Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【輪講資料】Destination Prediction by Sub-Trajectory ...
Search
Yuichiro SEKIGUCHI
December 18, 2013
Research
560
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【輪講資料】Destination Prediction by Sub-Trajectory Synthesis and Privacy Protection Against Such Prediction【ICDE2013】
2013-12-18に職場で実施した輪講資料を代理アップロードしました.
Yuichiro SEKIGUCHI
December 18, 2013
More Decks by Yuichiro SEKIGUCHI
See All by Yuichiro SEKIGUCHI
【輪講資料】Time-aware Point-of-Interest Recommendation【SIGIR2013】
dreamedge
1
710
【輪講資料】Exploring and Exploiting User Search Behavior on Mobile and Tablet Devices to Improve Search Relevance【WWW2013】
dreamedge
1
220
【輪講資料】Fast Candidate Generation for Two-Phase Document【CIKM2012】
dreamedge
1
170
【輪講資料】Inferring the Demographics of Search Users【WWW2013】
dreamedge
1
230
【輪講資料】Optimal Hashing Schemes for Entity Matching【WWW2013】
dreamedge
2
1.1k
【輪講資料】From Query to Question in One Click: Suggesting Synthetic Questions to Searchers【WWW2013】
dreamedge
1
170
【輪講資料】Are Web Users Really Markovian?【WWW2012】
dreamedge
1
190
【輪講資料】Learning to Rank for Spatiotemporal Search【WSDM2013】
dreamedge
1
970
【輪講資料】Mining the Web for Points of Interest【SIGIR2012】
dreamedge
1
1.2k
Other Decks in Research
See All in Research
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
4.1k
Harness Engineering and Al Agent
kzinmr
3
1.8k
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
某助成金プロジェクト採択に向けて企業研究所のアウトリーチ専任者がやったこと
afroscript
0
100
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
220
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
250
Featured
See All Featured
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Scaling GitHub
holman
464
140k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
What's in a price? How to price your products and services
michaelherold
247
13k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Ethics towards AI in product and experience design
