https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html • Gregory Koch et al. Siamese neural networks for one-shot image recognition. ICML Deep Learning Workshop, 2015. • Oriol Vinyals et al. Matching networks for one shot learning. NeurIPS, 2016. • Flood Sung et al. Learning to compare: Relation network for few-shot learning. CVPR, 2018. • J. Ba et al. Using Fast Weights to Attend to the Recent Past. NeurIPS, 2016. • Tsendsuren Munkhdalai and Hong Yu. Meta Networks. ICML, 2017. • Sachin Ravi and Hugo Larochelle. Optimization as a Model for Few-Shot Learning. ICLR, 2017.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
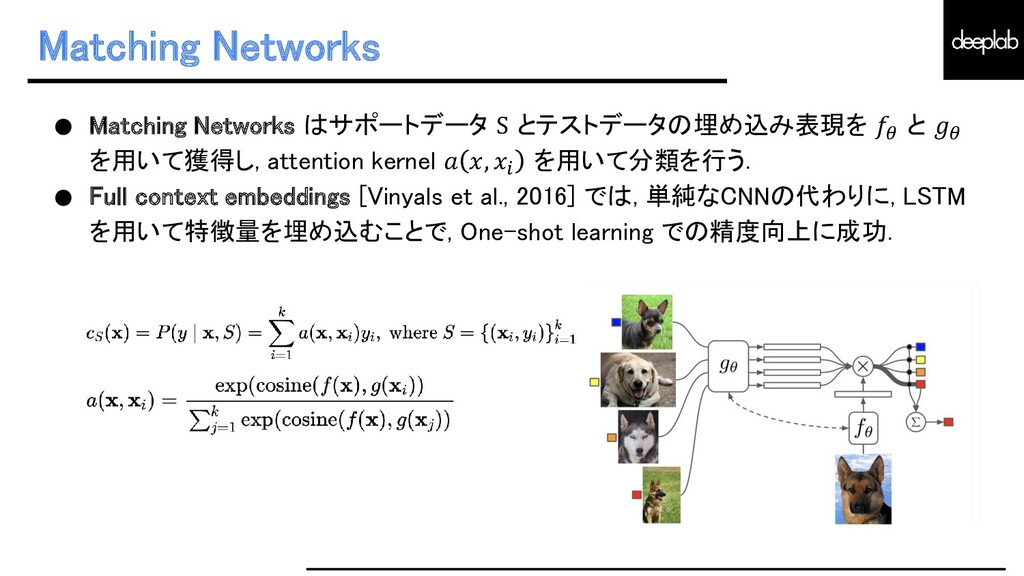{kind=link}
![Relation Network • Relation Network (RN) [Sung et al., 2018]](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_9.jpg){kind=link}
![Prototypical Network • Prototypical Network [Snell, Swersky & Zemel, 2017]](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_10.jpg){kind=link}
{kind=link}
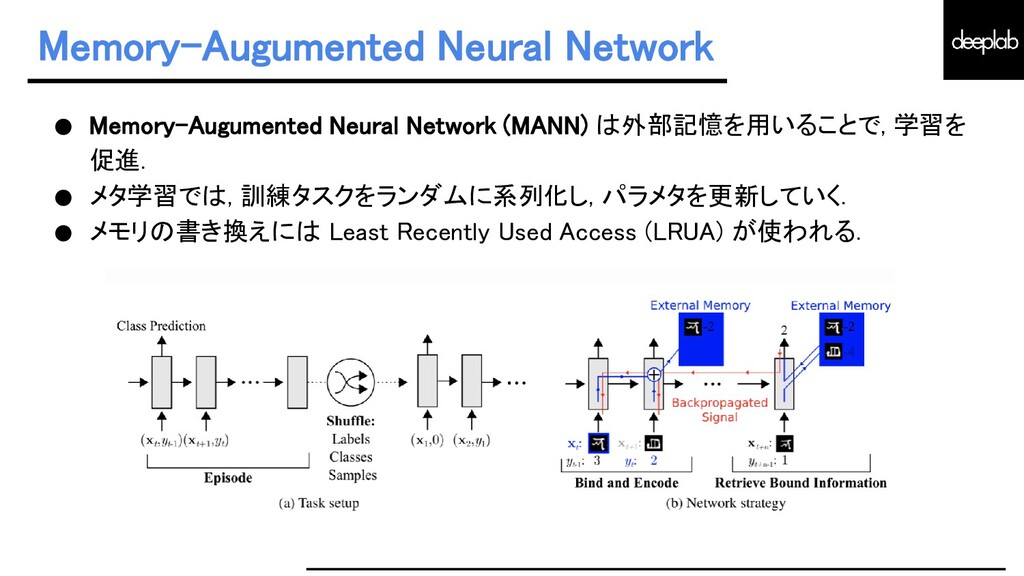{kind=link}
![Meta Networks • Meta Networks [Munkhdali & Yu, 2017] は](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_13.jpg){kind=link}
{kind=link}
![• 勾配によるパラメタの更新の代わりに, LSTM のセルをタスクのパラメタとし, 学習を 行う. [Ravi&Larochelle, 2017] • ミニバッチを用いて](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_15.jpg){kind=link}
![MAML • Model-Agonistic Meta-Learning (MAML) [Finn, et al. 2017] はタスクのミニバッチ](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_16.jpg){kind=link}
![Reptile • Reptile [Nichol, Achiam & Schulman, 2018] はMAMLと比べて, シンプルな最適化ア](https://files.speakerdeck.com/presentations/3ca81b6f28124cdfa510953139299461/slide_17.jpg){kind=link}
{kind=link}
{kind=link}