Liste von Einträgen Start der Suche bei mittlerem Eintrag; Vergleich des Suchschlüssels mit dem Eintrag Ist der gesuchte Eintrag gefunden, so ist die Suche beendet Ansonsten: Suche in der linken oder der rechten Hälfte der Einträge - je nachdem, ob der gelesene Schlüssel größer oder kleiner war als der Suchschlüssel Verfahren so lange, bis der Eintrag gefunden ist oder bis keine Halbierung des Suchraums mehr möglich ist (d.h. man ist an der Stelle angekommen, an der der Eintrag eigentlich stehen müsste). Binäre Suche Quelle und Bildnachweis: http://www-i1.informatik.rwth-aachen.de/~algorithmus/algo1.php
![Universität zu Köln. Historisch-Kulturwissenschaftliche Informationsverarbeitung Jan G. Wieners // [email protected]](https://files.speakerdeck.com/presentations/284bc9c0415c01309e46123139180b39/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
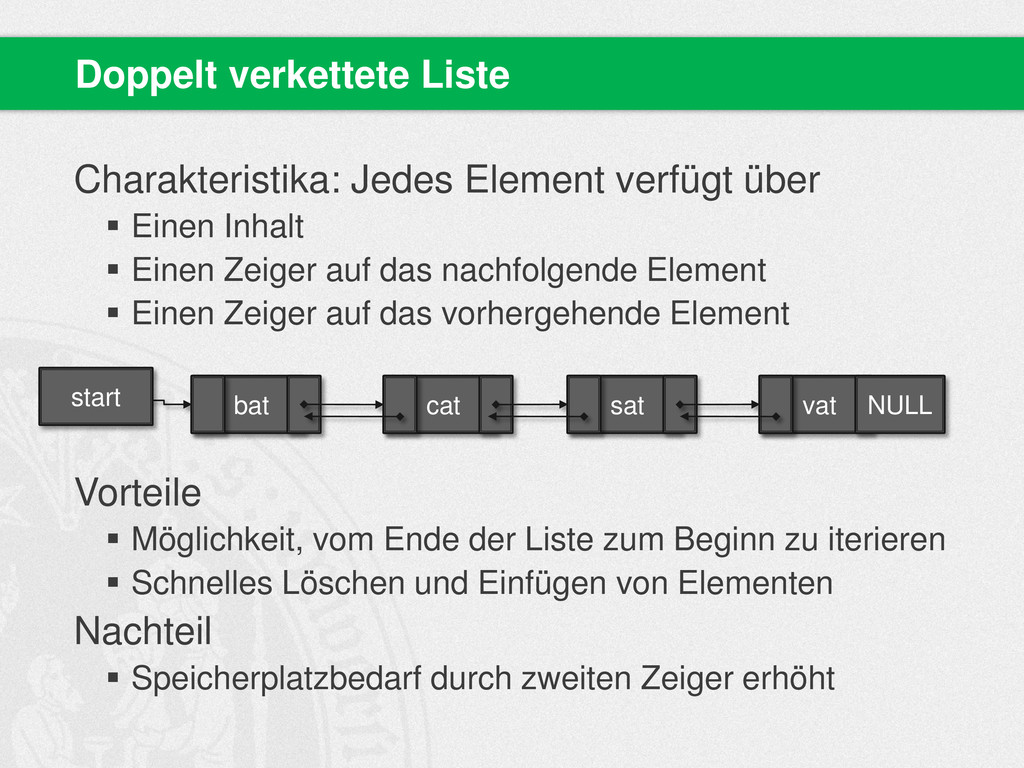{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
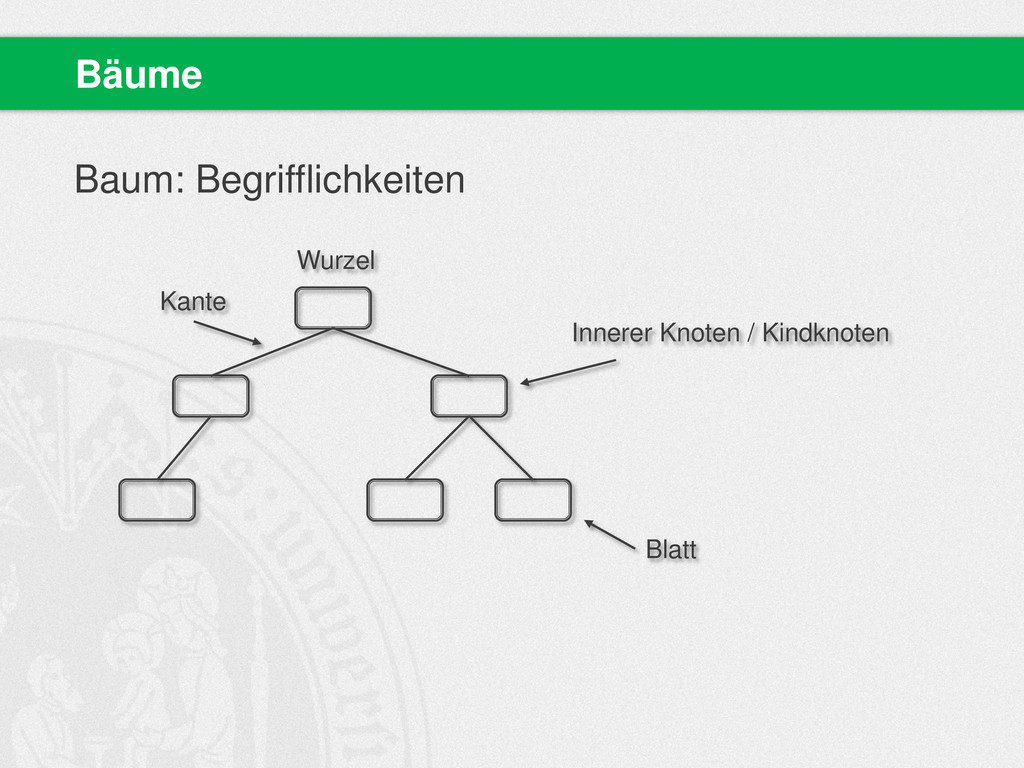{kind=link}
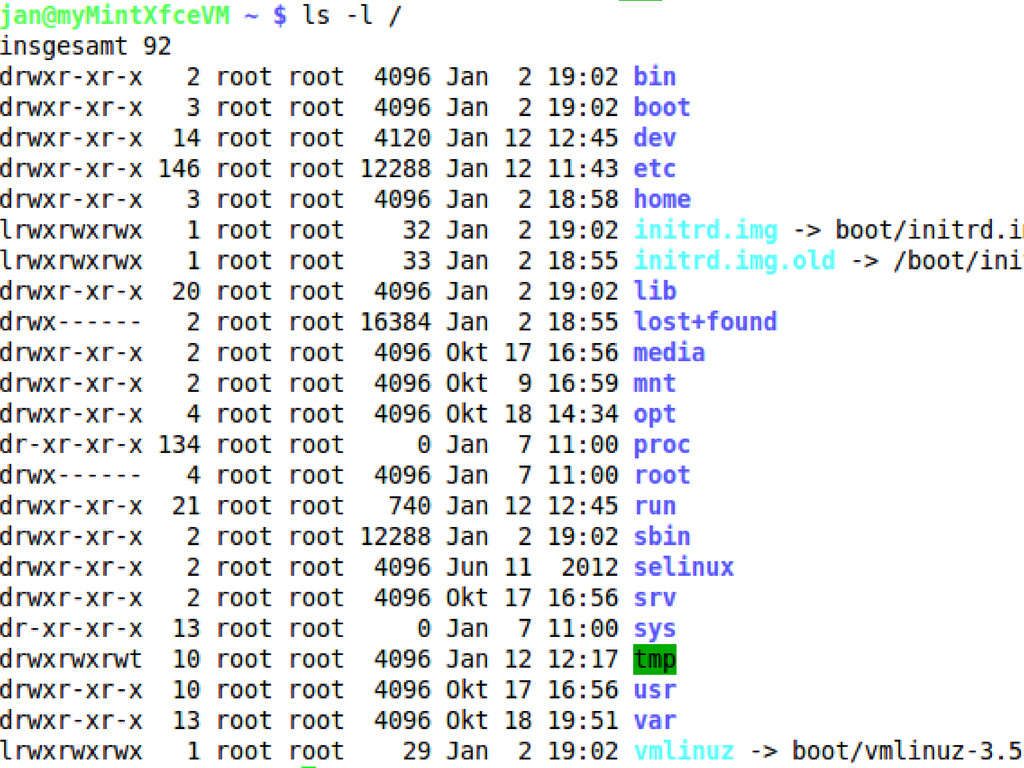{kind=link}
{kind=link}
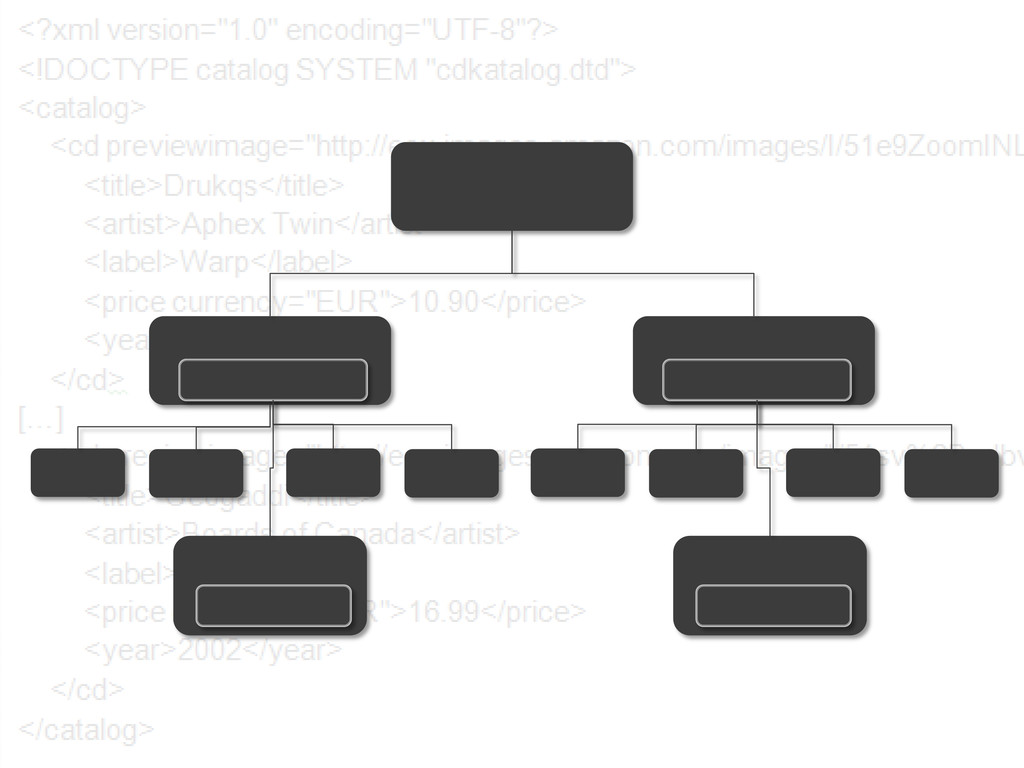{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