skipperchong
2
330
Transcript
1 Andy Yuan Xue, Rui Zhang, Yu Zheng, Xing Xie,
Jin Huang, Zhenghua Xu: ICDE 2013: 254-265 Destination Prediction by Sub-Trajectory Synthesis and Privacy Protection Against Such Prediction 2013-12-18 輪講資料
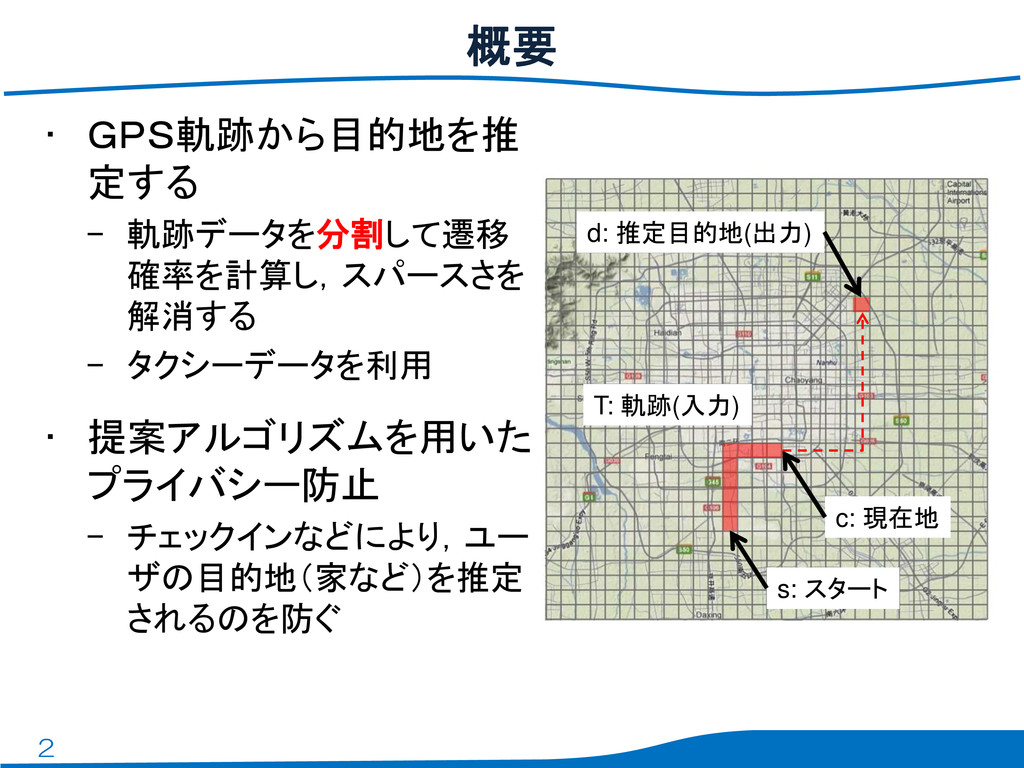
2 • GPS軌跡から目的地を推 定する – 軌跡データを分割して遷移 確率を計算し,スパースさを 解消する – タクシーデータを利用
• 提案アルゴリズムを用いた プライバシー防止 – チェックインなどにより,ユー ザの目的地(家など)を推定 されるのを防ぐ 概要 s: スタート c: 現在地 d: 推定目的地(出力) T: 軌跡(入力)
3 • 目的地推定(Destination Prediction)は多数の位置情 報サービスで必要な技術である – 観光地推薦 – (目的地関連の)広告配信 –
カーナビの自動目的地設定など • 目的地推定の一般的なアプローチは,過去の 軌跡データを利用すること – 入力軌跡と,過去履歴のマッチングを行い,目的地を 推定する はじめに
4 • 概要 • 関連研究 – 一般的手法のイメージ・問題点 – ベイズ推定による目的地推定 •
提案手法(SubSyn; Sub-Trajectory Synthesis Algorithm) • 提案手法を用いたプライバシー漏洩防止 • 実験 • まとめ 目次
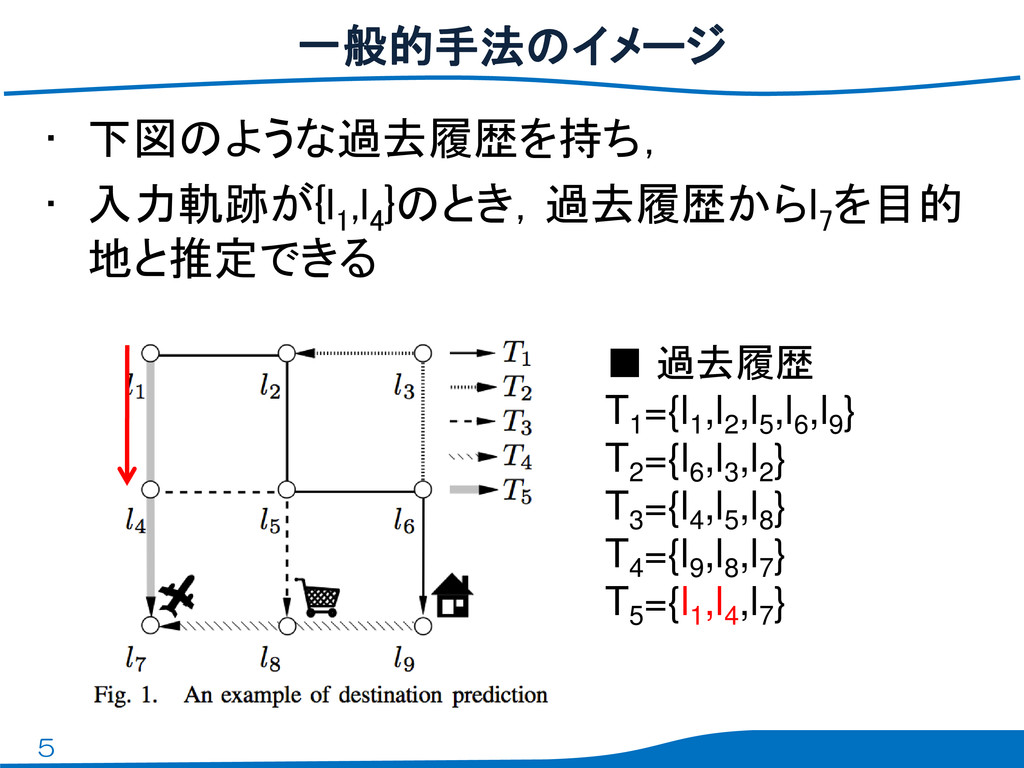
5 • 下図のような過去履歴を持ち, • 入力軌跡が{l 1 ,l 4 }のとき,過去履歴からl 7
を目的 地と推定できる 一般的手法のイメージ ▪ 過去履歴 T1 ={l1 ,l2 ,l5 ,l6 ,l9 } T2 ={l6 ,l3 ,l2 } T3 ={l4 ,l5 ,l8 } T4 ={l9 ,l8 ,l7 } T5 ={l1 ,l4 ,l7 }
