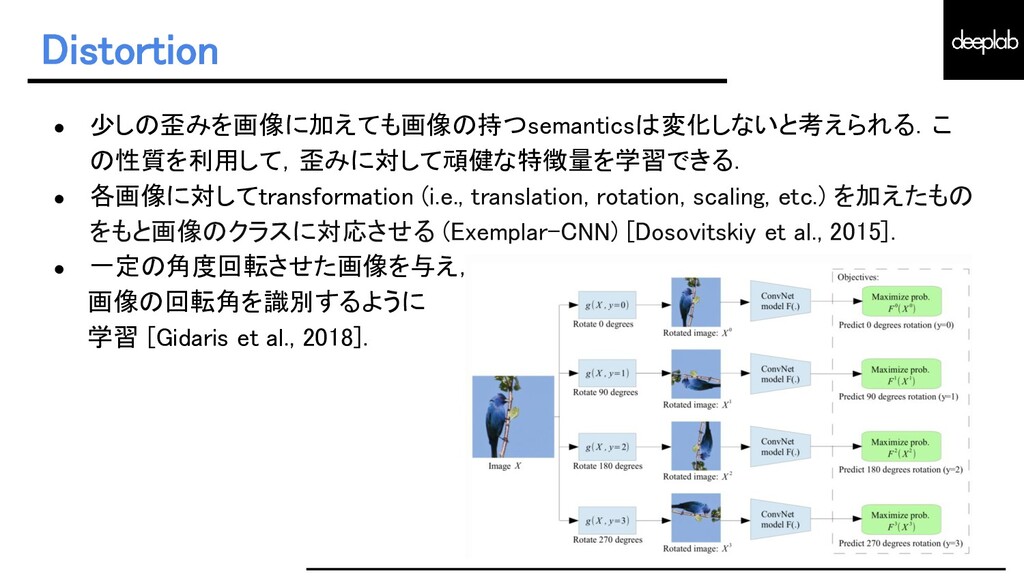{kind=link}
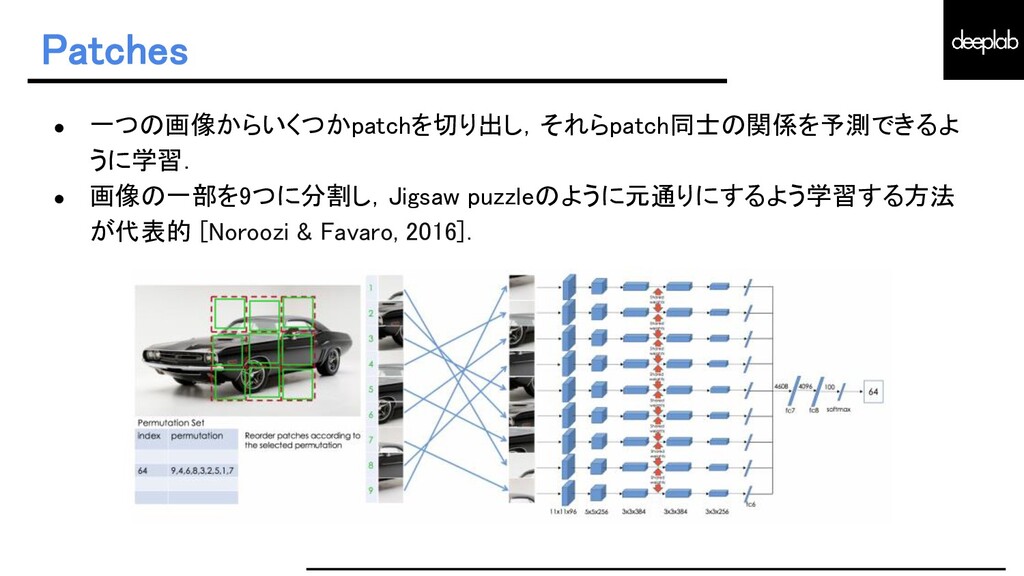{kind=link}
![Colorization • グレースケールの入力画像に色を付けるように学習させる [Zhang et al., 2016]. • RGBやCMYKといったカラーモデルではなく,CIE Lab*](https://files.speakerdeck.com/presentations/f37dbbc9ec98468eb952bab8f9e2f2ef/slide_7.jpg){kind=link}
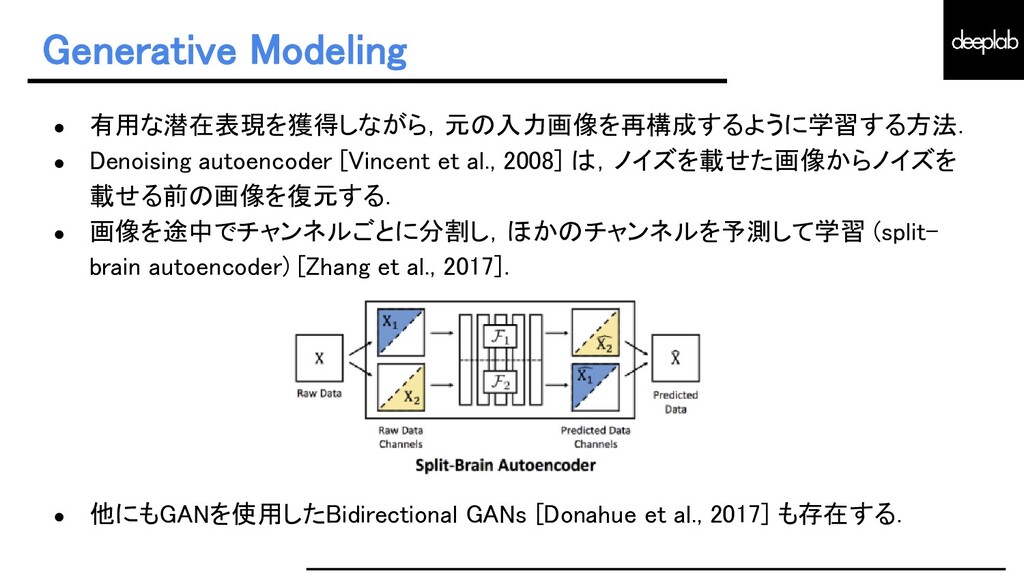{kind=link}
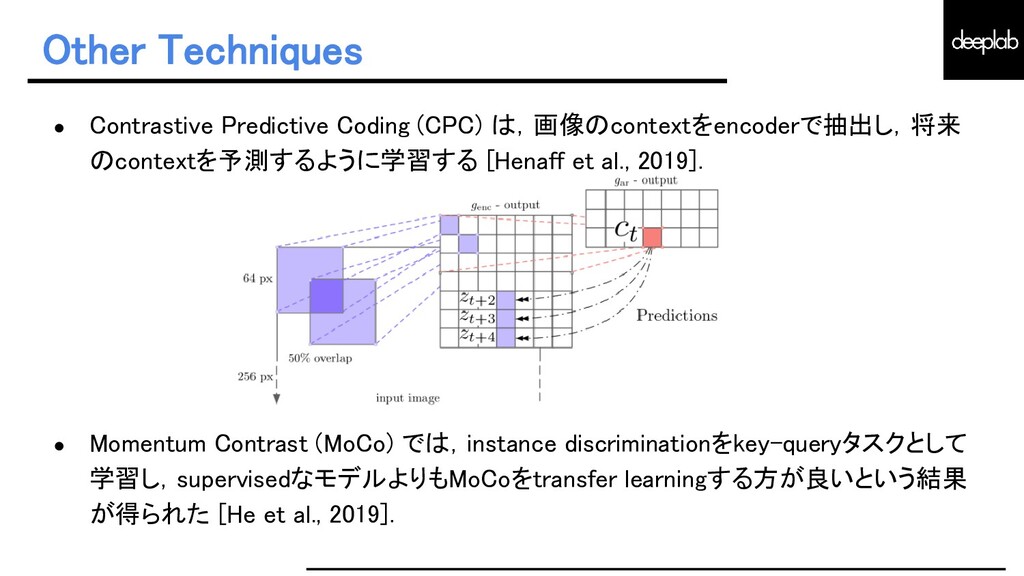{kind=link}
{kind=link}
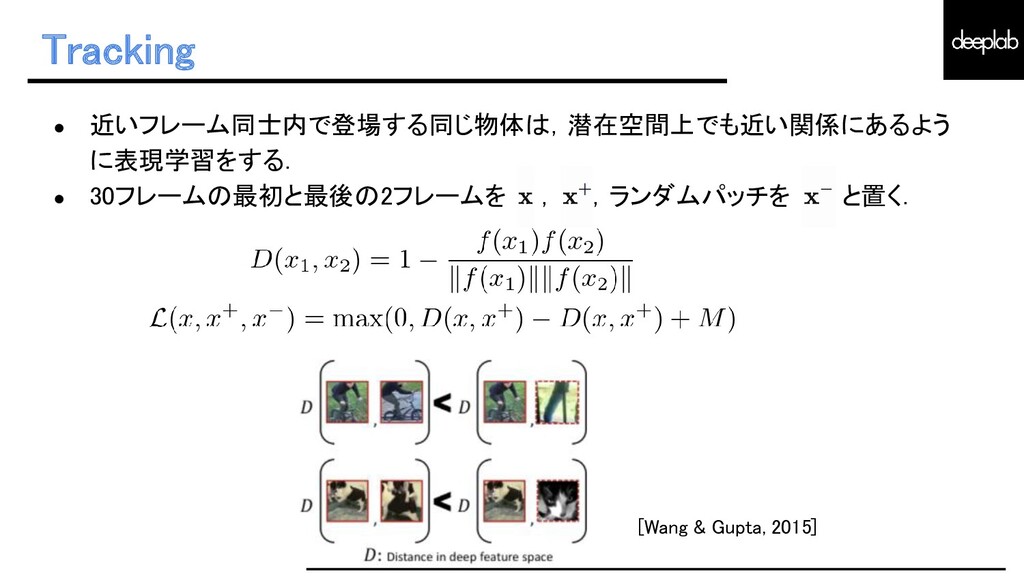{kind=link}
