impedance was important: relational DB not a good fit Clustering built in JSON document base for easy-ish doc translation Lucene query syntax is supported Fast!
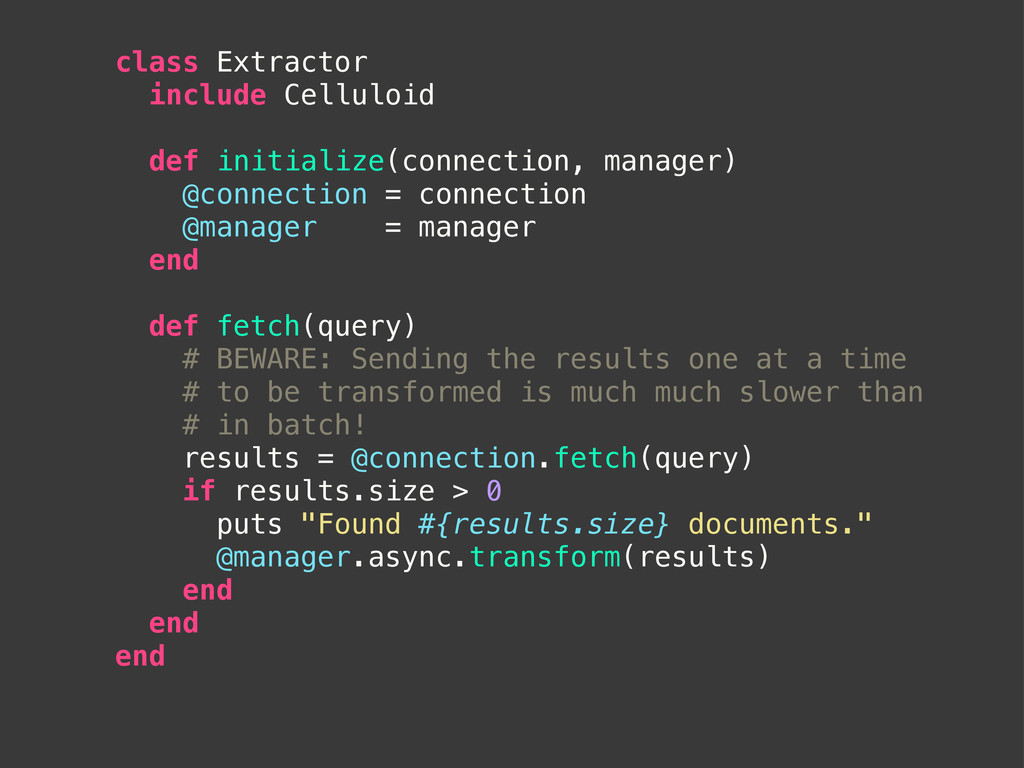
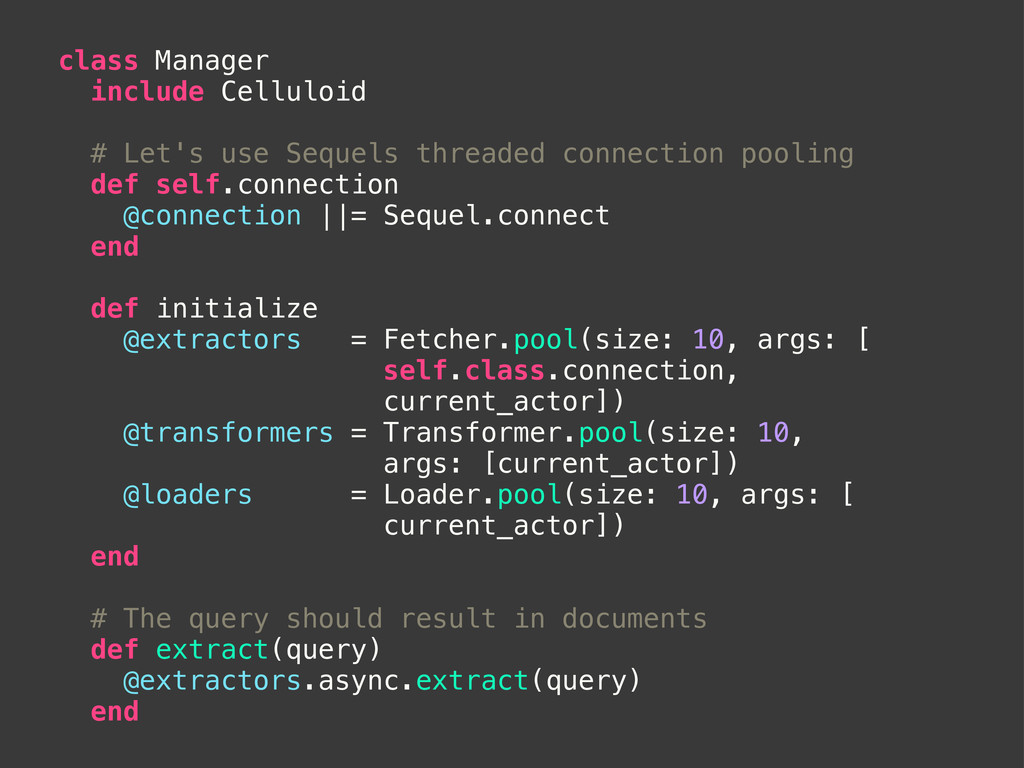
@manager = manager end def fetch(query) # BEWARE: Sending the results one at a time # to be transformed