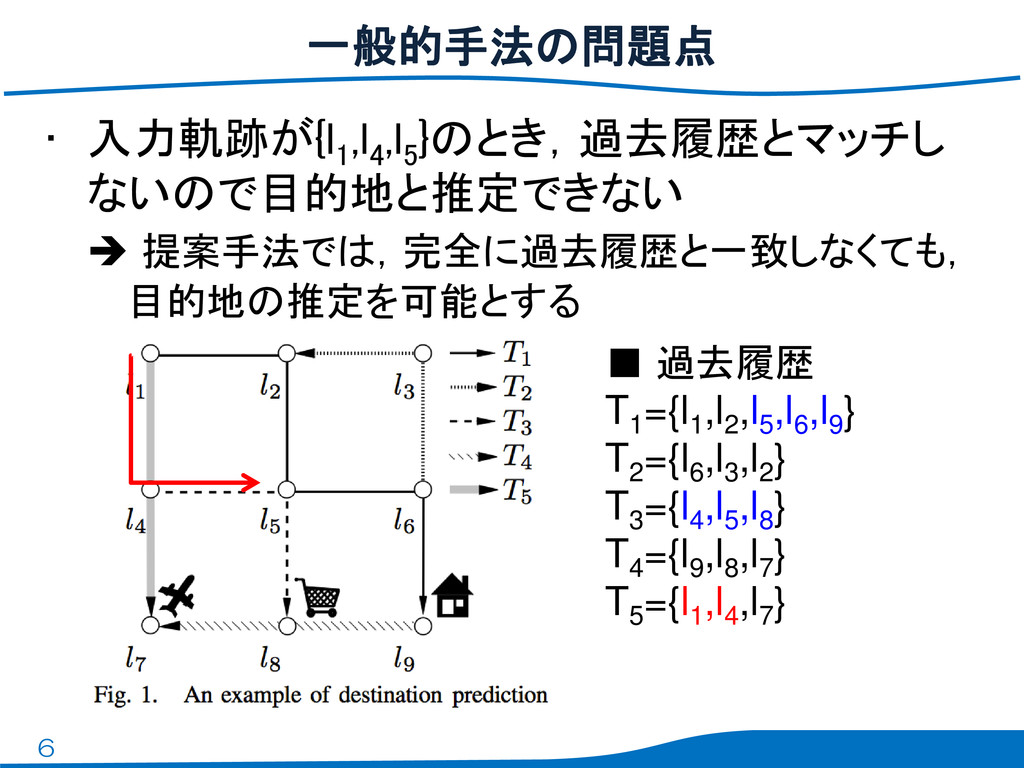
6 • 入力軌跡が{l 1 ,l 4 ,l 5 }のとき,過去履歴とマッチし ないので目的地と推定できない
提案手法では,完全に過去履歴と一致しなくても, 目的地の推定を可能とする 一般的手法の問題点 ▪ 過去履歴 T1 ={l1 ,l2 ,l5 ,l6 ,l9 } T2 ={l6 ,l3 ,l2 } T3 ={l4 ,l5 ,l8 } T4 ={l9 ,l8 ,l7 } T5 ={l1 ,l4 ,l7 }
7 • ベイズの定理により,入力軌跡Tpが与えられた時の 目的地dの推定確率は以下の様に与えられる • Tp=入力軌跡,nj=ノードj(グリッドのセル),d=目的地 • は全履歴のうち到着地がnjの割合で計算可 をどのように求めるかが課題
ベイズ推定による目的地推定[1/2] 推定値が高い到着ノードnjを求めたい
8 • 従来手法は,入力軌跡を含む過去履歴の数を用いて 推定 • 入力と過去履歴が完全にマッチしないと分子が0とな るため,目的地が予測できない入力軌跡がある ベイズ推定による目的地推定[2/2] 到着地がnjの軌跡数 到着地がnjで,入力軌跡を含むの軌跡数
9 • 概要 • 関連研究 • 提案手法(SubSyn; Sub-Trajectory Synthesis Algorithm)
– 部分遷移系列に基づく1次マルコフモデル – 迂回路を考慮した総合遷移確率 – 事後確率の計算 • 提案手法を用いたプライバシー漏洩防止 • 実験 • まとめ 目次
10 • 提案モデルは,最小の部分軌跡(長さ2)のノー ド遷移確率を利用する • 1次のマルコフモデルを仮定する – あるノードへの移動は,直前1個のノードにより決定 される確率過程とする 1次マルコフモデル[1/2]
ノード{i,j}の連続を含む軌跡数 ノードiを含む軌跡数 i→jの 遷移確率
11 1次マルコフモデル[2/2] ▪ 過去履歴 T1 ={l1 ,l2 ,l5 ,l6 ,l9
} T2 ={l6 ,l3 ,l2 } T3 ={l4 ,l5 ,l8 } T4 ={l9 ,l8 ,l7 } T5 ={l1 ,l4 ,l7 } 1次マルコフベースの 遷移行列M
