What happens when your database server runs out of disk space? Will your customers still be able to purchase on your webshop when your web server is at max capacity? Are your surveys still valid after a bot has filled out a couple of thousand times your forms?
These are just a few of the many things that can and will go wrong in your production environments. Are you confident your systems are still delivering value to your customers when the worst possible thing happens? The only way to know for sure is to adopt chaos engineering techniques. As popularised by Netflix with their open sourced Chaos Monkey and Simian Army tools, we should put our system under constant stress to ensure that we can face disruptive disasters at any given time.
In this talk I walk through some of the disasters we faced in the past decade and how we learned how to build resilience by design in all of our projects. We'll also share with you our learnings and our successes when Armageddon takes place. It will be an exciting experience that makes you become Dr. Evil in your own company.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
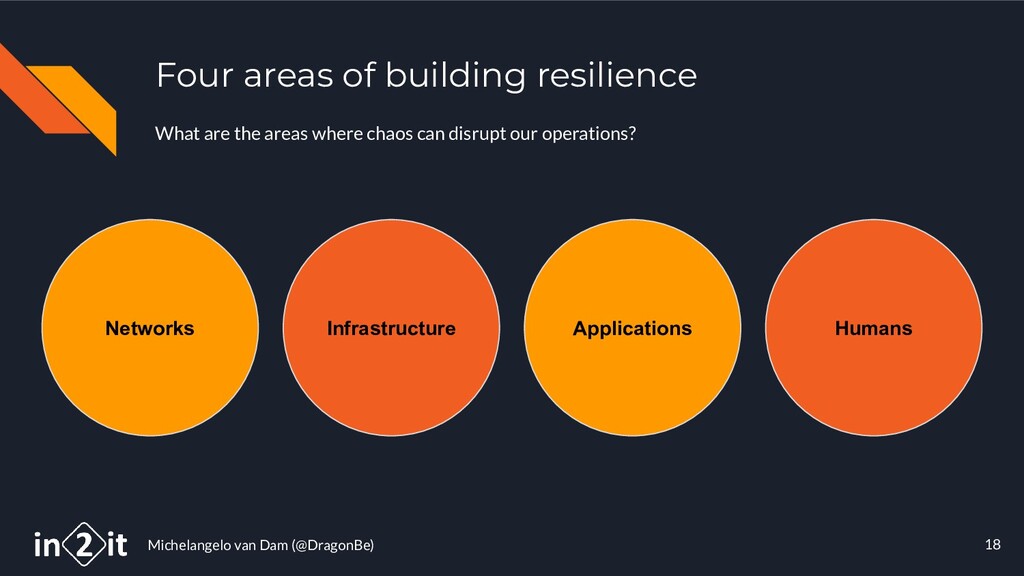{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}