is much much slower than # in batch! results = @connection.fetch(query) if results.size > 0 puts "Found #{results.size} documents." @manager.async.transform(results) end end end
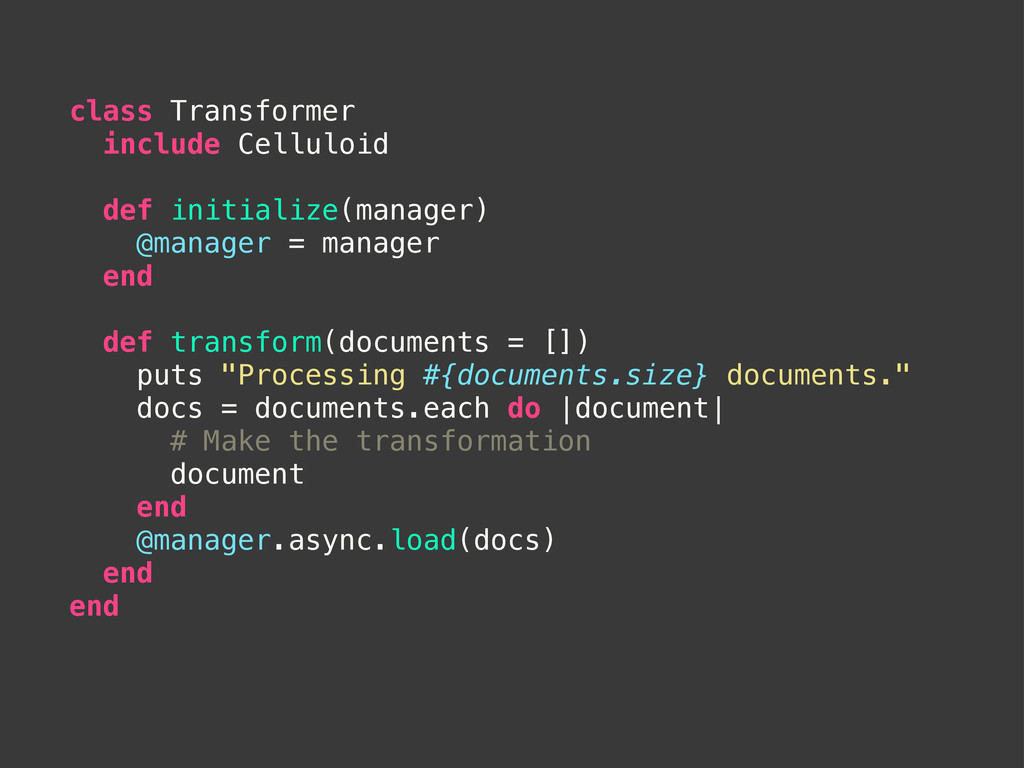
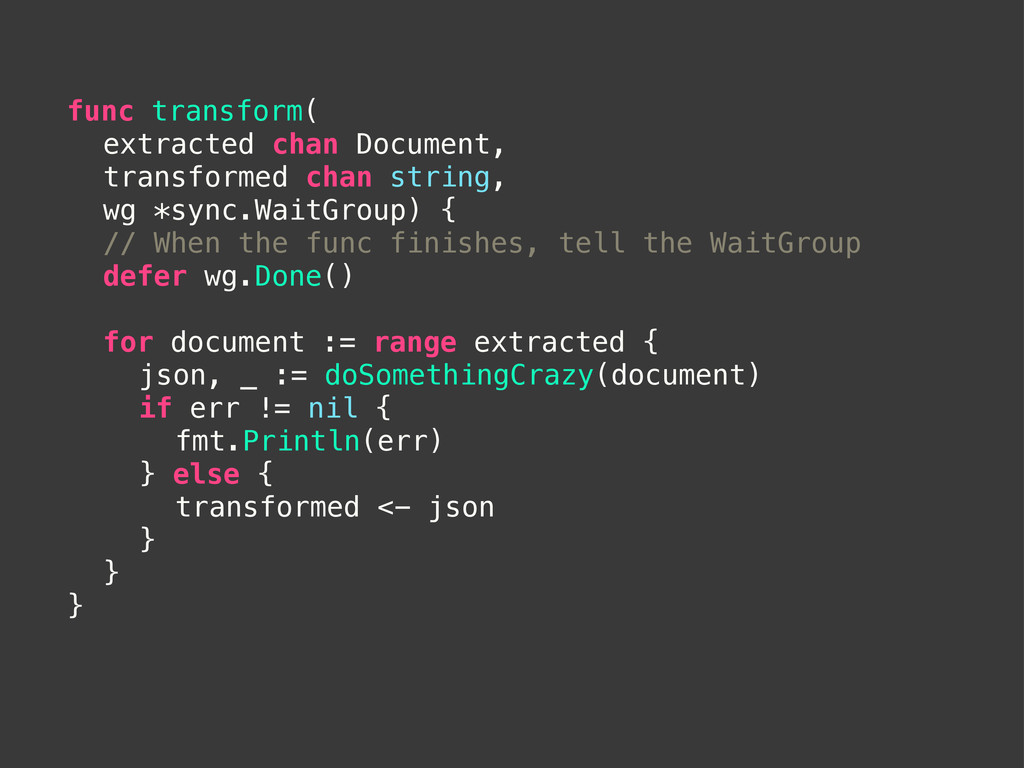
def transform(documents = []) puts "Processing #{documents.size} documents." docs = documents.each do |document| # Make the transformation document end @manager.async.load(docs) end end
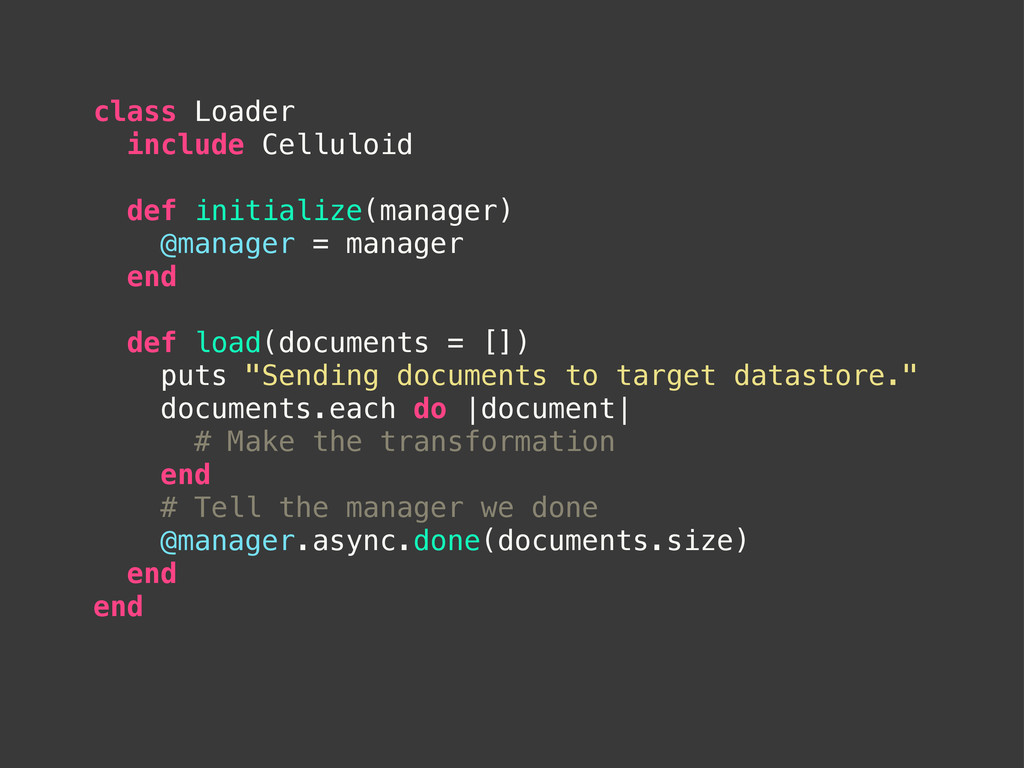
def load(documents = []) puts "Sending documents to target datastore." documents.each do |document| # Make the transformation end # Tell the manager we done @manager.async.done(documents.size) end end