12 • 遷移行列Mをr乗すると,Mrの要素はあるノードから別 のノードへrステップで辿り着く確率となる • 例えば,ノード1からノード6への最短経路長が長さ3 のとき,最短経路長で遷移する確率はM3の行列の要 素(1,6)の値となる • ノード1からノード6への(迂回も含めた)遷移確率は,
M3 16 +M4 16 +…+M∞ 16 で計算できる – ※ 大部分の迂回路の長さは,最短経路長の1.2倍を超える ことは無いため,これを上限値とする 迂回路を考慮した総合遷移確率[1/2]
13 • ノードiからkへの遷移確率 • グリッドが30×30のとき,遷移行列Mは302×302 下記変形を行うことで計算量・メモリ量を抑えられる 迂回路を考慮した総合遷移確率[2/2] 最短経路長+ceil(最短経路長×0.2)
14 • 2(g-1)が最も長い経路長 • Line3はA[0]←I の誤り? • 遷移が無いノードをリスト から除く •
Listを経路長でソートする ことでMpowerの計算量を 抑えている アルゴリズム(学習) メモリ量
15 • 入力軌跡Tp(s→c)を用いて尤度を推定 • 入力軌跡の出現確率 • 遷移確率pijは全て計算済みなので,高速計算可能 事後確率の推定 出発地→到着地 現在地→到着地
16 アルゴリズム(推定)
17 • 概要 • 関連研究 • 提案手法(SubSyn; Sub-Trajectory Synthesis Algorithm)
• 提案手法を用いたプライバシー漏洩防止 – End-Point 削除法 • 実験 • まとめ 目次
18 • 入力軌跡Tp={l 1 ,l 4 ,l 5 ,l 6
}に対して,提案手法を用いれば 目的地を推定することができる FoursquareのチェックインやSNSにアップした写真のジオタ グの系列(=入力軌跡)から,自分の知られたく無い目的地 が推定されないかを提案手法を用いて調べる • 知られたく無い目的地が,推定結果の上位k件に含ま れない様になるまで,入力軌跡からノードを削除 – End-Point削除法を提案 プライバシー漏洩防止