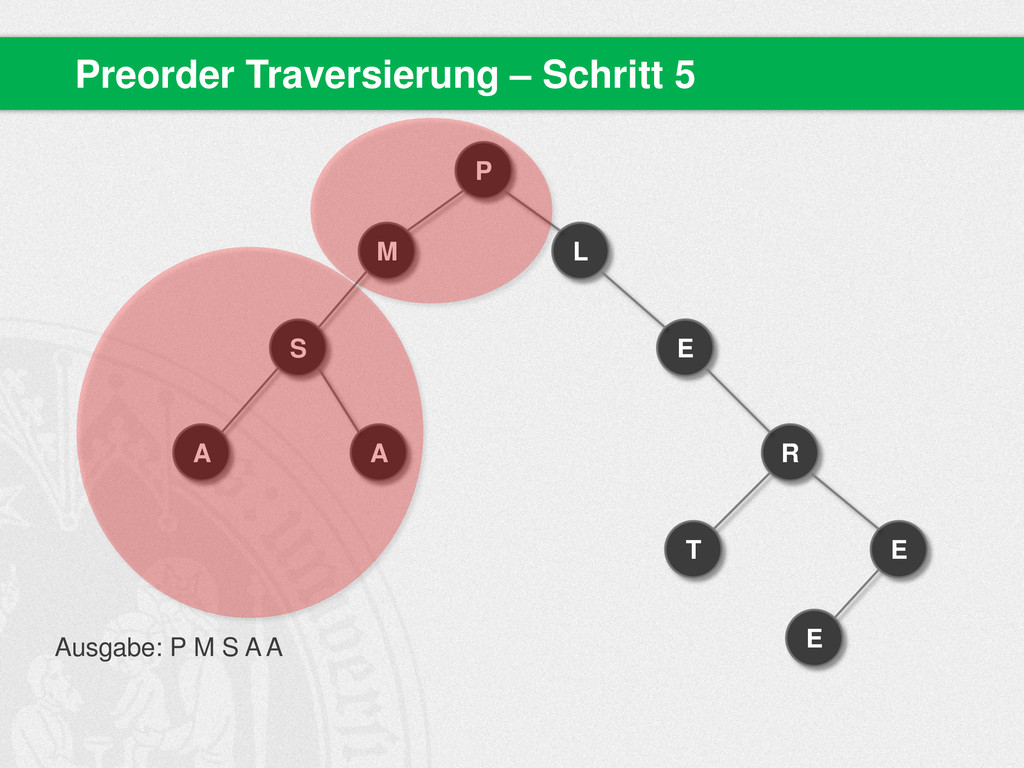{kind=link}
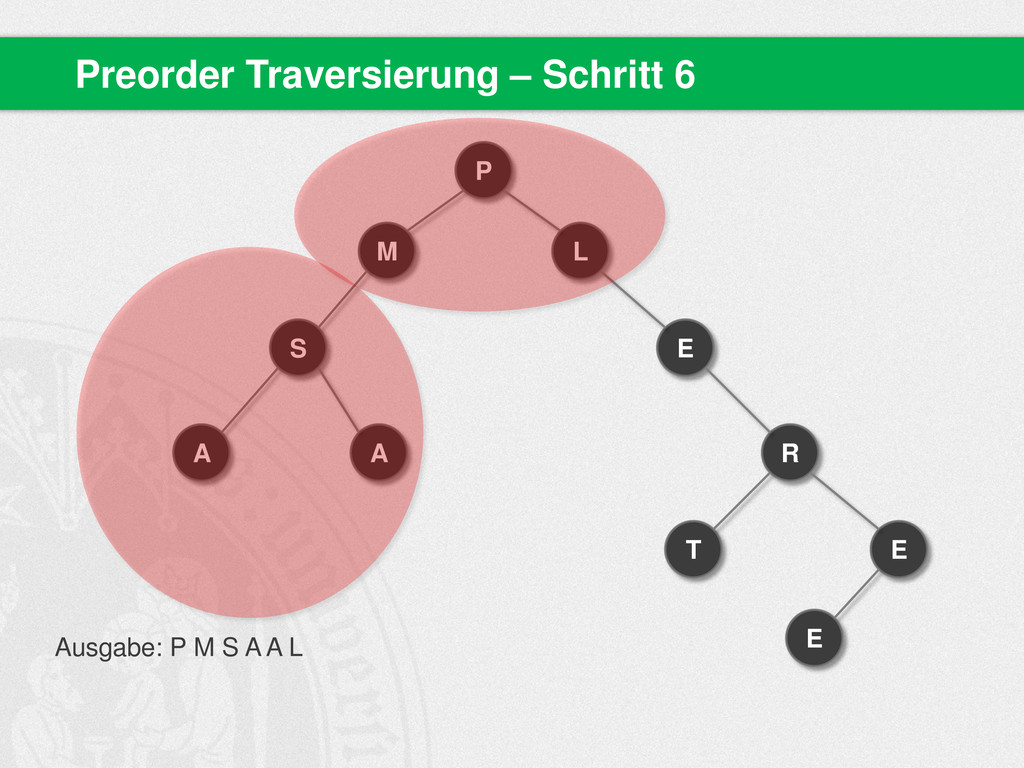{kind=link}
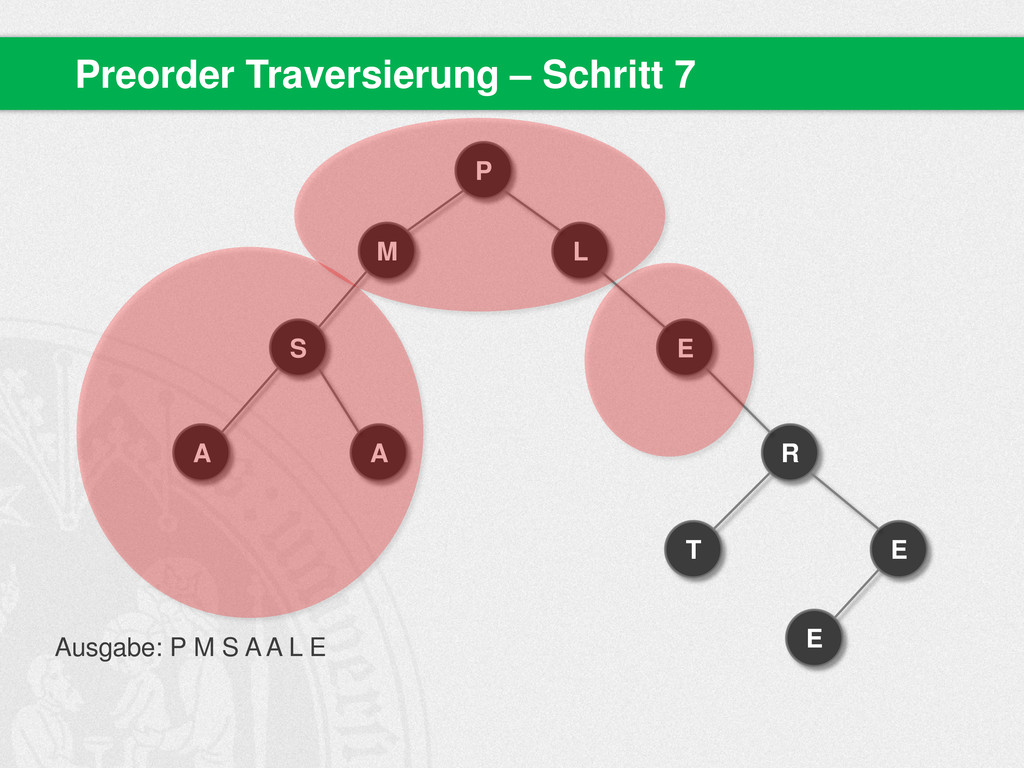{kind=link}
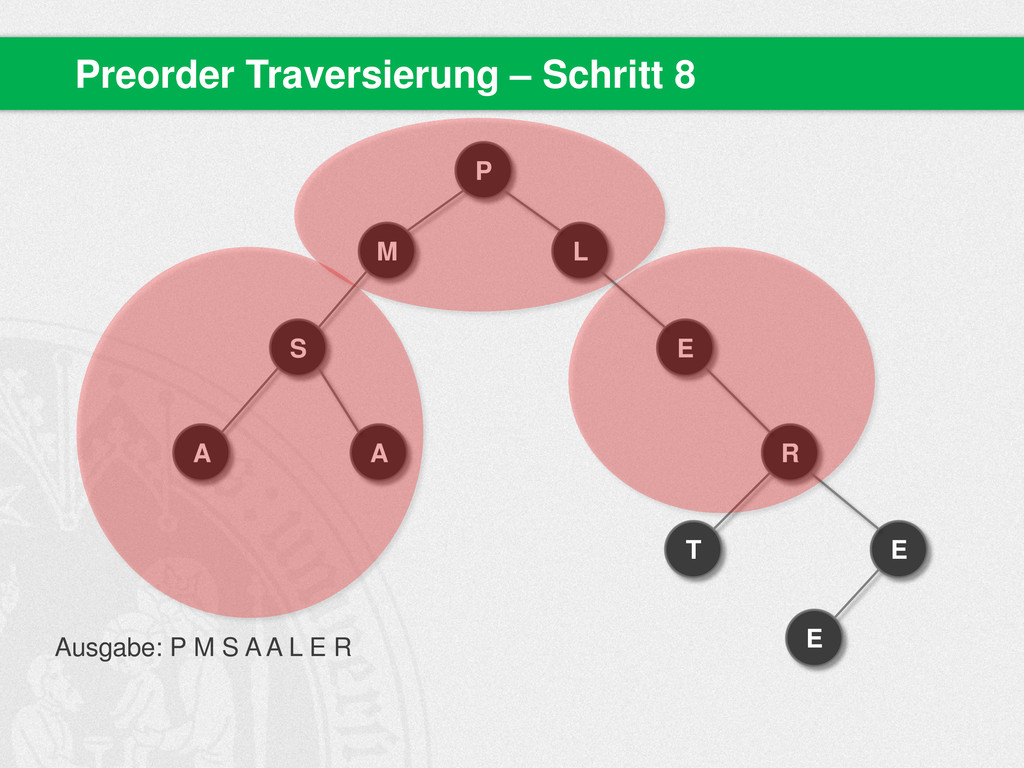{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}