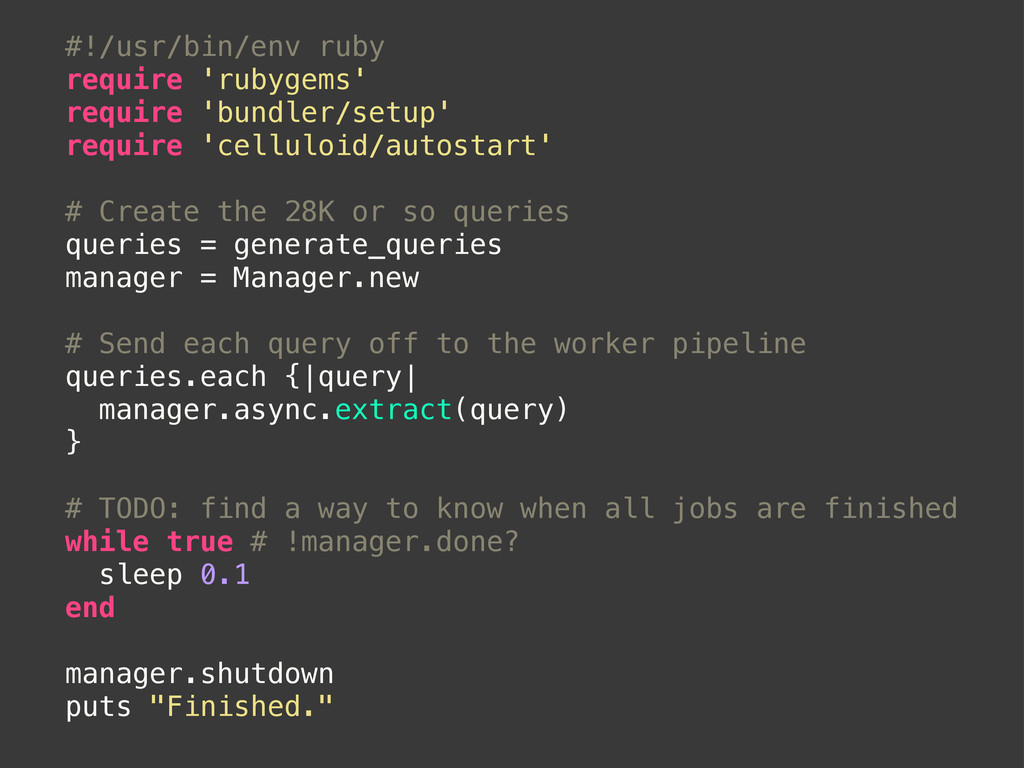
the 28K or so queries queries = generate_queries manager = Manager.new # Send each query off to the worker pipeline queries.each {|query| manager.async.extract(query) } # TODO: find a way to know when all jobs are finished while true # !manager.done? sleep 0.1 end manager.shutdown puts "Finished."