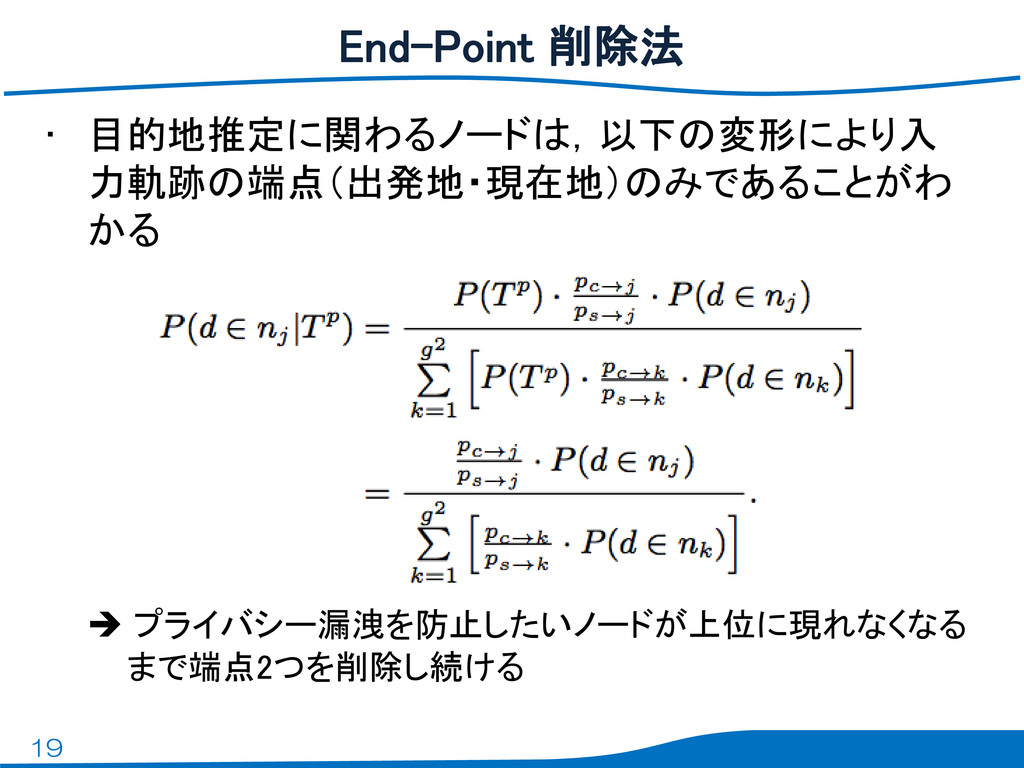
19 • 目的地推定に関わるノードは,以下の変形により入 力軌跡の端点(出発地・現在地)のみであることがわ かる プライバシー漏洩を防止したいノードが上位に現れなくなる まで端点2つを削除し続ける End-Point 削除法
20 • 概要 • 関連研究 • 提案手法(SubSyn; Sub-Trajectory Synthesis Algorithm)
• 提案手法を用いたプライバシー漏洩防止 • 実験 – 予測精度(Prediction Error),網羅性(Coverage) – 学習時間,推定時間 • まとめ 目次
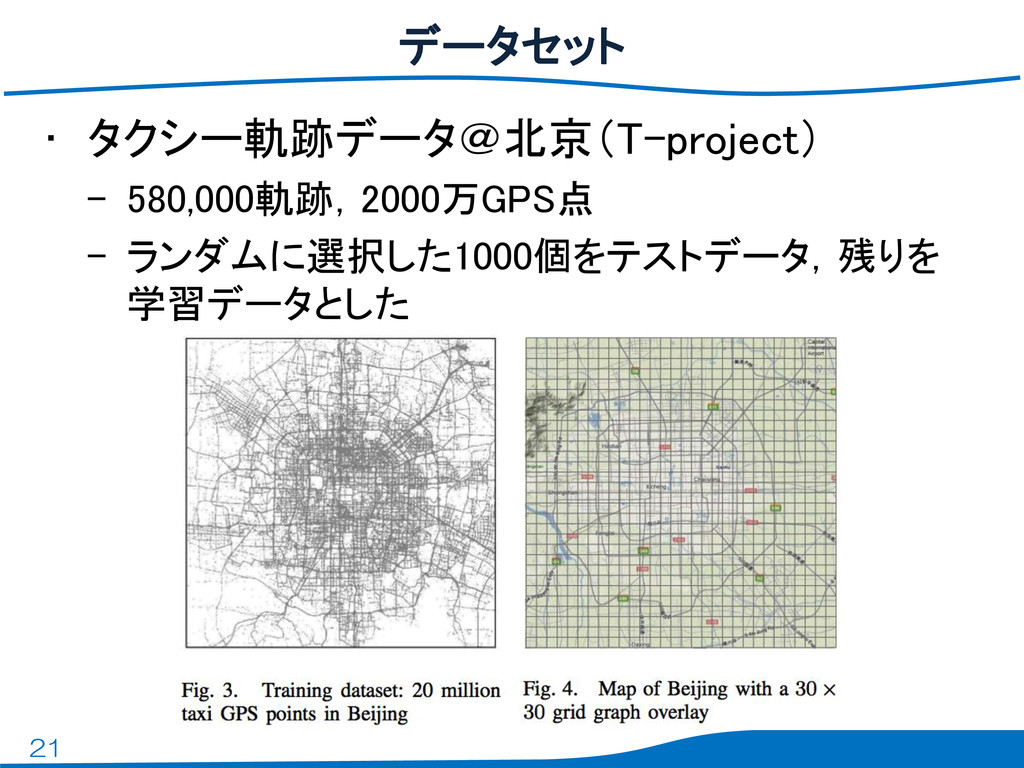
21 • タクシー軌跡データ@北京(T-project) – 580,000軌跡,2000万GPS点 – ランダムに選択した1000個をテストデータ,残りを 学習データとした データセット
22 • Coverage [% test dataset] – 入力軌跡に対して,k個の目的地を推定できた割合 ※ 従来手法の場合,入力軌跡が過去履歴に含まれないと
目的地を推定できないため,Coverageが低くなる • (Aggregated) Prediction Error [km] • 推定値と真の到着地の間の距離 • 入力軌跡に対して複数個出力した場合は,その平均値 評価指標
23 • グリッドサイズ – g = 20×20, 30×30, 40×40, 50×50
• 入力軌跡長 – trip = 軌跡全体の10% 〜 90% • 推定地数 – Top-k = 1〜5 評価パラメータ
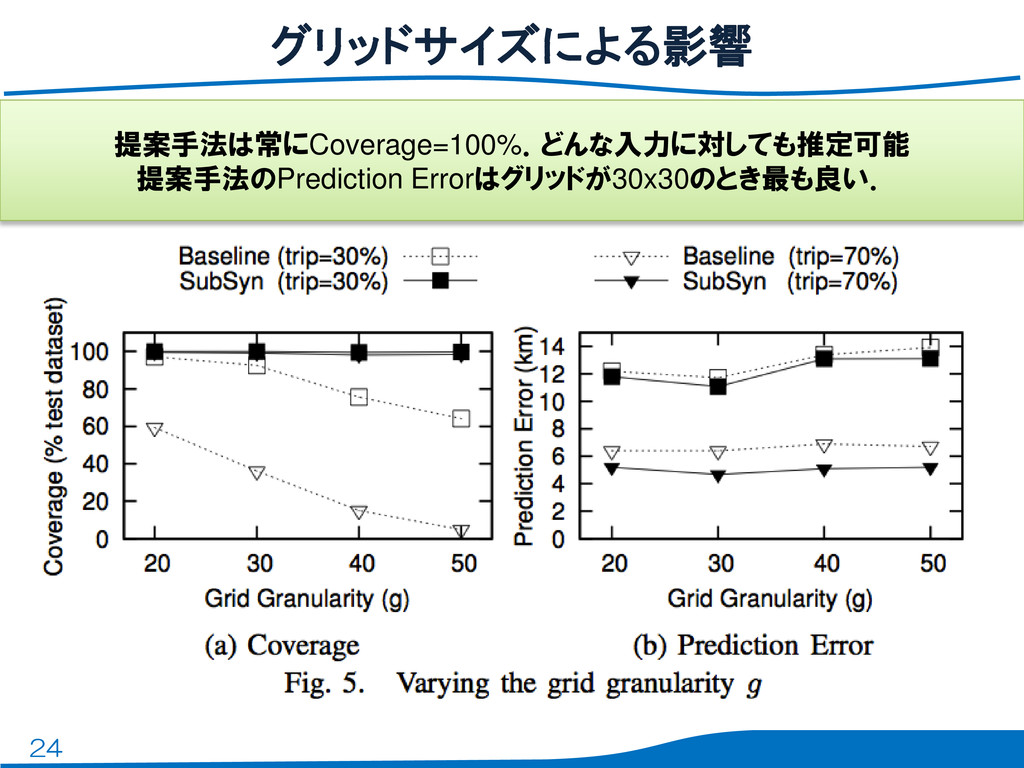
24 グリッドサイズによる影響 提案手法は常にCoverage=100%.どんな入力に対しても推定可能 提案手法のPrediction Errorはグリッドが30x30のとき最も良い.
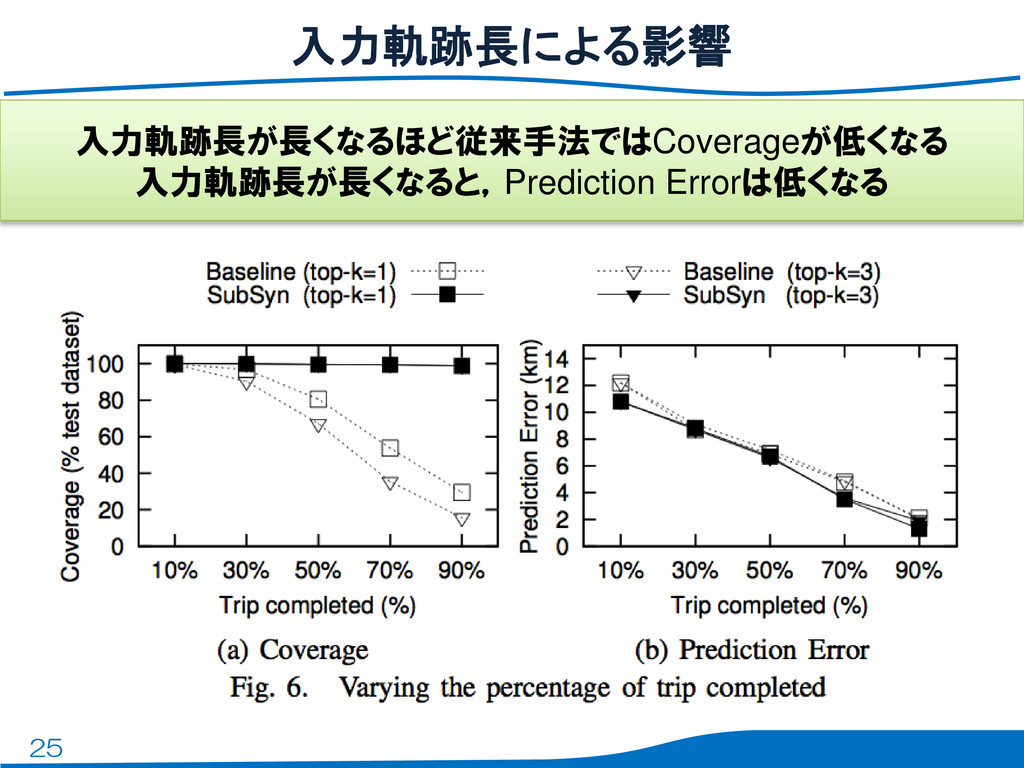
25 入力軌跡長による影響 入力軌跡長が長くなるほど従来手法ではCoverageが低くなる 入力軌跡長が長くなると,Prediction Errorは低くなる
