and its solutions. https://lilianweng.github.io/lil-log/2018/01/23/the-multi-armed-bandit-problem- and-its-solutions.html • CS229 supplemental lecture notes: Hoeffding’s inequality. • RL Course by David Silver - Lecture 9: Exploration and exploitation. • Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sampling. NeurIPS, 2011. • Daniel Russo et al. A tutorial on Thompson sampling. arXiv, 2017. • Fernando Amat et al. Artwork personalization at Netflix. RecSys, 2018. • David Silver et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Hoeffding’s Inequality • 個の[0,1]にスケーリングされた独立同分布のサンプル について, 以下へフディングの不等式が成立する. • 先程のUCBの問題に置き換えると,報酬は確率関数と見なせるので, • 式展開により,UCBを得る.](https://files.speakerdeck.com/presentations/35d0fcc90ecb4043ab9505f1c1502173/slide_9.jpg){kind=link}
{kind=link}
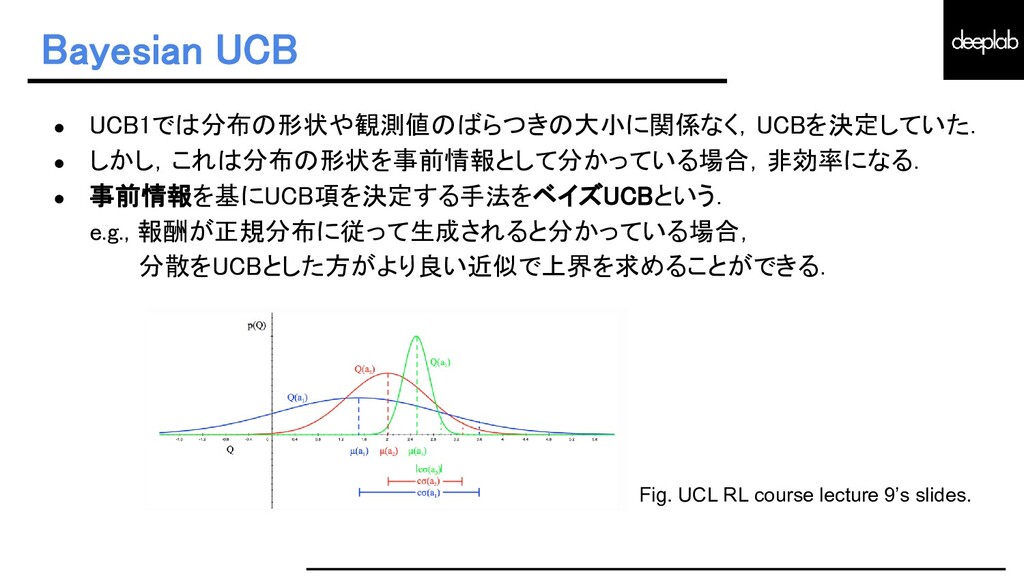{kind=link}
{kind=link}
{kind=link}
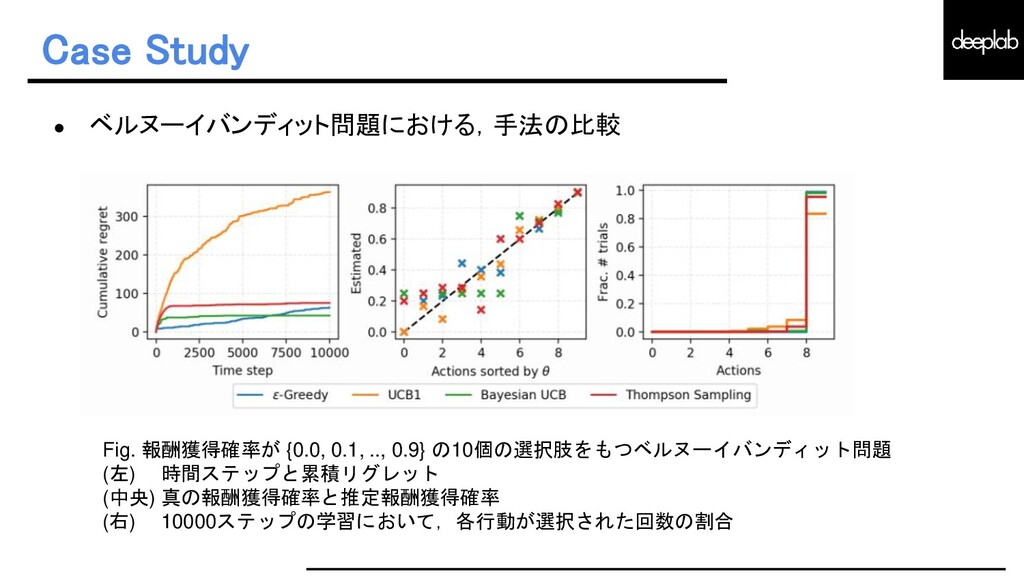{kind=link}
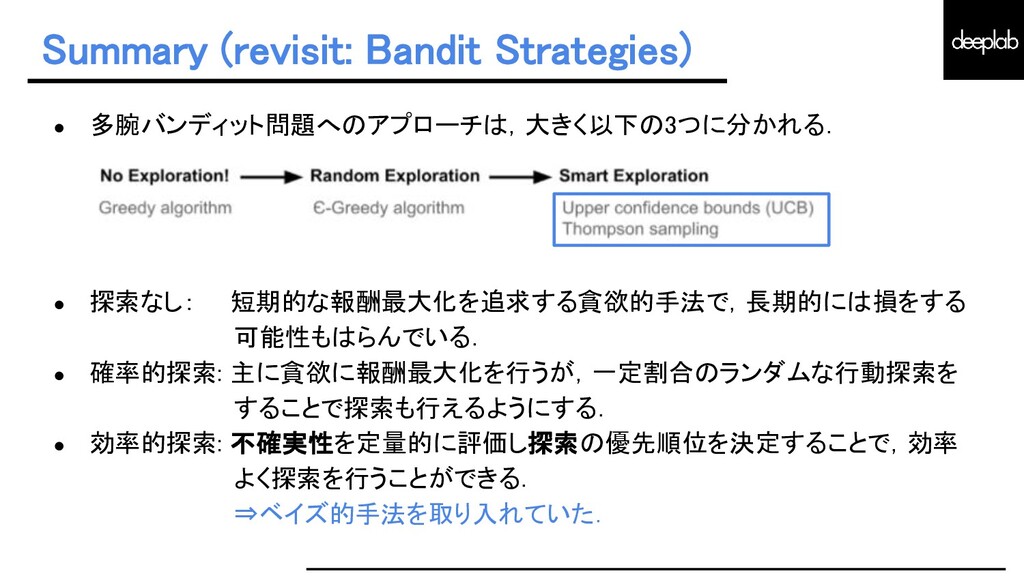{kind=link}
{kind=link}
{kind=link}