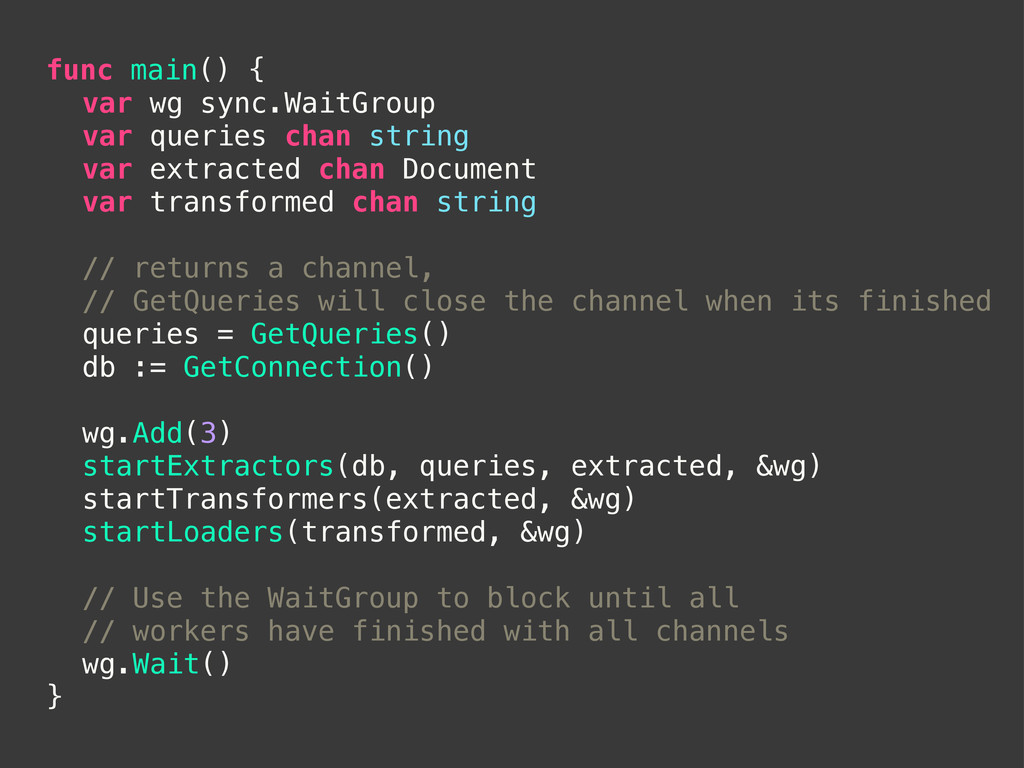
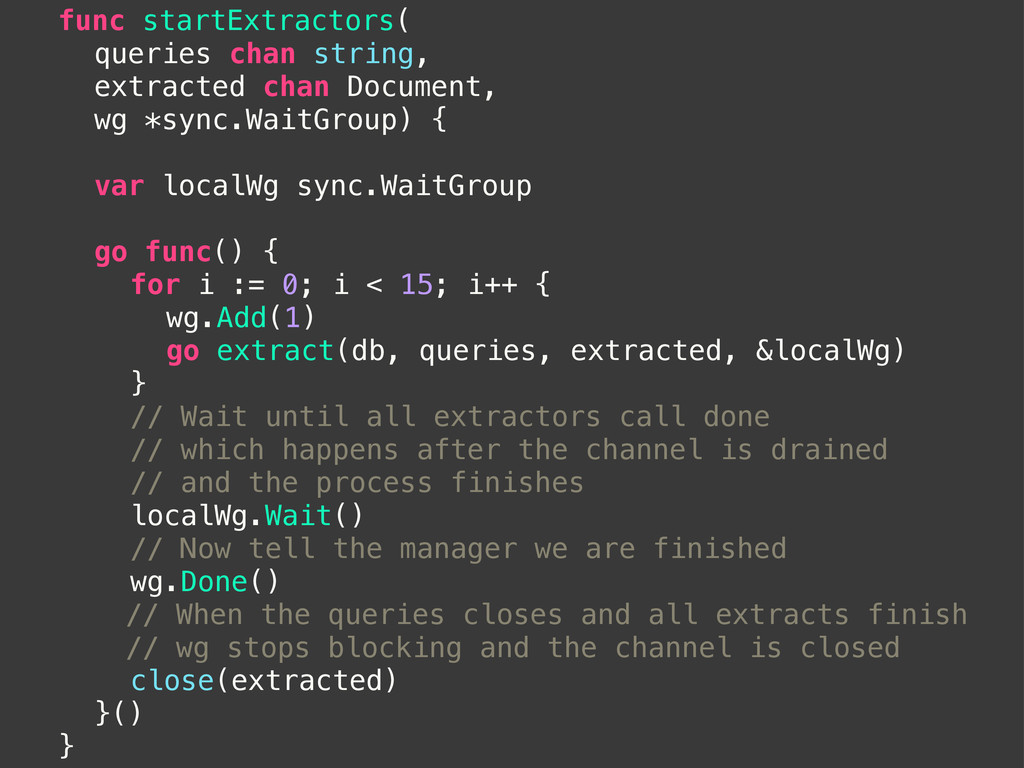
chan string ! var extracted chan Document ! var transformed chan string ! // returns a channel, ! // GetQueries will close the channel when its finished ! queries = GetQueries() ! db := GetConnection() ! ! wg.Add(3) ! startExtractors(db, queries, extracted, &wg) ! startTransformers(extracted, &wg) ! startLoaders(transformed, &wg) ! // Use the WaitGroup to block until all ! // workers have finished with all channels ! wg.Wait() }
{ ! var localWg sync.WaitGroup ! go func() { ! ! for i := 0; i < 15; i++ { ! ! ! wg.Add(1) ! ! ! go extract(db, queries, extracted, &localWg) ! ! } ! ! // Wait until all extractors call done ! ! // which happens after the channel is drained ! ! // and the process finishes ! ! localWg.Wait() ! ! // Now tell the manager we are finished ! ! wg.Done() // When the queries closes and all extracts finish // wg stops blocking and the channel is closed ! ! close(extracted) ! }() }