![Frame Sequence • 動画タスクにおいて良い表現とは,フレームの時系列関係が学習できているもの. • 事前学習として,動画のフレームの並びが適当かどうか判定する [Misra et al., 2016].](https://files.speakerdeck.com/presentations/f37dbbc9ec98468eb952bab8f9e2f2ef/slide_12.jpg){kind=link}
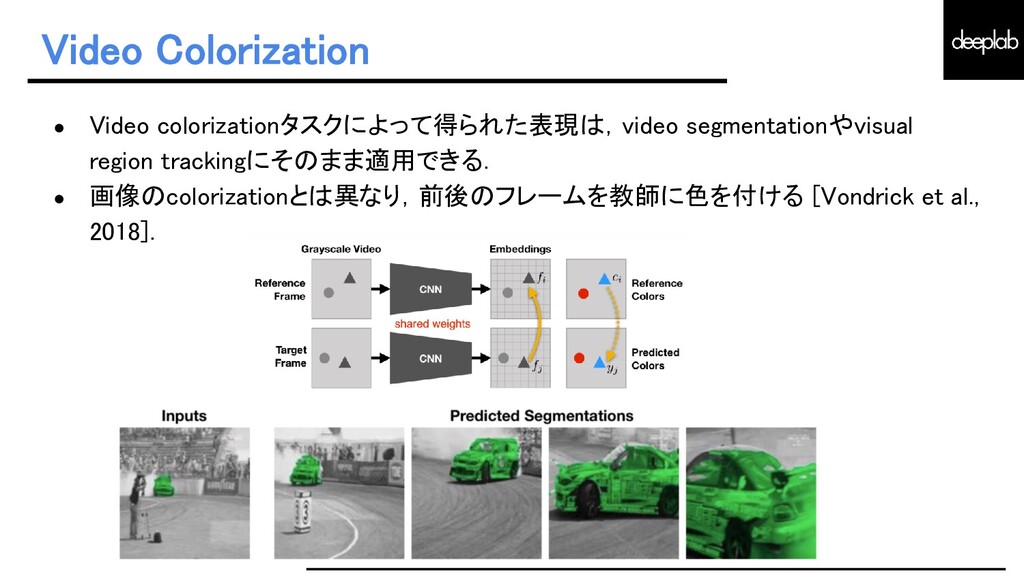{kind=link}
{kind=link}
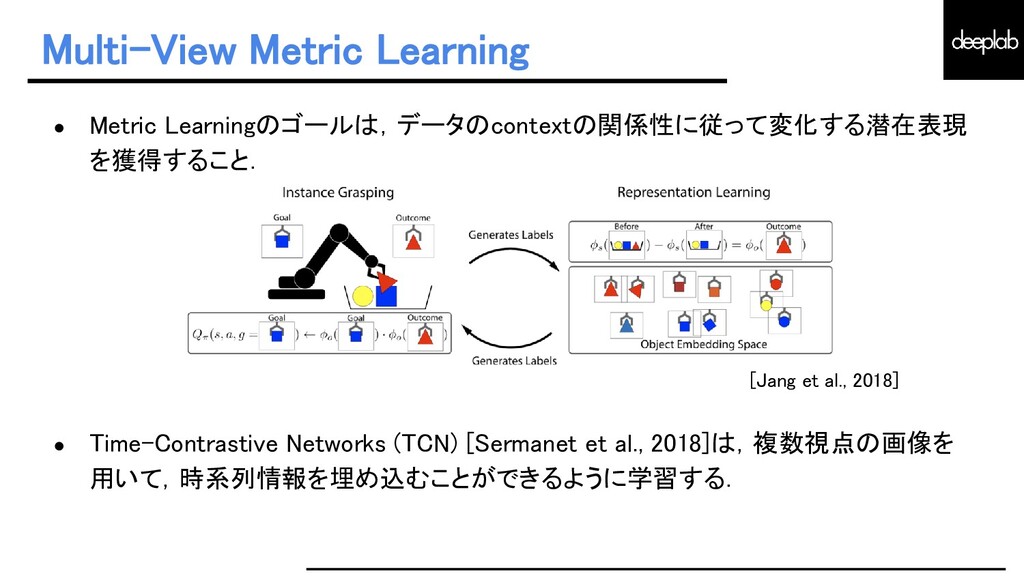{kind=link}
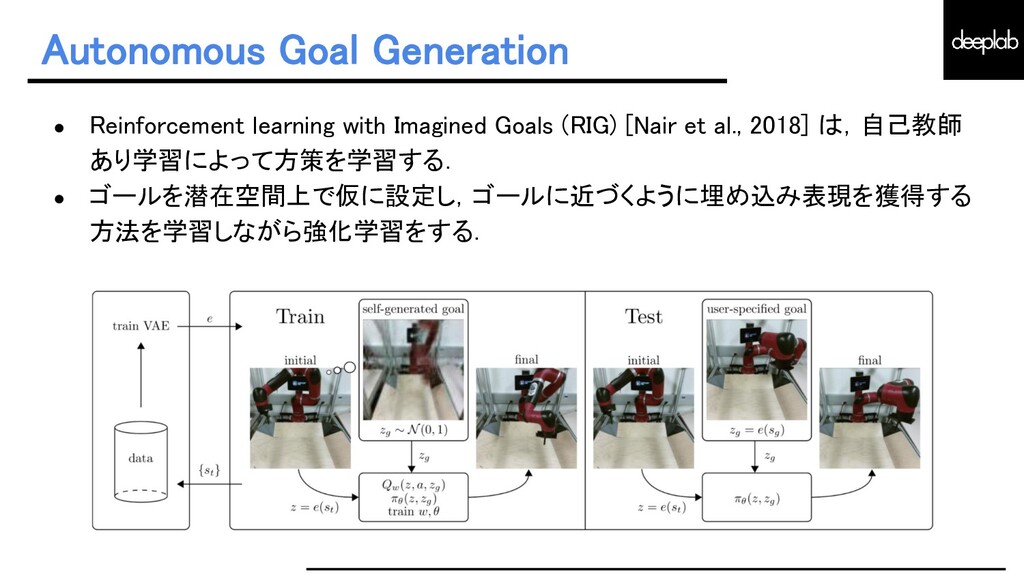{kind=link}
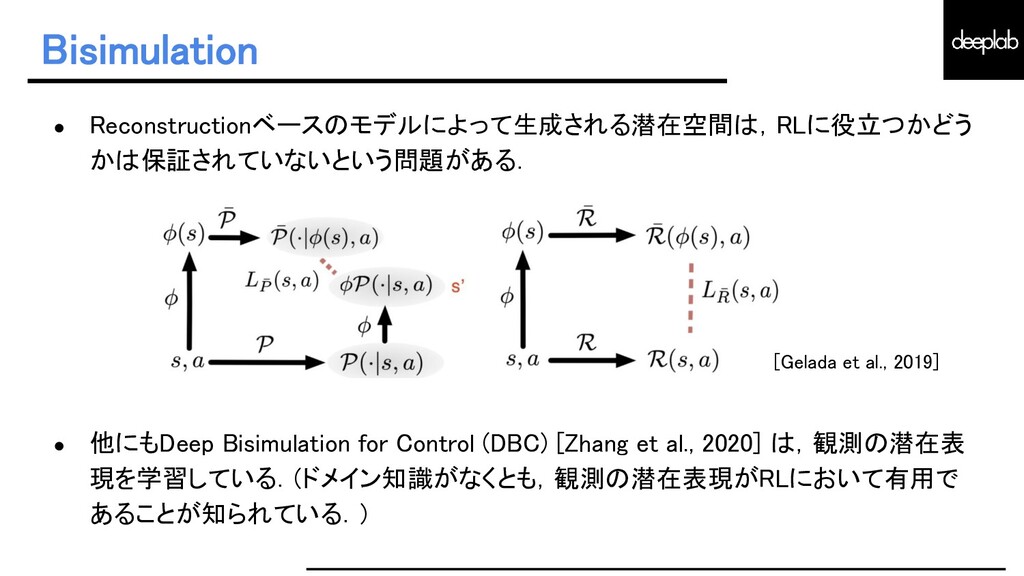{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}