[11:40am] dehora: 10.53.53.155 eu-west 1a Up Normal 895.21 MB 75.00% 0 [11:40am] dehora: 10.64.110.63 eu-west 1b Up Normal 851.05 MB 75.00% 42535295865117307932921825928971026432 [11:40am] dehora: 10.55.65.71 eu-west 1a Up Normal 892.55 MB 75.00% 85070591730234615865843651857942052864 [11:40am] dehora: 10.251.39.177 eu-west 1b Down Normal 430.73 MB 75.00% 127605887595351923798765477786913079296 [11:40am] matthew :O [11:40am] dehora: the last node’s instance doesn't exist anymore, but system’s fine [11:41am] dehora: asg spun up a new node, but it has a random token so didn't autojoin [11:41am] matthew: eugh >:( [11:41am] matthew: should Priam not have handled that? [11:41am] dehora: yes, but it can't [11:42am] dehora: the ami we're using here has a bug/feature (apache .deb starts cassandra which means priam can't assign) [11:42am] dehora: the latest ami (0.2.3) has a fix for that [11:45am] dehora: k, i'll remove that node and bring in a new one on c, done with testing 2 zone evac anyway Node loss - still 100% available
as possible & burn AMIs Use a management tool (DSE, OpsCenter, Priam) Set consistencylevel as QUORUM in the CLI Monitor growth in load Consider getting support Ask for help - mailing list, lots of community expertise
data access Avoid heavy delete after writes (queues) Avoid read before writes (usually) Understand your client Model, don’t prototype RDBMS if you need a lock Redis/RDBMS if you need precision counters Allow time to relearn & get productive
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[11:40am] dehora: lol, ec2 killed one of the events nodes](https://files.speakerdeck.com/presentations/75b06c40cc6a0130edcb46d00e8e686b/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
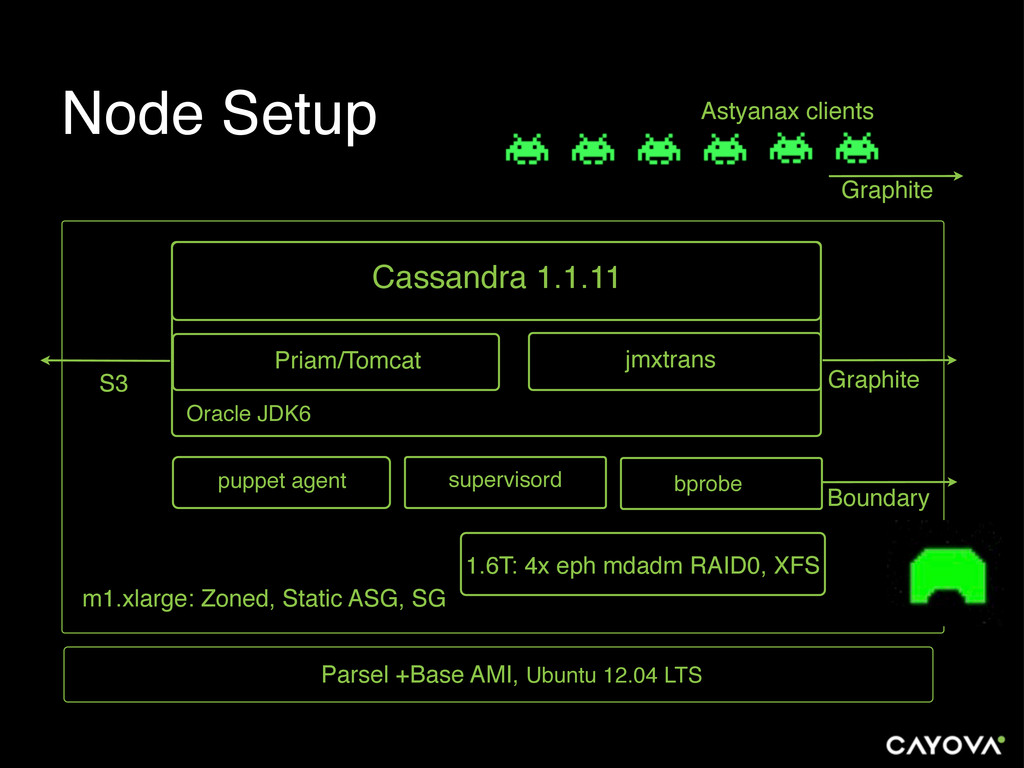{kind=link}
{kind=link}
{kind=link}
{kind=link}
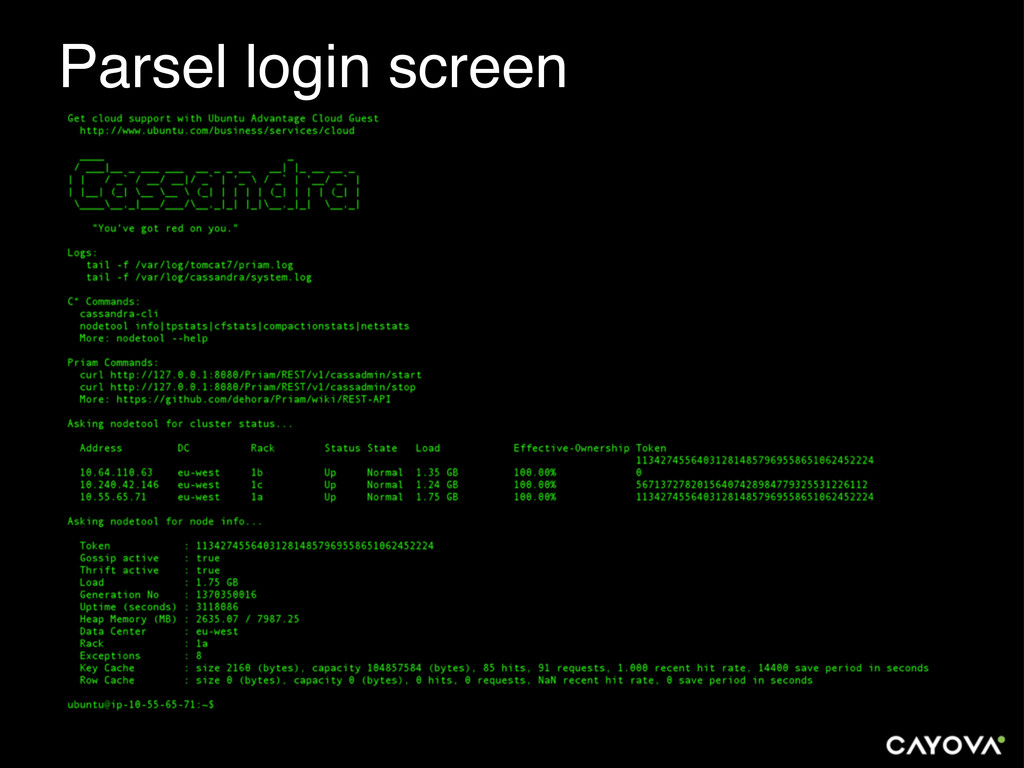{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}