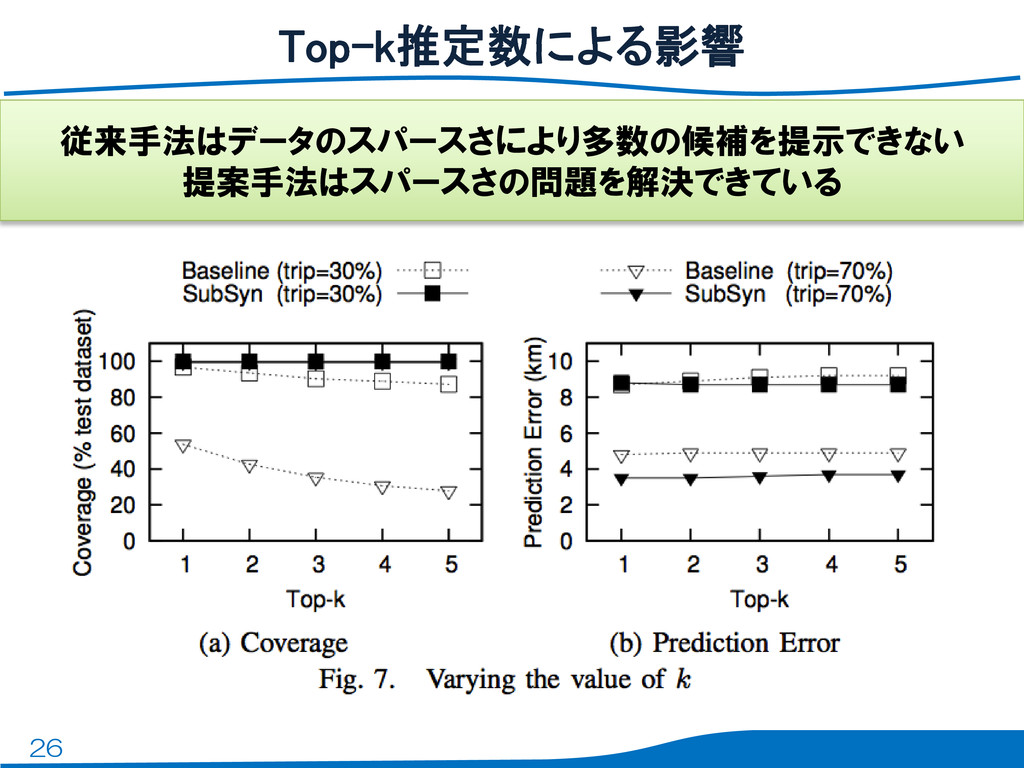
26 Top-k推定数による影響 従来手法はデータのスパースさにより多数の候補を提示できない 提案手法はスパースさの問題を解決できている
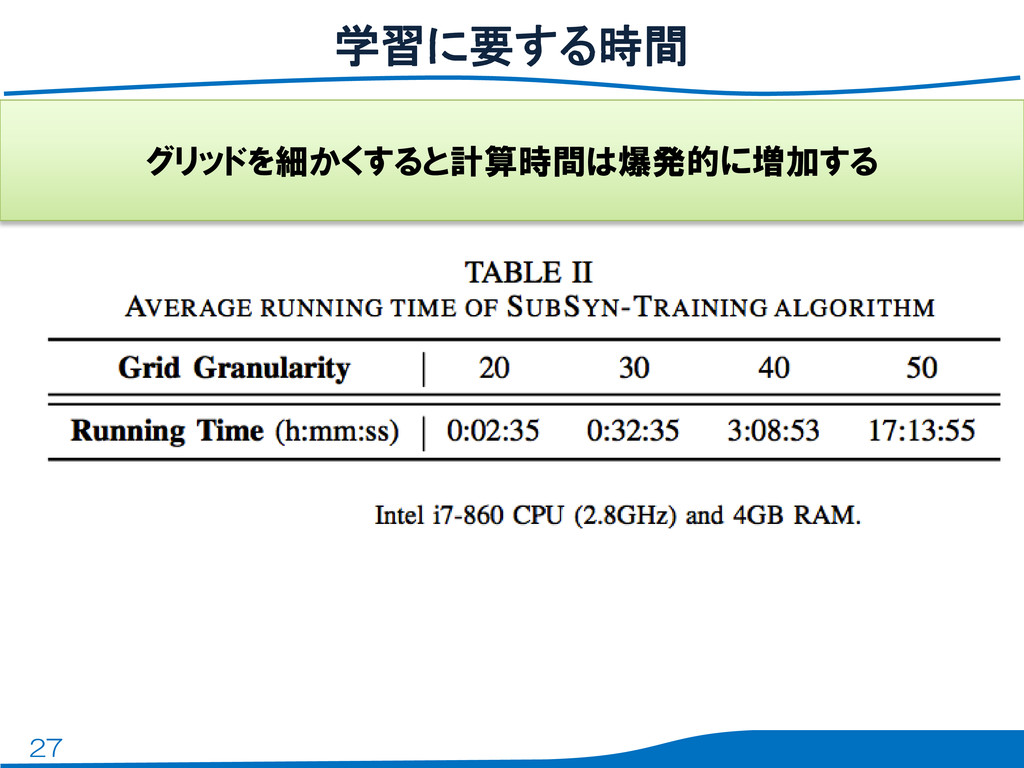
27 学習に要する時間 グリッドを細かくすると計算時間は爆発的に増加する
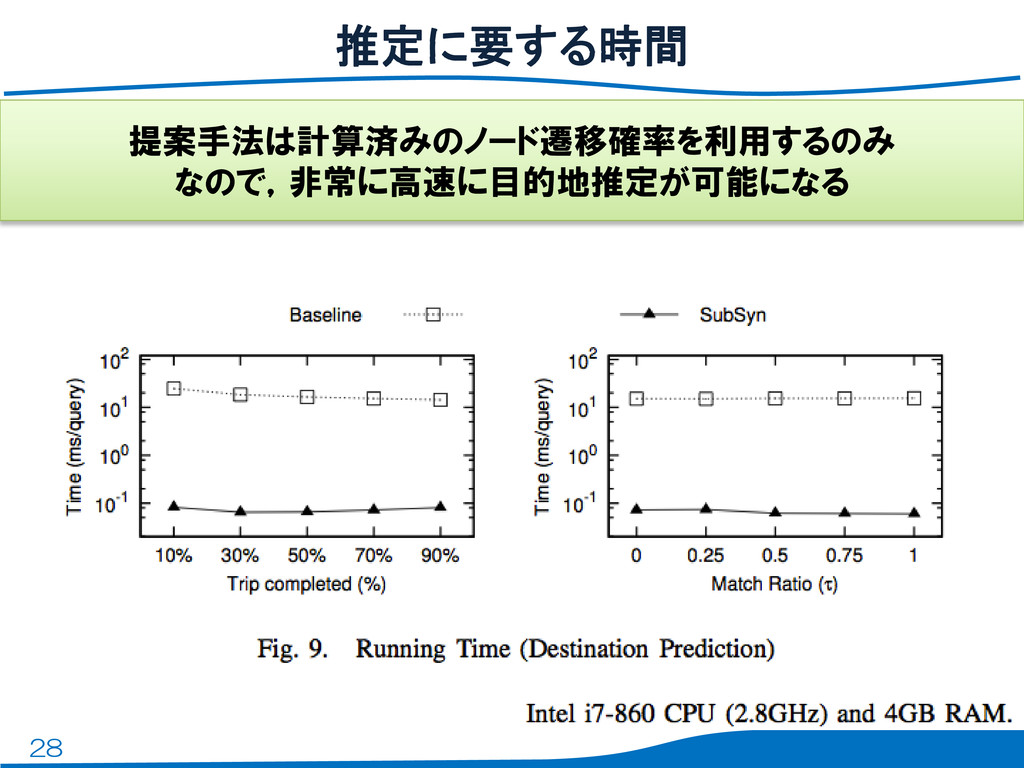
28 推定に要する時間 提案手法は計算済みのノード遷移確率を利用するのみ なので,非常に高速に目的地推定が可能になる
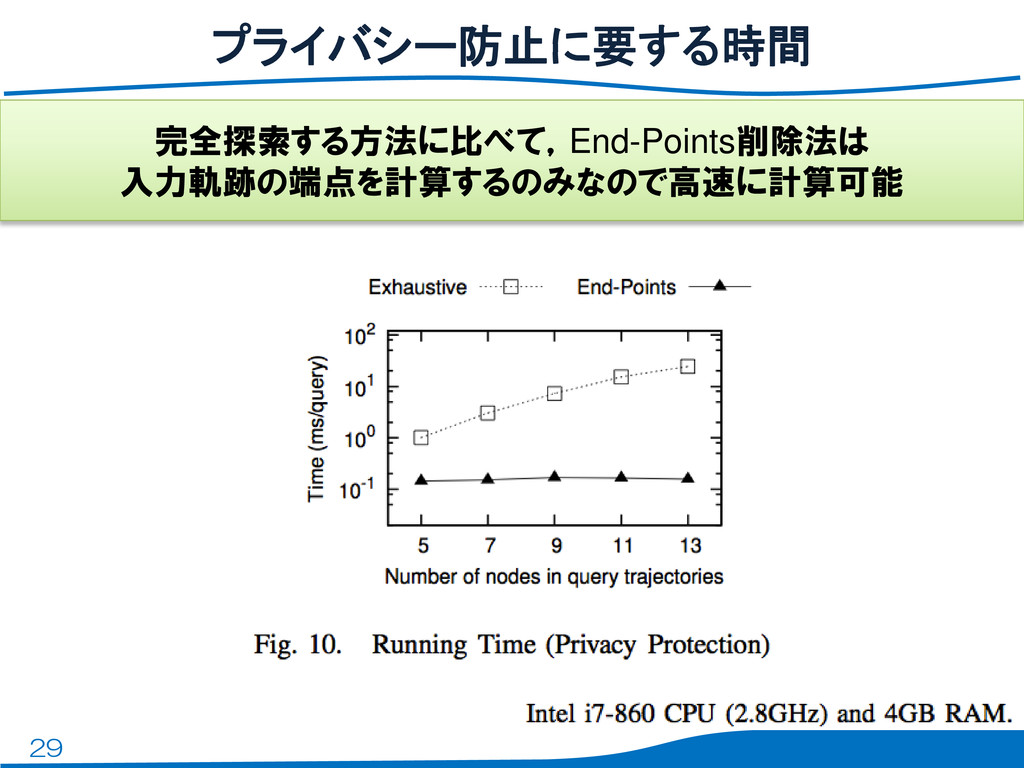
29 プライバシー防止に要する時間 完全探索する方法に比べて,End-Points削除法は 入力軌跡の端点を計算するのみなので高速に計算可能
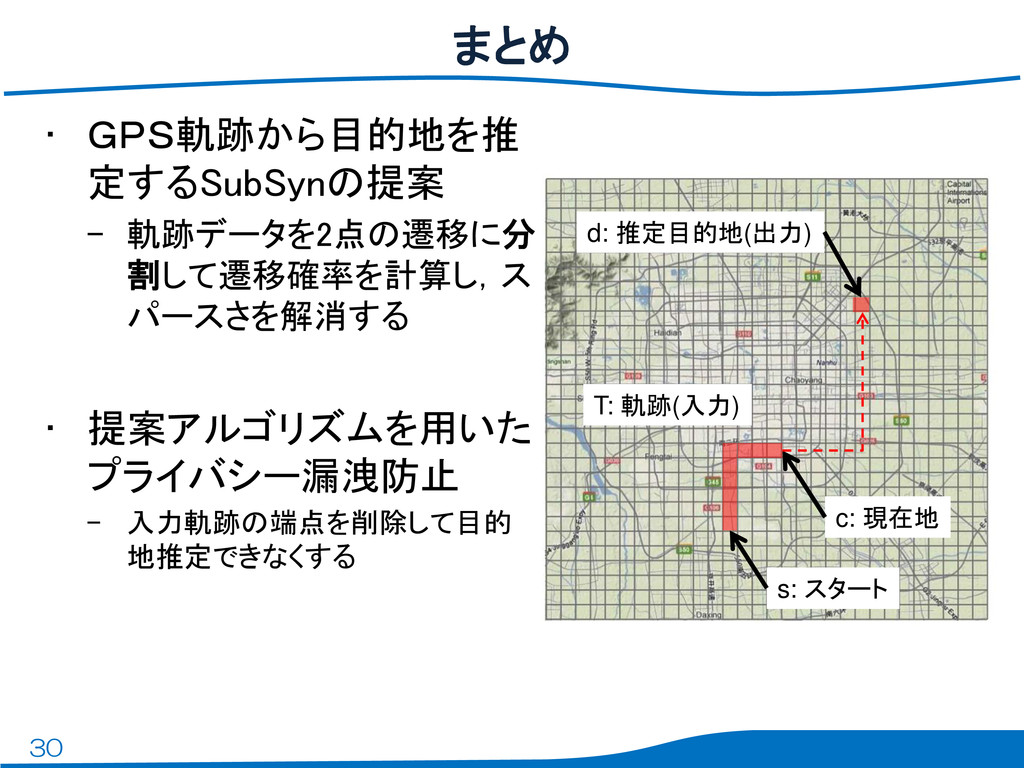
30 • GPS軌跡から目的地を推 定するSubSynの提案 – 軌跡データを2点の遷移に分 割して遷移確率を計算し,ス パースさを解消する • 提案アルゴリズムを用いた
プライバシー漏洩防止 – 入力軌跡の端点を削除して目的 地推定できなくする まとめ s: スタート c: 現在地 d: 推定目的地(出力) T: 軌跡(入力)
31 • 過去に無い経路でも,部分軌跡の組合せがあれば 目的地推定可能 • グリッドサイズが大きくなると学習時間が爆発的に 増えてしまう – 1グリッド内に複数個のPOIが存在することになる •
パーソナライズはしていない • 時間帯を考慮するには複数個遷移行列を考えなけれ ばならない? • 1次マルコフで本当にOKなのか? 考察
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![8 • 従来手法は,入力軌跡を含む過去履歴の数を用いて 推定 • 入力と過去履歴が完全にマッチしないと分子が0とな るため,目的地が予測できない入力軌跡がある ベイズ推定による目的地推定[2/2] 到着地がnjの軌跡数 到着地がnjで,入力軌跡を含むの軌跡数](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_7.jpg){kind=link}
{kind=link}
![10 • 提案モデルは,最小の部分軌跡(長さ2)のノー ド遷移確率を利用する • 1次のマルコフモデルを仮定する – あるノードへの移動は,直前1個のノードにより決定 される確率過程とする 1次マルコフモデル[1/2]](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_9.jpg){kind=link}
![11 1次マルコフモデル[2/2] ▪ 過去履歴 T1 ={l1 ,l2 ,l5 ,l6 ,l9](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_10.jpg){kind=link}
{kind=link}
![13 • ノードiからkへの遷移確率 • グリッドが30×30のとき,遷移行列Mは302×302 下記変形を行うことで計算量・メモリ量を抑えられる 迂回路を考慮した総合遷移確率[2/2] 最短経路長+ceil(最短経路長×0.2)](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_12.jpg){kind=link}
![14 • 2(g-1)が最も長い経路長 • Line3はA[0]←I の誤り? • 遷移が無いノードをリスト から除く •](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22 • Coverage [% test dataset] – 入力軌跡に対して,k個の目的地を推定できた割合 ※ 従来手法の場合,入力軌跡が過去履歴に含まれないと](https://files.speakerdeck.com/presentations/35d198304abb013129791e310588aaf1/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}