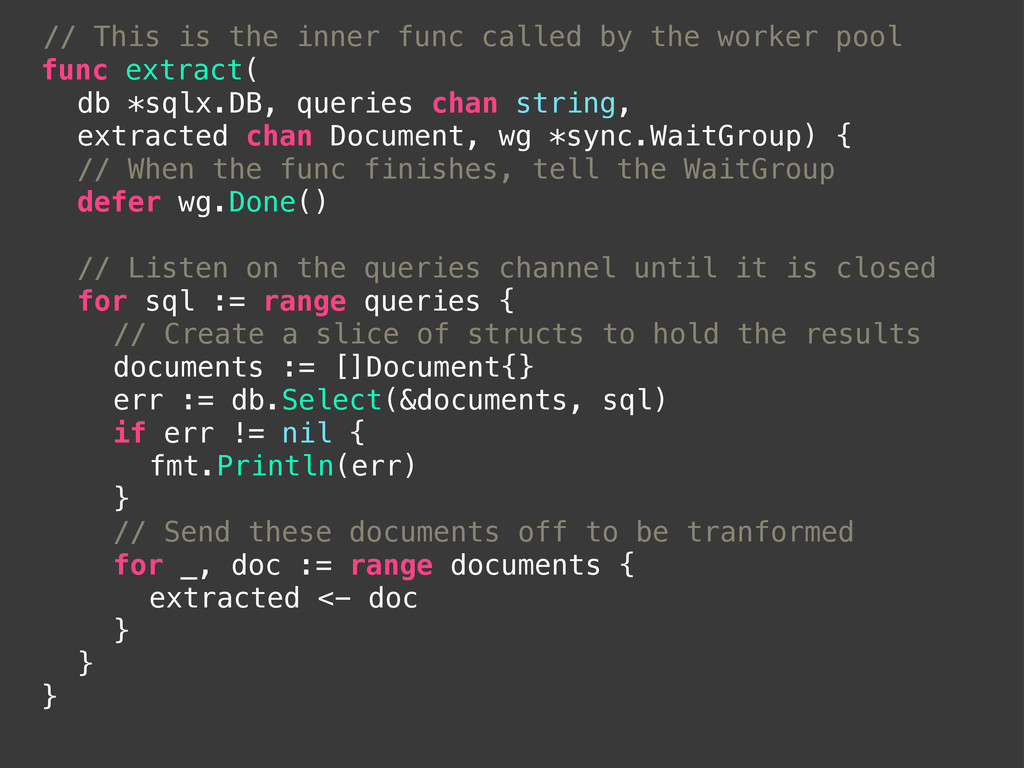
wg *sync.WaitGroup) { ! // When the func finishes, tell the WaitGroup ! defer wg.Done() ! // Listen on the queries channel until it is closed ! for sql := range queries { ! ! // Create a slice of structs to hold the results ! ! documents := []Document{} ! ! err := db.Select(&documents, sql) ! ! if err != nil { ! ! ! fmt.Println(err) ! ! } ! ! // Send these documents off to be tranformed ! ! for _, doc := range documents { ! ! ! extracted <- doc ! ! } ! } } // This is the inner func called by the worker pool
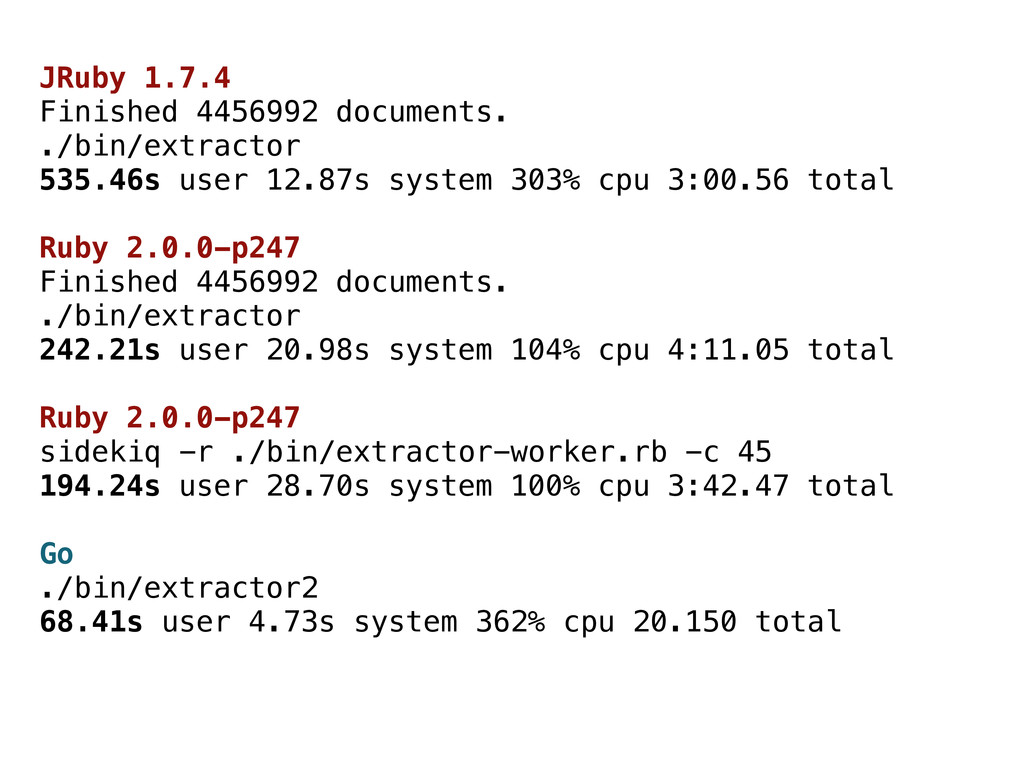
303% cpu 3:00.56 total Ruby 2.0.0-p247 Finished 4456992 documents. ./bin/extractor 242.21s user 20.98s system 104% cpu 4:11.05 total Ruby 2.0.0-p247 sidekiq -r ./bin/extractor-worker.rb -c 45 194.24s user 28.70s system 100% cpu 3:42.47 total Go ./bin/extractor2 68.41s user 4.73s system 362% cpu 20.150 total
the system NSQ is a good external queue solution for Go In Ruby, using many Sidekiq processes can help with batch management and CPU utilization. This could also be achieved by forking other such process spawning - its just that Sidekiq makes it pretty simple and its easy enough to have it’s workers run your Celluloid actors. Instead of shelling out, a message bus or queue can be used to coordinate the activities of heterogeneous processes. Context dependent of course. MarkLogic is another early document-based store based on XML and XQuery. Company was founded in 2001, though its not immediately clear when the database was released.
{kind=link}
![Giant Machines [email protected] We Program.](https://files.speakerdeck.com/presentations/ce8f1e90cb90013079447e4693246c88/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}