Митап на тему "Мониторинг", 16-05-2018
Михаил Прокопчук, Avito
Михаил рассказал, с чего начинался мониторинг облачной инфраструктуры в Авито, к чему компания пришла сегодня и куда планируется двигаться дальше. Подробно рассказал о тех инструментах и подходах, которые для этого используются.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1. CPU sum by(pod_name, namespace) (rate(container_cpu_usage_seconds_total{job="kubelet"}[1m])) Query time (dev-кластер): ~5s](https://files.speakerdeck.com/presentations/bf22df4b42c04413be585ee79a67a3af/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
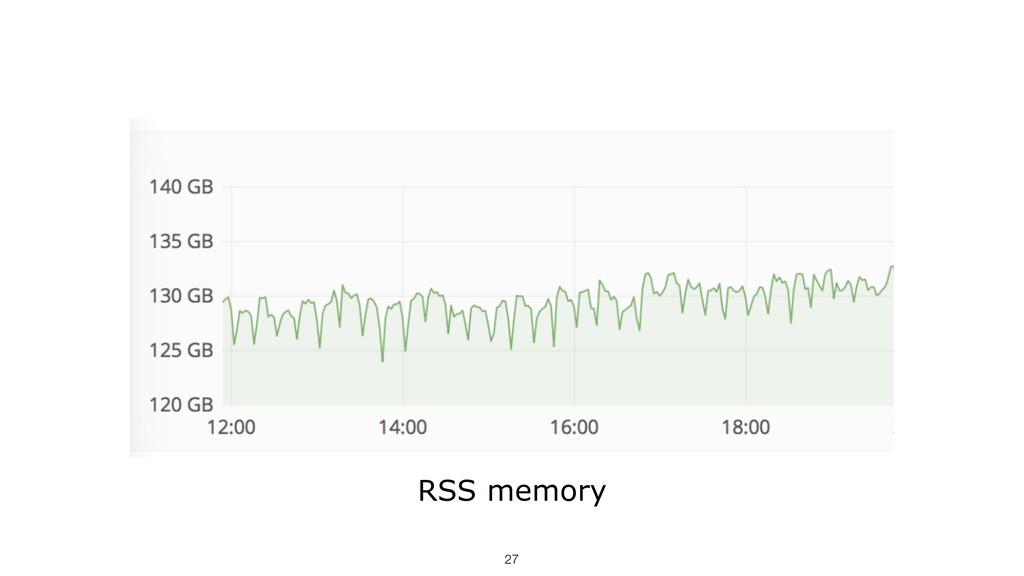{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
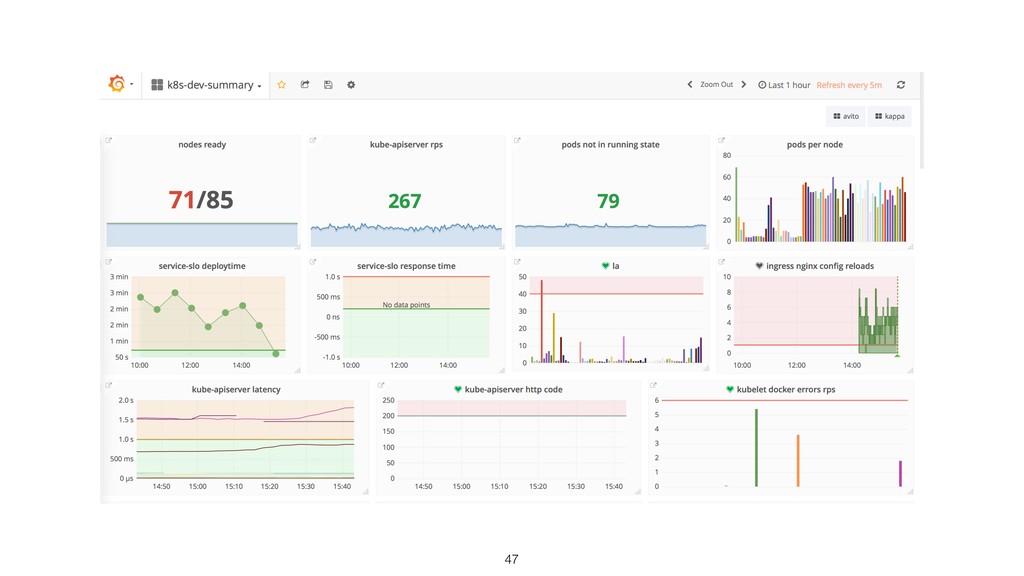{kind=link}
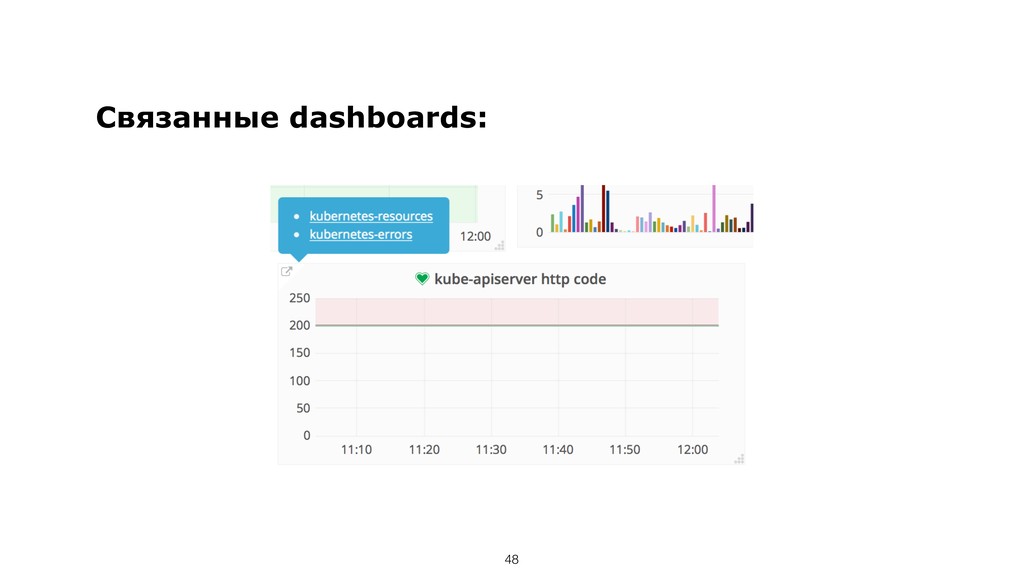{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}